电力时间序列的分布式索引算法
2021-03-14吴裔郭棋林陈颢天郭乃网
吴裔 郭棋林 陈颢天 郭乃网




摘 要:时间序列的研究已经被应用到越来越多的领域中。越来越多的领域应用需要索引和分析海量的时间序列,代表性的比如金融,电力,生物信息等等。这类应用往往面临数以亿计的时间序列的处理,然后从中识别出一些隐藏的模式来。然而目前对时间序列的索引技术都是单机版本,需要用漫长的时间来对大量的时间序列进行索引,限制了时间序列分析的产出率。提出了一种基于Isax表达的分布式时间序列索引算法,并在Spark分布式计算框架下实现算法。首先,给出了基于Isax的分布式索引算法的朴素实现想法,指明了其存在的问题。然后提出一种先建立索引结构,再将时间序列哈希到相应叶子节点的分布式索引算法。最终,构建了一个完整的电力时间序列的近邻近似查询系统,再保证查询精确率的前提下大大提高了计算效率。并在实验数据集上证明了算法的正确性、高效性和可扩展性。
关键词:时间序列;分布式;索引
DOI:10.15938/j.jhust.2021.06.011
中图分类号: TP392
文献标志码: A
文章编号: 1007-2683(2021)06-0081-06
A Distributed Algorithm for Indexing Power Time Series
WU Yi1, GUO Qi-lin2, CHEN Hao-tian1, GUO Nai-wang1
(1.State Grid Shanghai Municipal Electric Power Company, Shanghai 200122, China;
2.School of Economics, Fudan University, Shanghai 200433, China)
Abstract:Time series research has been applied to more and more areas. More and more domain applications need to index and analyze massive time series, such as finance, electricity, bioinformatics, and so on. Such applications are often faced with hundreds of millions of time series of processing, and then identify some hidden pattern from the model. Firstly, we give a simple idea of the distributed indexing algorithm based on Isax, which points out its existing problems. Then we propose a distributed indexing algorithm to establish the index structure and then insert the time series to the corresponding leaf node. Finally, this paper constructs a complete approximation query system of power time series, and greatly improves the computational efficiency under the premise of ensuring the accuracy of query. The correctness, efficiency and expansibility of the algorithm are proved on the experimental data set.
Keywords:time series; distributed algorithm; index
0 引 言
