特征增强的小目标检测算法
2020-12-31杨建秀刘桂枝
杨建秀,刘桂枝
(山西大同大学物理与电子科学学院,山西大同 037009)
目标检测是图像处理和计算机视觉领域的基础性算法,对后续的实例分割、人脸识别、姿态估计等任务起着关键的作用。但在实际的应用场景中,由于受成像条件及成像距离等限制,所成影像大多数面临目标区域小、背景干扰强的缺陷,给这些弱小目标的检测增加了难度。针对弱小目标的检测,传统的算法首先利用滑动窗口的策略对整幅图像遍历对小目标进行人工设计的特征提取[1];然后根据提取到的特征对小目标进行分类[2-3];深度学习的算法利用卷积神经网络(Convolutional Neural Network,CNN)对小目标进行特征提取实现端到端的分类回归任务并获得较好的效果。
基于深度卷积神经网络的目标检测算法,如经典的两阶段方法Faster-rcnn[4]和R-FCN[5],单阶段方法YOLO[6]和SSD[7]等,主要是针对通用的目标数据集设计的解决方案,对图像中的小目标的检测效果不是很理想。目前基于CNN 的小目标检测算法如建立图像金字塔,即利用不同尺度的图像生成对应不同尺度的特征,这种方法增加时间成本。为了同时提高小目标的检测精度和速度,最近一些算法如FPN[8],DSSD[9]和FAN[10],利用自顶向下结构为小目标提供上下文信息,来提升浅层中小目标的语义表达能力。但是较小的目标很容易在更深的卷积层中丢失,所以语义信息也会随之丢失。这样仅仅依靠上下文信息增强小目标特征是不够的,本文提出一种特征增强的小目标检测算法。该算法将含有准确空间位置信息的浅层特征和含有抽象语义信息的深层特征进行融合来提高小目标特征表达能力,这样为预测层中的小目标既提供了空间位置信息,又增强了语义信息,为解决弱小目标的识别检测问题提供一条新思路。
1 特征增强的小目标检测算法
1.1 网络结构
小目标检测算法是在单阶段精细神经网络结构RefineDet[11]上实现的,整体结构共分为三部分,默认框细化模块(Anchor Refined Module,ARM),特征增强模块(Feature Enhancement Module,FEM),以及目标检测模块(Object Detection Module,ODM),整体的网络结构设计如图1 所示。其中,ARM 模块主要实现二分类任务,并对前景小目标的位置实现初步预测定位,为后面的多类目标检测模块ODM 提供较好的候选框回归初始值。多类目标检测模块ODM 把默认框细化模块ARM 优化后的候选框作为输入,专注多分类任务和进一步的边框校正。本文利用FEM 模块将ARM 模块和ODM 模块连接起来实现了小目标的精确定位。
