深度伪造与检测技术综述*
2021-03-06李旭嵘纪守领吴春明刘振广邓水光孔祥维
李旭嵘 ,纪守领 ,吴春明,3 ,刘振广 ,邓水光 ,程 鹏 ,杨 珉,孔祥维
1(浙江大学 计算机科学与技术学院,浙江 杭州 310007)
2(阿里巴巴,浙江 杭州 311121)
3(之江实验室,浙江 杭州 310000)
4(浙江工商大学 计算机与信息工程学院,浙江 杭州 310018)5(浙江大学 控制科学与工程学院,浙江 杭州 310007)
6(复旦大学 计算机科学技术学院,上海 201203)
7(浙江大学 管理学院,浙江 杭州 310007)
近年来,以Deepfakes[1]为代表的换脸技术开始在网络兴起.此类技术可将视频中的人脸替换成目标人物,从而制作出目标人物做特定动作的假视频.随着深度学习技术的发展,自动编码器、生成对抗网络等技术逐渐被应用到深度伪造中.由于Deepfakes 技术只需要少量的人脸照片便可以实现视频换脸,一些恶意用户利用互联网上可获取的数据,生成众多的假视频并应用在灰色地带,如将色情电影的女主角替换成女明星,给政客、公司高管等有影响力的人伪造一些视频内容,从而达到误导舆论、赢得选取、操纵股价等目的.这些虚假视频内容极其逼真,在制作的同时往往伴随着音频的篡改,使得互联网用户几乎无法鉴别.如果这些深度伪造的内容作为新闻素材被制作传播,这会损害新闻机构的声誉和公众对媒体的信心.更深层次的,当遇到案件侦查和事故取证时,如果缺乏对Deepfakes 类虚假影像资料的鉴别,将对司法体系产生巨大的挑战.尽管深度伪造技术有其积极的一面,如“复活”一些去世的人进行影视创作,以及Zao APP[2]提供大众换脸娱乐服务等,但是目前负面影响远远大于正面,拥有鉴别此类深度伪造视频的能力变得尤为重要.
为了尽量减少深度伪造技术带来的影响,消除虚假视频的传播,学术界和工业界开始探索不同的深度伪造检测技术.相继有学者构造数据集,展开对Deepfakes 检测的多角度研究.脸书公司也联合微软一起举办全球Deepfakes 检测竞赛[3]以推动检测技术的发展.然而这些Deepfakes 检测工作各有侧重,存在众多局限性.针对本领域的综述工作还比较缺乏,只有针对早期图像篡改工作的一些总结[4,5],亟需对现有工作进行系统的整理和科学的总结、归类,以促进该领域的研究.
本文第1 节介绍深度伪造的各种相关技术.第2 节列举出当下深度伪造研究的数据集.第3 节对现有的深度伪造检测技术进行系统的总结和归类.第4 节讨论深度伪造生成和检测技术的双面对抗性.第5 节总结面临的挑战和未来可行的研究方向.最后,第6 节对全文的工作进行总结.
1 深度伪造生成技术
现有的深度伪造图像主要是指脸部的篡改,而脸部篡改伪造主要分为两大类:一类是换脸伪造,通过交换两张图像的人脸达到人身份修改的目的,其技术从传统的3D 重建方法发展到现在以生成对抗网络为基础的深度伪造;另一类是脸部表情属性伪造,迁移指定表情等动作到目标图像而不修改目标人脸标志,达到伪造表情或者特定动作目的,其技术也从基于3D 的图形学方法演变到最新的深度学习方法.此外,制作深度伪造素材时通常还包含了语音的伪造,使得欺骗效果更佳.本节将对这些伪造生成技术进行概述,其中重点关注深度伪造技术,并总结了一些开源的生成工具.
1.1 换脸伪造技术
1.1.1 基于图形学的伪造
在过去10 多年里,基于图形学的人脸篡改技术一直被研究者所关注,Zollhofer 等人[6]综述了当前比较主流的3D 模型重建追踪等技术.FaceSwap[7]是基于图形学的换脸方法,首先获取人脸关键点,然后通过3D 模型对获取到的人脸关键点位置进行渲染,不断缩小目标形状和关键点定位间的差异,最后将渲染模型的图像进行混合,并利用色彩校正技术获取最终的图像.Kevin 等人[8]提出了在视频里自动换脸的3D 方法,不需要大量的手动操作和硬件采集,只需要一个单相机视频,通过用3D 多线性模型追踪视频中的人脸,并用相应的3D 形状将源人脸仿射到目标人脸.Pablo 等人[9]用类似的3D 方法来替换目标视频中演员的人脸,而保留原始的表情.Pablo等人[10]还设计了一个系统,通过高质量的3D 人脸捕捉技术,改变人脸从而匹配嘴巴的动作.Nirkin 等人[11]用分割的思路促进换脸,通过网络分割出来的人脸估计3D 人脸形状,最后融合源和目标这两个对齐的3D 人脸形状.
1.1.2 基于学习的伪造
尽管基于图形学的脸部篡改方法研究了多年,但是时间开销大、门槛高、成本大,使得这项技术很难普及.随着深度学习技术的飞速发展,研究者们开始关注深度学习在人脸篡改上的应用[12].Deepfakes[1]是网络上较早开源的基于深度学习的换脸项目,如图1 所示,训练两个自动编码器,两个编码器共享权重参数,使得两个解码器学会重建人脸的能力.训练结束后,在换脸阶段,交换两个解码器,从而使得换脸效果达成.这只需要具备原人物和目标人物的人脸图片即可训练,大大降低了使用门槛.但是也需要一定的训练技巧,否则生成器的生成质量无法保障.鉴于此,研究者们开始关注GAN[13]技术的融合,Faceswap-GAN[14]就是增加了GAN 技术的Deepfakes,引入判别器的对抗损失函数,在生成的时候判别生成图像和原图的相似度,使得生成的图像质量有大幅度提高,另外引入了感知损失函数增加眼珠的转动效果.GAN 技术的加入使得换脸更加逼真自然,也一定程度增加了深度伪造技术的流行度.
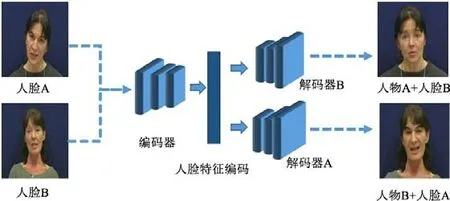
Fig.1 Framework for Deepfakes generation[1]图1 Depefakes 生成框架[1]
Korshunova 等人[15]将换脸问题视为风格迁移问题,训练一个卷积神经网络,从非结构化的图片中学习这种外观,并设计内容损失和风格损失函数来保障生成高质量真实度的人脸图像.这些人脸转换还是依赖于大量的源和目标人物的人脸图片训练,泛化性不强.Yuval 等人[16]基于GAN 技术提出了一个主体无关的人脸替换和重建方法,通过引入特定域感知损失、重建损失和对抗损失,可以应用于成对的人脸,不需要在大量人脸上训练.除换脸外,GAN 技术还被广泛用于生产虚拟的人脸和篡改人脸属性.如StarGAN[17]、Stackgan[18]、PGAN[19]等一系列GAN 技术可以生成虚假的人脸,Grigory 等人[20]利用conditional-GAN[21]技术改变人的年龄,Rui 等人[22]利用GAN 生成不同的人脸视角而保持全局的结构和局部细节.GAN 技术的发展使得人脸的生成和属性篡改都越来越真实,这也给人脸伪造的滥用留下了空间.
1.2 表情伪造技术
表情伪造是指不改变人脸的属性,迁移其他人脸图像的表情到目标人脸,从而达到目标人物做指定表情的目的.Thies 等人[23]基于一个消费级的RGB-D 相机,重建、追踪源和目标演员的3D 模型并最后融合,从而进行实时的表情迁移.另外,Thies 等人[24]提出了Face2Face,通过利用3D 重建技术和图像渲染技术,能够在商业视频流中进行人脸移动表情的修改.Head on[25]通过修改视角和姿态独立的纹理实现视频级的渲染方法,从而实现完整的人重建方法,包括表情眼睛、头部移动等.Kim 等人[26]利用含有时空架构的生成网络将合成的渲染图转换成真实图,并能迁移头部表情等动作.尽管现有的图形学方法可以较好地合成或重建图像,但是严重依赖于高质量的3D 内容.Thies 等人[27]提出了延迟神经渲染的框架,与渲染网络一起优化神经纹理而生成合成的图像,此方法可以在不完美的3D 内容上操作.Suwajanakorn 等人[28]利用循环神经网络建立语音到嘴型动作的映射,可以匹配输入的语音合成嘴型指定纹理动作.此外,还有针对人物特写镜头中的图像合成[29,30]、基于2D 仿射的源演员表情匹配[31]、基于网络编码空间的属性修改的表情迁移[32]等相继被研究者提出,不同场景的表情伪造技术日益成熟.
