基于注意力机制的深度学习推荐研究进展*
2021-03-01陈海涵吴国栋李景霞王静雅
陈海涵,吴国栋,李景霞,王静雅,陶 鸿
(安徽农业大学信息与计算机学院,安徽 合肥 230036)
1 引言
当前,深度学习在计算机视觉、自然语言处理和语音识别等领域得到了广泛的应用,许多学者也将其用于推荐系统研究。针对传统协同过滤算法中存在的数据稀疏性和冷启动问题,深度学习具有良好的对数据集本质特征进行学习的能力,一定程度上克服了推荐过程中的数据稀疏问题。但是,深度学习具有黑盒特性,很难对推荐系统的最终决策做出解释,而没有解释性的推荐是缺乏说服力的,会对提升用户的信任度带来负面影响。因此,如何在提高推荐性能的前提下,提升深度学习推荐系统的可解释性和透明度受到了工业界与学术界的广泛关注。
注意力机制通过对关注事物的不同部分赋予不同的权重,从而降低其它无关部分的作用。从注意力机制可解释性的角度看,它允许直接检查深度学习体系的内部工作,通过可视化输入与对应输出的注意权重,达到增强深度模型可解释性的效果[1]。在推荐算法中融入注意力机制,对每个潜在因素或特征的重要性进行区分,在提升推荐性能的同时,也提高了推荐系统内部的可解释性。本文主要分析了基于注意力机制的深度神经网络DNN(Deep Neural Network)、卷积神经网络CNN(Convolutional Neural Network)、循环神经网络RNN(Recurrent Neural Network)和图神经网络GNN(Graph Neural Network)等几种深度学习推荐的研究进展,指出了各自的优点与不足,并指出了相关研究难点与未来主要研究方向。
2 注意力机制及其分类
注意力机制是一种模拟人脑注意力的模型,最初由Treisman等人[2]提出,其本质是利用注意力的概率分布,捕捉某个关键输入对输出的影响[3]。以Bahdanau等人[4]提出的注意力机制模型为例,求解注意力的计算过程可以抽象为3个阶段,如图1所示。
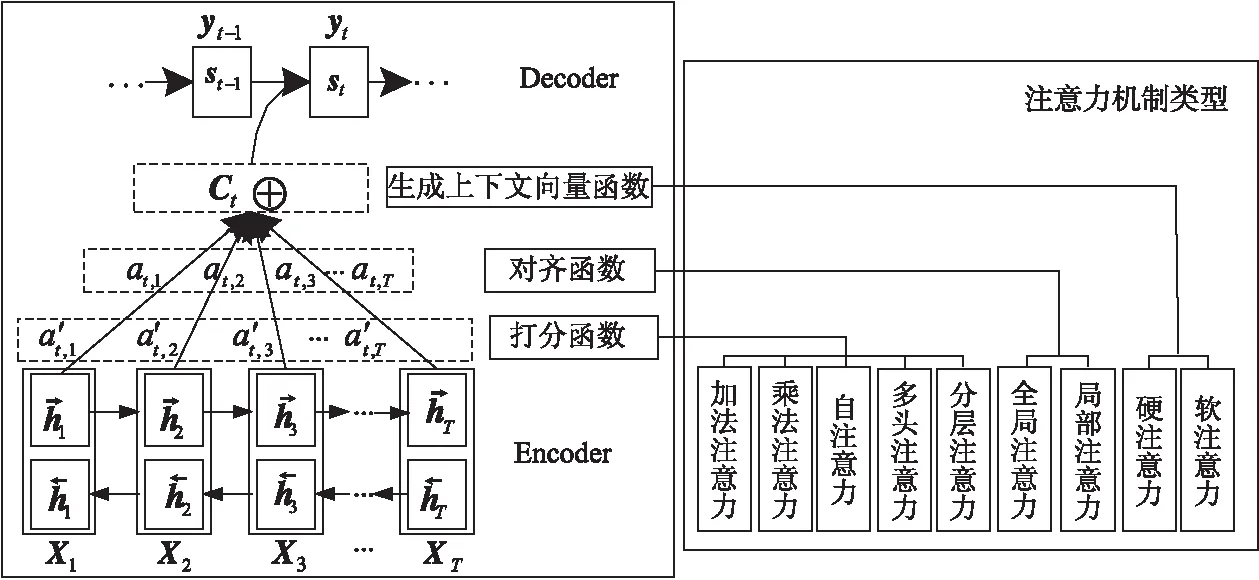
Figure 1 Structure and classification of attention mechanisms
图1中,注意力机制的3个阶段包括:计算打分函数阶段,主要根据解码器(Decoder)端和编码器(Encoder)端隐状态进行相似度计算;计算对齐函数阶段,主要通过归一化处理,将输出的相关性值进行数值转换;计算生成上下文向量函数阶段,主要对输入序列进行加权求和。
按照注意力机制在图1中3个阶段的不同变换,得到注意力机制的不同类型。根据不同的打分函数,将注意力机制分为加法注意力、乘法注意力、自注意力[5]、多头注意力[6]和分层注意力[7];根据不同的对齐函数,注意力机制可分为全局注意力和局部注意力[8];根据不同的生成上下文向量函数,得到硬注意力与软注意力[9]。
