下一代网络处理器及应用综述*
2021-03-06赵玉宇刘旭辉
赵玉宇 ,程 光 ,刘旭辉 ,袁 帅 ,唐 路
1(东南大学 网络空间安全学院,江苏 南京 211189)
2(教育部计算机网络和信息集成重点实验室(东南大学),江苏 南京 211189)
3(湖南华芯通网络科技有限公司,湖南 长沙 410000)
自21 世纪以来,人类已经不再满足于只运用互联网进行简单的信息交互.随着终端设备的智能化,互联网承载的任务变得复杂多样.这种发展一方面提高了人类社会生产生活的效率,为人们带来了很大的便利以及好处,但另一方面,也加重了互联网中以路由器、交换机为主的各项基础设施的压力.尤其是在约束了特定服务质量(quality of service,简称QoS)的情况下,网络设备处理速度随着CPU 利用率的增高而下降,使得网络传输效率降低,用户体验较差.当代互联网的发展,要求网络设备拥有强大的计算和存储能力,以便满足复杂网络环境以及特定任务.随着互联网用户需求的不断革新,人们对网络设备的可编程能力也提出了更高的要求.
网络处理器(network processor,简称NP)就是为网络设备提供计算能力的核心器件.它是一种能够完成路由查找、协议分类、报文处理以及防火墙和QoS 等各种任务的通信网络芯片[1].当前的部分网络处理器具备了一定的可编程性,能够灵活地应对管理人员希望使能的功能需求.在计算能力方面,拥有多个微码处理器和硬件协处理器的NP 能够对内存操作、路由表查找算法、拥塞控制以及主动队列管理进行一些标准操作.在下一代网络体系结构的提出与应用以及终端计算能力变强等硬件设备革新的技术潮流下,现有NP 由于设计缺陷和人为疏漏,未能很好地兼顾灵活性和高性能,使得网络设备的能力始终滞后,无法满足未来网络通信设备应用场景的迫切需求.所以,网络处理器的研究设计始终是网络与通信方面的热点问题,其研究层次逐渐提高.由于中兴通讯股份有限公司(下文简称为中兴)、华为技术有限公司(下文简称为华为)等中国先进通信设备制造商接连遭受美国制裁或者禁运,无法获得NP 芯片技术,网络处理器的国产化也成为国内业界学术界面临的紧急任务.
为了能够自适应地满足高性能和灵活应用场景的各项要求,使NP 拥有多样化分组处理以及超高带宽的体系结构[2],下一代网络处理器(next generation network processor,简称NGNP)成为NP 研究与设计的热点.NGNP的设计核心思想是:在灵活性上拥有良好的可编程性,尽可能地满足高级语言编程;针对不断涌现的新业务,能够减少部署时间,提高效率;在性能上,能够利用加速引擎或者体系结构优势优化处理流程、处理时间;同时,在能耗、芯片尺寸上尽可能地轻量化,降低成本的同时,提高网络设备的综合能力(见表1).

Table 1 Comparison between next generation network processor and traditional network processor表1 下一代网络处理器与传统网络处理器对比
下一代网络处理器是一种借鉴新型可编程技术、面向新型网络体系结构或新型应用的设计理念和目标,并不是指某一种具体的芯片设计.当前,在NGNP 设计目的指引下,国际国内的很多研究者进行了大量的研究工作.下一代网络处理器的各项内在设计关键技术也随着新型网络体系结构、可编程技术以及在网络环境复杂多变的高性能业务引导下进行革新和发展.学术界主要是提供NGNP 的体系结构以及关键技术研究,产生了很多新的NP 体系结构,也在协处理器设计上进行了突破,使其能够满足某一特定新型业务如优化数据转发、新型拥塞控制方法等.工业界则根据原有NP 迭代更新产品,定向提高了芯片内CPU 计算能力,或者加大带宽以满足当前应用需求.自2010 年以来,有部分学者进行了NGNP 技术的相关分析和研究,但审视现在已经公开发表的包括科技论文和专利等资料,其中大部分只是介绍和阐述NP 的特定新应用、新架构.国内外对下一代网络体系结构技术的分析和研究不够全面和深入,并且基本没有对NGNP 的综述性的学术著作出现.2010 年,Albrecht 和Carsten 等人[3]发表专著,介绍了一种利用动态可重构的协处理DynaCORE,以增加NP 相关负载功能,但是该书没有宏观地提炼NGNP 的相关体系结构.2016 年,Gadre、Geetanjaliy 以及Matthews 等人[4,5]系统性地提出了利用精简指令集计算机(reduced instruction set computing,简称RISC)处理器作为高速网络接口的NP 结构,但是该文献注重技术细节的阐述,针对新型网络体系结构下的NP 设计分析简单,主要还是面向NP 灵活性进行体系结构的技术更新,也缺少其他同类NP 体系结构设计的分析比对.
下一代网络处理器包括设备功能模块、体系结构、外围支撑以及协议与平台等内在关键技术,都是围绕新型网络架构技术及应用进行研究与设计.因此,本综述尝试对下一代网络处理器的关键技术设计研究进行全面的总结与归纳,按照利用新型可编程技术、面向新型网络体系结构、针对新型高性能业务的3 类下一代网络处理器设计方法进行阐述.提出了下一代网络处理器发展的挑战,设计了一种下一代高性能可演进的网络处理器体系架构,实现了原型系统并对其进行了测试.
本文第1 节介绍网络处理器的基本概念与面临的挑战.第2 节~第4 节按照3 类方法分类阐述下一代网络处理器设计的主要指导思想.第6 节提出下一代网络处理器的发展方向,并介绍一种高性能可演进的下一代网络处理器体系架构与实现方法.第7 节对全文的工作进行总结.
1 网络处理器基本概念
1.1 网络处理器基本架构
网络处理器由多个处理器内核构成[6],一般地,这些内核分为处理单元(processing element,简称PE)、协处理单元(co-processor,简称CoP)以及硬件逻辑管控单元(hardware logic block,简称HLB).以上单元的配置方式、指令集设计、共享资源访问策略以及调度方法一般有两种处理机制,处理机制的不同,导致网络处理器的硬件逻辑结构不同:一种是流水线方式,如图1 所示的Yang 等学者[7]提出的一种经典网络分组处理操作流程,各单元利用处理引擎无关的特点,通过流水线实现系统指令并行处理,完成分组相关操作;另一种是并行处理方式,由于使用并行处理要频繁地对分组状态进行更新,利用存储表格维护其状态,所需要的计算资源相对较多,采用并行处理的时机非常重要,使得每个处理单元完成相似的任务.并行处理架构使用HLB 和PE 集群关联,利用PE 间并行、PE 内部并行或者PE 和CoP 并行方式提高处理器效率.
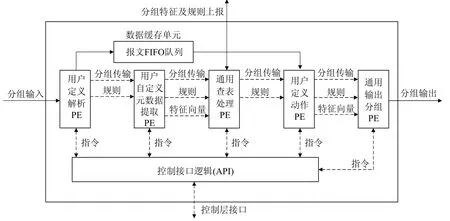
Fig.1 Pipeline structure of network processor图1 网络处理器流水线编排结构
学者谭章熹等人[8]认为,网络处理器本身必须具备以下5 点要求:(1) 拥有网络分组并行处理能力;(2) 具有高效的处理速度,能够达到分组的实时处理;(3) 拥有一定数目的网络专用协处理器;(4) 具有高度的可编程性和扩展性;(5) 能够快速投向市场,尽量减小再开发周期.
在这种条件下,除了拥有可靠的硬件架构外,网络处理器芯片内的各PE 上需要执行相关程序进行单元间通信和转发表、提取元数据等操作.依据不同的网络处理任务,软件系统分为控制层面和数据层面:控制面搭载网络协议栈以及实时操作系统等进行管理和策略控制;数据层面包括控制程序、管理程序和转发程序等完成对数据的高速和定制化处理.
1.2 网络处理器发展以及挑战
网络处理器作为一种支持各项网络协议实现的特殊处理器,它具备一定的可编程性保证部分工作所需功能的动态加入[9].网络处理器问世于1999 年,并即刻被网络设备厂商和半导体公司投资制作.随着学术界和业界对网络处理器的重视,不同体系结构、不同应用场景的网络处理器也相继出现.
作为推动下一代网络向灵活性和高性能结合的关键技术,新型网络处理器的体系结构研究首先成为了该领域的热点问题[10].为了使得网络处理器更具备灵活性,以便对新型业务进行处理,中间网络设备开始不仅仅满足于基本的转发和查表操作.各类基于新型网络处理器体系架构的QoS 路由器相继出现,如基于DifferServ[11]的VERA(virtual extensible router architecture,虚拟可扩展路由器体系结构)可扩充路由器.这些设备主要关注可扩展性和灵活性,稍微兼顾了效率.随着对QoS 控制策略的不断深入研究,网络处理器架构设计逐渐偏向可重点支持某一特定需求的协处理器设计[12].协处理器利用自身计算性能,增加了网络处理器针对特定应用的处理效率.当然,协处理器一定意义上拖累了网络处理器的灵活性,针对协处理器而设计的流水线或者体系架构更改成本较高.
为了解决上述问题,也随着网络环境的日益复杂,近年来,硬件领域以及编程语言的发展红利也逐渐映射到网络处理器研究上来.ASIC(application specific integrated circuit,专用集成电路)作为网络处理设备的初始应用芯片,在应用领域逐渐广泛并趋于灵活的网络市场上逐渐不被人满意.更多的半定制化芯片,如FPGA(field programmable gate array,现场可编程逻辑门阵列)应用到了网络处理器设计中[13].网络处理器应用开发难度也影响着其灵活性利用新型的可编程技术,简化网络处理器设计的方式方法也成为研究热点.
网络处理器的发展也面临着对应的挑战.面向新型的网络体系结构,从数据网到电信网、从接入层到骨干层,网络处理器开始被广泛开展研究以及应用.随着需求的推动和技术间的交叉融合,网络处理器在平衡高速、灵活特性上逐渐出现矛盾[14].随着通用性强、开发环境友好、软硬件融合度高等设计理念都逐渐泛化为数据处理技术从而成为潮流,网络处理器面临着从交换、路由、网络融合与演进等传统业务拓展到适应新型体系结构、满足特殊需求型业务甚至应用于终端领域的重大挑战.
在这种大背景下,将网络处理器的“高性能”“高灵活”结合的研究局面出现,下一代网络处理器设计成为了研究热点.下一代网络处理器的核心设计方法是结合应用场景,将分组处理与转发的高性能和可编程、可演进的灵活性进行结合,使得其能够在自身资源属性的限制下,完成可定制、可重构的,并且提高搭载网络处理器设备的效率、可编程性、鲁棒性和安全性.目前,网络处理器的“下一代”设计思路主要体现在3 个方面:利用新型可编程技术的下一代网络处理器、面向新型网络体系结构的下一代网络处理器、针对新型高性能业务的下一代网络处理器.具体的分类框架如图2 所示.同时,为了使下一代网络处理器更具有有效性和可用性,工业界开始针对新型设计方法进行产品化、原型系统化的输出,本文也将会介绍这一部分内容.
本文将重点关注下一代网络处理器设计思想和体系结构,将这些虽然没有量产但是实现原型系统的网络处理器进行体系化的整理、介绍以及对比.
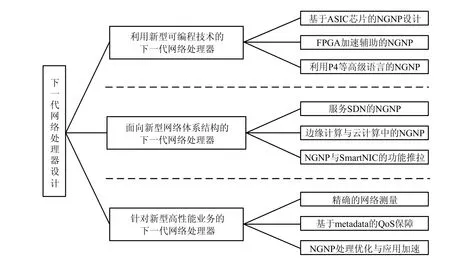
Fig.2 Classification framework of next generation network processor design methods图2 下一代网络处理器设计方法分类框架
2 利用新型可编程技术的下一代网络处理器
网络处理器的灵活性依赖于两点:芯片的可编程性以及平台编程语言的交互难度和编写难度.芯片作为一个集成电路的载体,因其特有的体积小、重量轻、处理速度快等优势,得以在各项工业制造中广泛应用.可编程技术在不同的硬件上有不同的体现方式,由用户在使用中通过计算机指令选择不同通道和电路功能进行编程实现[15].网络处理设备利用可编程芯片的起源较早,从开始的单片机到ASIC、FPGA 等,除了处理网络协议,还可以扩大转发表,满足高性能需求.网络处理器作为一种特殊器件,其借鉴不同可编程芯片架构的融合开发,是下一代网络处理器原型的重点方向.在当前对中间网络设备处理需求多样、复杂的情况下,对芯片编程的语言可操作性,成为了评判网络处理器灵活性的一个重要方式.硬件描述语言随着EDA(electronic design automation,电子设计自动化)技术的发展成为一种趋势.目前,最主要的硬件描述语言是VHDL 和在C 语言的基础上发展起来的Verilog HDL.两者语法相对严格,主要关注数字电路和系统的设计与描述,功能虽然覆盖网络处理但是针对性不够,编写编译复杂.斯坦福大学的McKeown 教授[16]于2014 年设计并提出了数据平面特定领域编程语言P4,充分发挥了网络处理中数据平面的编程能力,也为网络处理器的设计提供了新的思路.