1.3 语音伪造技术
语音伪造也叫做语音版 Deepfakes,利用 AI 技术合成虚假语音.通常有文本到语音合成(text-to-speech synthesis,简称TTS)和语音转换(voice conversion)两种形式:文本到语音合成主要完成指定文本的语音信息输出,而语音转换是指转换人的音色到目标音色.这些语音的合成不仅可以欺骗人的听觉,还可以欺骗一些自动语音认证系统.早期的语音合成主要依赖隐马尔科夫模型和高斯混合模型,而随着深度学习技术的发展,语音合成和转化技术的质量有了大幅度提高.来自谷歌的Oord 等人提出了WaveNet[33],这是第一个端到端的语音合成器,一种基于音频生成模型,能够产生于人相似的音频.相似的文本到语音合成系统有 Deep voice[34]和Tacotron[35],均在原始语音材料上训练,速度比WaveNet 更快.随后,百度对Deep voice 进行了扩展,提出了Deep voice2[36],通过使用低维度可训练的说话者编码来增强文本到语音的转换,使得单个模型能生成不同的声音.Ping 等人提出的Deep voice3[37]进一步改进了之前的Deep voice 系列,Deep voice3 是一个基于注意力机制的全卷积TTS 系统,通过设计字符到频谱图的结构,能够实现完全并行的计算,在不降低合成性能的情况下,速度更加快.Santiago 等人[38]则利用GAN 技术对语音的噪音进行过滤,提高了生成语音的质量.Chris 等人[39]提出了无监督音频合成模型,能够从小规模语音库中学习生成可理解的词汇.语音合成技术愈发成熟,且与视频中的换脸伪造往往同时出现,使得鉴别的难度更大.
1.4 开源工具与商业软件
随着对深度伪造生成技术的深入研究,网络上逐渐出现了众多开源软件和商业应用.已有文献[40]做了部分总结,但是不够全面.本文对其进行扩充和比较,结果见表1,主要分为人脸伪造和语音伪造.其中,人脸伪造主要分为两类:一类是以Faceswap 为代表的在GitHub 网站上开源的伪造项目,此类项目均是对原始项目进行改进,或在新的深度学习框架下实现;另一类是商业化的APP,如Zao[1]、FakeAPP[41]、FaceApp[42]等提供换脸、修改表情或者人类属性等功能.网上开源软件需要使用者对深度学习相关知识比较熟悉,需要使用者拥有一定数量的人物图像并在GPU 上进行训练,训练的稳定结果取决于使用者的专业水平.而商业化软件的使用门槛很低,只需使用者上传一张图像就可以实现伪造目的.其中,FakeAPP 需要用户安装在有GPU 的电脑上使用.总的来说,开源软件使用复杂,适合专业人士,并对生成效果进行改造;而商业软件适合大部分普通非专业用户,但是生成效果也取决于开发软件的公司或组织.语音合成伪造已逐渐成熟,被大多数云服务厂商开发为接口服务向大众开发,这里选取有代表性的软件展示.这些软件的流行和传播使得深度伪造变得更加低门槛、大众化,也进一步加剧了恶意用户带来的负面影响.
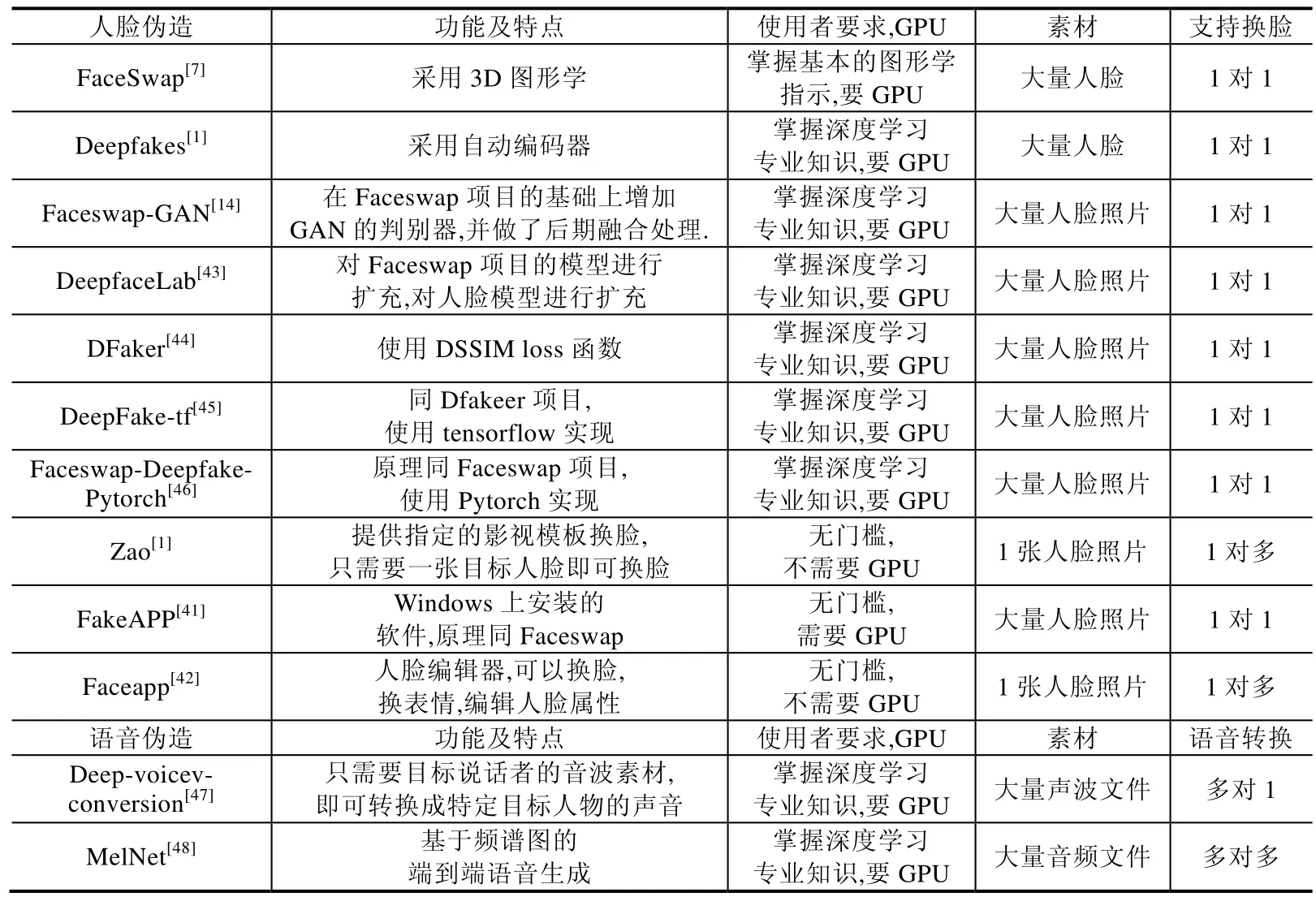
Table 1 Summary of Deepfakes tools表1 深度伪造工具汇总
2 深度伪造数据集
随着深度伪造的泛滥,研究人员开始了针对这些伪造视频、图像和语音的研究,逐渐有新的数据集被开源以促进此领域的研究.数据集的质量和规模对深度伪造领域的研究尤为重要,学术界和工业界均开源了部分数据集以促进该领域的研究.本节将逐一介绍这些数据集(见表2).
