毫米波大规模MIMO 系统基于等效信道的全连接混合预编码设计
2021-02-01曹海燕马智尧智应娟刘仁清许方敏方昕
曹海燕,马智尧,智应娟,刘仁清,许方敏,方昕
(杭州电子科技大学,浙江 杭州 310018)
1 引言
毫米波因波长较短使得其在很小的空间内封装大量天线成为可能[1-2]。同时,巨大的天线阵列能够提供显著的波束成形增益,可以有效地补偿毫米波的路径损失[3]。因而毫米波与大规模MIMO(multiple-input multiple-output,多输入多输出)技术相结合是第五代通信系统的关键技术之一。传统的全数字预编码方案需要与天线数量相等的RF(radio frequency,射频)链,直接应用于收发端具有大量天线的大规模MIMO 系统,会使硬件成本与功耗急剧增加[4]。而传统的模拟预编码方案,采用移相器代替RF 链,虽降低了成本,但也导致了系统性能损失过多。因此,一种将RF 链和移相器相结合的数字模拟混合预编码方案被提出,其可以在降低硬件成本的同时保证系统的性能不会损失过多[5-6]。
根据RF 链与天线的连接方式不同,混合预编码方案主要分为全连接、部分连接以及混合连接。部分连接混合预编码中每个RF 链只连接部分天线,每根天线连接一个移相器。参考文献[6]针对部分连接混合预编码提出一种基于 SIC(successive cancellation,连续干扰消除)的混合预编码方案,预先设定数字预编码矩阵为对角阵,进而将总的优化问题分解为一系列天线子阵的子优化问题。但是此算法只适用于数据流与RF 链相等的情况下,适用范围太小。混合连接混合预编码是全连接与部分连接的折中,通过RF 链将天线分为多个子阵,每个子阵采用全连接。参考文献[8]针对混合连接混合预编码提出一种持续干扰消除的混合预编码方案,根据发送数据流与RF 链数量的关系,先将数字预编码矩阵的形式设计出来,进而利用模拟预编码矩阵的块对角特性将其分解为子阵依次设计,最终得到混合预编码矩阵,该方案优于部分连接混合预编码方案。