首先利用VGG16 作为卷积特征提取的主干,相比于RefineDet,只保留了Conv1_1到Conv_fc7的卷积层,移除了Conv_fc7 之后较深的卷积特征层,因为较深的卷积层有较大的感受野,不利于小目标的精确定位。然后根据斯坦福无人机数据集中小目标尺寸分布选择Conv4_3 和Conv5_3 两个不同的浅层特征层用于小目标物体的检测。最后,将ODM 模块中的P4和P5作为最后的预测层。
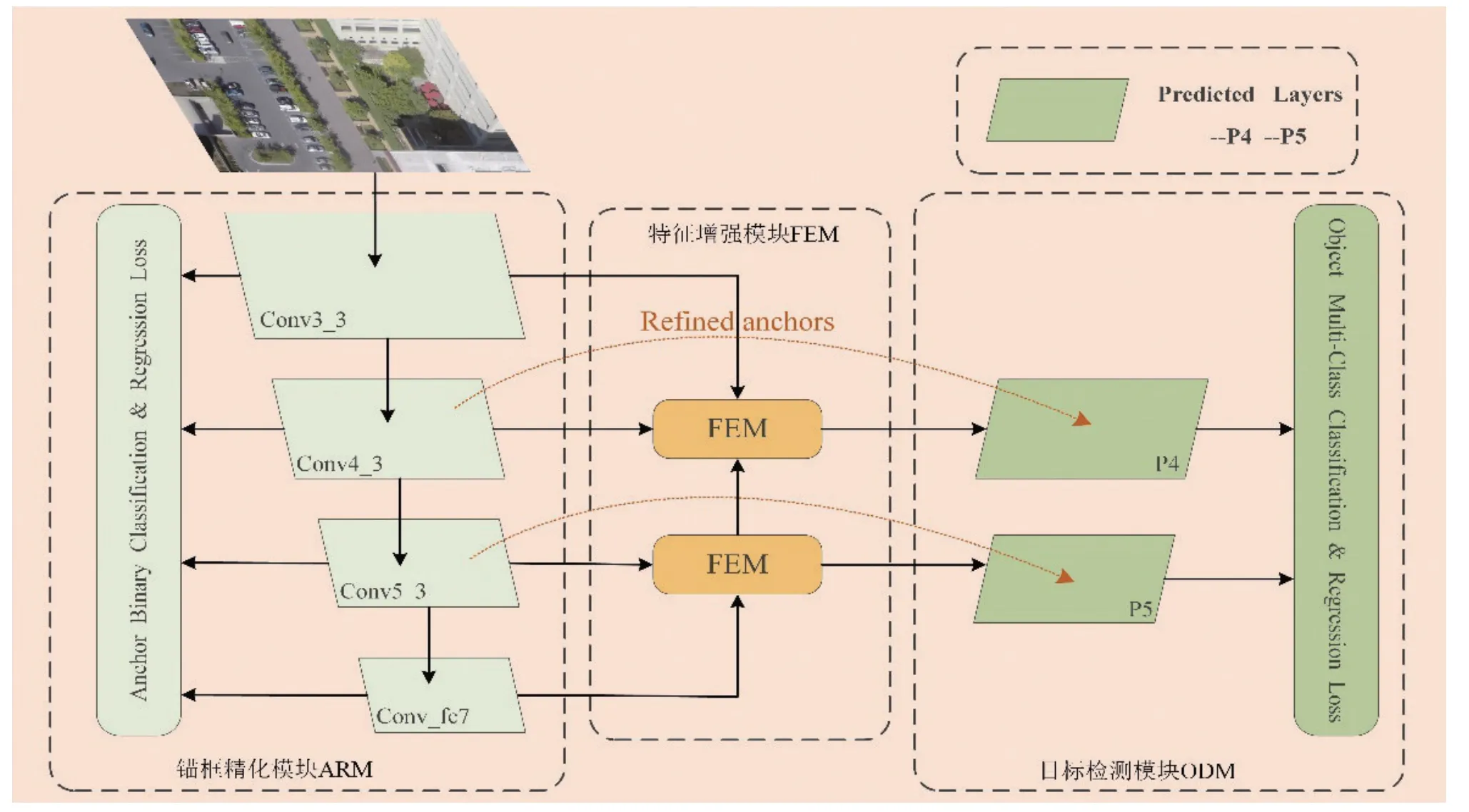
图1 配合物的分子结构图
1.2 特征增强模块
FEM(Feature Enhancement Module)模块结合相邻三层特征构成一个多尺度特征金字塔,为小目标既提供了浅层的空间位置信息,又保证了深层上下文信息的供给,从而增强了小目标的语义信息。FEM模块与单阶段精细神经网络结构RefineDet 中自顶向下的传输连接模块(Transfer Connection Block,TCB)不同。传输连接模块TCB 仅仅给小目标提供了上下文信息,而更深卷积层的上下文信息会伴随大量的背景干扰,造成小目标的检测性能下降。本文提出的FEM 模块为小目标提供合适的上下文信息,不会引入太多的背景干扰,因为FEM 仅利用一层或两层包含上下文的深层语义信息;同时,FEM 模块还融合了具有准确空间位置信息的浅层特征。因此FEM 模块为小目标提供了增强的特征表示,提高小目标的判别能力,其结构图如图2所示。
为确保当前特征层能够与相邻浅层特征和深层特征三层特征进行点对点相加(Eltw sum),采用下采样操作将浅层特征Fn-1的尺度缩小到与当前特征层Fn的尺度相同,同时深层特征Fn+1利用反卷积操作将其尺度扩大到与Fn相同。Fn+1和Fn-1分别经过一个2×2 的反卷积操作和3×3 的池化操作进行特征学习得到,其最后通道维数都是256;同时将当前层特征图Fn经过一个3×3 的卷积操作以及激活函数得到通道维数为256的特征;然后利用点对点相加操作将完成相邻三层特征的结合,最后再经过一个3×3的卷积层进一步整合特征得到预测层,使其预测层的特征既有浅层的空间位置信息又包含深层语义特征,提高小目标的判别表示,如图2所示。
