基于正则化理论的老人小孩高效SVM分类器的研究
2021-03-05王国庆李克祥郑国华邵卫华夏文培
王国庆 李克祥 郑国华 邵卫华 夏文培



摘要:利用(基于保持稀疏重构的半监督字典学习)中学习得到的字典,得到区域的稀疏编码系数,用该系数作为特征能够有效地区分目标间的形状差异。由于SVM在分类过程中需要计算测试样本与所有支持向量之间的核函数,故实时性较差。所以采用基于正则化的集成线性SVM分类方法,既实现了快速分类,又能避免过拟合情况的发生,融合CNN深度学习算法更体现其良好性能。
关键词:正则化 支持向量机 分类器 机器学习
Research on High-Efficiency SVM Classifier for the Elderly and Children Based on the Regularization Theory
WANG Guoqing LI Kexiang ZHENG Guohua SHAO Weihua
XIA Wenpei
(Zhejiang Sostech Co., Ltd., Wenzhou, Zhejiang Province, 325000 China)
Abstract: By using the dictionary learned in (Semi-supervised dictionary learning based on preserving sparse reconstruction), the sparse coding coefficients of the region are obtained.We can effectively distinguish the shape difference between the targets by using this coefficient as a feature. Since the SVM needs to calculate the kernel function between the test sample and all the support vectors during the classification process, the real-time performance is poor. Therefore, the integrated linear SVM classification method based on regularization not only achieves fast classification, but also avoids the occurrence of over-fitting. The fusion of CNN deep learning algorithm more reflects its good performance.
Key Words: Regularization; Support vector machine; Classifier; Machine learning
1. 基于正则化SVM分类器
对于提取的目标区域,需要对其进行快速判断是否为检测目标对象。SVM由于高准确率而成为目标识别分类的常用方法,然而其对新样本进行预测判断时,需要计算此样本与所有支持向量之间的核函数,故实时性比较差。针对上述问题,本项目拟提出一种新型的SVM分类器,以实现快速、准确分类,具体可分为以下几步。
1.1正则化理论
正则化[1](Regularization)是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。也就是目标函数变成了原始损失函数+额外项,常用的额外项一般有两种,英文称作ℓ1−normℓ1−norm和ℓ2−normℓ2−norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数(实际是L2范数的平方)。正则化又称为规则化、权重衰减技术,在不同的方向上有不同的叫法,在数学中叫作范数。以信号降噪为例公式(1-1):
(1-1)
其中,x(i)为原始信号,或者小波或者傅里叶等系数,R(x(i))为惩罚函数,λ是正则项,y(i)是噪声的信号, 为降噪后的输出。
范数,是衡量某个向量空间或矩阵中的每个向量长度或大小,范数的一般化定义为:对实数p>=1,范数定义如公式(1-2):
(1-2)
L1范数:当p=1时,是L1范数其表示某个向量中所有元素绝对值的和。
L2范数:当p=2时,是L2范数表示某个向量中所有元素平方和再开根,也就欧几里得距离公式。
1.2 混合线性SVM分类器
对于提取的目标区域,需要对其进行快速判断是否为目标对象。SVM由于高准确率而成为目标识别分类的常用方法,然而其对新样本进行预测判断时,需要计算此样本与所有支持向量之间的核函数,故实时性比较差。针对上述问题,本项目拟提出一种新型的SVM分类器,以实现快速、准确分类。
混合线性模型(Mixed linear model)是方差分量模型中既含有固定效应,又含有随机效应的模型。采用最大似然估计法(maximum likelihood,ML)和约束最大似然估计法原理计算协方差矩阵。
●总的混合线性模型(Mixed effect model,MLM)的模型方程为公式(1-3):
(1-3)
MLM在GLM基礎上引入随机变量设计矩阵Z。式(1-3)中Y表示反应变量测量值的矩阵向量, 为固定效应参数设计矩阵向量,X为固定效应自变量设计矩阵向量, 为随机效应参数设计矩阵向量,Z为随机效应自变量设计矩阵向量,其中 服从均值向量为0,方差协方差矩阵向量为G的正态性分布,表示为 , 为随机误差设计矩阵向量,服从均值向量为0,方差/协方差矩阵向量为R的正态分布,即 。