与部分连接与混合连接相比,全连接混合预编码因其所有RF链均连接到发送端每一根天线上,可以为发送信号提供更高的自由度,因而具有更好的性能,更加接近全数字预编码方案。参考文献[9]提出一种OMP(othogonal matching pursuit,正交匹配追踪)算法的混合预编码方案,通过不断地从候选矢量集合中找出与残差矩阵相关性最大的矢量更新模拟预编码矩阵,最后通过最小二乘准则获得数字预编码矩阵,该方案能够接近最优全数字预编码方案,但其复杂度过高。参考文献[10]提出一种交替迭代混合预编码算法,通过依次固定数字和模拟预编码矩阵,交替迭代使其逼近全数字预编码矩阵。但是,每次迭代前都要更新模拟和数字预编码矩阵,导致其复杂度过高。参考文献[11]提出了一种利用毫米波散射体路径增益最大的发送角与离开角设计模拟预编码矩阵,之后构造等效信道矩阵,通过RZF 算法获得数字预编码矩阵,该方案复杂度较低,但其接收端仅考虑纯模拟合并器导致性能较差。参考文献[12]提出了一种基于信道SVD 的混合预编码方案,模拟部分取信道矩阵右酉阵的相位,数字部分通过最小二乘准则逼近全数字预编码矩阵,但由于其模拟部分恒模约束的特性,因而无法逼近理论上最优全数字预编码方案。
总之,部分连接混合预编码复杂度最低,但是牺牲部分天线增益,因此其性能较差。混合连接则是部分连接与全连接的结合,实现了复杂度与性能的折中。全连接可以提供更大的天线增益,获得接近全数字预编码算法的性能。因此,伴随着人们对通信质量和传输速率要求的提升,全连接混合预编码将更加适用于未来天线的部署。
基于上述分析,本文提出一种全连接混合预编码算法,以系统频谱效率最大化为目标,联合设计收发端预编码矩阵和组合矩阵。首先,以等效信道增益最大化为目标设计模拟预编码矩阵和模拟组合矩阵,之后将总的混合预编码矩阵和接收端组合矩阵写成分块矩阵的形式,利用最小二乘准则,使其依次逼近最优全数字预编码矩阵和组合矩阵的每一列,可以达到理论上误差的最小化。仿真结果表明,本文所提算法优于参考文献[9]所提OMP算法与参考文献[12]所提基于信道SVD的混合预编码算法,且复杂度更低。