其中,图1的核心步骤是注意力分数a′t,j的计算,XT是输入序列,hj是Encoder端第j个词的隐向量,st-1是Decoder端在t-1时刻的隐状态,yt-1表示t-1时刻的目标词,Ct表示上下文向量。
3 基于注意力机制的深度学习推荐相关研究
将注意力机制融入深度学习推荐过程中,主要思路是先利用各类深度学习模型学习用户或项目的隐特征,结合注意力机制学习隐特征的权重;其次构建优化函数对参数进行训练,得到用户和项目隐向量;最后利用隐向量信息得到项目排序结果,对用户进行推荐。对于不同的深度学习模型,本文将基于注意力机制的深度学习推荐研究主要分为4类,如表1所示。
3.1 基于注意力机制的DNN推荐方法
DNN即深度神经网络,由多层感知机MLP(Multi-Layer Perceptron)发展而来,但DNN比MLP的激活函数种类更多,层数更深,其网络层数可以达到一百多层乃至更高,一定程度上改善了MLP优化函数的梯度消失和局部最优解问题。
针对当前的音乐推荐系统只能从不同歌曲中学习到相同的上下文权重问题,张全贵等人[10]利用注意力机制给每个用户的历史交互歌曲动态分配不同的注意力权重,得到更符合用户偏好的推荐结果,增加了对用户偏好分析的可解释性。沈冬东等人[11]加入平滑系数减轻对长历史活动用户的惩罚,并通过多层感知机参数化注意力函数改进注意力网络,解决了传统ItemCF(Item Collaboration Filter)算法难以充分挖掘数据间隐含信息的问题。针对传统推荐算法未充分提取用户行为中的隐式反馈特征问题,郭旭等人[12]利用自注意力机制生成用户短期动态项目的向量化表示,提高了推荐质量,但该方法对用户的向量化表示比较粗糙,未考虑融入用户的画像属性。

Table 1 Research on deep learning recommendation based on attention mechanism
文献[13]为了解决基于矩阵分解的协同过滤算法不能获取用户历史交互中复杂的非线性特征问题,构建了DeepCF-A(Deep Collaborative Filtering model based on Attention)模型,提取线性与非线性特征。DeepCF-A模型如图2所示。具体步骤主要有:
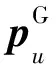
(1)
(2)非线性特征提取。在MLP中融入注意力机制得到用户和项目间历史交互数据的非线性特征φMLP-A,如式(2)所示:
(2)
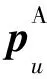
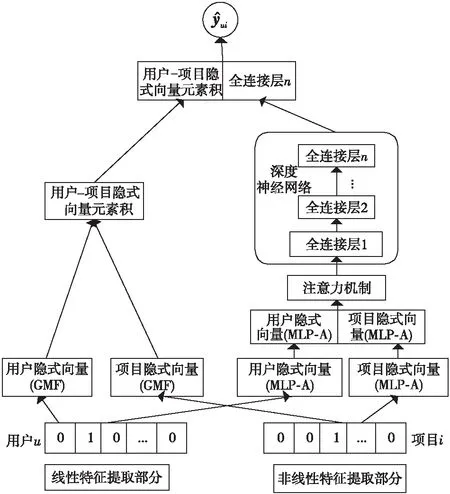
Figure 2 DeepCF-A recommendation model
(3)注意力机制层。在非线性特征提取部分,将嵌入层的m维特征向量Xm送入Softmax函数,得到每个维度特征的关注度Am,如式(3)所示;再将Am与相应维度的特征向量对应相乘,得到更新权重的特征向量Aout,如式(4)所示:
Am=Softmax(Xm)
(3)
