多源数据融合视角下的阅读推广用户画像构建研究
2021-02-24朱东妹安徽师范大学图书馆
朱东妹(安徽师范大学图书馆)
随着云计算、大数据及移动互联网等技术在图书馆的应用,图书馆能够捕捉读者全过程、全范围的阅读行为数据。但是多年来分散引进或开发的图书馆各应用系统,由于没有统一的数据接口、标准和规范,导致原始数据是异构的、复杂的、不完善的。多源数据融合方法为解决新时代图书馆大数据的集成共享提供了一种新的解决思路,并为在此基础上构建阅读推广用户画像模型提供了可行的实践视角。用户画像作为大数据环境下的用户描述工具,在用户描述与建模上具有优势,在此基础上构建针对读者个人、读者群体的阅读行为及需求偏好的读者画像及图书馆所提供资源的资源画像,从而实现精准阅读推广的目的。
1 相关研究
1.1 数据融合
数据融合是处理异构的、复杂的及不完善的原始数据以获取可靠、有价值和准确信息的一种广泛应用的方法[1]。国内外学者在数据融合方面进行了有效的探索,并取得了一定的研究进展。目前各种数据融合方法在不同的领域进行应用,如应用于军事中的目标识别、医疗中的医疗诊断以及工业工程中的复杂机械监控等[2]。数据融合技术方面,常用的有多数据库融合方法、中间件融合方法、基于本体的方法、数据仓库融合方法及基于机器学习的数据融合方法等。
1.2 用户画像
用户画像被定义为一组属性(独立的或不独立的),用来描述一个用户并将其与其他用户区分开来[3]。其研究的数据主要来自网页访问日志、搜索引擎日志、交易记录历史、商业公司日志及用户反馈数据等,在过去十多年间已被深入研究并广泛应用于各个领域。国外学者已涉足用户画像在阅读方面的实践应用研究,其研究方法大体概括为以下三种。①访谈法。Mohammad KAl等对26位人文学者进行访谈研究,构建出人文学者的网络信息搜寻行为模式用户画像[4]。②实验测试法。如,Josefine K等对9—11岁儿童在阅读叙事文和说明文两种不同文体时的阅读行为特征进行研究,总结得出字面读者、复述读者、阐述读者三类读者特征画像[5]。③问卷调查法。Amelie R等以15岁中学生为研究对象,结合问卷调查的方法,从学生的性别、教育经历、社会经济地位和语言背景等变量研究阅读乐趣度和阅读理解能力之间的特征画像[6]。④基于机器学习算法的画像方法。如,Daniel LD等运用机器学习算法中的层次聚类算法、贝叶斯聚类算法构建三、五年级学生阅读画像,并对两种方法聚类结果进行比较,从而发现读者的阅读表现及读者行为的差异[7]。
国内学者对用户画像在图书馆阅读推广工作方面也进行了研究。如,陈臣等建立了基于小数据的读者阅读画像的个体标签体系,并对读者画像的流程进行了研究[8]。王顺箐对智慧型个性化阅读推荐系统的构建提出以读者需求分析为核心模块,同时在数据采集的基础上构建用户画像[9];何娟利用图书馆读者借阅数据,通过构建读者个人与群体用户画像,实现图书个性化推荐[10];都蓝将用户画像技术应用到高校图书馆年度阅读报告中,便于了解读者阅读倾向,开展精准化阅读推广服务[11]。