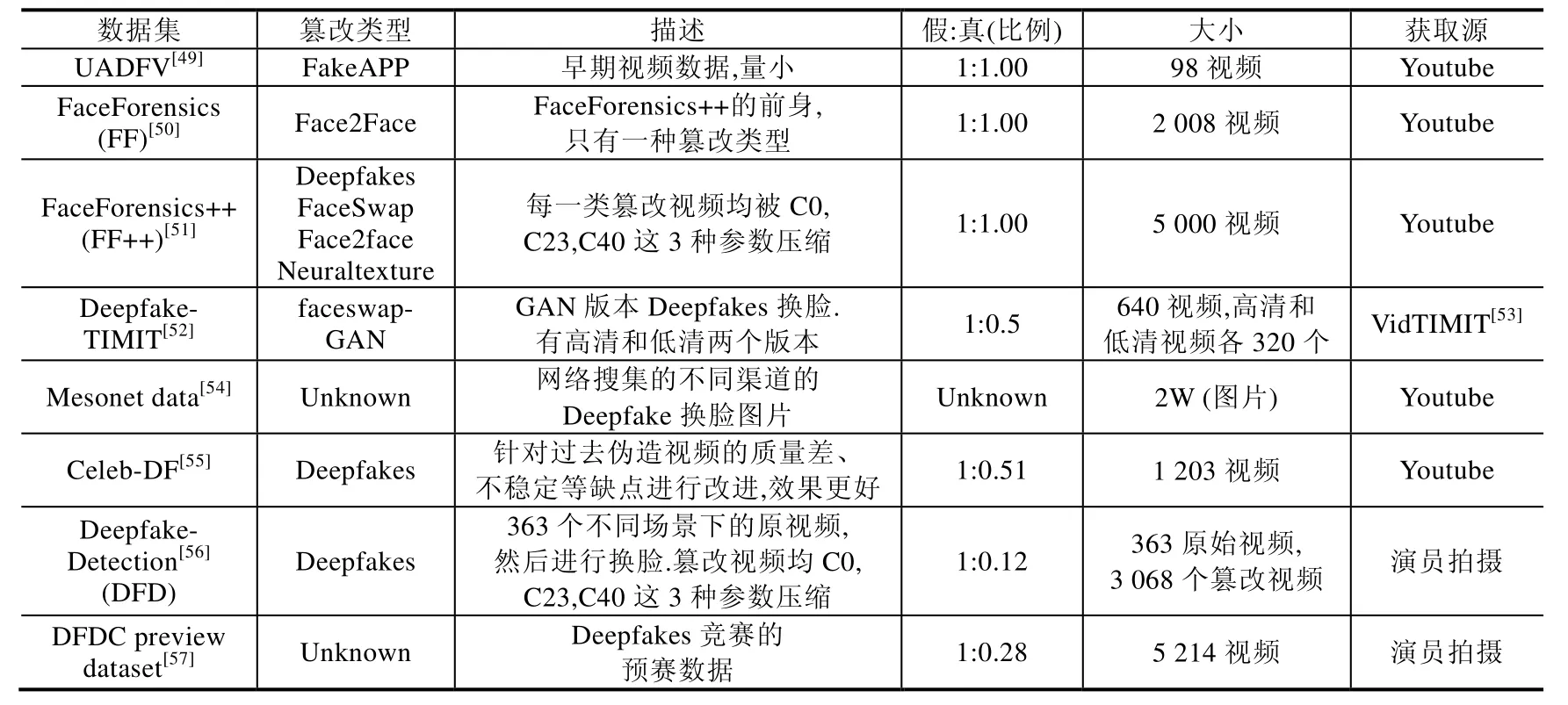
Table 2 Open source dataset of the Deepfake表2 深度伪造开源数据集
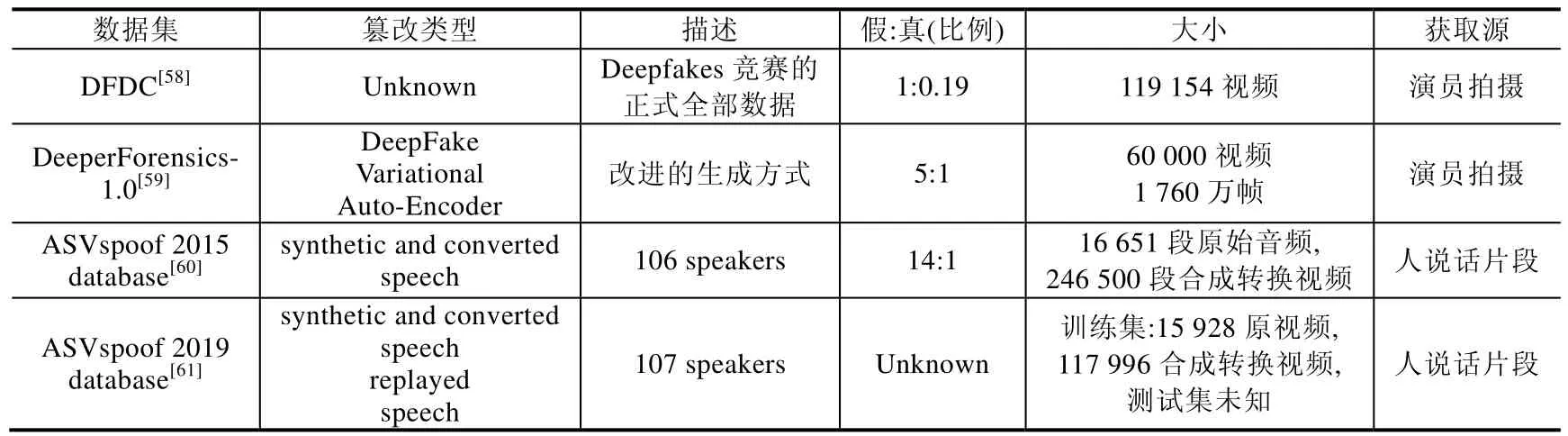
Table 2 Open source dataset of the Deepfake (Continued)表2 深度伪造开源数据集(续)
2.1 深度伪造视频数据集
· UADFV:此数据集素材取自YouTube,分别有49 个真实视频和49 个合成视频,合成视频由FakeAPP[41]生成,每个视频的平均长度是大约11s.然而,作为早期深度伪造研究的数据集之一,视频分辨率较低、生成质量差,有较明显的换脸痕迹,数量规模过于少,篡改类型比较单一.
· FaceForensics(FF):早期的大规模深度伪造数据集之一,素材来源于Youtube8M[62],选取该数据集中标签为人脸、新闻播报员、新闻联播的视频以及YouTube 上有类似标签的视频共1 004 个,所有选取的视频分辨率大于480p.除此之外,作者用人脸检测器抽取视频中的人脸序列,确保所选视频连续300 帧中含有人脸,并手动过滤掉人脸遮挡过多的视频以确保视频质量.最后,采用Face2Face 的换表情的方法构造1 004 个假视频.此数据集视频规模大、源视频人脸质量高,但是篡改痕迹明显,篡改方式单一.
· FaceForensics++(FF++):目前较大规模、种类最多的深度伪造数据集之一.素材与FaceForensics 相似,取自YouTube 的1 000 个视频.在筛选素材的过程中,同样用人脸检测器进行检测,确保连续帧含有人脸,并手动过滤掉人脸遮挡过多的视频以确保视频质量.在这个数据集中,作者共采用4 种类型的人脸篡改来制作假视频.
➢ Deepfakes:采用基于自动编码器的Deepfakes 方法实现,训练一对一的生成模型,可以实现一对一的换脸.
➢ Face2Face:采用Face2Face 方法实现.
➢ FaceSwap:采用FaceSwap 方法实现,基于3D 图像的方法.
➢ Neural Textures:利用延迟神经渲染网络优化纹理的方法实现.
其中,Deepfakes 与FaceSwap 属于换脸伪造,Face2Face 与Neural Textures 属于换表情伪造.4 种类型均在1 000 个原始视频上生成对应的1 000 个假视频,并对真假视频均做了H.264 codec 压缩方式中的C0、C23、C40 这3 种压缩水平的压缩.另外,数据集中还提供了对应人脸篡改位置的mask.然而这些篡改的质量不是很高,人眼能明显观察出篡改痕迹,修改的轮廓很明显;同时,在合成的假视频中还存在人脸闪烁现象.
· Deepfake-TIMIT:由Faceswap-GAN 方法生成,是第一个GAN 版本的Deepfakes 数据集.源数据是在VidTIMIT 中选取的32 个人(16 对相似的人)两两相互替换组成的视频,每个人有10 个动作视频,生成的假视频有高清(128×128)和低清(64×64)两个版本,共有640 段假视频.生成质量比FaceForensics++要好,但是视频分辨率不高,在脸部边界处有少量痕迹.
· Mesonet data:早期深度伪造研究数据集,数据量较小,由YouTube 渠道搜集的网络爱好者制作的伪造视频与图像.
· Celeb-DF:针对UADFV、FaceForensics++、Deepfake-TIMIT 等数据集的一些缺陷,如图片分辨率不高、合成的视频质量差、篡改痕迹粗糙、视频人脸闪烁感过多等缺陷,对Deepfakes 生成方法进行改进,增大生成图像的大小,并在训练阶段增加色调亮度、对比度等,以减小篡改区域与周边区域的不一致性.此外,使用更加精准的人脸关键点定位信息减轻人脸闪烁现象.数据集由从YouTube 渠道下载的408个原始视频和生成的795 假视频组成,视频的平均长度是13s,帧率是30.
· DeepfakeDetection(DFD):为了填充深度伪造数据的多样性,谷歌公司征集28 个演员拍摄了363 个原始视频,并将这些视频截取成一个个场景不同的片段,最后对这些片段进行相互换脸,生成3 068 个假视频.同样,此数据集也提供了H.264 codec 压缩方式中的C0,C23,C40 这3 种压缩水平的压缩版本.
