基于知识的零样本视觉识别综述*
2021-03-06冯耀功桑基韬杨朋波
冯耀功 ,于 剑 ,桑基韬 ,杨朋波
1(北京交通大学 计算机与信息技术学院,北京 100044)
2(北京交通大学 人工智能研究院,北京 100044)
大数据时代的到来,使得深度学习的热度持续高涨.但是同时,深度学习的模型也暴露出了很大的问题,其在训练过程中,特别依赖大规模、强标记的数据,往往意味着要耗费极大的人力和物力.针对此问题,有研究者提出了新的学习方式,比如依靠弱标记数据训练模型的弱监督学习[1];除此之外,如何通过之前已获得的知识并用于新的学习任务或者过程,大大减轻数据标注的压力,也成为人们解决这一问题的新出发点.受这一思想的驱动,元学习(meta learning)[2]、零样本学习(zero-shot learning,简称ZSL)[3-5]和小样本学习(few-shot learning,简称FSL)[6]等概念变得火热,并且都有所进展.
人们往往具备知识迁移的能力;在大多数情况下,人们可以结合已有知识,并通过针对未知事物较为具体的文字描述,借助标签-视觉对应关系来认知这一新事物.例如,通过已有知识“斑马拥有大熊猫的黑白色彩、老虎的花纹、马的形态”这样的描述,该人即使从未见过斑马,也能够大致推断出斑马的样子;这即是零样本学习最直观的解释.零样本学习最早见于文献[7],从数学角度来定义,其具体是指:给定一些有标记的训练样本,包含了这些有标记样本的类别,称为可见类(seen classes),也称为源域(source domain),其中,可见类数据记为Xtr,标签记为Ytr;同时还有一些无标记的样本,包含这些无标记样本的类,称为不可见类(unseen classes),也称为目标域(target domain),数据记为Xte,标签记为Yte.需要指出的是,在零样本学习中,Ytr∩Yte=∅,模型在源域中训练,在目标域中测试.但是,原始的零样本学习往往又有两种基础扩展:(1) 依据在训练过程中是否使用了无标记的Xte,零样本学习又分为归纳式零样本学习(inductive zero-shot learning)(使用了Xte)和直推式零样本学习(transductive zero-shot learning)(未使用Xte);(2) 依据在测试过程中测试类别是否包含可见类,零样本学习又分为传统零样本学习(zero-shot learning)(不包含可见类)和泛化零样本学习(general zero-shot learning)(包含可见类).如果在训练过程中,有少量的不可见类有标记数据参与到训练过程中,那么零样本学习就转化为小样本学习;零样本学习和小样本学习两者又合称少样本学习(low-shot learning)[8].因此,零样本学习是小样本学习的一种更加极端的情况.
通过上面的定义和所举例子表明,零样本学习本质上是用迁移学习(transfer learning)[9]的思想来解决问题的.即从一个域/任务/分布中学出一个有效的模型,然后迁移到新的域/任务/分布.这与迁移学习中域适应的思想内核是类似的.所以研究者也经常将域适应(domain adaptation)任务与零样本学习任务作比较[3,10,11](文献[12]提到了域不变性).而这两者最大的区别就在于:在零样本问题中,可见类与不可见类的交集为空集.因此,零样本学习可以被视作是一个特殊的迁移学习任务.并由于这种迁移性和随之带来的空间变换,在本领域长久以来存在着域偏移(domain shift)[13,14]问题和枢纽点(hubness)[15]问题:前者是因为数据特征空间的不同所带来的特征表示内容发生偏移的问题;后者是由于数据特征维度的变化所带来的“某些不相关点会成为大多数点的最近邻点”,进而会影响对不可见类数据进行认知的问题.详细内容我们将会结合模型细节在第4 节展开阐述.
文献[3]中指出:“零样本认知的关键就在于如何挖掘出不可见类与可见类之间语义上相关联的知识”.所以从知识迁移的角度出发,零样本学习的成立也存在一个先验条件,那就是可见类和不可见类数据之间须存在某种形式的知识关联.直观理解,这种关联性越强,模型效果越好.综上,零样本问题中知识的获取和迁移就是其关键核心.基于这样的认识,本文首先对“知识”的获取进行了全面的发掘,将其概念范畴定义了3 个层次:1.初级知识,即从数据集中直接可以获取的知识,比如属性、类别标签、视觉特征等;2.抽象知识,即多个数据包含的知识,比如数据概率、流形分布等;3.外部知识,比如人类已经建立的知识库等.具体内容我们将在第1 节详细论述.依据划分好的知识层次,本文进一步梳理了现有的零样本学习工作,即知识的迁移方式,具体论述将放在第2 节.
本文工作相较于文献[5]中归纳式和直推式的模型分类方法,其基于知识迁移的分类方法能够帮助人们更好地理解当前“数据+知识驱动”的思想潮流,也更加接近零样本学习任务的本质问题,即“在目标域和源域之间,通过何种形式的知识,才能更好地搭建起两者之间的桥梁”.在Rohrbach 等人[16]的工作中,将零样本学习领域基于知识的迁移方式分为3 个方向:(1) 利用类别来构建的“从一般到特殊”的层次化的体系结构(例如WordNet知识库);(2) 基于提取类别之间通用的可视属性,将不同类的特征视作是属性激活的不同模式;(3) 基于与相关类的直接相似性,有效使用大多数相似类的分类器.但是由于技术的快速发展,这样的分类方式是远不够全面的;并且从本质上讲,这也是因为对零样本学习中“知识”本身的定义不甚清晰造成的.因此,本文基于第1 节中所定义的知识,在第2 节中对现有的零样本工作(主要是关于图像分类任务)进行梳理.相比于文献[3],本文中对知识的定义也更加全面.本文中除“知识”的表述之外,“语义”也是本文的常用表述.而中文的“语义”一词相较于英文“semantic”,往往涵盖内容更加广泛,并且相关文献并没有对“语义”做出准确定义.因此在本综述中,我们结合国内外文献资料,对其进行了一定程度的狭义化:将“语义”狭义化为仅指向“文本的特征表示(例如标签或者属性,这也对应视觉信息经过高度抽象化之后的特征表示)”,它们的共性在于维度较低,且更为抽象.
除了本文主要涉及的图像分类任务之外,零样本学习的策略也运用在很多其他任务领域,诸如识别任务[17-36]、语义分割[37]、图像检索(image retrieval)[38-40]、视频理解(video understanding)[41-44]、检测任务[45-50]等其他视觉任务领域;还有自然语言处理(natural language processing,简称NLP)[51,52]等文本领域的任务.但是NLP 领域内的工作相对较少,并且我们可以简单理解为:在现有视觉模型的框架下,对视觉数据的处理转向对文本数据的处理.总体来讲,零样本学习正在渗透到实际应用的方方面面.
本文第1 节详细阐述在零样本视觉识别任务中,知识的层次以及各自的表示形式.第2 节介绍基于不同层次知识构建的零样本学习模型.第3 节则重点阐述目前本领域中一直以来存在的两个主要问题:domain shift 问题和hubness 问题,并基于问题对现有工作进行总结归纳.第4 节介绍本领域的通用数据集、评估标准(分类任务)和实验.最后对未来研究趋势进行一定的展望.
1 零样本视觉识别任务中的知识及表示
零样本学习的关键在于“知识”从可见类到不可见类的有效迁移.传统来讲,人们习惯于从知识的存在形式上对知识进行理解和分类.从这个角度来看,知识总体上可以分为4 种:文本形式、视觉形式、数据分布形式和符号形式.这样划分有助于人们更好地理解不同存在形式的知识本身具备的优缺点,见表1.

Table 1 Existence form of different knowledge and its advantages and disadvantages表1 知识的存在形式以及优缺点
其中,文本形式的知识,无论是人类对特定数据集进行的定义还是通过外部获取提取,虽然其拥有明确的描述性,但是由于其数量和维度的限制,以及其中可能存在的噪声,这类知识并没有足够的判别力来对不同类别进行区分.而视觉信息是数据不同类别的真实反映,因此其更具有判别性,但它们中可能包含了更多无法描述的信息(non-robust features)[53],因此无法像文本数据(例如属性)一样有较明确的描述性.数据分布形式的知识,反映了数据集中文本特征或视觉特征的内在规律,更为抽象和高级.从本质上来讲,绝大多数的零样本学习模型所寻求的是不同模态数据之间的对应关系,并寻求这种对应关系的泛化.因此,基于这类更高级特征表示来寻求对应关系的建立,能够使得模型更好地泛化到目标域中.但为了方便地利用这类知识,有的研究者做出了过于严格的假设,例如,“源域和目标域的数据流形结构是一致的”等.而符号形式的知识,知识图谱是其代表,其中包含了丰富的先验信息,例如不同概念层次以及概念之间的显式关系等,但是其难点在于知识采用何种技术手段才能尽可能多地保留其先验内容,即如何选取知识的合理表示形式,还有与深度网络(连接主义)的结合等问题.
传统的知识划分形式无助于人们理解零样本学习领域“知识迁移”的发展历程,因此,本文结合近几年工作,将零样本问题所用数据中蕴含的“知识”定义范畴进行了重新梳理.并根据知识的来源方式,将其划分为3 个层次:初级知识、抽象知识以及外部知识.采用这样的分类方式,有助于人们更好地理解研究者们如何通过知识的挖掘来缓解甚至克服领域中存在的问题.接下来我们将进行详细的介绍.
1.1 初级知识
初级知识,是指从原有数据集中直接可获取的数据知识,通常包含了类属性知识、类标签知识,以及每条数据的视觉特征.
· 属性(attribute)
属性(attribute)是零样本学习中最广泛使用的知识之一,获得了广泛的关注.在文献[41]中,对属性的定义是指描述某个体或某类所拥有的一系列特性.属性进一步可以分为视觉属性、局部属性.以家猪为对象进行举例,其视觉属性可以是“肉粉色”“皮毛”和“条纹”;其局部属性可以是“4 条腿”“蹄子”和“尾巴”.因此,家猪相对应的视觉属性以及局部属性的表示分别为[1,1,0],[1,1,1].从上面的例子中可以看出:属性向量中的数字均代表了该个体或者类的某一项特性的有无,且数值均为二值(0/1).这类属性知识得到研究者最广泛的使用,被称为人工定义的属性(user-defined attributes),0/1 的数值分布也被称为二值属性向量.
但是,二值属性有一个明显的缺陷,0/1 值并不能表示类间对同一特性的不同强度.例如,家猪和马都有4 条腿,但是这两个物种二值属性的对应表示均为1,但视觉上却差异巨大.因此,Parikh 等人[54]提出了相对属性(relative attributes)的概念,即向量的值不仅仅判断特性的有无,并且对应分值的大小还表示该特性的强弱,从而区分不同类别在同一特性上的差异.在一些数据集[17,35]中,分别使用了二值属性和相对属性对同一个目标对象进行描述.
除了二值属性和相对属性之外,还有属性的自动学习[55],即从数据中自动挖掘出相应的属性知识,这排除了人工定义的属性的局限性和不确定性,也被称为数据驱动的属性(data-driven attributes)[3].
最后还有视频属性(video attributes)[23,26,29,48-50],即提取视频中的概念(concept)作为视频属性.
总体来看,属性作为底层视觉像素特征和高层语义特征(即代表了用户对图像的理解,例如类别标签)之间的中间描述层,是对底层特征进行一定抽象的结果,保留了较多信息的同时,也不至于像高层语义特征一样丢失很多描述性信息.因此,属性知识表现出较好的描述性,并进一步具备了较好的共享性和可操作性.例如在AWA2数据集中,实现了85 个属性对50 个动物类别的描述.但是属性知识需要专家级别的标注,相比简单的类别标注更加复杂和昂贵,这在一定程度上违背了零样本学习的初衷.虽然有属性的自动学习,但是也没有得到很广泛的应用.近两年的趋势表明:更多研究者倾向于其他更加本质的数据知识,例如数据分布等,而非属性知识本身表示手段的革新.
· 类标签(label)
类标签(label)也是零样本学习中最广泛使用的知识之一.以Mikolov 等人[56]提出词向量的概念为起始点,并伴随着词嵌入技术的普遍使用,这类知识日益受到了研究者们的关注.常用词嵌入模型有Word2Vec[57]和Glove[58].获取类标签的词嵌入表示,大致需要进行如下的步骤:首先,使用词嵌入模型在语料中进行训练,例如Wikipedia Text;然后得到词向量矩阵;最后,通过查询找到类标签对应的词嵌入表示.
通过以上方式得到的类标签知识的优势是巨大的:首先,词嵌入的表示是低维稠密的;其次,词嵌入表示有着很好的空间分布特性,即能够在空间上很好地显示出不同词(每个词代表一个类别)之间的相似性程度.例如,在词嵌入空间中,“狗”和“猫”之间的距离要远小于“狗”和“高楼”之间的距离;还能进一步地作类比和推理,比如“Vec(“国王”)-Vec(“男人”)+Vec(“女人”)≈Vec(“王后)”.通过衡量类间的相似性程度,并将其作为一种零样本问题的先验知识,也有助于零样本问题的解决.但区别于前面的属性知识,词向量表示的每一个维度并没有明确含义,这意味着词嵌入之后的类标签表示没有类似属性知识一样明确的描述性,也就失去了知识的共享性这一性质.但在很多研究工作中的模型已经实现了对属性和类标签知识的兼容,即两者的输入在模型中可以相互替换.需要指出的是,由于词嵌入表示是通过词嵌入模型在语料上的训练来获取,而非通过数据集中的多个数据,因此将类标签归入到“初级知识”的范畴中.
· 语义空间中的类原型表示
在属性知识和标签知识中,涉及最多的就是关于“类原型(class prototype)”的表述,是指某个类的代表,而这一代表在语义空间中通常是唯一的,可视作前面属性知识和类标签知识概念上的延伸.在语义空间中,Fu 等人[59]将这一空间中的类原型表示对应为属性向量或者基于类名的词表示,因为在语义空间中,属性表示或者是类名称具备唯一性.因此,很多研究者直接将类标签的词嵌入[11,14,20,28,60-62]或者类属性[13,27,53,59,62-67]作为对应类的类原型,甚至是类别所对应的文本描述[68].其实针对这三者而言,根据数据获取的情况或者是任务的要求,在绝大多数情况下可以互换[69].除此之外,也有研究者基于这些知识学出了每个类的类原型表示[29,30,41,42,70,71].
· 图像特征(image feature)
图像特征(image feature)也是零样本学习中最广泛使用的知识之一.广义来讲,图像特征表示既可以是指人工设计的特征,例如SIFT,HOG 等,也可以是图像底层的像素级别的特征,还可以是通过各种深度网络提取的高层抽象的图像特征.近几年,随着端到端深度神经网络框架(例如AlexNet[72],VGG[73]等)的成熟,当前零样本学习范畴内的图像特征通常是指最后一种.
1.2 抽象知识
初级知识在构建零样本模型时存在较大问题,例如,基于语义空间的类原型表示,由于其唯一性,并不能很好地代表类内方差较大的数据类别;基于初级知识构建的映射,也很容易带来Hubness 的问题等.在这种情况下,进一步挖掘数据集合所包含的更加高级的知识来减轻或者消除前面存在的问题,就显得很有必要.在这种情况下,研究者通过多条数据甚至整个数据集的总结归纳,挖掘出数据集中的隐藏信息.相较于初级知识,这种类型的知识更能反映出数据的本质特征,我们称为抽象知识.这一范畴通常包含基于图像特征的类原型表示、数据的流形分布以及数据的概率分布.
