面向DRAM和NVM异构混合内存架构的排序连接算法优化*
2021-03-01金培权
杨 柳,金培权
(中国科学技术大学计算机科学与技术学院,安徽 合肥 230027)
1 引言
在传统的存储体系结构中,存储系统借助易失性内存DRAM提供高性能的数据访问,利用性能较差但价格低廉的固态硬盘SSD(Solid State Disk)或者硬盘HDD(Hard Disk Drive)保证数据的持久性。相变存储器PCM(Phase Change Memory)、自旋矩传输磁性存储器STT-RAM(Spin Transfer Torque RAM)和可变电阻式存储器RRAM(Resistive RAM)等非易失内存NVM(Non-Volatile Memory)引入到计算机系统后,对现有的存储体系结构带来了极大的影响[1-3]。与SSD相比,NVM支持按位寻址,读写延迟低,而且可以直接被CPU存取,因此可以作为内存使用;与DRAM相比,NVM掉电数据不丢失,且存储密度更高,因此能够支持海量的数据存储。目前,NVM离实用场景越来越近。2019年4月,DIMM接口的NVM(傲腾DCPMM)已正式投放市场,单片容量可达512 GB且单机可支持高达8 TB的NVM容量(https://www.intel.cn/content/www/cn/zh/architecture-and-technology/optane-dc-persistent-memory.html)。
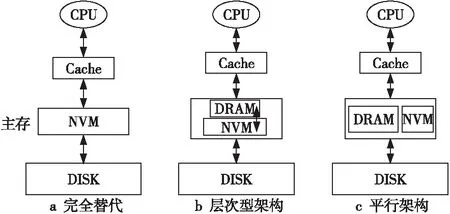
Figure 1 Possible architecture involving NVM
理论上,在内存架构中引入NVM后可能形成3种架构(如图1所示)。第1种用NVM完全替代DRAM,如图1a所示。但是,由于NVM与DRAM相比具有访问时延高、写次数有限和写功耗大等缺点[4],完全用NVM替代DRAM从目前看不是最佳选择。第2种是层次型架构,如图1b所示。这种架构需要把DRAM作为NVM的缓存,而NVM则作为DRAM的第2级内存。这一架构主要存在2个方面的问题:首先,由于DRAM只是作为NVM的缓存,因此系统可见的内存仅为NVM的空间,在内存空间使用上不合算;其次,这一架构只是利用了NVM比DRAM容量大的优点,操作系统的数据访问依然还是通过DRAM,没有充分利用NVM的非易失性特点。第3种架构是平行架构,即NVM和DRAM同时作为同一层次的主存使用,如图1c所示。在这种架构下,系统可用的内存空间等于DRAM的容量和NVM的容量之和,而且操作系统可以感知2类内存的特性,可以充分利用DRAM和NVM各自的优点。从目前DRAM和NVM的发展趋势来看,DRAM和NVM并存的异构混合内存架构更具有可行性和发展前景。无论采用哪种混合内存架构,出发点都是要尽可能地同时发挥DRAM和NVM的优势。
在未来理想的情况下,随着NVM容量的逐步增加和成本的下降,在异构混合内存架构中,我们可以只使用DRAM和NVM来构建内存数据库系统,以支持高性能的在线处理与存储,而磁盘(DISK)则成为离线的归档存储设备。这种情况下,主存和DISK之间的I/O操作就不再是决定系统性能的主要因素,这对传统的数据库管理系统提出了新的挑战。因为传统的数据库管理系统以DRAM+DISK的架构为基础,绝大部分的数据结构和算法都以减少DRAM和DISK之间的I/O操作为主要目标,因此不适合基于DRAM和NVM的异构混合内存架构。