· DFDC preview Dataset:为了推进深度伪造领域的研究,Facebook 举办了 The Deepfake Detection Challenge,在比赛前夕公开了预赛数据集,由5 214 个视频组成,真假比例1:0.28,原始视频均由66 个演员拍摄而成,假视频有两种篡改方式,大量的替换在相似人脸之间进行,如皮肤颜色、头发、眼睛等.每个视频均是15s 左右的小片段.
· DFDC:The Deepfake Detection Challenge 的正式数据集,共有119 196 个视频,真假视频比例约为1:5.原始视频均由演员拍摄,视频长度约为10s.视频分辨率跨度很大,视频场景涵盖了多种复杂场景,如黑人黑背景、侧脸、走动、强光、多人等.
· DeeperForensics-1.0:为了应对深度伪造研究数据量少的问题,南洋理工大学和商汤科技推出了大规模深度伪造数据集.研究人员从26 个国家收集了100 名演员的面部数据,演员在9 种灯光条件下转头做各种表情,并使用FaceForensics++中的1 000 个原始视频作为目标视频,其中,100 个演员的脸中的每一个都被交换为10 个目标.他们故意以35 种不同的方式扭曲每个视频,以模拟现实情况,从而最终数据集包含50 000 个未修改的视频和10 000 个修改的视频.
以上深度伪造数据集的示例如图2 所示.

Fig.2 Exmaples of Deepfakes datasets图2 深度伪造数据集示例
2.2 深度伪造语音数据集
· ASVspoof 2015 database
为了应对语音合成欺骗的攻击威胁,2015 年举办了第1 届自动说话人认证竞赛.该竞赛上开放了第一个大规模伪造语音数据集,以期发现多样的防御应对策略.数据集由10 种不同的语音合成和语音转换欺骗算法生成,包含原始的和欺骗的语音数据.原始语音是由106 个人(45 男与61 女)说话记录构成,这些记录没有噪音影响.其中,训练集由3 750 个原始话语片段和12 625 个欺骗话语片段组成,验证集由3 497 个原始话语片段和49 875个欺骗话语片段组成,测试集由9 404 个原始话语片段和184 000 个欺骗话语片段组成.
· ASVspoof 2019 database
2019 年,自动说话人认证竞赛包含了所有语音欺骗类型的攻击,如语音合成、语音转换、语音重放等.将攻击分类为两种场景:第1 种场景是逻辑访问,即直接将欺骗攻击的语音注入到自动说话人认证系统,这些语音由最新的语音合成和语音转换技术生成;另一种是物理访问场景,语音数据由麦克风等设备捕捉到,再经一些专业设备重放.这些语音数据由107 个人(46 男与61 女)说话组成,其中,训练集、验证集、和测试集分别由20,10,48个人的语音数据构成.测试集中的攻击类型与训练验证集中均不相同.
3 深度伪造检测技术
随着深度伪造技术的发展,互联网上充斥着大量包含伪造人脸和语音的虚假视频,Deepfakes 类技术的滥用带来巨大的负面影响,如损坏他人名誉、伪造证据、传播谣言,影响政客形象干涉选举等.这也吸引了一批研究者对深度伪造检测技术的重视.本节将综述现有的一些代表性检测工作,其中,前5 小节重点介绍研究较多的深度伪造视频检测,第6 小节概述伪造语音的检测工作,并在第7 小节对这些工作进行总结.
3.1 基于传统图像取证的方法
传统的图像取证初始主要是基于传统的信号处理方法,大多数依赖于特定篡改的证据,利用图像的频域特征和统计特征进行区分,如局部噪音分析、图像质量评估、设备指纹、光照等,解决复制-移动[63]、拼接[64]、移除这些图像篡改问题.而深度伪造视频本质也是一系列伪造合成的图片合成,因此可以将此类方法应用到深度伪造检测.Lukas 等人[65]提出了数字图像的相机设备指纹光响应不均匀性(PRNU),Chierchia 等人[66]进一步利用光响应不均匀性检测小的篡改图像.Jessica 等人[67]通过组装噪声分量模型提出了数字图像的隐写特征,随后,噪声特征被广泛运用在图像取证领域.此外,还存在诸多基于信号处理的取证方法,如利用JPEG 压缩分析篡改痕迹[68]、向JPEG 压缩的图像中添加噪声提升检测性能[69,70]、利用局部噪音方差分析拼接痕迹[71]、利用色彩过滤矩阵(color filter array,简称CFA)模型[72]进行篡改定位等.然而随着人工智能技术的发展,基于卷积神经网络的深度学习技术在诸多任务上均超过了传统方法,取证方法逐渐融合了机器学习方法特别是深度学习技术.此类方法检测成功率高,不依赖特定类型的篡改痕迹,比传统的信号处理方法鲁棒性更好.Cozzolino 等人[73]设计了一个孪生网络,在来自不同相机的图像块上训练来提取图片的噪音指纹,从而实现检测.Zhou 等人[74]提出了基于双流的Faster R-CNN 网络,其中,RGB 流主要从RGB 图像中输入提取特征,从而发现强烈对比差异与不自然的篡改痕迹;而噪音流利用噪声特征发现篡改区域与源区域的噪声不一致性.最后,融合两条流的特征进行学习两个模态空间的信息.利用深度学习技术提取关键取证特征的工作也被不断探究[75].Liu 等人[76]提出一个新的深度融合网络通过追踪边界来定位篡改区域.Minyoung 等人[77]通过训练照片所包含的相机EXIF 源数据指纹信息来区分图片是否被拼接.Xiaodong 等人[78]根据全局与局部块的特征不一致性学习一个半-全局网络实现拼接定位.Cozzolino 等人[79]提出使用卷积神经网络来学习基于残差的特征,此类特征可以有效提升取证检测和定位的性能.Chen 等人[80]则利用神经网络学习自然模糊和人为模糊带来的光直方图不一致性.Zhou 等人[81]将隐写噪声特征和卷积网络学习边界特征结合,提出了一个双流神经网络的方法.具体是用一个脸分类流训练一个GoogleNet[82]检测篡改的人工痕迹,利用捕捉的局部噪音特征和拍照特征训练一个基于块的三元组(triplet)网络,用这两条流的得分,综合判断是否图像被篡改.这是因为基于同一张图像的隐藏特征是相似的,距离小;不同图像的块之间的隐藏特征距离大,用三元组训练出块的距离编码后,用一个SVM 分类得到概率分数.
尽管基于取证的技术很成熟,但是在应对新的深度伪造视频时仍存在很多短板,因为此类伪造视频通常会被不同的后处理,如不同的压缩方式、不同的压缩率、不同的放缩合成.针对图片级的取证技术更多关注局部的异常特征,仍然应对乏力,很容易被绕过,并不能直接应用到日益升级的深度伪造视频检测上.
3.2 基于生理信号特征的方法
生成的伪造视频往往忽略人的真实生理特征,无法做到在整体上与真人一致,因此,基于生理信号的特征不断被研究者挖掘.Yang 等人[83]认为Deepfakes 创造的是分离的合成脸区域,这样在计算3D 头部姿态评估的时候就会引入错误.因为Deepfakes 是交换中心脸区域的脸,脸外围关键点的位置仍保持不变,中心和外围位置的关键点坐标不匹配,会导致3D 头部姿态评估的不一致,故用中心区域的关键点计算一个头方向向量,整个脸计算的头方向向量,衡量这两个向量之间的差异.针对视频计算所有帧的头部姿态差异,最后训练一个支持向量机(SVM)分类器来学习这种差异.Yang 等人[84]同时发现,GAN 网络生成的假人脸在关键点位置分布上与真实人脸不尽相同,尽管生成的假人脸在脸部细节上与真人相似,但是自然性和连贯性还是与真人有很大的不同之处,通过将关键点归一化的位置坐标作为特征喂入SVM 分类器进行学习.Li 等人[85]发现,正常人的眨眼频率和时间都有一定的范围,而Deepfakes 伪造视频的人基本没有眨眼现象,或者频率跟正常视频有较大差别,这可能是伪造视频在生成时没有丰富多样的眨眼素材导致的.因此,作者将CNN 和循环神经网络联合一起,设计了长期循环卷积网络来识别视频中的状态是否闭眼,从而最终判断是否是伪造的假视频.Ciftci 等人[86]从脸部抽取3 块区域来测量光电容积脉搏波信号,并将信号转换为一致性和连贯性特征,最后使用SVM 对特征进行二分类.类似的,Fernandes 等人[87]利用心率生物信号来区分伪造视频,先通过血流造成的脸部皮肤颜色变化、前额的平均光密度、欧拉影像变化等3 种方法来提取心率,然后采用神经常微分方程模型训练,最后测试Deepfakes 视频时,主要依据正常视频与异常视频的心率分布不同.
