求解0-1背包问题的混合贪婪遗传算法
2021-01-21钟一文
陈 桢,钟一文,林 娟
(1.福建农林大学计算机与信息学院,福州 350002;2.智慧农林福建省高等学校重点实验室(福建农林大学),福州 350002)
0 引言
背包问题(Knapsack Problem,KP)[1]属于经典的组合优化问题,属于NP 难问题[2],该类问题包括许多变种:0-1KP[3]、有界KP、无界KP、多重约束的KP、多维KP、集合并集的KP、多KP、多重选择的KP、二次KP、动态KP、折扣KP[4]以及其他类型的KP。在众多变体KP中,最基本的就是0-1KP。在理论上,许多整数规划问题的求解都依赖于一个高效的求解KP的算法,因此在实际应用中常常被用于工业、金融等领域,比如投资决策、货物装载等。
传统求解0-1KP 的办法是精确算法,譬如穷举法、动态规划法、递归法、回溯法和分支定界法等[4]。精确算法可以得到问题的精确解,但是随着物品数量和背包容量的增加,算法时间的复杂性呈现出指数级的增长趋势,计算效率比较低,因此只适合小规模问题的求解。而元启发式算法作为近似搜索算法,可在较短时间找到问题的近似有效解,逐渐成为解决大规模0-1KP 的主流方法。该类算法大致可分为两类:以局部搜索为特征的单个体迭代算法,包括经典的模拟退火(Simulate Annealing,SA)算法[5]、混合贪婪修复算子的噪声检测算法(Noising Methods with hybrid greedy repair operator,NM)[6]等;以协同搜索为特征的基于种群的智能优化算法,包括常见的蚁群优化(Ant Colony Optimization,ACO)[7]、粒子群优化(Particle Swarm Optimization,PSO)[8]、遗传算法(Genetic Algorithm,GA)[9],新兴的布谷鸟搜索[10]、帝王蝶优化算法[11],以及和声搜索算法(Harmony Search Algorithm,HSA)[12]等,均可见在0-1KP上的应用。
GA作为一种典型的进化型算法,其独特的选择、交叉、变异算子以及概率化的寻优方式,使得算法自动获取解空间的布局,自适应地调整搜索状态,因此算法具有较好的全局协同搜索能力。但由于GA 缺乏有效的小范围搜索策略,导致其局部搜索能力较差,在实际应用中,容易产生早熟收敛的问题。为了有效提高GA 在全局大范围搜索中跳出局部极值解的能力,同时结合0-1KP 的问题特征,本文提出混合贪婪遗传算法(Hybrid Greedy Genetic Algorithm,HGGA):在GA 的并行解空间中,增加提高个体的局部求精能力的搜索模块;并针对常用的基于物品价值密度的修复优化算子仅强调物品的性价比,使得总体价值高但相对性价比低的物品难以被选入,从而导致搜索范围缩减及收敛速度降缓的问题,提出同时选择物品价值密度以及物品价值为标准的混合贪婪操作算子,在局部解空间中展开弹性的动态搜索。算法在并行迭代的算法框架中,通过增强GA 的精细搜索能力得到算法求精能力和求泛能力的良好平衡。算法在不同问题性质及大规模的测试集上进行了测试,并通过与同类算法的对比,显示出较好的性能。
1 相关工作
1.1 0-1背包问题
0-1KP 可以简单描述为:给定n种物品集合N={1,2,…,n}和一个背包容量为C的背包。每一种物品i都有它的重量wi(>0)和价值vi(>0)(i=1,2,…,n)。求最优装包方案(x1,x2,…,xn),xi∈{0,1}(xi=0 表示不把第i个物品放入背包,xi=1 表示把第i个物品放入背包),使得背包的总重量W不超过C的同时获得的价值V达到最大。在选择物品装入背包时,物品只有两种状态:整体装入或不装入。其数学表达式为:

0-1KP 问题属于带有约束条件的最大值优化问题,对违反约束条件的处理通常有两种方法。第一种是罚函数方法,通过对不可行解增加一个负值罚分从而排查此类解进入下一轮迭代的可能性。另外一种更常见的方法是引入修复优化操作,该操作分为两个步骤:首先是修复操作,即对不可行解按照一定的准则移除物品,直到该不可行解变为可行解为止;接下来是优化操作,即选择合适的物品加入,在出现不可行解之前停止。其中,对于物品的选择标准,通常采用的是基于价值密度的贪婪选择方法,即优先选择单位价值(vi/wi)密度大的物品。具体算法描述如算法1和算法2。在两个算法中,均引入了一个基于价值密度降序排列的物品列表HD,当不可行解出现时,首先采用贪婪修复算子(OPerator-Repair,OP-R)进行修复,根据物品在HD中的排序依次对物品进行考察,如果当前物品在背包中,将其移除,直至背包内物品总量量满足约束条件为止;随后采用贪婪优化算子(OPerator-Optimization,OP-O)对该解进行优化,同样根据HD中物品的顺序,优先选择价值密度大的物品进行加入。
算法1 贪婪修复算子(OP-R)。

1.2 求解0-1背包问题的启发式算法
GA作为一个经典的启发式搜索算法,通过对生物遗传和进化过程中选择、交叉、变异机制的模仿,来完成对问题最优解的自适应搜索过程,在解决大规模组合问题方面具有较好的表现。其中在解决0-1KP 方面,一般是通过两种方法进行求解:一种是基于罚函数的基本遗传算法(Simple GA,SGA)[13];一种是基于处理约束条件的修复或修复优化的贪婪算子的改进遗传算法,其中改进遗传算法较SGA 优越。Michalewicz[14]首先研究了利用GA 求解0-1KP 时个体编码方法的优劣以及处理0-1KP 不可行解的罚函数法与修复法,指出:GA的个体采用0-1向量编码比自然数编码的效果更佳,而且利用修复法处理0-1KP 不可行解比罚函数法的结果更好。从此,人们在利用GA 求解0-1KP 时一般均采用0-1 向量的编码方式。
GA 的搜索能力由选择算子、杂交算子决定,变异算子保证算法能搜索到问题空间的尽可能多的点,从而使其具有搜索全局最优的能力,所以一般求解0-1KP的改进GA 也是从这3 个算子上做调整和改进,结合基于修复或修复优化的贪婪算子求得最优解。文献[15]将贪婪算子与GA 结合起来得到混合遗传算法(Hybrid Genetic Algorithm,HGA)。在HGA 中首先采用二进制编码的GA 产生新解,然后通过价值密度引导的贪婪算子对不满足约束条件的解进行修复。文献[16]针对HGA 中提出的贪婪算子的缺陷提出新的贪婪算子,不仅仅修复不满足约束条件的种群,也优化满足条件的种群,并将此方法与GA 相结合构成一种新的算法GGA。文献[17]将基于价值密度的贪婪算法与GA 相结合提出一种改进的混合GA来求解0-1 背包问题,改进的混合GA 通过GA 的择优,重复执行选择、交叉和变异以及基于价值密度的贪婪算法的修复优化这样一个过程,使得解无限接近最优解,同时采用精英保留机制来提高算法的收敛速度。文献[18]用GGA 改进的贪婪算子提出一种改进混合遗传算法(Improved Hybrid Genetic Algorithm,IHGA),对染色体进行修复和优化,并基于稳态复制的策略,对GA 的选择操作进行改进,给出了随机选择操作。