· 基于图像特征的类原型表示
基于图像特征的类原型表示是前面图像特征的概念延伸,但是其不同于之前基于语义空间的类原型表示,它的表示可以是不唯一的.研究者发现:经过深层网络抽取的图像高级特征,经过t-SNE 算法[74]的降维并进行可视化,其每个类的数据在空间中呈现簇状分布.因此,有研究者直接将最终提取到的某类所有图像特征[75-78]或者部分图像特征[79]的均值作为该类的视觉类原型表示(前者可以理解为类的质心).但是也有研究者指出[80],基于质心的类原型表示并不能让类间保持很好的判别性.因此,也有模型是通过学习得出的类原型表示[53,80-90].例如,Liu 等人[90]首先基于语义信息来学出类原型表示,然后利用基于均值的图像类原型表示来进行紧致化的结果修正.但是就总体而言,单个类原型不能很好地表示类内方差较大的类别,因此也有工作[83]将基于图像特征的单个类原型表示扩展为多个,其大致过程是将该类包含的所有图像特征,先做聚类,然后将聚类结果的每个簇的均值作为该类的类原型之一,以更好地表示类内方差较大的类别.可以看出,基于图像特征的类原型表示能力远大于基于语义空间的类原型表示.
· 数据的流形分布(manifold distribution)
数据的流形分布(manifold distribution)是数据集中所有(部分)类的整体分布结构,由于视觉特征和语义特征之间存在模态鸿沟,因此,基于不同表示空间获取的数据流形结构可能也是不一致的.为了更方便进行知识的迁移,研究者常常需要一定的假设来对这种情况进行约束,最常见的是假设两个空间中的数据流形分布一致;通过对齐不同空间中的数据结构,或者保持映射过程中数据的结构性,能够有效缓解Hubness 问题并获得泛化能力更好的模型.有的研究者通过两两类原型之间的欧式距离(Euclidean distance)或者余弦距离(cosine distance)来构建数据的结构图[28,29,53,59,76,88,91-95],这虽然能够直接反映出两个类别之间的相似程度,但是这样简单直接的计算只是基于二维空间分布的前提条件下,一定程度上忽略了数据的分布可能存在更为丰富的流形结构(欧式空间只是流形空间的一个特殊情况).例如,某些对象类会组成超类,并位于相同的子流形上,如果此时再用欧式距离或者余弦距离进行度量,就有可能出现如图1[14]所示的情况(如果使用欧式距离进行度量,那么x将被划分到z1类;如果考虑数据的流形分布结构,那么x将被分类到z2类),进一步影响测试集数据的正确分类.因此,有的研究者[13,14,60,87,96]基于更加复杂的数据流形分布,进一步考虑了类原型之间的流形距离(semantic manifold distance).
· 数据的概率分布(probability distribution)
相对于数据的流形分布是挖掘数据集中多个数据的分布规律,数据的概率分布指的是单个数据的生成规律,即通过现有的数据特征,学出这一类特征存在的规律.有的研究者通过建立数据概率分布之间的映射,来使得模型更加鲁棒[30,97-100].伴随着近两年生成式模型的广泛使用,更多的研究者通过生成式的模型来挖掘数据的概率分布知识,并将问题转变为标准的监督学习问题.在基于生成式方法的零样本模型中,通常基于变分自编码器(variational auto-encoder,简称 VAE)[39,86,101-104]、生成对抗网络(generative adversarial network,简称GAN)[32,40,44,62,83,99,105-110],或是将两者结合[111-113].其中,VAE[114]优化的是似然下界而非似然本身,而GAN[115-117]则通过神经网络强大的拟合能力来直接缩小伪数据与真实数据之间的分布差异(Jensen-Shannon divergence,简称JS divergence).由于GAN 中对抗训练的存在,使得其训练稳定性相比VAE 较差.也正是由于对抗训练的思想,GAN 最终生成的伪样本效果整体上要优于VAE 的表现.但是这类工作均包含了一个隐藏的前提假设:数据服从多元高斯分布.
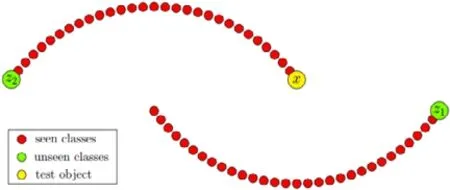
Fig.1 Manifold distance of data in complex manifold distribution[14]图1 数据在复杂流形分布中的流形距离[14]
1.3 外部知识
外部知识,顾名思义,是指独立于目标数据集之外的、来自于相关领域的知识,可以被认为是来自于人类的先验知识.传统的深度神经网络得益于大规模标注数据,能够习得有效的层次化特征表示,从而在相关任务领域,尤其是图像领域取得优异的效果.但是也受困于大数据,伴随着数据标注成本日益高昂,单纯依赖大数据的模型性能也已经触摸到天花板,体现出其局限性,比如模型训练过分依赖大数据、模型无法有效与人类先验知识相结合、模型学习结果往往与人的认知规律相冲突(缺乏解释性)等.因此,将外部知识加入到目前零样本问题的解决过程中,可以进一步提升模型在目标任务上的性能(例如模型鲁棒性或者任务相关指标精度).引入外部知识通常有两种形式:其一是引入与类别相关的、除属性和类标签之外的其他来源的描述,这一过程类似于“数据增广”,即在现有数据集基础上,进一步扩大数据来源;其二是直接利用现有大型知识库,主要存在形式为知识图谱,是人工智能符号主义的典型代表.
· 类别文本描述(text-description)
在数据集中,由于图像对应的文本信息,例如类标签、属性等知识包含的信息是有限的,这在某种程度上限制了模型在ZSL 任务上进一步提升性能.因此,有研究者通过扩展数据集中文本信息的来源,即增加数据量来增加所包含的知识量,从而进一步提升模型处理对应任务的性能.额外数据来源有很多,例如,可以用从网站(例如Wikipedia 或Wikipedia articles)的词条中或者对应的专业领域网站,获取到针对该类更多的描述[107,118-120].同样,也可以通过搜索引擎[47]等其他渠道.在挖掘到额外的文本描述之后,通过一些自然语言处理(natural language processing,简称NLP)技术,例如传统的词袋模型(bag of words,简称BOW)[119]或者提取TF-IDF 特征[118,120],对这些信息低维嵌入进行处理;还可以利用词嵌入+深度模型等方式,对额外的信息进行编码,映射到一个低维的表示空间中[107].需要指出的是,在获取额外知识的同时,也需要过滤掉其中包含的噪声.如何有效过滤噪声并同时保留任务相关知识,是目前比较棘手的问题.
· 知识图谱(knowledge graph)
知识图谱的本质是语义网络,是一种图结构的数据,由“节点-边-节点”组成.其中,节点代表“概念”或“实体”;边则代表两个节点之间的关系,用来描述现实世界中的概念、实体记忆以及他们之间丰富的关联关系(知识谱图发展报告2018).在零样本学习领域,常用的知识图谱有WordNet,ConceptNet[121,122]等.想要利用知识图谱,首先要解决的问题就是如何对知识图谱进行合理的表示.由于知识图谱中的实体、概念以及关系均采用了离散的、显式的符号化表示,而这种表示形式难以直接应用于基于连续数值表示的神经网络中,因此,将其包含的知识尽可能地嵌入表示在一个低维向量空间中,是知识图谱与深度神经网络相结合的前提条件.在这方面,有两类主要方法:以翻译模型为代表的传统知识表示技术[123];以图神经网络(图神经网络(graph neural network,简称GNN)[124]和图卷积网络(graph convolutional network,简称GCN)[125]是代表性的两种)为代表的深度知识表示技术.尤其后者的出现,使得知识图谱的表示学习跨入了深度学习的领域,将以知识图谱为代表的符号主义和以深度学习为代表的连接主义走上协同并进的道路.其次,还有另一个关键的问题在于“符号主义和连接主义,两者分别包含的人类先验知识和从数据中学出的经验知识,怎样结合才能有效提升特定任务性能?”.以WordNet 知识图谱为例,主要包含了两方面可用的知识:其一是层次化的概念表示,例如“哺乳动物-猫科动物-东北虎”,有研究者利用这一层次化的知识表示形式来引导判别性特征的生成[40,126-128];其二是包含不同类之间的显式关系,有的研究者利用这一特性来辅助源域到目标域之间知识的迁移[31,46,62,129-132].需要指出的是,后者还处在起步的阶段,也是如今的“数据+知识驱动”思想潮流的主要呈现形式.
1.4 知识之间的联系
初级、抽象、外部这3 个层次的知识并不是孤立存在的,它们之间也存在千丝万缕的联系.基于第1.1 节~第1.3 节的介绍,它们之间的详细关系如图2 所示(抽象知识中的数据分布包含了数据的流形分布和概率分布).
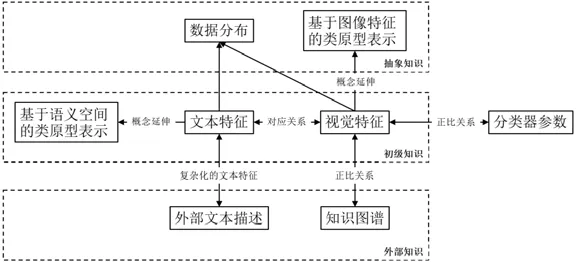
Fig.2 Knowledge relation framework图2 知识关系架构
从图2 中可以看出:初级知识中的文本特征与视觉特征存在对应关系,即某个类的标签或者类属性对应该类全体图像样本;而基于语义空间的类原型表示则可以看成文本特征在概念层次的进一步延伸.基于初级知识中的文本和视觉特征,我们可以建模它们各自的多个数据点之间的流形分布,或者学出他们的特征概率分布;而基于图像特征的类原型表示也可以看成是视觉特征在概念层面的进一步延伸,多类原型表示也可以在一定程度上反映类内方差的信息.外部知识中的外部文本描述,则可视作复杂化的文本特征,因为它在包含更多信息的同时,也包含了更多的噪声,使得任务相关信息的处理和提取变得更加困难.
除此之外,我们在原先不同类型知识之间关系的基础上,新增加了两个关系.
(1) Zhou 等人[76]提出了一个假设,即“如果两个类视觉上相似,那么其分类器的参数也相似”.因此,我们可以通过这一假设,将分类器参数加入到语义空间和视觉空间的对应关系构建过程中,代表性工作如文献[76,130,131]中的ZSL 模型.
(2) 针对视觉特征和知识图谱之间的关系,Deselaers 等人[133]基于对ImageNet1k 数据集的分析得出一个结论:类中图像视觉相似性与类标签的语义相似性在总体上成正比(总体上).即在人类定义范畴内的概念之间的相似性,能够反映在这些概念内所包含的图像之间的视觉相似性上.该文献类标签之间的相似性度量使用的是JC 距离(Jiang and Conrath semantic distance,简称JC distance),因此更确切地说,视觉之间的相似性和所对应的类标签在知识图谱中的显式距离,在总体上成正比.
2 基于知识迁移的零样本视觉识别模型
在这部分内容中,我们将基于本文第1 节所定义的不同层次的知识,对现有零样本学习的相关工作进行梳理.为便于读者理解该层次模型使用知识的方式,本文在每一层次的模型中,进一步进行了相应的合理划分.需要指出的是,这一过程是向下兼容的,即依据模型所用到的最高级层次知识进行模型的划分.例如,模型如果同时使用了初级和抽象层次的知识,就将其归纳到基于抽象知识的模型范畴中.接下来,我们将进行详细的介绍,介绍的重点将是最具代表性的图像分类任务领域的模型.
2.1 基于初级知识的零样本模型
在零样本学习领域,大部分的工作仅仅使用了数据集中包含的一些初级知识(属性、类别标签、视觉特征等).在这类模型中,属性作为标签和视觉特征之间的中间描述,在源域类别和目标域类别之间拥有良好的描述性和迁移性.因此,有很多研究者从概率的角度去进行属性学习的工作.其中,Lampert 等人[33,63]提出了代表性的属性学习模型,掀起了属性学习的热潮,后面很多工作均是受此启发.除了属性学习之外,也有的研究者将文本特征空间和视觉特征空间之间进行映射建模,这样更接近零样本学习的本质.深度学习的兴起,其强大的拟合能力极大地提升了模型性能,这也让很多研究者使用深度模型去重复这些建模思想.下面,我们分别对基于属性迁移的模型和基于映射的模型两大类方法进行介绍.
2.1.1 基于属性迁移的模型
如前面第1.1 节中所述,属性知识作为一种中间描述,能够让可见类和不可见类之间实现信息的共享,具备了良好的迁移性.因此,很多研究者将属性作为底层特征和高层抽象特征(即标签)之间的中间表达层,进行零样本的学习.根据建模的方法,大致可以分为概率模型和深度模型.
· 概率模型(属性学习)
Lampert 等人[33,63]首先提出了两个具有影响力的基于属性的概率模型:直接属性预测模型(direct attribute prediction model,简称DAP)和间接属性预测模型(indirect attribute prediction model,简称IAP).
DAP 模型的架构如图3 所示.