基于生理信号特征的检测方法大部分利用深度伪造技术的局限性,但是随着生成技术的改进,如眨眼数据、头部转动、眼球转动等的加入,使得此类方法失效.此外基于脉搏、心率等生物信号的方法会因为伪造视频的压缩等处理而准确度大大降低.
3.3 基于图像篡改痕迹的方法
深度伪造图像受限于早期深度网络的生成技术,在生成的人脸在细节上存在很多不足.因此,有研究者对此展开了探索.Li 等人[88]认为Deepfakes 算法生成的图像分辨率有限,之后需要被转换到匹配替换的脸,这使得Deepfakes 的视频中留下更多可以辨别的人工痕迹,这个可以被深度神经网络有效地捕捉.作者人工构造了大量的负样本,如将要替换的人脸进行高斯模糊、旋转等操作后放缩到源位置,这个扭曲的人脸人工痕迹就保存了,最后使用Resnet50[89]网络区分这些伪造视频或图像.同标记视觉人工痕迹篡改视频类似,Matern 等人[49]利用真假脸的不一致性来区分,如:
(1) 全局不一致性:新的人脸的生成,图像的数据点插值是随机的,并不是很有意义,这会导致的全局眼睛的左、右颜色不一致,鼻子的左、右色彩等.
(2) 光照不一致性:篡改区域和正常区域对光照的反射不一样,如眼睛区域,Deepfakes 生成的视频大多丢失这个眼睛反射细节.
(3) 几何位置不一致:细节位置缺失,如牙齿,只有一些白色斑点,这个细节没有建模.通过对这些特定区域(牙齿、眼睛等)提取的特征向量训练多层感知机进行分类.
尽管基于篡改痕迹的方法在一些数据集上表现良好的检测能力,但是这些数据集大多是早期的生成器生成的,随着生成技术的提升,高分辨率和更多细节处理的伪造图像不断出现,同时容易受到一些对抗措施的影响,如加噪、压缩、放缩,会使得这类方法的检测能力大大减弱.
3.4 基于GAN图像特征的方法
由于当前的深度伪造视频大部分借助了GAN[13]技术,因此研究GAN 生成技术的特点也成为了检测伪造图像的方法之一.研究[90,91]发现:GAN 生成技术改变了图像的像素和色度空间统计特征,通过对特征共生矩阵的学习来区分生成图像的差异.Xuan 等人[92]使用图像预处理,如滤波、噪音等预处理方法破坏GAN 图像低级别的生成缺陷,迫使模型学习高级别的固有的线索.Scott 等人[93]发现:GAN 生成器的中间值通常通过归一化来限制输出,这一定程度上也会限制饱和像素的频率.此外,生成器在多通道使用的权重与真实相机的光敏感度有很大不同,通过对这两个指标进行量化提取分类特征.也有相关研究尝试用GAN 指纹[94,95]来区分伪造,不同的GAN 生成的图片在中间分类层具有唯一的特征,可以作为GAN 生成器的辨别指纹.
Wang 等人[96]提出了FakeSpotter,利用神经元监控的方法来进行分类,原理如图3 所示.使用神经元覆盖的方法观察真假图像经过人脸识别器中的神经元激活变化情况,用SVM 去学习神经元激活的差异,而假脸在神经元覆盖的行为上表示相似.
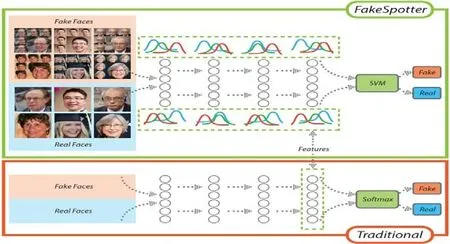
Fig.3 Using neuron coverage method to track fake face features[96]图3 利用神经元覆盖方法追踪假脸特征[96]
此类基于GAN 特征的方法会依赖GAN 的结构,使得特征分类器在已有的生成器行为上过拟合,而无法处理未知的生成器,泛化能力很差.研究不同GAN 结构生成伪造图像的共同特点,依然是一个研究难题.
3.5 基于数据驱动的方法
新的伪造生成算法和数据量的规模都在不断增加,使得研究者开始关注用基于数据驱动的方式来学习这些Deepfakes.基于数据驱动的学习方法主要分为两大类:一类是图片级,将视频处理成帧,设计不同的网络结构,对帧进行判别,实现帧级的识别,最终对视频的帧进行综合决策;另一类视频级,利用循环神经网络学习帧序列的时序特征对一个视频进行整体判断.
3.5.1 基于图片级学习的方法
Afchar 等人[54]设计了多个小的卷积模块来捕捉篡改图像的微观特征,Rossler 等人[51]利用Xception[97]架构对视频的全帧和人脸分别训练.结果显示,基于人脸训练的模型效果远远好于全帧模型.同时,实验结果显示:在面对高度压缩的图片时,模型的训练难度会上升且检测率会下降.其中,利用人脸关键点信息提升性能的结论也被Songsri-in 等人[98]实验证实.Nguyen 等人[99]设计了胶囊网络来判别造假的图片或视频,通过抽取人脸,用VGG-19[100]提取特征编码,然后输入胶囊网络进行分类.Mo 等人[101]增加高通滤波和背景作为CNN 输入,对检测结果有提升.Durall 等人[102]通过离散傅里叶变换提取特征学习,显示了很好的效果.Ding 等人[103]利用迁移学习,使用Resnet18 进行调优;同时对于这些部署的关键系统,对每个预测提供一个不确定水平,如每个神经网层络输出值差异.现有的神经网络能够快速地过拟合特定的篡改痕迹,学习到的features 有高度的区分性,但是缺乏迁移性.Cozzolino 等人[104]设计了一个新的基于自动编码器的神经网络结构,能够学习在不同的扰动域下的编码能力,只需要在一个数据集上训练,在另一个数据集上获取小规模进行调优,就能达到很好的效果.在此基础上,Nguyen 等人[105]设计了Y 型解码器,在分类的同时融入分割和重建损失,通过分割辅助分类效果.此外,一些针对现有神经网络结构的修改也被研究:Hsu 等人[106,107]采用对比损失寻找不同生成器生成的图像的特征,后面再连接一个分类器进行分类;Dang 等人[108]设计了特定的CGFace 网路,专门检测计算机生成的人脸;Bayar 等人[109]设计了受限制的卷积层学习特定的篡改特征;Stehouwer 等人[110]通过在主干网络增加注意力机制来聚焦篡改区域;Rahmouni 等人[111]加入了计算统计数据的全局池化层.Li 等人[112]则设计了基于图片块的双流网路框架,如图4 所示,一条流学习人脸块的微观特征,另一条流学习人脸和背景区域的差异性.通过多任务学习,能够较好地提升模型的泛化能力.
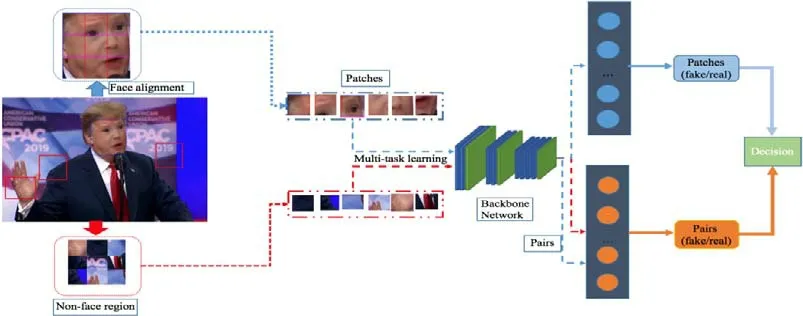
Fig.4 Multi-task forgery classification framework based on image patches[112]图4 基于图像块的多任务伪造分类框架[112]
基于图片级的学习方法是现有研究较多的方向之一,借助深度学习强大的学习能力和日益大幅增长的数据集,学习篡改图片的特点可行且高效.此类方法不仅可以判断单帧图像的真伪,还可以利用组合策略检测视频帧,应用范围较广,但是也存在很多局限性,学习到的模型大多数依赖相同的数据分布,在面对未知篡改类型时很乏力[113,114];同时,对高度压缩的视频帧检测能力会大幅下降.此外,如果视频中的篡改人脸非常少,这对基于图片级方法的综合决策策略提出了挑战.
3.5.2 基于视频级学习的方法
Agarwal 等人[115]发现:作为个体,他们有不一致的面部表情和移动,通过追踪面部和头部移动然后抽取特定动作集合的存在和强度,脸部肌肉的移动可以编码成动作单元,再利用皮尔森系数对特征之间的相关性进行扩充,最后在扩充后的特征集合上建立一个新的单分类SVM 来区分各类造假视频.然而实验结果显示:虽然AUC达到0.9 以上,但是召回普遍不高,实用性较差.
