差分进化樽海鞘群特征选择算法
2021-03-09李占山杨鑫凯
李占山, 杨鑫凯, 胡 彪, 张 博
(吉林大学 a. 计算机科学与技术学院; b. 符号计算与知识工程教育部重点实验室; c. 软件学院, 长春 130012)
0 引 言
特征选择是从原始特征中选择一些最有效特征以降低数据维度的过程[1], 是机器学习、 数据挖掘、 模式识别领域中关键的预处理步骤。常见的特征选择方法依据选择策略的不同大致可分为3类: 过滤式(filter)、 嵌入式(embedding)和包裹式(wrapper)[2]。过滤式方法不依赖于任何学习算法, 仅依靠对数据的某些特征进行评估, 以评估特征的重要性; 嵌入式方法将特征选择过程与学习器训练过程融为一体, 在学习器训练过程中自动地进行特征选择[3]; 包裹式方法依赖于预定义的学习算法评估所选特征的量。特征选择的困难在于搜索空间会随着特征个数的增加呈指数级增长[4], 因此, 设计并改进特征选择算法成为了特征选择问题求解的关键[5]。
演化计算技术由于具有良好的全局搜索能力, 近年来在特征选择领域获得了越来越多的关注[6]。一些基于演化计算的特征选择包括较经典的粒子群特征选择算法PSO(Particle Swarm Optimization)[7]和较新的二元灰狼特征选择算法bGWO(binary Grey Wolf Optimization)[8]、鲸鱼特征选择算法WOA(Whale Optimization Algorithm)[9]、 正余弦特征选择算法SCA(Sine Cosine Algorithm)[10]、 二元蝴蝶特征选择算法bBOA(binary Butterfly Optimization Approaches)[11]等。
