基于GPS轨迹数据的旅行者时空行为分析
2021-02-10黄秋华邱弘逸
黄秋华,邱弘逸
(惠州学院 地理与旅游学院,广东 惠州 516007)
随着互联网、手持移动设备、定位、位置服务等技术的出现与高速发展,轨迹数据的获得变得越来越容易.轨迹数据的挖掘分析已经变得不再陌生,通过轨迹数据的挖掘可以得到很多领域人类活动的潜在的规律,用挖掘得到的信息为国家经济建设和社会管理领域等提供辅助决策[1-2].
在信息化的大背景下,各行各业都开启了“互联网+”模式的发展,同理催生了“互联网+旅游业”的出现,进而带来了旅游业的新业态、新发展.旅行者可以借助专业的互联网旅游平台获取信息、与网友互动交流、在论坛上发表观点,使得大量由用户生成的有效旅游信息得以汇集在旅游平台上.
传统的旅行者时空行为分析所需数据通常需要实地调研获取,需要耗费大量人力物力,且以文本为载体的记录形式依赖于数据提供者的个人主观想法,不能保证数据的完整性和准确性.旅游信息分享平台的出现,让旅行者可以使用手机的GPS功能记录完整的路线[3],使用者也可自由地在平台上获取需要的数据,使得信息的收集与获取难度大大降低,可通过爬虫技术批量采集旅游轨迹分享网站上用户自行上传的轨迹数据,使用Python进行数据挖掘提取景区热点区域,借助GIS实现数据的可视化.
1 研究内容与技术路线
1.1 研究内容
从两步路旅游轨迹分享平台上获取旅行者GPS轨迹[4],利用数据挖掘算法提取有效信息,再利用GIS专业软件对提取到的信息做进一步空间分析.
(1)使用两步路平台作为GPS轨迹数据的来源,数据包括用户在当前轨迹点的经纬度、高程、时间、速度信息.
(2)对爬取得到的GPS轨迹数据进行数据清理等预处理操作,将预处理后的轨迹数据进行入库存储和管理,使用轨迹聚类等时空数据挖掘算法[5]对入库后的数据进行挖掘,得到旅行者在时空上的行为特征.
(3)使用ArcGIS的核密度分析,找出旅游景区内的热点区域,并给予景区相关建议.
1.2 技术路线
选取深圳市梧桐山景区作为研究区域,通过旅游轨迹平台数据爬取获得大量旅游者的旅游轨迹数据,对爬取得到的数据进行预处理,对预处理后的数据入库管理.利用数据挖掘算法对轨迹数据进行信息挖掘,利用GIS专业软件对轨迹数据进行核密度分析,最后将结果利用软件可视化显示.具体实施技术路线如图1所示.
2 数据采集与数据预处理
2.1 研究区域
梧桐山,地处广东省深圳市东部,省级风景名胜区,山西麓有仙湖植物园和著名的佛教寺庙建筑群弘法寺.在交通方面梧桐山交通方便,旅游线路成熟,从东南西北四个方向均有已经被开发的线路,不同方向的登顶路线共有19条,比较常见的路线有:梧桐山村—盘山公路—停车场—好汉坡—大梧桐顶,梧桐山村—梧桐山水库—泰山涧—葫芦池—梧桐顶,梧桐山村—梧桐山水库—百年古道—大梧桐顶.
丰富的登顶路线使得旅行者可选择的线路大大增加(图2),但景区日常需投入的人力物力等成本也会大幅增加.该研究以梧桐山为研究案例,基于GPS轨迹数据对旅行者的时空行为进行分析研究,借助轨迹数据挖掘技术,分析旅行者轨迹的相似性,找出景区内的热点区域,让景区管理投入的人力、物力资源得到合理分配.

