基于机器学习的网络支付欺诈交易动态识别模型的构建
2021-02-10熊传文
熊传文
(厦门工学院 计算机科学与信息工程学院,福建 厦门 361021)
随着互联网的兴起和网络社交平台的不断发展,网络支付安全问题日益突显.机器学习技术有利于保障网络支付环境安全,能有效识别出网络支付欺诈交易.通过计算机技术模拟人类学习,并在此基础上不断获取新的技能和知识.把机器学习应用到互联网DDoS发攻击检测中,可以精准地完成攻击检测[1].网络支付交易属于互联网安全范畴之内,在日常网络支付交易中,由于网络信息不对称,网络支付存在很大的安全隐患,容易发生网络支付欺诈交易行为[2].网络支付欺诈行为具有多样性的特点,网络经营者采取不正当的手段欺骗和误导消费者就是其中一种网络欺诈行为.
在相关研究中,樊春美等[3]提出了一种基于电商平台的恶意支付账户识别算法,通过关联分析和特征的重要性筛选交易数据.利用随机森林算法分析电商平台的真实交易数据,使用k-means进行恶意支付账户聚类,区分恶意支付账户和正常支付账户.赵朋亚等[4]提出了一种基于标签传播的协同分类欺诈检测方法,考虑了欺诈节点间关联紧密的现象,利用标签传播算法扩散欺诈节点的标签信息,确定未知标签节点是否为欺诈用户.
由于传统的欺诈交易识别模型分类器效果不佳,导致所需网络支付欺诈交易行为识别时间较长,容易发生网络安全问题.因此,本文提出了基于机器学习的网络支付欺诈交易动态识别模型,以机器学习技术为主,对动态识别模型展开研究,抓取网络支付数据包并提取网络交易信息链特征,采用迭代算法搭建网络支付交易多分类器,实现数据分类,以期提供一个安全的网络支付环境,减少网络支付欺诈交易行为.
1 基于机器学习的网络支付欺诈交易动态识别模型
1.1 抓取网络支付数据包
进行网络支付诈骗交易动态识别之前,需要抓取网络支付数据包,由于每天网络的支付数据信息较多,需要设置一个提取数据程序,收集和整理每天产生的网络支付数据,提取每一项网络支付数据的特点[5].网络支付数据包的实时抓取是通过用户网关实现的,将用户网关收集到的数据包传输到整个网关系统中,路由器是抓取数据包的重要组成部件,网关能够通过路由器传输数据进行数据识别.网关识别程序可以从路由器中抓取数据包.网络支付数据包括2种支付数据,分别是用户数据和业务数据.用户数据是指网络支付服务运营者从用户处直接收集的数据,以及在网络支付服务业务开展过程中产生归属于用户的数据[6].业务数据是指在网络支付服务业务开展过程中产生的为保障业务正常运行的数据.网络支付欺诈交易行为存在于用户和业务数据中,当网络支付安全受到威胁后,可以将网络支付数据安全性分成4个等级,安全等级是根据网络支付数据包的安全程度划分的.
网络支付欺诈交易包括金钱损失、用户信息泄露等,通过网关抓取数据包,将抓取的数据包进行特征分析,提取网络支付数据包特征,划分安全等级,筛选出安全等级较低的数据包,进行重新计算分析,识别出安全等级低的数据包是否存在网络支付欺诈交易行为[7].整个网络支付动态识别系统设置有网络传输层、分类识别传输层的数据包,但不对数据包进行深度识别.抓取数据包的网关不需要详细分析数据包内容,只需要掌握整个数据包结构,对数据包的安全层次进行相同安全等级划分.由于网络支付数据较多,通过网关进行简单的数据包分析和传输,有利于提高数据包抓取速度,数据包信息抓取过程相对简单,网络支付数据包抓取过程,如图1所示.

图1 网络支付数据包抓取过程图
根据图1可知,利用网关抓取网络支付数据包,网关可以分析数据包的数据层次和数据包大小,生成网络支付数据特征.网关获取数据包大小可以通过计算数据包的时间跨度来确定,时间跨度越小说明网络支付数据包里面的内容信息较少,时间跨度越大说明网络支付数据包里面的内容信息较多,时间跨度与网络支付数据包呈正相关[8].抓取网络支付数据包,是实现欺诈交易动态识别的前提条件,是进行动态识别的数据来源,将抓取出安全等级较低的数据包进行重新排列组合,着重识别安全等级较低的数据包,后期构建的动态识别模型,主要对筛选出来的网络支付数据包进行识别,能够有效节省识别时间.