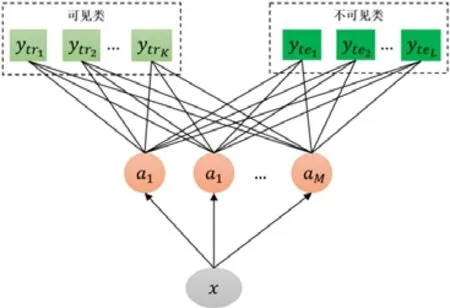
Fig.3 DAP model图3 DAP 模型
图3 中,x表示为可见类样本的图像底层特征,a1,a2,…,aM表示为可见类与不可见类之间共享的M个属性,顶层的y tr1,ytr2,...,ytrK和y te1,yte2,...,yteL分别代表可见类的标签和不可见类的标签,K和L分别表示可见类和不可见类的类别数.在训练过程中,首先将可见类样本的图像底层特征和二值属性向量作为输入,然后利用支持向量机训练属性分类器,最终得到样本和属性之间的关系p(aM|x).在测试过程中,结合之前得到的属性分类器,首先输入不可见类样本的图像底层特征,即可实现对该样本的属性预测;然后利用类-属性矩阵(即类别和属性之间的先验知识),最终完成对测试样本的分类;测试时,对测试样本的属性进行预测,再从属性向量空间里面找到和测试样本最接近的类别.从公式角度来看,在测试时,首先计算不可见类样本属于每个未知类的概率:
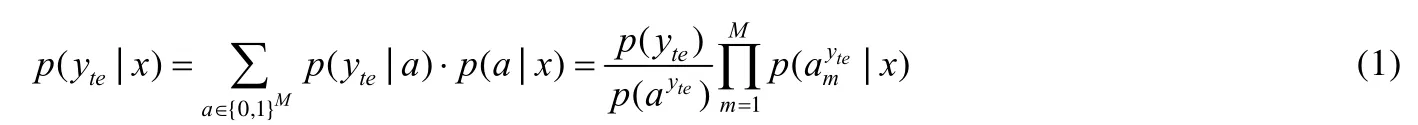
其中,p(yte)为每个未知类的先验概率.因此,利用了最大后验估计方法(maximum a posterior,简称MAP),其预测最终不可见类标签的公式如下:
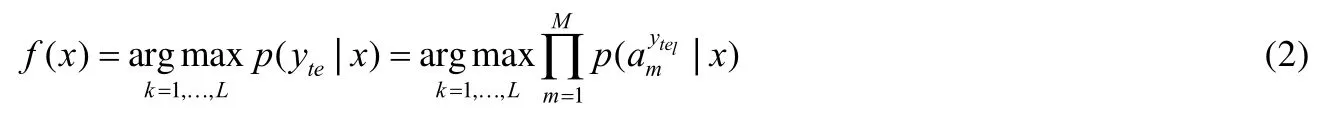
有研究者基于DAP 模型的思想框架进行了进一步深入的工作.针对属性本身,区别于文献[33,63,64]均是专家标注的属性,有的研究者进一步地扩展了属性的来源[20,41,42,134,135],还有的研究者[136,137]在建模时考虑了不同属性的重要性程度.Jayaraman 等人[138]则注意到了属性在预测不可见类时的不可靠性(unreliable)问题,并用随机森林的算法对其进行了处理,通过统计每一个属性在预测时的错误率,来提高属性预测的鲁棒性.Rohrbach 等人[139]则借助了知识库来降低人工标注属性的成本.针对模型本身,Huang 等人[64]将属性学习转化为了超图分割的问题.在超图中,每个节点表示一个样本,每条超边表示样本共享的属性.文献[41,42]使用了主题模型来替代SVM.Yu 等人[140]使用了作者-主题模型来建模特征-属性分布.Wang 等人[141]则使用了统一的概率模型去建模目标独立属性和目标依赖属性之间的关系.此外,在其他类型任务中,Hariharan 等人[142]将DAP 模型进一步扩展到了多标签分类领域.Cheng 等人[21]将这一原理扩展到了动作识别领域,具体是将动作转化为属性特征然后加入到零样本网络训练当中.
IAP 模型的架构如图4 所示.
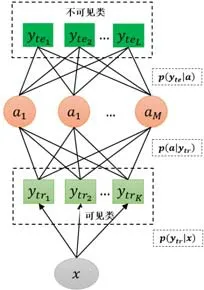
Fig.4 IAP model图4 IAP 模型
图中参数的定义与图3 一致,最大的不同之处在于:IAP 模型使用已知类的标签,间接地学习图像底层特征到属性的映射.在训练过程中,首先将可见类样本的底层特征和其对应标签作为输入;然后利用支持向量机训练出类别-特征模型,得到样本和每个可见类之间的关系p(ytr|x);接着,根据类别-属性关系矩阵获得属性-类别模型;最后,将前两个模型进行结合,推导出属性预测模型.在测试过程中,输入不可见类样本的图像底层特征,首先实现对该样本的属性预测,然后利用类别-属性矩阵并结合贝叶斯定理,实现对该样本的标签预测.从公式的角度来看,在测试时,首先计算不可见类样本属于不同属性的概率:

其中,p(a m|ytrk)为属性-类别模型.然后结合属性-类别模型,进一步预测样本的类标签.这一过程同样利用了MAP 方法,其预测不可见类标签的公式如下:
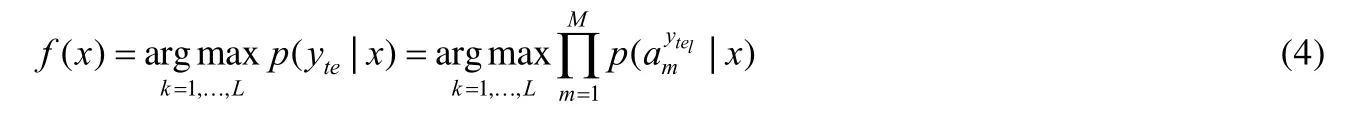
相较于DAP 模型,IAP 模型在实际中使用较少,但也有学者基于IAP 模型进行了深入的研究.Kankuekul 等人[143]考虑到IAP 模型相较于DAP 模型拥有更低的计算成本等优势,因此基于IAP 模型提出了一种在线增量学习算法,能够动态地学习新的属性以及更新现有的属性.
· 深度模型
在基于属性迁移的模型(属性学习)中,Morgado 等人[144]使用了深度神经网络,将RIS(recognition using independent semantics)方法和RULE(recognition using semantic embeddings)方法(该文献中的分类定义)相结合,即利用两者的互补性,将Deep-RIS(属性分类器)加入到Deep-RULE 的过程中,取得更好的效果.Lu 等人[145]则为每个属性训练一个单独的深度属性分类器,并进一步筛选出置信度高的属性组合成为不可见类的伪样本进行训练,将ZSL 问题转化为了一个有监督学习的问题.
· 针对属性特性的学习
除了上述的方法之外,有研究者从属性本身的角度出发,就“属性应该具备怎样的特性”这一问题进行了深入探究.Wang 等人[141]提出了一个统一的贝叶斯概率模型,发现和捕获Object-Dependent(例如“条纹”和“白色”依赖于斑马,互斥于北极熊)和Object Independent(“翅膀”和“爪子”与许多不同的鸟类有关)的属性关系,这是DAP 和IAP 类的模型所没有考虑的问题.Jayaraman 等人[146]针对之前模型中存在“属性的应用依赖于正确相关语义概念”的问题,提出了一种多任务学习方法(每个属性被视作一个任务).该方法通过将相似的图像特征与含义相近的属性对齐,不相似的图像特征与含义较远的属性对齐,并强制结构稀疏,最后为每个属性学得一个分类器,这个分类器能够更好地处理经常协同出现的属性,而非将它们合并为一个属性.Liang 等人[147]注意到了“同一属性在不同的视觉空间中变化很大”这一问题,将类别标签信息和图像特征共同映射到一个共享潜在表示空间,然后进行进一步的属性分类器学习,使得最终学出的分类器依赖于特定而非所有类共享的类信息.Gan 等人[148]聚焦于属性学习中一个最基础的问题:如何抽取出更具泛化性的属性?作者认为属性检测是一个多源域(该文献中每个类被当作是一个域)泛化的问题,并利用现有的分类器最终获取了高质量的属性检测器.Jiang 等人[71]基于字典学习的方式,将人工定义的属性进行重新组合,学习了潜在属性表示.但从另一个角度来看,潜在属性的描述性没有人工定义的属性明确.
除此之外,Li 等人[149]将DAP 和IAP 方法进行了不同方式的结合.Zhu 等人[84]认为,在映射过程中应该保留视觉中包含对应语义空间的部分,因此将视觉样本嵌入到一个低维的概率矩阵中(具体作用是衡量对象中某个属性的出现概率(语义组件)),在视觉空间、属性的语义空间和标签的语义空间之间构建了更加精确的关系.在其他类型任务中,Kumar 等人[17]将属性用于人脸的识别,具体提出了两种类型的分类器:前者筛选出65 个可描述性的属性用于分类器的训练;而后者则不依靠人工标注,转而依靠图像区域的相似性来进行人脸的识别.
2.1.2 基于映射的模型
基于属性迁移的模型,其大致构建了“图像特征-属性-类标签”这3 个层次的架构.而基于映射的模型从不同模态数据对齐的角度出发,直接构建了“视觉特征-文本特征”两层次的架构,即构建视觉空间和语义空间之间的映射,并且要求映射是具有泛化性的(从源域可见类到目标域的不可见类).这种映射形式从方向到形式上都是多种多样的,我们根据所构建映射的方向差异,将这类模型分成以下4 类:从视觉空间到语义空间的映射(正向映射)、从语义空间到视觉空间的映射(反向映射)、视觉空间和语义空间的双向映射、视觉空间和语义空间中的数据共同映射到共享潜在空间(共同映射).下面分别对它们进行介绍.
· 正向映射
根据映射方式的不同,这种映射方式既可以是线性的,也可以是非线性的.其基本形式如下所示:

其中,f(·)是指正向映射函数,最基本的,它可以只由一个映射参数W组成;Ytr可以是标签,也可以是属性.研究者还进一步地加入了各种类型的正则化项,例如常见的二范式约束.针对映射函数f(·),有的研究者[61,82,150,151]致力于扩充映射内容丰富性,例如Yu 等人[150]增加了类分离性损失、Li 等人[82]增加了潜在属性空间学习等;而针对映射函数本身,有的研究者[19,23,81]利用神经网络强大的拟合能力来进行映射、有的研究者[65,152-154]通过使用矩阵分解的技术来构建更加细粒度的映射.
损失函数min 的方式也分多种,例如有均方误差的形式,也有基于均方误差的Triplet Loss[45,65,78,155]的形式.除了岭回归形式的损失之外,基于概率的损失(例如深度神经网络模型中常见的交叉熵损失)也可以被认为是存在于正向映射过程中的损失方式.Atzmon 等人[156]基于OOD(out-of-distribution)的思想构建了一个概率模型框架,用以区分来自于可见类和不可见类数据,并通过softgate 的方式将可见类分类器(expert model for seen classes)和不可见类分类器(ZSL expert)结合起来,以更好地适用于广义零样本任务(GZSL),该框架可以整合任何输出为类别概率的模型.Zhu 等人[78]通过利用语义信息引导的多注意力机制来定位图像中最具判别性的部分,并在Softmax Loss 和Triplet Loss 的共同作用下,挖掘出类间分离、类内紧致的视觉特征.
在测试阶段,由视觉到语义空间的映射完成后,使用k近邻分类器来对不可见类样本进行认知.在其他类型任务中,文献[19,23,45,157]则分别将正向映射的思想扩展到了零样本面部欺骗攻击任务(face anti-spoofing)、零样本的动作识别、目标检测等任务当中.其中,Liu 等人[19]引入树状的条件CNN 结构来进行零样本面部欺骗攻击任务(face anti-spoofing);Jain 等人[23]利用神经网络将视觉内容映射为目标概率,并利用词嵌入技术来建立在目标和动作之间的联系;BANSAL 等人[45]将从图像目标中提取到的图像特征,通过相似性比较的策略进行类别的认知.
· 反向映射
一般来讲,视觉空间维度要比语义空间维度大,所以建立从视觉空间到语义空间的映射往往会丢失判别性信息,产生特征空间坍缩.因此相较于正向映射,反向映射能够保留更多的描述性信息,从而能够防止特征空间坍缩,进而缓解零样本学习中存在的Hubness 的问题.其基本形式如下所示:

其中,g(·)是指反向映射函数,其设定类似于正向映射的函数;Ytr可以是标签,也可以是属性.研究者们还进一步地加入了各种类型的正则化项,例如常见的二范式约束.min 的方式也是多种多样的,例如均方误差的形式.在这类方法中,目前只有少量的研究[11,68,89,158,159],更多的是针对映射函数的改进,例如,Kodirov 等人[11]增加了源域和目标域所学字典的相似性约束,使得学得的映射更加具有泛化性;Changpinyo 等人[89]直接建立视觉类原型(簇中心)与语义类原型之间的反向映射.
在测试阶段,由语义空间到视觉空间的映射完成后,使用k近邻分类器来对不可见类样本进行认知.
· 双向映射
这种映射方式同样也是为了解决正向映射过程中产生的信息丢失、特征空间坍缩的问题.为了保留更多的判别性信息,研究者将映射到语义空间中的特征,再重构回视觉空间.这样,学习到的映射就能够得到保留更多的信息.其基本形式如下所示:

其中,f(·)和g(·)是指映射函数,这两个映射函数同样可以是线性的,例如只是互为转置的映射参数W,也可以是非线性的;而Ytr可以是标签,也可以是属性.min 的方式一般为均方误差的形式.
Kodirov[66]构建了基本的自编码器(auto encoder,简称AE)结构来实现双向的映射,其中,编码器(encoder)将视觉空间映射到语义空间(属性),然后再重构回去(decoder).基于这样的思想,许多后续的研究针对双向映射函数进行了改进.Annadani 等人[160]在加映射层数的基础上加入了类别之间的关系约束,且映射方向与文献[66]相反.Wang 等人[101]使用了生成式的模型VAE 来构建双向映射,将语义空间作为隐层(将属性假设为高斯分布,即属性经过两个线性映射分为生成均值和方差).这样能够更好地揭示数据的复杂结构,从而学出判别性更强的特征表示.Zhao 等人[12]利用双向映射来生成域不变的特征.此外,有研究者扩充了映射方式的丰富性.Lu 等人[67]构建了竞争性的双向映射(competitive bidirectional projection),在构建双向映射的基础上,先利用不可见类与可见类之间的相似性关系来辅助不可见类伪样本的生成,再通过Competitive Learning 机制,使得伪样本离最相似不可见类中心(只是将视觉特征空间中,映射过来的语义特征作为类原型)最近,离次优的中心较远,使得生成的模型更加泛化和鲁棒.Chen 等人[161]在实现上述过程(重构)的同时,将语义空间分解成两个子空间(两个子空间分别进行分类和重构任务,可以认为是两个互相冲突的任务).通过对这两个子空间进行对抗学习,使得学出的嵌入表示既能保留细节又具有判别性.Bin 等人[162]在构建双向映射的同时,将所提取的特征分解为语义(描述性)特征、非语义(非描述性)特征以及非判别性特征.通过这种方式来提取出更加具有判别性和泛化性的特征,从而增加模型的泛化能力.
这类方法在测试阶段对不可见类的认知类似于正向映射.
· 共同映射
基于共同映射的模型,其形式更加多样,我们下面分别进行介绍.其基本形式如下所示:

其中,f(·)和g(·)分别指语义空间和视觉空间到共享空间之间的映射,这一映射函数既可以是线性的,也可以是非线性的;Ytr可以是标签,也可以是属性;而g(Ytr)既可以是映射,也可以是指类名对应的词嵌入的表示.
共同映射形式的多样性体现在sim(·)的多样性上,sim(·)主要的存在形式是兼容函数(compatibility function),两个向量直接内积相乘(f(Xtr)·g(Ytr))的形式是主要模式之一[10,52,159,163-168].其中,Frome 等人[159]提出了著名的DeVise 模型,将CNN 提取的图像特征和标签的词嵌入表示进行内积形式的相似度计算,然后使用度量学习的Ranking Loss(triplet loss)将它们学习到一个共享潜在表示空间.文献[165,166,168]则是这一模式的基本延续.文献[163,164]则在此基础上考虑了语义的组合问题.文献[10,167]采用了集成学习(ensemble strategy)的思想.其中,文献[10]与字典学习相结合,构建了多个字典,从而能够更好地重构可见类与不可见类所共享的潜在语义字典.文献[167]则通过最大化可见类标签矩阵和随机选取的不可见类标签子矩阵之间的关联性来产生多个标签映射权重,进而映射出多个标签子矩阵;同时,相对应的视觉特征提取模块也产生同等数量的分支,然后两个模块对应分支通过内积相乘(对齐的目的)并通过集成的标签预测方式来为不可见类数据进行打上高置信度的伪标签,迭代地加入到训练过程中.