图2 梧桐山景区导游图与众多登山线路[6]
2.2 数据的采集
两步路平台是一个专业的基于UGC(用户生成内容)模式的GPS轨迹分享平台,用户使用“户外助手”手机APP记录出行轨迹.两步路平台上的GPS轨迹数据主要包括以下信息:轨迹点的经纬度、时间、速度、海拔,以及用户上传的照片、文字等信息.
基于两步路旅行轨迹分享平台上梧桐山旅行者分享的游览轨迹进行收集与整理,使用Python爬取获得旅游者的轨迹数据,对轨迹数据进行一定的预处理操作,处理后的gpx格式轨迹数据利用FME软件进行格式转换,转换成Shapefile格式,最后将其进行入库管理.对入库后的数据提取出轨迹中包含的时间、轨迹长度等信息,接着再使用ArcGIS软件和Excel软件分别从空间和时间上分析旅行者的时空行为特征.
选取旅游平台用户2008-2019年上传的梧桐山景区旅行轨迹和文字标注作为研究数据,使得数据的真实性与完整性有所保障,以此来对梧桐山旅行者的时空分布情况进行长达10年以上的连续性对比分析.通过分析旅行者不同年份间在梧桐山景区的旅行轨迹变化情况来了解旅行者的景观偏好及旅行方式的变化特征.
在两步路平台官网(https://www.2bulu.com)使用“梧桐山”作为关键词,搜索所有步行、长度在0~30 km以内的相关轨迹,使用Python与Scrapy爬虫模块对搜索结果进行爬取,将相同轨迹与和梧桐山没有关系的轨迹去除,最后共得到有效轨迹720条,轨迹空间分布如图3所示.
图3 2008-2019年梧桐山旅行者游览轨迹分布图
2.3 数据的预处理
使用FME2016,从720条轨迹数据中提取出生成轨迹的时间和轨迹长度,去除无时间字段和无轨迹长度的数据共29条,共获得691条真实有效的GPS轨迹数据.
使用Python与Kalman噪音滤波算法[5],对所采集得到的轨迹数据中的噪音点(由于设备异常或进入室内及信号受到干扰而导致的坐标点位与实际点位置不符)进行消除或削弱[2].具体如图4所示.

图4 轨迹数据预处理前后对比图
使用FME2016将图4中经过滤波处理后的轨迹点与轨迹线进行格式转换,将其格式转换为Shapefile,并将拍照点文字标注导出到Excel中.
2.4 停留点的检测
旅行者的GPS轨迹中,停留即旅行者在较长的时间内移动了较短的距离.一般将停留点分为两大类:第一类就是轨迹中的某个点就是一个停留点;第二类是连续的轨迹点所发生的时间长度远远超过正常移动速度时所需要的时间长度,此时认为该部分连续轨迹点发生了停留,即认为其是环绕轨迹停留点.
采用的停留点检测算法(表1)的基本原理是找出个体在某段轨迹内所花费时间超过某个阈值,然后将这一段全部的轨迹点作为一组停留点,计算出这组停留点的停留中心.

表1 停留点检测算法
使用Python与停留点检测算法,计算得到所有轨迹的停留点以及停留中心,将停留中心X、Y坐标输出到Excel表中,然后使用ArcGIS软件将停留点中心坐标进行可视化显示,并将其转换为Shapefile图层,得到结果如图5所示.

图5 2008-2019年梧桐山旅行者停留点分布图
3 旅游者时空行为分析
3.1 旅行者时间分布特征
根据当地气候特点与深圳市气象局数据,深圳市春夏秋冬四个季节分别为2-4月,5-10月,11-12月,1月,四个季节具有不同的持续时间.本文选择采用平均值来表达各季节游客量.将月份按季节归类,利用Excel表格对其进行分类统计,得到结果如图6.从图6中观察得到2008-2019年梧桐山春季月均游客量最多,占比高达34%;其次是秋季和冬季,占比分别为23%和24%,两季的差距并不明显;夏季占比最低,仅为19%;由此可见,春季是梧桐山旅游的旺季,而夏季则是梧桐山旅游的淡季.