随着配用电网技术的发展、电力采集设备的更新,电力系统积累了海量用电负荷数据。而电网的稳定运行和智能化发展在很大程度上依赖于对这些数据的挖掘分析[1],如用电预测、错峰调度、用户用电行为模式识别、设备状态和风险评估[2-3]等等。在这个过程中,我们会涉及到数以亿计的数据资源的调取、运算以及分类等,而这样级别的运算量对于计算性能、数据库性能有着极高的要求,在数据挖掘领域,尤其是每天都有百万更新數据的电力数据分析领域,用更少的计算资源、更短的时间搜索到更加精确可靠的结果是我们的最终目标,也是所有数据挖掘研究的前提条件。而在这些搜索的背后,都需要近似近邻查询。
在大规模的高维时间序列的应用场景中,精确的近邻查询需要耗费大量存储和计算资源,实际应用中效果不理想。近似近邻查询技术可以大幅度缩短查询时间,同时效果比较好的近似近邻查询方法都可以保证查询结果与精确查询结果近似。由于其在的高应用价值,近似近邻技术被广泛应用于信息检索,统计分析,机器学习等领域。
近年来,时间序列的近似近邻查询技术有了很大的进展,但是随着互联网的蓬勃发展,需要处理的数据规模越来越大。传统的单机版索引算法和索引结构往往只能处理小规模数据。大规模数据往往无法做到单机存储,这些数据往往存储于分布式系统中且需要一种分布式索引结构来支持查询和检索。
随着google、facebook等企业和实验室相继开源了Haoop、Stotm、Spark等分布式计算平台,有效的管理和分析海量分布式数据成为可能。本文基于Spark分布式计算平台提出一种使用Isax表达的分布式时间序列索引算法。
本文第2节介绍了Spark分布式计算平台,Isax表达式以及时间序列上的分布式索引研究进展。第三章介绍了基于Isax的分布式时间序列索引算法及其在Spark上的设计与实现。第四节分析讨论了索引算法和基于索引的最近邻查询在大规模时间序列数据集上的实验结果。第五节介绍了算法在电力数据挖掘中的实际应用。第六节对本文工作进行了总结和展望。
1 相关工作
1.1 SPARK与MR编程模型
分布式编程模型(MapReduce,MR)[4]是一种用于并行运算的编程范式,用户无需关注分布式通信和传输的细节,只需关注包装在map、reduce中的核心业务逻辑,就可在分布式系统上运行自己的程序。简单的说,MR编程范式采用了”分而冶之”的思想,将一个大而复杂的作业分割成众多小而简单的独立任务,然后将这些任务分发给集群中的各节点独立执行。MR为用户提供了一个极其简单的分布式编程模型。
主流的实现MR编程模型的框架主要有Google的Hadoop平台和UC Berkeley AMP lab的Spark[5]。相对于Hadoop,Spark启用了分布式内存数据库,可以在内存中完成所有的数据分析操作再将结果存入集群,其在迭代计算中速度要远远快于Hadoop。同时其提供了更丰富的api接口,以及覆盖整个数据分析流程的DAG图,更有利于分布式算法的设计和实现。
1.2 时间序列表达式
时间序列通常维度非常高,高维空间下时间序列呈现稀疏性,导致不符合大数定律,统计结果不具备可信度。时间序列的降维手段主要有分段聚集近似PAA[6],符号聚集近似SAX[7]和可索引的符号聚集近似iSAX[8]等等。分段段聚集近似PAA[6]。将时间序列在时间轴上划分为若干段,每段用平均值来表示。SAX[7]将标准化后的时间序列PAA处理,然后根据高斯分布和子段值将序列离散化为符号串。iSAX时SAX基础之上提出的一种多辨析率的符号化表示,通过选择不同的基数大小表达不同的辨析率层次。
时间序列的索引方法中,效果比较好的主要有iSAX[8]索引,以及iSAX2.0[9]。iSAX2.0[9]通过增加bulk loading机制和一种基于统计的分裂策略大大减少了索引所需的时间,使得索引算法能够处理数亿级的时间序列。
但是不论是iSAX[8]还是iSAX2.0[9]都是单机版的算法,受到单机内存和计算资源的制约,在面临更大数据的时间序列时扩展性不足。本文提出一种分布式iSAX索引算法。不仅提高了索引速度,而且具備很强的扩展性。
1.3 分布式相似性索引算法
分布式索引算法不等于相似性索引算法。树结构相似性索引方法有很多,比如R树、KD树等。
经典的KD树会将原始的数据空间按数据的维度划分为一棵二叉树。也有解决kd树在高维空间退化现象的随机化kd树的方法。李天驹等人提出一种面向KD树建树过程的多核并行算法-ParK[10]。FLANN[11]中包含的层次Kmeans树,在每一层都使用Kmeans聚类,若类中节点小于某个阈