2.1 基于ASIC芯片的NGNP设计
网络处理器设计之初,ASIC,FPGA 以及NP 作为不同的架构都可以搭载在路由器上,学术界也开始争论这几种芯片架构对交换机等设备的适用性.拥有不同特点的3 种芯片的相互融合借鉴,是下一代网络处理器的设计潮流.2013 年,Teubner 和Woods 编写了利用可编程门阵列FPGA 进行网络数据处理的专著[17],该书主要关注了网络处理器的硬件系统的可编程性,对利用FPGA 进行网络数据流的处理进行了系统化的整理和指导,讨论了基于ASIC 芯片对网络处理器的设计影响.
自2005 年开始,3 种芯片的架构融合设计潮流兴起.David 和Taylor 等人[18]探讨了利用FPGA 和ASIC 等芯片形式,用以硬件辅助设计权衡的健壮的报头压缩(robust header compression,简称ROHC)方法.ROHC 在网络处理器上实现,并为分组交换网络中的无线通信提供更有效的无线链路使用.Renterghem 等人[19]研究了一种适合以太网接入节点的网络处理器,借鉴ASIC 数据包处理器设计方法,通过多个处理器在多核环境下并行运行,并达到10gbit/s 的以太网速率.该处理器有一个优化的体系结构来处理流处理任务,如解析、分类和包操作.VLIW(very long instruction word,超长指令字)指令集允许ASIP(application specific instruction set processor,专用指令集处理器)内部各功能单元之间的高度并行,并有专用指令来加速典型的包处理任务.当然,上述两点研究没有考虑可编程性,无法灵活更新任务.来自开罗大学的Suleiman 等学者[20]介绍了一种利用ASIC 设计的嵌入式应用的低功耗、中性能网络处理器,它的典型时钟频率为 260MHz,功耗为 0.11mW/MHz,功率效率为8.78dMIPS/mW,这使得它非常适合嵌入式和实时系统.但是实验验证,其处理性能不高.Yoon 等人[21]提出了由多核处理器实现的一种适用于未来互联网和需要多层协议处理的高端网络服务的全流系统(OmniFlow system).作为一个基于流的网络处理器,使用了65nmCOMS(complementary metal oxide semiconductor,互补金属氧化物半导体)技术,它包含40 个处理核,并利用ASIC 实现.OmniFlow system 可通过两个SPI-4.2s 处理传入的包,并拥有40Gb/s 包转发可编程引擎.文中也指出,该方法包含较多处理器核,如何进行并行调度也是未来的研究重点.
2.2 FPGA加速辅助的NGNP设计
Zhang 等学者[22]提出了一种基于FPGA 的高速OBS(optical burst switch,光突发交换)核心节点BCP 网络处理器,并提出了一种新的有效的波长调度算法.它不仅在调度有效波长时具有较高的带宽利用率,而且调度时间更短.当系统时钟为200MHz 时,BCP 只需180ns 的处理时间:约50ns 用于调度有效波长,130ns 用于核心节点的其他问题.上述方法针对业务较为普通,获得高带宽后,面对拥塞情况没考虑.在用于特定业务的网络处理器方面,Niu 等人[23]提出了一种基于FPGA 的可配置的IPSec 处理器,其本质是高性能在线网络安全处理器.它由两个嵌入式32 位CPU 核和一个SoC 上的IPSec 协议处理器构成,4 个并行AH,ESP,AES,HMAC-SHA-1ip 核分别连接到IPSec 处理器中的8×8 交叉开关上,实现了200MHz 时1.5Gb/s 的吞吐率.虽然关注点是网络安全,但是进行网络流量可视化难度较高.Veeraprathap 等人[24]介绍了一种基于FPGA 的网络处理器设计与实现,它是一种可扩展的分组交换结构,具有存储转发、错误管理、电源管理和安全等先进的网络功能.它不仅具有数据包化/去封装化、频率转换、数据大小转换等基本功能,还具有有限电路复杂度和较低的成本.然而,该方法在灵活性上的体现还是基于设计时的应用下发,没有考虑任务热部署,无法实现除预设能力外的更多功能.
由于预测网络流量以每年大约60%的速率快速增长,因此迫切需要在NGNP 上利用其他成熟芯片原理降低功耗.Roy[25]讨论了3 种减轻NP 功耗的技术:异构多核架构、通用功能的硬件加速和非对称扩展技术.Shamani 等人[26]介绍了一种基于FPGA 的网络处理器的COFFEE RISC(reduced instruction set computing,精简指令集计算机)协处理器,它能够通过控制器局域网(controller area network,简称CAN)协议与外围设备通信.此外,核心和协处理器之间的数据传输在主数据总线上不引入任何工作负载,减少耗能的同时,最大可达825MHz的最大工作频率.上述方法由于性能上受限于设计架构,很难满足当代网络业务的高性能需求
利用FPGA 进行灵活与性能优化的NP 研究方面,Gadre 等人[27]提出了一种利用RISC 处理器作为高速网络接口的、基于FPGA 实现的网络处理器,其使用RISC 处理器作为网络处理器的专有高速网络接口卡.这种NP 可以进行多线程协议处理.文章还解释了在确定了完整的设计规范并在硬件上实现了整个设计之后,支持新协议所涉及的增量变化以及调试复杂协议处理和纠正协议实现错误所需的调试策略.Li 等人[28]的文章介绍了一种基于FPGA 加速平台的高柔性和高性能的ClickNP,该处理器灵活性高,可以服务基于高级C 类语言的可编程点击模块化路由器.其原型拥有每秒高达2 亿个包的流量处理速度,并且具有低于2μs 延迟.该方法由于设计性能要求高,加载策略过多,导致芯片产业化过于困难.
打破传统的芯片体系结构,将多种芯片优点混合设计进行网络处理芯片开发,成为2018 年之后的主要研究热点.Zhou 等人[29]设计并实现了ECTCAT 实时应用的灵活快速路径可编程网络处理器.作为家庭网关的快速路径处理器,最多可用于10GPON 访问.使用 VLIW(超长指令字)体系结构,可以并行运行多达 8 条指令.在SMIC(中芯国际) 65nm 技术下,在1.75Ghz 的运行频率下,最多可支持7Gb/s 的数据吞吐量.同时,该处理器对于1G 以太网具有最小40ns 的端到端延迟,且无抖动.不过该设计受限于定制化服务,如何面对今后的网络发展是一个无法解决的问题.2019 年的INFOCOM 上,Su 等人[30]甚至提出了一种基于模板的网络处理器自动生成框架,通过将P4 程序自动转换为VHDL 程序来生成具有匹配动作结构的网络处理器.作为一种基于模板的解决方案,其使用P4 程序自动转换为VHDL 程序,从而在FPGA 中生成包转发处理器,最后实例化生成网络处理器.该方法实例化过程复杂,适合学术界进行学术研究,不适合现场部署.
2.3 利用P4等高级语言的NGNP
一般地,转发芯片绝大部分都不是可编程芯片,无论是路由器中采用的NP,还是交换机中采用的Switch Chip,都不是可编程芯片[31].这些芯片的硬件转发逻辑已经设计好,无法通过调整软件参数去更改.编程语言的协议或者是平台相关性随着芯片种类的冗杂导致数据平面控制平面分离失效,网络处理器可编程性变差[32].P4的出现开始改变这种局面,网络处理器原型设计开始考虑对这种语言的适配性.
领域专用语言(domain-specific language,简称DSL),如P4,以其高生产率在网络领域得到了广泛的应用.然而,在FPGA 上实现P4 程序的自动转换是很困难的.
Cao 等人[30]提出了一种基于模板的网络处理器自动生成框架,通过将P4 程序自动转换为VHDL 程序来生成具有匹配动作结构的网络处理器.该框架首先从P4 程序中提取功能模块和相应的参数,这些功能模块将映射到预构建的高效VHDL 模板以获得高性能.最后,所选模板将被实例化,并根据需要安排形成一个完整的处理器.实验表明:生成的处理器不仅具有较高的吞吐量,而且具有较低的延迟.该方法的缺陷是精度较差,测试压力强度不够.He 等人[33]建议利用P4 实现NP 的网络功能虚拟化(NFV),可以处理与协议无关分组处理的P4 语言,在计算和存储硬件方面等运营商指定的网络功能实例化具有很好的优势.同时,可以利用P4 增强的网络硬件的性能改进.Cao 等人[34]提出了一种将P4 程序转换为VHDL 语言并在FPGA 平台上实现NP 的框架,在该框架中,引入了一种基于匹配动作的硬件体系结构,其预构建的模板库用于编译,包括与特定的明确设计的组件相对应的优化VHDL 模板.通过调用、配置、优化和实例化这些参数和关系,将它们映射到相应的模板,这样生成的NP占用资源少、吞吐量高、延迟低.当然,上述方法原型到芯片的过程比较困难.
NP 与P4 的结合可以实现在灵活性上的质变,这首先给流量监测技术带来了新鲜血液.Martins 等人[35]提出了利用P4 实现的NP 中搭载概率数据结构来监视多租户网络.文章为每个租户实现了sketches 架构,利用位图和计数器数组两个概率结构来进行独立的网络监视.该方法没有考虑带内测量带来的精确问题,导致测量结果精确度不高.Paolucci 等人[36]利用P4 语言对SDN(software defined network,软件定义网络)交换机的数据平面结构和行为进行编程.实例化的NP 可以自定义管道和有状态对象,支持复杂的工作流、用户定义的协议/头和有限状态机强制.原型系统显示出良好的可扩展性性能和总体延迟.该方法没有进行现网测试,实际应用能力存在一定的疑问.在网络管理方面,Yazdinejad 等人[37]设计了一种与静态网络设备不同的NP 体系结构,它在数据平面具有高灵活性和可编程性,支持特定分组的解析和处理,原型系统采用了P4 语言在FPGA 上实现.Guan、Jiang、Benácek 等人[38-40]都利用P4 设计了负载均衡的网络监控、网络拥塞控制以及线速转发框架,使得下一代可能的异构网络硬件能够根据不同领域的特定应用程序的需要进行运行时定制.这些方法注重灵活性,在部署时间、处理性能两方面考虑不足.
P4 除了能够提高NP 的灵活性,解决了有状态数据平面的局限性之外,也能利用存储和计算性能的改变,实现学习功能,提高性能.Sviridov 等人[41]引入并提供了LODGE 的设计准则.LODGE 是一个模型,根据该模型,分布式网络应用程序可以基于在其他交换机上共享的一些全局变量在每个交换机上利用NP 做出本地决策.应用程序可以支持在P4 和开放包处理器的有状态数据平面中学习并检测分布式拒绝服务(DDoS)攻击.Pontarelli 等人[42]的目标是使NP 进行预先操作,在保持高速多Gb/s 操作的同时可编程.他们提出了一个特定领域的NP 架构,称为包操作处理器(PMP),能够有效地支持微程序实现隧道、NAT(network address translation,网络地址转换)和ARP(address resolution protocol,地址解析协议)应答生成等相关操作.上述方法由于需要离线学习,对数据要求严格,准确性过度依赖先验处理知识.
3 面向新型网络体系结构的下一代网络处理器
近年来,网络的应用场景变化复杂,传统网络体系结构在时延、传输性能上的弊端逐渐显现[43].新型的网络体系结构成为了学者们从根本上解决各种网络问题的研究热点,这种学术潮流也影响了学者们对网络处理器的设计模式.数据平面与控制平面分离原本就符合网络处理器的设计思想,面向软件定义网络这一新型网络体系结构进行NP 设计,可以增强网络各节点处理性能,灵活开展各项业务.去中心化的下一代网络体系结构设计思潮体现在了边缘计算中的网络应用.边缘计算节点对计算能力要求高,其功耗和成本必须维持在普通环境下的可接受的程度[44].所以在边缘计算以及云计算、甚至雾计算的节点上,NP 可以成为一种专用的预处理器,在海量级的数据报文流量下,利用高效的包处理能力提炼出相关有效载荷,转发至计算节点的不同核心计算处理器进行数据计算或者相关处理.NP 作为一种功能芯片,实现非核心业务向智能网卡(smart network interface controller,简称SmartNIC)的功能推拉与卸载,可以帮助NP 提高利用率,增强网络的转发与处理性能.
3.1 服务SDN的NGNP
SDN 的设计虽然从控制层面进行了逻辑上的简化,但是实现这种下一代架构需要各个交换机拥有足够的计算与处理甚至是存储资源[45].使用下一代网络处理器应用在交换设备上能够加速SDN 体系结构的流表下发、带内遥测以及网络监管的性能.