图6 梧桐山各季节月均游客量的占比
梧桐山旅行者访问月份分布不均匀,一年内变化出现了2个峰值,是多峰季节型.由图7可以看出:春季3-4月和夏季10月梧桐山的客流量出现了2个高峰值,而春季2月和夏季的5-9月则出现了明显的2个低谷期,秋冬季的11月至1月游客量变化不大.深圳市夏季高温多雨的气候特征使得梧桐山景区夏季的客流量减少,10月出现旅行高峰是受到了“十一”长假和气温略微下降的影响;其余三季气候都较为宜人,因而有着较高的客流量.
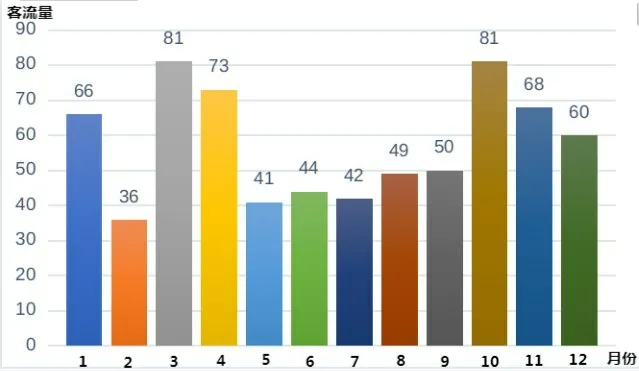
图7 梧桐山各月游客量变化
3.2 旅行者的空间分布特征
旅行者在景区内游览的兴趣点和游览路径偏好对于旅游景区的基础设施规划有着重要的指导意义.本文基于两步路平台上用户分享的轨迹数据,进行整理与预处理后,使用ArcGIS软件对停留点进行空间分析,试图分析梧桐山旅行者的空间分布特征.
3.2.1 采用数据挖掘方法及原理
本研究主要采用了核密度分析和DBSCAN聚类算法.DBSCAN聚类算法的主要的思想是通过假设以任意一个对象p为中心,假设1一个邻域半径r,假设最小对象个数Min为阈值,则在对象p的周围半径r的区域内当对象个数满足大于Min的时候,则生成一个以p为核心的聚类.依此类推直到完成所有对象的聚类,可以认为DBSCAN聚类实际上是靠任意一个对象满足要求的邻域内的对象的个数来衡量的,达到或超过要求就完成聚类.
聚类方法DBSCAN是通过计算一个半径为r的区域内的对象的数量得出聚类结果,这样的密度估计对半径r的大小比较敏感,为了克服这个问题可以使用核密度估计方法.该方法是统计学中的一种非参数的密度估计方法,主要用于计算要素在其周围邻域中的密度的大小.核密度估计方法既可以计算点要素的密度,也可以用来计算线要素的密度.
将观察对象的位置作为一个在其周围区域有较高的概率密度的一个指示点,而其他位置的点的概率密度的大小由该点到观察位置指示点之间的距离决定.通常情况下,x1,x2,...,xn是一个随机变量f中的相互独立的分布样本,这个概率密度函数的核密度近似值可以由下式计算得到[7]:
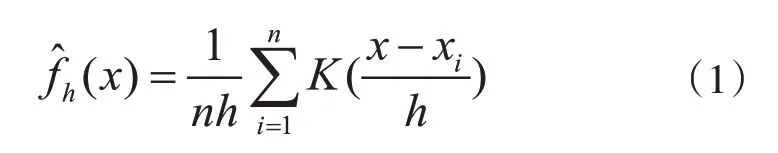
其中,K()是一个核,h是搜寻带宽.一个核K()可以被认为是一个样本点对其邻域所带来的影响值的功能模型.从技术上来说核K()是一个非负的实数值,并且应满足下式的2个条件:

经常使用的核是均值为0、方差为1的标准高斯函数,如下式所示:

3.2.2 兴趣点的空间分布特征
使用Python与停留点检测算法,计算所有轨迹的停留点中心,并输出为gpx,然后使用FME2016将所有停留点中心转换到一个Shapefile里.通过ArcGIS核密度分析功能,得到的核密度结果如图8所示.