符号说明:| ⋅|表示取模,||⋅||F表示矩阵的F−范数,(⋅)H表示矩阵的共轭转置,tr(⋅)表示求迹,E[⋅]表示取期望,angle(⋅)表示取相位,A(i,j)表示矩阵A第i行j列的元素。
2 系统模型


接收端经过译码处理的信号可以表示为:
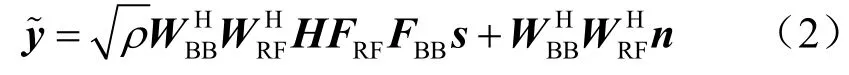
其中,H∈CNr×Nt为信道矩阵;WRF∈CNr×NRF为模拟组合矩阵, 需要满足恒模约束:为数字组合矩阵;ρ为接收信号的平均功率;n∈Nr×1为加性高斯白噪声,服从均值为0、方差为1 的复高斯分布,即n~CN( 0,1)。
毫米波信道可以建模为扩展的Saleh-Valenzuela信道模型[14],信道矩阵表示为:
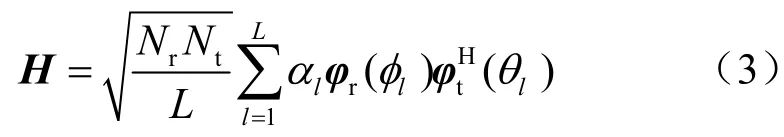
其中,L为收发端传播路径数 ,αl为第l条传播路径的复增益,φl∈[0,2π]和θl∈[0,2π]分别表示第l条路径的接收角和发送角。φr(φl)和φt(θl)分别代表接收端和发送端的天线阵列矢量。对于含有N个元素的ULA(uniform linear array,均匀线性阵列)响应向量,其可以分别表示为:
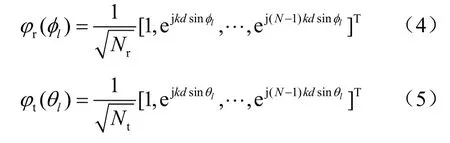
其中,k=2π/λ,λ为毫米波波长,d为每两根天线在空间上的距离[14]。
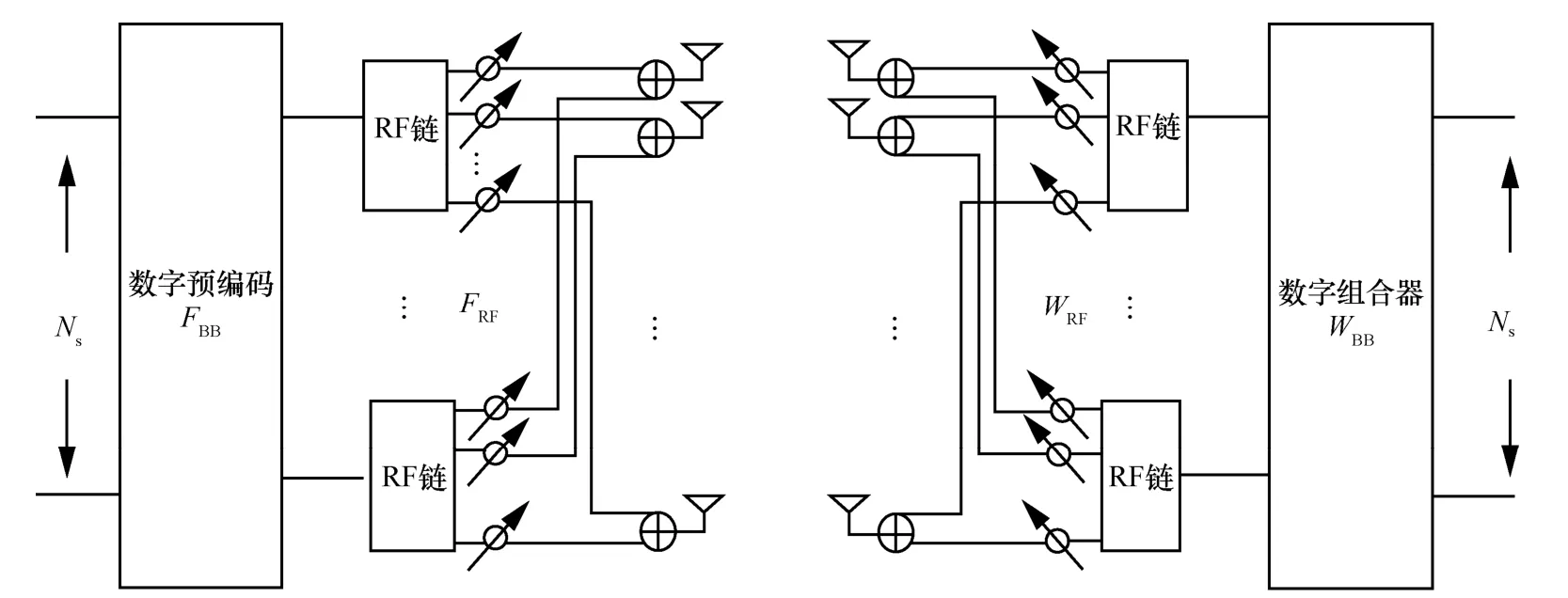
图1 毫米波大规模MIMO 系统结构
3 混合预编码矩阵与组合矩阵的设计
3.1 问题描述
针对第2 章所描述的系统模型,毫米波大规模MIMO 系统的频谱效率可表示为:
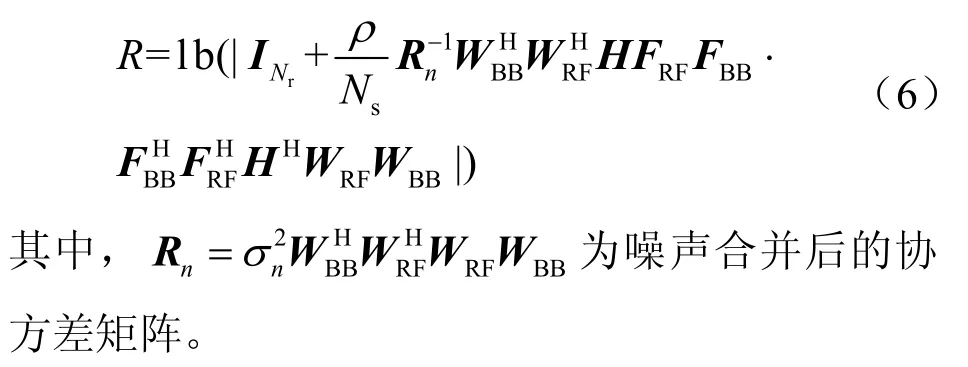
假设发送端和接收端均已知CSI(channel state information,信道状态信息),混合预编码矩阵(FRF,FBB) 和组合矩阵(WRF,WBB) 的设计目标是使得系统的频谱效率最大化,则设计问题等效于:
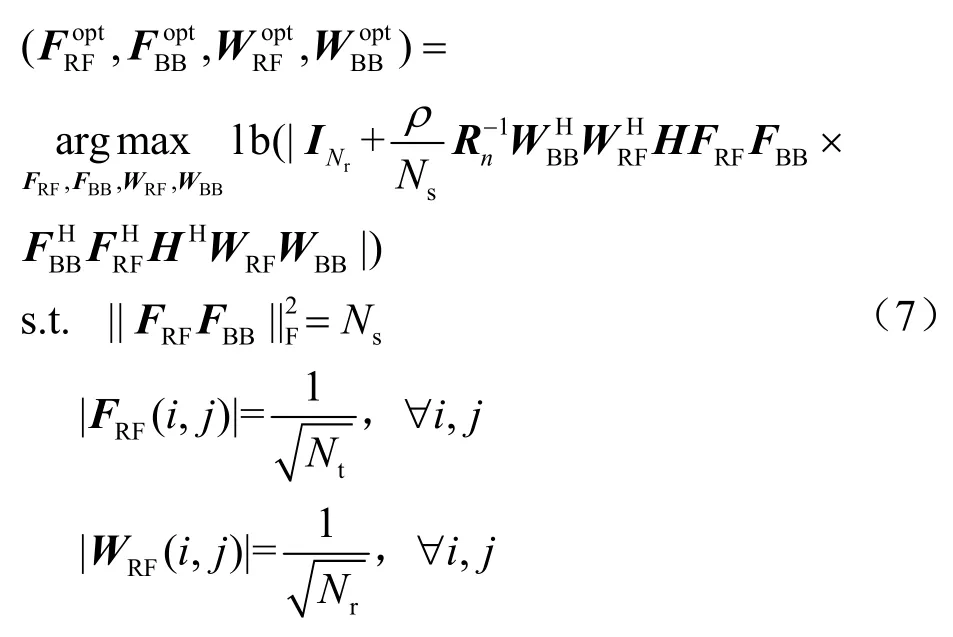
然而,式(7)的求解是含有非凸约束的四变量联合优化问题,很难直接求解以获得其全局最优解。因此,本文对其收发端的模拟部分和数字部分分别进行设计,在保证系统性能的同时,降低了运算复杂度。下文的工作便是基于此思路设计混合预编码矩阵和组合矩阵,实现系统频谱效率最大化。
3.2 模拟预编码矩阵和组合矩阵的设计
首先设计收发端模拟预编码矩阵FRF和模拟组合矩阵WRF,根据式(7)中的表达形式,将模拟预编码矩阵FRF、模拟组合矩阵WRF和信道矩阵H作为一个整体,构造等效信道He,使得:

(FRF,WRF)的设计目标是使等效信道增益达到最大化,即:

式(11)中,Σ为信道矩阵H的奇异值按降序排列组成的对角阵,U与V分别为其左右奇异向量组成的矩阵。则将式(11)代入式(10)中,可得其最优解分别为U、V的前NRF列,即:
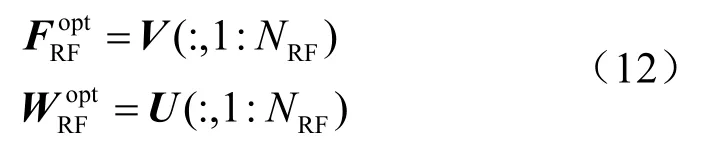
考虑到模拟预编码矩阵FRF和模拟组合矩阵WRF的恒模约束,无法直接应用其最优解,因此,取式(12)相位可得模拟预编码矩阵FRF和模拟组合矩阵WRF,表示为:
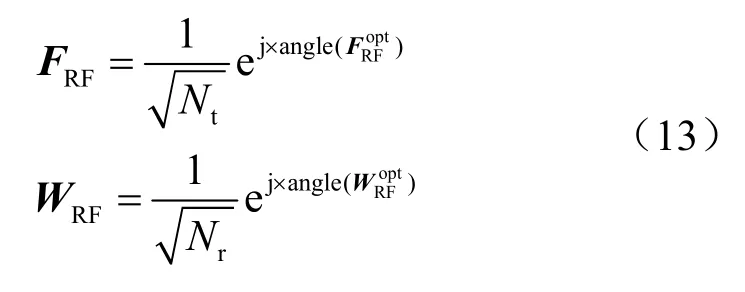
3.3 数字预编码矩阵和组合矩阵的设计
本节在第3.2 节中收发端模拟部分的基础上,对数字预编码矩阵FBB和数字组合矩阵WBB进行设计。由参考文献[10]可知,最优全数字组合矩阵Wopt和最优全数字预编码矩阵Fopt分别为信道矩阵H进行SVD 后的左右酉阵的前Ns列,即:
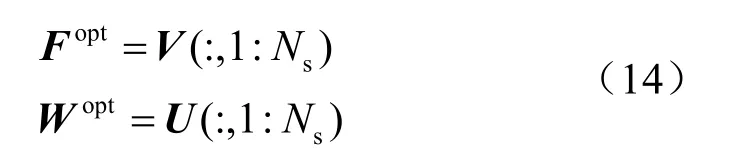
因此对于数字预编码矩阵FBB和数字组合矩阵WBB的设计,可以分别等效于求其与最优全数字预编码矩阵Fopt和全数字组合矩阵Wopt的欧氏距离最小值,即:
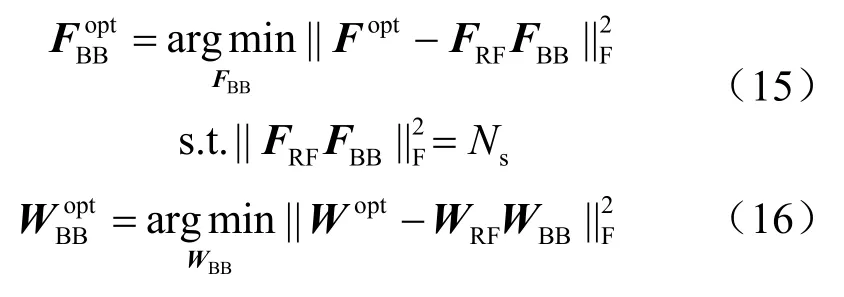
由式(15)、式(16)可知数字预编码矩阵FBB和数字组合矩阵WBB的设计过程完全一样,且接收端WBB无须考虑功率约束。因此,本文重点介绍数字预编码矩阵FBB的求解过程,此过程同样适用于数字组合矩阵WBB。
将数字预编码矩阵FBB按列写成分块矩阵的形式,式(17)中的fBBn表示数字预编码矩阵FBB的第n列:

将最优全数字预编码矩阵Fopt按列写成分块矩阵的形式,式(18)中的vn表示全数字预编码矩阵Fopt的第n列:
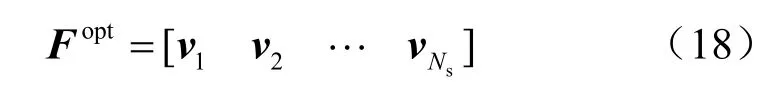
将式(17)、式(18)代入式(15),并进一步推导,得:
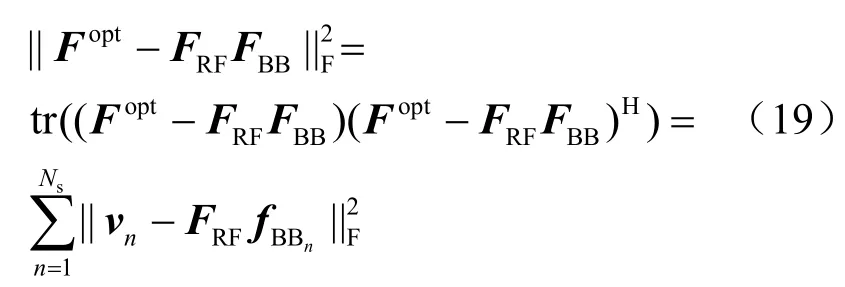
由式(19)可知,对数字预编码矩阵FBB的求解可以转化为对其每一列fBBn依次求解。因此,最优的数字预编码矩阵第n列的求解可以表示为:
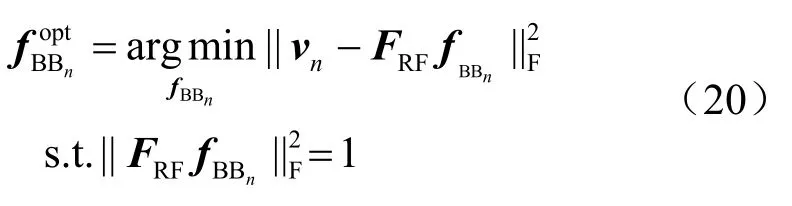
对式(20)展开可得:
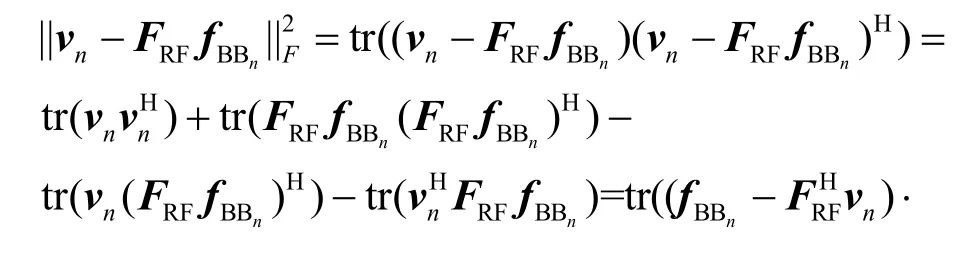

最终求得数字预编码矩阵FBB。
数字组合器WBB可采用同样的方法获得,在此不再赘述。
4 复杂度分析
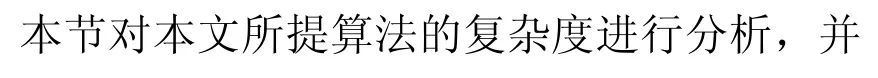


表1 各算法复杂度对比
5 仿真与分析
5.1 完美CSI 下各算法性能对比