Aout=Am⊙Xm
(4)
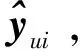
(5)
该模型提升了协同过滤方法处理隐式反馈数据的效果,适用于解决推荐系统中数据量庞大、难以捕捉深层非线性关系的推荐问题。但是,在深度神经网络中,高效地捕捉用户和项目隐向量间的交互信息,是以不断提升网络层数为代价的,深度神经网络层数的增加会导致新的参数数量膨胀问题[14]。此外,DNN无法对时间序列上的变化进行建模,不能反映用户兴趣的动态变化,而样本出现的时间顺序对推荐任务又有着非常重要的意义。
3.2 基于注意力机制的CNN推荐方法
CNN即卷积神经网络,具有限制参数个数和挖掘模型局部结构的特点。为了解决DNN训练数据时带来的参数数量膨胀问题,有学者将注意力机制和CNN结合用在推荐系统研究中。

Figure 3 ACoNN recommendation model
针对微博的话题标签推荐任务,经常需要大量人工进行分类这一问题,Gong等人[15]提出了一种基于注意力机制的CNN微博标签推荐模型。该模型使用全局和局部注意力2个通道,有效提高了推荐性能;但推荐数据仅使用了微博文本标签,未考虑使用图像等其它形式数据提取微博特征。针对这一问题,Zhang等人[16]加入协同注意力机制对标签与图像、文本中的局部关联性进行建模,相较于仅使用文本信息的模型,推荐效果更好。不足之处是作者仅验证了1层和2层的协同注意力机制对推荐结果的影响,没有在层数上做更多的尝试。针对在线新闻网站中,平台编辑手动挑选推荐候选文章的耗时问题,Wang等人[17]构建了一种动态注意力深度模型DADM(Dynamic Attention Deep Model),DADM将专业与时间2个潜在因素加入注意力机制,自适应地为编辑分配偏好权重,使模型在处理动态数据和编辑行为方面拥有很小的方差。但是,文章中的文字和图像对编辑选择行为的影响应该是不同的,此模型未加以区分。
针对传统推荐算法对评论文本信息提取能力有限的问题,文献[18]提出了一种融合注意力机制对评论文本深度建模的推荐模型ACoNN(deep Cooperative Neural Networks based on Attention),通过注意力机制设计一层权值更新层对文本矩阵进行重新赋权,再使用一组并行的CNN,充分挖掘用户和项目的隐含特征。推荐流程如图3所示。
ACoNN推荐模型的主要实现步骤:
(1)输入层:利用词嵌入模型,将用户与项目的评论文本表示成词嵌入矩阵Mu和Mi。
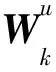
(6)
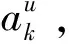
(7)
最后对目标用户词向量矩阵进行加权,得到更新权值后的矩阵Su,如式(8)所示:
Su=A(u)×Mu
(8)
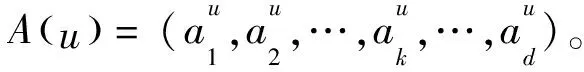