还有一类改进GA,通过加入模拟退火算法(SA)或改进的SA 来增加局部搜索能力,使得通过GA 的全局搜索方式下求得的解能够跳出局部极值,并最终趋于全局优化。文献[19-20]分别运用模拟退火和遗传算法相结合的方法求解0-1KP,克服了各自的弱点,提高算法的优化性能、优化效率和可靠性。文献[21]借鉴二重结构编码的解码处理方法设计了一种新解码方法,在保证解可行性的同时修正种群中无对应可行解的个体;采用模拟退火算法和改进的精英选择算子改进SGA。
上述算法在进化效率或最优解搜索能力上都存在一些不足,因此,受SA具有较强局部搜索能力可以弥补GA的局部求精能力不足的启发,同时借鉴文献[6]中贪婪算子的改进方法,本文提出了一种新的混合贪婪遗传算法,使得局部搜索和全局搜索相互结合,取长补短。
2 改进的混合贪婪遗传算法
本文提出的改进算法主要针对以下问题:混合GA 的局部求解能力不足、算法倾向早熟收敛;基于价值密度的修复优化方法过分强调价值与重量的比率、无法全面覆盖优质解且降低搜索速度。本文提出结合局部搜索和混合修复优化算子的混合贪婪遗传算法,首先在标准的GA 框架下增加局部搜索模块,并采用基于贪婪思想的混合修复优化算子,对个体展开解空间中的精细更新,有机结合协同搜索和局部搜索的优势,从而提高算法的整体性能。
2.1 解的表示及初始化
0-1KP 属于组合优化问题,对于此类问题的解,在GA 中采用二进制编码方式,即种群中的每一个个体为一个n元0-1向量x,该向量中的每一位随机取值为0或1,分别表示把此物品放入或不放入背包中。
2.2 全局搜索模块
本文提出的算法依托标准GA 的全局开拓能力,执行标准GA 的进化框架,在种群随机初始化产生之后,通过交叉、变异和选择操作产生新的种群。
1)交叉操作:对初始化种群中的解随机取两个染色体作为父母个体,依照交叉概率选择个体进行均匀交叉操作,生成与父代个体数目一致的子代个体。
2)变异操作:对子个体按照变异概率进行基位变异,对选中的位置上的0/1 编码进行逆向转化,即0 变异位1,1 变异为0。
3)选择操作:采用择优选择法,将父代和子代的个体统一按照适应值的降序排序,根据该排序选择满足种群数的个体组成新一代的种群。
2.3 局部搜索模块
通过第一阶段的种群进化过程,种群中的个体已覆盖了较广的搜索区域,但对于现有范围的精细搜索,在GA 的算法框架内没有较好的办法。因此,在种群总体得到一次进化操作后,对于种群中的每一个个体,增加一个局部搜索模块,使得每一个个体以自身为搜索起点,在其周围展开局部范围内的搜索。具体操作步骤为:对于种群中的每一个个体,随机对一个位进行翻转,采用贪婪的方式接受修改,即如果该操作使得对应的适应值得到提高,就接受新解以代替旧解;否则沿用旧解,进行下一轮的局部扰动,直到达到预先设置的局部搜索次数。在后续的操作中,经过新一轮的全局搜索过程,采用GA三个基本操作将优质的局部解信息迅速扩散,同时在局部搜索中出现的极易陷入局部最小值,而贪婪接收方式无法轻易跳出极值的问题,通过全局的进化过程,陷入极值的解得以相应调整并往正确的方向进化。进一步地,在总体迭代条件不变的情况下,通过合理平衡全局迭代次数以及局部搜索次数,在种群中的优良信息得以均匀快速地推广同时,在较理想的解空间周边的细致搜索也使得算法找到全局最优解的可能性大大提高。通过这样全局搜索和局部搜索有机结合的方式,算法在全局求泛和局部求精的性能上得到了良好的平衡。具体算法描述如算法3。在算法3 中,对于种群的每一个个体,随机选择一维进行扰动,同时进行修复和优化,如果之后的结果好于原先的解,就替代原先的解,继续进行下一轮搜索,直到达到局部搜索次数为止。
算法3 局部搜索算法。

