基于改进VMD和自适应BSA优化LS-SVM的刀具磨损状态监测方法
2021-01-18蔡力钢李海波杨聪彬刘志峰赵永胜
蔡力钢,李海波,杨聪彬,刘志峰,赵永胜
(北京工业大学先进制造与智能技术研究所,北京 100124)
在机床进行实际加工时,刀具磨损会必然出现,而刀具磨损情况与加工精度、生产效率和人员安全都有直接关联.因此刀具状态智能监测技术在要求更高精度、更加智能化的生产加工过程中具有重要的意义.目前主要采用间接法对刀具状况进行监测,间接监测法的过程大致可分为信号采集和预处理、敏感特征提取、磨损模式识别3个部分[1].
刀具磨损过程影响因素十分复杂,与试件材料、刀具特性、机床状态以及加工工艺等诸多原因有关,很难找到能够反映刀具磨损规律的数学模型.加工过程中的振动信号与切削力和机床系统自身特性有很强的关联性,进而包含了大量与刀具实时磨损相关联的信息.综上所述,提取信号特征的优劣与刀具状态的监测有着直接联系.信号特征选择的常用方法有:时频域处理、小波分解(wavelet transform, WT)、经验模态分解(empirical mode decomposition, EMD)等.时域、频域分析是从时间和频率成分角度分析信号.WT和EMD对多分量、非平稳信号的处理更具有优势.文献[2]对车削过程的切削力信号基于小波变换建立了刀具状态在线监测和磨损预测系统.文献[3]对声发射信号采用经验模态分解并结合最小二乘支持向量机(least squares-support vector machine,LS-SVM)实现刀具磨损状态的监测.文献[4]提出了基于辅助噪声的改进EMD.变分模态分解(variational mode decomposition, VMD)是由Dragomiretskiy等[5]在2014年提出的一种非递归分解算法,具有坚实的理论基础.文献[6]基于VMD对风力序列进行分析并构建预测模型,证明采用VMD相对于EMD具有更好的预测效果.与EMD[3-4]的分解形式不同,VMD将原始信号中包含的不同的固有模态分量(intrinsic mode function, IMF)及其各自中心频率同时分解提取出来,实现各个IMF有效划分,避免了经验模态分解过程存在的频率混叠现象.基于上述优点,本文使用VMD进行信号特征提取.
VMD需要预先设定分解IMF数量K.目前选取参数K的方法有DFA(detrended fluctuation analysis)法[7]、中心频率法[8]、单尺度排列熵法[9]及进化算法参数寻优法[10].这些方法虽然能够得到相对不错的分解效果,但是却存在原理复杂、计算量过大等缺点.因此本文采用计算简单、效果明显的瞬时频率均值法进行K值的预先判定.
