基于图像处理和深度学习的葡萄叶片钾含量的检测方法
2021-03-11高晓阳李红岭邵世禄
杨 芳, 高晓阳*, 李红岭, 杨 梅, 邵世禄
(1.甘肃农业大学机电工程学院,甘肃 兰州730070;2.甘肃省葡萄与葡萄酒工程学重点实验室,甘肃 兰州 730070;3.甘肃省干旱生境作物学重点实验室,甘肃 兰州 730070)
葡萄种植过程中,营养元素对葡萄品质有很大的影响,其中元素钾在葡萄所含的矿物质中含量最高[1]。当葡萄植株缺钾时,会在一定程度上抑制其对氮含量的吸收,降低叶片的光合作用,叶子会出现发黄长斑的现象,抗病虫能力降低。适时施用钾肥,对促进浆果上色、成熟,提高含糖量及风味有明显效果,对促进根系与枝条生长、增强植株抗寒和抗旱效果显著。传统的植物营养检测方法都是对采摘样本进行实验室分析,如酶学诊断法、化学检测法、施肥检测法、形态检测法等,目前国内外对植物营养元素含量的快速非化学检测方法已成为研究热点。Wiwart等[2]对蚕豆、豌豆和羽扁豆采集的图像颜色进行了分析,进而采用数字图像处理分析了三种豆类的N、P、K、Mg营养元素状况。Fitzgerald等[3]运用图像光谱技术,对小麦氮营养元素进行检测,建立了预测小麦氮素的模型,其相对系数达到97%。Subhash等[4]通过叶绿素荧光分析技术研究了水稻营养元素,结果发现荧光强度比值F740/F725和F690/F750能更好地反应出水稻营养元素匮乏状况。这些研究解决了实验室分析方法及根据种植经验判断等耗时耗力的弊端,探究了植物营养元素的无损检测技术,为科学种植高品质农作物提供了技术保障。
近年来,深度学习在农业检测和图像识别领域应用迅猛[5-7]。深度学习(Deep Learning)是机器学习中具有深层结构的神经网络算法,目前流行的深度学习模型之一是1989年LeCun et al.等提出的卷积神经网络(Convolutional neural networks,CNN)[8-9]。Krizhevsky等利用非线性激活函数ReLu[10]与Dropout[11]方法,提出了经典CNN结构AlexNet[12],接着相继出现了ZFNet[13]、VGGNet[14]、GoogleNet[15]、ResNet[16]等。目前深度学习的主流框架有Caffe、Tensorflow、Keras、Pytorch、MXNet、Theano等。与深度学习主流框架TensorFlow相比,PyTorch使用动态而不是静态计算图,使用GPU和CPU优化深度学习张量库,其框架运用Python编写,使得源码更简洁高效。
在国内,屈莎等[17]以开花期植株氮素积累量、植株氮素含量、叶片氮素累积量等指标作为中间变量,研究采用支持向量机建立冬小麦的GPC预测模型,实现氮素营养指标的估测。李小正等[18]从棉花叶片图像中提取R、G、B值和H、I、S值以及组合相对应的氮含量,选取6种输入向量组合,利用线性网络、BP网络以及径向基网络3种神经网络进行比较,筛选出了最适宜网络模型和最佳输入组合。刘连忠等[19]从原始茶树叶片图像中提取叶片的R、G、B均值,并计算归一化NRI、NGI、NBI及H、S、I均值,选15种颜色特征对含氮量进行回归分析,建立茶树氮营养元素估算模型。但以上模型检测的准确率均较低。
谢忠红等[20]将深度学习和光谱分析相结合,将菠菜划分为新鲜、次新鲜和腐败三个等级,拍摄菠菜叶片的高光谱图像,计算ROI反射率均值,筛选出训练集和测试集,使用SVM分类器,找出识别率均值最高的3个波长,搭建CNN实现了圆叶菠菜新鲜度的无损检测。
本试验针对甘肃红提葡萄,采集不同物候期的葡萄叶片实时图像信息,提取颜色特征,构建训练基于葡萄图像的深度卷积神经网络,实现快速无损检测葡萄叶片钾含量,有利于实时制定葡萄田施肥管理适宜措施。本研究对葡萄生长期营养状况监控和提高葡萄品质具有重要意义。
1 试验数据
1.1 试验地点及材料
本试验在甘肃农业大学的甘肃省葡萄与葡萄酒工程重点实验室的葡萄试验园进行。试验园位于甘肃省兰州市安宁区黄河北岸(36°03′N、103°53′E),兰州地处内陆腹地,干旱少雨,年平均日照数26 070.6 h,年平均气温9.1 ℃,年极端最高温39.1 ℃,年极端最低温度-23.1 ℃,年平均降水量为250~350 mm,并集中分布在6~9月,气候条件为大陆性季风气候明显。试验材料选用适宜在干旱与半干旱地区栽培的红地球葡萄。3月下旬葡萄行两头通风,4月上旬发芽,4月中旬上架,人工施肥,喷灌方式为滴灌,整形方式为“厂”字形,南北行向,株行距为1 m×2 m,单侧蔓。
本试验软件环境为Ununtu 16.04 LTS 64 位系统,采用Pytorch深度学习开源框架,选用python作为编程语言。硬件环境为搭载Intel Xeon(R)Silver 4110 CPU @ 2.10GHz x16处理器,计算机操作系统类型为64位,内存45 GB,并采用英伟达GTX980Ti显卡加速图像处理。
1.2 试验方法与样本采集
为获得不同钾含量的葡萄叶片样本,从萌芽展叶期到果实成熟期的葡萄整个生育过程中,将试验区域划分为A、B两块区域,两区域占地比为5∶1。A区和B区正常施肥管理共6次,其中A区在新梢生长期(6月22日)和果实膨大期(8月30日)各追肥一次,试验期追加施肥用量为NPK配比关系。试验用钾量见表1。