2.4 混合贪婪算子
对于在迭代过程中不可行解的处理,通常采用基于价值密度的贪婪修复和优化操作。虽然这种操作方式使得性价比高的物品优先进入背包,但是这种单一的选取方法将导致具有较大价值但相对性价比低的物品无法被选入,而这部分物品的加入可大幅提高算法的全局寻优速度。但是单纯选择价值大的物品同样也会增加算法陷入局部最优解的概率。因此在HGGA 中采用基于混合策略贪婪修复算子(Operator-Hybrid,OP-H)。该算子借鉴了文献[6]的混合贪婪修复算子策略,在不可行解时,算法首先采用采用基于价值密度的准则移除性价比最低的物品,在尽量保持现有优质解信息的同时进行有效率的修复;在优化过程中,采用随机的方式,概率性地选择基于价值密度或价值的策略,弹性地对解进行优化,在提高算法的收敛速度的同时有效避免陷入极值点。与文献[6]不同的地方在于:NM算法在不可行解出现时,直接采用概率方法选择不同的策略同时进行修复和优化,这样会造成价值大的物品有较大概率被移除出背包,从而降低算法收敛速度。具体算法描述如算法4。
算法4 混合贪婪算子(OP-H)。
输入 按照价值密度降序排列的物品列表HD,按照价值降序排序的物品列表HV,选择概率p和不可行解个体x。
输出 满足约束条件的优化解x′。


在算法4中,首先基于价值密度的选择方式调用算法1修复初始解x中的不可行解,接着随机生成概率r,对于修复过的可行解来说,如果r小于p,采用基于价值密度的选择方法对个体x进行优化;反之则优选选择价值大的物品加入x中。
在算法运行过程中,一旦产生新解,上述两个算子OP-R及OP-O就对该新解分别进行修复和优化的工作。其中,贪心修复算子负责将价值密度最低的物品尽快移除,在对违反约束条件的解进行修复的同时提供进一步优化的空间,贪心优化算子负责对修复后的解进行局部优化。两个算子协同工作,在解空间中展开合法、有效的搜索。
2.5 HGGA框架
HGGA 主要有3 个重要的组成部分:在初始解随机生成之后,首先依靠GA 的全局搜索流程,通过经典的交叉、变异、选择操作进化出新一代种群;然后对种群中的每一个个体展开局部范围内的更新;对于不可行解的修复过程采用混合贪婪修复算子进行操作。3 个组成部分协同搜索,构造有效解空间,引导整个种群进化,最终找到最优解。具体算法描述如算法5。
算法5 HGGA流程。
输入 函数评价次数MET,popSize,localTimes,HD,HV。
输出 最优解Xbest。

3 仿真实验及结果分析
3.1 测试数据集
为了验证HGGA 的性能,引入在各文献中出现的3 个数据测试集分别进行测试。
第1 个测试数据集来自文献[22],根据问题特征按照物品质量、价值呈无相关、弱相关和强相关分为3 类,分类特征如表1所示。每类中包含5个测试实例,分别包含物品数量为800、1 000、1 200、1 500 和2 000。在表2 中分别给出这3 类测试例子的具体名称、物品数目及理论最优解。
第2 个测试数据集的两个实例(实例1、2)是0-1KP 的经典实例,实例来自文献[18],两个实例的实验次数均为50 次。n为物品数量,C为背包容量,V为物品价值,W为物品重量。
第3 个测试数据集来自文献[23],数据集是大规模的0-1KP 产生的。每个物品的价值是从0.5到1之间随机生成的,相应的物品重量也是在0.5到2之间随机生成的。
背包的最大容量被设置为上述物品重量之和的0.75 倍。这些数据都是随机生成器一次生成的,并且用于所有的实验。放入背包的物品数量从100 到6 400,包括100、200、300、500、700、1 000、1 200、1 500、1 800、2 000、2 600、3 000、3 500、4 900、5 800、6 400。这些实例被标记为LKP1~LKP16。