磨损状态识别方面,文献[11]说明人工神经网络技术已经大范围应用于监测和预测,但在实际应用中容易得到局部最小值并出现过拟合.LS-SVM能够很好实现具有小数量样本、高维度等特征问题的分类,所以被很多学者应用到机械故障检测和识别领域.文献[12]将声发射信号作为输入,并划分刀具磨损状态为3种,使用改进的多分类支持向量机(SVM)模型实现了刀具磨损多状态识别;文献[13]采用LS-SVM、Spider SVM、SVM-KM(SVM based on clustering by k-means)及ANN(artificial neural network)估计车削过程中AISI 304奥氏体不锈钢的表面粗糙度,实验结果显示所有SVM算法的预测正确率都要高于ANN模型.但LS-SVM的惩罚因子γ和核参数σ2组合与模型预测效果存在直接联系,所以优化选择LS-SVM模型的参数组合是决定该模型识别性能的关键.
针对LS-SVM模型的参数组合自动搜寻问题,文献[14]使用粒子群算法(particle swarm optimization,PSO)对LS-SVM模型的参数组合进行了寻优选择,并对铣刀磨损类型进行识别,通过与标准LS-SVM的识别结果对比,证明其具有识别精度更高、计算速度更快的优点;Pinar在文献[15]中首次提出回溯搜索算法(backtracking search algorithm, BSA),并将其与CLPSO、SADE等算法在CEC-2005、2011函数上的运行结果进行对比,证明BSA结构简明,且全局大范围搜索性能和适用性较强.文献[16]提出自适应控制参数的BSA,其可以自适应地调整变异的幅度参数F和交叉参数dimRate,具有更短的求解时间和更好的优化效果;BSA[15]的全局搜索性能较强但在优化后期存在局部小范围搜索性能较差、容易出现局部最优等缺点.文献[17]对BSA的选择Ⅰ、交叉、变异、初始化以及选择Ⅱ部分都进行了改进,在增强全局大范围搜索性能的基础上,改善了局部寻优能力.文献[18]提出了最优个体引导的BSA算法,在迭代前期,充分发挥其全局搜索能力;优化后期,由于BSA本身能够存储迭代历史经验,能够根据种群最优个体所携带的特征进行局部搜索,搜索得到更优解.
本文在上述研究的基础上,提出一种基于瞬时频率均值法的降噪型变分模态分解算法(modified VMD, MVMD)、自适应回溯搜索算法(adaptive BSA, ABSA)优化的LS-SVM刀具磨损模式识别方法.实验最终结果表明,在小样本数据的基础上,该方法能够剔除多余虚假特征并充分挖掘隐藏信息,实现了较高的识别精确度.
1 基于变分模态分解的特征提取
1.1 瞬时频率均值法确定VMD最佳参数K
参数K直接决定了信号经VMD处理后得到的IMF数量,为提取到更精确信号特征,需要根据实际信号确定K值.K值太小,会使各IMF包含的信息丢失或信号频率混叠;K值太大,会导致某个IMF被分解到多个IMF中,并影响算法运行效率.