●一种混合线性[2]的快速SVM分类器公式(1-4):
(1-4)
其中,x为输入样本, 和 分别为线性子分类器的权重系数和偏差,可以看出,分类器的输出为 个子分类器群组的输出之和,页每个群组的输出则是 个相互竞争的子分类器输出的最大值。
根据上述优化问题,建立一个具有层次树结构的SVM分类器,其基本思想是在尽可能小的函数复杂度下,用线性SVM不断把错分的正(负)类样本从当前分类器所分得的负(正)类中分离出来再进行训练。
2. 实验与结果分析
2.1 线性SVM分类器实验
实验使用sklearn官网提供的Iris数据集,然后通过代码片断结合实验结果进行分析。
步骤一,数据预处理,通过Iris数据集分为两个数组,一组存放值,另一组存放标签,以两个特性为例,代码如下所示:
iris_datas = datasets.load_iris()
x = iris_datas.data[:,:2] #value
x = iris_datas.target #label
步骤二,拆分数据集,将数据集拆分为训练集和测试集验证集,训练集50%,验证集20%,测试集30%。
步骤三SVC和拟合模型参数设置,选择SVM参数,Kernel支持向量机的线性核函数,C控制误分类训练数据损失函数。Gamma控制模型中误差和偏差之间误差权衡函数,代码如下所示:
clf = svm.SVC(kernel=’rbf’,C=c,gamma=g)
clf.fit(x_train,y_train)
接着在验证集评估以上参数设置,并检查相应的成功率,找到算法最优值,代码如下所示:
clf_predictions = clf.predict(x_validate)
clf_sc = clf.score(x_validate,y_validate)
对于不同的C值训练一个线性SVM,并绘制了数据和决策边界。图1中可看出1边界变化是由C引起的通知SVM在每个训练中避免出现多少错误分类。对于较大的C值,优化将选择一个较小的边界超平面,该超平面能更好地得到所有训练点的正确分类。
相反,一个很小的C值将导致优化器寻找一个更大的边界分隔超平面,即使这个超平面错误分类了更多的点。所以C值小的错误分辨率低,反之错误分辨率高。C=0.1时给出的最佳精度是77.77%。最后,选择了C的最佳值,并在测试集上对模型进行了评估.通过将C调整最佳后,发现测试的准确率为83.333%为最高。
2.2 深度学习分类实验
线性SVM分类器[3]在实验中进行的二分类测试,经过几轮的C值调整最后得到一个令人比较满意的结果83.33%。但是,在实际复杂场景检测中每次都是需要人工去干预,调整模型的参数值,这不是一个合适的方法。所以选择一个可定制化的环境与CNN深度学习[4]一起工作,使用一个实际参数和神经元。为了简化模型的构建项目中使用tensorflow下的轻型框架Keras,实验步骤如下。
步骤一:获取文件目录里老人与儿童面部图像数所存放目录,将数据分成两组,一组存放转换后的二进制,另一存放二进制标签值。然后将得到每一张图像修改尺寸大小为64×64,最后存储为npz文件。
步骤二:读取npz文件获取图像值和标签值,拆分数据集为训练集和测试集,训练集为80%,测试集为20%。
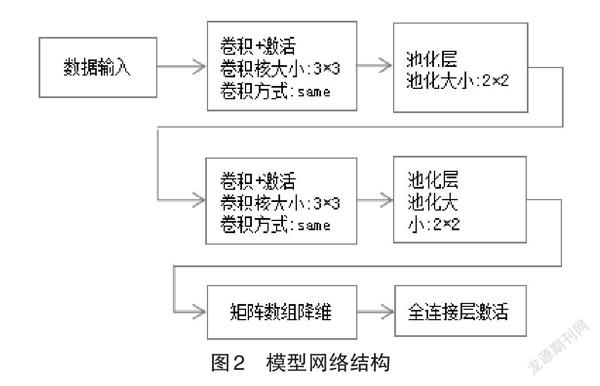
步骤三:构建网络结构图2分为卷积层、池化层、全连接层。网络参数、训练参数为Batch_size=32,num_class=2,epochs=30
Batch_size是一个重要参数,它是批大小,它定义了一次向前/向后传播网络的样本数量。通常这意味着更高的批大小将为单次传递提供更多的示例,但也会增加内存使用。通常较小的批大小将导致更好的泛化[5-6]。
步骤四:模型训练,通过创建的模型网络结构(如图2所示)和训练参数设置,可以观察到训练过程中精确率,验证正确率,训练轮数,测试结果如图3和图4。
图3的模型训练过程精度为0.9967训练30轮验证率0.9868。
图4的模型测试结果为label=0,predict=0表示为老人,label=1,predict=1表示儿童
3 结语
通过以上两组实验对比线性SVM分类器算法,调整C值过后精确度为83.333%,而选择与深度学习CNN搭建网络模型融合训练得到结果0.9868%。采用这种算法虽然取得了比较好的效果,但仍然还有需要改进的地方。例如,年龄不在老年人阶段,但面脸表情特征如老年人,儿童检测也存在类似问题。后期,计划在人脸特征提取,人脸数据多样性方面进行优化和增强。
参考文献
[1] 刘保成,朴燕,唐悦.基于时空正则化的视频序列中行人的再识别[J].计算机应用,2019,39(11):3216-3220.
[2] 杨斌,王斌,吴宗敏.基于双线性混合模型的高光谱图像非线性光谱解混[J].红外与毫米波学报,2018,37(5):631-641.
[3] 王福斌,潘兴辰,王宜文.基于SVM的多核学习飞秒激光烧蚀光斑圖像分类[J].激光杂志,2020,41(4):86-91.
[4] 林景栋,吴欣怡,柴毅,等.卷积神经网络结构优化综述[J].自动化学报,2020,46(1):24-37.
[5] 叶俊贤.深度神经网络数据并行训练加速策略研究[D].成都:电子科技大学,2020.
[6] 王铎. Relu网络的一种新型自适应优化方法研究[D].北京:北京工业大学,2020.
2292501186223