Yazdani 等人[52]将共同映射的思想扩展到了Spoken Language Understanding 任务中,直接构建了句子与标签之间的相似性.
双线性兼容函数(f(Xtr)TWg(Ytr))也是另一种兼容函数的主要形式,这一形式的目的是学出来自两个空间表示的最大兼容分数(maximum compatibility score)[27,95,169-175].其中,Yu 等人[173]为了解决在映射过程中各个样本可靠性(贡献)不同的问题以及Domain Shift 问题,提出了ASTE(adaptive structural embedding)和SPASS(selfpased selective strategy)方法,在构建映射的同时,前者自适应地调整松弛变量,以体现训练实例之间的不同可靠性,使得映射更具辨别性;后者通过迭代地迁移可靠性逐渐减弱的不可见类样本以缓解Domain Shift 问题,同时极大地缩短了训练时间(也用了矩阵分解技术).Jiang 等人[174]在训练过程中采用了自适应的方式,即加入不可见类的文本数据来缓解可见类与不可见类之间存在的Domain Gap 问题.Song 等人[175]在构建共同映射的过程中,除了将可见类数据进行准确的映射约束之外,还将不可见类的数据强制映射到其他点,从而缓解了Domain Shift 问题.在其他类型的任务中,Wang 等人[27]将双线性映射方式扩展到了零样本动作识别领域,其模型框架类似于文献[159].
除此之外,sim(·)也可以是均方误差[176]或者是余弦相似度等形式,也可以是基于这些基本相似性度量方式进一步构建的Triplet Loss 形式.Tsai 等人[177]在视觉分支和文本分支映射的过程中加入了AE 的结构,并在隐层施加了分布对齐的约束,然后分别将AE 的隐层映射到共享的潜在表示空间.
· 其他基于映射的模型(多种映射方法混合)
这个类型的映射方式,其主要借助判别性损失(例如softmax loss)来完成正向(或者反向)映射,并在此过程中加入对方模态(除正在进行映射模态之外的另一种数据形式)的信息.我们依据模型的构建思想,可以分为传统模型和元学习模型.
在传统模型中,Liu 等人[69]在映射的过程中,通过温度校正(temperature calibration)[178]来缓解由于在可见类数据上的过拟合导致的对可见类的域偏移现象,最终将两种模态的信息映射在同一空间.Jiang 等人[179]定义了可见类的分类损失与不可见类的迁移损失,将知识迁移的过程进行了一定程度的量化,使得提取的特征同时具有判别性和迁移性(正向).Liu 等人[70]之前的模型均是基于空间中可见域和不可见域的数据分布在样本级别具有一致性这一假设,而该假设过于严格,因此,Liu 等人提出不寻求在样本级别上进行映射,转而致力于任务级别的一致性,即,以任务为基本单位来构建不同空间之间的映射关系(任务是指对数据集的不同划分).具体来说,对可见类进行不同的划分,形成N个任务;然后,每个任务中类的属性值通过非线性的方式转化为类原型,并与该任务中的图像进行相似性度量(PEC),提升类原型在可见类样本中的泛化性;最后,将相似性度量的结果进行归一化表示之后,完成分类(cross-entropy loss,简称CEP),其本质上是通过训练和测试在任务层面的对齐,使得训练阶段尽可能地仿真模型的测试环境.模型的思想如图5 所示(每个几何形状表示一个样本,每种颜色表示一个类).
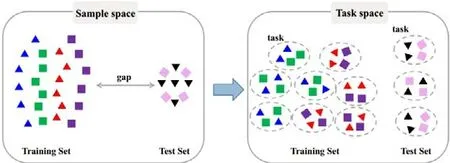
Fig.5 Core idea of CPL (convolutional prototype learning)[70]图5 CPL(convolutional prototype learning)核心思想[70]
元学习模型区别于传统的数据集划分方式,对数据集作了进一步的划分,即进一步将训练集划分为两个部分(这一划分的标签集情况,不同文献中,根据不同的训练要求有着不同的要求);此外,元学习采用了Episode-Based 的训练策略,即其每次迭代都会随机抽取所有类别的子集作为一个训练任务,这样的目的均是为了最大程度的追求模型的泛化性能.Sung 等人[180]提出的基于元学习的零样本学习模型将整体数据集分割为训练集、支持集(support set)和测试集,并且其支持集和测试集共享相同的标签.该模型的核心思想是,通过比较的方式来认知新的事物.因此,将训练集的数据进一步随机划分为样本集(sample set)和查询集(query set)(这样的划分用于仿真测试阶段的support set/test set).具体做法是:将样本集分别与查询集中的样本语义特征作拼接,然后输入到分类网络中进行训练.而Hu 等人[181]提出的模型将训练集进行了随机划分,并要求两者的标签集是互斥的.该模型的核心思想是,根据零样本学习中两个域相似性的差异做出不同程度的修正.因此,所提出的模型包含两个模块——Task Module(learner)和Correction Module(meta-learner):前者将语义特征作为输入并输出初始的预测(视觉特征的质心);后者将前一模块的预测结果、可见类数据、不可见类语义特征作为输入,输出修正量,目的是对前一模块的结果进行修正.与前一模块的输出相加,即为最终的预测结果.
除了图像分类的任务之外,Shen 等人[38]将这一思想用于基于轮廓的图像检索任务,除了各自模态数据的编码网络之外,还利用了图卷积网络和Kronecker 融合来增强两种模态数据(草图和真实图像)的一致性,并最终用于基于轮廓的图像检索任务(哈希检索).
总体来讲,基于初级知识的模型,所使用到的知识范畴包含了类别标签、视觉特征、属性这3 种.在这3 类知识中,类标签虽然包含的信息没有属性丰富,但是其词嵌入的分布式表示特性(该表示形式还具备一定的推理能力,这也是类别标签的词嵌入表示形式所隐含的知识)也能较好地完成零样本学习任务.文献[170]证明了类标签词嵌入的表示形式和属性在表示能力上基本上是等同的.因此,在基于映射的零样本学习模型中,其语义空间中的属性知识和类别标签知识在大部分时候可以进行互换;同时,也有模型可以兼容多种形式的映射[51,182].但是,基于映射的模型无法很好地反映数据类内方差的特性[62],并且基于共同映射的方法有两个局限性:一是不能使用高效的判别分类器,二是不能有效地处理GZSL 任务[99].
2.2 基于抽象知识的零样本模型
在零样本学习领域,初级知识仅代表可以直接获取的信息.而随着研究的深入,研究者进一步借助初级知识挖掘出了基于图像特征的类原型表示、数据流形分布、概率分布等更加高级的抽象知识,这些知识能够更全面地反映出数据的本质特征,从而能够学出泛化性能更好的模型.因此,接下来我们将从基于视觉类原型的模型、基于数据流形分布的模型和基于数据概率分布的模型去分别展开阐述.
2.2.1 基于视觉类原型的模型
基于视觉类原型的模型,是将所挖掘出的类原型表示作为一个中介,然后去进一步地构建模型,如用于推理等,而非直接用于认知不可见类.从这点来看,其用法更加近似于初级知识.
Zhao 等人[85]使用了基于类内均值的视觉类原型表示来构建映射模型,并与基于合成视觉类原型表示的模型进行了对比.Wang 等人[80]使用基于交叉熵(cross-entropy loss)的损失学出每个视觉类的类原型表示,这样学出的类原型相较于基于质心的类原型表示,能够让类间保持足够的判别性.Changpinyo 等人[87,89]基于视觉类原型提出了样本合成模型,具体来说,在其视觉分支,为了获取每个类的聚类中心表示,为所有样本做PCA,然后加和求均值(在该文献中被称为视觉特征代表),从而将视觉特征从视觉空间变换到语义嵌入空间(该文献中语义嵌入空间可以理解为共享表示层),最后使用支持向量回归机SVR(多核回归模型)来建立从语义空间到语义嵌入空间的映射,并最终基于对模型不同的理解.提出了两种方式对不可见类的认知手段:首先,通过训练好的模型得到预测原型(examplars)的表示,如果将预测的原型视作训练数据,那么直接利用训练好的模型,共同映射到语义嵌入空间进行最近邻的分类;如果将预测原型视作改进后的语义特征表示,则可以整合入任何现有的ZSL框架中,辅助零样本认知过程.前面的模型均基于“源域和目标域数据分布一致”的假设,而这一假设过于严格.Wan 等人[77]利用目标域样本进行聚类得到每个类的类中心,然后同时缩小不可见类样本与模型训练得到的类中心和聚类得到的类中心的距离,并利用二部图匹配对这一机制进行优化(两个虚拟的图进行一对一对齐,但没有上升到流形对齐的高度).该模型的反向映射机制和直推式的机制均有利于缓解Domain Shift 现象(该文献事实上使用了基于视觉的类原型表示,但是没有Prototype 这一表述).
如本文第1.4 节所述,分类器参数也可以认为是正比于类原型的表示,因此很多模型也是基于分类器进行进一步操作的.Misra 等人[183]利用了分类器组合的思想,认为复杂视觉概念是简单概念进行组合的结果,并且进一步的认为:应该用属性视觉分类器和目标视觉分类器组合得到新的复杂视觉分类器,例如“红色(属性)+酒(目标)=红酒”.具体过程为:通过分类器参数组合,然后输入到转化网络中,计算与真实目标的内积,从而进行训练.
2.2.2 基于数据流形分布的模型
研究者主要利用数据流形来主要达到两个目的.
(1) 由于在基于映射的模型中,跨空间的数据映射为使重构误差最小化,从而倾向于学习两个空间数据之间的共性,这会导致数据的判别性出现不足.鉴于这种情况,有的研究者将流形正则化项加入基于映射的零样本学习过程中,保持数据的结构,从而增加映射的泛化性.
(2) 不同空间进行的映射所产生的Domain Shift 问题,其本质上可以视作模态鸿沟(media gap)的问题,从数据分布的角度,将不同空间的数据进行流形对齐的操作,实质上就是缓解这一问题(文献[80,94]明确提到这一点).
下面,我们根据研究者是否考虑数据的复杂流形分布,对相关工作分别进行详细的介绍.
在零样本学习中,模型的泛化性能显得尤为重要.而在半监督学习中,增加流形正则化项(manifold regularizer),能够增加对测试数据的泛化能力[184].其基本形式如下所示:

· 简单数据流形
仅考虑简单数据流形结构(pair-wise 级别)时,不同的研究者有着不同的正则化项构建方式.Xu 等人[28]在映射模型的基础上,通过使用训练数据和测试数据共同构建kNN 图来添加流形正则化项约束.文献[88,93]则通过构建潜在空间的图正则化项来保持数据的几何结构:前者还将DAP 模型的图像特征层和属性层进行了交换,使得模型能够生成一些不可见类的样本;后者则将每个样本被视作可见类的分数组合.Xu 等人[92]用两个流形正则化项来分别保持数据映射过程中在视觉特征空间和属性空间中的几何结构.在其他类型任务中,Qin 等人[29]将这一思想运用到了零样本的动作识别领域,使用了从语料中训练得出的语义表示而非属性特征来判别更加细粒度的动作场景,并在此过程中使用类级别的语义相似性矩阵来保持数据结构,进而维持判别性.
除了增加流形正则化项来保持映射过程中数据的判别性之外,Zhang 等人[91]还提出了结构化的预测方法,即通过最大化后验估计来获取目标域数据的分布,使得潜在空间中对不可见类数据的标签分配是平滑的.Wang等人[94]简化了文献[91]中复杂的结构预测过程,首先建立从视觉空间到潜在空间的映射,相同一批数据在潜在表示空间的结构需要与其在语义空间中的结构保持一致,从而得到不可见类在潜在表示空间中的节点表示.Jiang 等人[53]提出了一种双字典学习方法,通过视觉空间和语义空间的类原型对齐来使得数据的结构对齐,目的是利用视觉空间的判别性来提升语义空间中的判别性.
有的研究者则直接从特征提取的角度出发,去考虑如何更好地保持特征空间的结构.Li 等人[95]考虑到数据可能存在的类间方差小以及类内方差大的情况,增加了图像特征结构约束来归一化类内和类间样本的距离,使得提取的图像特征能够保持空间结构.这一工作虽然考虑到了所提取特征的空间结构的保持,但是并未上升到数据流形的高度.Wang 等人[80]将排序损失和结构优化损失相结合,在学出的共享表示层中,除了保持不同模态数据的对齐之外,同时也能够确保空间中的视觉特征表示拥有更好的结构,使得判别性更好.
· 复杂数据流形
前面的方法均仅考虑了数据的简单流形结构,事实上,数据中存在着更为复杂的流形结构,不同的研究者也给出不同的改进方式.Fu 等人[13]相较于其之前工作[59]中构建的简单近邻图,进一步基于数据特征表示构建起了超图,最终在超图中进行基于随机游走的标签传播过程(该文献中,多视图的方式也可以缓解映射过程中的Domain Shift 问题).Fu 等人[14,60]考虑嵌入空间中存在更为丰富的流形结构,使用类标签图对嵌入空间中的流形进行建模,对空间的距离度量计算采用了吸收马尔可夫链过程(absorbing Markov chain process,简称AMP)而非传统的余弦或者欧式距离.Changpinyo 等人在文献中[87,96]提出了分类器合成模型,该模型考虑了模型空间(分类器参数空间)和语义空间的复杂流形分布,并在语义空间和模型空间分别引入一组了伪基类(phantom class)(这些伪基类能构成各种真实类),与真实类一起构建了加权图;通过马氏距离计算图中边的权重,进而计算类别之间的条件概率;最后,通过模型空间中节点对于权重图的嵌入来进行对齐的操作.测试过程中,通过训练好的模型直接合成分类器来进行不可见类的识别.Yanan 等人[79]提出了一种多模态数据流形对齐的度量方式,考虑到数据可能存在的复杂流形结构,将目标节点的k近邻节点取均值作为类原型的表示.
2.2.3 基于数据概率分布的模型
基于数据概率分布的模型,其本质上是要模拟数据高级特征的生成规律,主要可以实现两个目标:其一,使得模型可以通过这一规律来生成同类型的伪样本特征,从而将零样本问题转化为标准的监督学习问题;其二,可以让模型在生成规律的层次上进行不同模态数据的对齐操作,缓解模态鸿沟问题,变得更加鲁棒.下面我们根据构建模型技术的不同,将相关工作分为非生成式模型和生成式模型,分别进行详细的介绍.