表1 植株生育期施钾肥方案 kg/hm2
深度卷积神经网络模型的训练样本收集试验自4月13日葡萄上架开始,采集葡萄叶片直至10月22日霜降落叶,试验期为192天。以三天为一周期采集葡萄叶片,采集的葡萄叶片来自不同植株不同母枝的不同分枝,每次采摘叶片A、B两区共计20片,其中选择A区和B区各一组植株用于分析不同施肥处理区域植株上叶片钾含量分布,采集叶片放置阴凉处自然晾干。采集红地球葡萄叶片共计1 280片,其中A区叶片960片,B区叶片320片。按照采集日期将阴干的叶片称重、磨粉与装袋,做好相应日期与区域的标记,送至甘肃省农科院进行葡萄叶片全钾含量检测,检测结果制作为模型训练的标签(Labels)。试验采集图片所用仪器是数码照相机,叶片采摘后第一时间带回实验室,将叶片平放到白色的背景纸上,相机与背景纸距离保持60 cm进行垂直拍摄。然后用Photoshop软件将图片统一裁剪为416×416像素大小,JPG格式。试验样本处理如图1所示,图1(a)为试验采集的葡萄叶片样本照片,图1(b)为干燥的葡萄叶片经粉碎处理后的粉末样本。

图1 试验样本处理
1.3 扩充试验数据集
鉴于采集叶片工作量大且周期长,另外采集叶片过多还会影响葡萄正常生长,为提高图像分类的准确性,并使训练模型更加精准,本试验对已有采集样本进行了数据集扩展处理。目前图像扩展方法包括图像旋转(线性变换、矢量相加)、透视变换、仿射变换(平移、旋转、缩放、翻转、错切)和强度变换(对比度、亮度增强、颜色和噪声)等。本文对原始图像进行仿射和强度变换,利用Photoshop对原始图像进行颜色、亮度和对比度的减弱与增强,添加噪声,翻转与缩放的动作处理。这样使每张原始图片产生9张扩展图片,数据集由原来的1 280片扩展至11 520张样本。本试验中CNN模型训练样本分为训练集和测试集,其中训练集随机取7 680张,测试集3 840张用来验证模型的准确性,训练集和测试集中A、B两区采集的样本数量比为30∶1。
1.4 图像特征提取
试验首先运用Photoshop获取叶片图像直方图的R、G、B值,再用OpenCV+python将R、G、B归一化至[0,1]区间,转换为HSI颜色空间。葡萄叶片样本选择的图像特征值包括红光值(R)、绿光值(G)、蓝光值(B)、色调(H)、色饱和度(S)、亮度(I)、红光标准化值(NRI)、绿光标准化值(NGI)和蓝光标准化值(NBI)。其中,NRI(normalized redness intensity)=R/(R+G+B)、NGI(normalized greenness intensity)=G/(R+G+B)、NBI(normalized blueness intensity)=B/(R+G+B)。本试验中B区部分试验样本不同生育期钾含量对应数字图像特征值见表2。

表2 不同生育期叶片钾含量对应数字图像特征值
1.4.1 相关性分析
采用Microsoft Excel 2010进行图像特征值的处理与分析。对B区不同生育期葡萄叶片提取的特征值R、G、B、H、S、I、NRI、NGI、NBI、R/(R+B-G)、B/(R+B-G)、G/(R+B-G)与植株钾素营养参数做相关性回归分析,见表3。结果表明指标R、G、B、NRI、NBI与叶片钾素呈正相关关系,指标NGI、R/(R+B-G)、B/(R+B-G)、G/(R+B-G)与叶片钾素呈负相关关系。