值则作为叶子节点,否则是中间节点继续对节点下的数据进行Kmeans聚类,Kmeans算法可以利用MR框架并行化,相比单机版提升了建树的速度。但是这样的Kmeans树虽然能够快速的找到近邻候选集合,但是在树的每一层都需要进行一次Kmeans聚类所消耗的空间和时间资源还是非常之大。Murphy等的工作中介绍了这种算法的MR版本[12]。
传统的树结构索引在大规模数据下往往迎来空间资源不足的局面。而基于哈希的索引方法有着良好的扩展性,适合在分布式环境下处理海量的数据。
局部敏感哈希(LSH)[11]是最常见的数据无关哈希方法。其基本思想是在空间转换中保持原始空间和转换后空间的相似性。原始空间中越相似的两个数据点,经过哈希之后,越有可能被哈希到同一个桶,桶的编号就可以作为他们的整体编码。常见的有基于欧式距离、余弦距离、Jaccard距离的局部敏感哈希算法。局部敏感哈希算法非常适合利用MR框架并行化,Szmit等[13]已经实现了相应的分布式版本。LSH为了有更好的索引效果,并行化的LSH算法往往需要经历多轮不同节点间的数据传输(shuffle)。本文基于isax索引的特性,提出了一种只需要一次shuffle的基于MR的分布式时间序列索引算法。
2 分布式的时间序列索引算法
2.1 并行模式分析
2.1.1 朴素想法
1)单机版建立isax索引如图1所示,每条时间序列计算isax表达,并分配到一个节点,如果节点上时间序列的数量超过阈值,则进行split。而split的策略是从左到右依次基数加倍,将父节点上的时间序列根据新基数重新计算isax表达并分配到新的节点上。
2)由上述过程可以发现,每个时间序列在这个树中的操作是相互独立的。可以将每一层的isax表达式视为哈希桶的key,每一层的各个节点分别是不同key值的哈希桶。朴素的分布式建树可以视为一个层次的哈希过程,每一层某个哈希桶中数据量小于阈值为叶子,否则继续进入下一轮哈希。但是这样的分布式算法扩展性较差,且面临一系列问题。
2.1.2 朴素想法存在的问题
1)算法存在数据倾斜问题:其一方面是由于时间序列的分布本身并不均匀,有些中间节点分裂后信息熵减少有限。另一方面是由于程序多次使用shuffle算子。
2)算法耗费大量的传输时间,成为性能瓶颈。在建立索引树的每一层节点时都需要一次shuffle过程,而shuffle过程消耗大量的传输时间,是hadoop,spark这类分布式计算平台的性能瓶颈。
3)解决方案:①让shuffle算子提高并行度,缓解数据倾斜问题;
②把部分数据清洗掉,比如数据集中中很多0.0的时间序列,往往是导致数据倾斜的原因,需要过滤掉;
③尽量避免join操作,将reduce join改为map join,用广播的形式存放小rdd。
这些方案能够大大优化算法的性能,但是却是治标不治本,算法的shuffle次数依赖于树的层次无法减少。因此我们提出了一种建立索引不依赖于树的层次、只需要经过一次shuffle的分布式索引算法。
2.2 算法設计
可以发现,朴素想法中每次shuffle过程的目的只是为了通过获得哈希到每个索引节点的时间序列数目判断是否需要分裂。换而言之,每层的shuffle都只是为了获得树的索引结构。改进算法的思想就是先通过所有的时间序列通过一次shuffle建立整棵索引树的结构,再并行的将所有时间序列分配到相应的叶子节点。
算法过程如下:
1)生成一个长度为depth的由每一层基组成的集合。
2)并行对每条时间序列计算其在索引中经过的长度为depth的路径集合。
3)对所有时间序列的路径集合中的每个iSAX索引节点进行计数。
4)若某个iSAX索引节点计数值大于阈值,则其是中间节点,否则是叶子节点。
5)并行将每条时间序列插入到叶子节点中
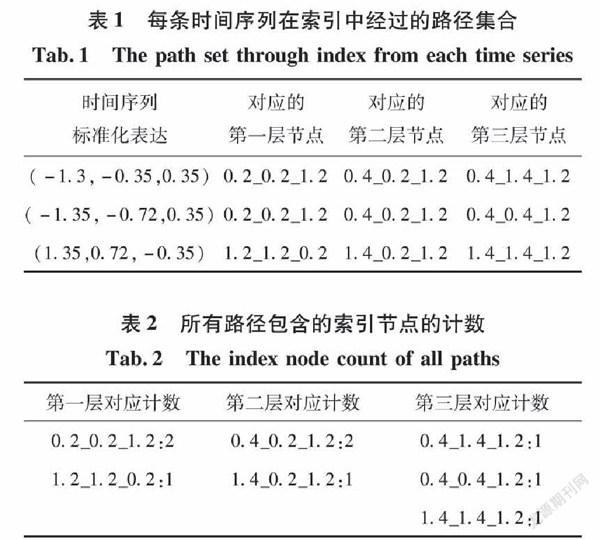
算法通过计算每一个时间序列的路径,对路径上所有节点计数,然后根据每个节点计数值与阈值的关系获得了整棵树的结构。如表1、表2。
如果分裂阈值为2,那么中间节点为0.2_0.2_1.2, 0.4_0.2_1.2.其他都为叶子节点.因此我们就获得了iSAX索引树的形状。找到时间序列对应的叶子节点的具体的做法是再对时间序列计算一次路径,找到路径中第一个不为中间节点的iSAX表达,该表达即时间序列对应的叶子节点.比如对于时间序列t= (-1.3,-0.35,0.35),发现第三层的iSAX表达式0.4_1.4_1.2不在中间节点列表中,将其作为插入的叶子节点表达式.