NGNP 在SDN 的数据中心建设上有得天独厚的优势.Brebner 等人[46]探讨了利用FPGA 实现的NP 原型作为光网络和数据中心服务器之间的一种经济高效的中介,以满足下一代数据中心的需求.在数据中心本地或是在载波网络中,配备了这种NP 的主要作用有3 个:首先是从服务器上卸载网络处理功能,以便在较低的延迟下实现更高的吞吐量,同时释放服务器资源以集中于数据处理;第2 个是为不同的通信协议和标准提供灵活的硬件支持;第3 个是作为一种可管理的资源,它可以提供支持SDN 和网络功能虚拟化(NFV)的软件控制器和管理程序所需的数据平面功能.该方法没有考虑突发流量情况下或者是网络攻击时的NP 性能表现.为了破除兼容性带来的OpenFlow 控制平面在许多网络平台上的部署障碍,Suñé 等人[47]描述了xDPd 和OpenFlow 的网络处理器.硬件无关部分主要是使用修订的OpenFLASH 库(RoFL),它为OpenFLASH 控制器和数据通路元件的开发提供了基础,并允许为各种设备开发特定平台的驱动程序.Belter 等人[48]描述了一种在软件定义的网络体系结构中实现NP 的支持发现和HSL 翻译功能,它将基于OpenFlow 的AFA 消息转换为NP-3 网络处理器中的内存结构.NP-3 存储器结构通过EZchip 提供的EZdriver 访问,其内存包含一个带有流条目的结构、包匹配和操作的专有二进制编码.这两种方法在提供控制器命令编译支持时没有考虑SDN 架构下流量的特征与分组处理特点,导致过多指令集翻译带来的性能下降.
将输入业务流与控制器发送的规则相匹配,是SDN 业务转发的一个重要组成部分,其执行效率对网络性能有很大影响.Wijekoon 等人[49]提出了一种高性能、低成本的SDN 交换机流匹配体系结构,通过定制NP 处理特定于SDN 的业务.该NP 由一个用于流匹配的专用单元和一个自定义处理器组成,这个处理器的ISA 被设计用来加速OpenFlow 和SDN 相关的任务,比如向流表添加条目、处理相关报文等.其使用32 位长指令,操作码保留6 位,能够保持最大频率150MHz,其流量匹配单元也可保证250MHz 工作.但是该NP 的功耗很高,设计相对复杂,很难大规模地在SDN 网络中部署.Blaiech 等人[50]提出了一种基于网络演算模型和博弈论算法的公平共享网络处理器资源分配策略,该策略根据虚拟节点的处理,动态地映射合适的资源.在NP 的实现中,他们专注于在多个协处理器中根据OpenFlow 转发模型来重新分配资源的包处理任务.
随着业务的不断更新,SDN 仍然寻求灵活的方式定义网络设备的行为,控制平面需要能够充分利用现代网络硬件不断增长的能力及其多样性,使得控制平面加快对网络变化的探测和响应[51].Belter 等人[52]提出了一种新的NP 硬件抽象,其首要目标是公开NP 和软件交换机的高级可编程能力;第2 个目标是通过提供动态检查特定网络设备支持的功能的可能性,来扩展网络节点可编程性的概念;第 3 个目标是将使用新定义的 API(application programming interface,应用程序接口)的编程语言引入到不同类型网络设备的数据路径的可编程抽象中.Kaljic 等人[53]提出了一种基于现CPU+FPGA 技术的深度可编程NP 混合结构,以克服OpenFlow 在实现新协议和高级分组处理功能方面的局限性.通过对实现和实验评估,该NP 将交换任务减少到简单的包流表查找,证明了采用混合的FPGA/CPU 结构是可行的.这种方法的不足是在CPU 和FPGA 混合编排时忽略了缓存架构的设计,导致性能较差
在SDN 中,OpenFlow 表查找可能需要检查15 个包头字段.为了针对SDN 这种下一代网络体系结构进行优化加速,Qu 等人[54]提出了利用NP 的包分类实现与有效的优化技术.在多核GPP 上,他们使用并行程序线程并行化搜索和合并阶段.该方法强调性能,可能会加大NP 中Cache 的资源占用,反而导致Cache 失效.Sun、Bi 等人[55]针对SDN 数据平面提出了一种新的状态数据平面体系结构SDPA.为SDN 交换机设计了一个专用NP,通过新的指令和状态表来管理状态信息,进而实现扩展的开放流协议来支持平面间通信.Wu 等人[56]提出了一种支持Openflow 协议的高扩展性SDN 交换机的NP 软硬件协同设计,为了在灵活性、能量效率和性能之间取得平衡,NP 核心是基于集成了ARM 处理器和FPGA 的嵌入式片上系统(SOC)平台来实现的.特别地,在所提出的交换架构中设计了专用高速信道,使得多个交换机可以互连在一起,成为一个堆叠的交换机.Li 等人[57]提出了一种基于Cavium 的开放式vSwitch 实现,Cavium 平台就是一种多核NP,它支持包的零拷贝,处理包的速度更快.这两种方法在高速通道的使用上容易引发堵塞和不一致性,风险系数较高.
安全性是SDN 中最具挑战性的问题之一,网络安全应用程序通常需要以比SDN 数据平面实现允许的更高级的方式分析和处理流量[58].NP 可以在SDN 数据平面(即交换机)上对分组进行预处理,以初步确定其在网络中的行为.近期,区块链被用于安全传输网络中的交易和文件传递.Yazdinejad 等人[59]根据区块链的安全特性和对数据处理功能的支持,提出了一种新的SDN 分组解析器体系结构,称为区块链启用分组解析器(blockchainenabled packet parser,简称BPP),并进行了利用FPGA 的NP 原型实现.在他们提出的架构中,NP 利用一个基于多元相关方法的数学模型,用于从观察到的数据包流量中检测攻击,能够做到处理速度快、灵活性强、消耗资源较低.但是该方法没有对NP 本身的架构加以解析和更改,没有突破原有NP 架构在使能安全业务时的限制.
3.2 边缘计算与云计算中的NGNP
边缘计算、云计算节点最注重节点的数据处理能力[44].作为分导网络数据的重要“关卡”,网络处理器对网络数据的预先处理可以倍速增加计算节点的处理效能,甚至可以缓解整体网络的压力.
在边缘计算节点中,领域特定的局域网语言(如Click)是捕获应用程序一致性的好方法,但网络处理器仍有许多其他机会来提供更符合应用程序需求的功能.Mihal、Andrew 等人[60]提出了一个处理元素,它在实现Click应用程序任务时非常有效.其使用Click 作为高级输入语言编程PE 提供了一种高效的方法,并利用FPGA 实现了为IPv4 转发应用处理超过8Gb/s 流量的NP.Nayaka 等人[61]介绍了一种用于片上系统(SoC)的以太网NP 设计,该处理器实现了所有核心的分组处理功能,包括分组和重组、分组分类、路由和队列管理,提高了交换/路由性能,使其更适合下一代网络(next generation network,简称NGN)的各项节点.该NP 可支持1/10/20/40/100 千兆链路,具有速度和性能优势.当然,其也具有片上系统的共同弱点,灵活性受限于定制流程.
加速 NP 中的数据处理流程、增强节点性能、减少复杂度,是面向计算节点的 NP 设计重点.Ihor,Tchaikovsky[62]成体系地介绍了面向边缘计算的网络处理器的体系结构和服务,描述了网络处理器在设备流量处理和形成中的应用.他指出:在满足这些要求时,重点是包的处理速度.但是该文章没有讨论NP 在遭遇计算节点流量突发时的情况.Kanada 等人[63]提出了一种利用多个包处理器控制(packet-processing cores,简称PPC)NP中的分组处理的方法.通过这种方法,NP 芯片外的CPU 对复杂的控制信息进行部分处理,并将其分为简化的控制包,这些控制包被发送到控制处理PPC.利用PPC 的数据交换机制(例如共享存储器或片上网络)来控制数据处理,这些机制比原有机制更加统一和简单.处理器关联性是提高NP 性能的有效途径之一.He 等人[64]详细分析了网络处理器的缓存特性,提出了一种兼顾负载均衡和数据包相关性的多核网络处理器调度算法BLA.该方法尝试将同一个流的数据包调度到同一个NP 核心,同时保持核心之间的工作负载平衡.但是增加核间调度,使得该方法牺牲了一定的性能
链路速度的显著和连续增加以及应用的多样性,要求新的云计算节点服务高效又灵活.Niu 等人[65]提出一种基于NP 的高效流量管理QoS 调度机制,详细讨论了利用数据平面软件体系结构的操作过程.他们将NP 的一些协处理器设计得更加亲和计算节点业务,如准确的流量分类、灵活的访问控制和三步调度等.针对网络应用中数据量大、实时性要求高的问题,Wu 等人[66]通过优化配置NP 控制和数据平面,提出一种基于核心处理器的快速数据包处理的NP 体系结构.它减少了CPU 的调度,与平均分配CPU 内核资源相比,提高了30%的包转发率.上述方法的缺点是没有引入负载均衡考虑,准确的流量分类带来的高功耗,加大了计算节点的环境、能动压力.
与DPDK(data plane development kit,数据平面开发套件)的设计模式类似,很多云计算或边缘计算节点不希望所有的数据通过之前搭载的网络协议栈进行处理,为NP 专门实现一种协议栈,成为了计算节点的加速方式.Tang 等人[67]提出一种实时操作系统中的多径可靠数据传输(multi-path reliable data transfer,简称MPRDT)系统,该系统在多核NP 的实时操作系统(real time operating system,简称RTOS)中实现了一个基于UDP 的可靠数据传输栈,以加速网络处理器的可靠数据传输.该系统由两部分组成:基于UDP 的可靠栈(URS)和连接管理模块.系统采用多径方法,使系统能够通过不同的接口管理到不同接收端的多径连接,充分利用网络接口和带宽资源.
随着服务器的虚拟化的发展趋势,出现了一种新的网络访问层,它由运行在服务器平台上的虚拟交换机组成,为同一物理服务器上的虚拟机(VM)提供连接.Blaiech 等人[68]提出了一种策略,旨在通过将包处理任务扩展到NP,以提高虚拟交换机的性能.该策略基于处理器资源的自适应动态分配,分配机制包括将虚拟交换机任务映射到足够的资源集,即多核数据路径或硬件加速器数据路径.传统的NP 不能处理7 层包,给计算节点带来了很大困扰,Bae 等人[69]提出了一种新的NP 互通结构,该结构通过将传统NP 与通用处理器(GP)相结合,能够处理OSI 第2 层(L2)~第7 层(L7)的数据包,并在不增加硬件开销的情况下提高NP 中数据包处理的吞吐量和负载平衡.实现上述方法并不简单,兼容性是搭载新协议NP 的重要问题,无法识别分组头部或者协议偏差导致识别错误时,NP 的后续处理不仅消耗CPU 资源,而且导致下发的转发和处理任务全部失败.
随着云计算中网络即服务(network-as-as-a-service,简称 NaaS)的发展趋势,加速租户 NFs(network file system,网络文件系统)以满足性能要求也具有重要意义.然而,为了追求高性能,现有的工作如AccelNet 被精心设计,以加速数据中心提供者的特定NFS,这牺牲了快速部署新NFs 的灵活性.Li 等人[70]提出了一种可重构的NP 流水线DrawerPipe,它将数据包处理抽象为多个由同一接口连接的drawer.开发人员可以轻松地将现有模块与其他NFs 共享,只需在适当的“抽屉”中加载核心应用程序逻辑,即可实现新的NFs.此外,他们还提出了一个可编程模块索引机制,即PMI,它可以以任何逻辑顺序连接“抽屉”,从而为不同的租户或流执行不同的NFs.这种NP设计方案暂时无法大规模投入生产.Li 等人[71]提出了一个并行包处理运行系统,并探讨了一种基于关联度的包调度算法,以提高NP 负载平衡度并减少缓存丢失为.在并行数据包处理系统中,由于牺牲了部分缓存,NP 任务分发器和调度器能够在负载均衡和缓存关联性之间达到较好的折衷.方法缺陷是租户单点故障时容易使得全部服务器NP 性能宕机,在高并发情况下其效率有限,安全性也一般.
3.3 NGNP与SmartNIC的功能推拉
NP 的设计原型一般以板卡的形式实现,所以NP 的设计阶段与SmartNIC 的设计方法类似,呈现形式也相似.可以预见的是:面向复杂网络应用和对网络压力不同的各项应用,实现NP 和smartNIC 的功能推拉是必备的节点能力,很多研究者也在开始寻找两者的平衡点.
NP 的使用受到不断提高的灵活性和高性能的分组处理的需求的鼓舞.此外,适应性要求、产品差异化和缩短上市时间鼓励在网卡中使用网络处理器,而不是包括特定用途的硬件.Cascón 等人[72]提出了一种利用NP 的并行性来提高通信性能的网卡,遗憾的是,他们没有提出特有的框架,而是基于包括16 个多线程处理内核和包处理的优化设计Intel IXP28xx 网络处理器.通过使用NIC 卸载和/或加载策略,利用不同的选项来优化主机中的通信路径.Sabin 等人[73]提出的SmartNIC 是一种用户可编程的10GE NIC,可以满足HPC(high performance computing,高性能计算机群)和数据中心社区的高性能网络需求.这种SmartNIC 支持开发特定于应用程序的卸载引擎,以实现与NP 的功能推拉.应用程序开发人员可以实现应用程序感知的卸载引擎,网络开发人员可以测试和开发网络协议卸载引擎,研究人员可以测试和开发新的卸载协议和中间件.但该方法没有明确卸载协议类型,适用范围有限.