基于上述背景,本文重点研究传统数据库管理系统中的排序连接算法在异构混合内存架构上的优化问题。传统的排序连接算法如果直接移植到异构混合内存架构上不能充分发挥DRAM和NVM的特性,因此必须针对架构的特性进行重新设计。本文详细分析了异构混合内存架构对排序连接算法带来的挑战,提出了基于键值分离和键值去重的C-Join算法,并进一步提出了C-Join算法的3种实现方式。最后的实验结果表明,本文提出的C-Join算法在异构混合内存架构上的性能明显优于传统排序连接算法,并且有效降低了DRAM的使用代价。总体而言,本文的主要工作和贡献可总结为如下几个方面:
(1)针对NVM可字节寻址和低延迟的特性,采用键值分离策略重新实现了传统的排序连接算法。从目前文献看,本文提出的键值分离的混合内存排序连接策略具有一定的新意。
(2)在键值分离策略的基础上,进一步提出了面向异构混合内存架构的新的排序连接算法C-Join和键值去重机制,通过减少连接中重复的键值来降低连接过程的内存开销,从而减少CPU需要处理的数据量,最终提升连接算法的时间性能。
(3)讨论了C-Join算法的不同实现方式,提出了3种可能的策略,并进行了对比实验。结果表明,键值分离策略可以有效减少DRAM的使用,同时提高了算法的性能,而C-Join算法的几种实现方式均能够在保证时间性能的前提下保持较高的内存空间利用率。
2 相关工作
2.1 非易失内存技术
非易失内存是一种新型的存储介质,它不同于存储器和磁盘,属于存储级内存,既具有磁盘的特点,又具有内存的特点。与传统的DRAM和SRAM不同,新兴的非易失性内存,如相变存储器(PCM)、电阻式记忆体(ReRAM)和铁电存储器(FRAM),使用电阻存储器来存储具有更高密度和近零泄漏功率的信息。因此,NVM有希望成为构建下一代主存和缓存的有主要技术[1-5]。
这些非易失性内存虽然制作材料和制作工艺不同,但却有着相似的特性,如表1所示,以PCM为例,与DRAM、机械硬盘和固态硬盘进行比较。(1)它们具有高密度和低延迟的特点;(2)它们可以字节访问并持久化数据;(3)它们都具有读写固有的不对称特性[4,5],写延迟比读延迟大得多,并且写操作相比读操作会消耗更多的能量;(4)NVM通常具有有限的写耐久性。因此,在使用NVM时,有必要减少甚至避免写操作。
2.2 排序连接算法
排序连接算法一般指排序归并连接算法。为了将2个输入表数据按照连接键进行排序,算法先对输入进行划分,然后对每个划分进行排序后多路归并得到最终的排序结果,最后遍历2个排序后的表得到最终的连接结果[6]。排序归并连接的时间代价主要集中在排序过程中,在此过程中算法会对磁盘进行大量的读写操作。通常来说排序连接算法的时间性能会比哈希连接算法差,但是排序连接的通用性更好,因为哈希连接一般只能解决等值连接问题,而排序连接可以处理非等值连接问题。当遇到选择度为M∶N的连接问题时,哈希连接更是无能为力,而排序连接则可以完美地解决这类问题。另外,当数据库中关于连接问题的表数据已经按照连接键排好序时,采取排序连接算法也能获得非常好的性能。
2.3 连接算法优化