假设某原始信号第a个IMF具有T个数据点,经计算其第d个数据点的瞬时频率为fad.使用VMD对某个原始信号进行预处理.分别计算K=2~10分解到的各IMF子信号经Hilbert变化得到的解析信号,再采用公式
(1)
求解各IMF分量瞬时频率的均值fa.式中m表示当前IMF中瞬时频率的总数.
在此基础上,分别绘制K=2~10时各IMF的瞬时频率均值变化趋势图.通过观察对比瞬时频率均值曲线首次出现明显弯曲特征时的K值,即可确定分解层数K的最优取值.
造成这种现象的原因是:分解的IMF数量过多,会使IMF模态分量不连续,由于这些突变产生的额外频率会相应地使得IMF瞬时频率的均值发生剧烈变化.只有当K取值适当时瞬时频率才会变化较为连续、平滑.
1.2 降噪变分模态分解算法
在使用瞬时频率均值法确定好最佳参数K的基础上,为进一步降低信号中包含的噪声,均布信号极值点,抑制模态混淆现象,并达到滤除多余或虚假信号特征的目的,本文采用一种基于VMD的噪声辅助方法,即MVMD算法[9].借鉴EMD改进算法[4]的策略,MVMD算法同样向原信号中分别加入幅度相同、正负相反的辅助噪声对,得到2个待分解的信号,然后再使用VMD算法对待分解信号分别处理,每次循环后待分解信号会生成2×K个IMF,经过N次循环一共得到2×K×N个IMF.然后对分解得到的{IMF1,…,IMFK}各层子信号进行集成和平均,将得到的均值结果相加组成重构信号,最后使用VMD对重构信号进行分解得到最终IMF集合.MVMD的信号重构过程见文献[9].重构过程中需要根据具体信号设置算法循环次数N和噪声幅值Nstd.文献[19]指出添加的白噪声幅度Nstd应为原始信号标准差Std的0.1~0.2倍.若Nstd取值过小,则无法达到平均极值点尺度的效果;若Nstd取值过大,虽然可以减少白噪声信号的干扰,但会增加计算负担.所以为均衡降噪效果和计算时间,幅值参数Nstd和循环次数N需要根据具体信号合理选择.
2 ABSA算法优化的LS-SVM
2.1 自适应回溯搜索算法
BSA是一种新颖的多种群搜索更新的优化算法,其整体可概括为初始化、选择Ⅰ、变异、交叉、选择Ⅱ共5个操作流程.虽然BSA具有适用性强、结构简单等诸多优点,但相对于自身较好的全局寻优性能,其局部小范围寻优性能较差,并且在优化的末期容易陷入局部最优却不能进一步优化.为达到进一步提高BSA的全局大范围搜寻性能,提高收敛速度以及增强局部搜寻性能的目的,本文在选择Ⅰ、变异、交叉部分对BSA进行改进.
历史种群具有存储先前迭代过种群的历史经验的功能.标准BSA的历史种群是在选择Ⅰ部分以整体更新的形式生成的.为进一步提高历史种群的丰富性,增加历史种群的搜索范围,本文将历史种群中的个体逐一更新,并最终完成整体的生成.
标准BSA的种群变异公式为
mutant=P+F×(oldP-P)
(2)
式中:P表示当前种群;oldP表示历史种群,搜索方向矩阵幅度系数F的值是固定不变的.为进一步提高变异的丰富性且避免因人工选择参数不当带来的影响,本文采用
(3)