在最新的工作中, Seyedali等[12]提出了一种樽海鞘群优化(SSA: Salp Swarm Algorithm)算法。相比于其他算法, SSA算法在解决特征选择问题上有着较好的表现力[13], 但由于粒子通过迁移方向单调的平均算子移动, 导致算法搜索能力受限而易陷入局部最优; 同时和其他演化算法一样存在收敛速度较慢的问题, 因此SSA算法仍有较大的提升空间。
笔者提出了一种改进樽海鞘群优化算法的特征选择方法, 将原本种群中跟随者采取的平均算子更换为搜索能力更强的差分进化策略, 使粒子向前驱粒子迁移的同时向较优的粒子移动, 并引入了根据适应度大小的进化种群动态机制用以加强收敛能力, 形成了差分进化樽海鞘群特征选择算法(DESSA: Differential Evolution Salp Swarm Feature Selection Algorithm)。实验结果表明, 笔者提出的方法与对比算法相比具有一定优势和竞争力。
1 相关工作
1.1 SSA算法
与其他演化计算一样, 在SSA算法中各粒子的位置由二维矩阵各个向量表示, 并假定在搜索空间中存在最优位置, 作为整个群体的目标。其中领导者通过
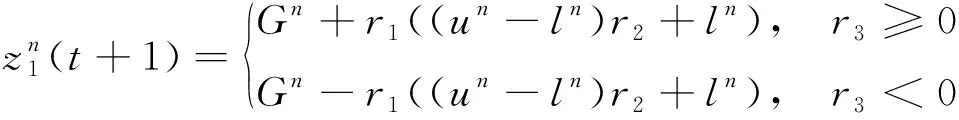
(1)
r1=2e-(4t/T)2
(2)
其中T为最大迭代次数,t为当前迭代次数。
跟随者采用
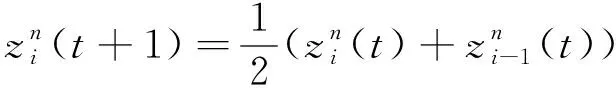
(3)
该算法流程图如图1所示。
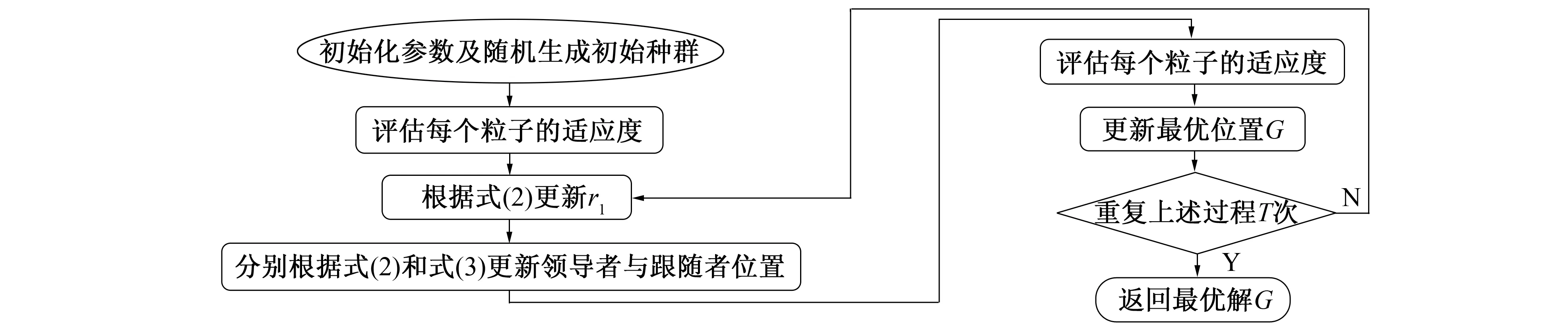
图1 SSA算法流程Fig.1 Flowchart of SSA algorithm