(3)CNN层:利用CNN对词向量矩阵Su进行卷积、池化和全连接操作得到用户向量outputu,同理可得项目向量outputi。
(4)推荐:连接outputu、outputi,构建用户-项目特征向量z;向向量z加入因子分解机,根据最小化损失函数进行训练,完成参数更新,如式(9)所示:
(9)
其中,yreal为用户对项目的真实评分值,w0为全局偏置量,wi表示向量z中第i个分量的权重值,zi和zj分别表示向量z的第i和第j个分量,wij表示z中第i个与第j个特征向量的交互值。
相比深度神经网络,该模型训练阶段参数较少、复杂度较低。此外,注意力权值更新层的设计有助于捕捉文本中的重点信息,结合CNN具有共享权值和局部连接的特性,更加易于模型的优化[19]。此方法适用于解决图像视觉领域的图像分类和文本处理等问题,运用注意力机制能使CNN在每一步关注图像或者文本上的不同位置,提高对重点特征的提取效率。虽然基于注意力机制的CNN推荐方法能从输入中获取最有效的信息[20],但是这种方法也不能表示动态变化的用户兴趣。
3.3 基于注意力机制的RNN推荐方法
RNN即循环神经网络,是一类用以处理序列数据的神经网络。针对DNN和CNN不能解决时序数据的问题,一些研究者将注意力机制和RNN结合应用于推荐任务中,刻画用户兴趣的动态变化。LSTM(Long Short-Term Memory)和GRU(Gated Recurrent Unit)是RNN的2种改进版本,它们在简化RNN内部循环结构的同时,缓解了RNN无法检测长序列的问题[21]。
针对微博的话题标签推荐没有考虑文本的时序特征问题,Li等人[22]构建了一种基于主题注意力机制的LSTM模型,该模型与文献[15]中的CNN推荐模型相比,加入了时序特征的影响,有效提升了推荐性能。不足之处是忽略了用户信息、时间信息等数据对标签推荐的影响。Xing等人[23]提出了基于词级与语句级注意力机制的用户-项目推荐模型,在Yelp和Amazon数据集上的实验中,推荐性能皆提升了近2%,验证了考虑语义层面的推荐是有效的。但是,这种方法只有当目标用户为目标项目编写的评论可用时,才表现出最佳性能,数据量较少时会降低推荐效果。冯兴杰等人[24]提出了深度协同模型DeepCLFM(Deep Collaborative Latent Factor Model),解决了用户与项目的深层抽象特征挖掘不充分问题,通过对评论文本信息作全局偏倚项的补充,有效缓解了冷启动问题。但是,DeepCLFM学习到的用户偏好向量是静态的,而同一用户对不同项目的偏好向量是不同的,此模型未加以区分。
为了解决标签推荐中存在的微博噪声问题,文献[25]提出了基于LSTM的时态增强语句级注意力模型。通过在语句级注意力层引入时间信息,减少了噪声数据对分类器的影响。其推荐模型如图4所示。其中,Mi(i=1,2,…,N)表示第i条微博的词向量矩阵。
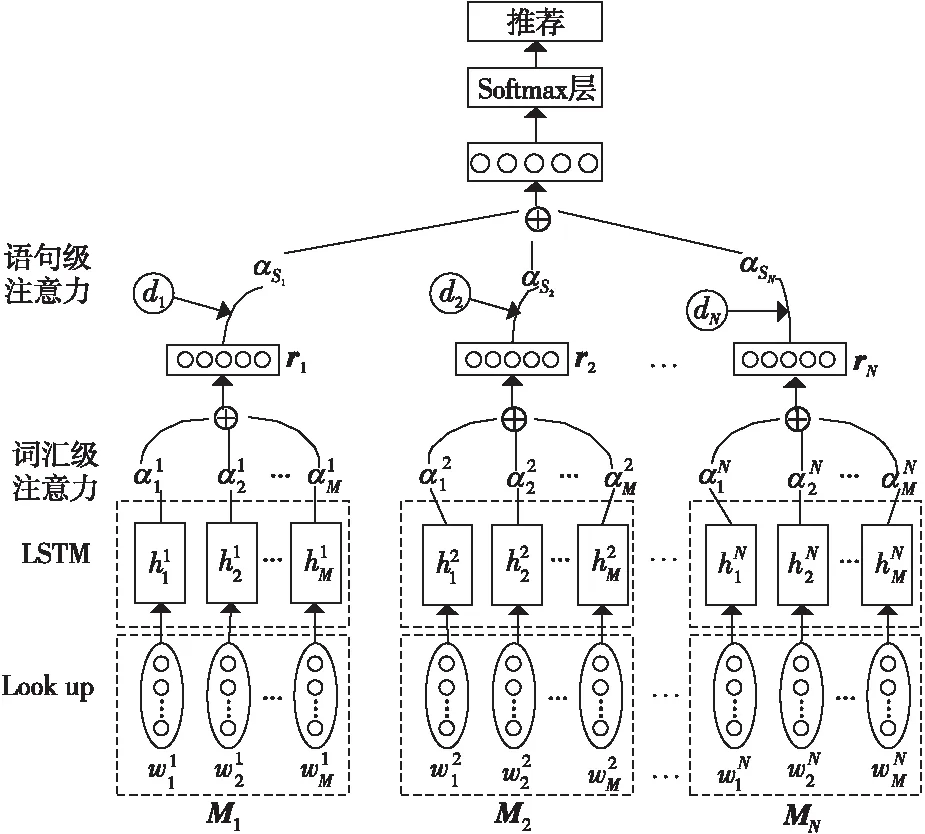