Amerini 等人[116]探索帧间光流的不同,采用VGG16 学习光流的差异并进行分类,因为光流是连续帧间的运动差异计算的,自然拍摄和伪造的视频之间的运动差异很大.
Guera 等人[117]考虑用循环神经网络处理深度伪造的序列数据,因为多个相机视角,光照条件的不同,不同的视频压缩率使得生成器很难产生实际真实的在不同条件下的脸,这个会导致交换的脸在剩下的场景下看起来不一致.此外,因为生成器没办法意识到皮肤或者其他场景信息,所以新脸和剩下帧之间的融合性差,不同帧场景间的光源会引起大多数脸部闪烁现象,这个可以被时序网络较好地捕捉到.
整体框架如图5 所示,分为两阶段分析器,一个CNN 抽取帧内feature,输入一个测试序列,CNN 获取一个每一帧的特征集合,然后将这些多个连续的帧特征集串联传输到LSTM 分析,并产生一个概率估计.
相似地,Sabir 等人[118]采用双向时序网络和人脸对齐结合的方法学习伪造序列,结果显示,基于关键点的人脸对齐与Bidrectional-recurrent-denset 对视频的篡改检测最佳.
基于视频级的学习方法可以学习到视频的时序特征,如前后帧的不一致、人脸区域的不稳定等一些篡改视频均会出现的缺陷,泛化性较好;同时,也能检测到视频中的少量篡改.但是基于时序特征的检测依然对视频的预处理很敏感,如视频压缩、背景光线的变化等,也无法判断单帧的真伪.
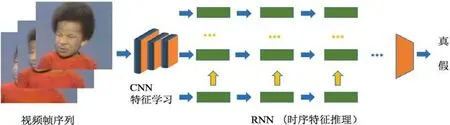
Fig.5 Frame sequences are learned by recurrent neural networks and convolutional neural networks图5 循环神经网络和卷积神经网络学习帧序列
3.6 深度伪造语音检测
随着合成伪造语音技术的发展,对伪造语音的检测工作也在兴起.尤其是2019 年自动说话人语音认证竞赛(ASVspoof2019)的举办,产出了一些针对性的语音欺骗工作.初始伪造语音检测主要是传统的信号处理方法,研究者尝试对不同低水平的频谱特征进行建模,如Todisco 等人[119]提出的常量Q倒谱系数(constant-Qcepstral coefficients,简称CQCC)、Wu 等人提出的归一化的余弦相位和修改的群延迟[120,121],在一些音频处理技术上有效,但是在ASVspoof2019 数据集上泛化性很差.有研究[122]针对ASVspoof2019 数据集进行了数十种声学特征分析,结果显示,这些声学特征均不能在未知类型欺骗攻击有很好的泛化性.随后,基于深度学习的检测方法逐渐被研究者所关注.Zeinal 等人[123]利用CQT 特征[124]和功率谱图特征进行学习,并分别使用网络混合、VGG 与light CNN、VGG 与Sincnet 应对物理访问和逻辑访问场景的攻击.目前,语音欺骗系统检测的最大问题是泛化能力,Alejandro 等人[125]提出了基于光卷积门的循环神经网络来同时抽取帧级的浅层特征和序列依赖的深层特征,检测率在ASVspoof2019 数据集上显示有很大提升.Chen 等人[126]通过随机掩去相邻的频率频道、加入背景噪音和混合噪声提高检测系统的泛化性.
伪造语音的检测从传统信号处理方法发展到深度学习方法,在应对语音欺骗领域取得了一定的成果,但是现有方法还是依赖特定攻击类型,对未知类型攻击检测的泛化性提升还有很大的空间.
3.7 检测技术总结
前述研究工作在提出的同时,大多在开源数据集上进行了评测,本文将主流的深度伪造检测算法在公开数据集上的检测表现总结见表3.所有数据均由论文的实验整理而得,大多数是深度伪造视频检测的工作.其中,主要评估指标有准确率(Acc)、ROC 曲线面积(AUC)、等错误率(EER);Raw、HQ、LQ 分别代表原生态、高清和低清;DF/F2F/FS/NT 分别是FF+中4 种篡改类型的缩写.
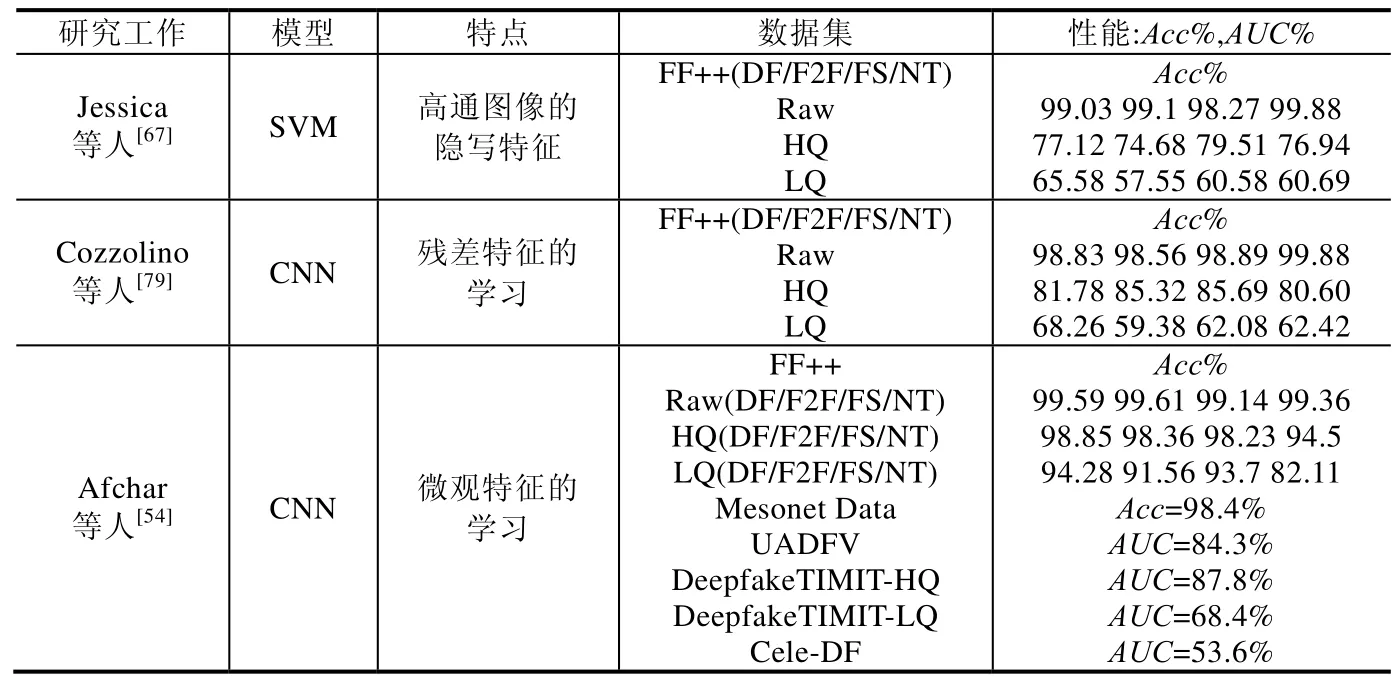
Table 3 Performance evaluation of representative methods on major test sets表3 代表性方法在主要测试集上的性能评估
