多GPU系统虚实地址转换架构研究*
2021-03-01魏金晖鲁建壮
魏金晖,李 晨,鲁建壮
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
由于图形处理器GPU(Graphics Processing Unit)的大规模数据并行性,使得其广泛应用于信号处理[1]、图像分析[2]、大规模仿真[3,4]和机器学习[5,6]。近年来,随着大数据的发展,GPU应用的数据集规模急速增加,这对GPU的处理能力提出了挑战。由于摩尔定律即将达到极限[7],通过在单个芯片中集成更多的计算资源来提升单GPU的性能变得越发困难;而多GPU系统通过提升GPU处理器级的并行性,成为应对该挑战的一种方案[8-11]。
近几年GPU制造商对内存虚拟化(Memory Virtualization)的支持进一步简化了编程,提高了资源利用率。内存虚拟化需要地址转换(Address Translation)的支持。地址转换指的是把虚拟地址转换成物理地址的过程。为了提高地址转换的效率,减小转换延迟,研究者提出了快表TLB(Translation Lookaside Buffer)[12,13]。普遍认为,当前GPU的地址转换架构是基于TLB的[12-14]。而且实验表明GPU地址转换的效率对系统的性能具有重要影响[13,14]。
当前多GPU系统中有2种常见的地址转换架构,即集中式地址转换架构和分布式地址转换架构。2种架构的主要区别在于系统中各GPU是否具有本地的内存管理单元GMMU(GPU Memory Management Unit)。例如,NVIDIA Volta架构的GPU具有GMMU[15],因此由该GPU组成的多GPU系统使用分布式地址转换架构;AMD GCN架构的GPU没有GMMU[16],因此由该GPU组成的多GPU系统使用集中式地址转换架构。当前学术界研究的热点为集中式地址转换架构。在该架构中,当GPU的L2 TLB失效后,请求被送往CPU端的输入输出内存管理单元IOMMU(Input Output Memory Management Unit)进行转换。在分布式地址转换架构中,当L2 TLB失效时,请求被送往本地的GMMU进行页表查询,如果所需要的页表项位于本地GPU,则该转换过程就可以在本地完成;否则,请求被送往CPU端的IOMMU进行转换。
本文对上述2种地址转换架构进行了深入分析和比较。集中式地址转换架构较为简单,系统中所有GPU结点的页表查询操作均在CPU端的IOMMU完成,因此硬件开销相对较小。分布式地址转换架构相对复杂(硬件开销也更大),系统中每个GPU结点具有自己的GMMU,当访问的内存页位于本地内存时,页表查询在本地GMMU完成;当访问的内存页位于其它结点内存或者CPU内存时,页表查询在CPU端的IOMMU完成。实验结果表明,在L2 TLB失效后,主要访问本地内存页表项的应用,即数据集中共享数据较少的应用,在分布式地址转换架构中的性能更好;若应用在L2 TLB失效后主要访问远程内存页表项,即数据集中共享数据较多的应用,更适用于集中式地址转换架构。
2 背景
2.1 多GPU系统
由于功耗和散热等问题,在单一芯片上集成更多的晶体管变得越来越困难,因此提升单GPU的性能也越发困难。多GPU系统通过开发GPU处理器级的并行性,在处理大数据应用方面展现出一定的优势。学术界也开展了对多GPU系统的研究[8-11]。近几年,GPU制造商引入了对统一内存(Unified Memory)、按需页迁移(On-demand Page Migration)等技术的支持,这些技术简化了GPU的编程,也提高了多GPU系统的可用性。然而,由于GPU之间连接(例如PCIe)的带宽较低,延迟较高,大量的非本地(远程)访问成为多GPU系统主要的性能瓶颈[9]。