1.2 二进制SSA特征选择算法
在特征选择问题中, 所有粒子对应的问题解都限于离散{0,1}二值中, 因此在将SSA算法应用于解决特征选择问题需通过
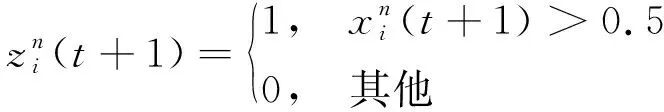
(4)
2 差分进化樽海鞘群特征选择算法
针对以上算法的不足提出了相应的改进方案, 给出了差分进化樽海鞘群特征选择算法。实验表明, DESSA相较于SSA具有更优的性能。
2.1 差分进化算子
差分进化(DE: Differential Evolution)是由Storn等[14]于1997年提出的基于人口的元启发式优化算法, 因其简单性、 有效性和鲁棒性而受到广泛关注。在DESSA中, 差分算子主要由突变、 交叉和选择3个基本部分构成。在突变步骤中, 当前t时刻粒子对应的目标向量zi(t)会发生突变并生成突变载体vi(t)。DESSA通过
vi(t)=zi(t)+F(G-zi-1(t))
(5)
对跟随者粒子进行突变。其中zi-1(t)为zi(t)的前驱粒子的位置向量,G为当前种群最优粒子的位置向量,F为在[0,f]范围内通过
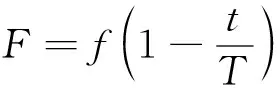
(6)
递减的变化系数。其中f为变化参数的人为初值。通过式(5)得到的突变载体vi(t)需通过式(4)转化为离散形式向量。
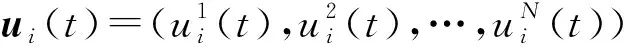
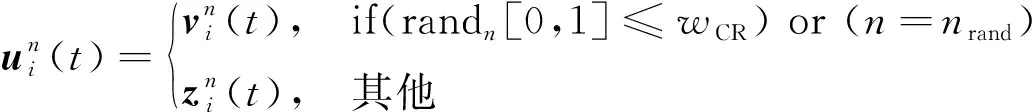
(7)
其中wCR为交叉权重。
在选择过程中, 将交叉载体ui(t)与目标向量zi(t)进行评估比较, 具有较高适应度的粒子将胜出并作为更新位置zi(t+1), 表示如下