Figure 4 Temporal enhanced sentence-level attention model based on LSTM
基于LSTM的时态增强语句级注意力模型的主要实现步骤如下所示:
(1)Lookup层:将微博中的单词wi映射到一个低维向量中,得到嵌入向量ei。
(2)LSTM层:将实值嵌入向量序列bN={e1,ei,…,eN}输入LSTM,获得微博的高级语义表示H,且H={h1,h2,…,hM}。其中,N和M分别表示微博条数和最大长度。
(3)词汇级注意力层:通过更新每个隐状态hj的注意力分数,得到词汇级注意力矩阵αW,然后求解隐状态的加权和,得到语句向量r,如式(10)~式(11)所示:
αW=Softmax(ωTtanh(H))
(10)
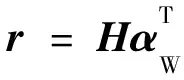
(11)
其中,ω是一个训练好的参数向量,ωT是它的转置,通过预训练得到。
(4)语句级注意力层:将词汇级注意力层输出的句子向量集合S={r1,r2,…,rN}输入语句级注意力层,先计算语句向量ri与标签查询向量t的匹配分数mi;然后加入时间信息di,得到每个语句向量ri的注意力权重αMi;最后求解集合S中语句向量的加权和,记为R,如式(12)~式(14)所示:
mi=riAt
(12)
(13)
(14)
其中,di表示时间元素,当给定一个〈microblogMi,hashtagh〉的元组时,根据微博词向量矩阵Mi和标签,可以从一个需要训练的二维矩阵B∈R|time|×|hashtag|中查找对应的di。|time|是时间节点的个数,|hashtag|是标签的个数,A是一个加权对角矩阵。
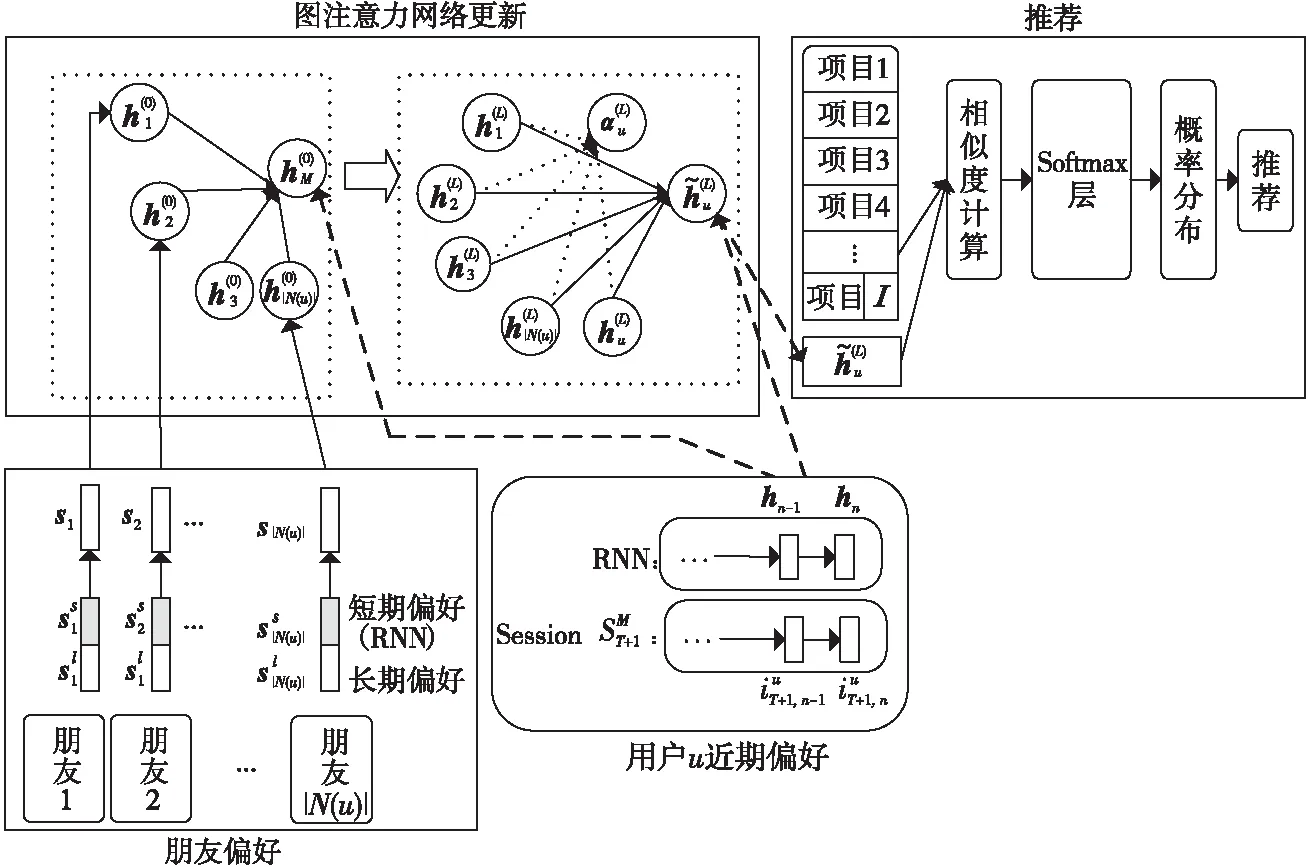
Figure 5 Dynamic graph attention network social recommendation model
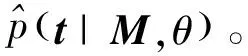
(15)
其中,θ是模型的所有参数,Mi和ti分别表示第i个微博向量和标签向量。
该模型不仅从词汇和语句2个级别对微博特征进行分层刻画和关联,还将时间信息引入注意力机制模型,弥补了文献[22]未考虑时间信息的不足,更形象地刻画了微博数据的动态性。因此,适用于解决文本翻译、语言识别和推荐中的序列预测问题,应用注意力机制使RNN能够将输出序列中的每一项与输入序列相关项对应,克服传统循环神经网络在学习超长序列上的限制问题[26]。但是,LSTM和GRU等作为RNN的衍生,只可以处理欧几里得空间数据,对非欧空间数据的处理存在一定局限性,也无法解决非欧空间的推荐问题。
3.4 基于注意力机制的GNN推荐方法