常用的GPU编程框架,如CUDA和OpenCL,都支持多GPU系统编程。在这2种编程框架中,所有的GPU都对编程人员可见,编程人员可以选择将内核程序(Kernel)映射到GPU的方式。目前有2种多GPU系统编程模型[17],即分立式多GPU模型和统一式多GPU模型,如图1所示,其中CU表示计算单元(Compute Unit)。在分立式多GPU模型中,一个Kernel只能被分配到一个GPU上执行,这使得针对单GPU开发的应用不能直接在分立式多GPU系统中运行,编程人员需要重新编程才能利用多GPU系统的并行计算能力。在统一式多GPU模型中,分配任务以线程块(Thread Block)为粒度,即单个Kernel的任务可以被分配到多个GPU上执行,针对单GPU开发的应用可以直接在统一式多GPU系统中运行,这在很大程度上减轻了编程人员的负担。因此,统一式多GPU模型是目前的研究重点,本文也是针对统一式多GPU模型开展研究。
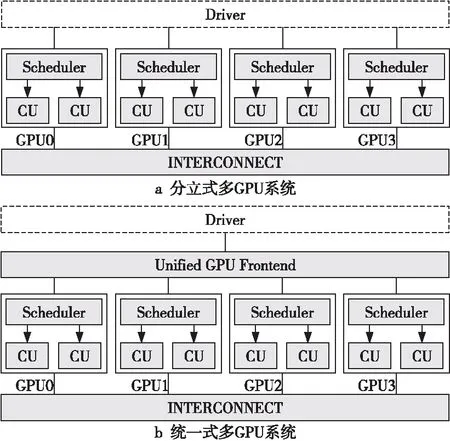
Figure 1 Discrete multi-GPU system and unified multi-GPU system
2.2 多GPU系统远程数据访问机制
多GPU系统中的远程数据访问机制是指当GPU所需要的数据不在本地内存时,使用何种方式访问。目前,主要有3种数据访问的机制,即缓存行直接访问、页迁移和首次访问页迁移(First-Touch Page Migration)。远程数据访问机制对于地址转换架构有着一定的影响,具体将会在本文的第3节进行分析。接下来将详细介绍这3种机制。
2.2.1 缓存行直接访问
缓存行直接访问指的是当GPU所访问的数据不在本地内存时,通过RDMA(Remote DMA)直接将数据从数据所在的GPU取到对应的计算单元CU中[8,9,15],而不是通过缺页处理机制迁移整个内存页。该机制的具体步骤如下所示:
(1)数据访问请求在访问L1 Cache之前首先进行地址转换,如果对应的页表项不在本地,则地址转换请求被送往IOMMU。
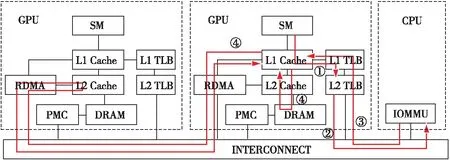
Figure 2 Centralized address translation architecture
(2)IOMMU通过地址转换服务ATS(Address Translation Service)而不是缺页中断响应来处理该请求[18],查询页表并返回对应的页表项。
(3)收到页表项后,地址转换过程结束。L1 Cache通过对应的物理地址判断数据位于哪个GPU中,并将请求重定向到RDMA部件。RDMA将请求送往远程GPU的L2 Cache,获取该数据并返回给L1 Cache。为了保证数据的一致性,L1 Cache直接把数据发送给对应的CU,而不会把数据缓存到Cache Line中。
2.2.2 页迁移
页迁移指的是当GPU需要的数据不在本地内存时,会把对应的内存页从源GPU迁移至本地内存[8,15]。假设GPU2所需要的数据位于GPU1的内存,则该机制的具体步骤如下所示:
(1)GPU2的访存请求在访问L1 Cache前先进行地址转换,如果对应的页表项不在本地,则地址转换请求被送往IOMMU。
(2)IOMMU启动缺页处理机制,通过查询得知GPU2需要的页表项位于GPU1,通知GPU1排空其CU流水线中正在执行的指令,并刷新(Flush)其Cache和TLB中与该页表项相关的内容。