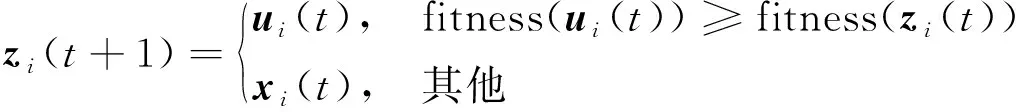
(8)
其中fitness(z)为用于评价目标函数。
在DESSA中, 各跟随者粒子依次通过式(5),式(7),式(8)进行差分算子形式迁移, 直至t=T时结束。
2.2 进化种群动态机制
进化种群动态机制(EPD: Evolutionary Popu-lation Dynamics)是一种通过将最佳解决方案重新定位在最佳解决方案上以消除最差解决方案的过程[15]。它可以剔除找到最优粒子可能性较小的一些粒子并根据一定机制将其替换为环绕当前种群最优粒子的粒子, 从而快速将计算资源集中到搜索找到最优粒子可能性较大的区域。在算法DESSA中, 它被应用到每次迭代的最后。进化种群动态机制具体分为淘汰和产生新粒子两个步骤。在淘汰步骤中, 种群会按适应度将较差的后一半粒子淘汰。在产生新粒子步骤中, 种群会先根据排名选出当前适应度值排名前3的粒子zfirst(t),zsecond(t),zthird(t), 以及一个种群中异于该3个粒子的其他粒子, 之后对每个新生粒子在各维度的位置都以相同概率随机从上述4个粒子同维度位置中选出一位作为其值, 进而生成新生粒子直至恢复种群固有数量。在EPD机制中参照多个优质粒子位置生成的新生粒子在种群中更具有搜索潜力, 同时淘汰种群中较劣粒子提高了种群质量, 缩小了搜索空间, 进而加强种群的收敛能力。
2.3 评价指标
在DESSA中, 为了在特征选择过程中提高分类准确率的同时减少选择特征数量, 笔者采用的适应度函数[16]
fitness(z)=αRCA+(1-β)RDR
(9)