本节在完美CSI 下对所提算法的性能进行了仿真。分别对比了参考文献[9]所提OMP 算法、参考文献[12]所提基于信道SVD 的混合预编码算法、纯模拟预编码算法以及最优全数字预编码算法。对比文献均采用全数字接收。本文Saleh-Valenzuela 信道参数设置如下:考虑一个点对点大规模MIMO 下行链路,收发端均采用ULA天线阵列。假设信道中散射簇的个数Ncl= 5,每个簇中射线数Nray=25,路径总数为NclNray=125。发送角AOD 与接收角AOA 均在[0,2π]上服从均匀分布,角度扩展为10°。路径增益αl服从均值为0、方差为σl2的复高斯分布,满足此外,仿真图上每一个点均通过1 000 次循环后取平均获得。
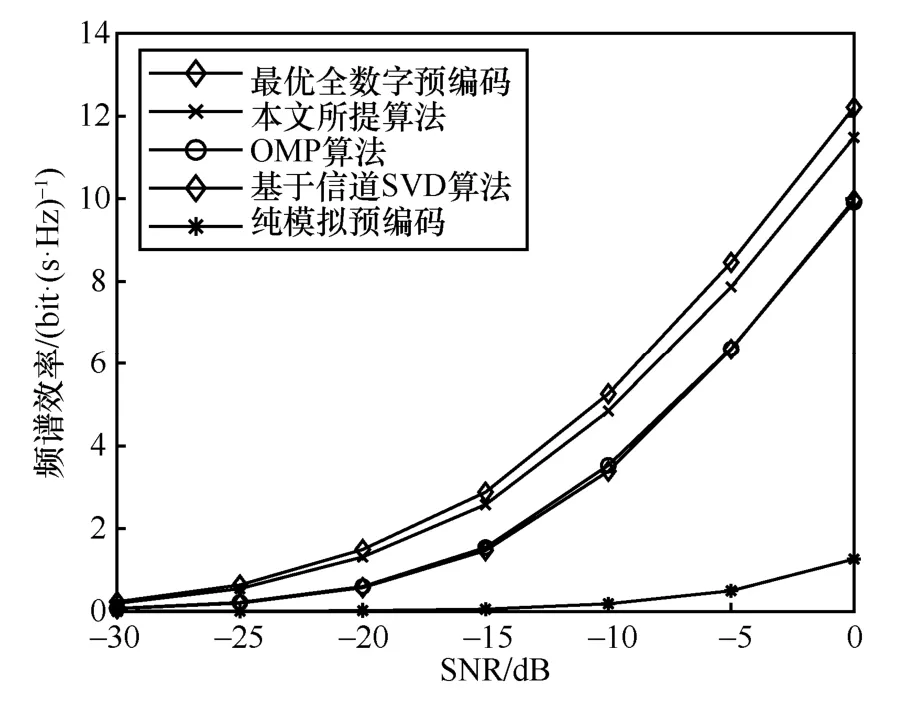
天线数Nt×Nr=128 × 8、Ns=NRF= 4的毫米波大规模MIMO 系统,各算法频谱效率与信噪比关系如图2 所示,数据流数Ns与RF 链数量满足Ns=NRF。由图2 可以看出,混合预编码算法性能上均远远优于纯模拟预编码算法,并且本文所提算法虽略低于全数字预编码算法,但相较于OMP 算法和基于信道SVD 混合预编码算法的性能更好,更加接近全数字预编码的性能。
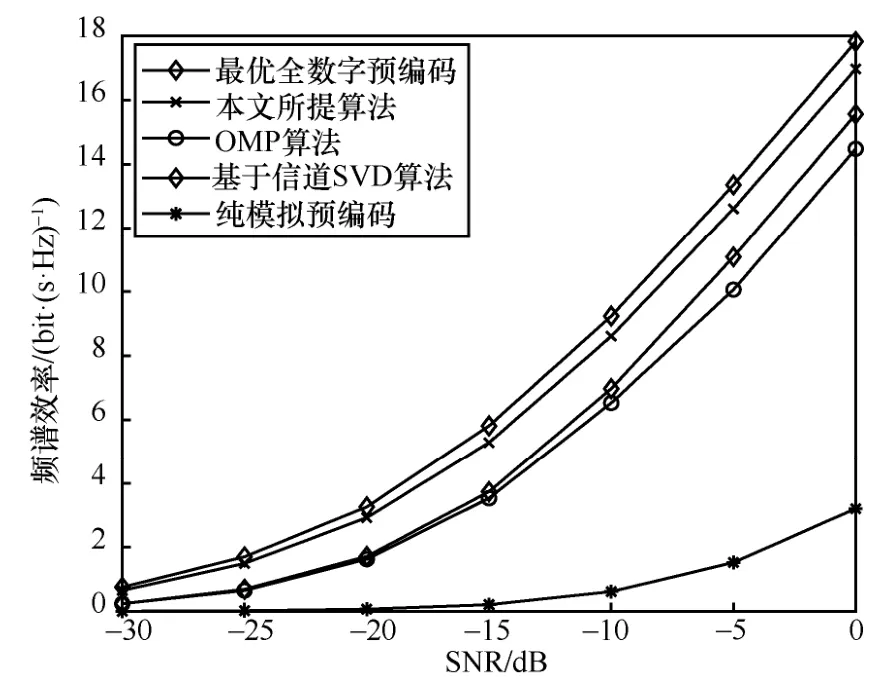
图2 各算法频谱效率与信噪比关系1
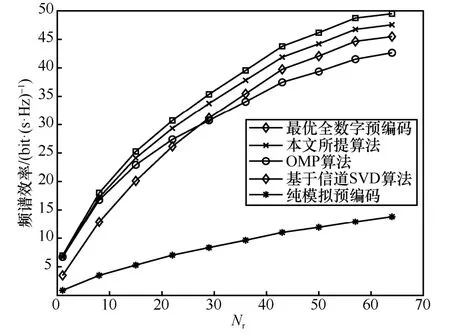
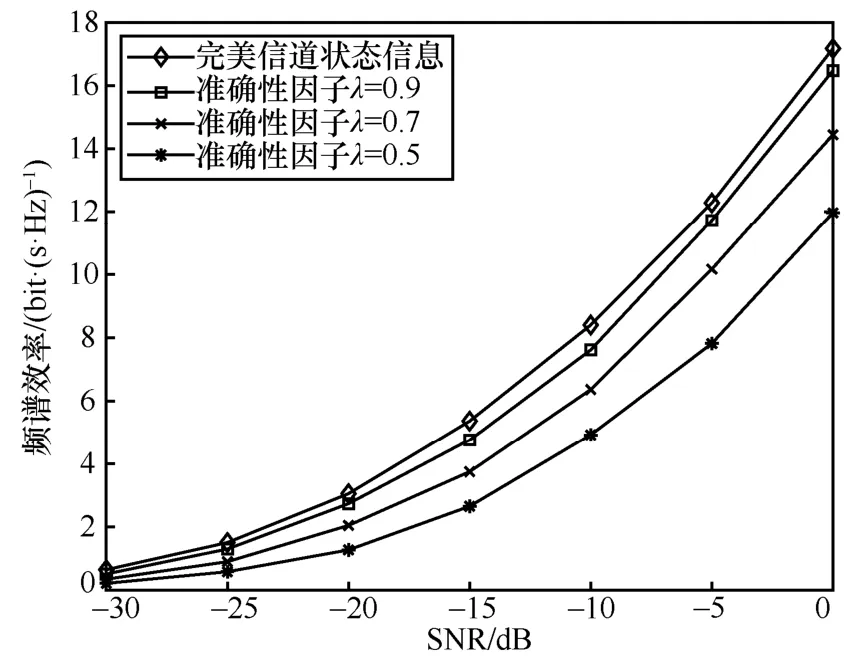
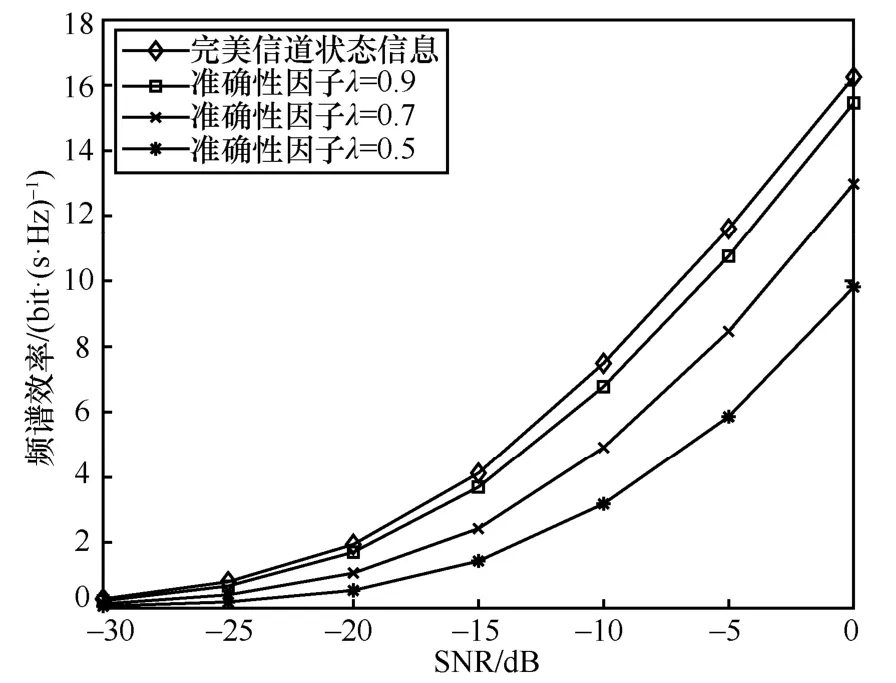
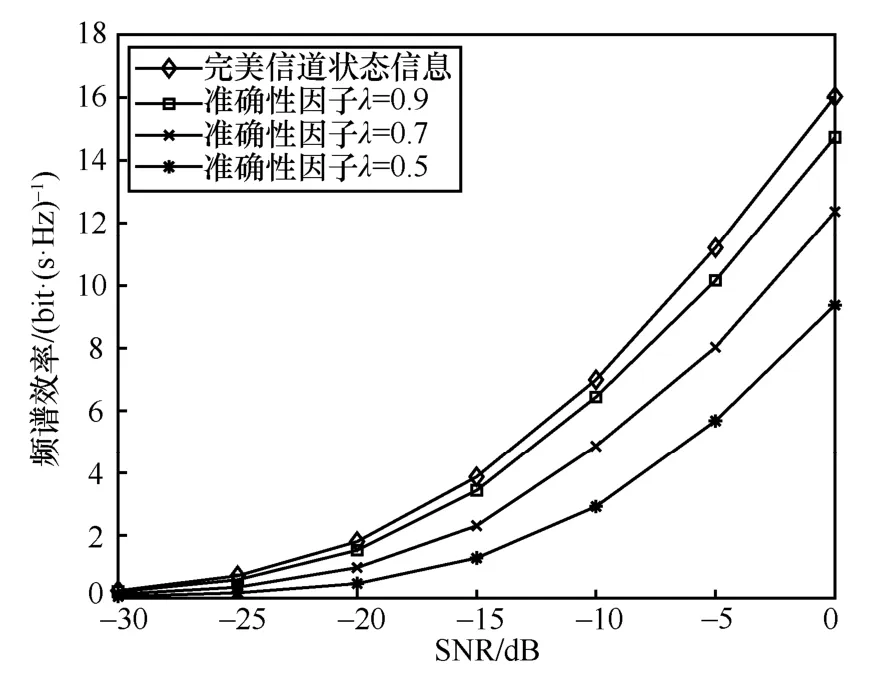
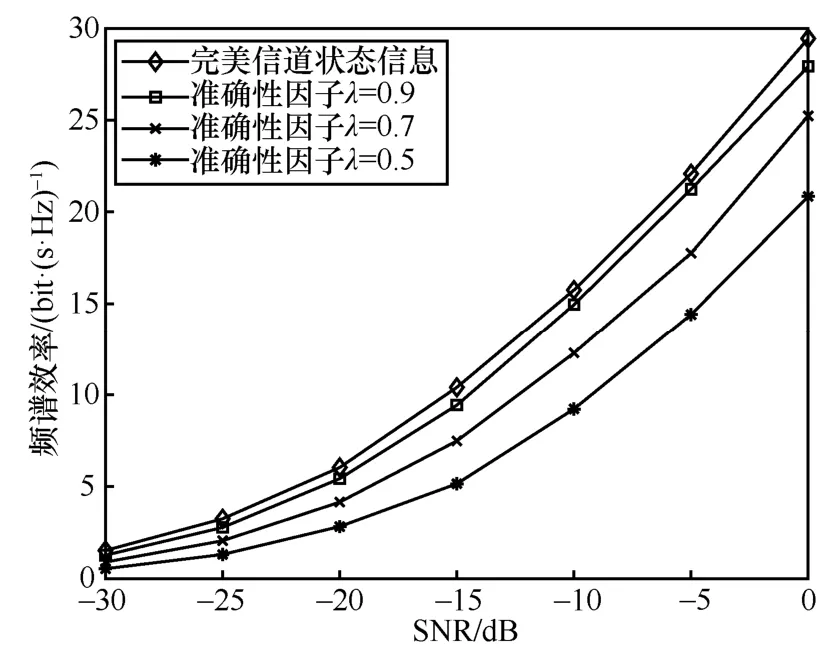