自20世纪70年代以来,数据库连接算法得到了广泛的研究。目前对连接算法的研究主要集中在硬件优化、并发执行等方面。Li等人[7]提出了面向闪存的DigestJoin算法,利用固态硬盘高速的随机读能力减少了中间结果和数据处理量。Balkesen等人[8]通过对不同算法和体系结构的实验分析比较发现,对硬件进行优化和参数调优仍然很重要,具有硬件意识的连接算法比硬件无关的算法性能更好。Albutiu等人[9]设计了一个新的基于部分分区排序的大规模并行排序归并MPSM(Massively Parallel Sort-Merge)连接算法,证明了MPSM在具有数十亿对象的大型内存数据库上的竞争性能。Viglas[10]提出了Segment Sort、Hybrid Sort和LazySort等算法,通过将写多读少和写少读多的排序算法结合在一起使用,采用以读换写的方式使得总体的读写代价达到最小,在整体性能可观的同时减少了对NVM的写操作。
一些研究者针对面向NVM的连接算法优化开展了研究。文献[11]中研究者提出了数据库虚拟分区连接算法,该算法通过虚拟分区的方式,避免了数据库分区时的拷贝过程,大大减少了数据库连接算法执行过程中对NVM的写操作。文献[12]则研究了多关系连接算法在NVM内存环境中的优化方法,作者提出的NVjoin算法利用抽样估计得到中间结果数最小的连接次序,该连接次序使得对多个关系执行连接时,使用最少的内存空间,并且连接过程中对NVM读写总数最少。但是,这些方法都是针对NVM Only的架构,不同于本文所针对的异构混合内存架构。
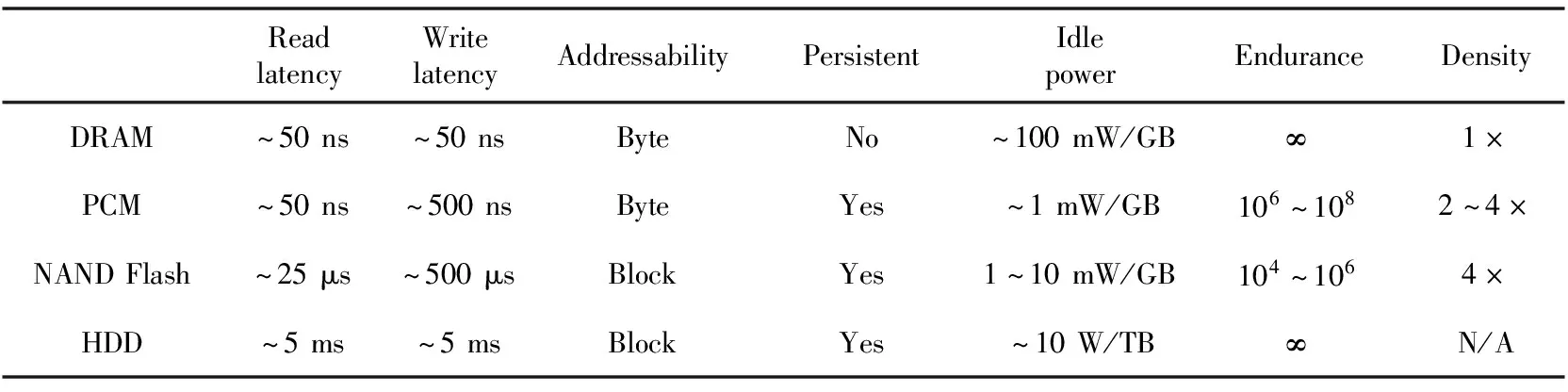
Table 1 Comparison of several storage medias
在面向DRAM和NVM异构混合内存架构的连接算法方面,Yang等人[13]在2019年提出了一种新的Hash连接算法BF-Join。BF-Join重新设计了Hash分区的数据结构,使用NVM在Hash连接过程中存储构建表和探测表的数据,以避免向NVM写入数据。BF-Join还引入了布隆过滤器来加速连接过程,并将布隆过滤器设计为一个Cacheline的大小,从而减少BF-Join连接过程中的缓存丢失。从现有文献看,目前还没有直接针对基于DRAM和NVM异构混合内存架构排序连接算法的优化工作。
3 C-Join算法
本节介绍面向异构混合内存架构的新型排序连接算法C-Join。C-Join的主要设计思想包括2个方面,即键值分离和键值去重,下面分别加以讨论。
3.1 键值分离策略
DRAM和NVM是2种各有特点的存储设备,它们的优势和缺点也都很明显。DRAM的读写性能非常好,但是受限于容量和能耗;NVM的容量能耗可观,并且读写性能与DRAM相当,但是读写不对称且写耐久有限。一个主要的问题是如何在基于DRAM和NVM混合内存的系统中平衡二者的使用,以达到最优的性价比和最佳的性能。NVM由于在写入方面有着过多的局限(写速度相对慢、写能耗相对高、写耐久有限),所以不能作为经常写入的设备,与此同时DRAM就理所当然地成为了处理数据结构中需要经常读写的内存设备,而NVM的容量大的特点使得其更适合作为多读的内存存储设备。
为了使排序连接算法适合异构混合内存架构,本文首先提出基于键值分离策略的排序连接思路。通过键值分离,将一条记录拆分为键(key)和值(value),然后在NVM中维护整条记录或者只维护值,而在DRAM中维护键和指向原记录的指针。该策略不仅大大减少了DRAM的使用量,也减少了CPU需要处理的数据量,从而提升性能。