确保DESSA具有一定的降维能力。其中RCA与RDR为分类准确率和维度缩减率,α和β为调节参数, 分别代表了分类准确率RCA和维度缩减率RDR的重要性。
2.4 DESSA算法流程
DESSA算法流程如图2所示。
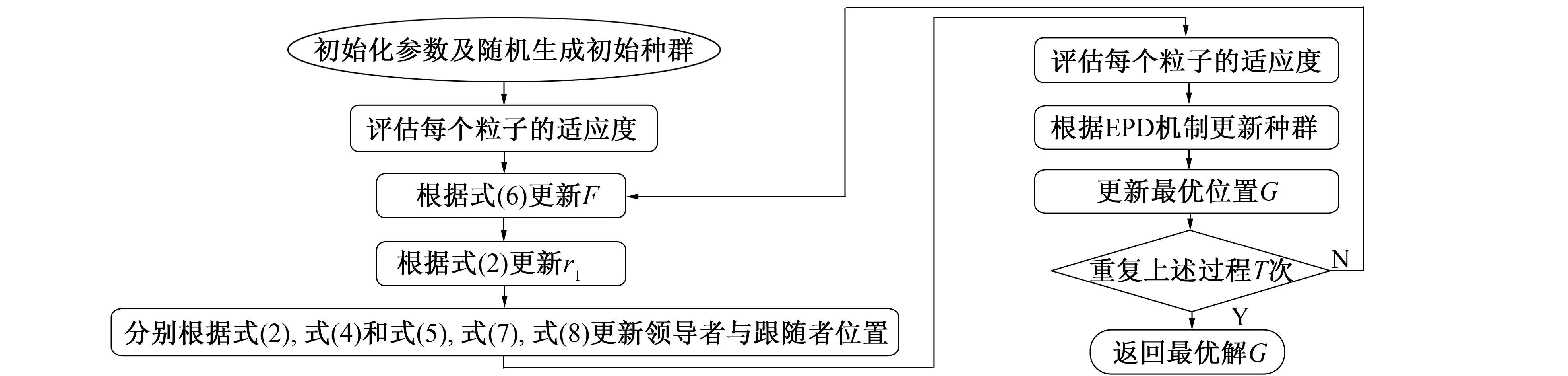
图2 DESSA算法流程Fig.2 Flowchart of DESSA algorithm
3 实验结果与分析
3.1 实验描述
为了验证所提出算法的优化效果, 笔者使用了8个选自UCI机器学习库[17]的数据集进行对比实验, 表1描述了各数据集的分类数、 特征数和样本数, 表2展示了数据集Glass的部分数据; 实验中使用了K折交叉验证方式, 即将数据集切分为K份, 每次取K-1份数据用于训练, 剩余数据用于测试, 进行K次的训练和测试; 实验结果在每个数据集和算法中独立运行20次, 最终统计平均值; 在分类器的选择上,K近邻(KNN:K-Nearest Neighbor)是一种简单且非常通用的分类器, 已广泛用于包裹式特征选择[18], 实验选择该分类器作为基分类器, 并将参数K设置为最佳参数5[19]。

表1 数据集详细信息
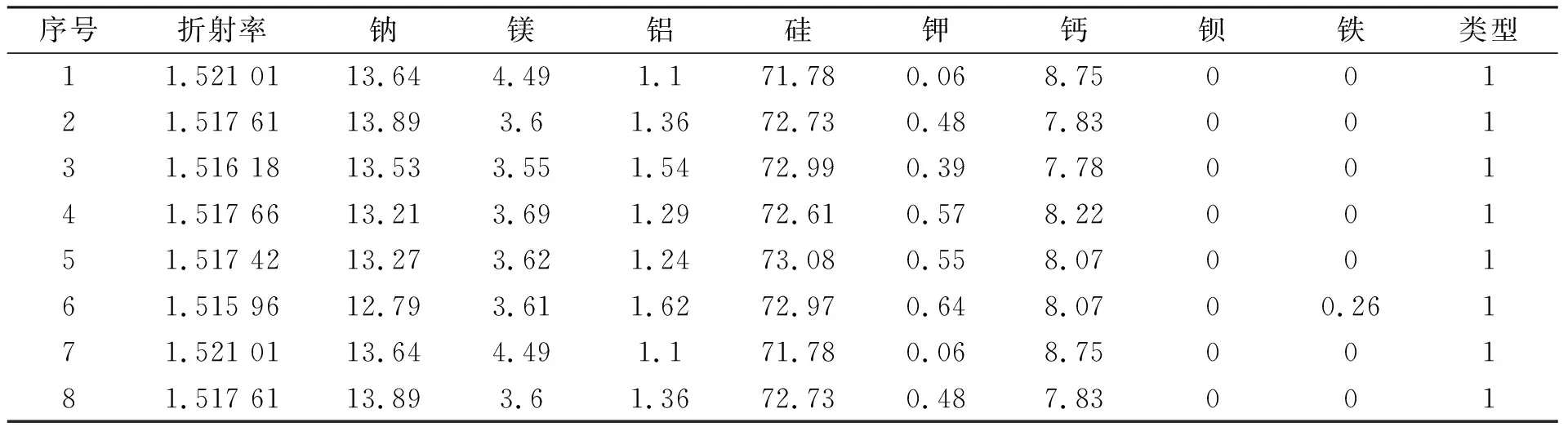
表2 数据集Glass部分数据
为对比算法的性能, 笔者在实验中比较DESSA与SSA的同时加入了一些具有代表性的特征选择算法: PSO[7]、 bGWO[8]、 WOA[9]、 SCA[10]、 bBOA[11]; 为保证对比实验的公平性, DESSA除了变化参数初值f与交叉权重RCR, 参数设置与SSA完全相同, 实验中所有算法的具体参数在表3中给出; 在笔者的实验中, 用python 3.6实现算法, 同时使用了公开的工具包scikit-feature和scikit-learn。所有实验均在一台配置为Intel i7-7700HQ、 8 GByte内存、 500 GByte硬盘的电脑上完成。