从增加包处理性能的角度看,SmartNIC 从主机处理器上卸载网络功能,使其部分功能通过板卡或者是NP进行实现,是一个较优策略.Le 等人[74]提出了一种广义的SDN 控制的NF 卸载结构(uniflying host and smart NIC offload,简称UNO).通过在主机中使用多个交换机,它可以透明地将动态选择的主机处理器的数据包处理功能卸载到SmartNIC,同时保持数据中心范围的网络控制和管理平面不变.UNO 向SDN 控制器公开单个虚拟控制平面,并在统一的虚拟管理平面后面隐藏动态NF 卸载.这使得UNO 能够最佳地利用主机和SmartNIC 的组合包处理能力,并根据本地观察到的通信模式和资源消耗进行NP 参与转发的本地优化,而无需中央控制器的参与.这种方法依赖于板卡CPU 的计算性能,可能会无法正确地判断本地网络状态.Cornevaux-Juignet 等人[75]考虑了采用嵌入式现场FPGA 的SmartNIC 辅助NP 进行处理的新解决方案,提出了一种混合体系结构来实现灵活的高性能流量取证.这项工作结合了硬件性能、高吞吐量和软件高灵活性,以实现超过40Gb/s 的数据速率,同时可以通过参数在运行时热配置.Cerović 等人[76]提出了一种将数据平面包处理卸载到具有并行处理能力的可编程硬件上的体系结构,因此,他们使用MPPA 这种大规模并行NP 阵列组建的SmartNIC,它提供可用于数据包处理的ODP(open distributed processing,开放式分布处理)API,并且可以建立一个全网格无阻塞的第2 层网络.当然,这两种方法注重转发性能,包处理性能考虑不周.
实现与SmartNIC 功能推拉的NP 可以扩大自身的网络监控能力.Huang 等人[77]设计并实现了一个基于多队列网卡和多核NP 的数据流捕获系统,该系统充分利用了轮询技术、多队列技术和原始设备技术,大大提高了系统性能.2019 年的SIGCOMM 上,Li 等人[78]提出了一种新的高速拥塞控制机制HPCC(high-precision clusion control),HPCC 利用网络遥测技术(INT)获得精确的链路负载信息,并精确控制通信量.他们用可编程的网卡(NICs)模仿NP 来实现HPCC.这种方法能够在避免拥塞的同时快速收敛,以利用空闲带宽,并能在网络队列中保持接近零的超低延迟.这种定制板卡的拥塞控制方法部署环境受限于大规模数据中心.在网络安全问题上,S.Miano 的文章[79]旨在利用SmartNICs 构建一个更高效的处理管道,并为特定用例(即减轻分布式拒绝服务(DDoS)攻击)的使用提供具体的方案.他们通过透明地卸载SmartNIC 与NP 中的DDoS 缓解规则的一部分,实现了XDP 灵活性在操作内核中的流量采样和聚合时的平衡组合,并具有基于硬件的过滤流量性能.由于依赖DDoS 配置规则,缺乏在线流量学习功能,在真实网络环境中预计无法有效清洗DDoS 流量.
SmartNIC 不仅可以包含NP,还可以利用多项元器件加强网络包的转发或者处理性能.与此同时,学者将眼光转向保证SmartNIC 与NP 功能推拉结构的灵活性[80].在Caulfield 等人[81]的文章中,他们重点讨论了基于FPGA 的智能网卡(sNICs)和可编程交换机实现这一愿景的潜力.NP 和SmartNIC 涵盖了从完全基于CPU 的设计到完全定制的硬件的范围.基于CPU 的可编程NIC 提供一个或多个通用处理器,算法可以在这些处理器上运行.这种设计可以映射到FPGA 上.这样可以保证推拉架构的可编程的能力,并且拥有完全定制硬件的效率和吞吐量特性.Microsoft 公司的Firestone 和Greenberg 等人[82]提供了Azure 加速网络(AccelNet)解决方案,其使用基于FPGA 的自定义Azure 智能网卡将主机网络卸载到硬件.利用NP 的性能和FPGA 的可编程性,为客户提供小于15ms 的TCP 延迟和32Gb/s 吞吐量.这种方案在运行正常时缺乏日志记录,在业务演进过程中必须重新匹配软件定制方案,增加了运维成本.
4 针对新型高性能业务的下一代网络处理器
下一代高性能业务是指随着平台软硬件的迅速升级,在网络监测、网络传输、服务质量保证、VR(virtual reality,虚拟现实)以及高带宽低时延终端应用、网络安全以及物联网等方面新兴的复杂业务.这些业务一般需求更改时间快、性能要求高、针对性强,部署在当前的网络处理器中难度很高.针对下一代高性能业务,业界希望能够设计出符合要求的专用网络处理器满足相关需求.网络监测和网络传输的基本要求是,网络处理器具备精确网络测量能力[83],测量过程的自适应性和精确性直接影响了监测结果和传输效率.利用网络处理器获得的数据包元数据(metadata)能够定制化地完成不同的服务质量保障.在性能方面,具备多核的网络处理器的核间调度、提高Cache 亲和性以及分组向量化处理是当前研究的热点.
4.1 精确网络测量
网络测量作为众多网络管理应用的基础,其一直作为众多学术研究者的重要研究领域.网络处理器具有计算和存储能力后,借助报文的往返所携带的各项遥测数据进行非全域视角下的网络资源视图绘制,可以成为网络测量方向的发展重点.面向这一热点,NGNP 的设计对精确的网络测量进行了偏移.
高速捕获和处理流量中的数据包,是NP 在精确网络测量中的重要应用.Ficara、Lu 以及Li[84-86]都利用了已有的网络处理器实现架构,如Intel IXP2400 网络处理器PCI-X 卡实现网络流量测量,并在在此基础上实现了二维矩阵测量器和入侵监测系统等.这几种方法在思想上贴近下一代网络处理器架构设计,但是由于受限于已有架构,简单地通过下发基本测量任务使得其性能较差.Yang 等人[87]提出了一种被动HTTP 流量性能测量的NP架构,将对象分为不同的源/目的IP 地址对,并使用对象间请求时间间隔来判断这些对象是否属于同一页面,从流量中实时地测量HTTP 性能.该系统可以在高速网络中工作,可以部署在ISP 上.Yuan 等人[88]提出了用FPGA作为专用NP 原型平台的ProgME 的方法.ProgME 可以整合应用程序要求,调整自身缓存,以规避大量流带来的可扩展性挑战,并实现更好的应用程序感知准确性.其核心是基于流集的查询答案引擎协处理器,它可以由用户和应用程序通过提议的流集组成语言进行编程.上述文章基本实现的是NP 中的协处理器,所以存在适用场景小、性能以及可靠性差的缺陷.
依靠NP 的存储实现NP 的智能测量任务下发以及测度值反馈分析,能极大地提高测量精度.Xie 等人[89]提出了一种在NP 上实现的新的动态测量方法(dynamic measurement method,简称DMM),它通过记录在NP 存储里的运行时计划操作和相应时间戳来导出测量路径;通过判断派生路径能否通过任务调度IMC 模型接收;通过判断实际值是否满足初始状态的标签函数进行可靠性验证.当然,多核处理器进行测量值的传递一定是具有一定开销的,这种方法还是有优化空间.Ferkouss 等人[90]提出了在100Gb/s 混合NP 上的Openflow 多表流水线的记录及测量方案,该方案描述了几种将这些流水线查找表链接起来并将它们映射到不同类型的NP 存储器设计方案.SDN 网络应用程序的要求可以在这种NP 上灵活地实现,以便实现智能测量.但是,该方法没有使用IXIA硬件流量生成器以线速进行详尽的性能评估,这种NP 的性能暂时未知.
平衡测量和转发的CPU 负载以及Cache、存储的利用率是针对下一代高性能测量任务的NP 需要关注的重点.华盛顿大学的Liu 等人[91]研究如何使用NP 的加速服务器在数据中心执行基于微服务的应用程序.文章提出了通过适当地将测量微服务卸载到SmartNIC 的低功耗处理器上而不会造成延迟损失的负载均衡方法,这种方法依然面临网络流量路由和负载平衡、异构硬件上的微服务布局以及共享智能网卡资源的争夺等严重挑战.在利用测量结果进行拥塞控制方面,Narayan 等人[92]提出将拥塞控制从数据路径转移到一个独立的NP 代理中.这个必须同时提供一个表达性的拥塞控制API 和一个规范,供数据路径设计者实现和部署.他们提出了一个用于拥塞控制的API、数据路径原语和一个用户空间代理设计,该设计使用批处理方法与数据路径通信.但是这种方法的NP 设计复杂,无论部署在端节点还是重要的中间路由设备上都不适合,定位不清晰.
4.2 基于metadata的QoS保障
服务质量保障在硬件上的实现一直是学术届的研究热点.在数据平面上获取分组的元数据后,对数据传输链路以及流量进行简单的阈值分析,对相关服务质量进行保障在网络处理器变得可行.
有效进行分组分类、保障特定业务的分组延迟和丢失,是 NGNP 在 QoS 保障上的重点研究方向.Avudaiammal 等人[93]在基于通用NP 架构上实现并验证了高速、低复杂度的基于启发式的专用分组分类(high speed packet classifier,简称HASPC)机制可以执行多维分组分类.通过多位的Trie 数据结构用于对地址前缀对的搜索,从而有效地聚合了协议和端口字段的搜索结果,并将该方法应用到IXP 2400 上.但是他们没有提出通用分组分类高效方法,只对多媒体分组进行QoS 保障.Park 和Lee 等人[94]提出了基于流的动态带宽控制方法的网络处理器体系结构.他们提出的FDBC(flow-based dynamic bandwidth control,基于流的动态带宽控制)通过使用流分类、识别活动流并重新计算活动带宽,通过流量工程的方法屏蔽网络拓扑配置,以便在以太网上提供有效的QoS.该方法的缺点是:当传入流量的总大小超过最大上游带宽时,无论服务类型或流的属性如何,HLS 都会丢弃流量.
面向IP 网的传统服务,Li 等人[95]在IXP2400 架构上改进了一种传统的ACL 算法,将TCP 的ASK 和RST添加到1 级表分类索引中,减少了规则冗余.通过微码实现的IP QoS 体系结构,利用CAR 处理器实现了带宽限制功能,满足数据线速转发,有效地保证多媒体服务的低延时需求.同样地,Saleem 等人[96]利用DiffServ 架构对IXP2400 编程,添加缓存单元,以便在查找操作期间减少对SRAM(static random access memory,静态随机存取存储器)的访问,使得总体速度提高并减少延迟.当然,两种方法基于SDK3.1 开发,没有成体系结构地更改核心NP的架构.Nguyen 等人[97]提出了一种针对NP 的多模式完全可重新配置路由器.设计NP 支持混合式分组交换体系结构,该体系结构可以在运行时进行动态重新配置,以在虫洞和虚拟直通交换方案之间进行交换.配备了QoS驱动的仲裁器保证了无需预留资源的吞吐量保证服务,基于优先级继承仲裁机制有效地利用了网络资源,具有动态的期限可感知的重新路由机制.但是该方案成本较高,没有进行负载均衡,等待CMOS 技术对其进行综合评估.
在拥塞控制的流量管理架构方面,Benacer 等人[98]提出了一种支持5G 传输的流量管理器架构.他们设计了基于FPGA 的NP 原型对传入流量(数据包)进行管制、调度、整形和排队的模型.流量管理以要满足每个流所允许的带宽配额并强制执行所需的QoS 目标的方式,对要发送的数据包施加约束.方法实现在Xilinx 板卡上,注重可编程性,通过流量发生器进行测试,其真实效果未知.Iqbal 等人[99]重新设计了NP 中的数据包调度方案,以在最小化乱序数据包的同时,提高网络处理器的吞吐量.其调度策略试图通过保持流局部性来维护数据包顺序,通过识别激进流来最大程度地减少流从一个核心到另一个核心的迁移,并在多个服务之间划分核心,以获得指令缓存局部性.此外,调度程序将基于哈希的设计扩展到了多服务路由器,其中,内核被动态分配给服务,以改善I-Cache 局部性.该方案通过减少乱序包来获得吞吐的QoS 性能,过多的调度设计增加了数据平面和控制平面的耦合.