键值分离的策略最早是在2017年在针对闪存存储优化的Wiskey[14]系统中提出的,本文受到Wiskey的启发,首次将键值分离策略与排序连接算法相结合,并用于优化异构混合内存架构上的排序连接性能。当2个表R和S在基于DRAM和NVM的异构混合内存架构上执行排序连接时,按照传统的排序连接算法,需要把输入的表数据存储在NVM中,然后将每条记录〈key,value〉复制到DRAM中进行排序,排序完成后再对表R和S进行连接操作。而在基于键值分离的排序连接算法中,仍将原始表数据存储在NVM中,但是在执行排序和连接操作时采用〈key,rowid〉形式来代表整条记录,即只将键和记录指针读入到DRAM中进行处理,记录的值则仍然保留在NVM中。该方式可以有效减少DRAM的使用量,也可以减少CPU处理的数据量,因此有助于提高排序连接的性能。
3.2 键值去重策略
排序连接算法的基本思想很简单,首先将输入的2个表排序,排序完成后再进行连接操作。不同于哈希连接算法只能解决等值连接的问题,排序连接算法还可以处理不等关系的连接问题,其根源在于排序连接算法中的连接操作是在已经排好序的数据上执行的,而排序操作也是算法中最重要的部分。一般来说算法会使用通用的快速排序、堆排序、归并排序等排序算法,这些算法确实可以高效地完成排序操作,但是对于选择度为M∶N的连接问题来说,还可以进一步优化。
选择度为M∶N意味着在表R中的1条记录在S表中可能会有多条(超过1条)记录与之相匹配,反之亦然。也就是说,在表R和S中有多个key相同而value不同的记录。如果按照传统的方式执行算法,这些记录〈key,value〉都需要被传输到DRAM中进行排序操作,因此存在着大量重复的数据拷贝,即key的多次拷贝。本文在键值分离策略的基础上,进一步提出键值去重策略,通过去除重复的键来进一步降低DRAM的使用代价。
在选择度为M∶N的连接问题中,输入的表数据中可能有多个key相同而value不同的记录,为了能够减少key的重复拷贝,本文采取对具有相同key的记录进行合并的方式来组织数据。算法1给出了基于键值分离和键值去重的C-Join算法流程。首先,为了对表R和S中相同key的记录合并,分别为它们分配了2个桶数组bucketsR和bucketsS,这2个桶数组的个数是按照连接键的上阈值Kmax设定的。接着,遍历2个表的每条记录,通过key可以确定它所属的那个桶,然后将之插入到该桶中,在插入时使用〈key,rowid〉的形式来表征完整的记录。当2个表的记录都插入到对应的桶中时,整个排序操作也已经完成。接着,进行连接操作,桶数组bucketsR和bucketsS中连接键相同的桶是互相匹配的数据,而那些空的桶则跳过,最终得到连接的结果。
算法1C-Join
Input:R,S;
Output:none。
1 mallocKmaxbucketsbucketsR;
2foreach record inRdo
3 insert 〈key,rowid〉 intobucketsR[key];
4endfor
5 mallocKmaxbucketsbucketsS;
6foreach record inSdo
7 insert 〈key,rowid〉 intobucketsS[key];
8endfor
9foreach bucket inbucketsRdo
10 find the mathing bucket inbucketsS;
11endfor
3.3 C-Join的3种实现方式
在C-Join算法中,桶的数据结构是整个算法中的关键部分,桶的设计方案也会直接影响算法在执行过程中的DRAM代价和时间性能。因此,本节针对桶的设计提出3种实现方案,即链式结构、线性结构和预分配线性结构。