表3 植株叶片数字图像特征值与钾素营养参数的相关系数
1.4.2 不同施肥区域植株叶片钾含量变化分析
随机选择试验A区第二颗葡萄植株上半部的1个结果枝条,并选该枝条靠近母枝端葡萄果穗处的叶片作为分析钾含量的样本,由于1片葡萄干燥后重量偏轻,因而选定样本叶片后,采摘同一株葡萄不同枝条上的5片叶片理想化为1片叶片,记为L1。B区采用和A区相同的采样方法。不同区域不同植株的结果枝叶位的叶片钾含量变化趋势如图2所示。由图2可见,常规施肥不追肥B区和追肥A区结果枝的叶片钾含量变化差异较为明显。由于叶位L1靠近果穗的生长位置,这个区域的叶片光合作用能力较强,光合作用产生的有机物质传输予果实,其钾含量的变化幅度较大。常规施肥B区叶片的钾含量变动幅度较追肥A区钾含量变动幅度变化小,在6月22日膨大期追肥试验后不久,肥料开始分解,植株吸收肥料中的钾,此时植株获得的营养充足,A区叶片钾含量在这一阶段呈上升趋势,6月28日钾含量开始有所下降。7月21日,植株进入果实膨大期,果实逐渐成熟,此时叶片中的钾元素开始向果实转移,叶片钾含量继续下降,8月30日进行着色成熟期第二次追肥试验后,叶片中的钾含量下降缓慢。B区叶片的钾含量变化趋势与A区相似,自开花期后,叶片钾含量逐渐减少且随追肥波动。

图2 A区和B区不同生育期叶片钾含量变化
1.5 叶片钾含量检测网络
Darknet-53网络主要是由一系列1×1与3×3的卷积层组成,每个卷积层(Convolutional layer)之后都会有BN(Batch Normalization)批标准化归一层和Leaky ReLU层,如图3所示。网络中共有53层卷积层。

图3 卷积层(Conv)的网络结构
BN即批标准归一化,是由Google于2015年提出,其在一定程度上解决了深层网络训练过程中的“梯度弥散”现象。
YoLoV3是一种使用深度卷积神经网络训练得到的特征来检测对象的目标检测器,其最大的特点是提出新型的图片特征提取网络Darknet-53作为YoLoV3的全卷积神经网络(Fully Convolutional Networks,FCN)[21]。传统基于CNN的图像分类方法所需的存储空间很大,且计算效率低,像素块的大小限制了感知域的大小,从而导致分类性能受限。FCN将传统CNN的全连接层转化为卷积层,能对样本图像进行像素级分类。YoLoV3网络结构见表4。
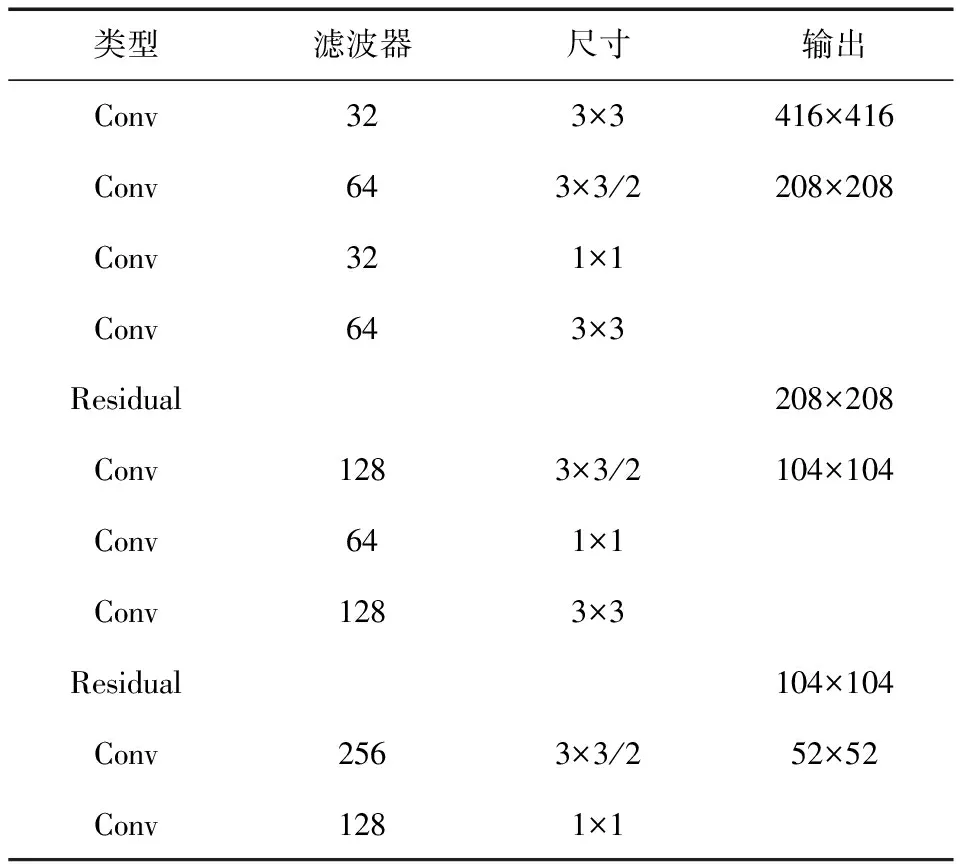
表4 YoLoV3网络结构
1.5.1 测试数据集
本试验采集不同生育期内叶片,在采摘后第一时间带回进行相机采样。以不同生育期不同叶位钾含量的不同为依据自建训练样本集。训练样本集部分实例如图4所示。