为提高BSA在接近最优解时的局部搜索能力,并均衡合理利用全局和局部搜索性能.本文采用最优个体引导BSA[18]的思想,在算法优化过程的后期采用最优个体引导的算子构建变异种群mutantnew
mutantnew=P+Fnew×(Pbest-P)
(4)
该方法使算法放弃大范围搜索的方式,转为在得到最优适应度值的个体附近进行局部搜索.式中Pbest表示最优个体构成的种群.在式(2)~(4)的基础上,前期和后期分别使用式(2)和式(4),并且将前后期迭代次数的比例参数mark设置为0.75,即前期迭代数量:后期迭代数量=3∶1.
BSA的交叉部分由交叉概率参数mixrate控制实验种群中将要变异个体的元素数量.本文采用
mixrate=0.5×(1+rand(0,1))
(5)
同样进行参数mixrate的自动选择.
经过对BSA上述几部分的改进,不仅全局和局部搜索能力都得到了加强,并且两者在整个搜索进程获得充分合理的应用.另外算法中的参数也实现了自动选择,不需要人为干预,所以将该优化算法称之为自适应回溯搜索算法(adaptive BSA, ABSA).
2.2 自适应回溯搜索算法结合LS-SVM
本文提出运用ABSA优化算法以惩罚因子γ和核参数σ2为种群个体,在二维空间内进行迭代寻优,使模型具有更低的错误分类率.ABSA算法对LS-SVM模型进行参数自动选择进程中将错误分类率f作为目标适应度函数.
(6)
式中:n0为被错误分类的样本数;N0为样本总数量.
本文的目的是在小样本的前提下实现刀具磨损的快速在线监测,为充分利用有限的信号数据,又使模型具有较好的泛化能力并避免对验证数据过拟合,本文采用K折交叉验证法.基于瞬时频率均值法的MVMD和ABSA优化的LS-SVM刀具多种磨损状态识别算法的具体过程如下.
步骤1确定最佳参数K:利用瞬时频率均值法针对不同的振动信号确定最佳模态数K值.
步骤2信号分解:使用MVMD算法对信号进行重构,并将其最终分解为K个IMF.
步骤3优化提取特征:提取多种时域特征,经归一化后计算与刀具磨损量的相关性系数,并筛选对刀具磨损更加敏感的信号特征组成模型的优化输入数据集.
步骤4模型训练:将LS-SVM模型的参数γ和σ2组成BSA的个体,基于K折交叉验证原则训练ABSA优化的LS-SVM,并计算K次交叉验证后的适应度函数的均值f.
步骤5优化结束:本文设定优化结束的条件是优化达到设定的最大次数epoch,若满足条件则输出最优的参数γ和σ2的组合,若未达到结束条件则返回步骤4.
步骤6磨损状态识别:根据最优γ和σ2参数组合,建立LS-SVM刀具多种磨损状态分类识别算法,并对算法的性能进行检验.图1为刀具多种磨损状态的分类识别模型的流程示意图.
3 刀具磨损识别实验分析
3.1 实验描述
实验数据来源于2010年美国纽约预测与健康管理学会(Prognostic and Health Management Society) PHM2010刀具磨损比赛公开数据集.本文采用ISO标准规定的1/2背吃刀量位置的磨损宽度为刀具的实际磨损量VB.此次铣削实验采用的主要条件与设备如表1所示.
实验加工过程采集切削力、声发射信号以及机床进给方向X、主轴切向Y、主轴轴向Z方向的振动信号.振动和声发射紧贴在工件表面,工件置于测力仪上.试验进行端面铣削的工件为正方形,铣刀每次都沿着Y方向进行端面铣,每次加工的长度为108 mm,并记为一次走刀.为使刀具磨损尽可能连续,每次走刀结束后都测量并记录球头铣刀的后刀面磨损VB值.铣削试验在上述工况下使用6把相同的球头刀重复了6次实验,每次都进行315次走刀且单次试验过程中不换刀.本文选取第1次试验的X、Y、Z方向振动信号进行分析.为提高计算效率且避免每次走刀开始和结束时产生的多余振动的影响,本文采用每次走刀过程的第50 001~60 000共计10 000个数据点.
图2中横坐标为走刀次数,纵坐标为在X、Y、Z方向铣刀刃磨损和其均值的变化情况.观察这几种磨损值可以发现:刀具的磨损分为3个阶段,前期初步磨损阶段、中期正常磨损阶段以及末期快速失效阶段.其中前期和末期阶段刀具磨损较为迅速,其原因为:在前期刀具表面不平滑且可能存在氧化等问题,后刀面与试件相切面积较小,造成切削面处存在较大的应力,此阶段刀具磨损较迅速;末期磨损带宽度增加,刀具变钝,切削温度上升导致刀具的加速磨损.正常磨损阶段由于切削接触面变得平整润滑,接触面受到的应力较小,故而磨损速率降低.
基于图2的刀具磨损量的变化,人为地预先把磨损状态划分为5种,具体见表2.