1.2 提取网络交易信息链特征
通过筛选出来的数据包,进一步提取数据包内网络交易信息,分析网络交易信息链特征,运用类型学原理对信息链进行分类.整合以往的网络支付欺诈交易数据包信息内容,利用网络信息共享系统,将筛选出来的数据包信息与以往欺诈交易数据包进行对比,分析出数据包存在的交易欺诈程度[9].将提取的网络交易数据信息内容存储在网络安全数据库中,分类编码网络交易数据信息,通过信息分类编码框架整合成一条网络支付数据信息链.由于信息链是由数据包信息内容构建而成的,数据包信息内容安全等级一共划分了4个等级,所以信息链根据数据包安全等级进行编码.由于每天网络支付交易数据较多,构成的数据信息链可以有效节省网络数据库空间,编码后的信息链更有利于动态识别模型运行,不需要动态识别模型在海量数据信息中分析,信息链能够有效提高动态识别效率.网络支付交易信息链编码模型如图2所示.

图2 网络支付交易信息链编码模型
网络支付交易信息链是由信息编码模型实现的,按照等级有序排列信息链,是实现信息链有效管理的基础.网络支付信息链资源的开发利用,能够有效节省网络支付欺诈交易的动态识别成本,网络支付交易生成的信息链是将网络支付资源数据进行整合[10].网络支付交易是建立在信息网络的一项经济活动,信息链里面有资金交易情况,根据提取信息链中的资金交易特征,分析交易双方价值平等度是否一致,如果出现不一致的情况,说明这一次的网络支付交易存在欺诈行为[11].根据信息系统构建的信息链模型,对网络支付数据包进行深度检测,将数据包中的数据进行重新排列组合,利用数据构成一条信息链.在进行网络支付欺诈交易动态识别之前,要对网络支付信息链进行分析,提取信息系统中的信息链特征,信息链包含了整个交易信息内容,包括交易物品、交易资金、交易地点等信息,能够有效分析网络支付交易情况.网络支付交易信息链是进行动态识别的重要环节,一旦信息链遭到破坏,信息链里的信息将会遗失,导致信息链不完整,网络支付交易特征不清晰,严重影响到网络支付欺诈交易模型的稳定性[12].在进行动态识别时,一定要保证信息链的完整性,构建一个安全稳定的信息链存储系统.
1.3 迭代算法搭建网络支付交易多分类器
利用迭代算法搭建一个网络支付交易多分类器,由于网络支付交易信息呈现多样化特点,搭建网络支付交易多分类器是非常有必要的.将网络支付交易产生的数据通过不同的分类划分,数据包的数据信息存储在分类器中,将分类器分为强分类器和弱分类器,不同类型里面数据大小和数据安全性都不一样[13].分类器将根据每一次抓取的网络支付信息数据包得到一个数据集合,将数据集合进行分类从而确定每一个数据样本的权值,通过多分类器对数据集合进行分析,将数据样本的权值进行重新修改,最终满足弱分类器的参数值[14].随着网络支付数据样本的不断增加,动态识别难度也会随之加大,采用迭代算法可以排除安全性较高的网络支付交易数据特征,可以有效提高动态识别的准确性,降低错误率.根据多分类器的数据样本利用迭代计算方法,得到弱分类器的数据之间的分类误差值,计算公式如下:

其中,Q表示分类器之间的误差值,E代表网络支付数据样本r的权重值,()T r表示分类器对样本的结果值,Uk表示样本标签.
多分类器之间的误差值,就可以表明网络支付数据中存在的关系,如果安全系数不高的数据包与以其他弱分类器之间的误差值较小,说明这一类的弱分类器里面的网络支付数据信息可能会存在欺诈行为.利用的迭代算法可以分为2个运算阶段:第1个阶段就是样本集合阶段,将网络支付产生的数据进行整合,形成一个数据集,数据集也是由迭代算法实现而来的;第2个阶段就是样本分类阶段,由于网络支付数据特征不一样,需要对不同特征的数据进行分类,这也是建立多分类器的重要阶段,迭代算法将每一个分类器进行加权平均计算,对数据进行最终结果分类.迭代算法进行权值计算,构建分类器的过程相对比较复杂,需要对数据集合进行反复计算,即使根据上述设置的信息链,数据信息链也是相当庞大.在搭建多分类器时,需要严格控制好迭代的次数,让迭代值符合测试范围.