综上可知,数据融合技术已在不同领域被广泛研究,而数据融合是构建读者阅读画像的基础,这为图书馆进行读者阅读行为数据集成提供了技术参考。关于用户画像技术在图书馆领域的研究,国外针对不同类别读者阅读行为、搜索行为等方面已有相关研究成果,我国近年来也有一定的理论研究,然而在应用画像技术开展精准的阅读推广工作方面的实证研究还比较缺乏。阅读推广精准化可以有效降低成本,帮助图书馆更好地满足读者个性化需求,赢得更多的读者,提升阅读推广效果。
2 研究设计
2.1 总体框架
文章从读者和资源两个维度构建画像模型。读者维度包括读者的人口属性、行为属性及习惯偏好等;资源维度包括图书和文章的关键词、主题词,以及资源被利用情况。基于关系型数据库和大数据分析平台,构建的图书馆读者精准阅读画像系统总体框架包括底层数据源集成融合、画像标签建设、画像模型构建及画像模型应用四个层级。
2.2 异构数据源
图书馆读者阅读行为数据主要来源于两方面:各业务系统结构化数据和Web端的非结构化数据。各业务系统主要包括图书管理系统、门禁系统、座位管理系统及电子阅览室管理系统等业务系统,其数据一般存于关系数据库中。这些系统由于是不同企业开发,数据保存在Oracle、SQL Server及MySQL等不同的关系型数据库中。
Web端的非结构化数据主要包括图书馆门户网站、数字资源网站以及图书馆各应用App数据等,这些线上平台有读者的搜索、浏览及下载等行为信息,还有读者的终端机型、操作系统、网络类型及IP地址等基本信息,由系统前台获取发送给后台Web服务器记录下来。由于Web应用由不同企业及数据商提供,日志产生的来源较分散,存储的目的地也很不一致,有文件、文件夹及Socket数据包等各种形式源数据。
2.3 多源异构数据集成
由于业务系统数据和Web端数据,在数据类型、数据存储格式及数据获取方法方面存在较大差异,因此需要对多源异构数据进行集成。其中Web端日志生成阶段需要根据用户画像主题事先设计埋点参数,统计用户的关键行为。数据埋点方式有自己搭建相应数据体系或集成第三方SDK等,埋点数据是构建读者画像的基础,数据统计和模型训练都基于埋点数据,需保证埋点数据的正确无误。同时为了分布式处理、避免直接连接操作业务数据,需要将各终端的数据同步到统一数据分析平台。结合本研究实际分布式统一数据平台采用Hadoop[12]的MapReduce架构,分别利用其架构上的Hive分布式数据仓库进行离线画像的数据处理与分析,Hbase分布式数据库进行实时画像的分析与查询[13]。