NP 中,QoS 调度器的性能直接影响新QoS 需求层出不穷背景下的NP 性能和部分灵活性.Yu 等人[100]在线卡中利用NP 提出了基于DVFS(dynamic voltage and frequency scaling,动态电压频率调整)的数据包QoS 调度器设计方法,该方法使用队列长度(QL)和链接利用率来控制线卡中的执行速率.通过不同的频率缩放策略,保障了节省能源时的处理器性能下降,在一定意义上解决了功耗和QoS 调度器的性能均衡.该方法基于预测队列长度,但在预测时只是根据阶段时间内的队列长度均值,很难应对bufferbloat 情况,容易导致全方案失效.Paul 等人[101]使用机器(深度)学习技术为智能IP 路由器中的多核NP 开发了QoS 增强型智能调度程序,他们将NP 每个内核都以利用率驱动的期限感知模式处理传入流量,并且使用学习算法,在运行时以智能方式动态地最小化负载不平衡,保持内核之间的稳态负载分配.该方法最大程度地减少每个内核的计算开销,获得更高的吞吐量、更低的平均等待时间值和PLR(packet loss rate,丢包率).但是机器学习本身就有极大的开销,计算和存储资源在学习方法加载过程中会造成转发能力下降.由于NP 本身架构受限,该方法与真正做到在线学习调度还有差距.
4.3 NP的处理优化以及应用加速
针对众多的高性能业务,网络处理器在设计架构上需要进行改进,加速分组的处理能力以及针对特定应用进行包分类后的处理优化.
提高Cache 亲和性能够提高NP 多核处理器的处理性能,许多多核处理器实时操作系统提供了通过设置相似性掩码来提高任务迁移到处理器指定子集的可能性.Bonifaci 等人[102]提出了强任意处理器相似性调度的概念,利用层次(层流)亲和力掩码的系统硬件拓扑结构,在最早截至优先(EDF)调度策略上实现对强大的分层处理器相似性的支持.该方法强调降低处理任务的时间复杂度,将性能提高到O(m2)左右.但是亲和性实现原理复杂,可调度性损失过大.Jang 等人[103]提出了多核NP 的新颖网络过程调度方案MiAMI,其根据处理器缓存布局、通信强度和处理器负载来确定最佳处理器亲和力.该方法可以适应网络和处理器的动态负载,同时以最少的处理器资源需求充分利用网络带宽.在Intel SMP Symmetrical Multi-Processing,对称多处理和AMD NUMA(non uniform memory access architecture,非统一内存访问)服务器上,处理器利用率的有效性改善率分别达到65%和63%.但是,该方法的缺陷是没有考虑存储资源的I/O 性能,扩展到外围设备的流程相对复杂.
在NP 处理多媒体流服务、实时或者是高性能计算应用服务时,需要处理器周期多、提高时钟频率和微体系结构效率的困难.Ortiz 等人[104]提出并分析了几种配置,以在NP 可用的不同处理器核之间分配网络接口.该方法根据相应的通信任务与处理位置,优化存储不同数据结构的存储器的接近程度以及处理核特性之间的相关性.该方法使用多个内核加速给定连接的通信路径,利用多个内核同时处理属于相同或不同连接的数据包的补充.Hanforda 等人[105]基于追踪高速TCP 流网络设备瓶颈的方法,将协议处理效率定义为系统资源(例如CPU 和缓存)计算量.在多核NP 终端系统中,将网络中断,传输和应用程序处理接收过程分配、甚至绑定给相关亲和的特定处理器内核.但是这两种方法同样实现困难,算法复杂度过高.
NP 使用多个数据包处理元素提高数据包处理的并行性,是处理优化的重要研究点.OK 等人[106]提出了一种用于具有多个分组PE 的NP 新序列保留分组调度器,使相同流的数据包由不同的PE 并行处理,调度程序通过利用预先估计的数据包来保留每个流的输出数据包的序列处理时间.该方法的缺陷是没有关注成本效益以及分组处理的准确性.Roy 等人[107]提出了16 核的类NP 多核加速计算体系架构,其中的每个核均配备有专用硬件,可在每次硬件加速器调用时快速切换任务.控制器侦听到重点任务时,将任务抢占请求发送到内核,减少了实时任务的延迟.该方法利用优先级阈值化技术,避免了低级的任务和行头阻塞的延迟不确定性.遗憾的是,该方法芯片化过程较慢,仅仅用28nm 技术制作,但是正在研发最新版本,市场前景光明.
减少NP 内的队列长度,可以提高多数应用相应速度.Satheesh 等人[108]提出了一个新的动态重新配置NP 的波动流量排队系统,该方法使用Kolmogorov 微分方程分析了NP 中的动态可重配置排队模型,并获得了PE 数量、队列长度、平均等待时间和重配置时间的上限.该方法能够动态地调节被使用的处理器数量,当队列增大到指定阈值时投入备用处理器,并在队列减小时动态减小.Avudaiammal[93]的文章里也有这种设计思想,有效地聚合了协议和端口字段的搜索结果,以分配不同的处理器核.两个方法也是基于原有NP 架构IXP2400,很难大幅度提高性能.Steven 等人[109]提出了一种基于数据流微体系结构的NP 设计方法,能够解决资源虚拟化和数据包处理的并行性问题.当然,这项研究仍在进行中,如何将块级数据流、连接性和运算符涵盖进入这种NP 体系结构是一个难点.表2 是文中提到的不同NGNP 设计方案优势及不足对比.
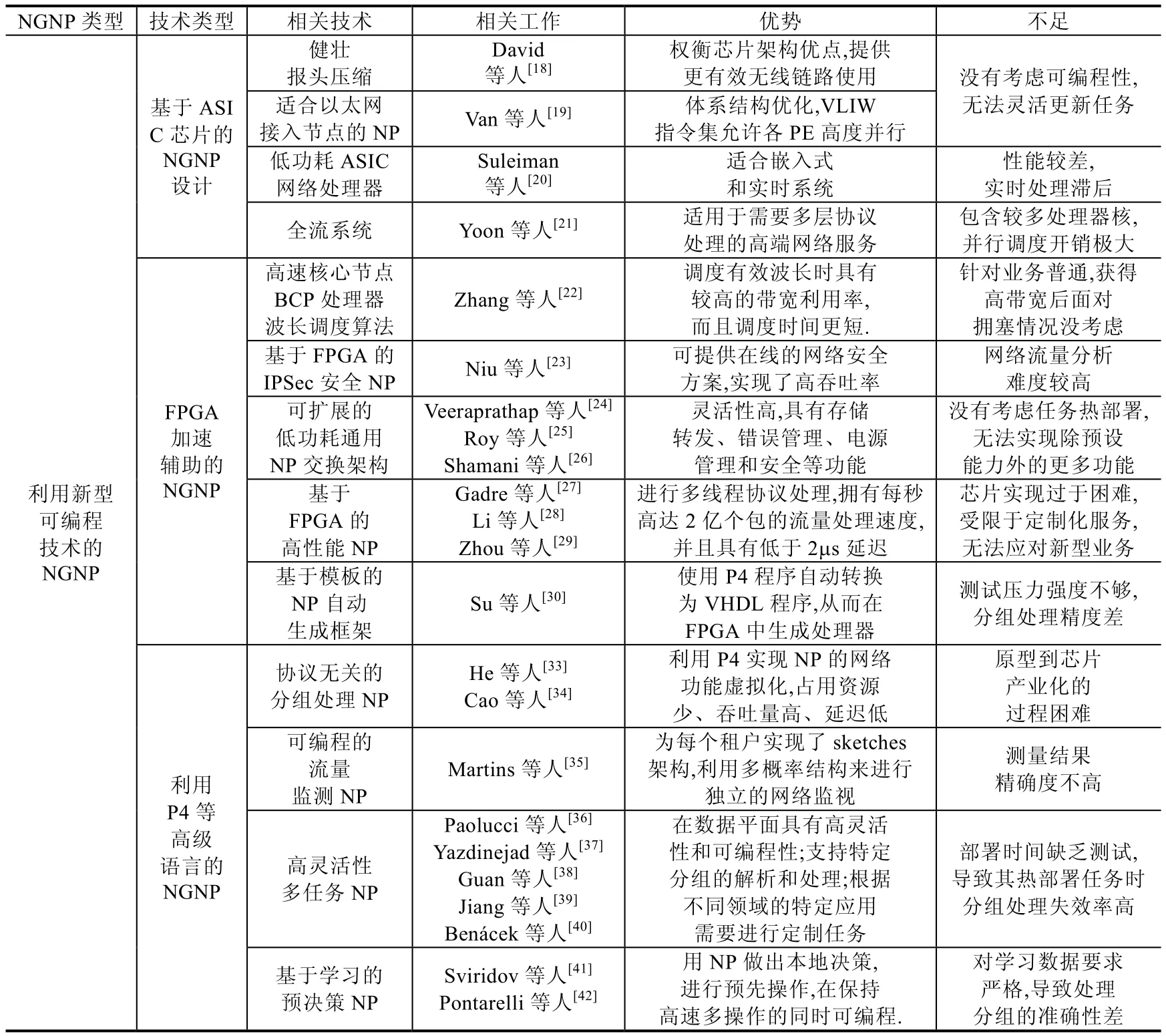
Table 2 Summary of designs of next generation network processor in existing study表2 现有下一代网络处理器设计方案总结
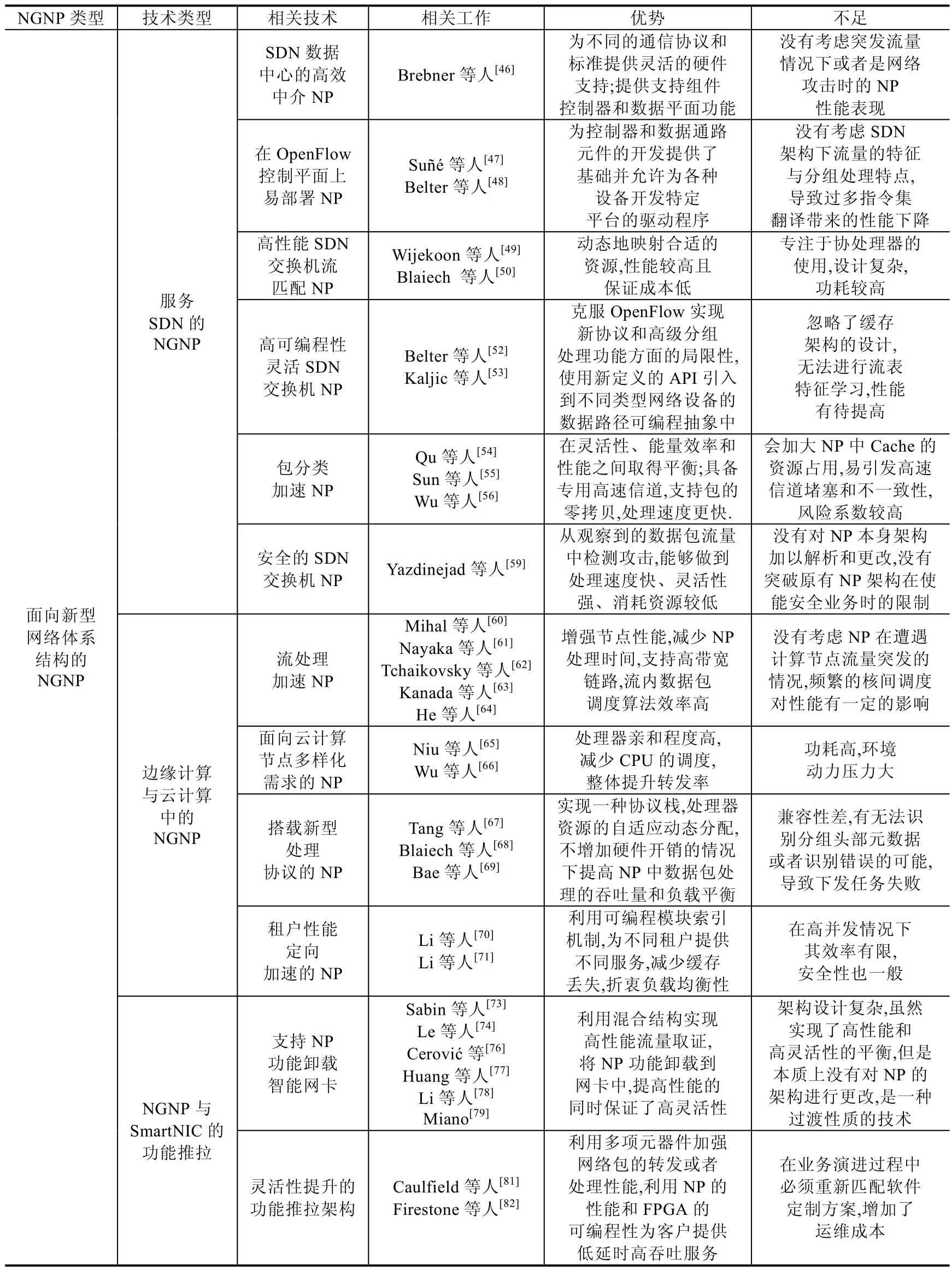
Table 2 Summary of designs of next generation network processor in existing study (Continued 1)表2 现有下一代网络处理器设计方案总结(续1)
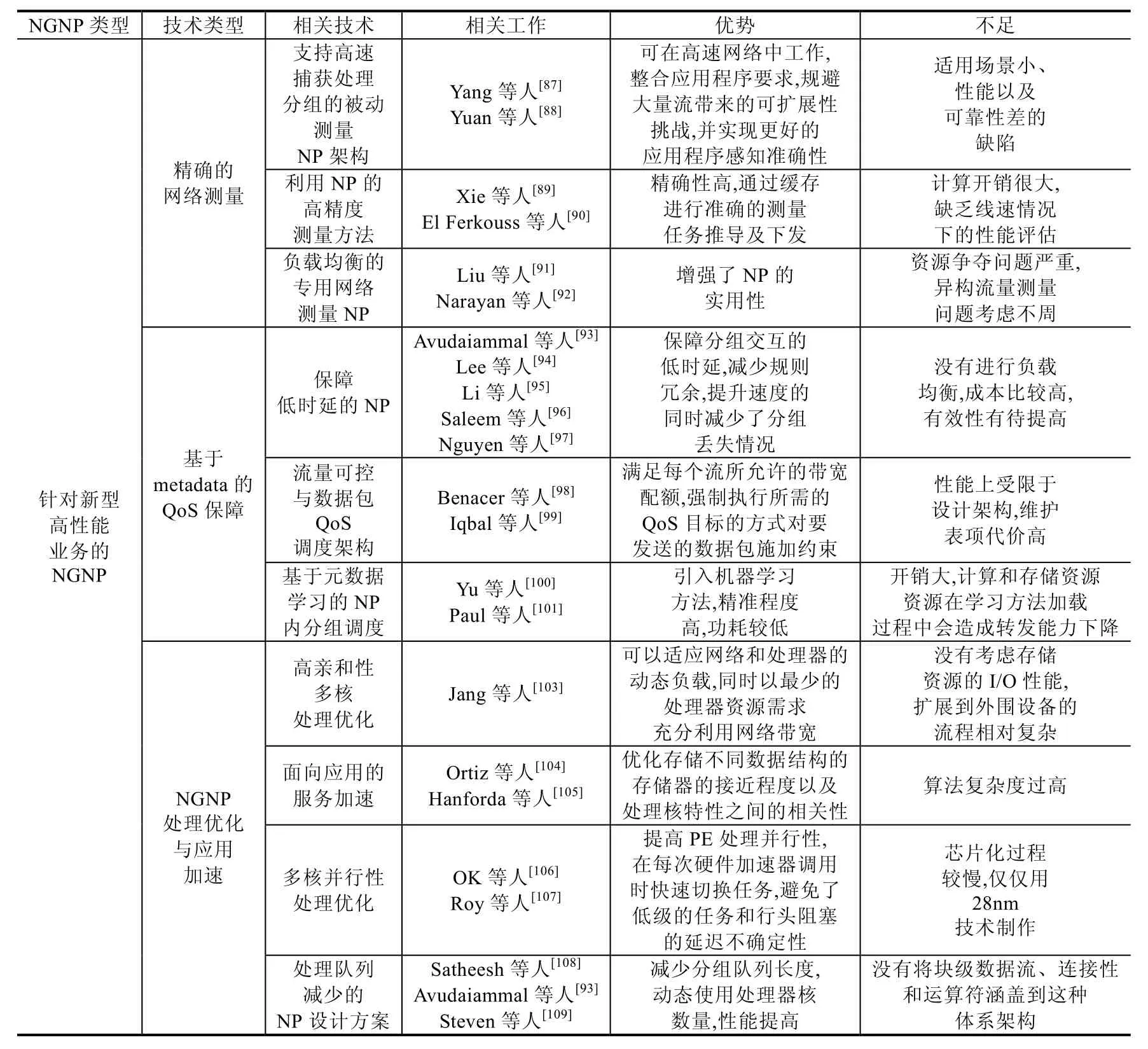