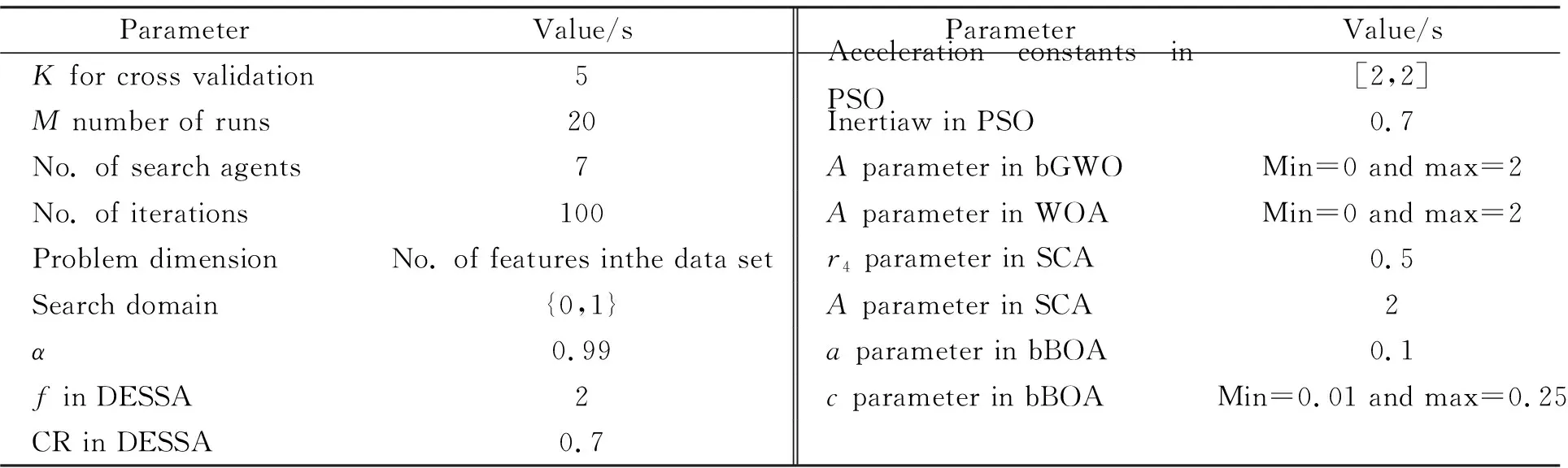
表3 算法参数详细信息
3.2 评价指标
下面使用分类准确率CA(Classification Accuracy,RCA)和维度缩减率 DR(Dimensionality Reduction,RDR)作为算法最基本的评价指标[20], 其具体定义如下
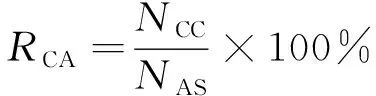
(10)
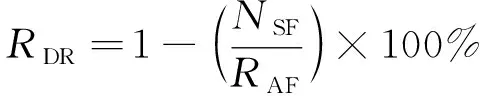
(11)
其中NCC为正确分类的实例数,NAS为数据集实例总数,NSF为被选择的特征数,NAF为数据集的特征总数。为测试实验中算法的稳定程度, 笔者使用标准差评价算法鲁棒性的指标, 具体定义[11]如下
(12)
其中Vfitness(G*i)为第i次运行得到的最佳适应度值,VMean为运行得到多个最优解的平均适应度, 定义如下
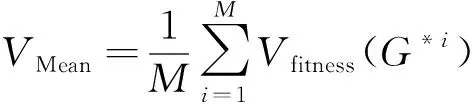
(13)
3.3 实验结果对比分析
对比分类准确率, 从表3可见, DESSA相较于SSA有较大的提升, 且在除Spambase数据集外的所有数据集上的平均分类准确率均达到了最高。因此在分类准确率上有了明显的提升。
对比维度缩减率, 从表4可见, DESSA在所有数据集上相较于SSA都有一定提升, 且在Heart、 Vehicle、 Wine和Yeast数据集上达到了最高, 在其他数据集上也有较优表现。