针对不同结构的数据,采用不同的工具进行数据集成。在对结构化的数据集成中采用开源工具Sqoop[14]进行数据抽取、清洗及数据同步,在非结构化的数据集成中采用Flume[15]将业务数据服务器中埋点日志收集到统一分析平台中。
2.4 标签体系构建
画像的标签能够将人或物进行全方位“数据化”描述,从而使每个人或物变得更加立体且独一无二。
2.4.1 读者画像标签体系
(1)相关理论。①RFM理论。RFM理论起初主要用于直效营销(Direct Marketing)领域,是衡量客户价值和客户创利能力的重要工具和手段[16],其包含三个指标:最近一次消费(Recency),消费频率(Frequency)及消费金额(Monetary)。②MECE原则。MECE(Mutually Exclusive Collectively Exhaustive)原则,其意为相互独立,完全穷尽。拆解分类必须不重复、不遗漏,使用该方法后,各个观点将不会相互重叠、抵触,对问题的检视也不至于有疏漏[17]。
(2)构建标签。从给用户构建标签的方式来看,一般分为四种类型:事实类标签、统计类标签、规则类标签及模型类标签。事实类标签,该类型标签是既定事实,是从原始数据中获知或提取,如读者性别、年龄等;统计类标签,该类型标签需要统计计算(计数、求和等)得到,如基于RFM模型的最近一次借阅图书距离今天天数、最近30天访问图书馆次数以及最近30天搜索(浏览、下载)文章总数等;规则类标签,基于读者行为及确定的规则产生,需要工作人员结合图书馆业务确定高频活跃时间段、高借阅人群、高下载人群、高登录人群、长时间浏览人群及资源最受欢迎等;模型类标签,该类型标签在原始数据中没有,需要建立模型或进行机器学习并结合业务类型计算读者相应属性匹配度,对读者的行为及需求进行预测,如预测读者阅读内容主题词、阅读习惯偏好及潜在需求等。梳理标签分类时,尽可能相互独立且完全穷尽,每一层下级标签的组合都能覆盖到上一层级标签的所有数据。
2.4.2 资源画像标签体系
图书、文章是阅读推广的基础资源,读者对图书的借阅,对文章的搜索、浏览及下载均代表了读者对这本图书或这篇文章内容的喜好程度。因此根据图书、文章的自身属性及读者相对图书、文章的行为制定一系列标签,包括:基于图书及文章自身属性的资源类型、分类、题名、摘要/内容及入档日期等事实类标签;有基于读者行为的图书借阅、文章搜索、浏览及下载等行为事实类标签;以及基于模型计算提取的图书与文章关键词、主题词等模型类标签。
2.5 画像计算
设计好标签体系后,进入标签开发环节,即进行画像计算。具体步骤是首先要在存放标签的存储库中建立存放标签的宽表,建立表的过程中,可以多建立几个预留字段用于存放中间计算结果,其次就是存储各类经过计算的标签值。
2.5.1 资源画像主题词标签计算