表1 第1个大样本数据的分类特征Tab.1 Classification characteristics of first dataset of large sample data

表2 第1组15个测试例子的参数值Tab.2 Parameter values of 15 test cases in first dataset
3.2 参数设置及运行环境
在HGGA 中,采用函数评价次数MET作为迭代结束条件,取值为40 000;在GA框架下的参数沿用经典的GA参数[24]设置:交叉概率cp取值为0.1,变异概率mp取值为0.01;对于平衡算法全局与局部搜索性能的种群数popSize和局部搜索次数localTimes,在固定的MET条件下,采用实验的方式决定。混合贪婪算子的选择概率dp设为0.5。每个测试用例上的实验独立运行次数设为100。
实验的硬件环境为小米笔记本,CPU 型号为Intel Core i5-8250U,内存8 GB,软件环境为64 位Windows 10 操作系统,算法使用Java语言在Eclipse IDE中编写。
3.3 参数分析
在相同的函数评价次数下,如何设置种群数和局部搜索次数决定了HGGA 搜索的深度和广度。如果种群数太大,而局部搜索次数太小,会导致种群在局部范围内搜索精度不足,从而影响算法整体寻优能力;反之如果局部搜索次数太大,而种群数设置太小,会因算法的多样性不足而容易出现早熟收敛的现象。选用3.1 节中的第1 组数据集中的重量价值呈强相关的5 个数据集,对于popSize和localTimes分别设置(100,10)、(50,20)、(20、50)、(10、100)进行测试,并观察100 次重复实验中Xbest最后一次得到改善时的平均迭代次数。从图1可以看出,当种群数和搜索次数取(10、100)时,最优解得到最后一次改进所需要的迭代次数最少,所以这种搭配可以对算法在多样性和收敛性上达到一个比较均衡的平衡。因此,算法最终的popSize设置为10,localTimes设置为100。