(3)页迁移控制器PMC(Page Migration Controller)将内存页从GPU1迁移至GPU2。
(4)迁移完成后,GPU1再次执行被刷新的指令。
(5)IOMMU更新页表信息,并返回对应页表项,GPU2根据返回的页表项信息进行数据访问。
2.2.3 首次访问页迁移
首次访问页迁移是页迁移的特殊情况,它指的是CPU把内存页迁移至第1次访问它的GPU中,具体步骤与页迁移基本相同。该机制通常用于数据分配,能大大降低程序员的工作负担。
3 多GPU中的地址转换架构
当前的多GPU系统有集中式地址转换架构和分布式地址转换架构2种地址转换架构。本节介绍这2种地址转换架构的原理,并分析它们的优点和缺点。
3.1 集中式地址转换架构
集中式地址转换架构的原理和工作流程如图2所示。访存请求在访问L1 Cache之前首先访问L1 TLB,如果L1 TLB失效,则请求被送往L2 TLB(①)。如果L2 TLB也失效,则请求被送往CPU端的IOMMU(②)。IOMMU进行页表查询,并将相应的页表项返回给GPU(③)。GPU获取页表项后完成地址转换,L1 Cache根据物理地址获取对应的数据。如果数据位于本地内存,则按照内存层次的结构依次进行访问,取得所需的数据;如果数据位于远程GPU,则L1 Cache将请求重定向到RDMA,访问远程GPU的L2 Cache,以获取所需数据(④)。
3.2 分布式地址转换架构
分布式地址转换架构的原理和工作流程如图3所示。访存请求在访问L1 Cache前首先访问L1 TLB,如果L1 TLB失效,继续访问L2 TLB(①)。如果L2 TLB也失效,则请求被送往GMMU。GMMU中的页表漫游器(Page Table Walker)进行页表查询,如果所需的页表项位于本地内存,则GMMU将页表项返回给L2 TLB(②)。如果所需的页表项不在本地内存,请求被送往IOMMU(③)。IOMMU进行页表查询,并将相应的页表项返回给GPU,并且GMMU会判断页表项的物理地址是否在GPU上。若页表项对应的物理地址在GPU上,则将该页表项写入GMMU中,并且将页表项返回给L2 TLB;若不是,则只将页表项返回给L2 TLB(④)。GPU获取页表项后完成地址转换,L1 Cache根据物理地址获取对应的数据。如果数据位于本地内存,则按照内存层次的结构依次进行访问,取得所需的数据;如果数据位于远程GPU,则L1 Cache将请求重定向到RDMA,访问远程GPU的L2 Cache,以获取所需数据(⑤)。
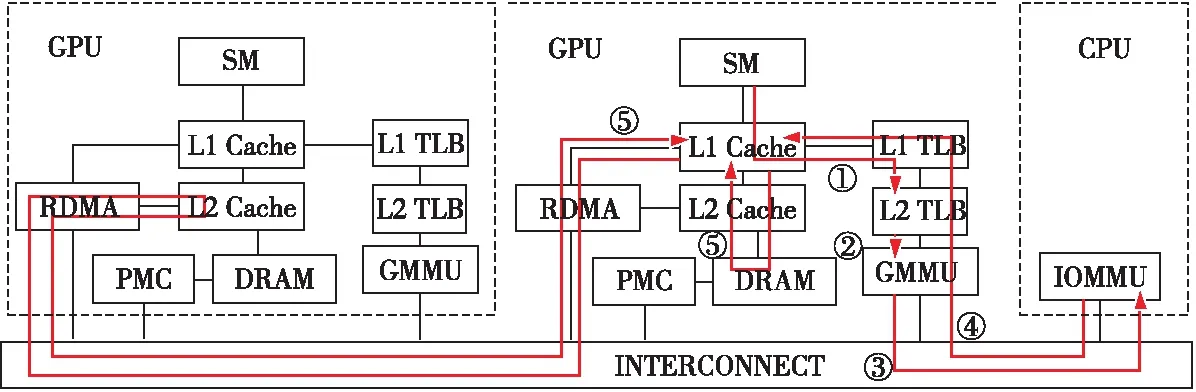
Figure 3 Distributed address translation architecture
3.3 虚实地址转换架构对比分析
集中式地址转换架构和分布式地址转换架构在硬件开销、地址转换流程、远程数据访问机制的开销以及地址转换性能等方面均存在差异,本节将从以上几个方面深入分析2种架构的特点。
(1)硬件开销。分布式地址转换架构与集中式地址转换架构的主要区别在于系统中各GPU结点是否具有本地的GMMU。普遍认为,GMMU中包含高度线程化的页表漫游器(Highly-Threaded Page Table Walker)等部件,因此会引入部分硬件开销。此外,本地内存中需要存储一些页表项,也会引入部分存储开销。
(2)地址转换流程。由于分布式地址转换架构的各GPU结点具有本地的GMMU,当L2 TLB失效时,转换请求首先被送往GMMU进行页表查询,如果没有在本地页表中找到对应的页表项,请求被送往IOMMU。对于集中式地址转换架构,当L2 TLB失效时,请求被直接送往IOMMU。因此,如果转换请求通过GMMU的页表查询可以在本地找到对应的页表项(即命中),就可以省去远程访问IOMMU的步骤,由于访问IOMMU的延迟远大于访问本地GMMU的延迟,在这种情况下,分布式地址转换架构可以减小地址转换开销。相反,如果转换请求没有在本地找到对应的页表项(即失效),分布式地址转换架构会因为额外的页表查询步骤而带来性能损失和页表查询开销。