(1)相关理论。Jieba中文分词。Jieba中文分词是目前主流的中文分词工具,该分词词库提供了常用词组以及词组出现的频率和词性。词库支持四种分词模式:精确模式、全模式、搜索引擎模式以及Paddle模式。Jieba中文分词提供TF-IDF、TextRank两种算法从文本中提取关键词[18]。①TF-IDF算法。TF-IDF(Term Frequency-Inverse Document Frequency)是由Salton在1988年提出的,主要是指一个词语在一篇文章中出现次数越多,即TF(词频)高,同时在所有文档中出现次数越少,即IDF(逆文本频度)越大,越能够代表该文章[19]。TF-IDF算法是以TF和IDF的乘积作为取值测度,TF-IDF值越大,则这个词成为一个关键词的概率就越大。②TextRank算法。TextRank算法其基本思想来源于谷歌的PageRank算法,是一种用于文本的基于图的排序算法。通过把文本分割成若干组单词或句子并建立加权文本图模型[20],利用局部词汇之间关系(共现窗口,默认为5)对后续关键词进行排序后直接从文本抽取。
(2)主题词标签计算。由于相同题名的书或者相同题名的文章并非只代表是同一本书或同一篇文章,因此图书、文章分别结合图书的摘要、文章的内容,将每种图书以“题名+摘要+分类名称”三列合并一列、每篇文章以“题名+文章内容+分类名称”三列合并一列,构建新字段内容,用于计算图书与文章的主题词标签。该类型标签计算分两步进行。①分词处理。分词就是将文本中每个连续的字序列按照一定的规范重新组合成词序列的过程。通过分词我们可以得到读者利用过的图书和文章的庞大词库。如对题名为“中国绘画美学史”图书,进行“题名+摘要+分类名称”三列合并后,用Jieba中文分词中全模式进行分词(见表1)。分词处理时句子中出现的词语都会被切分,而有些副词、连词、介词、数字及标点符号等,是没有实际意思的,如结果中的“/的/,/对/,/等/,/与/,/和/”等但由于对后续的关键词提取且可能提取的关键词是无效的,所以在分词处理以后,需用停用词文本库对分词后的词语进行过滤,去掉停用词,才能使后面取得的关键词更加具有意义。②主题词计算。停用词过滤后,对分词结果进一步基于语料库分别进行TF-IDF、TextRank权重计算,筛选出权重最高的20个词作为关键词,将TF-IDF与TextRank进行乘积运算,最后对权重值排序,将共现的词作为主题词。计算结果见图1。
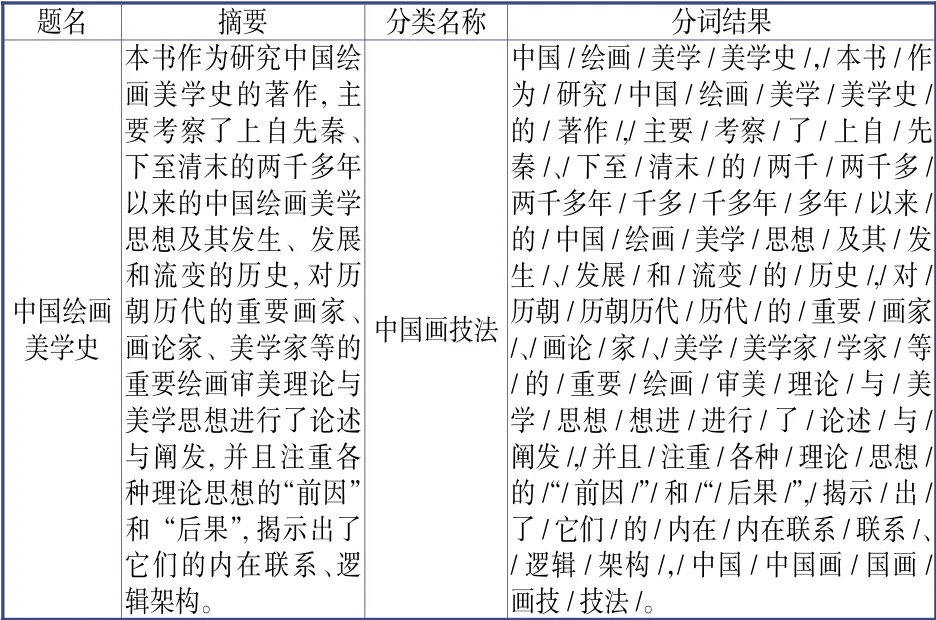
表1 Jieba中文分词全模式分词结果
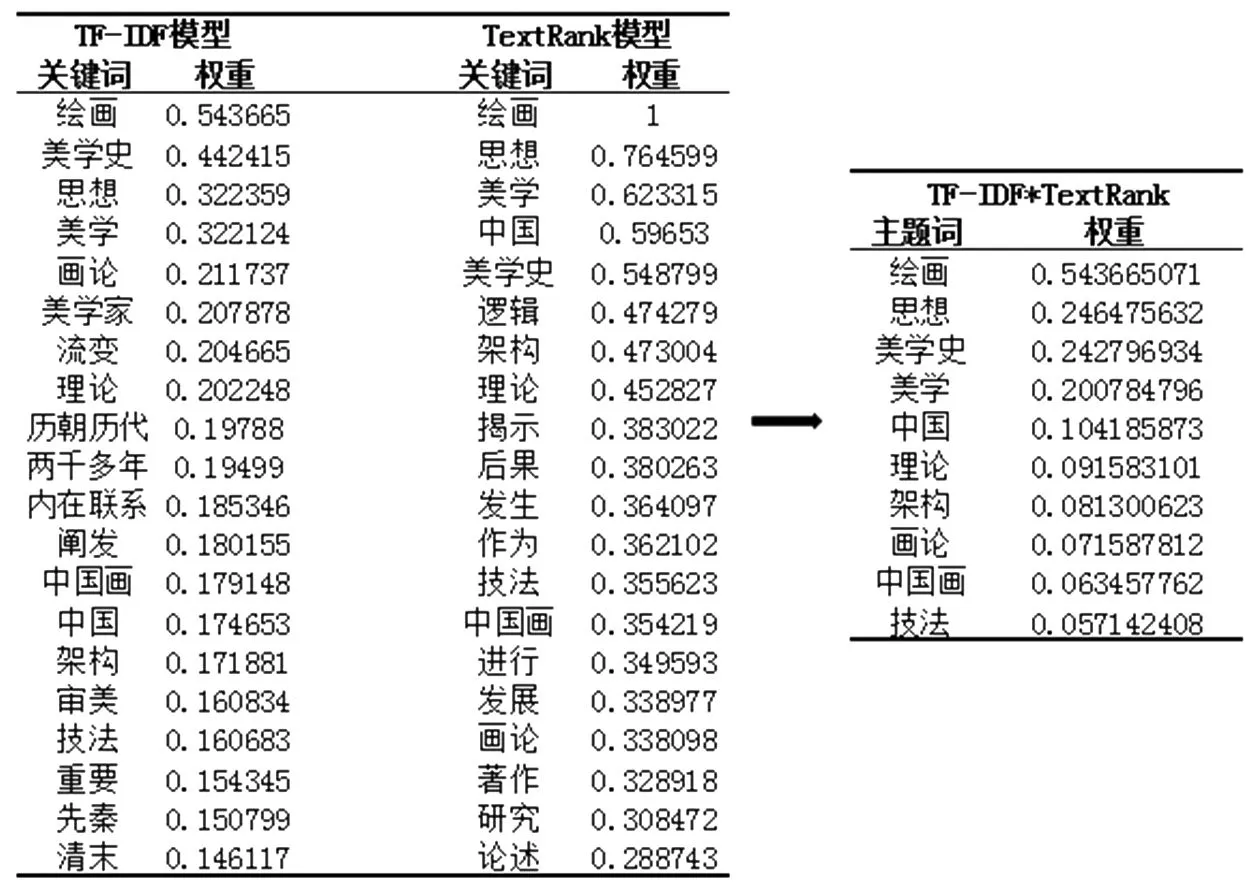
图1 主题词计算结果
2.5.2 读者画像标签计算
读者画像标签内容比较丰富,下面分别以统计类标签中基于RFM模型构建的标签、模型类标签中读者利用资源的内容标签为例进行计算。