1.4 基于机器学习构建网络支付欺诈交易动态识别模型
基于机器学习构建网络支付欺诈交易动态识别模型,能够有效节省识别时间,通过人工智能化技术实现实时动态识别.首先需要对网络支付数据样本的亲和度进行计算,通过二进制位串来表示数据长度,由于网络支付信息一般通过数据传递,数据包在进行传递时,只能靠数据长度进行初步分析,通过数据之间的距离和长度来计算数据样本的亲和度,计算公式如下:

其中,I表示网络支付数据样本的亲和度,o表示网络支付数据长度,iθ表示第i个数据样本的相似度.
根据网络支付数据样本的亲和度,可以有效分析出数据样本之间的相关性,安全等级较高的数据样本与其他数据样本的亲和度高,说明其他网络支付数据样本安全性能也相对较高,动态识别模型在识别的时候,识别程序相对较简单[15].动态识别模型首先需要识别出存在网络支付欺诈交易行为的数据数量,这是动态识别的基础.欺诈识别数量公式如下:

其中,A表示样本欺诈交易数据数量,S表示整个数据包数据量,D表示与原数据集合的亲和度不高的数据数量,F表示网络支付实时产生的新网络支付数据数量.
2 实验与分析
2.1 实验准备
选择不同类型、不同特点、不同长度的网络支付交易数据包作为研究对象,选择性能较好地计算机、监控设备等硬件设备,为实验搭建一个安全稳定的测试环境.为了获得更加真实有效的实验测试结果,需要多次提取网络支付数据包数据以及信息链的特征.此次实验选用8种类型的数据包,数据包特征如表1所示.
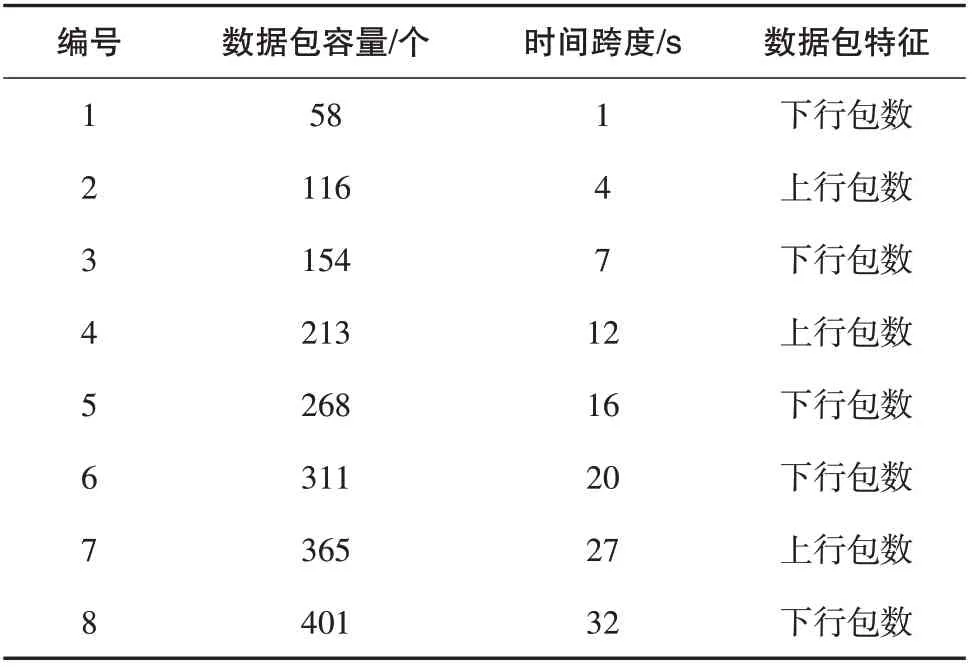
表1 网络支付数据包特征
本实验选用上述8类数据包(表1)里面的数据进行测试,8类数据包中的数量都不一样,且通过网关的时间跨度也不同.
2.2 实验结果
采用基于机器学习的动态识别方法和传统识别技术进行实验测试.测试这2种网络支付欺诈交易动态识别模型所需的识别时间,测试结果如表2所示.