(3)远程数据访问机制的开销。第2.2节指出,目前主要有3种远程数据访问机制:缓存行直接访问、页迁移和首次访问页迁移。2种地址转换架构的地址转换流程也会对远程数据访问机制的开销产生影响。对于缓存行直接访问机制,与集中式地址转换架构相比,分布式地址转换架构需要访问本地GMMU,因此会增加地址转换开销,进而增加缓存行直接访问开销。对于页迁移机制,分布式地址转换架构会引入额外的访问本地GMMU的开销。此外,为了保证数据的一致性,集中式地址转换架构在迁移页之前,需要清除源GPU中TLB对应的页表项;分布式地址转换架构还需要清除源GPU中GMMU的页表项信息,页迁移之后,需要更新目标GPU中的页表项信息。因此,分布式地址转换架构会引入额外的清除和更新页表项的开销。对于首次访问页迁移机制,分布式地址转换架构会引入额外的访问GMMU的开销、清除和更新页表项的开销。
(4)地址转换性能。地址转换架构的转换性能与应用的访存特征有关,具体可以从L2 TLB失效后的情况中看出,分为2种情况:①如果访问本地内存页表项的请求占比高,就意味着在分布式地址转换架构中,大部分访问GMMU的页表查询请求会命中,因此会大幅减少远程访问IOMMU请求的数量,在这种情况下,分布式地址转换架构会表现出性能优势。②如果访问远程内存页表项的占比高,就意味着在分布式地址转换架构中,大部分访问GMMU的页表查询请求会失效,因此会引入不必要的访问GMMU的开销,在这种情况下,集中式地址转换架构的性能更优。同时,分布式地址转换架构与集中式地址转换架构的性能差异与访存请求的局部性相关,若访存请求的局部性较好,L2 TLB的命中率较高,送往GMMU和IOMMU的请求数量就会很少,则2种架构的地址转换开销差别较小。相反,如果访存请求的局部性较差,L2 TLB失效后的请求数增多,则两者性能差异会增大。
4 实验和分析
本文使用MGPUSim模拟器[17]评估与分析2种地址转换架构的性能。MGPUSim模拟器基于AMD的GCN3架构,支持多GPU系统仿真。
4.1 实验环境
本文使用MGPUSim模拟器模拟由4个AMD GPU组成的多GPU系统,具体配置如表1所示。每个GPU包含4个Shader Engines,每个Shader Engines由9个计算单元(CU)组成,因此每个GPU总共包含36个计算单元。每个CU具有一个私有的L1 vector TLB,每个Shader Engines具有一个L1 instruction TLB和L1 scalar TLB,GPU中所有的CU共享一个L2 TLB。系统中的GPU通过PCIe-v3总线连接,每个总线提供16 GB/s的带宽。CPU和GPU之间也通过PCIe-v3连接。IOMMU由8个Page Table Walker组成,这是典型的IOMMU配置。GMMU由64个Page Table Walker组成,可以满足GPU高频率的地址转换请求。本文将数据页大小设置为4 KB。
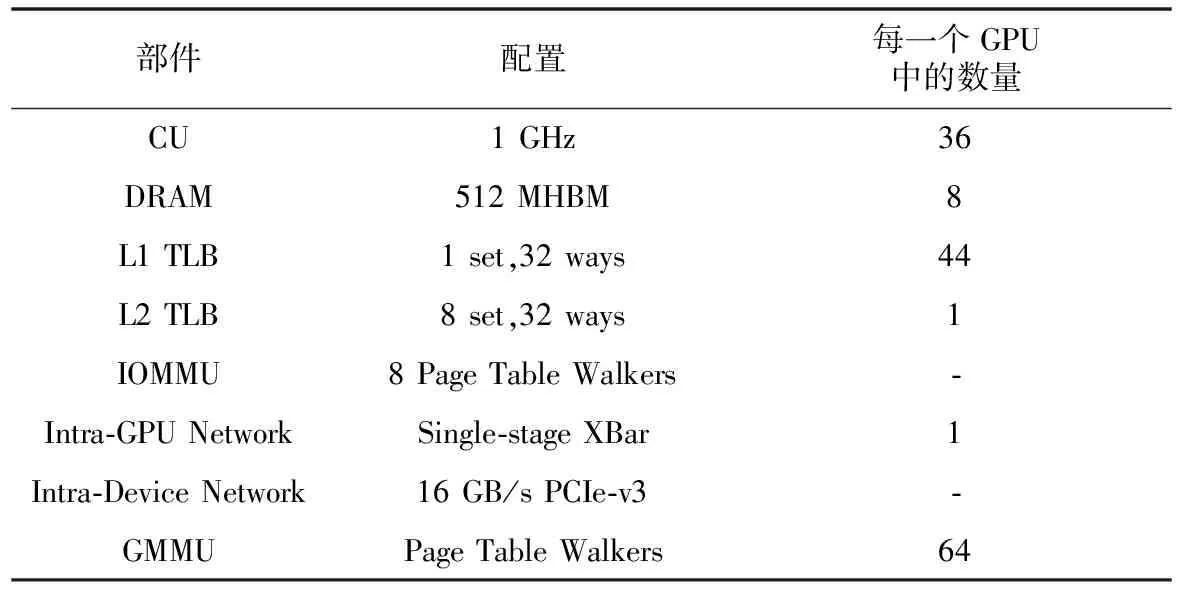
Table 1 Configuration of multi-GPU system

Table 2 Workloads used to evaluate two address translation architecture.