· 非生成式模型
最开始,一些研究者通过非生成式的模型来建模数据分布.在这类方法下,不同研究者的思路千差万别.Mukherjee 等人[97]借助高斯词嵌入方法[185]将不同模态的数据建模为高斯分布,然后建立不同高斯分布之间映射关系.文献[30,100]中也是将数据建模为高斯分布.Micaelli 等人[186]面对许多数据集并不公开的情况,利用符合高斯分布的随机噪声来生成伪数据,并通过依次迭代的最大化和最小化学生网络(student network)和教师网络(teacher network)预测之间的KL 散度,最终使得Student Network 在不依靠任何数据或元数据的情况下,与Teacher Network 的预测相匹配.该文献还提出了新的度量标准来量化教师网络与学生网络在决策边界附近的信念匹配程度.Guo 等人[98]依据可见类与不可见类之间的关系,使用线性映射的方法来估计每个不可见类的条件概率,进而生成不可见类的样本.Bucher 等人[99]基于降噪自编码器(denoising autoencoder)和对抗自编码器(adversarial autoencoder)的模型:前者与标准自编码器的区别在于在输入层增加了噪声输入,在隐层增加了类别信息的输入;后者在前者的基础上,引入对抗训练来对隐层潜在特征的生成进行约束,使编码分布与固定的先验分布相匹配.在这两个模型中,隐层生成的潜在特征编码信息可以视作是数据的分布信息.在其他类型任务中,文献[22,30]分别将这一思想用在了活动识别领域、零样本动作识别领域任务中.其中,Antol 等人[22]将这类模型运用在了活动识别领域,先将模型在草图上进行训练,然后在真实的图像上进行测试,训练过程中的草图可以视作由人类定义的、数据特征的本质分布;Mishra 等人[30]基于双向映射的思想提出了一个生成式模型框架,将语义空间映射到视觉空间然后再重构回去(这一映射可以是线性或者是非线性的),其中,视觉空间的每个类被建模为高斯分布.
· 生成式模型
更多研究者通过生成式的模型来完成零样本学习任务,其中绝大部分研究者通过GAN 来拟合数据的特征分布,并生成伪样本.Tong 等人[105]认为:在映射过程中加入流形的知识虽然可以使得模型更加鲁棒,但是数据流形本身可能存在着的复杂结构(类分布重叠)也会极大地影响Hinge Loss 或者回归损失的训练性能.因此,Tong等人在建立共同映射模型的基础上,整合了生成对抗网络来生成两种类型的样本,分别用来增加同一类样本的多样性和提升存在重叠分布的类之间的判别性.Xian 等人[106]基于WGAN(Wasserstein GAN)来构建模型,能够使得训练过程更加稳定;而且在GMMN(generative moment matching network)模型[99]的基础上增加了生成伪样本的分类损失,这些举措都有助于提升所生成伪样本特征的判别性.该模型奠定了之后绝大多数基于GAN 模型的基础架构.在此基础上,针对伪样本生成的质量问题,Li 等人则[83]进一步增加了灵魂样本(soul sample)的正则化项以及针对伪样本特征置信度的计算,其中,灵魂样本是指每个类所包含多个类原型,生成的伪样本只需靠近其中之一的表示即可.这样能够增加生成伪特征的多样性.Liu 等人[90]则加入类原型进行修正,来提升所生成的不同类伪样本之间的区分性.Paul 等人[108]基于GAN 提出了一个直推式的零样本模型,其在目标域也训练了一个生成器和判别器,并增加目标域生成器与源域生成器参数相似的约束,从而缓解ZSL 中的Domain Shift 问题;除此之外,模型中还通过语义判别损失和语义关联损失相结合预训练了一个特征提取网络,经过该网络提取的图像特征在保持类内相似性关系的同时也能保持其判别性,从而减轻ZSL 中的Hubness 问题.需要指出的是,因为在目标域的不可见类中并不存在对应的图像-文本对,因此在直推式部分输入的数据是不存在对应关系的,这样的处理方式其实包含了“源域和目标域的数据服从同一个概率分布”这一隐藏的前提假设.文献[109,110]则将GAN 与双向映射模型的思想结合了起来.在其他类型任务中,文献[32,37,44]分别将GAN 扩展到了零样本动作识别、零样本语义分割和零样本视频分类任务中.其中,Mandal 等人[32]在条件WGAN 中加入了数据分布检测器(out-of-distribution detector)来判别源域和目标域的动作类别;Bucher 等人[37]在零样本语义分割任务中,除了常规的生成网络结构之外,还使用了GCN 来融合图内各个语义类别的信息,最终生成融合上下文信息的语义表示;Zhang 等人[44]通过增加多层次信息推断损失和互信息相关约束措施来最大化地保持不同模态信息的一致性,从而提升生成的伪样本质量.
有的研究者基于VAE 来构建模型,VAE 相较于GAN,其训练稳定性更好.其中,文献[86,101-104]利用单个VAE 来学习数据的概率分布,文献[102,104]使用了CVAE 模型.Yu 等人[104]将不可见类的数据视作可学习的变量,通过类似于EM 算法的迭代学习策略,即重复生成伪数据的过程和参数学习的过程,来最终完成模型的训练.在该文献中也提到了生成的伪样本特征置信度问题(类似的提法还有文献[83]),并通过dropout 操作来进行置信度的度量.而Schonfeld 等人[103]将零样本问题视作多模态学习问题,通过减小视觉和语义空间中各自VAE 隐层分布的Wasserstein 距离,并增加交叉对齐损失约束,来实现不同空间数据概率分布的一致.在其他类型任务中,Yelamarthi 等人[39]将这一思路用于基于轮廓的图像检索领域,具体是将经过编码之后的真实图像特征和草图特征经过拼接输入到自编码器结构的网络中,其中,自编码器网络可以是VAE 或者是对抗自编码器.
还有的学者将VAE 和GAN 相结合来处理ZSL 任务.Huang 等人[111]将视觉-文本语义映射、文本语义-视觉映射以及度量学习(metric learning)方法融合在统一的框架下,分别对应到所提出模型的生成器模块、回归器模块和判别器模块.其中,判别器损失受文本生成图像工作[187]的启发,通过文本语义和视觉特征的组合构成了多种形式的伪数据,能够帮助生成更加鲁棒的跨模态对应关系.Xian 等人[112]通过VAE 解码模块和GAN 生成器参数共享的方式,将两种模型进行了结合,这种结合方式可视作对GAN 的生成器的输入增加了VAE 的约束;除了零样本学习任务之外,该工作还从可视化的角度去尝试对ZSL 的认知过程进行解释,即利用文献[188]中Image Caption 任务的网络输入伪特征,并经过反卷积生成的图像来生成文本,观察文本内容是否与图像视觉内容相吻合.刘欢等人[113]也是基于与文献[112]的类似思路,但是为非直推的模型.
总体上来看,基于抽象知识的模型在工作模式上主要分为两种:其一是在数据映射的过程中保持数据的流形结构,以增加数据的判别性;其二是在该层次知识的基础上对多模态数据之间进行对齐操作,然后进一步开展后续的工作.由于抽象知识要比初级知识更加接近数据的本质,因此往往取得更好的效果.这也是近两三年来比较热门的研究点.
2.3 引入外部知识的零样本模型
除了挖掘数据集本身所包含的知识之外,有研究者考虑引入外部知识来进一步帮助提升模型的性能.其主要包含了两种形式的外部知识:外部描述和外部知识库.下面我们将分别进行介绍.
2.3.1 基于引入外部描述的模型
在模型输入中引入有关于类别的外部描述,主要有两个目的:首先,外部的语义描述往往包含了更多对任务有利的信息,并且有时还可以节省人工标注的成本;其次,外部引入的数据形式更加贴近实际,其中包含的噪声也能使得最终的模型更加鲁棒.
Lei 等人[118]使用了Wikipedia Article 作为语义空间,提取文本描述的TF-IDF 特征和图像的CNN 特征,并通过简单的内积形式将两者学习到一个统一的潜在表示空间.Qiao 等人[119]延续了文献[154]中的建模思想,并使用词袋模型处理Wikipedia Article,用于替代对应类别的属性表示,这样能够减轻人工搜集语义表示的负担.区别于文献[154],考虑到引入的外部描述包含了极大的噪声,Qiao 等人[119]将映射参数分解后的结果进行了更进一步的矩阵分解,分解后的两个矩阵分别作为图像的分类器权重参数和用于抑制外部引入知识(属性)的噪声.Elhoseiny 等人[120]也是提取外部文本的TF-IDF 特征,并最终用于细粒度的图像分类任务.Zhu 等人[107]则基于GAN 强大的特征拟合能力,利用目标域类别的Wikipedia Articles 描述来生成对应类别的视觉特征,并通过全连接层来过滤文本特征输入所包含的噪声.在其他类型任务中,Xu 等人[25]在构建视觉-语义映射的同时,通过增加额外数据来扩展数据集,并根据与目标域的相关性进行加权,从而提升模型的泛化性能,最终用于动作识别任务.Xu 等人[43]利用外部图像来提取情感词典以及外部语料中包含的语义关系信息,共同辅助迁移从视频中提取的深度特征,最终用于视频情感识别任务.
2.3.2 基于引入外部知识库的模型
外部知识库是目前大多数人所理解知识的狭义的概念范畴.通过引入外部大型知识库并作为任务的先验信息,主要有3 个目的:其一是进行数据挖掘和分析;其二是帮助模型提取更好的特征表示;其三是在当前纯数据驱动的模型在遭遇瓶颈时,利用大规模知识库中的显式关系,能提升现有模型对于特定任务的性能或者减轻模型对数据的依赖,并可以在一定程度上增加模型的可解释性.下面我们分别进行介绍.
· 首先,一些研究者针对外部知识库进行了一些前沿性的探索.
Rohrbach 等人[16]使用WordNet 同义词集的定义去挖掘属性.Rohrbach 等人[139]通过实验来分析知识库取代部分现有数据的可能性,实验证明:在零样本问题中,用知识库取代人工标注属性会导致基于属性的模型分类精度下降;但在基于分类器相似度方法中,其性能达到了人工监督的水平.而且实验也表明,在语义相似性度量(SR measures)方面,不同的知识库通常会导致不同的结果:Yahoo image search 和Wikipedia 表现较好,而Yahoo Web search 和WordNet 表现欠佳.Zeynep 等人[182]鉴于属性知识获取代价较大,探讨了对外部层次化的知识库或者外部描述进行编码,并辅助或者取代属性知识的可能性.Gan 等人[24]通过实验分析得出:相较于基于WordNet 关系计算的词的相似度(JC 距离),基于类名词嵌入之间余弦相似度构建的可见类与不可见类之间的关系,能够更好地进行知识传播过程(但仅限于动作识别领域).Kordumova 等人[36]通过引入外部信息以及知识库(WordNet)去识别图像中的场景,并不使用任何场景图像作为训练数据,并通过实验分析得出:来自知识库中间层次的目标对于场景的识别有较大贡献,而分别来自顶层和底层的General 目标和Fine-Grained 目标则对场景识别贡献有限.
有的研究者受限于现有知识库对于某些任务的局限性,根据特定任务特性自己定义知识库,从而更好地完成相应任务.Deng 等人[34]鉴于多分类问题中标签相互独立的假设并不成立的问题,自己定义了一个HEX(hierarchy and exclusion)图,图中的语义关系可以分为Mutual Exclusion、Overlap 和Subsumption,然后以该图作为标签关系先验,构建了一个基于条件随机场的概率分类模型.
· 其次,有的研究者引入知识图谱,并侧重于使用其层次化的知识表示形式.
Al-Halah 等人[126]利用了知识库中层次化的分类信息,在不同层次上进行属性学习,并进行层次化的属性迁移.Li 等人[127]沿用了文献[163]中学习映射的思想,借助WordNet 知识库进行了层次化的文本语义嵌入,并假定每个标签在WordNet 中均有对应节点,从根节点到特定节点,越靠近特定节点的节点,其贡献越大,最后将这一思想加入到凸化组合中.Li 等人[128]则利用了知识库中层次化的分类信息,用于提取更加具有判别性的图像特征,然后基于提取的源域图像特征进行域适应和标签传播操作,最终进行细粒度的类别认知.DUTTA 等人[40]将自编码器和GAN 结合,利用知识库(WordNet)中层次化的表示并结合词嵌入来引导自编码器生成更加具有判别性的特征表示,从而更好地辅助GAN 进行对抗的训练,最终进行基于轮廓的图像检索任务.
· 最后,有研究者将“符号主义”和“连结主义”中的表示方法相结合,成为当前的主流形式.
本文根据对符号知识表示方法的应用,又分为传统方式和基于深度学习(如图网络)的方式.
有研究者将知识图谱用传统的知识表示方法(如翻译模型)进行表示.这一类模型更多地出现在传统图像分类任务之外.Lu 等人[46]将传统的知识表示与零样本视觉关系检测任务相结合,所构建的模型由两个模块组成.
1)Visual Appearance Module:训练VGG 网络用于提取图像中的Object 和Predicate.
2)Language Module:将两个Object 拼接为新的向量来表示视觉关系三元组,然后通过映射函数来使得三元组之间的关系正比于它们所包含的Predicate 对应词嵌入之间的余弦距离,其值越大,表示对应的视觉三元组成立的概率就越高.
最后做Triplet Loss(rank loss),并且区别于之前的数据集只包含较少的视觉关系类型,Lu 等人创建了一个新的数据集VRD,包含了数万种关系.Cui 等人[129]将传统知识表示用于零样本图像的多标签分类任务中,所提出模型将知识(ConceptNet 知识库)表示与多标签的图像表示结合在一起,两者进行协同的训练,即将图像分类分支的分类器权重参数与知识表示分支的节点映射参数进行了共享,在完成图像多标签分类的同时,能够实现知识库中有关系的节点表示尽可能接近.最终,在标签预测任务、零样本标签推测任务以及基于内容的图像检索任务中证明了模型的有效性.并且实验表明:该模型可以在某种程度上提炼知识库来描述图像,并使用结构化标记来标记图像.
有研究者将现有任务模型与图网络相结合.Wang 等人[130]首先将图网络与知识库结合并用于零样本图像分类任务中.模型分为两个独立的部分:CNN 分支和GCN 分支.CNN 分支首先使用预训练好的CNN 网络为原始图像抽取高级特征;其次,GCN 分支(如图6 所示下方的GCN 网络,模型示意图来源:https://github.com/JudyYe/zero-shot-gcn)将数据集中的每个类别作为知识图中的一个节点,并对其词嵌入表示作为节点的初始输入.模型训练时,可见类节点的初始表示经过GCN 网络的信息融合,融入了周围节点的信息并形成新的表示,然后知识图中可见类节点范围内,利用来自CNN 部分的图像类别对应的分类器权重参数作为监督信息(图6 所示绿色节点)来训练GCN 模型的参数.测试时,将知识图中的不可见类节点的输出视作对应类别的分类器权重参数.需要指出的是,该模型使用的知识图谱是基于NELL[189]和NEIL[190]构造的新知识图谱.Kampffmeyer 等人[131]则对前面的模型[130]进行了进一步改进,包括:(1) 使用了更少的图卷积网络层数来避免训练过程中节点表示的趋同性;(2) 进一步地改进现有WordNet 知识库,使其节点之间的连接更加密集,并根据节点间的距离加入了注意力机制(attention mechanism,简称AM);(3) 在训练过程中采用轮流优化策略,固定GCN 的参数,对预训练好的CNN进行微调操作来缓解Domain Shift 问题.这些操作均进一步的提升了模型效果.