Table 2 Summary of designs of next generation network processor in existing study (Continued 2)表2 现有下一代网络处理器设计方案总结(续2)
5 下一代网络处理器的工业化及评测
5.1 网络处理器的工业化
国际上,作为最早的网络处理器生产厂家之一,Motorola 于2000 年生产了面向中低端应用的网络处理器C5,其只能执行第7 层以下的分组分类作业.虽然能力较弱,但作为一种独立网络转发处理芯片,其出现代表着NP 开始了工业化之路.IBM 于2002 年生产了PowerNP NP4GS3,其拥有16 个协议处理器、7 个专业协处理器和一个PowerPC 核心处理器,具有2.5Gb/s 的报文处理能力.同样作为一款廉价处理器,其占据了国际国内大部分市场,但处理性能依旧不佳.2005 年,Intel 推出了IXP42X,其逐渐开始争夺业界主流位置,这款产品的处理单元内继承了数十个以太网口,内置了加速功能降低系统成本.这几款产品出现的年代网络业务简单,智能终端尚未普及,所以其灵活性重视不够,性能上差强人意.
随着网络技术创新浪潮出现,传统网络处理器开始顾此失彼,逐渐被市场淘汰[110].2013 年,Cisco 推出了nPower X1,其具备高可扩展性,也是首款支持400Gb/s 吞吐率的单芯片,引领了利用新型可编程技术的网络处理器产业化趋势.创新性地,其为软件定义网络构建,支持在运行中重新编程,大幅简化了网络运营.2015 年,Mellanox 公司发布了NP-5 网络处理器,作为一款240Gb/s 线速网络处理器,其峰值处理数据路径和CoS 分类高达 480Gb/s.同年,ExpressPlus 推出了 Juniper 处理器,每秒可执行超过 15 亿次过滤操作,并可扩展到500Gb/s(1Tb/s 半双工).作为一款面向新型网络体系结构的下一代网络处理器,其利用3D 内存的多级缓存架构,与以前的解决方案相比,物理占用空间减少了20 倍,优化了功耗和空间要求.Nokia 在2017 年推出了世界首款可支持3.0Tbit/s 转发的网络处理器,利用网络元数据作为安全解决方案的一部分,是针对新型高性能业务网络处理的产品代表之一;同年,Cisco 设计了可支持400Gb/s 转发的多核网络处理器,它包含672 个处理器核心,拥有着大于6.5Tb/s 的核心I/O 带宽,外部DRAM(dynamic random access memory,动态随机存取存储器)用于大型数据结构和数据包缓冲.2020 年初,收购了Freescale 的NXP 公司推出了S32G,该设备是第一款将具有ASILD 安全性和网络加速功能(micro control unit,简称MCU)集成车载网络处理器,并且具有分组转发引擎用于以太网加速功能.当然,这几款产品设计与生产成本较高,市场化进程缓慢,大多在自家高端路由器或者交换机产品中应用.
中国的网络通信设备制造商在2016 年以前以采购国外网络处理器芯片为主,以便获得硬件发展红利,将创新与产能焦点集中在网络业务出新和5G 通信网络研究与建设上.然而随着中美贸易争端开始,2018 年4 月16日,美国商务部法部发布公告,声称未来7 年内禁止中兴向美国企业购买包含网络处理器芯片在内的“敏感”设备,该事件直至同年7 月12 日才以中兴向美国支付近10 亿美元告一段落.然而一年后,2019 年5 月15 日,美国商务部将华为和其下属子公司列入出口管制名单,华为产业下的多款中高端路由器产品网络处理器芯片断供.中国业界及学术界逐渐认识到网络处理器芯片作为一种重要网络设备元器件,其设计与生产应当至少具备自主可控能力,在特殊时期保证网络处理器芯片的供应.
2019 年,华为和中兴都开始进行自主可控的下一代网络处理器研发工作,设计方案的基本要求是,使得网络处理器具备高性能、低时延、可编程甚至是全流可视化.华为于2019 年初推出了Solar S 下一代网络处理器设计,其可以灵活地利用高级编程语言下发业务,保障低时延的同时,利用特有的存储结构,将流量的特征信息在时间域内存储,以便实时网络管理和精确测量,并且大多数开始应用于华为的高端路由器产品.同年,中兴发布了一款拥有先进内核互联结构、大容量微码指令空间、层次化的流量管理的100Gb/s 网络处理器.在此基础上,设计了这款处理器的迭代更新版本原型系统,升级内部体系架构,利用多核的性能提升转发速度.这两款国产化网络处理器与国际市场主流处理器相比在性能上相差无异,但是在芯片工艺、产品能耗上还有差距,亟待弥补.
5.2 部分主流网络处理器的性能评测
一般地,对网络处理器分为4 个层次,即硬件指令层、模块任务层、应用功能层和系统平台层来进行性能评估.通过在每一个层次上逐步分析,可将多级并行的系统性能评估问题转化为简单的串行程序性能分析,或者是简单的并行程序性能分析[111].在这种评估模型的基础上,利用网络测试设备搭建相关拓扑,连接测评仪器、控制器以及NP 芯片(原型系统)开始测评被测设计性能.对于芯片数据包的处理能力的评测,一般采用M/M/1 排队模型进行评估,利用流量生成器完成流量生成.接口驱动模块负责将数据流发送给被测NP.NP 将处理后的数据发送给平台的接口响应模块.最后,接口响应模块将数据发送给相应评测模块,模块内置了相关算法对正确性和性能进行统计评测.
现有的网络测试设备厂商一般有思博伦、安捷伦、IXIa 等.一般地,NP 芯片的性能测试组网方式如图3 所示.图3 中,PC 机通过串行COM 接口对网络处理器进行配置和管理.其硬件编译环境通过JTAG(joint test action group,联合测试工作组)接口与网络处理器相连进行调试诊断.测试仪产生、发出以及接收流量也由PC 机进行控制,测试仪与网络处理器原型之间通过万兆Ethernet 接口进行流量传输、测试.针对上述产品,本文搭建了相关测试平台,购买并测试了C5,NP4GS3 和IXP42X 这3 款NP 的吞吐率以及处理时延.吞吐率为测试仪线速发送测试报文得到的速率统计信息,时延为利用测试仪时间统计功能得到的报文从发送到返回所消耗时间的一半.对于刚刚上市、价格昂贵无法购买的下一代网络处理器,本文通过查询企业产品手册、相关文献等对结果进行了统计.测试与统计结果展示于表3.