天线Nt×Nr=256 × 16、NRF= 8、Ns= 6的毫米波大规模MIMO 系统,各算法频谱效率与信噪比关系如图3 所示,数据流数Ns与RF 链数量满足Ns 图3 各算法频谱效率与信噪比关系2 Nt=128、NRF=Ns= 8、SNR = 0的毫米波大规模MIMO 系统,各算法性能与接收端天线数关系如图4 所示。由图4 可以看出,当接收端天线数较少时,本文所提算法与最优全数字预编码算法以及OMP 算法性能相同,高于基于信道SVD混合预编码算法,随着接收端天线数的增加,基于信道SVD 分混合预编码算法性能逐渐优于OMP 算法。本文所提算法随着接收端天线数的增加逐渐低于最优全数字预编码方案,但仍优于OMP 算法以及基于信道SVD 混合预编码算法。 上述仿真基于完美的CSI,然而在实际的应用中,由于信道估计存在误差,往往不能获得完美的CSI,因此本节将在不完美的CSI 下,对本文所提的算法进行评估。根据MMSE 准则信道估计,不完美CSI 下的信道矩阵H可以表示为[15]: 图4 各算法性能与接收端天线数关系 其中,λ为进行信道估计的准确性因子,满足0≤λ≤1 。E为误差矩阵,服从均值为0、方差为1 的复高斯分布。 图5~图7 分别表示Nt×Nr=128 ×8、NRF=8、Ns= 4毫米波大规模MIMO 系统 ,各算法在不完美CSI 下所能达到的频谱效率。当λ=0.9时各算法性能损失均不大,仅为1~2 dB。但随着信道估计误差的增加,各算法性能损失逐渐增加。当λ=0.7时,本文所提算法达到完美CSI 下频谱效率的85.3%,OMP 算法与基于信道SVD 算法分别为81.2%和76.3%;当λ=0.5时,本文所提算法达到完美CSI 下频谱效率的71.8%,OMP 算法与基于信道SVD 算法分别为62.5%和57.5%。本文所提算法容错性优于OMP 算法与基于信道SVD 算法。 Nt×Nr=256 ×16、NRF=Ns=8毫米波大规模MIMO 系统,本文所提算法在不完美CSI 下所能达到的频谱效率如图8 所示。从图8 中可以看出,随着收发端天线数以及数据流的增加,本文算法的频谱效率相应增加。