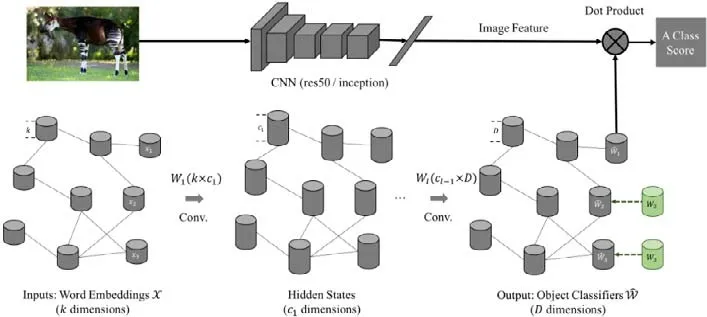
Fig.6 Architecture of GCNZ (GCN for zero-shot learning)[130]图6 GCNZ(GCN for zero-shot learning)框架[130]
Zhang 等人[62]指出了之前基于图网络模型[130,131]的不足:首先,它们仅基于可见类构建损失进行训练,而不涉及到不可见类,因此域偏移问题仍然存在;其次,该关系仅在类级别层次建模,忽略了实例级关系,导致数据的判别能力不足;最后,这些方法对关系的利用仍然是隐式的(指不是直接利用关系进行标签传播,而是借助关系将节点表示转化为分类器参数),这会导致在最终分类的过程中,被提炼出来的知识被稀释.针对前面这些问题,Zhang 等人提出了TGG(transferable graph generation)模型.
TGG 由两个模块组成——GraphGeneration 和RelationPropagation.
· 在GraphGeneration 阶段,首先构建了Class-Level Prototype 图,该图是借助ConceptNet 知识库包含的显式关系进行构建的,各个节点的表示为视觉特征,不可见类的节点由GAN 生成的伪样本作为输入;在此基础上进行Multi-Head Attention+Multi-Level Attention 机制的训练,修正节点表示,使得数据更加具有判别性;最终经过关系核(relation kernel)损失(即生成的新图需要和对应的原图结构保持一致,防止第1 阶段训练过拟合)生成了Instance-Level 图,进入到RelationPropagation 阶段.
· 在RelationPropagation 阶段,使用标签传播算法(相比隐式嵌入方法,这样能使知识的传播更有效率),并构建双向传播机制(分别将图的可见类部分和不可见类部分作为初始标签矩阵),最终使用元学习的训练策略来训练模型.
需要指出的是,注意力机制、双向标签传播以及元学习的训练机制均是用来缓解域偏移问题的,而该模型可以用于完成ZSL,GZSL 以及FSL 任务,其框架示意图如图7 所示(Gc表示类级别的图,Gl表示样本级别的图).
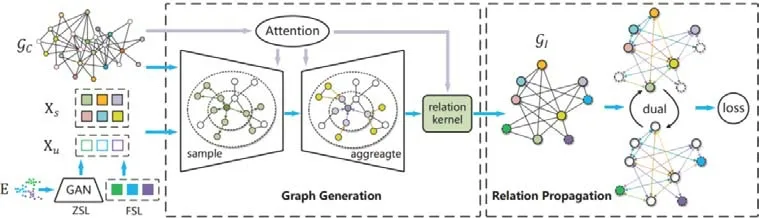
Fig.7 Architecture of TGG[62]图7 TGG[62]框架
除了传统的图像分类任务之外,Lee 等人[132]将图网络扩展到零样本多标签图像分类领域,利用WordNet 知识库中的显式关系为图像标签构建图关系表示,然后基于标签词嵌入向量之间的相似度来建模关系的权重,最后将图像特征和标签表示作为初始的节点状态,使用图门神经网络(graph gated neural networks,简称GSNN)[191,192]来进行知识传递.Zhang 等人[31]进一步将ConceptNet 5.5 知识库引入到动作识别领域,设计了一个两分支的图卷积网络:一个分支用于生成分类器参数,另一个分支用于生成实例,从而有效地对动作-属性、属性-属性以及动作-动作之间的关系进行建模.
总体来看,引入外部知识的模型,其作用更多体现在通过增加人类的知识先验来进一步减小模型对当前数据的依赖,并提升特定任务的性能.但是这同时也意味着需要对外部知识进行噪声处理,以尽可能消除对任务不利的影响.
3 存在的问题和模型总结
3.1 存在问题
在视觉领域的零样本学习任务中,长期以来存在两个传统的问题:域偏移问题和枢纽点问题,下面分别进行详细的介绍.
· 域偏移问题
即Domain Shift 问题,该问题由Fu 等人[13]首次提出.该文献中将问题定义为“由于源域数据集和目标域数据集包含不同的类,因此这些类所包含数据分布也可能不同.在源域数据集上学习的从视觉空间到嵌入空间的映射函数,如果没有针对目标域数据集进行任何的调整,就会产生未知的偏移/偏差”.在Fu 等人[14]的工作中,对这一问题进行了扩展,由原先源域到目标域(projection domain shift)映射偏移的问题扩展到不同模态映射偏移(visual-semantic domain shift)的问题.从本质上看,前者可以简单理解为域适应问题,后者可以简单理解为模态鸿沟(又被称为语义间隔)问题.
针对第1 种类型的域偏移问题,Long 等人[88]阐述为“这个问题是因为基于回归形式的模型无法发现语义空间固有的几何结构,也不能捕捉到可见类到不可见类之间的关系”.因此针对这个问题,最好的解决方式就是在训练过程中融入不可见类(目标域)的信息(利用不可见类的流形信息),使得模型更好地捕获源域与目标域之间的关系,从而增加模型在目标域的域适应性.由这一思想产生了两种主流的做法:第1 种是建立直推式的模型[10-13,25,28,30,31,42,43,53,59,77,79,85,93,94,100,101,108,112,153,173-175,177],即在训练过程中加入不可见类的样本;第2种是通过生成伪样本(基于GAN[32,40,44,83,90,99,105-113]、非GAN[67,88,98,102,104,145,151]),将零样本问题转化为标准的监督学习问题.这些做法其实均隐含了一个前提假设条件:“目标域与源域的数据分布在样本级别上是一致的”.Liu 等人[70]则放弃寻求样本级别的一致性,转而寻求任务级别上的一致性.Wan 等人[77]则直接利用目标域的不可见类样本进行k-means 聚类来获取目标域的数据分布.
此外,除了在训练过程中加入目标域的信息的方式之外,也有研究者通过保留源数据足够多的信息来缓解Projection Domain Shift 问题.主要有两种方式:一种是建立双向映射[66,67,101,109,160-162],经过特征空间的重构从而建立更加鲁棒的映射模型;另一种是通过增加流形正则化项来保持数据的结构[28,29,88,92,93,161].最后,还有Zhang等人[62]在基于所生成伪数据的基础上,通过引入元学习的训练机制来减轻Projection Domain Shift 问题.
针对第2 种类型的域偏移问题,比较典型的处理方式是基于数据的抽象知识去构建模型,并在抽象层次上进行不同模态数据的对齐操作.有以下的两种方式:第1 种是利用流形对齐的思路,从数据分布的本质特征角度出发,去进行多模态空间的流形对齐[53,79,80,87,94,96],但是Wang 等人[151]对“不同空间中的数据分布一致”这一假设过于严格的问题进行了处理;第2 种是从数据概率分布的角度出发,将多模态数据的特征概率分布进行对齐[30,86,97,100,101,103].
· 枢纽点问题
即Hubness 问题,其可以阐述为“在特征空间中,某个点会成为大多数节点的最近邻点(即使它们之间无关),这会导致数据失去其判别性”,尤其会影响基于最近邻的零样本认知方式的最终效果.Dinu 等人[15]通过实验发现了Hubness 问题的存在,并将Hubness 问题阐述为“Hubness 问题是高维空间的固有问题”,会极大地影响基于回归映射的方法.Lazaridou 等人[155]将Hubness 问题具体阐述为“高维空间经常受到中心性(hubness)的影响,也就是说,它们包含某些元素(即中心点),这些元素会靠近空间中的许多其他的点,却并不与后者相似”.这些论述均表明,Hubness 问题是在高维空间中的一个固有现象.接着,在Shigeto 等人[158]的工作中,通过实验的分析表明:Hubness 问题的出现不仅仅是因为高维空间,而且和Ridge Regression 岭回归方法在零样本问题中的使用方式有关.作者还进一步讨论了基于Ridge Regression 的模型受到的Hubness 问题的影响.
对于Hubness 问题,有3 种主流的解决方式.
1)其一是更新映射的方式.基于文献[155]的论述,很多研究者[11,68,77,89,158]革新了映射的方式,建立了反向的映射(从文本到视觉,从低维到高维)来减轻Hubness 问题对结果的影响;但在文献[193]中证明了,Hubness 问题在低维空间中也会存在,因此这一解决方式并不彻底.
2)其二是基于原有模型增加流形正则化项.从上面的论述中可以看出,Hubness 问题更多是基于回归映射的模型所存在的本质问题,即映射会导致数据的判别性降低.因此,很多研究者[28,29,88,92,93,161]通过增加流形正则化项来保持数据的流形结构,进而保持数据的判别性.
3)其三是转换建模思路.有的研究者不使用基于回归映射的模型,转而通过生成伪样本,将零样本类的认知过程转化为一个标准的监督学习问题,从而也避免了Hubness 问题对结果的影响.但是伪样本也需要进行筛选以保证质量.
此外还有一些非主流的方式,例如,Dinu 等人[15]提出一种基于全局修正的近邻搜索方法而非最近邻搜索的零样本认知形式;在文献[155]中,Lazaridou 等人将岭回损失替换为Max-Margin Ranking Loss 来缓解Hubness问题.
3.2 模型总结
本文从数据知识的角度出发,依据知识的来源途径将知识的定义划分为“初级知识、抽象知识和外部知识”,并基于这样的划分方式将现有相关工作分为“基于初级知识的模型、基于抽象知识的模型以及引入外部知识的模型”.在每部分内容中,我们基于模型对该层次知识的利用方式,分别对其进行了梳理和归纳总结.更重要的是,这样的架构也有助于我们理解模型逐渐克服ZSL 中存在的各种问题的过程.基于本文第3.1 节针对问题的论述,我们对3 类模型进行了总结,并将它们总体表现出的优缺点呈现在表2 中,以便更好地看出ZSL 技术发展的脉络和趋势.
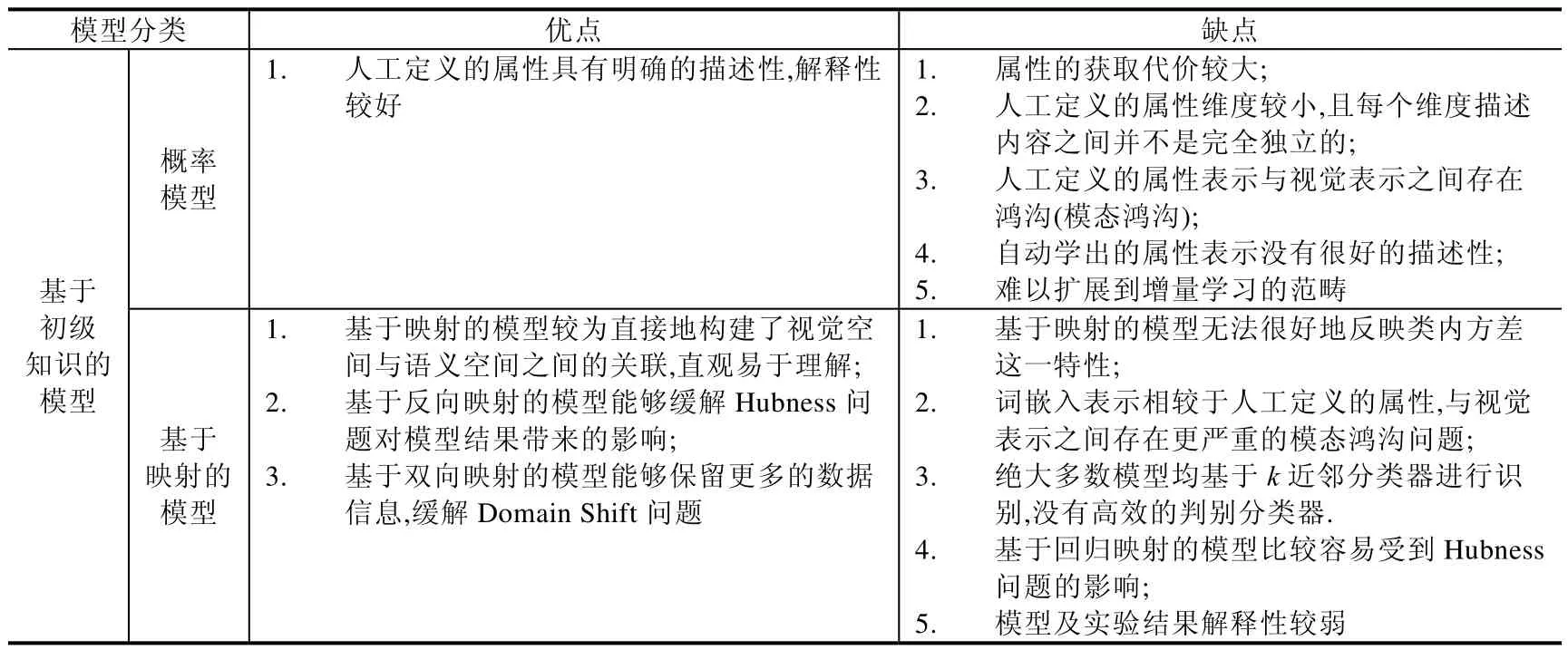
Table 2 Comparison of advantages and disadvantages in different zero-shot learning methods表2 零样本学习各类方法优缺点对比
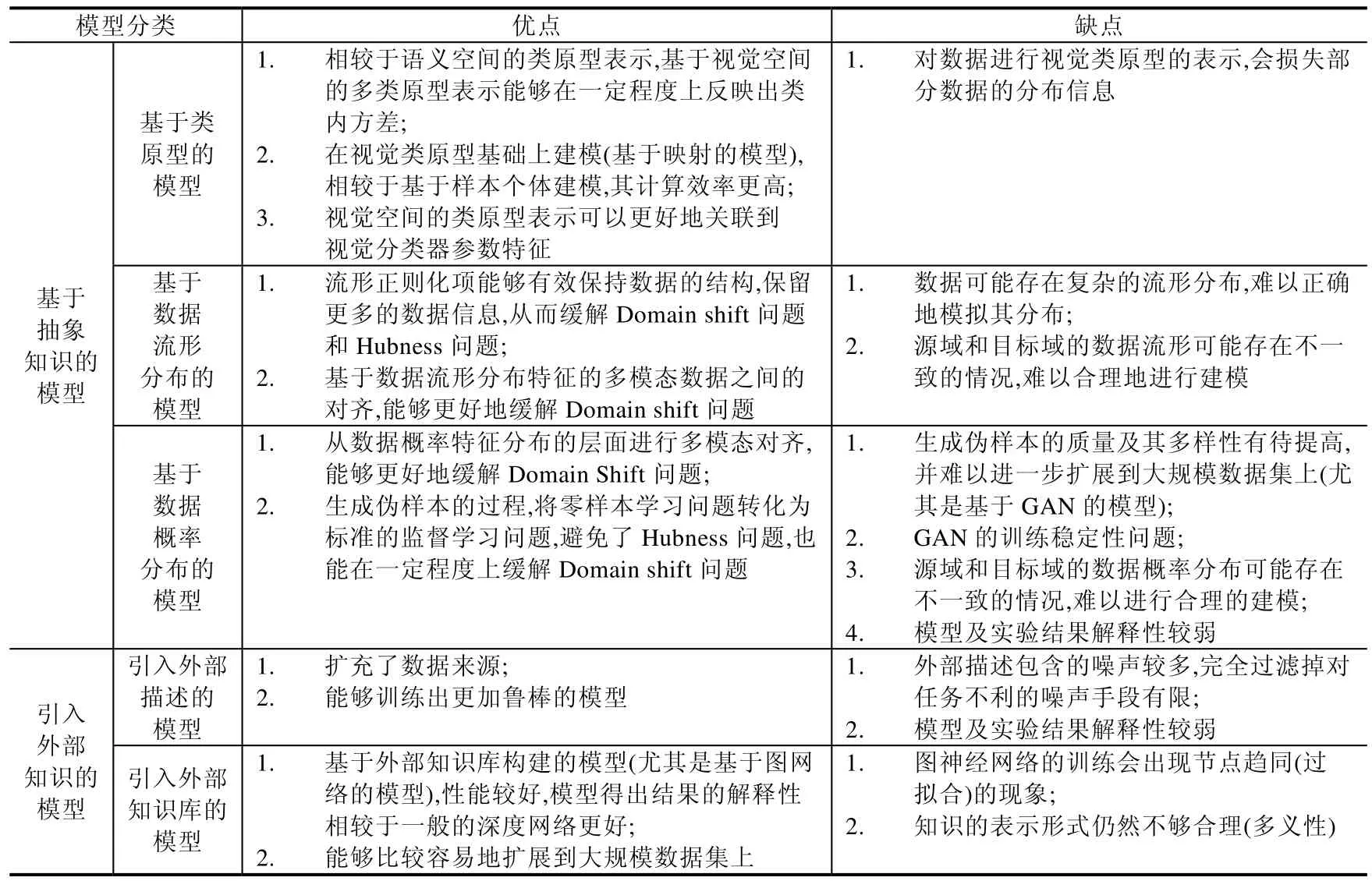
Table 2 Comparison of advantages and disadvantages in different zero-shot learning methods (Continued)表2 零样本学习各类模型优缺点对比(续)
4 数据集、评估标准和实验
由于在零样本学习领域,图像分类任务是主流,因此,本节将介绍零样本图像分类任务中的常用数据集,并且基于当前“数据+知识驱动”的背景,进一步介绍了基于外部知识库的模型中常用的知识图谱.最后,还介绍了ZSL 和GZSL 两个分类任务的评估标准.