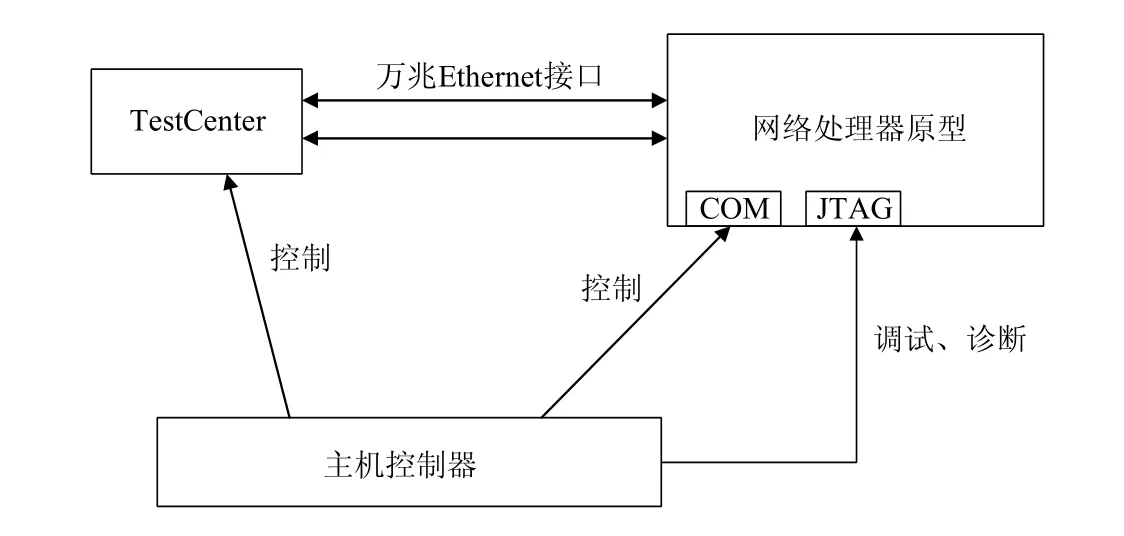
Fig.3 NP testbed图3 NP 性能测试床
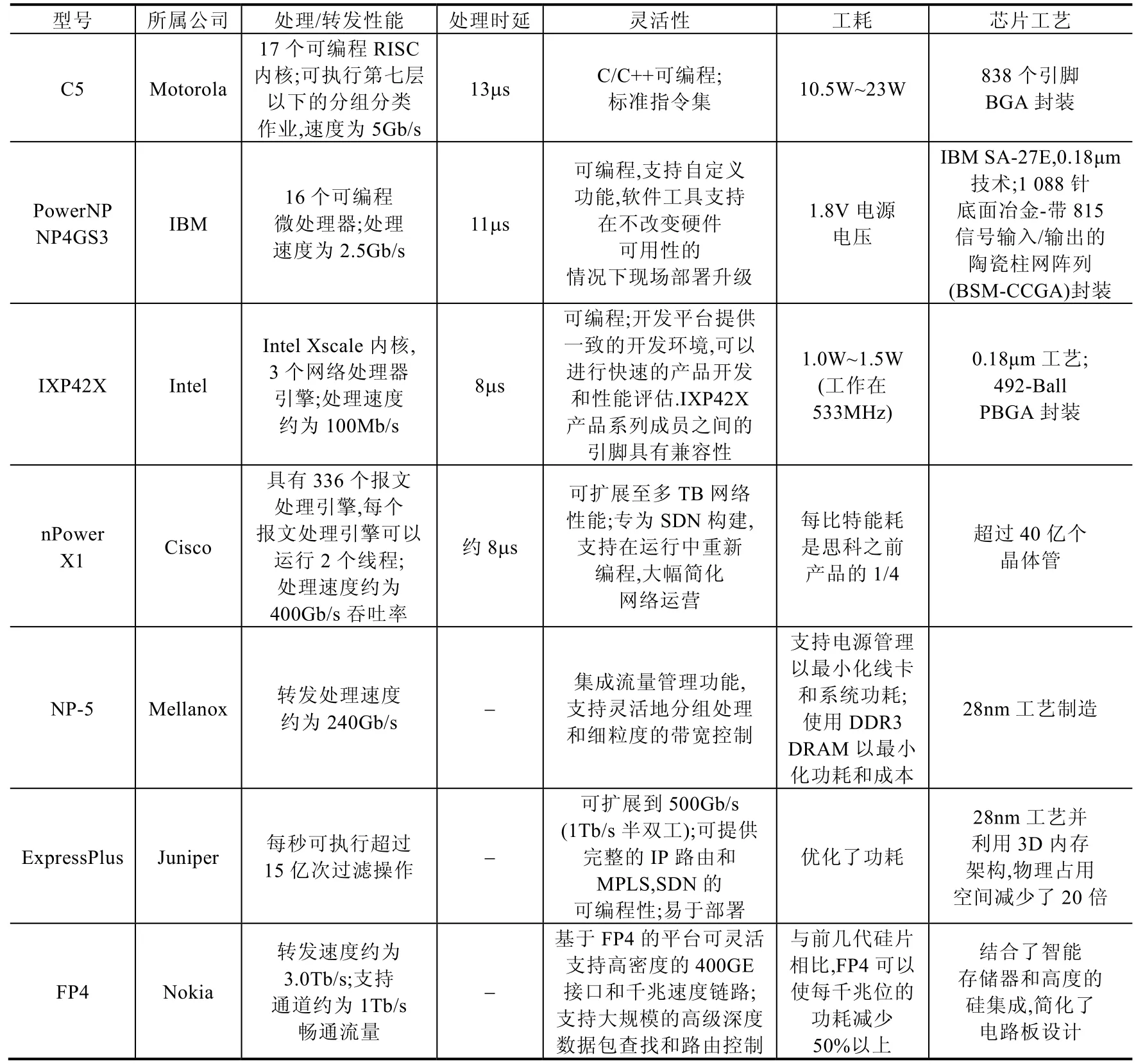
Table 3 Performance of some network processor products表3 部分网络处理器产品性能
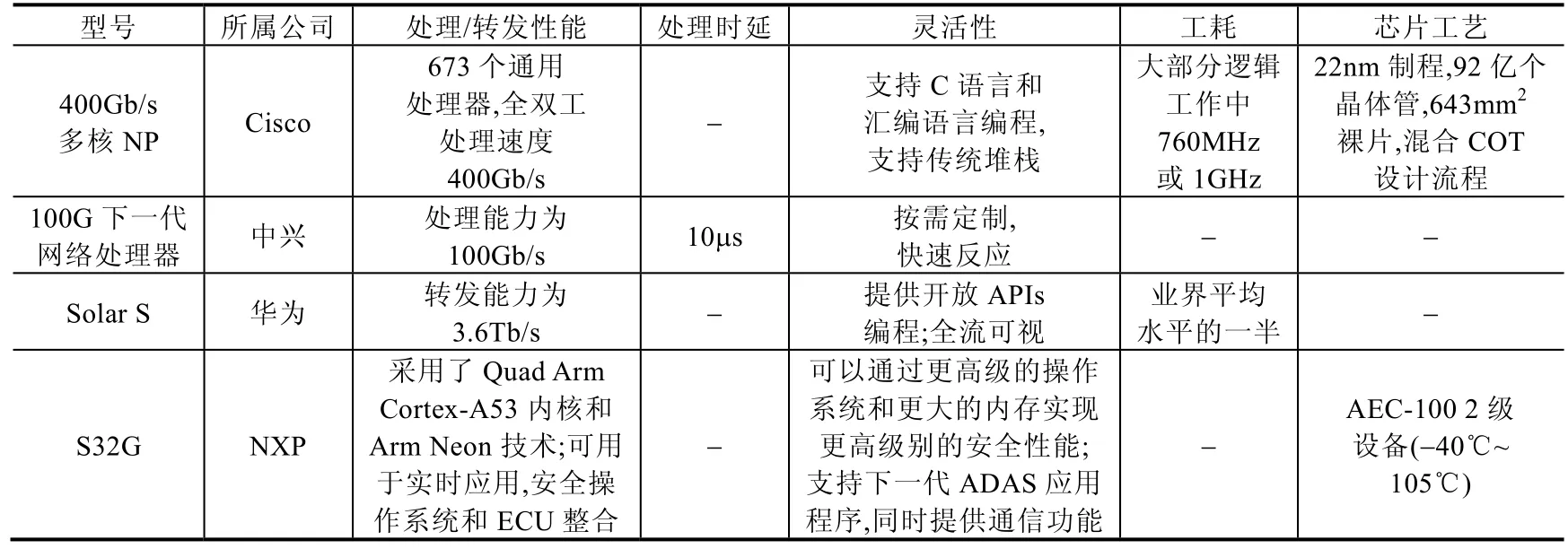
表3 部分网络处理器产品性能(续)Table 3 Performance of some network processor products (Continued)
6 未来发展趋势
尽管目前的网络处理器都考虑了可编程性和处理转发速度,但是没有在顶层设计上兼顾灵活和性能[112].网络处理器可编程性多是借助开发平台或者是使用语言的先天属性,在此基础上调整相关数据平面控制平面的处理架构、元器件编排方式以及业务处理流水等,导致灵活和性能总是无法收敛到最优程度[113].
6.1 高性能可演进下一代网络处理器架构
为了解决上述问题,下一代网络处理器应当朝着高性能、可演进的融合架构方向发展.针对处理优化和应用加速等高性能要求,融合架构的研究应当包括多级分组缓存管理框架、CPU 分组调度方法、可动态重构的应用加速等方面.一方面优化改进网络处理器基础设计架构;另一方面,则面向业务应用的加速进行实现[114],并为上层提供相应的基础开发接口.在这种架构下,网络处理器的接口线速和转发能力都被良好地设计和实现.融合架构的可编程性、可演进性主要体现在硬件资源管理和可扩展API 编程接口的研究.基于上述优化加速的平台架构,下一代网络处理器应当为用户提供高效、良定义、可扩展的API 接口和开发模型,支撑上层业务应用的开发.提供平台无关的API 接口、支持高级语言编程不仅方便了业务应用开发周期,也使得所设计的网络处理器的场景适应能力增强.在当前网络技术和人工智能结合的发展热点下,融合架构能够拥有足够的资源将部分学习方法卸载进入网络处理器,细粒度、高效率地实现包转发处理.
现有的网络处理器通常基于多CPU 核加硬件协处理器阵列架构实现,加解密、查表等协处理器以ASIC 电路形式实现,可以有效提升网络处理器进行分组转发处理的性能.然而随着硬件协处理器开发周期长[115],且功能固定,难以满足网络处理可演化性需求以及面向多业务场景的应用需求.综上,本文提出了基于通用多核CPU加FPGA 的高性能可演进下一代网络处理器(high performance evolvable network processor,简称HPENP)架构.HPENP 设计的软硬件协同可扩展分组处理架构一方面利用通用多核CPU 的可编程灵活性和并发处理能力,支撑网络分组深度处理[116];另一方面,利用FPGA 具有的硬件可重构特性,支持数据平面处理及加速模块的按需部署[117].HPENP 具有转发模块与硬件加速模块的混合编排架构,可在此基础上实现基于模块ID 映射表的流水线功能动态扩展方法,有效支持软硬件功能的动态加载,提升网络处理器面向多场景的应用能力和未来新型业务协议的演化能力.
6.2 软硬件协同分组处理流水线
高性能可演进的下一代网络处理器体系结构基于通用多核处理器及可重构FPGA 硬件构建,其中的设计重点是实现软硬件协同的分组处理流水线.HPENP 支持CPU+FPGA 平台软硬件高效数据通信,并且利用转发模块与硬件加速模块的混合编排方法.设计采用可编程硬件流水线、硬件流水线扩展、软件模块扩展以及软硬件协同扩展这4 种方式提升网络处理器可编程及可演进能力,满足网络设备功能扩展的性能和灵活性要求.
如图4 所示,软硬件流水线均包含多个在CPU 上可按需动态加载的扩展模块,实现对不同处理功能的扩展.动态扩展模块一方面可以实现通用路由交换处理的“慢速路径”功能(如分片重组),也可扩展实现一些新的如按需部署的安全防护网络功能.可定制处理模块还可将目的IP 地址是本地的分组发送到控制平面处理.动态扩展模块和控制平面软件通过网络接口发送分组时,该分组首先会送给FPGA 中由可定制处理模块组成的硬件流水线处理.软件发出的分组可以对硬件流水线进行重入,进一步增加了下一代网络处理器处理的灵活性.由国产CPU 内搭载的协议栈、驱动以及内核等通过良定义接口实现用户空间的交互,完成扩展性能.
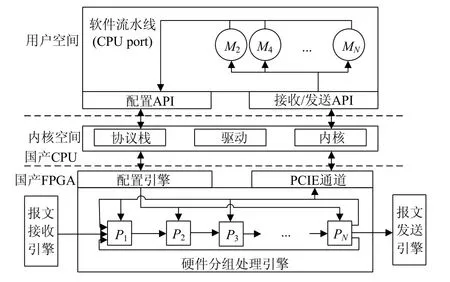
Fig.4 HPENP’s architecture图4 HPENP 体系架构
6.3 多级缓存与分组调度
HPENP 架构实现Cache、内存和外存相结合的多层次分组缓存管理,以打破“存储墙”问题对网络处理器系统性能瓶颈的影响.网络流量到缓存的调度与映射优化算法、多层次分组缓存动态管理与调度机制融入到了本架构设计中.借鉴计算机体系架构的多级缓存设计模型[118],基于CPU Cache、内存、FPGA 内部RAM 和DDR外存设计多层次存储框架实现多级缓存的分组统一管理与调度.针对突发数据流的可导致拥塞状况,HPENP 具备动态缓存分配方案,引用大容量DRAM 作为备用队列缓存存储溢出流量.
HPENP 支持基于多核分组路径感知的分组调度技术,如图5 所示.