(1)统计类标签,基于RFM模型构建的标签。该类型标签值需要进行多表关联聚合运算,其中日期参数是关键,日期参数便于回溯历史数据,贯穿标签计算始终。如30天累计进入图书馆次数、累计借阅册数、累计下载文章数标签,以读者的ID字段为单位对历史记录分组做求和运算;30天累计借阅次数、累计下载文章次数标签,以读者ID字段为单位对历史记录去重做计数运算;最近一次访问图书馆、借阅图书、下载文章距离今天天数,以读者ID字段为单位按时间排序,选取最近借阅日期与当前系统时间做减法运算。
(2)读者利用资源的内容标签。该类型标签计算分两步进行。一是主题词拆分。文章根据读者对哪些图书和文章发生了借阅、搜索、浏览及下载行为以及与之对应的图书和文章主题词表,将每本图书或每篇文章的主题词表按词拆分对应到读者作为一条记录。以前面资源画像中计算好的主题词为例,进行主题词拆分(见图2)。
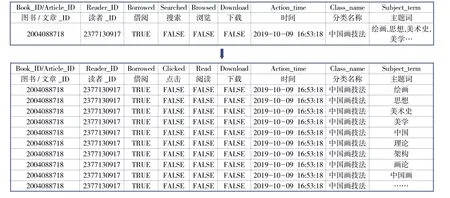
图2 主题词拆分
二是标签权重计算。主题词经过拆分处理后就可以根据读者对主题词的行为来计算主题词对读者的权重,并且将这些主题词作为读者的标签。由于读者历史行为所蕴含的作用总是随着时间的推移而不断变化,近期的行为所蕴含的作用一般要比历史行为的作用有价值得多。如某位学生在大学一年级阅读内容与他(她)在大学四年级阅读内容涉及的主题内容有差异,因此这里我们结合时间衰减模型TDM(Time Decay Model)计算主题词标签权重,时间衰减系数=1/(log(t)+1),公式中t为发生行为的时间距离当前时间的大小。标签权重=(读者行为分值之和)×时间衰减系数,公式中的每种行为对应分值可以根据阅读推广工作实践由专业人员确定。如图2中:读者_ID号为“2377130917”的读者在“2019—10—09”当天“绘画”主题词对该读者的权重为3,而100天后该主题词对该读者的权重为1。根据主题词权重值排序作为用户标签,随着时间的推移用户标签是动态变化的。
3 画像用于阅读推广场景
3.1 读者个人画像
个人画像查询是千人千面信息的一种表现形式。前台通过代码实现SQL聚合函数以及多表关联Join进行读者数目的计算,后台通过JDBC的方式连接Spark集群进行HDFS上的标签宽表的运算。工作人员输入读者ID后,查看并了解每一位读者的画像,如查看某位读者的属性信息、行为信息及文章内容偏好信息等,如图3所示,读者专业:生物科学,年龄:24,性别:男,学历:研究生;近30天的借阅图书、检索文章、浏览文章及下载文章等情况;主题词颜色由红色渐变为橙色、形状由大变小表示主题词重要程度及频率的变化;星期与时间点气泡颜色由红渐变为绿色、形状由大变小表示读者访问时间的变化规律;中图法类别表示读者检索、浏览及下载的文章类别。
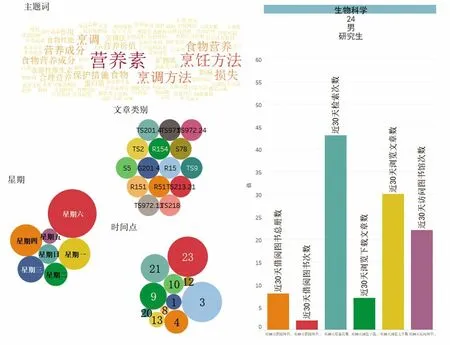
图3 读者个人画像
3.2 读者群画像