4.1 常用数据集
绝大多数零样本图像分类模型所用的数据集包含了AWA(animal with attribute)数据集[33]、AWA2(animal with attribute 2)数据集[4]、CUB(Caltech-UCSD Birds-200-2011)数据集[194]、SUN(SUN attributes)数据集[195]、FLO(Oxford 102 flowers)数据集[196]和aPY(aPascal-aYahoo)数据集[134].上述6 个数据集属性见表3.

Table 3 Introduction of datasets (image classification) properties表3 数据集(图像分类任务领域)属性介绍
需要指出的是,AWA2 数据集是AWA 数据集版权到期之后该数据集的替代;CUB 数据集中的每幅图像都用Bounding Boxes 和Part Locations 进行了标注,并被用于细粒度的图像分类任务;SUN 数据集是用于细粒度场景分类的SUN 数据库[197]的一个子集;在FLO 数据集中,不同的研究者给出了每个类别不同的对应文本语义描述[166,198];aPY 数据集包含来自于PASCAL VOC 2008 数据集的20 个类别以及来自于Yahoo 的12 个类别.
除上述6 个通用的数据集外,ImageNet 数据集[199]也是目前零样本图像分类任务领域越来越广泛使用的大规模数据集.该数据集根据WordNet 的层次结构进行组织,因此ImageNet 数据集中的所有类都能在WordNet 中找到对应节点.完整的ImageNet数据集包含了大约22 000 个类别,超过1 500 万张标签高分辨率图像,由Amazon s Mechanical Turk (AMT)众包工具进行标记,被称为ImageNet 21k 数据集.该数据集存在较大的类别不均衡问题,因而是当前同类任务中最具挑战性的数据集.Xian 等人[4]的工作中,总结了前面具有代表性的方法在该数据集上的实验效果;最近的一些方法也同样在ImageNet 21k 数据集上进行了验证[4,103,130,131].其使用情况大致如下:首先,使用ImageNet 1k 进行模型的训练;然后,测试集分为3 个级别——2-hop,3-hop 和all,其中,2-hop 和3-hop分别是指在WordNet 中,距离ImageNet 1k 类对应节点2-hop/3-hop 距离的节点所对应类作为测试类,all 则代表了剩余的20k 的类别;除此之外,还有模型使用除ImageNet 1k 之外的剩余类别中最受欢迎的500/1k/5k 等类别,以及最不受欢迎的500/1k/5k 的类别进行测试.但在基于生成式模型的方法中(尤其是指基于GAN 的模型),由于其生成的伪样本质量不能得到充分的保证,因此向ImageNet 21k 这种大规模的数据集扩展仍具有较大困难.
由于ImageNet 21k 过于庞大,因此进一步衍生出了ImageNet 1k 数据集(ILSVRC),其包含1 000 个类别,每个类别大约有1 000 张图片.有的研究者使用该数据集来测试模型性能,例如,Yanan 等人[79]将ILSVRC 2012 数据分为800/200 类用于训练/测试;文献[61,86,102]则以ILSVRC 2012 的训练集为源域数据,并以ILSVRC 2012的测试部分和ILSVRC 2010 的数据(或者不与ILSVRC 2012 重合的ILSVRC 2010 类别)作为目标域数据等.但是显然,ImageNet 21k 是未来工作的主流.
4.2 常用知识库
· WordNet(知识图谱发展报告2018)
WordNet 是最著名的词典知识库,主要用于词义消歧,其表示框架主要定义了名词、动词、形容词和副词之间的语义关系,例如名词之间的上下位关系(如“猫科动物”是“猫”的上位词)、动词之间的蕴含关系(如“打鼾”蕴含着“睡眠”)等.在WordNet3.0 中,已经包含超过15 万个词和20 万个语义关系.在零样本任务领域,主要使用的是WordNet 知识库中的名词部分.在这部分内容中,有别于通常意义上的字典,WordNet 知识库根据词条的意义将其分组,每一个具有相同意义的字条组称为一个Synset(同义词集合),WordNet 为每一个Synset 提供了简短、概要的定义,并记录不同Synset 之间的语义关系.这些语义关系通过一个层次化树状结构组织起来,并且图中节点之间的距离(JC 距离)大致可以反映出视觉上的相似性程度[133].由于WordNet 与ImageNet 数据集的紧密关系,WordNet 知识库成为视觉任务,尤其是图像分类任务领域的常用知识库.
· ConceptNet[121,122]
ConceptNet 是常识知识库,是具有代表性大规模网络知识获取的工作,最早源于MIT 媒体实验室的Open Mind CommonSense(OMCS)项目.ConceptNet 知识库以三元组形式的关系型知识构成,比较侧重于词与词之间的关系.从这个角度看,ConceptNe 更加接近WordNet,但是又比WordNet 所包含的关系类型多.ConceptNet5 的知识表示框架主要包含如下要素:概念Concepts、词Words、短语Phrases、断言Assertions、关系Relations、边Edges.Concepts 由Words 或Phrases 组成,构成了图谱中的节点.与其他知识图谱的节点不同,这些Concepts 通常是从自然语言文本中提取出来的,更加接近于自然语言描述,而不是形式化的命名.Assertions 描述了Concepts之间的关系,类似于RDF 中的Statements.Edges 类似于RDF 中的Property.ConceptNet5.5 中已经包含了超过2 100 万个关系描述和800 万个节点(英语部分包含了大约150 万个节点),其中包含了21 个预定义的、多语言通用的关系(如IsA、UsedFor 等)和从自然语言文本中抽取的更加接近于自然语言描述的非形式化的关系(如on top of,caused by 等).在文献[31,129]中,研究者选取其英文表述的概念,并且NUSWIDE 数据集和ConceptNet之间存在92 595 个共享标签(包含words 和phrases 在内),因此也能较方便地用于视觉任务.
· NeLL[189]
该知识库由卡内基梅隆大学开发,是具有代表性的大规模网络知识获取的工作.和ConceptNet 类似,也是遵循RDF 数据模型的形式.其已经抽取了大约170 万种物体实体、240 万条边.文献[130]中,将其和NEIL[190](包含超过1 700 条关系和超过40 万的视觉个体)一起,构建了新的知识图谱来进行零样本认知的任务,
以上介绍的知识库包含了海量的各种人类先验知识,但是对于特定任务而言,任务不相关信息属于噪声.因此,研究者在构建基于这类知识库的模型时,通常需要根据具体任务来对初始的知识库进行适当的筛选和改造.
4.3 常用任务评估标准
在单标签的零样本图像分类任务中,通常使用Top-1 准确率来进行模型性能的度量.Top-1 准确率的定义为:预测概率最大的标签与真实标签相符的准确率(即每个测试类中正确标记的实例的比例).由于测试涉及到多个类的Top-1 准确率,因此要进一步对所有的测试类求平均精确值.其公式定义如下:

其中,|y|表示类别数.在传统的ZSL 设定下,|y|的范畴仅包含目标域的类别,但在GZSL 的设定下,|y|的范畴进一步包含了源域的类别.因此在这种设定条件下,通过计算源域类和目标域类的Top-1 精确度的调和平均值(该均值更加强调较小的一方的重要性,因为模型最终需要在源域和目标域均取得较高的精确值)来进行模型性能的度量,其公式表示如下:

其中,accytr表示源域的平均Top-1 精确值,accyte表示目标域的平均Top-1 精确值.
在多标签的零样本图像分类任务中[132],使用Precision(P),Recall(R)和F1-measure来进行模型性能的度量.接下来,通过一个例子来说明这3 个性能度量标准的含义.假定模型通过预测,给出了某个图像的最终预测标签集合,其中有TP(true positive)个确实为图像的标签并被正确判定;有FN(false negative)个确实为图像的标签,但没有被正确判定,即在预测集合中没有出现;有FP(false positive)个不属于图像的标签,但被错误判定为其标签,即出现在预测集合中;最后有TN(true negative)个本来不属于图像的标签,也没有出现在预测标签集合中.基于上面的统计,这张图像对应的精确率(precision)和召回率(recall)的计算方式如下:

从上面的两个计算结果中我们可以看出:精确率度量的是给出的标签预测中有多少是正确的,召回率度量的是模型正确召回了多少个正例.接下来,基于与GZSL 任务中调和平均数相同的考虑,计算精确率和召回率的调和平均数来得出模型的F1 均值,其公式表示如下:

这即为多标签图像分类任务的评估标准.
4.4 实 验
本节在前面第2 节的模型梳理工作基础上,并结合文献[4]中实验部分的工作,从每个类别的方法中分别抽取了1~2 个较新的模型来展示其实验结果,并在部分研究者们公布的源代码(COSMO[156],https://github.com/yuvalatzmon/COSMO;RKT[151],https://github.com/LiangjunFeng/Implement-of-ZSL-algorithms;文献[68],https://github.com/lzrobots/DeepEmbeddingModel_ZSL;EXEM[89],https://github.com/pujols/Zero-shot-learning-journal;BMVSc[77],https://github.com/raywzy/VSC;ListGAN[83],https://github.com/lijin118/LisGAN;ADGPM[131],https://github.com/cyvius96/DGP;CADA-VAE[103],https://github.com/edgarschnfld/CADA-VAE-PyTorch;GCNZ[131],https://github.com/JudyYe/zero-shot-gcn)基础上对相关模型进行了验证(未公布源码的模型均根据作者文中描述进行实现),算法运行平台为GPU TITAN Xp×2,显存为12×2GB.在表4 中,从上到下的模型类别依次为基于属性迁移、正向映射、反向映射、双向映射、共同映射、其他映射、视觉类原型、数据流形分布、数据概率分布、引入外部描述、引入外部知识库的模型,依次对应了表4 中第1、2-3、4-5、6、7、8-10、11、12、13-18、19、20个模型.表5 则为对应模型在GZSL 中的实验结果.需要指出的是,表格中带*号的是直推式的模型,字体加粗的模型则打破了“样本级别,源域目标域数据分布一致”潜在假设.需要注意的是,表4 和表5 中‘SS’和‘PS’的定义与文献[4]保持一致,分别表示传统的数据集分割标准和新提出的数据集分割标准.后者在一定程度上防止了预训练增益,使得在该标准下的实验结果更具科学性.而表5 中ts、tr、H 分别表示模型在GZSL 任务中,目标域类别、源域类别的实验效果以及前两者的调和平均数.