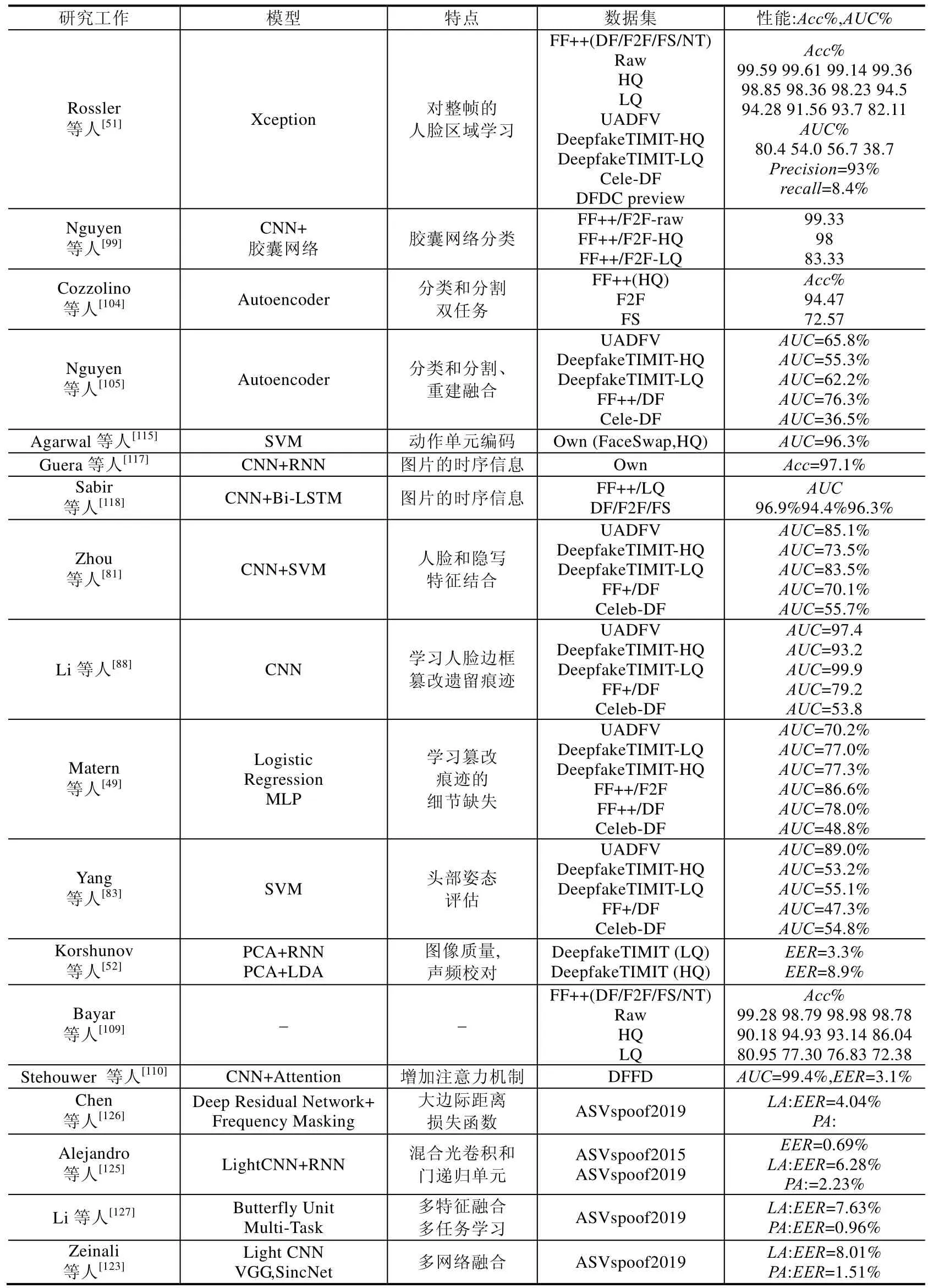
Table 3 Performance evaluation of representative methods on major test sets (Continued)表3 代表性方法在主要测试集上的性能评估(续)
此外,如前文所述,深度伪造视频检测归纳为5 大类的检测算法适用于不同的场景,也在不断的推进发展中,但是都存在一定的局限性,各有优劣,总结见表4.
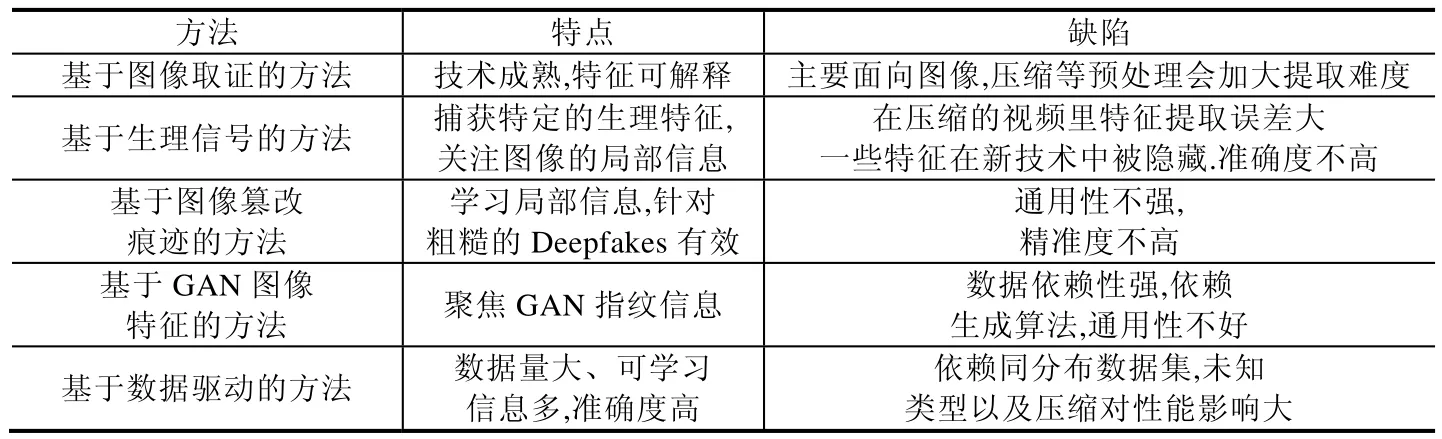
Table 4 Advantages and disadvantages of various detection methods are summarized表4 各类检测方法优劣总结
4 深度伪造的对抗性研究
4.1 深度伪造生成的对抗性
基于深度伪造生成的人脸能够修改人的身份属性,还可以操控人脸做不同的表情,这使得依赖人脸识别的应用存在着重大威胁.而针对人脸识别的对抗性攻击一直层出不穷.Goswami 等人[128]研究发现:对人脸图片的遮挡和加噪等操作,能够一定程度欺骗人脸检测器VGGface[129]和Openface[130].文献[131,132]利用查询优化的方式对人脸图片进行加噪,以此来绕过人脸识别引擎.Song 等人[133]使用注意力机制和生成对抗网络生成指定语义信息的假人脸,使得人脸识别器误判.Majumdar 等人[134]研究发现:对人脸部分区域的修改和变形,可以让人脸识别器有很高的误识率.人脸识别系统的脆弱性,使得基于深度伪造的Deepfakes 类技术更容易攻击成功.Korshunov 等人[52,135]测试了基于VGGnet[100]和FaceNet[136]的人脸检测器的安全性,通过输入生成的Deepfakes视频,发现这两类人脸检测器分别有85.62%和95.00%的错误接受率,说明人脸检测器分辨不出深度伪造人脸和源人脸.
4.2 深度伪造检测的对抗性
深度伪造检测算法大部分均采用了神经网络技术,而神经网络本身存在着对抗样本攻击[137-139].对抗样本攻击是一种对模型输入进行扰动,从而使模型产生误判的技术.这使得深度伪造技术在生成的时候可以隐藏自身的一些特征从而绕过检测,因此对检测算法进行对抗性评估也十分必要.Wang 等人[140]研究发现:不同的GAN生成的伪造图像都留下特定的指纹特征,虽然依赖于指纹特征训练的检测器泛化能力不好,但是对训练数据进行预处理,如增加JPEG 压缩、模糊等操作,大大提高模型的泛化性能,同时在检测时对图片进行后处理,可以增加模型的鲁棒性.但是Neves 等人[141]设计了一个自动编码器能够将合成的伪造图像移除指纹等信息,让现有的伪造检测系统失效.Brockschmidt 等人[113]对深度伪造检测器(Xception[51]、Mesonet[54])进行了对抗性评估,作者采用6 个伪造数据集对检测器的可靠性进行探测,结果显示:在同分布的数据集上,检测器均能达到非常高的检测率;但是在未知篡改类型数据集上,只有特征重合程度高的数据集之间迁移性较好,否则检测效果非常差.Marra 等人[142]则模拟了篡改图片在社交网络的场景中的检测,结果显示,现有的检测器在现实网络对抗环境下(未知压缩和未知类型等)表现很差.Zhang 等人[143]寻找GAN的共有痕迹,提高检测器的鲁棒性.现有的检测器对数据依赖强,泛化性不够,Du 等人[144]利用局部性感知的自动编码器实现造检测,使得模型聚焦篡改区域,通用性更强.Huang 等人[145]则借鉴了对抗样本的思想,对这些基于神经网络的检测器进行对抗性攻击,设计了单个对抗攻击和通用对抗攻击两种方式,使得检测器的篡改分类和定位失效.尽管现在已经存在众多的检测器,在一些数据集上表现很好,但是攻击者依然可以完善生成方法,隐藏一些标志性特征从而绕过检测器,这是一个长期的攻防博弈过程.
5 总结与展望
5.1 技术风险
深度伪造技术的发展给社会带来了巨大的负面影响,从社会国家领导人到普通的互联网公民,都有被此类技术侵害的可能性[146].对深度伪造技术带来的技术风险如下.