2.3 索引存储结构
为了适应分布式的插入和查询,我们需要放弃单机版的索引存储方案,因为其会成为整个并行过程中的瓶颈。我们在hadoop大数据分析架构的基础上,采用Hbase技术对用电数据进行存储与管理,提出一种基于iSAX的分布式索引技术对用电数据进行存储索引,实现海量时间序列的高效查询与匹配,如图2所示。
在HBase中,建立表用于存放iSAX的索引结构以及所有的原始时间序列。我们将每一个iSAX节点作为一行存放在HBase中,每一个iSAX节点作为一个对象,对象的内容除了原始iSAX的内容还包括节点类型等内容。根节点的key为“root_node_00”,中间节点和叶子节点的key为iSAX表达,value是iSAX索引节点对象序列化的byte数组。
3 实验和结果分析
3.1 实验环境
实验是在Spark平台下完成的,硬件设备为8台ubuntu15.04的系统,其中主节点配置为3核16G内存;从设备节点采用配置为3核10G内存。
3.2 实验数据集
1)上海市浦东居民和工商业用户的日冻结量,它包括了200万个电表850天的用电数据,数据集的大小为10GB(以下简称200万用户用电数据)。
2)典型上海市30万用户用电数据,365天日冻结量(以下简称30万用户用电数据)。
3.3 实验参数
根据isax索引构建的描述,本实验设置的参数如下:
1)30万用户用电数据:根节点的基数4;
分段数=14;分裂阈值=100;原始时间序列长度=364;
2)100万、200万用户用电数据:根节点的基数4;分段数=17;分裂阈值=100;原始时间序列长度=850;限制最大树高为52;
3.4 结果及分析
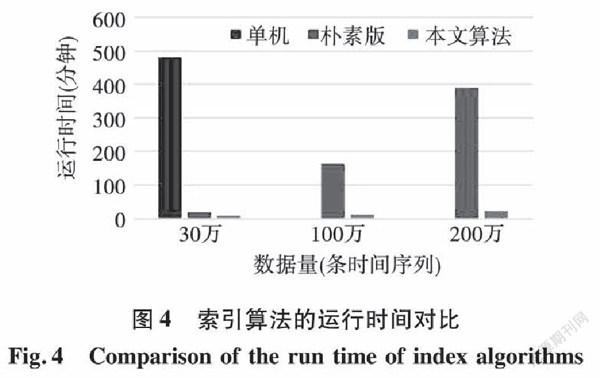
首先对单机版的时间序列索引算法和本文提出的分布式算法的运行效率进行比较.为了证明分布式索引算法的高效性还实现了朴素的分布式索引版本并增加实验对比。
图3实验用来说明本文提出的算法的扩展性。从图一可以看出在100万和200万数据下,随着节点的增多,算法的运行时间也线性的减少。但是在30万数据集下,运行时间并没有随着节点数量增加而减少,反而有所增加。原因是增加节点减少计算时间的同时,反而消耗了更多的分布式通信调度的时间。因此需要根据数据量选择合适的并行度。