图1 算法整体流程图Fig.1 Overall flow of the algorithm

表1 刀具磨损实验条件

图2 实验过程刀具磨损量变化曲线Fig.2 Tool wear curve during experiment

表2 刀具磨损状态划分标准
3.2 基于MVMD的信号特征提取
采用瞬时频率均值法确定每个方向的参数K.根据5种磨损状态的划分标准随机抽取X方向的若干次走刀的振动信号,采用瞬时频率均值法进行分析.通过观察这些走刀的信号对应的瞬时频率均值变化图,可以发现都是当K=5时其子图中曲线首次发生明显弯曲,说明X方向信号VMD的模态数参数K=4,所以采用K=4的MVMD对X方向的振动信号进行处理.图3表示的是其中的3次走刀信号情况,纵坐标为瞬时频率均值f,横坐标为分解得到的IMF的个数,若K=5,则原始信号分解为5个IMF,每个子图为各个IMF瞬时频率均值的变化情况(具体可见1.1节).基于上述相同方法确定Y方向信号的VMD参数K=2,Z方向信号的VMD参数K=4.
为提高信噪比,剔除多余或虚假信号,采用MVMD算法对各个方向的信号进行处理,得到降噪之后的重构信号.
MVMD算法需要确定幅值参数Nstd和循环次数N.表3~5为各方向不同走刀数据的重构信号信噪比对比结果.
结果表明:当循环次数N一定时,Nstd等于0.1倍Std时重构信号的信噪比最高,即降噪能力最好;当参数Nstd确定时,循环次数N越多,信噪比越高,但是计算时间增加并且降噪效果不明显.通过对3个方向不同走刀次数的信号数据进行相同的测试,计算结果都有相同的结论,证明本算法参数选取针对不同工况具有通用性.为兼顾计算效率和降噪效果,MVMD算法的循环次数N设定为100,幅值参数Nstd设定为0.1.
经计算X方向的信噪比均值在7 dB左右,Y和Z方向的SNR均值在10 dB左右,说明MVMD算法具有一定的降噪作用,降低了VMD算法对噪声的敏感性.
在重构信号基础上,使用VMD对其进行分解,由此得到表6所示的组成成分.
为进一步说明MVMD的降噪作用,图4、5分别为磨损前期和末期原始信号和重构信号的分解情况.图4中重构信号与原始信号曲线相比较,重构信号曲线“尖峰”更少且更加光滑,证明MVMD去除了一部分噪声信号;图4(b)中的IMF1和IMF2曲线相较于图4(a)中的曲线,明显更加光滑,而IMF3和IMF4曲线变化不大,说明在磨损前期低频信号IMF1、IMF2对总体信号影响更大.
图5(b)中重构信号曲线相较于图5(a)中原始信号曲线幅值更小,说明MVMD算法去除了部分噪声信号;图5(b)中IMF4曲线对比图(a)中IMF4曲线更加光滑,说明磨损后期高频信号IMF4对整体信号影响更大.图5中的高频信号相较于图4中的高频信号曲线振幅更大,说明磨损后期由于磨损程度加剧,振幅增大,噪声高频成分增多.
由于采集到的信号多是非平稳信号,直接对其分析,很难发现其与刀具磨损之间的联系,因此需要对初始信号数据进行处理,提取到与刀具磨损状态具有某种关联信号特征.研究表明一些时域特征可以用来表征刀具的磨损情况[20].表7中详细介绍了这些时域特征的数学计算公式.对X、Y、Z三方向经MVMD分解处理之后的IMF进行分析提取,一共可以提取得到27种信号特征.
此外,按照公式
(7)


图3 X方向第25、100、299次走刀数据瞬时频率均值Fig.3 Means of instantaneous frequencies of the 25th, 100th, and 299th feeding data in the X direction

表3 X方向第60次走刀数据不同参数下重构信号信噪比

表4 Y方向第80次走刀数据不同参数重构信号信噪比

表5 Z方向第250次走刀数据不同参数重构信号信噪比

表6 3方向信号组成成分
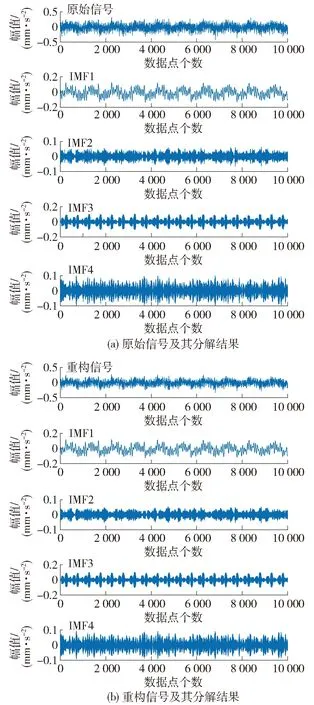
图4 Z方向第25次走刀原始信号、重构信号及其各自分解结果Fig.4 Original signal, reconstructed signal and their decomposition results of the 25th feeding in the Z direction