图1 不同参数组合下算法最后一次得到改进所需的平均迭代次数对比Fig.1 Comparison of mean iterations required by the algorithm to have the last improvement under different parameter combinations
对于混合贪婪算子中使用的选择概率dp的取值,采用实验统计方式进行。当dp取0 和1 时,分别代表只采用基于价值和密度和只采用价值作为选择准则的操作算子。测试选用3.1 节的表2 的3 组大样本数据的15 个测试数据集,dp分别取0、0.1、0.2 取到1,统计15 个测试用例在不同取值下得到最优解的个数。结果如图2所示。
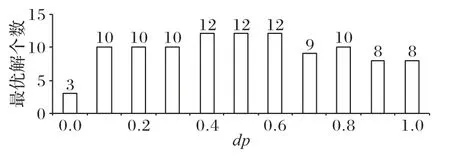
图2 不同dp取值在15个测试例子上取到最优解的个数对比Fig.2 Comparison of the number of obtained optimal solutions on 15 test cases with different dp values
当dp=0 时,仅有3 个测试用例能够得到最优解,当dp在0.4~0.6 时,能够取到的最优解的个数最多。因此,为了增强算法的普适性,在本文中dp取值为0.5。
3.4 算法性能分析
为了测试HGGA 性能,在第1 个数据集上进行了测试。算法独立运行100 次,统计得到的最优解与理论最优解的实际差值、最优解、最差解、均值解、中位数解和标准差,适应值最后一次得到提高时的迭代次数,运行时间以及在100 次重复中得到最优解的成功率。表3 给出测试结果。粗体部分为获得最好状态的解。
从表3 中可以看出,本文提出的算法在所有15 个测试用例上均能找到最好解,对于其中的11 个测试用例可以百分百找到最优解。虽然在KP01、KP08、KP09 上的成功率较低,但是通过观察其找到的均值解、中位数解以及最差解可以看出,HGGA 所能找到的解与最优解非常相近,并且所有测试均在1 s内完成100次重复性实验,显示了算法的良好性能。
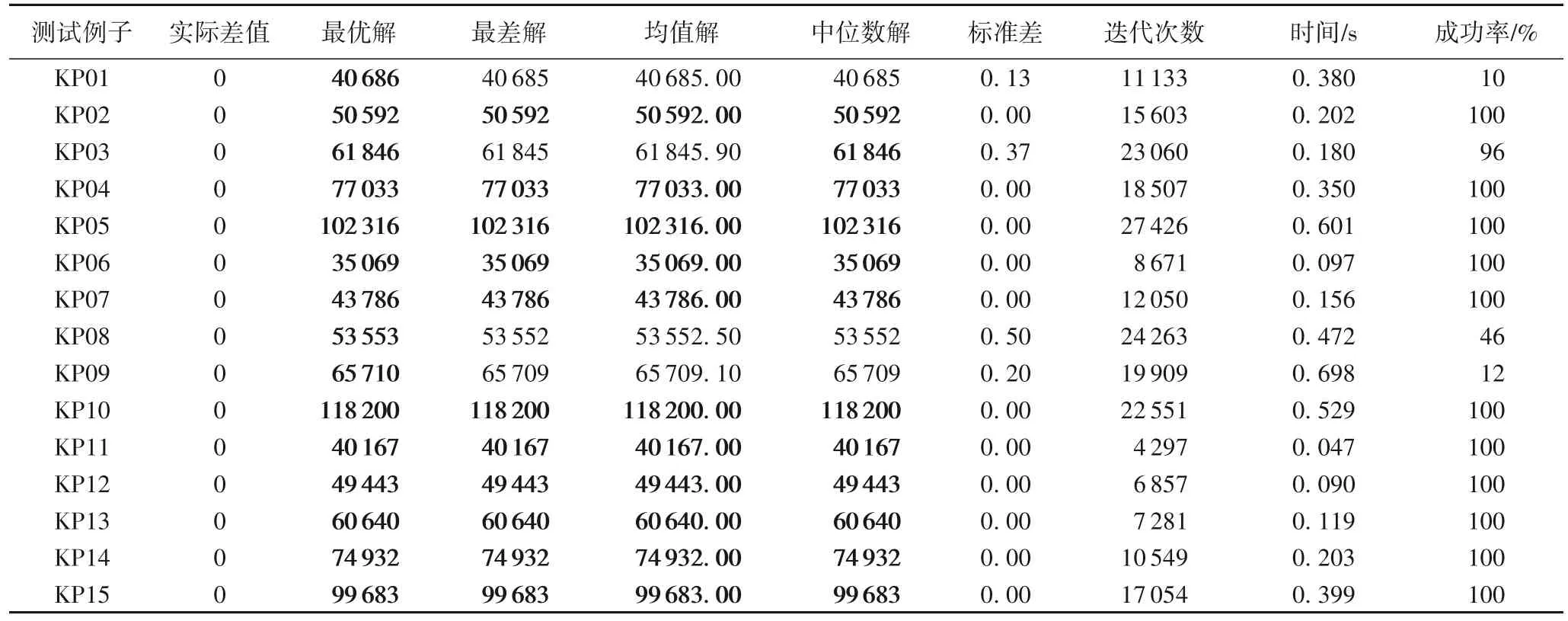
表3 HGGA在15个不同类型测试例子上的结果Tab.3 Results of HGGA on 15 test cases with different types
3.5 与同类算法的比较
为了进一步显示HGGA 的算法性能,引入不同的测试数据分别与其他GA 以及近年来表现较好的其他新型算法分别进行纵向及横向的比较。
3.5.1 与GA的比较
测试数据采用上述第2 个测试数据集,背包里的物品数目分别取50和100,所有结果的数据均来源于原文献。其中,HGA 是使用贪心变换与GA 结合的贪心GA[15],IHGA[18]是改进的混合GA。n代表物品个数,算法独立运行50 次,J为50次实验中得到的最好解,JC代表最好解在50 次内出现的次数,JZ代表繁殖代数的均值。cp和mp分别采用与文献中相同的设置值0.5和0.01。表4给出与其他GA的比较结果。
从表4 可以看出,HGA、IHGA 和HGGA 在背包里的物品数目取50时都得到最优的结果,HGGA 在50次实验中每次都能求出最优值,而背包里的物品数目取100 时,只有HGGA 能得到最优解,而且50 次实验中都能找到最优解。从这两个结果可得出,HGGA 与同类算法相比,在小规模的测试数据上具有较好的性能。