GNN即图神经网络,不仅对数据具有强大的特征提取和表示能力,还可以表示非欧几里得结构数据,可用于解决非欧空间的推荐问题[27]。针对传统协同过滤方法的稀疏性问题,Wu等人[28]提出了一种双图注意力网络协作学习双重社会效应的推荐方法。该方法一方面由用户特定的注意力权重建模,另一方面由动态的、上下文感知的注意力权重建模,通过将用户领域的社会效应扩展到项目领域,缓解了数据稀疏性问题。模型可学习多方面社会影响的有效表示,具有良好的表达性,但社会图网络的构建相应增加了模型的时间复杂度。考虑当前网络社区推荐未充分考虑用户会受朋友偏好影响的问题,Song等人[29]提出了一种基于动态图注意力神经网络的社区推荐模型,图注意力网络用来捕获朋友的短期与长期偏好对用户的影响。其模型图如图5所示。详细步骤主要有:
(1)用户动态偏好建模:通过RNN对用户近期的浏览内容进行建模,得到用户的偏好hn。
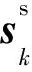
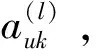
(16)
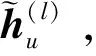
(17)
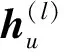
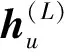
(18)
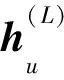
之后由Softmax函数得到项目y的概率,表示用户对项目y可能感兴趣的程度,如式(19)所示。最终根据这个概率的大小,向用户进行推荐。
(19)
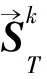
该模型能充分利用朋友的短期与长期偏好,获取社会关系对用户偏好的影响,但项目的特征提取过程过于粗糙,忽略了用户和项目之间的互动关系。将注意力机制应用到GNN邻近节点上,能够学习每个邻近节点与该节点之间的影响[30]。此外,基于图结构的广义神经网络能够表示除语言、视频和图像之外的非欧几里得结构数据,通过对图数据进行处理,可深入挖掘其内部的特征和规律,解决如社交网络、信息网络和基础设施网络等领域中的推荐问题。
4 基于注意力机制的深度学习推荐的难点
4.1 提取注意力方法的选择问题
在一些场景下,可选择的注意力方法可能有多种。如文献[6]中,引入多头注意力与单层自注意力皆可提升分类任务的性能,但较使用自注意力而言,多头注意力更能提升模型在语句层面的特征表达能力,在SemEval-2010数据集上的实验中,多头注意力模型的F1值相对自注意力模型的提高了2.0%左右,说明不同的注意力方法对提升模型性能的贡献是不同的。近年来,许多研究者在不同任务场景下又提出了不同注意力机制的新变体,如双注意力[31]、双向分块自注意力[32]等,如何结合这些新变体,选择适合当前推荐任务的注意力方法仍具有一定的复杂性。
4.2 注意力融入时机的选择问题