图5 Z方向第280次走刀原始信号、重构信号及其各自分解结果Fig.5 Original signal, reconstructed signal and their decomposition results of the 280th feeding in the Z direction
图6显示的是随机选择的5次走刀的IMF能量比随走刀次数的变化情况.图6显示随机选择的IMF子信号能量比分布随着磨损程度的改变也发生相同或相反趋势的变化,因此可以将其作为初步输入特征的一部分.另外,提取得到的信号特征中存在一些多余特征和相关性较差特征,会增大后续模型的复杂程度且增大计算时间.本文采用皮尔逊相关系数法以确定各信号特征与铣刀磨损量的关联程度[21].为消除信号特征之间不同数量级之间的影响,在进行相关性分析之前,需要首先对所有的信号特征量进行归一化处理,使得所有特征量分布在[-1,1]之间.
皮尔逊相关系数|ρ|>0.7表示该特征对刀具的磨损状态更加敏感,两者之间的相关程度也更高,所以筛选|ρ|>0.7的特征组成刀具多种磨损状态识别模型的输入特征向量.如图7所示,X方向有10个敏感特征,Y方向有7个敏感特征,Z方向有13个敏感特征.为说明MVMD算法具有剔除多余或虚假信号特征的性能,使用VMD对原始信号进行分解、提取信号特征并计算相关性系数,最终得到皮尔逊相关系数|ρ|>0.7的信号特征有36个,说明使用降噪型变分模态分解算法MVMD在有效降噪的同时,可以有效剔除多余或虚假特征.
3.3 模型识别效果验证
本次测试所使用的实验数据按照刀具磨损测量结果将走刀数据划分为5个磨损状态.对每种磨损状态按照4∶1的比例随机选择信号数据,分别组建分类识别模型的训练集和测试集.对于多分类模型的输出,需要对每种状态对应的输出标签进行编码,目前较为常用的编码方式有MOC、ECOC、1vs1、1vsA.经过多次分析比较,编码方式对模型误分类结果影响不大,本文选用运算速度较快的MOC.
本文ABSA优化算法设定的最大寻优次数epoch为100,种群包含个体为30,核参数γ和σ2的选取区间是[0.01,1 000],利用5折交叉验证的方式.为证明本文所选模型的优越性,在前述参数相同的情况下,与标准BSA优化的LS-SVM和PSO优化的LS-SVM模型进行对比.其中BSA的参数mixrate预设为1,PSO算法的学习因子c1=c2=1.
图8为采用ABSA、BSA以及PSO算法优化的LS-SVM模型每次迭代后的5次交叉验证后适应度平均值变化情况.

表7 时域特征的数学表达形式

表8 三方向信号能量比特征
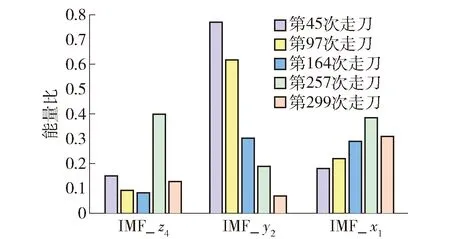
图6 IMFx1 、IMFy2、IMFz4能量比随走刀次数的变化情况Fig.6 Distribution of energy ratio with feeding times of IMFx1,IMFy2, and IMFz4

图7 优选信号特征的相关系数Fig.7 Correlation coefficient of the optimized signal characteristics

图8 ABSA-LSSVM、BSA-LSSVM、PSO-LSSVM模型迭代过程适应度值Fig.8 Fitness values of iteration process using ABSA-LSSVM, BSA-LSSVM and PSO-LSSVM models
由图8曲线的变化趋势可以看出,在寻优过程的0~70次中,ABSA-LSSVM适应度值发生了多次变化,说明ABSA优化算法找到了多种核参数的组合,并且使得适应度呈递减的变化趋势,证明该ABSA算法具有很强的搜索能力,能够在二维区间内实现尽可能全面的探索.另外迭代在开始很少的迭代范围内就降到了很低的数值,说明具有很快的收敛能力.在迭代过程的70~100次范围内,在最优个体引导算子的局部搜索能力的作用下,适应度值进一步降低到0.02.
对比BSA-LSSVM和PSO-LSSVM适应度曲线,发现BSA-LSSVM曲线出现了较多的下降沿,说明BSA相对于PSO搜索到的参数组合更丰富,证明BSA搜索能力更强.ABSA-LSSVM相比BSA-LSSVM不仅在迭代前期具有更多的下降沿,而且在迭代后期适应度值进一步降低,说明ABSA具有较强的全局大范围探索和局部小范围寻优的性能,避免了陷入局部最优的情况.
为避免迭代过程产生的结果可能具有随机性,将测试重复10次,表9为ABSA-LSSVM测试结果.
表9数据结果显示,ABSA优化的LS-SVM刀具多种磨损状态识别模型对测试数据集的错误识别率在1%~3%,10次测试的均值为1.67%.模型对测试集的最佳误分类率的最低值为0.