表4 不同改进遗传算法求解0-1KP的结果Tab.4 Results of different improved genetic algorithms in solving 0-1KP
3.5.2 与其他元启发算法的比较
为了进一步测试算法性能,算法与其他同类型的元启发算法在不同规模的问题上进行了比较。进行比较的算法为:基于全局和谐搜索的混合布谷鸟搜索算法(hybrid Cuckoo Search algorithm with Global Harmony Search,CSGHS)[10]、二元帝王蝶优化(Binary Monarch Butterfly Optimization,BMBO)算法[11]、混沌帝王蝶优化(Chaotic Monarch Butterfly Optimization,CMBO)算法[22]、基于对立学习的帝王蝶优化(Opposition-based learning Monarch Butterfly Optimization,
OMBO)算法[25]和混合贪婪修复算子的噪声检测算法(NM)[6]。表5~7分别给出了3组数据上的表现。

表5 HGGA与其他元启发算法在求解5个无相关特征0-1KP时的数据对比Tab.5 Data comparison of HGGA and other meta-heuristic algorithms in solving 5 0-1KPs without correlation characteristics
表5 的数据表明,在大样本的物品价值和数量无相关的测试数据中,CMBO、OMBO、NM 和HGGA 比CSGHS 和BMBO在找到最优解上表现得更好,NM 在KP01 的测试数据里表现略差,CMBO 和OMBO 在KP03 上表现较弱。HGGA 在这5 个例子中最差解、均值解和中位数解上的表现都比CMBO、OMBO 和NM 好。在方差std的测算上,HGGA 的总体表现也是最好的,足见该算法的稳定性。表6 显示了这些算法在求解5 个无相关特征的0-1KP 数据上的平均排名,对于KP05,CSGHS 和BMBO 没有数据,取KP01~KP04 排名的平均值作为KP05 的排名取值,并对这些排名数据进行0.05 显著性水平条件下的Friedman 检验,得到的p值等于0.003,说明这些算法在排序值上有显著性差异。

表6 6个算法在求解5个无相关特征的0-1KP时的平均排名Tab.6 Average ranking of 6 algorithms in solving 5 0-1KPs without correlation characteristics
表7 的数据表明,在大样本的物品价值和数量呈弱相关的测试数据中,CMBO、OMBO、NM 和HGGA 比CSGHS 和BMBO 表现得好。OMBO、HGGA 在5 个测试算例中都得取得最优解,CMBO 在KP08,NM 在KP09 上没有取得最优解。HGGA 在最差解、均值解和中位数解上综合表现是胜出的,方差也较小。表8 显示了这些算法在求解大样本的物品价值和数量呈弱相关的测试数据上的平均排名。对于KP10,CSGHS 和BMBO 没有数据,取KP06~KP09 排名的平均值作为KP10 的排名取值,在0.05 显著性水平条件下的Friedman 检验得到的p值为0.004,说明这些算法在排序值上有显著性差异。

表7 HGGA与其他元启发算法在求解大样本弱相关特征的0-1KP时的数据对比Tab.7 Data comparison of HGGA and other meta-heuristic algorithms in solving 0-1KPs with weak correlation characteristics of large samples