图4比较的是单机版及两种分布式算法在不同规模数据集下的运行效率对比。从图4可以看出我们的算法在运行效率远高于朴素的分布式索引算法。这是因为朴素分布式算法在每一层都需要经历一次shuffle,使得传输时间成为了算法的瓶颈。而本文的分布式算法通过先建树再插入的想法,只需要一次shuffle,从而避免了这个问题。单机版的索引算法在30万数据下就需要运行8h,在我们的机器配置下无法在超过百万的数据集下运行。
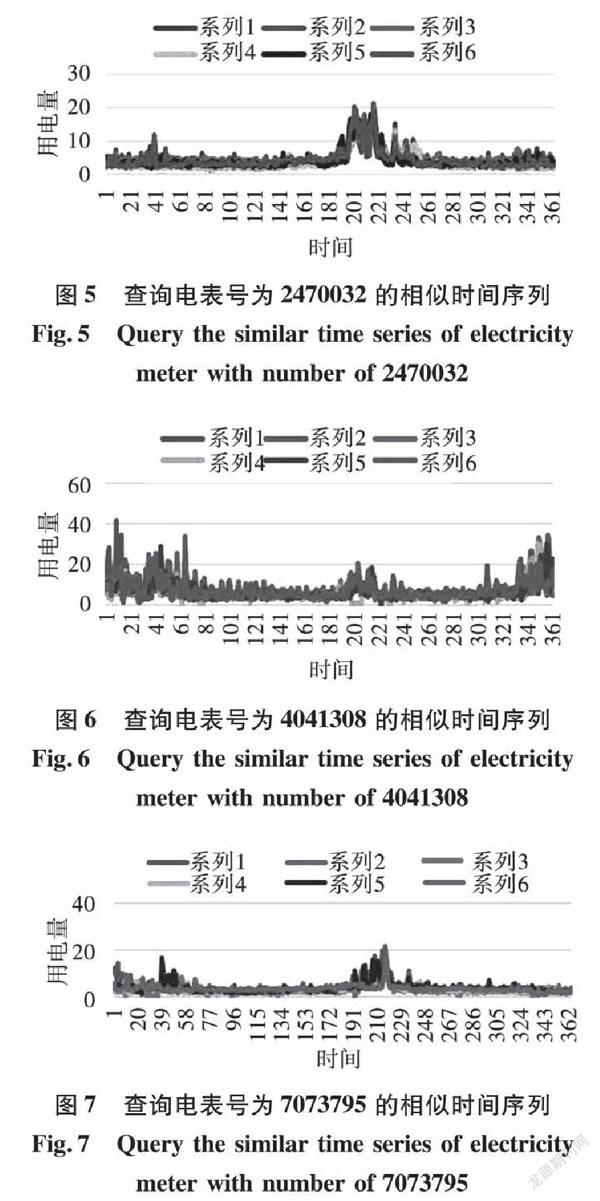
3.5 查询效果展示
查询[7]可以指定返回与查询序列相似的若干条时间序列数目,我们选取返回5条时间序列为例,展示查询效果。其中序列1代表查询序列,序列2-6代表返回的相似时间序列。查询电表号为2470032、4041308和7073795的相似序列发现,返回的时间序列形状上查询时间序列均非常相似。其中绿色时间序列为所要查询的时间序列。可以发现查询到的时间序列整体上与目标非常接近。
3.6 查询性能对比
下面分别对本地顺序存储的时间序列和基于Hbase的iSAX索引的时间序列数据进行查询响应速度对比实验,结果如表4所示。
比较两者的平均查询时间可知,当时间序列的数量超过10000时,在HBase的查询速度超过在本地。当时间序列的数量较小时,因为本地IO的速度大于网络IO的速度,所以Hbase的查询速度小于本地。当时间序列数量越大,Hbase查询的优越性就越能体现,如表5所示。
分布式索引算法的优势在于可以快速对海量时间序列建立索引,以此来应对相似序列查询,这在数据挖掘中有重要意义。同在具体的分析中,如聚类、关联,异常识别等,通过大幅节约数据从数据库提取的时间,可以大大加速分析过程。
4 结 论
用电负荷大数据分析为电力系统的稳定运行和智能化发展提供了数据支撑,而快速有效的索引对日益庞大的数据的存储和读取至关重要。本文基于上海市浦东新区200万电表850d时间序列数据,通过Spark平台实现了分布式索引算法,能够快速准确的进行时间序列查询,同时可以建立多条索引,对不同周期的时间序列进行查询,返回多条相似的完整的时间序列。分布式索引算法避免了通过全局扫描的方法查询,速度比单机版高数十倍,可以有效的提高数据挖掘的产出率,不仅保证了数据分析的正常运行,还可以和数据挖掘算法有机结合大大提高分析效率。除了用电负荷数据,我们的分布式索引算法同样可以应用到更多存在海量时间序列数据的领域。
参 考 文 献:
[1] 张晓晨. 电力大数据应用研究与展望[J]. 山东工业技术, 2017(3):155.