本文使用首次访问页迁移策略来分配数据,该方法能有效减少程序员的工作量,是目前常见的数据分配方法。本文从AMDAPPSDK、Hetero-Mark、DNN和SHOC测试集中选择了部分应用来评估2种地址转换架构的性能,部分程序由于不能在多GPU系统中运行而被省略。选择的应用数据集的平均大小为64 MB,过长的仿真时间使得模拟器无法使用更大的数据量进行评估,具体的应用信息如表2所示。
4.2 结果和分析
图4显示了各应用在2种地址转换架构下的性能。从图4中可以看出,对于RL、FIR和MP,集中式地址转换架构的性能比分布式地址转换架构的性能好,平均有8%的性能差异。部分应用程序分布式地址转换架构的性能优于集中式地址转换架构,例如PR、MT、KM、FFT、ST,特别是KM与ST,最大的加速比分别为4.81和5.18。平均而言,分布式地址转换架构的性能好于集中式地址转换架构的,取得了2.0的加速比。
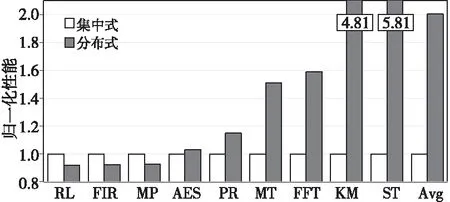
Figure 4 Performance of each applications in two address translation architectures
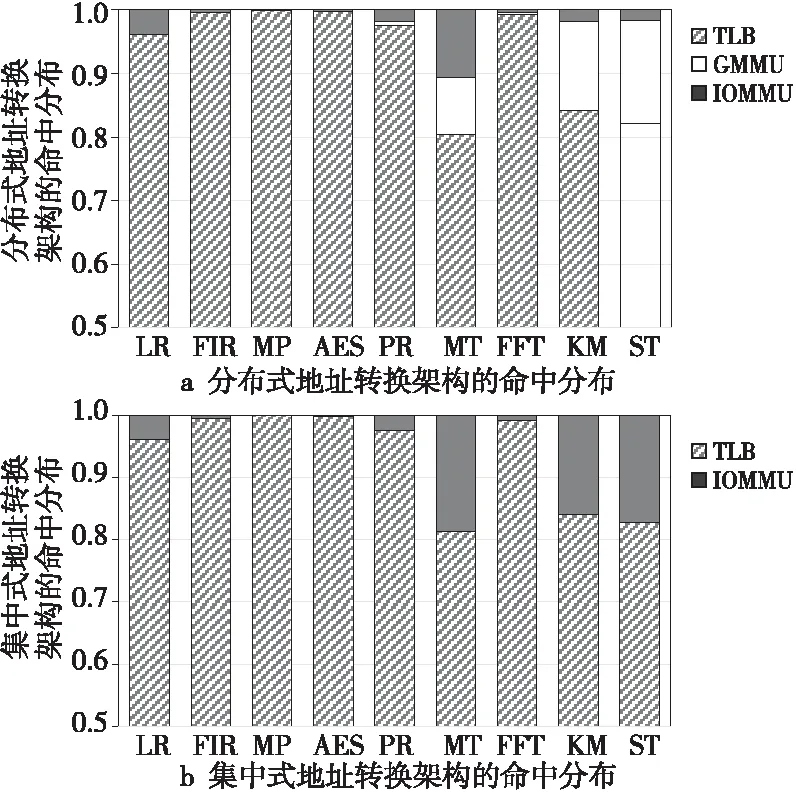
Figure 5 Hit distribution of address translation requests in 2 address translation architectures
图5显示了地址转换请求在2种地址转换架构中的命中分布;由于请求在TLB中命中对于整体性能影响较小,故而将2级TLB命中合并为TLB命中。从图5中可以看出,2种地址转换架构对TLB的影响很小,两者的TLB命中情况基本一致;且地址转换请求大多在TLB命中,这充分体现了数据访问的时间局部性和空间局部性。而部分应用程序在TLB命中的地址转换请求在整体地址转换请求中占比极高,例如FIR、MP、AES和FFT,这说明该类应用程序的数据访问具有较高的时间局部性特征。
图6展示了L2 TLB的失效请求中在GMMU命中和在IOMMU命中的比例。从图6可以看出,分布式地址转换架构与集中式地址转换架构相比,应用程序MT、KM、FFT和ST访问IOMMU的次数明显减少,平均降低了68.3%;对于ST,在分布式地址转换架构中访问IOMMU的次数与在集中式地址转换架中相比构减少了90%。这说明分布式地址转换架构能够有效降低远程数据访问开销,也意味着这些应用访问本地内存页的比例较大。RL、FIR和MP绝大部分地址转换请求都在IOMMU中命中,意味着这些应用在L2 TLB失效后访问远程页表项的比例较大,即这些应用主要访问远程内存页。
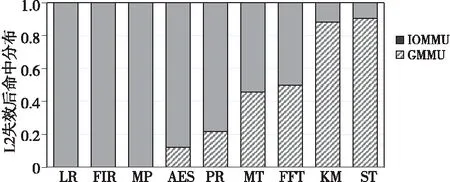