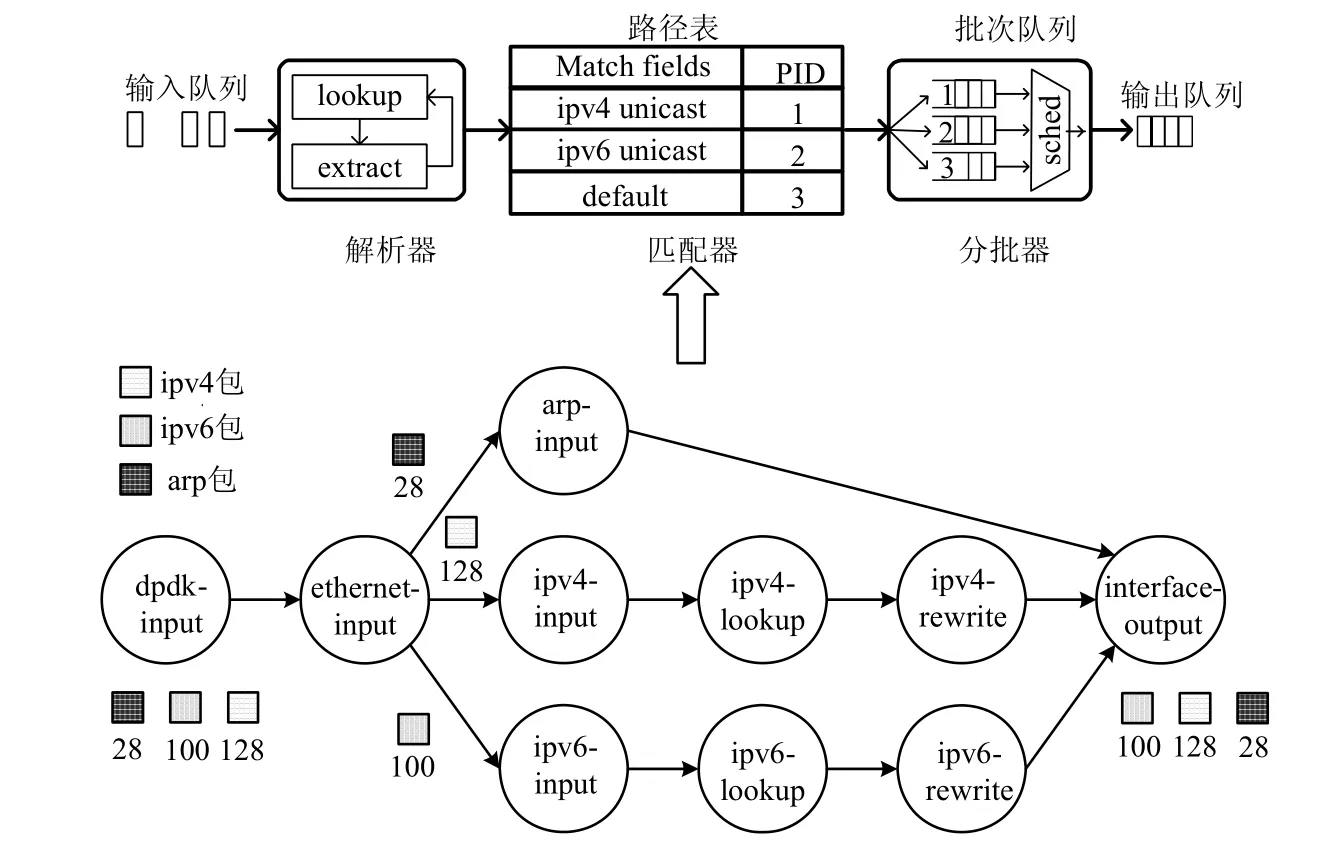
Fig.5 HPENP’s packet scheduling model图5 HPENP 分组调度模型
分组调度感知器按分组特征预先分类进入CPU 的分组,生成无处理分支的报文向量,以减少CPU TLB(translation lookaside buffer,转译后备缓冲器)和cache 失效.输入队列经过解析器、匹配器以及分配器进行分组的路径处理,以生成输出队列.各个硬件处理单元通过多项用户定义处理功能,降低分组IO 过程中的性能损失,提升并行化处理性能.
6.4 编程接口及进程实现
HPENP 将CPU 核、FPGA 逻辑资源、内外部存储资源进行统一抽象,并支持按需配置和动态分配,完成分组业务应用到系统各类资源的重构、映射与调度.HPENP 资源管理与编程接口主要研究层次化的资源管理和可扩展API 编程接口,基于优化的网络处理器平台架构,为用户提供可扩展API 接口和开发模型,支撑上层业务应用的开发.分层处理结构分为内核态与用户态两个部分,每一部分都是一个完整的开发环境,分别包含内核态开发环境库和用户定义开发环境库.在每一个开发环境中都分为3 层:底层通信模块、中间适配模块和上层应用模块.由于提供多层次封装编程接口,高层接口可以最大限度屏蔽底层硬件资源的感知[119],完善底层接口支持对系统的深度调优.
一般地,NP 进程包括ACL(advanced C library,跨平台C 语言库)线程、路由线程、编排调度、数据响应/请求、协议栈响应/请求以及控制响应/请求线程.HPENP 进程中,线程间通信使用自定义msg 消息,由编排调度负责具体搬运.每个NP 平台服务线程都有两个队列,分别是rxq 输入队列和txq 输出队列.所有线程的服务拥有唯一标识号用以认证该线程的身份.具体如图6 所示.
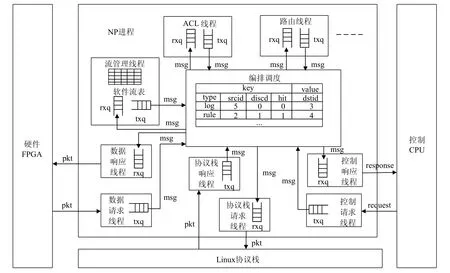
Fig.6 NP process implementation architecture图6 NP 进程实现架构
6.5 基于HPENP的在线智能测量及应用
基于HPENP 架构,在线智能测量业务能够完备地满足当前智能网络管理、网络监控以及网络安全等多方面业务的基础处理需求[120].用户可以在路由器上利用自定义功能(测量、审计、加解密等),使用HPENP 中扩展的API,直接在NP 上开发相关的加速逻辑,实现基于测量的在线统计分析和机器学习功能.
在线智能测量作为各项网络业务的基础,需要满足自适应粒度的调控.在搭载下一代网络处理器的路由器上加载自适应测量调度控制器,其根据所在网络环境中网络状态和测量任务自适应的调整测量粒度,结合主动与被动测量,对链路时延、网络带宽、丢包率、网络拓扑等进行探测以及结构化的描述.HPENP 可以加速面向多测量任务的动态调控,将测量的数据层和控制层功能进行分离.控制器通过了解各个节点的当前流量状况,全局编程调配网络测量体系结构,以进行测量任务的优化调度.通过扩展的API 实现被动轮询和主动探测的结合,审计动态网络的视图状态.通过各项软硬件资源,建立网络环境中地址资源、流量资源表示模型,建立网络拓扑表示流量矩阵的多维动态资源视图,完成流量统计分析.通过统计分析提取网络状态特征,利用机器学习功能弹性智能的判断网络状态,完成寻路应用等场景.
6.6 HPENP原型系统构建与测试
针对上述HPENP 的架构设计,本文将FPGA 和CPU 等按照设计在PCB 板上编排,采用国产麒麟操作系统,利用标准的19 英寸的机箱构构建了HPENP 的初步原型系统.原型系统如图7 所示.

Fig.7 HPENP prototype system图7 HPENP 原型系统
图7 中,FPGA 模块主要用于流量输入解析处理和流量输出整形调度,可扩展流水线与存储模块相关联.CPU 为4 核处理器,处理器阵列利用分组感知调度模块提高整体核间亲和性,尽量减少处理分支,保证整体性能.
为了测试上述原型系统性能,本文利用IXIa perfectstorm one 测试仪,按照如图8 所示的拓扑方式搭建了实验环境,对HPENP 原型系统相关性能进行测试.实体测试环境如下.
原型系统测试主要是网络交换基础能力测试,其包括接口指标、转发性能指标等等.针对原型系统的千兆和万兆的接口测试,本文使用了网络测试仪对千兆一套网口进行性能测试,设置使用千兆速率发送随机长度报文1 亿个,设备开启网口回环功能后,网络测试仪的收发报文数量一致.针对原型系统的共计10 个千兆网口用于测试交换能力,通过主机管理系统,将千兆接口的转发设置为相邻端口转发.为了验证每秒最大bit 传输率,在网络测试仪中,将与设备相连的2 路万兆和2 路千兆配置了每个网口的测试报文长度为1 518 字节,设置报文数量为1 亿个.通过长时间测试统计,确定其交换稳定不丢包,从而可得所有网口都是线速转发.针对分组转发率指标,测试在网络测试仪中将与设备相连的2 路万兆和2 路千兆配置每个网口发送报文长度为64 字节的1 亿个报文.启动网络测试仪后,线速发送测试报文,观察并统计测试仪各网口的速率统计信息,汇总统计结果,并计算转发能力,得到原型系统拥有30Mpacket/s 的分组转发率.针对流水线时延,利用网络测试仪的报文时间统计功能,用测试仪的一个网口发送报文,中间经过测试设备转发,然后在另一个网口回环,得到了一个报文从发送到返回经历路径的延迟,从而设备端到端的延迟为28μs.具体结果见表4.

Fig.8 HPENP prototype system performance test environment图8 HPENP 原型系统性能测试环境

Table 4 Basic performance test results of prototype system表4 原型系统基础性能测试结果
为了验证原型系统的可编程性,本文利用原型系统的用户态编程,通过定义软件模块的流表,对不可信的外部网络进行了规则约束,搭建了简易的网络安全防火墙,并建立了测试拓扑对相关功能进行验证.测试实验拓扑如图9 所示.
在HPENP 原型系统上,本文设置了一条包过滤的防火墙安全策略,并在内部主机C 上启动抓包工具,配置抓取本机接收的所有报文.原型系统启动后,初始状态下,其包过滤防火墙功能默认不允许报文通过,此时,外部主机D构造的报文无法发送到内部主机C,抓包工具无法抓取到外部主机D发送的报文;通过用户态控制器,向原型系统下发一条源MAC 地址为主机D、目的MAC 为主机C、源IP 为主机D、目的IP 为主机C、协议为UDP、动作为“允许”的五元组包过滤防火墙规则.继续发包后发现,外部主机D构造的报文成功发送到内部主机C,抓包工具也成功抓取到外部主机D发送的UDP 报文.说明原型系统被成功部署防火墙,能够按需进行相关业务的逻辑编程.
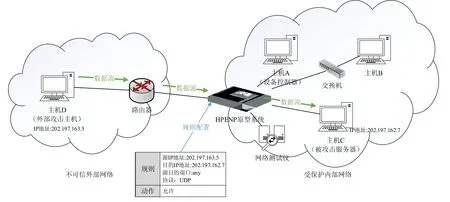
Fig.9 HPENP programmable function test图9 HPENP 可编程性功能测试
上述结果表明:HPENP 的设计理念合理,具备高性能、可演进的优势,能够较好地兼顾灵活性和处理转发性能.相信经过进一步的研究和学习,能够完善原型系统的各项功能,升级相关架构,为下一步的处理器芯片化做好充足的准备.
7 总结
网络处理器的设计与研究,一直是通信、网络传输领域的重点问题.硬件协处理器开发周期长、功能调整不灵活的特点,导致多样分组处理可演进化需求在网络处理器中无法满足.所以,下一代网络处理器体系架构一直受到研究人员的广泛关注.针对这一背景,本文首先梳理了网络处理器的基本架构及其在当前网络环境下的发展挑战,其次介绍了利用新型可编程技术、面向新型网络体系结构、针对新型高性能业务这3 个层面的业界学术界主流NGNP 设计模式,并对不同的架构方案进行了分析和比较,指出它们的优点及不足,结合网络处理器的工业化进程,得到了相应的结论.
我们认为,下一代网络处理器研究及设计方案应当遵从以下几点意见.
(1) 体系架构高性能可演进.当前网络由超高带宽反哺出对网络处理器的多样化分组处理需求.网络处理器体系架构设计首先考虑高性能的处理分组,进行包解析、包分类以及元数据提取存储等操作的同时完成高速转发,实现通信转发.同时,架构应当包含可动态重构硬件完成业务灵活配置,利用软硬件协同扩展的编程方式实现网络处理器的可演进性.
(2) 分组处理可加速可优化.体系架构给予支撑,技术细节完善性能.下一代网络处理器设计应当在核间调度、多级缓存、并行处理等关键技术上有所突破,规避处理器核内大量路径分支处理开销和核间负载不均衡带来的性能损失问题.在突发流量到来时能够导流溢出流量,减少拥塞时间,高效转换地址映射,及时转发处理分组.
(3) 硬件资源按需配置.抽象硬件资源,精准动态分配.CPU 核、FPGA 或者其他可重构逻辑资源、缓存资源应当进行统一管理,抽象成表按需、动态配置相关业务.利用业务应用到系统各类资源的重构、映射与调度算法,提高下一代网络处理器处理性能,扩展应用场景.
(4) 编程接口底层无关.开发环境决定使用效率.下一代网络处理器借助关系明了的开发编程接口、清晰划分的功能模块和流程规范的数据处理,完成可视、透明以及简单的业务逻辑开发与调试.软硬件通信的底层模块提供相应的API 接口,帮助内核态分组转发设备驱动进行应用适配.向下使用底层API实现控制,向上丰富通信开发接口对应应用需求.
(5) 搭载应用智能高效.高效精准的各项网络应用需要分组处理与转发的智能化.利用下一代网络处理器的硬件资源,全局编程调配各项业务.通过存储的动态多维资源视图,完成搭载应用的学习功能,实现自适应高性能的流量转发、视域测量、网络安全、QoS 保障等业务.
针对这些特点,我们提出了高性能可演进的下一代网络处理器体系结构HPENP,介绍了软硬件协同分组处理流水线、多级缓存与分组调度、资源管理及编程接口的相关设计方案,提出了基于下一代NP 的在线智能测量及应用,并搭建测试了HPENP 原型系统.目前,国内外有关网络处理器的研究与设计处于快速发展阶段,虽然早期已有许多设计被产业化并大量应用,但当前也存在一些初步涉及的重要研究点.本文希望通过大量研究工作的讨论比较以及新型体系架构的设计,为下一代网络处理器的未来工作提供参考与建议.
致谢本文的匿名评阅者对文章内容,特别是对下一代网络处理器中高性能可演进方面的完善提出了许多建设性的意见和建议,在此表示感谢.