(1) 舆论负面影响:如色情电影的制作、政治家的谣言传播,会严重损害个人名誉.
(2) 对人脸认证的影响:目前大多依赖活体检测来识别视频攻击,如果在没有活体检测的应用场景以及活体功能失效的场景,如端劫持,对换脸的人与本人的识别面临挑战.
(3) 对视频人脸识别系统的影响:通过追踪视频人脸并识别的技术面对挑战,换脸的视频与真人的视频分辨不出来.
(4) 影响司法体系:由于缺乏完全可靠的鉴别深度伪造数据的能力,法院需要重新审视图片或者视频证据的效力.
(5) 影响经济活动:名人的假视频能让股市瞬间暴跌.
而这些风险后面还隐藏着国家治安稳定、伦理道德、经济发展、信任危机等更深层次的社会问题,亟需研究更有效的应对措施.
5.2 研究难点
从深度伪造技术诞生至今,有不少的研究工作展开对伪造图像或视频进行检测,但是依然没有完美的解决方案[40],在检测领域依然存在着诸多研究难点问题.
(1) 压缩方式的不同、压缩率的不同:视频不同于图片,在上传到网站时会做不同的压缩方式处理;同样,视频在线下制作时也可以做不同的后处理裁剪压缩,这会使得很多篡改特征模糊甚至消失.制作者甚至可以对视频中的部分帧进行压缩处理,人为地增加检测难度.此外,不同的压缩方式和压缩率下的数据分布也有很大不同,这也意味着基于学习的方法会很容易在已有的训练集上过拟合.现有的检测方法还无法有效地检测未知压缩的视频,大多是在训练集中扩充压缩的数据,增加模型的决策边界以此来应对压缩[51].此类方法本质还是基于同分布压缩的假设.
(2) 视频分辨率的不同:互联网上的视频质量和大小各异,不同的视频有着不同的分辨率,人脸大小跨度从几百像素到百万像素级别.如果统一放缩到指定大小处理,会丧失部分特征,在一定程度上影响着检测器的特征提取,这就需要检测算法从根本上考虑不同尺度特征的融合.
(3) 篡改算法未知:生成算法层出不穷,不同的生成算法篡改的侧重点不同,所具有的特征也不尽相同.基于学习的方法虽然能快速捕捉到训练集中的人脸篡改特征,但是大多是拟合已有的生成器特征,对未知的篡改类型不鲁棒.现有的应对方法大多是将新的生成算法数据集加入到训练集[51,112],以此来提高跨生成算法之间的检测率.如何设计鲁棒性强、泛化性能高的检测算法,依然是难点.
(4) 一些复杂的对抗场景:真实网络世界中的视频远远比公开数据集的复杂度要高的多,而且存在较强的对抗性.一些在实验数据上表现很好的模型,在面对真实网络伪造数据集时可能束手无策.如多人脸的视频如何无误地检测、针对只有部分帧部分区域篡改的视频如何区分、视频里过强或过暗的光线对人脸检测的影响如何评估等,人脸生成伪造者在制作的同时也会考虑加入这些对抗性场景,以此来降低检测效果,这些复杂场景对伪造检测算法带来巨大的挑战.
5.3 未来研究方向
虽然针对伪造图像或语音的检测已经取得了一部分研究成果,但目前该领域的研究依然存在诸多关键问题尚待解决.同时,一些新的生成技术的发展成熟,会让此类深度伪造的鉴别工作越来越困难.针对以上的难点和问题,我们可以考虑从多角度多层次来探索深度伪造检测未来可行的方向.
(1) 研究泛化性好的检测算法:已有的检测方法容易依赖特定的数据集和生成算法,泛化能力很弱.这往往是由于训练数据的单一同分布所致.仅仅粗暴地对数据直接学习并不能满足多样的伪造类型,需要探索尽可能多的深度伪造类型,寻找其中的共性特征,如生成器的指纹[94,95]、不同伪造数据中人脸与嘴唇一致性差异等.通过对共性特征的学习,使得检测模型能够适用于更多的深度伪造类型.
(2) 研究鲁棒性强的检测算法:论文中展现的检测算法大多在单一的场景下测试,而现实世界中常常面对压缩、噪音等复杂情况,使得检测算法不鲁棒.可以在训练阶段和测试阶段对数据进行压缩、放缩等预处理,探索不同预处理对检测算法鲁棒性的影响.同时,还可以将对抗样本技术应用到检测模型的鲁棒性提升上,探索检测模型在对抗样本攻击下的缺陷,进而可以利用对抗环境下生产的对抗样本对模型进行对抗训练以增加模型的鲁棒性.此外,已有的数据集大多数都为单人脸的真伪鉴别,检测模型缺乏应对视频中多人脸的复杂场景.如何在保证准确率的同时对视频中多人脸的篡改进行判断,是一个具有挑战性的课题.
(3) 研究主动防御算法:现有的检测算法总是依赖已发现的深度伪造类型,对未知类型的伪造数据检测很被动,这使得检测算法总是落后于生成技术.可以从两个角度进行主动防御:第1 种思路是利用对抗样本技术对上传到互联网上的媒体数据注入对抗噪音,如注入对抗人脸检测的噪音,使得人脸检测技术在预处理人脸数据时检测错位或失败,从而使得依赖人脸检测技术的深度伪造换脸技术不再精准,导致换脸异常或失败;第2 种思路是控制视频传播的源头,对互联网上的视频进行溯源,研究视频网站上的视频追踪技术,如Hasan 等人[147]尝试用区块链技术对互联网上的视频进行追踪.
(4) 研究深度伪造图像和伪造语音的融合检测技术:现有针对深度伪造的检测技术基本只关注了一个单一的伪造领域,而伪造的多媒体数据通过图像和语音结合能达到更逼真的效果.因此,对伪造数据进行图像语音多模态的检测是一个有意义的方向.如,Facebook 举办的深度伪造检测竞赛[58]已经增加了同时篡改音频和图像的数据类型.这种伪造类型将会越来越普遍,带来的负面影响也会更大.针对此类伪造的检测研究也给单模态(图像或语音)伪造的检测提供了思路.
(5) 建立研究性社区:现有的研究资源没有得到很好地共享,缺乏如全球研究者认可维护的研究性网站.对现有的研究数据集共享,需要建立统一的社区,集中现有零散的数据资源,让研究者们能更好地利用已有的资源和成果.现有网站[56]在开源部分数据集,但是力度不够,需要集成大规模数据集并公开现有最好的评估指标,定期举办学术研讨会和比赛,增加研究者们对深度伪造检测领域的关注度.
(6) 进行司法立法:深度伪造的检测仅仅依靠技术手段可能不能完美地解决问题,因为生成与检测是一个永恒博弈的过程,仅依靠一门检测技术来杜绝深度伪造现象不太现实,需要社会建立完整的法律体系,对恶意制作或传播的互联网用户进行一定的惩戒.如美国加州[148]已经立法,禁止制作政治人物的伪造视频,同时也明确规定了制作色情伪造人物视频属于违法行为.中国的互联网信息办公室也发行了《网络信息内容生态治理规定》[149],其中明确规定,网络信息内容服务使用者、内容生产者和内容服务平台不得利用深度学习、虚拟现实等新技术新应用从事法律、行政法规禁止的活动.尽管已出台了相关法律抑制深度伪造的滥用,但是此类法律还不健全,如何区分伪造视频是属于娱乐和恶性传播等在法律边界游走的现象,还需要相关部门建立更加完整细致的法律体系.
(7) 培训新闻工作者:法律和技术检测能一定程度增加恶意伪造传播的代价,但是给社会带来的负面影响无法挽回,这需要在视频传播的源头进行控制,如一些社交媒体,特别是主流媒体承担着大量的视频图像的传播任务,需要对这些新闻工作者进行专业培训,培养鉴别一些假视频的能力,从源头减少伪造视频的传播,降低负面影响.同时,对本身制作视频的新闻工作者,要明确在视频上打上是否伪造的标签,以减少新闻媒体的误导能力.
6 结束语
随着深度学习技术的发展,深度伪造技术会不断完善,生成更加逼真难以鉴别的视频和语音数据.这对深度伪造的检测提出了巨大的挑战.尽管已存在有一些针对深度伪造检测的工作,但是都依赖特定的数据集或者场景,依然存在许多关键的科学问题尚待解决.为了理清现有研究的进展,明确未来研究方向,本文从生成技术、研究数据集、主流检测方法进行总结,回顾了大量极具影响力的研究成果,并对相关研究进行了科学的分类、总结和分析.同时,本文指出了深度伪造检测领域当前面临的挑战,探讨了未来可行的研究方向,旨在为推动深度伪造检测领域的进一步发展和应用提供指导和参考.