图8 聚类代表性轨迹段
通过停留点核密度分析得到梧桐山景区核心节点有2个,分别为大梧桐山顶和小梧桐山顶.另外,有2个亚热点区域在前往大梧桐山顶的路上:一个是好汉坡前的停车场以及休息区,另一个是从盐田沙头角街道出发的“碧桐道”登山路线上.
3.2.3 旅行者的轨迹空间分布特征
从691条旅行者轨迹的分布可以看出,旅行者走过的路线已经遍布梧桐山景区大部分步道,包含了所有的登山线路,而旅行者选择登山线路更倾向于线路成熟、容易行走的路线.
使用FME将所有轨迹融合到一个Shapefile图层内,利用ArcGIS核密度分析功能得到轨迹的核密度分析结果,游览密度最高的路线是“梧桐山村一盘山公路一停车场一好汉坡一大梧桐顶”,也是梧桐山开发最成熟的一条路线.除此以外,不少旅行者还选择了与盘山公路线同起点的百年古道线,以及从莲塘出发到小梧桐再到大梧桐的路线,也都是梧桐山开发得比较完善的线路.
采用轨迹分段、压缩以及轨迹聚类算法(表2),对两步路平台上获取的深圳市梧桐山景区旅行者轨迹进行聚类,找出梧桐山景区的代表性路径.使用Python与DBSCAN聚类算法,将经过Kalman噪声滤波处理的轨迹文件作为聚类输入数据集,经过多次聚类实验确定参数后,将聚类代表性轨迹段导入ArcGIS中进行可视化.DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类.将该聚类得到的结果与核密度分析结果进行对比,发现两者具有很大的相似性,这进一步验证了该研究方法的可靠性.

表2 基于轨迹段的DBSCAN聚类算法

(续表2)
根据DBSCAN聚类提取出的代表性路径,可以看出代表性轨迹段基本位于核密度分析结果密度较高的部分,大部分轨迹段也都处于道路上,但有部分密度较高的区域没有聚类结果,同时也有密度低的区域在聚类中呈现出高密度结果,因此在参数上还需做进一步的调整.
4 结论
使用两步路旅游轨迹分享平台上用户自行上传的GPS旅游轨迹数据,该方法在很大程度上降低了数据获取所需的成本.以此为基础,使用Python对两步路平台的数据进行适当的爬取、整理和预处理,再使用FME软件进行数据格式的转换以及属性字段的提取,结合ArcGIS软件对停留点以及轨迹线进行核密度分析,主要结论如下:
(1)在时间上,梧桐山旅游有明显的淡旺季,但客流量受季节性影响程度较低.梧桐山旅游的高峰期集中在3-4月和10月,深圳市夏季高温多雨气候特征导致梧桐山的客流量受到了一定的负面影响,春节过后的春季气候较为温和,也让很多旅行者选择此时到梧桐山进行游览、踏春.
(2)在空间上,梧桐山的景区热点集中在大梧桐山顶和小梧桐山顶附近,符合现实中登山旅行者的空间行为规律,登顶后的旅行者通常在山顶进行休息.同时大梧桐好汉坡前的停车场作为登顶前唯一的大型休息区域,也成为了一个亚热点区域.
(3)在路线选择上,旅行者更倾向于选择已开发成熟的路线作为登山路线,而未开发成熟的路线则更受到登山爱好者以及本地居民的青睐.
本研究数据来源比较单一,仅使用两步路平台上用户分享的数据,群体覆盖面较小,且仅从GPS轨迹数据上无法准确判断该旅行者的性别、年龄、客源地等个人信息,无法对旅行者进行分类分析.
