任务驱动法在医学数据挖掘中的应用
——以帕金森综合征的预测为例
2021-01-11肖伟昌聂小英
余 维 肖伟昌 聂小英 彭 微
(湖北科技学院 湖北·咸宁 437100)
0 引言
目前,很多高校结合自己的优势进行转型发展,其中不乏向应用型进行转型,更加注重培养应用型人才。针对理工多学科交叉专业,比如医学信息工程专业的专业课教学,传统的理论教学面临重大的挑战。传统的理论教学往往是学生被动填鸭式的接受知识,虽然能让学生学到很多理论知识,但是在解决实际问题时十分茫然,不能做到举一反三。因此有必要以任务驱动为导向,在结合案例教学的基础上增加学生的主动性,将教师与学生的角色互换,充分发挥学生的主观能动性,让学生享受学习的过程,在提高学习成效的同时提高理论与实践应用的能力。
目前,人口老年化一直呈现出上升趋势,而帕金森综合征是一种常见的神经系统退行性疾病,常见于老年人。发病平均年龄约为60岁,帕金森病在40岁以下的年轻人中很少见。大多数帕金森病患者是散发性的,只有不到10%的人有家族病史。
本文从加州大学欧文分校(UCI)的机器学习库①中的帕金森综合征数据集入手,对其数据进行分析并构建一个帕金森综合征预测模型,以供决策者提高诊断效率及准确率。根据所要解决的问题,按照数据挖掘的流程,本文所得到预测帕金森综合征的分类模型是通过数据获取、数据预处理、挖掘建模、模型评估等几个阶段完成的。通过对理论与实践操作,学生能对数据挖掘过程中的每个阶段有更深刻的认识。
1 数据挖掘过程
1.1 数据获取
本文选取的公开数据集来自伊斯坦布尔大学医学院神经内科188例帕金森综合征患者(男性107例,女性81例),年龄从33岁到87岁不等(65.1±10.9)岁。对照组为64例健康人(男23例,女41例),年龄41-82岁(61.1±8.9)岁。在数据收集过程中,麦克风设置为44.1kHz,并根据医生的检查,从每个受试者中收集元音/a/的持续发音,并进行三次重复(见表1)。

表1:帕金森病分类数据集
1.2 数据预处理
对于庞大的数据量,原始数据集中的数据或多或少是存在质量下降的现象,直接利用该数据进行数据挖掘,不仅会增加挖掘工作的难度,还会影响挖掘效果的准确性。为了减轻影响数据挖掘的多种因素,提高用来挖掘的数据质量,通常获取数据后需对数据集进行预处理,以使混乱无序的数据变为容易分析处理的数据。对获取的数据进行预处理步骤通常包括数据清洗、数据集成、数据变换、数据精简等。
1.3 算法建模
要解决的问题是通过对帕金森综合征数据集进行数据挖掘,分类得到能有效判断罹患帕金森综合征的预测模型。基于python的第三方工具库中,sklearn作为机器学习领域知名的模块之一,包含了很多重要的数据挖掘算法。鉴于此,考虑选用两种常用分类算法(如KNN算法和决策树算法)对帕金森综合征数据集进行分析预测,并在python语言编程环境下结合sklearn库进行建模②。
1.3.1 决策树算法建模
将采集到的188例帕金森综合征患者数据分成两部分:一部分作为训练集,用来构建模型;另一部分作为测试集,用来评估模型的准确性。利用sklearn库中的train_test_split生成训练集和测试集,利用sklearn库中的Decision Tree Classifier生成决策树,得到决策树模型的核心代码如下:

1.3.2 KNN算法建模
与上述决策树算法建模操作相似,将188例帕金森综合征患者数据集分成训练集和测试集,利用sklearn库中的train_test_split生成训练集和测试集,利用sklearn的KNeighbors-Classifier方法对KNN算法进行建模,得到KNN算法模型的核心代码如下:

1.4 模型评估
利用1.3节对188例帕金森综合征患者数据集分离出的训练集生成出对应的决策树算法模型和KNN算法模型后,用相应的测试集对生成的两种模型进行精确度评估。通过验证,得到两种不同模型的预测精度。
1.4.1 决策树算法模型评估
利用predict对测试数据集x_test进行预测,y_predict为预测结果,借助y_test,利用sklearn库中的metrics.confusion_matrix生成混淆矩阵结果并对y_predict进行分析,核心代码如下:

结果见表2决策树算法模型混淆矩阵表。通过表2所示的混淆矩阵,计算出模型的准确率和错误率见表4。

表2:决策树算法模型混淆矩阵表
1.4.2 KNN算法模型评估
与1.4.1节类似,通过测试集对模型进行预测,并对预测结果进行分析,核心代码如下:
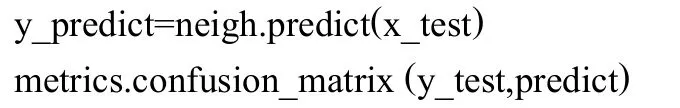
结果见表3 KNN算法模型混淆矩阵表。通过表3所示的混淆矩阵,计算出模型的准确率和错误率见表4。
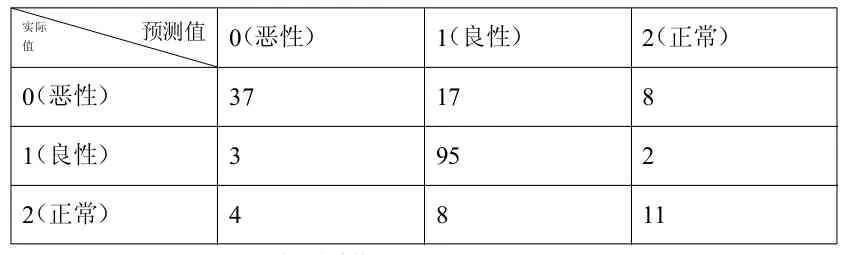
表3:KNN算法模型混淆矩阵表
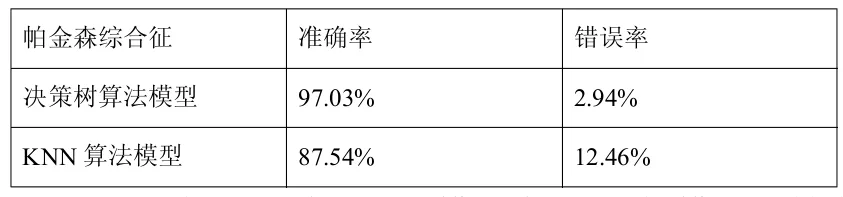
表4:算法模型准确率和错误率
由表4能看出,两种不同的模型中,决策树模型对帕金森综合征的预测更加准确。
2 小结
通过对公开的帕金森综合征数据集入手,对目标任务进行分析,构建一个帕金森综合征预测模型。针对该分类问题,本文利用python编程环境和相关工具库完成了帕金森综合征数据挖掘,包括数据获取、数据预处理、算法建模与模型评估等四个阶段。利用机器学习领域著名的 sklearn库实现了决策树算法模型和KNN算法模型,并对188例帕金森综合征数据集分离出的测试集进行模型评估。通过对比决策树模型和KNN模型的精确度,能够得出决策树算法在帕金森综合征数据挖掘上的应用优于KNN算法的结果。与单纯理论教学相比,课堂学习中,将实践与理论结合,使学生在学习理论的同时加强编程的练习,能有效提高学生理解并掌握所学的数据挖掘方法在临床工作中的应用。
注释
① http://archive.ics.uci.edu/ml/index.php
② https://scikit-learn.org/stable/