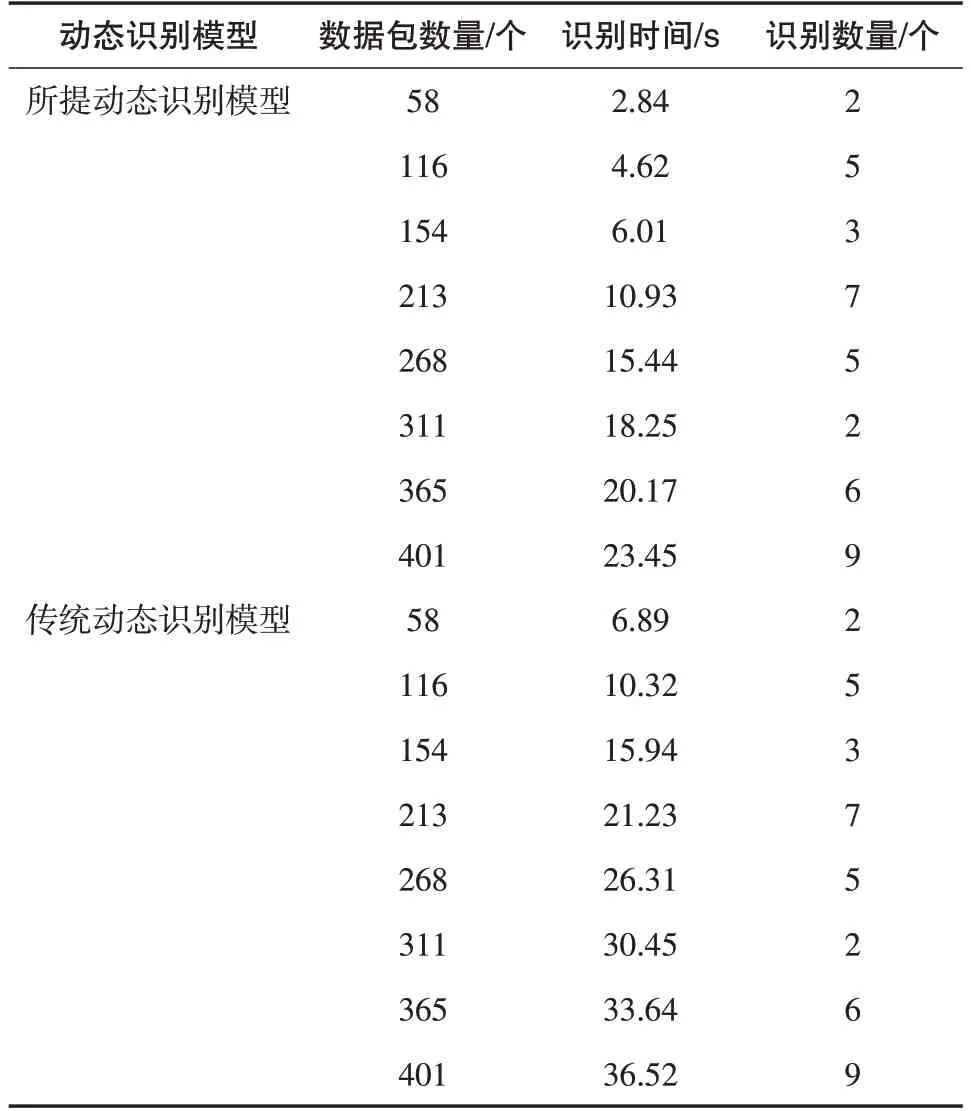
表2 动态识别时间结果
由表2可知,所提动态识别模型识别出的欺诈交易数量与传统动态识别模型识别出的网络支付欺诈交易数量相同,但在数据包容量相同时,所提动态识别模型识别时间都比传统动态识别模型所花费的识别时间短.根据计算得出,在8类数据包中,所提动态识别模型平均识别时间为12.71 s,传统动态识别模型平均识别时间为22.63 s,所提动态识别模型识别时间比传统动态识别模型时间快了9.92 s.因此,基于机器学习的网络支付欺诈交易动态识别模型,能够有效减少识别时间,提高动态识别效率.
3 结论
基于机器学习的网络支付欺诈交易动态识别模型的构建,旨在为网络支付提供一个安全的环境.为了能自动识别出网络交易是否存在欺诈行为,首先在网络上抓取网络支付数据包;然后通过数据包特征提取网络交易信息链,对信息链进行初步分析,利用识别算法完成动态识别;最终通过机器学习技术构建出网络支付欺诈交易动态识别模型.本研究仅在网络支付的层面上进行分析和搭建支付欺诈交易动态识别模型,虽能够有效辨别出网络支付存在的欺诈行为,但没有对网络安全的其他方面进行风险识别,因此,基于科学技术搭建不同类别的识别模型尚需进一步研究.