当λ=0.9时,频谱效率损失2~3 dB;当λ=0.7和λ=0.5时,可以分别达到完美CSI 频谱效率的83.4%和71.7%。对比图5 与图8 可知,本文所提算法的容错性稳定,不会因收发端天线数的增加或数据流的改变而发生较大的变化,在信道估计存在较大误差时,依旧能保持较好的性能。 图5 N t×Nr=128 ×8、NRF=8、Ns =4本文算法在不同CSI 下的系统性能 图6 N t×Nr=128 ×8、NRF=8、Ns =4OMP 算法在不同CSI 下的系统性能 图7 N t×Nr=128 ×8、NRF=8、Ns =4基于信道SVD算法在不同CSI 下的系统性能 图8 N t×Nr=256 ×16、NRF=Ns =8本文算法在不同CSI 下的系统性能 天线数Nt×Nr=128 × 8、Ns=NRF= 4的毫米波大规模MIMO 系统,各算法在信道估计准确性因子λ=0.5时的性能对比如图9 所示。对比图2可以看出,各算法频谱效率均有损失,其中基于信道SVD 算法的性能损失最大,OMP 算法在完美CSI 下性能低于基于信道SVD 算法,但其容错性更优。本文所提算法无论性能与容错性均优于OMP 算法和基于信道SVD 算法,在不完美CSI下,依旧更接近最优全数字预编码方案。 图9 N t× Nr=128 ×8、NRF=4、Ns =4、λ=0.5各算法性能对比 本文提出了一种毫米波大规模MIMO 系统全连接混合预编码方案。仿真结果表明,本文所提算法在并未增加算法复杂度的情况下,与OMP 算法和基于信道SVD 混合预编码算法相比在系统性能上均更优。同时,本文所提算法的性能不会因信道估计的误差而受到较大的损失,容错性较强。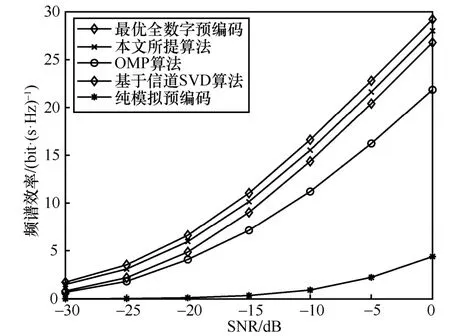
5.2 不完美CSI 下各算法容错性与性能分析
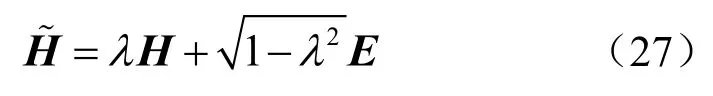
6 结束语