前面个人画像查询是单独查看读者个人的相关特征。图书馆读者群体来自不同身份、专业及学历层次,对信息服务的需求也是多样化的。要想满足不同类型读者的需求,就需要基于画像标签做好读者分组分类工作,发现不同类型读者的潜在需求。读者群画像中主要通过多个维度透视分析实现根据现有用户标签圈定用户群的功能。如工作人员根据业务逻辑筛选进行相应的读者定位,从而实现不同类别读者群特征的探索。如图4所示,可以根据年份、读者下载文章数量、访问频次及最近下载文章距离天数等标签维度筛选特定人群;也可以通过对多个维度标签组合,筛选人群,实现对读者群的动态分析。对于阅读推广工作及回访等行为中,为了实行不同的阅读推荐策略并且避免重复打扰读者,可以将每阶段待推广的读者群减去近期已经推广过的读者群,从而为精准化阅读推广工作提供支持。
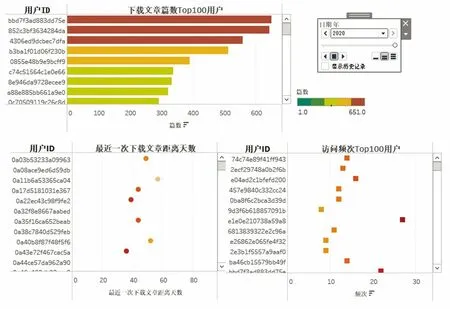
图4 读者群动态画像
3.3 个人阅读主题推荐画像
(1)个性化资源推荐。个性化资源推荐解决从海量(万、百万)的文献资源中,挑选出读者感兴趣的内容,推荐给读者(百、十的输出)。文章通过在前面读者及资源画像的基础上构建主题词共现矩阵,计算资源之间的相似性,进行阅读推荐。以图3中的读者为例,构建“营养素”主题词共现矩阵,利用度中心度、接近中心度、中介中心度及PageRank等算法对主题词排序与聚类,构建个人阅读主题画像,如图5所示,图中节点不同颜色表示不同的类,各类之间泾渭分明;节点的大小越大,表明主题词词频越高;连线表明主题词之间有共现关系,连线粗细表明主题词之间共现的程度;将每类中具有最高中心度的主题词标签作为推荐结果。
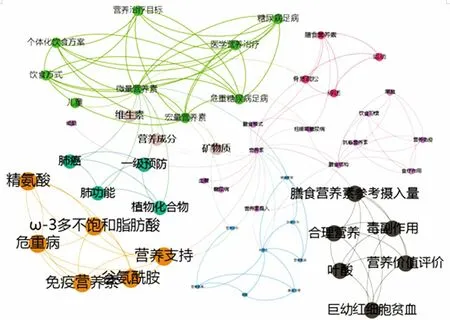
图5 读者个人阅读主题推荐画像
(2)非个性化推荐。为解决新读者、新文章一开始没有太多数据和特征来训练模型的问题,即如何给新读者做个性化推荐阅读,如何将新的资源推荐给可能对它感兴趣的读者,我们可以采用非个性化推荐策略。策略一是热门召回。自定义热门规则,根据当前时间段热点定期更新维护资源库。策略二是新资源召回。为了提高新资源的利用率,建立新资源库,进行推荐。这里非个性化推荐是对前期个性化推荐的补充。
4 结语
文章从高校图书馆读者基本属性特征、阅读资源特征及读者阅读行为特征数据出发,研究构建阅读推广用户画像的技术与方法。运用Sqoop迁移业务系统数据库,Flume采集Web应用日志数据,进行各类异构数据融合构建数据仓库。分别从读者和资源两个维度进行阅读推广用户画像标签体系设计,并对画像计算以及画像在阅读推广工作中的应用场景进行了研究。在倡导以用户需求为中心的时代背景下,图书馆作为信息服务机构,充分借助用户画像发掘潜在需求,提高了信息推送的精准度。下一步在资源画像设计中,将加入全文内容进行分词处理,计算资源之间的相似性,构建更精准的画像。