表9 ABSA优化LS-SVM最终结果

图9 ABSA优化的LS-SVM模型分类预测结果Fig.9 Classification and prediction results of LS-SVM model optimized by ABSA
图9为使用(157.293,1.368 8)组合参数的分类模型对测试集的预测分类情况.分类预测结果显示,模型对于随机抽取的测试数据集的5种磨损情况的预测只出现2次错误分类.
表10、11分别为BSA-LSSVM和PSO-LSSVM重复进行10次测试的结果.由表8可知BSA优化的LS-SVM虽然对训练集具有较低的误分类率,但是对测试集10次测试的平均误分类率均值却是3.87%;而PSO优化的LS-SVM进行10次测试的平均误分类率均值是5.59%,且具有更高的最佳误分类率.

表10 BSA优化LS-SVM最终结果
将使用标准VMD算法分解、提取和优化得到的36个信号特征同样按照4∶1的比例组建数据集,并使用ABSA-LSSVM模型进行测试,得到的最终结果见表12.结果显示虽然相较于MVMD结合ABSA优化的LSSVM使用了更多的特征,但是使用标准VMD结合ABSA优化的LSSVM的测试平均误分类率更高,并且计算时间也有所延长.说明使用降噪型MVMD算法在降低噪声的同时,提取到数量更少,更能准确表达刀具磨损信息的信号特征.
表13为采用结构为30×10×5的BP神经网络的识别结果.其隐含层传递函数为tansig(),输出层传递函数为purelin().最大训练补数为20 000,性能参数为0.02.测试结果显示,BP神经网络对刀具磨损状态的错误识别率在5%~11%,相较于ABSA-LSSVM模型的识别效果有较大差距.虽然ABSA-LSSVM模型的核参数迭代优化过程所需要的时间比BP神经网络要多,但ABSA-LSSVM模型的核参数确定后,其针对测试数据的模型训练时间均值为0.8 s,且具有非常高的识别准确度.

表11 PSO优化LS-SVM最终结果
另外,根据BP神经网络模型的建立过程可知,其不同的网络结构之间具有明显的差异,且不同的神经网络可使用的具体情况也不尽相同.LS-SVM模型核函数的选择对于分类器的识别精度没有太大的影响[14],说明LS-SVM模型具有更普遍的适用性.

表13 BP神经网络测试最终结果
4 结论
本文提出了一种采用基于瞬时频率均值法的降噪型变分模态分解算法对振动信号进行重构和分解,对分解得到的子信号提取特征并结合相关性分析对输入特征进行优化,最后采用ABSA自适应回溯搜索算法对LS-SVM模型的参数组合自动寻优,达到了刀具多种磨损状态的分类检测和识别的目的,并且取得不错的正确识别率.经试验数据的结果表明:
1) 使用瞬时频率均值法可以针对加工过程中特定信号预先确定变分模态分解算法的最佳分解模态数,且不需要大量复杂计算.
2) 采用降噪型变分模态分解方法对信号进行分解并应用到刀具磨损状态的识别是可行的.使用降噪型变分模态分解,不仅具有一定的降噪作用,避免出现模态混叠现象,也可以剔除多余或虚假信号特征,在不影响最终识别效果的前提下,提高了识别模型的运行效率.
3) 采用自适应回溯搜索算法ABSA对LS-SVM模型进行参数寻优,经过测试结果证明:该优化算法不仅不需要预先设定任何参数,并且还具有更强的全局探索和局部寻优能力.
4) 以降噪型变分模态分解方法为核心的信号处理方法和ABSA算法优化的LS-SVM相结合的刀具多种磨损状态的分类识别模型,针对小样本数据具有较高的识别准确性,在此基础上能够实现刀具磨损状态的在线快速识别.