图4 不同钾含量训练样本集
1.5.2 YoLoV3-M1网络模型
本试验将网络模型改进为YoLov3-M1,合并BN层到卷积层,提升模型前向推理的速度。BN层能够加速网络收敛,控制训练样本时过拟合的问题。虽然BN层在训练样本时能起到积极的作用,但在网络前向推理时增加了运算,影响了模型的性能。
表示卷积层的计算见式(1)。每个输出像素计算中x表示输入图像中的像素,w表示该层的权重,b表示偏置项。
outj=xi*w0+xi+1*w1+xi+2*w2
+…+xi+k*wk+b
(1)
BN层对该卷积层输出执行的计算见式(2)。
bnj=γ*(outj-mean)sqrt(variance)+β
(2)
为了将BN层合并到卷积层,需要改变式(1)和式(2)来计算卷积层新的权重和偏置项,如式(3)、式(4)所示。
wnew=γ*wsqrt(variance)
(3)
bnew=γ*b-meansqrtvariance+β
(4)
这样就得到新的卷积层,与原始卷积+BN层得到相同的结果,网络性能上没有损失。YoloV3改进网络中只使用卷积层,但要使用调整后的权重wnew和偏置项bnew。
试验的训练样本分为训练集和测试集,对训练样本进行分批次(batch)训练,训练集train batch_size为64,即训练集图片分120次训练完成,每个批次训练64张样本图片。测试集test batch_size为60,即测试集图片分64次测试完成,每个批次测试60张样本图片。一个完整数据集通过神经网络一次并且返回了一次称为一个迭代(epoch),共迭代40 000次,学习率为0.01。输入已做标记的红地球葡萄叶片图像,feature map=3。Detection层划分grid数目,对规模为13、26、52的boxes回归值进行预测。卷积的Strides默认为(1,1),边界填充padding默认为same,当Strides为(2,2)时,padding默认为valid。过滤器(filters)值为32,输入特征图尺寸为416×416×32。共进行5次下采样,提取特征。
2 试验结果与分析
2.1 网络训练结果
YoLoV3-M1网络在训练过程中训练精确度(accuracy)和交叉熵(cross entropy)变化曲线如图5所示。从图5中可以看出在整个YoLoV3-M1模型训练过程中,交叉熵下降较快,迭代次数2 100次时曲线趋于稳定。训练准确度上升也较快,并且很快就趋于平稳。

图5 YoLoV3-M1训练曲线
2.2 模型准确率评估
单个类别的检测准确率(accuracy,Acc)为正确检测的正反例数/类别总数,即:
Acc=Xn
(5)
搭建网络模型平均检测准确率(Average accuracy)为单个类别的检测准确率之和/总类别数,即:
Aac=AccN
(6)
其中样本类别是根据试验中采摘不同叶位不同生育期样本的编号进行分类,本试验样本类别总数分别为A区n为45、N为192,B区n为45、N为64。本试验部分训练样本对应钾含量的检测准确率见表5。

表5 样本钾含量检测结果
本试验以甘肃红提葡萄为研究对象,在葡萄整个生育期的钾含量测定试验基础上构建基于数字图像特征的卷积神经网络模型,葡萄叶片钾含量无损检测方法的试验平均准确率为94.49。本研究选用图像检测更为精确的YoloV3卷积批归一化层改进模型,以深度学习框架(Pytorch)实现动态检测的模型架构,搭建实现对葡萄叶图像优化调节模型参数,在网络迭代2 000次后就能达到90%以上的检测准确率。但试验中也发现极个别样本的预测结果与化学检测钾含量值差异较大,这与获取葡萄叶片数字图像颜色特征值时的试验处理误差有关,其主要来自采集叶片样本时的小部分缺损或干枯或病害因素,使颜色信息受干扰而影响结果的准确性。本试验采用图像处理技术与深度学习方法实现葡萄叶片钾含量的无损检测,为现代精准园艺农业的信息化发展提供了技术支持。