在注意力机制与CNN相结合的工作中,Yin等人[33]和Santos等人[34]通过实验证实了注意力机制用于池化层的效果比卷积层好。在此基础上,文献[35]将注意力与CNN池化层、项目潜在向量层及MLP输入层相结合进行对比实验,发现在稠密数据集上,注意力与池化层相结合的模型表现得更加稳定;而在稀疏数据集上,注意力与隐藏层相结合模型预测效果更佳,说明注意力引入时机的差异、数据集稠密度差别,都会影响最终的推荐结果。CNN相对神经网络,结构较简单,而在更加复杂的任务场景下,使用的神经网络也更加复杂,增加了注意力机制融入深度神经网络中的时机的难度。
4.3 融入注意力机制引起推荐模型复杂度增加问题
虽然注意力机制可以改善传统编码器-解码器的部分问题,但引入注意力机制获得注意力分配权重时,需要计算源语言句子中所有词语的权重,该过程计算资源耗费大,增大了推荐模型复杂度,还会导致模型的训练速度和推断速度下降。同时,引入注意力机制可能需要更多的存储资源,例如对于自注意来说,需要很大的存储空间来保存元素的对齐分数,需要的存储空间随序列长度呈二次方增长,因此在保证效率的前提下降低推荐模型的复杂度存在一定的难度。
4.4 融入注意力机制的推荐效果评价问题
注意力机制应用范围广,但并不是对所有模型引入注意力机制都可以提高性能。例如,因子分解机FM(Factorization Machine)利用同一特征向量表示某个特征和其它特征间的交互显然是不合理的。于是Juan等人[36]和Xiao等人[37]分别提出了FFM(Field-aware Factorization Machine)和AFM(Attentional FM)2种新的方法。FFM通过引入“域”的概念,对不同域使用不同的向量来解决这一问题。而AFM通过引入注意力机制对不同的交互项计算注意力权重,区分特征的重要程度。比较来看,AFM虽然和FFM效果相当,但是AFM通过引入新参数来弥补某方面的拟合能力,可能会造成过拟合现象。所以,对模型引入注意力机制后的推荐效果进行多方面的评价,也是当前基于注意力机制的深度学习推荐的一个难点。
5 基于注意力机制的深度学习推荐未来研究方向
5.1 多特征交互的注意力机制深度学习推荐
当涉及多特征交互时,通常采用矩阵分解模型来实现,如文献[37]利用一个神经注意力网络对不同交互特征的重要程度进行区分,改善了因子分解机的性能,并在真实数据集上将回归任务的性能提高了8.6%。但是,基于矩阵分解的协同过滤方法仅使用评分信息,不能捕捉更深层的特征信息。而文献[38]利用多层交互的非线性网络结构获取不同层次的交互结果,将RMSE指标的值降低了2%左右。但是,这种基于深度学习的推荐模型在提升推荐效果的同时,难以对推荐效果做出合理的解释。所以,考虑在多特征交互的推荐模型中加入注意力机制,以提高模型的可解释性,是值得研究的重要课题之一。
5.2 多模态注意力机制的深度学习推荐
信息的媒介有音频、文字、语音和图像等多种模态,目前对多模态信息的使用仍不够广泛,在多模态注意力机制中,主要使用语音和图像信息。文献[39]认为不同模态对于情感状态的影响是不同的,作者通过多模态注意力机制,将视频特征和音频特征进行融合,相比一些采用主流深度学习方法进行情感分析的任务,在性能上提高了2%左右。在深度学习的推荐研究中,除了利用文本、评分等信息外,还可以从视频和它模态信息中提取用户的偏好特征。所以,将多模态注意力机制结合深度学习技术,用于推荐系统也是未来的一个研究方向。