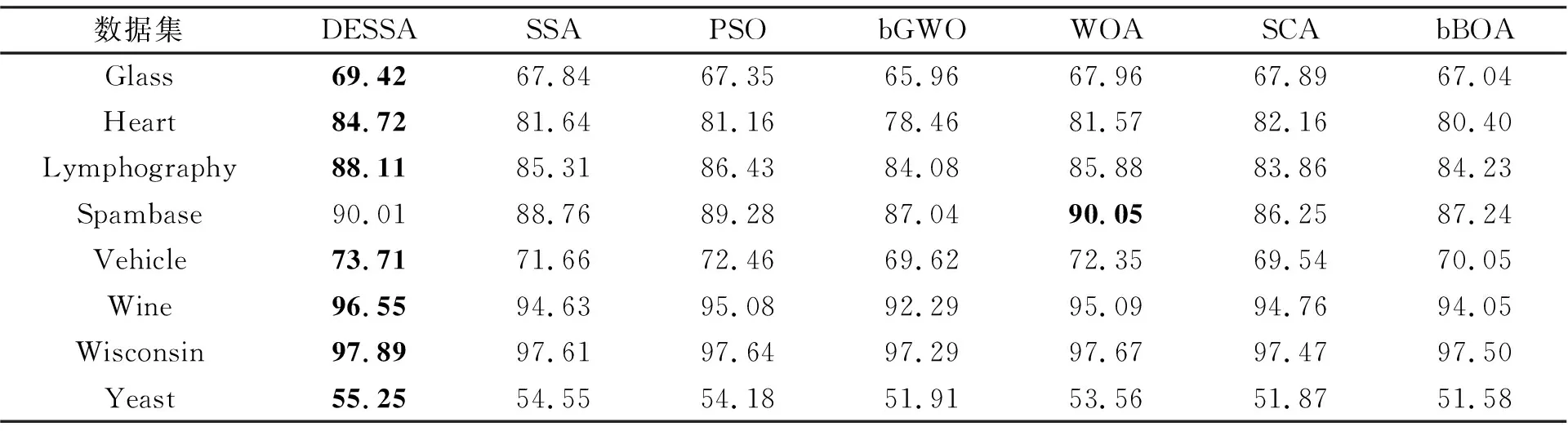
表4 DESSA及其对比算法的分类准确率CA实验对比Tab.4 The results of the proposed DESSA and its comparison algorithms on classification accuracy (%)
对比标准差, 从表5中可见, DESSA在所有数据集上相较于SSA都表现更加稳定, 且在Glass、 Lymphography、 Spambase、 Wisconsin和Yeast数据集上达到了最小, 在其他数据集上也有较优表现。由此可见DESSA具有较好的鲁棒性。
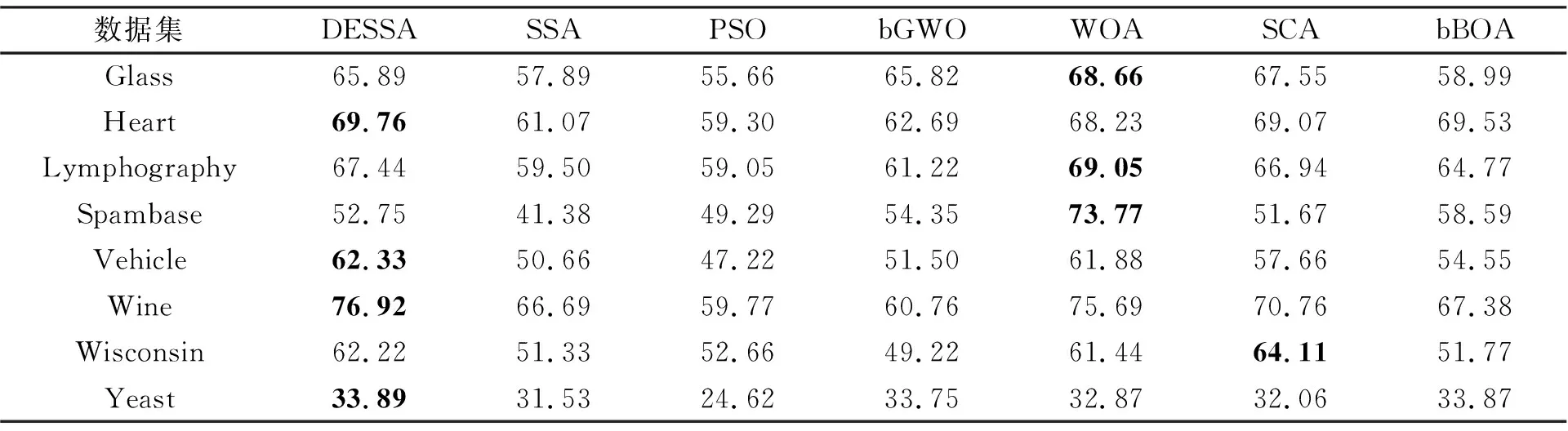
表5 DESSA及其对比算法的维度缩减率DR实验对比Tab.5 The results of the proposed DESSA and its comparison algorithms on dimension reduction (%)
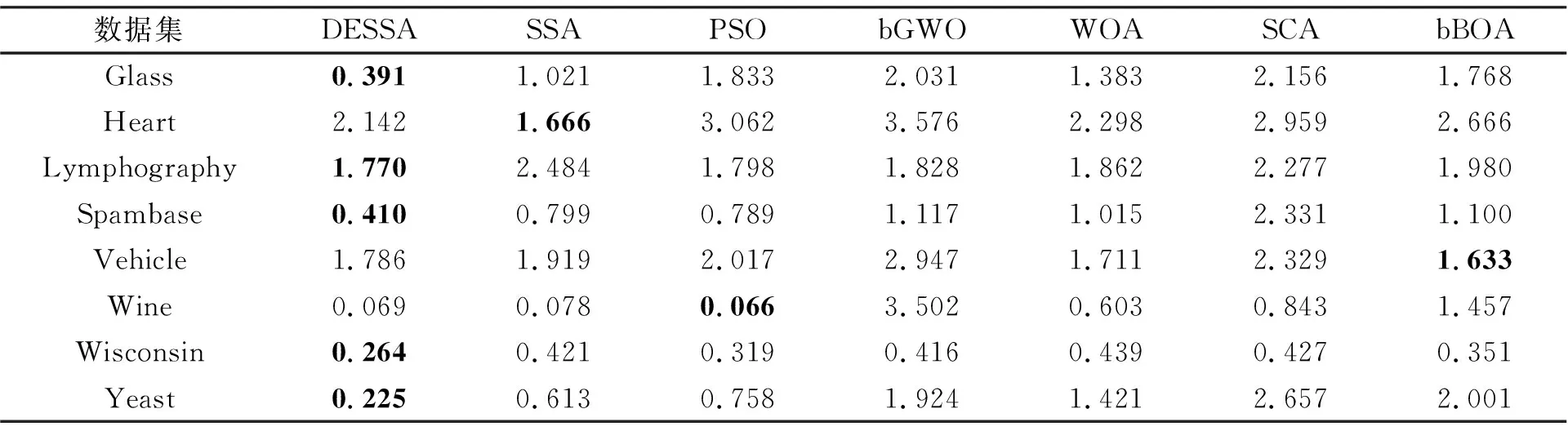
表6 DESSA及其对比算法的标准差实验对比
4 结 语
笔者针对SSA在解决特征选择问题时的不足之处提出了差分进化樽海鞘群算法DESSA。DESSA结合差分算子增强了算法的搜索能力, 同时引入EPD机制加快算法的收敛速度。最后, 通过8个数据集与具有代表性的6个特征选择算法, 与DESSA一起进行了对比实验, 验证了DESSA优异的性能。如何进一步增强算法的降维能力, 以及针对解决在高维数据集上的特征选择问题的优化, 将是下一步重点研究的内容。