(1)链式结构(C-Join-Chained)。如图2所示,在链式实现中,桶由一个key形成的头节点以及后面跟着的若干个rowid节点组成,节点之间以指针相连,这样的数据组织形式的优点在于方便灵活,可以灵活地扩展桶的大小,但是由于指针太多会对空间利用率和性能造成一定的影响。

Figure 2 C-Join-Chained
(2)线性结构(C-Join-Linear)。线性实现方案的思路如图3所示,与链式实现相比,线性实现在rowid的管理上采用了线性数组的形式,这样的组织形式减少了指针的占用空间,并且在访问数据时避免了由指针带来的多次寻址问题,从而缩短了算法的执行时间。但是,其缺点在于该种实现方式必须事先分配一个合理大小的空间以容纳所有的记录,这往往会带来一部分的空间浪费。

Figure 3 C-Join-Linear
(3)预分配线性结构(C-Join-Premalloc)。线性实现中需要提前分配一个合理大小的空间,带来了一些内存空间的浪费,因此,希望找到一种方法能够提前准确地分配一个空间使之刚好能够容纳所有的记录。要想达到这个效果,那么就必须要知道每个桶所需容纳的记录的数量,而数据库中一般没有这项参数。因此,只能先读取一遍数据,以统计每个桶中记录的数量,然后再分配每个桶的空间,这样就避免了一部分的内存浪费。但是,同时也会造成时间性能的下降,因为多读取了一遍数据。具体数据结构如图4所示,与线性实现的结构基本相同,只是减少了桶中不必要的空间浪费,使得整个桶空间变得非常紧凑。
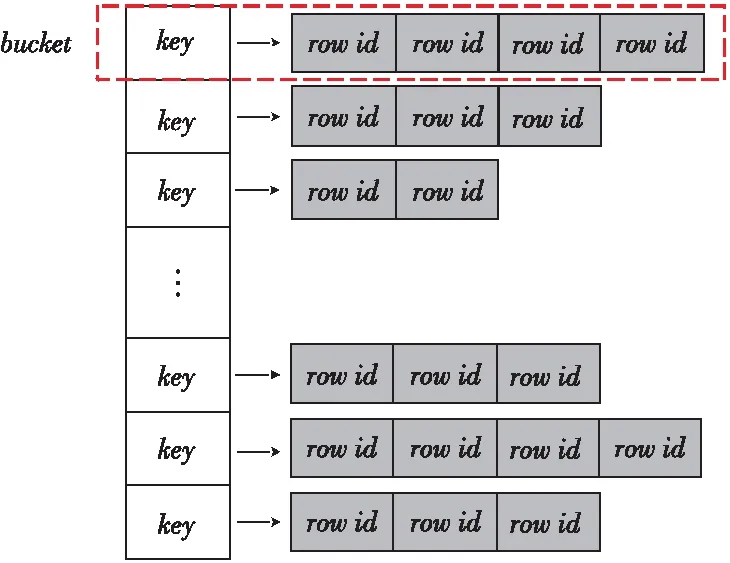
Figure 4 C-Join-Premalloc
从理论上来看,链式结构除了在使用上比较灵活外,在内存空间和运行时间方面表现都不会很好。而当表数据每个独特key出现次数比较接近而且已知出现次数的上限时,采用线性结构比较好,至于更普遍的情况则是采用预分配线性结构比较好。
4 实验结果
4.1 实验设置
本文所有的实验都是在安装了Ubuntu 18.04系统的笔记本电脑上执行的。该电脑的处理器为Intel® CoreTMi5-4210U CPU @ 1.70 GHz 2.40 GHz,L1、L2、L3缓存大小分别为128 KB、512 KB和3 MB。DRAM内存大小为12 GB。由于排序连接算法的所有实验均不涉及到NVM的写操作,所以在实验中没有模拟NVM的写延迟,而NVM读延迟与DRAM相当,所以可以用DRAM来模拟NVM。在实验中主要考察算法的时间性能和DRAM的代价。
由于目前还没有基于异构混合内存系统上的排序连接算法,所以实验中主要对比C-Join算法与传统的排序连接算法(SortJoin)。为了更细致地测试键值分离与键值去重策略的性能,本文单独实现了基于键值分离的排序连接算法,记为SortJoin-V。同时也对比了采用了键值分离和键值去重的C-Join算法的3种实现方式。所有对比的算法如下所示:
(1)传统排序连接算法(SortJoin)。这个算法不使用键值分离而是使用〈key,value〉整条原始数据执行算法,其中使用的排序算法是快速排序算法。
(2)键值分离的排序连接算法(SortJoin-V)。该算法与传统排序连接算法类似,只不过采用了键值分离策略,使用〈key,rowid〉来表征整条数据。
(3)C-Join-Chained(CJoin-C)。C-Join-Chained是C-Join 3种实现方式的一种,它采用了链式结构来组织桶,桶中的〈rowid〉以指针相连。