5.3 注意力机制的GNN推荐和其他推荐方法融合
由于GNN可以用来表示其它神经网络无法表示的非欧几里得结构数据,将其作为辅助工具应用在推荐系统领域,可有效缓解数据稀疏性问题[40]。文献[28]引入双图注意力网络来协作学习用户的静态和动态双重社会效应,同时考虑到用户领域和项目领域中不同的社会效应会相互作用,提出了基于多臂赌博机的一种新的融合策略来衡量这种交互作用,在真实数据集上的实验表明,其推荐精度最高提高了9.33%。因此,将注意力机制的GNN推荐融合其它推荐算法或深度学习技术,有利于提高推荐的效果。
5.4 基于注意力机制的深度学习群组推荐
大多数推荐技术应用于个性化推荐,但在很多情况下,推荐的产品或服务被一群用户所消费[41]。文献[42]提出了一种AGR(Attention-based Group Recommendation)模型,利用注意力机制学习群体中每个用户的影响权重,相较于基准模型其推荐性能提高了3%以上。但是,作者只在模型中使用了项目的ID信息,得到的信息非常有限,对模型性能的提升也有一定的限制。而李振新[43]提出的基于Phrase-LDA模型从评论中提取用户主题,更细致地从语义层面描述了用户的偏好,在群组推荐领域中具有一定的新颖性。考虑在AGR模型的基础上,将诸如社交关系、文本信息(例如事件描述)或时间等上下文信息用来学习群组推荐中的注意力模型,也是未来的一个研究方向。
5.5 基于注意力机制和深度学习的跨领域推荐
单领域个性化推荐中容易出现数据稀疏性和冷启动问题,使得推荐效果不够理想。而在跨领域推荐中,其它辅助域信息可以为目标域推荐提供帮助,从而解决传统单域推荐中数据稀疏和冷启动问题,因此逐渐成为学术界的研究热点。文献[44]构建了一个基于注意力机制和知识迁移方法的卷积-双向长短期记忆AC-BiLSTM(Convolution-Bi-directional Long Short-Term Memory based on Attention mechanism)模型,向BiLSTM中引入注意力机制得到不同词汇对文本的贡献程度,并且在目标函数中加入了正则约束项,避免在迁移过程中出现负迁移现象,使跨领域情感分类的平均准确率在2个数据集上分别提高了6.5%和2.2%。结合相关情感分类模型,将注意力机制应用到跨领域推荐研究中也是未来的一个研究方向。
6 结束语
注意力机制的特点是能主动从海量输入信息中选择对当前目标任务更重要的信息,在提高推荐模型性能的同时,提升深度学习可解释性。将注意力机制应用到深度学习推荐研究中,扩展了推荐模型中神经网络的能力。本文围绕注意力机制的结构、分类以及注意力机制在深度学习推荐中的研究等角度展开,并针对深度学习推荐模型中存在的注意力机制的选择、阶段融入、评价和模型复杂度增加等难点与挑战进行了分析,最后指出了基于注意力机制的深度学习推荐未来的研究方向。