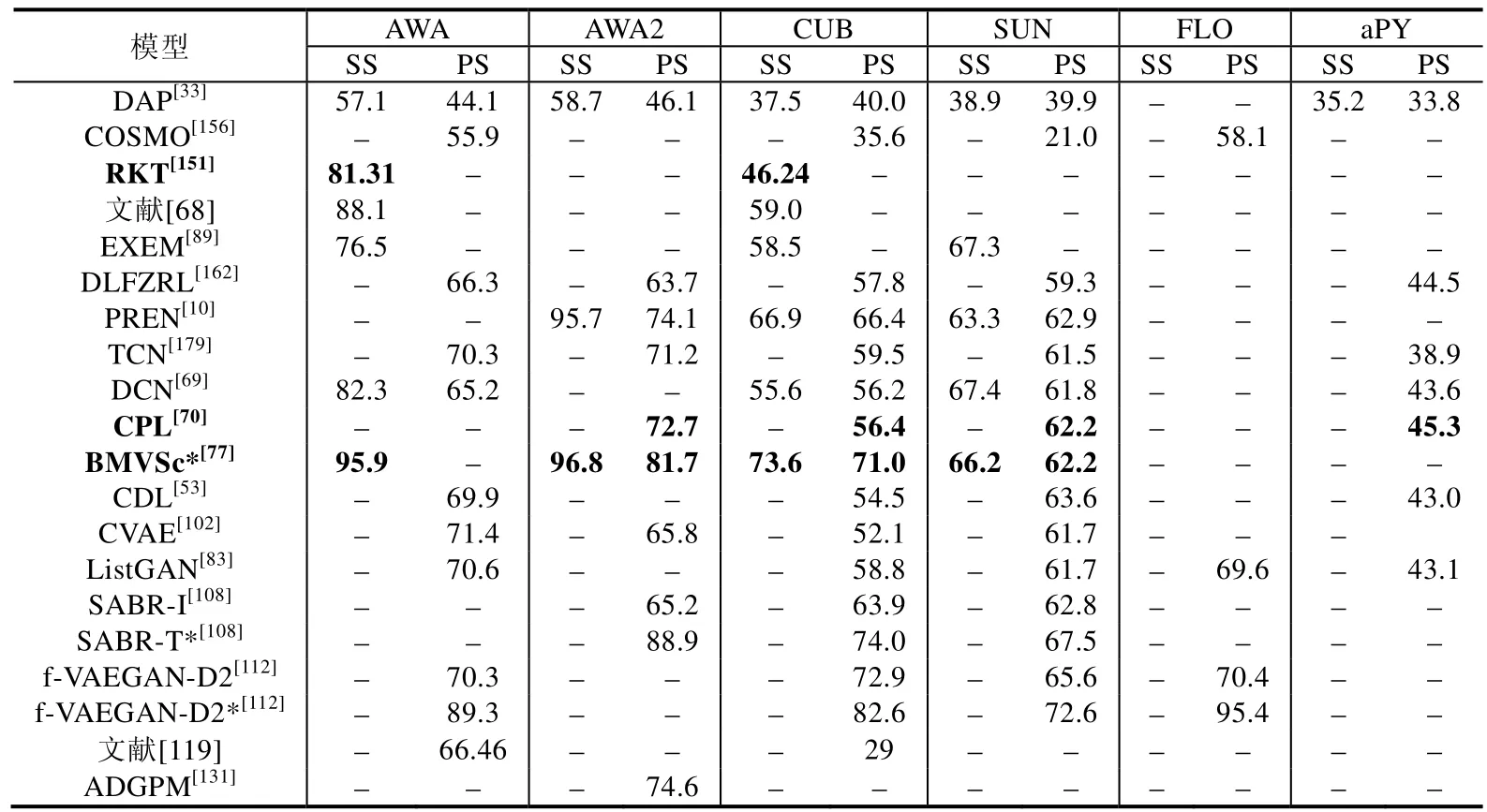
Table 4 Traditional ZSL experiments of different models on various datasets,measuring top-1 accuracy (%)表4 在不同数据集中,各个模型在传统ZSL 任务中的Top-1 准确率(%)
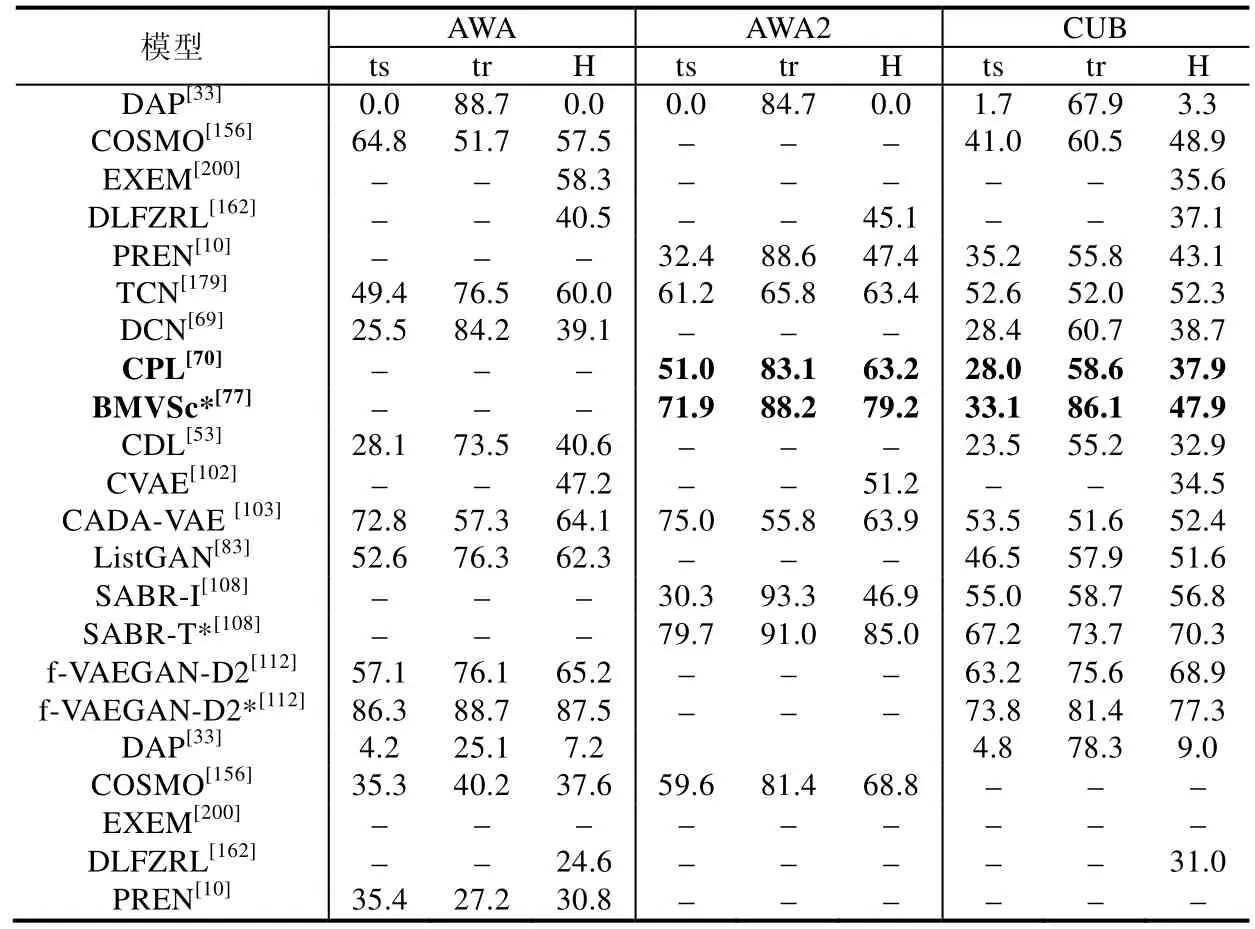
Table 5 GZSL experiments of different models on various datasets,measuring top-1 accuracy (%)表5 在不同数据集中,各个模型在GZSL 任务中的Top-1 准确率(%)
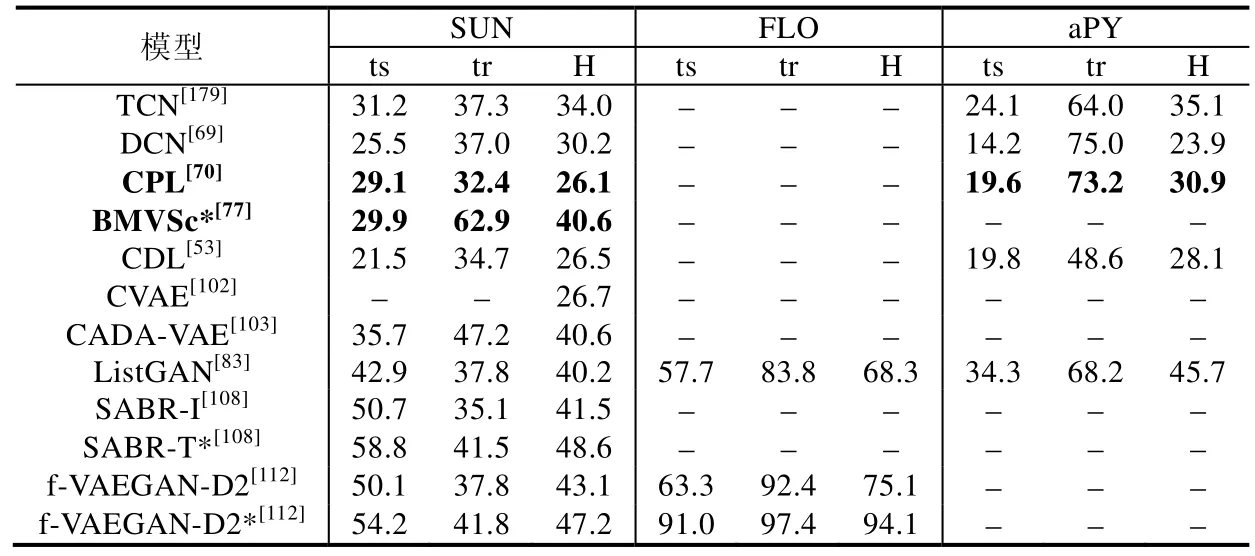
Table 5 GZSL experiments of different models on various datasets,measuring top-1 accuracy (%) (Continued)表5 在不同数据集中,各个模型在GZSL 任务中的Top-1 准确率(%)(续)
总体上来看:从初级知识到抽象知识的发展过程中,各类模型的识别准确率是不断上升的.这是因为抽象层次的知识相比于初级知识更加接近数据分布的本质.以常用的AWA 数据集为例,通过分析表4 和表5,我们能够印证本文第3 节得出的一些结论.
(1) 从模型本身结构的角度来看,在基于初级知识的模型中,基于映射的模型是已有方法的主流.针对领域内问题从而对映射方式所做的改进,使得模型效果也在不断提升.从表4 中我们可以看出,反向映射、双向映射和共同映射以及其他方式的映射确实能对模型效果提升带来较大促进作用,因为他们相对于正向映射建立了更加鲁棒的映射关系.这一点我们从表4 的ZSL 任务中(从第2 类方法到第6类方法)可以明显看出:相对于正向映射,平均提升效果20.3%.而在基于抽象知识的模型中,依赖于生成式模型的强大拟合能力,能够挖掘出数据的内在分布规律,因此,基于数据概率分布的模型普遍取得了更好的实验效果.相较于基于映射的模型,平均提升效果17.0%.从表4 和表5 中可以看出,基于GAN 的模型相比于基于VAE 的模型普遍效果更好(例如ListGAN 和CVAE 相比,提升效果31.9%).这是因为基于GAN 的模型生成伪样本的能力更强,这类方法将成为今后的主流.
(2) 从数据利用的角度来看,在训练过程中融入不可见类的数据,即将模型由归纳式改造为直推式,往往是能够提升模型识别不可见类精度的最简单有效的方法,这从表4 同一个模型(例如SABR 和f-VAEGAN-D2)的对比中可以看出.以f-VAEGAN-D2 为例,平均提升效果27.0%.由于直推式模型的参数更具泛化性,这类模型在GZSL 任务下也取得了不错的效果,这从表5 对应模型的效果可以看出.仍以f-VAEGAN-D2 为例,平均提升效果34.2%.
(3) 从打破潜在假设的角度来看,这类模型(表格中字体加粗的模型:RKT,CPL 和BMVSc*)大致保持了已有工作实验效果,但能够使得模型的应用场景更加贴近实际.
在引入外部知识的模型中,表4 中文献[119]的模型实验效果表明了:挖掘外部描述来替代人工标注语义的模型,经过噪声抑制等措施的处理,同样也能实现较好的效果.而引入外部知识库的模型,借助现有的知识图谱,其最大的优势在于可以方便地扩展到大规模的数据集中,实验效果见表6.

Table 6 Experiments of different models on ImageNet21k,measuring top-1 accuracy (%)表6 各个模型在ImageNet21k 数据集中的Top-1 准确率(%)
表6 中的1K、2H、3H 和ALL 分别表示训练集包含的1 000 个类别、以训练集为核心的2-hop 距离的类别(借助相关KG 的显式关系)、以训练集为核心的3-hop 距离的类别、除训练集之外的所有类别.从中我们可以看到:GCNZ 和ADGPM 这种引入了KG 的模型,效果相较于之前的传统方法(EXEM 模型)均有较大的提升,效果平均提升84.4%,充分说明了引入外部知识的有效性和必要性.
5 挑战与展望
· 预训练增益
随着深度网络架构的成熟,很多模型直接利用预训练好的CNN 网络来进行目标数据集中样本视觉特征的提取.但如果预训练CNN 的数据类别与目标数据集中不可见类部分有重叠,那么就会给零样本模型对不可见类数据的识别效果带来某些提升(增益),因此在Xian 等人[4]的工作中,对现有的数据集进行了重新划分(PS 的划分方法),来避免这种情况的发生.也可以通过使用目标数据集中的可见类对预训练好的CNN 进行微调来避免预训练增益情况的发生[112].但是,如何更好地防止增益效果对实验结果的影响,这是未来研究中需要注意的问题.
· 大数据集的挑战
ImageNet 21k 数据集,其庞大的数据规模中存在着较大的类别不均衡问题,是当前零样本图像分类任务中最具挑战性的数据集.文献[4]中对之前代表性的方法进行了集中的验证,近期工作也有少量模型在该数据集上进行了验证[89,103,112,130,131,200].在未来工作中,需要将这个数据集作为衡量零样本图像分类模型性能的基准.
· 伪样本的生成
利用生成式模型建模,在近两三年变得火热.生成更好的伪样本,有利于使用更少的数据来更快地确定准确的分类边界.但是如何生成质量更高的伪样本,这是生成式的方法面临的主要问题之一.基于Wang 等人[8]工作中的表述,伪样本的生成应该有3 个标准:真实性、有效性和多样性.其中,真实性是指生成的伪样本在视觉上要尽可能地接近真实的样本;有效性是指生成的目标类伪样本需要有利于目标类分类器的训练;多样性是指生成的某个类的伪样本,其类内方差要尽可能地大一些,更具有判别性.由于在ZSL 领域,生成式模型是基于样本的高级特征来进行操作的,因此生成伪样本的真实性则更加适合于文本生成图像[187]等任务.而伪样本有效性方面需要优先进行考虑,通过在生成模型中引入条件,然后进行伪样本置信度筛选[83,104]等操作,伪样本的有效性有了较大的提升.在此基础上,增加生成伪样本的多样性,以更好地确定分类边界,是当前该类模型面临的挑战.文献[83,90]均通过类原型修正来提升所生成伪样本的多样性和区分性.同时,生成式模型生成伪样本的能力是有限的,如何将生成式模型进一步扩展到大规模数据集中(如ImageNet21k),也是一个值得思考的问题.
· 模型的可解释性
深度网络的可解释性是近期比较热门的话题,但这里所指的可解释性是指从视觉角度出发,去阐述模型在进行零样本认知时的视觉依据,是一种弱可解释性.Xian 等人[112]的工作已对此进行了尝试.在未来的工作中,如何进一步扩展视觉可解释性的功能,甚至利用视觉层面的解释性来反馈辅助模型的训练,也是未来面临的挑战.
· 多义性
这一问题特指在词嵌入过程中发生的问题,即在词嵌入过程中,出现的一个词嵌入对应多个名词表示的现象.放在知识库中,即转化为“一个词嵌入对应多个图节点的表示”.在WordNet 知识库中存在大量的这种现象(例如上下义词共享词嵌入表示),这是由于知识库的粒度和词嵌入表示的粒度不对等造成的.因此,这一问题更多是与知识表示是否合理有关.而多义性的存在是否会影响引入外部知识库的零样本模型性能,这也需要进行深入的探究.
6 结束语
在计算机视觉领域,由于数据爆发式增长带来信息标注成本高昂的问题,零样本学习越来越受到人们的重视.而随着“数据+知识驱动”这一理念深入到深度学习的各个领域,零样本学习也进入到新的发展阶段.本文针对当前对于“知识”这一概念并无统一表述的问题,对零样本学习领域所使用的知识进行了总结和归纳,从模型所使用的不同层次知识的角度出发,梳理了已有视觉相关的零样本学习工作(主要聚焦于零样本图像分类任务);接着阐述了本研究领域的现存挑战,并基于存在挑战对已有工作进行了优缺点归纳;然后介绍了领域内常用数据、评估标准、实验分析;最后对未来工作进行了展望.本文的角度有助于人们理解零样本学习中的3 大关键问题:如何更好地挖掘已知类的知识、如何更好地将获取的知识用于对未知类的认知中以及怎样合理地使用先验知识.