(4)C-Join-Linear(CJoin-L)。C-Join-Linear是C-Join 3种实现方式的一种,它采用了线性数组结构来组织桶,桶中的〈rowid〉存储在一个地址连续的空间中。
(5)C-Join-Premalloc(CJoin-P)。C-Join-Premalloc是C-Join 3种实现方式的一种,它与C-Join-Linear类似,但是对桶的大小采用预分配的方式进行设置,使得空间更加紧凑。
上述所有算法都使用了相同的NVM和DRAM设置。表R和表S都在NVM上维护,所有中间数据和数据结构都在DRAM上维护。由于在连接过程中不会对NVM上的表数据进行写操作,因此,排序连接算法的实验中只关注DRAM的使用量和运行时间。
在工作负载方面,使用与Balkesen等人[8,15]和Albutiu等人[9]类似的工作负载生成方式。文献中大多采用key加payload的方式,key的大小一般为4 B或8 B。在本文实验将记录的key和rowid设为8 B,而value的默认大小设置为1 024 B,在比较键值分离的排序连接算法实验中,将通过改变value的大小来观察算法在内存用量和运行时间方面的表现。N表示表R和表S中独特的key的数量,KR和KS分别表示表R和表S中每个独特key出现的次数,表R和表S的记录数量分别为N×KR和N×KS,其中N设置为100 000,KR和KS分别设置为10和20。
4.2 SortJoin vs.SortJoin-V
(1)DRAM代价:如图5和图6所示,采用了键值分离策略的SortJoin-V的DRAM使用量大大减少,而且随着value的增大,SortJoin-V的DRAM使用量不再增加。当N增大时,SortJoin-V的DRAM使用量虽然略有增加,但是与传统的SortJoin相比完全可以忽略不计。与SortJoin相比,SortJoin-V大幅减少了DRAM使用量(SortJoin的DRAM使用量约为SortJoin-V的16倍)。从图5和图6中可以得到一个结论,SortJoin-V对DRAM内存空间的使用更加高效,而且当输入数据规模不断增大时,SortJoin-V会节省更多的DRAM空间。
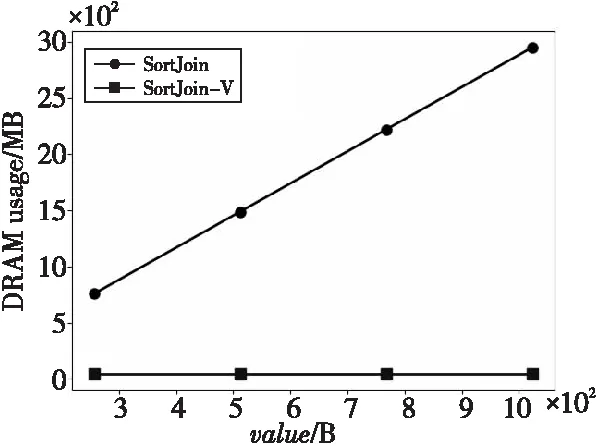
Figure 5 DRAM usage of SortJoin and SortJoin-V with different value
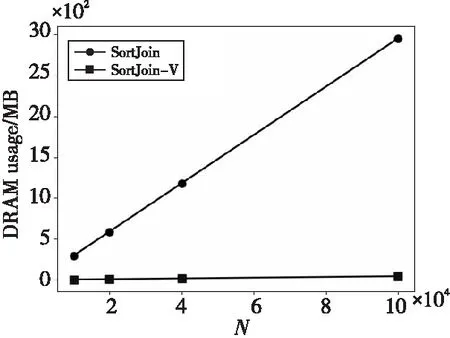
Figure 6 DRAM usage of SortJoin and SortJoin-V with different N
(2)运行时间:排序连接算法的运行时间如图7和图8所示,SortJoin的运行时间比SortJoin-V的运行时间高出约2.4倍,而且随着数据规模的增大,SortJoin-V的运行时间增长速度也比SortJoin的运行时间增长速度更为缓慢,这表明采用了键值分离策略的排序连接算法在运行时间方面更有优势。

Figure 7 Running time of SortJoin and SortJoin-V with different value
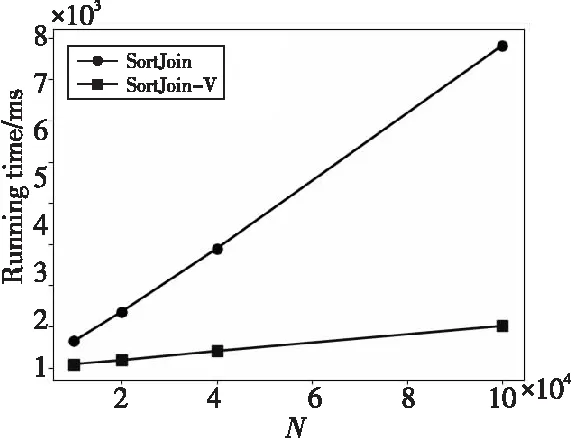
Figure 8 Running time of SortJoin and SortJoin-V with different N