ZHANG Xiaochen. Research and Prospects of Electric Power Big Data Application[J]. Shandong Industrial Technology, 2017(3):155.
[2] 郑海雁, 金农, 季聪,等. 电力用户用电数据分析技术及典型场景应用[J]. 电网技术, 2015, 39(11):3147.
ZHEN Haiyan, JIN Nong, JI Cong, et al. Data Analysis Technology and Application of Electric Power User in Typical Scenarios[J]. Power Grid Technology, 2015, 39(11):3147.
[3] 沈玉玲, 呂燕, 陈瑞峰. 基于大数据技术的电力用户行为分析及应用现状[J]. 电气自动化, 2016, 38(3):50.
SHEN Yulin, LV Yan, CHEN Ruifeng. Electric Power User Behavior Analysis and Application Status Based on Big Data Technology[J]. Electric Automation, 2016, 38(3):50.
[4] DEAN J, GHEMAWAT S. Map Reduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM, 2008, 51(1): 107.
[5] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: Cluster Computing with Working Sets[C]// Hot Cloud, 2010: 10.
[6] KEOGH Eamonn, CHAKRABARTI Kaushik, PAZZANI Michael, et al. Dimensionality Reduction for Fast Similarity Search in Large Time Series Databases[J]. Knowledge and Information Systems, 2001, 3(3): 263.
[7] JUNEJO Imran N., AGHBARI Zaher Al. Using SAX Representation for Human Action Recognition[J]. Journal of Visual Communication and Image Representation, 2012, 23(6): 853.
[8] SHIEH Jin, KEOGH Eamonn. iSAX: Disk-aware Mining and Indexing of Massive Time Series Datasets[J]. Data Mining and Knowledge Discovery, 2009, 19(1): 24.
[9] CAMMERRA A, PALPANAS T, SHIEH J. iSAX2. 0: Indexing and Mining One Billion Teme Serees[C]// International Conference on Data Mining. Washington: IEEE. 2010: 1.
[10]李天驹, 张铮, 张为华. 高效KD树并行算法优化[J]. 计算机系统应用, 2015, 24(8):1.
LI Tianju, ZHANG Zheng, ZHANG Weihua. Efficient KD Tree Parallel Algorithm Optimization[J]. Computer System Applicatoin, 2015, 24(8):1.
[11]MUJA M, LOWE D G. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration[J]. VISAPP (1), 2009, 2(331/340): 2.
[12]HUTCHISON S A. Distributed Kernelized Locality-Sensitive Hashing for Faster Image Based Navigation[R]. Air Force Institute of Technology Wright-Patterson Afb OH Graduate School of Engineering and Management, 2015.
[13]SZMIT R. Locality Sensitive Hashing for Similarity Search Using Map Reduce on Large Scale Data[M]//Language Processing and Intelligent Information Systems. Springer Berlin Heidelberg, 2013: 171.
(编辑:王 萍)
收稿日期: 2020-12-03
基金项目:
国家重点研发计划项目(2017YFC0803700);上海市科委科研计划项目(19DZ2252800);国家电网公司科技项目(52094016000A);国网上海市电力公司科技项目(52094020001A).
作者简介:
吴 裔(1987—),男,博士,工程师;
陈颢天(1996—),男,博士研究生.
通信作者:
郭棋林(1984—),男,硕士,E-mail:15210240072@fudan.edu.cn.
3073501908223