表8 6个算法在求解5个大样本弱相关特征的0-1KP的数据的平均排名Tab.8 Average ranking of 6 algorithms in solving 5 0-1KPs with weak correlation characteristics of large samples
表9 的数据表明,在大样本的物品价值和数量呈强相关的测试数据中,CMBO、OMBO、NM 和HGGA 比CSGHS 和BMBO 表现得好。CMBO、OMBO、NM 和HGGA 在5 个测试算例中都取得最优解。NM 和HGGA 的方差在5 个例子里都为0,说明算法的在这个测试数据集上的表现非常稳定。表10显示了这些算法在求解大样本的物品价值和数量呈强相关的测试数据上的平均排名。对于KP15,取KP11~KP14 排名的平均值作为KP15 的排名取值,在0.05 显著性水平条件下通过Friedman 检验得到的p值为0.002,说明这些算法在排序值上有显著性差异。

表9 HGGA与其他元启发算法在求解大样本强相关特征的0-1KP时的数据对比Tab.9 Data comparison of HGGA and other meta-heuristic algorithms in solving 0-1KPs with strong correlation characteristics of large samples

表10 6种算法在求解5个大样本强相关特征的0-1KP的数据的平均排名Tab.10 Average ranking of 6 algorithms in solving 5 0-1KPs with strong correlation characteristics of large samples
值得说明的是,HGGA 与除NM 之外的其他比较函数一样,属于基于种群的优化算法,因此针对0-1KP,它们的算法时间复杂度均取决于外层迭代数目、种群数目及物品数量;而NM虽然不属于基于种群的算法,但其迭代过程类似地取决于外层迭代数目、内层局部搜索迭代数目及物品数量;进一步地,虽然HGGA加入了局部搜索部分,但这个部分的时间复杂度取决于局部搜索迭代次数、种群数目及物品数量,并不影响整体算法复杂度,因此这几个参与比较的算法均具有相同的时间复杂度,而HGGA 可以在更少的函数评价次数内找到优质解。
3.5.3 在大规模数据集上的比较
为了进一步测试算法在大规模数据集上性能,采用上述第三组测试用例,进行比较的算法为:大型0-1 背包问题的简化二进制和声搜索(Simplified Binary Harmony Search,SBHS)算法[23],表11 给出了不同的算法在16 个测试数据上的表现。表11 的数据表明,在这16 个大型0-1KP 的测试数据中,对于前6 个数据,SBHS 和HGGA 的最优解相同,而HGGA 在最差值、均值解和中位数上的表现都均优于SBHS。在数据LKP7-LKP14 中,HGGA 在各指标上的表现都优于SBHS;在数据LKP15中,SBHS的均值解和中位数解较优;在数据LKP16中,SBHS解的所有表现都会比HGGA略好。
在标准差上,除了最后一个测试例子外,HGGA 在每一个测试用例上的表现均优于SBHS,足见HGGA 在大规模的测试数据上的稳定性。

表11 HGGA与SBHS算法在求解大样本强相关特征的0-1KP时的数据对比Tab.11 Data comparison of HGGA and SBHS algorithms in solving 0-1KPs with strong correlation characteristics of large samples
4 结语
针对GA 在解决大规模离散优化问题上全局搜索能力强、局部求精能力薄弱的缺点,本文提出混合了局部搜索算子的改进GA。算法在不变动GA 的基本框架下,融合具备局部精细搜索能力的局部搜索方法,使得算法得以依赖GA 的强大全局搜索性能将局部搜索中得到的优质解快速扩散;同时设计混合贪婪修复算子,在个体保留优良信息的同时提高算法的寻优速度。算法应用于0-1KP,在不同问题规模及性质的测试集上进行大量的仿真实验,通过与其他同类算法的比较显示出算法的高效性和稳定性,特别是在大规模数据集上的有效性。
今后的工作将进一步挖掘局部搜索和基于种群的新型智能优化算法的有机融合,并扩展到更大的应用范围,例如多维KP、折扣KP等。