Figure 6 Hit distribution of each component in 2 address translation architectures
图7对比了2种架构进行的页表查询总数。从图7中可以看出,对于RL、FIR和MP,分布式地址转换架构的页表查询总数为集中式地址转换架构的2倍,这是由于这些应用的地址转换请求在TLB失效后都访问远程页表项,分布式地址转换架构中GMMU进行页表查询无法返回请求所需的页表项,请求将发送到IOMMU进行页表查询,故而整体页表查询数增加。平均而言,与集中式地址转换架构相比,分布式地址转换架构的页表查询总数增加了67%,增加了硬件开销。

Figure 7 Number of page table walks in MMUs
上述结果中可以得知,分布式地址转换架构与集中式地址转换架构各有其优势,可以得出以下2点观察结果:
(1)当L2 TLB失效后,访问本地GPU页表项的次数占整体地址请求次数比例较小时,分布式地址转换架构在进行本地GMMU的页表查询时失效的可能性越大,这相比于集中式地址转换架构会带来更大的性能开销;若访问本地GPU页表项的次数占比较大,分布式地址转换架构在GMMU命中的可能性大大增加,避免了将请求发送给IOMMU,可大大减小地址转换延迟,故而性能会优于集中式地址转换架构的。
(2)访问远程内存页表项时,分布式地址转换架构在GMMU进行页表查询会失效,造成额外的本地页表查询开销,这不仅会造成地址转换架构性能的降低,也会产生相应的页表查询开销。
上面2点观察结果也给未来的工作指明了方向:(1)可以通过线程块调度或内存分配等方式有效提升L2 TLB失效后访问本地内存页的比例,这样能提升应用程序在分布式地址转换架构中的运行效率。(2)由于复杂应用程序往往在程序执行的不同阶段表现出不同的访存特征,通过旁路地址转换的方式将分布式地址转换架构与集中式地址转换架构结合起来,在应用程序执行过程中进行动态选择,实现更高的地址转换效率,也能有效减少页表查询总数,降低硬件开销。
5 结束语
本文对2种虚实地址转换架构进行了深入比较,通过对应用程序在各个地址架构中的命中分布、访问数据的来源和TLB失效情况进行分析,得到以下结论:(1)分布式地址转换架构的性能普遍高于集中式地址转换架构的,集中式地址转换架构有着更低的硬件开销。(2)集中式地址转换架构适用于L2 TLB失效后主要访问远程页表项的应用程序,即数据集中访问共享数据较多的应用程序;分布式地址转换架构适用于L2 TLB失效后主要访问本地页表项的应用程序,即数据集中访问共享数据较少的应用程序。本文的研究成果也给未来的工作指明了方向:通过提升L2 TLB失效后访问本地数据的比例来提升应用程序在分布式地址转换架构的性能;通过旁路地址转换的方式将分布式与集中式地址转换架构的优势结合起来,实现更高的地址转换效率和更低的页表查询开销。