4.3 C-Join vs.SortJoin-V
在这一节中,将SortJoin-V作为基准与C-Join的3种实现方式进行对比,具体结果如图9和图10所示。
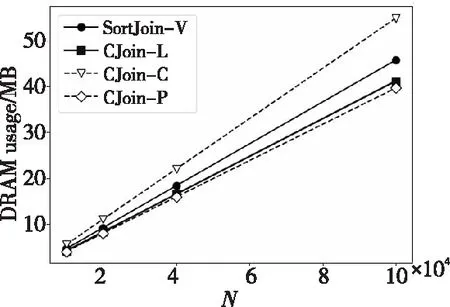
Figure 9 DRAM usage of C-Join and SortJoin-V with different N

Figure 10 Running time of of C-Join and SortJoin-V with different N
从图9中可以看出,与SortJoin-V相比,CJoin-L和CJoin-P的DRAM使用量更低,而其中CJoin-P的最低,在最好情况下比SortJoin-V节省了13.3%的DRAM空间。这主要归功于CJoin-P的预分配策略,这也与本文之前的分析相符合。从图10中可以看到,CJoin-L是4种算法中执行时间最短的,最多比SortJoin-V节约了27.8%的时间,运行时间最高的则是采用了大量指针的CJoin-C,而CJoin-P由于需要提前读一次表数据,所以性能略有下降,与SortJoin-V的性能相当。总的来说,C-Join实现方式中的CJoin-L和CJoin-P表现比较出色,特别是CJoin-L在DRAM使用量和时间性能方面都要比SortJoin-V更好。
4.4 KR对C-Join算法的影响
由于C-Join算法的核心思想是通过减少数据中重复的key来达到内存空间的节省和时间性能的提升的,所以KR和KS(KR和KS分别表示表R和表S中每个独特key出现的次数)会对C-Join的2个评估指标产生影响。图11和图12展示了不同KR时DRAM使用量和运行时间的变化(这里我们只使KR变化,而KS设置成KR的2倍)。
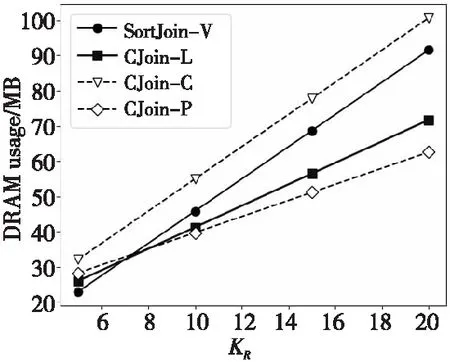
Figure 11 DRAM usage of C-Join and SortJoin-V with different KR
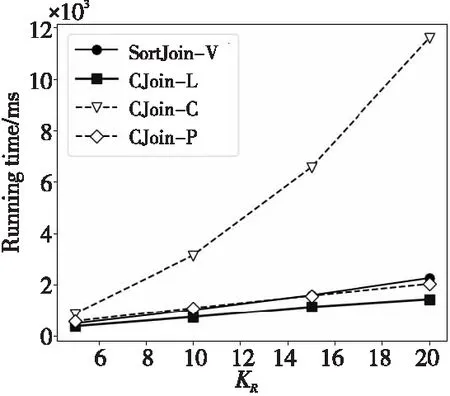
Figure 12 Running time of C-Join and SortJoin-V with different KR
从图11和图12可以观察到,随着KR的增大,CJoin-L和CJoin-P在DRAM使用量方面增加得较为缓慢,在运行时间方面,CJoin-L的增速也是4种算法中最低的。综合来看,CJoin-L的实现方式可以很好地应对不同KR的连接问题,在内存使用量和运行时间方面其性能都超过了SortJoin-V,而CJoin-P虽然使用的内存空间更少,但是在运行时间方面却没有优势。
5 结束语
本文针对基于DRAM和NVM的异构混合内存架构提出了一种基于键值分离和键值去重策略的新型排序连接算法C-Join。键值分离的策略可以充分发挥NVM的独特特性和DRAM的高性能优势,从而能够有效减少DRAM使用量,提升连接性能。键值去重策略则通过消除连接过程中重复的键值拷贝进一步降低了DRAM的代价。本文在算法设计的基础上,进一步给出了C-Join算法的3种实现方式,通过采用不同的桶数据结构来执行C-Join算法。在模拟数据集上的实验结果表明,键值分离的策略能够有效地缩短连接时间和降低DRAM代价。C-Join算法的3种实现方式均能够进一步优化DRAM代价和时间性能。