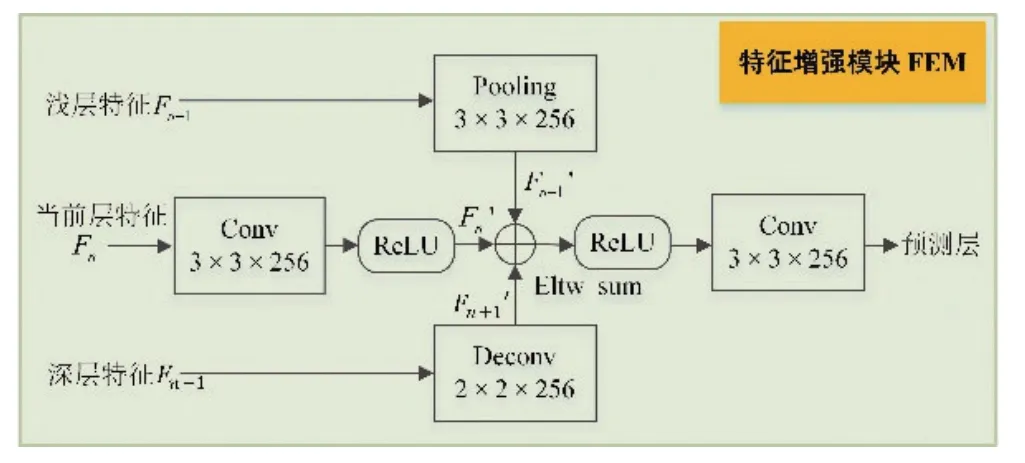
图2 特征增强模块(FEM)
2 实验结果与分析
2.1 实验环境
利用斯坦福无人机数据集作为小目标检测的实验数据,训练样本和测试样本分别为3,500 张和831张图像。其中三类目标小汽车、公交车和高尔夫球车作为人工标注图像的训练数据集。本文采用平均检测准确率(Average Precision,AP)和平均准确率均值(mean Average Precision,mAP)作为小目标检测性能的评判准则。
把图像分类网络VGG ISSVRC[12]训练的权重用于网络的初始值,输入图像大小为320×320,训练图像中每批次的数量为16。其中训练所用初始学习率为0.001,训练次数共为120 k次,在80 k次和100 k次时学习率降为0.0001和0.00001。实验的硬件环境为NVIDIA GTX-1080 GPU,软件环境为Ubuntu16.04 操作系统下的Caffe 深度学习框架[13],其中所用CUDA版本为8.0,cuDNN版本为6.0。
2.2 实验结果分析
移除了RefineDet 中Conv_fc7 之后的卷积层,利用自顶向下的结构为小目标提供合适的上下文信息,避免太大的感受野引入较多的背景干扰;同时,为了进一步增强小目标的特征,将浅层的空间位置信息融合到预测层中。通过设计特征增强模块FEM,使得提出的小目标测算法能够达到89.1%的准确率。如表1所示,相比于深度学习算法中的单阶段实时检测算法和两阶段高性能算法,本文所提出的方法可以达到较好的检测性能[14-15]。从图3 可知,特征增强的小目标检测算法对小目标在存在遮挡等复杂环境下具有良好的检测性能。
3 结论
针对小目标判别性不足的问题,在浅层获取准确的空间位置信息和足够的语义信息是增强小目标判别性的关键,因此本文提出一种特征增强的小目标检测算法。将含有准确空间位置信息的浅层特征和含有抽象语义信息的深层特征进行融合来提高小目标特征表达能力,这样为浅层中的小目标既提供了空间位置信息,又增强了语义信息,因此这种算法可以较好解决处于遮挡、阴影干扰等复杂环境下小目标定位问题,为中高级计算机视觉问题提供良好的预处理手段。
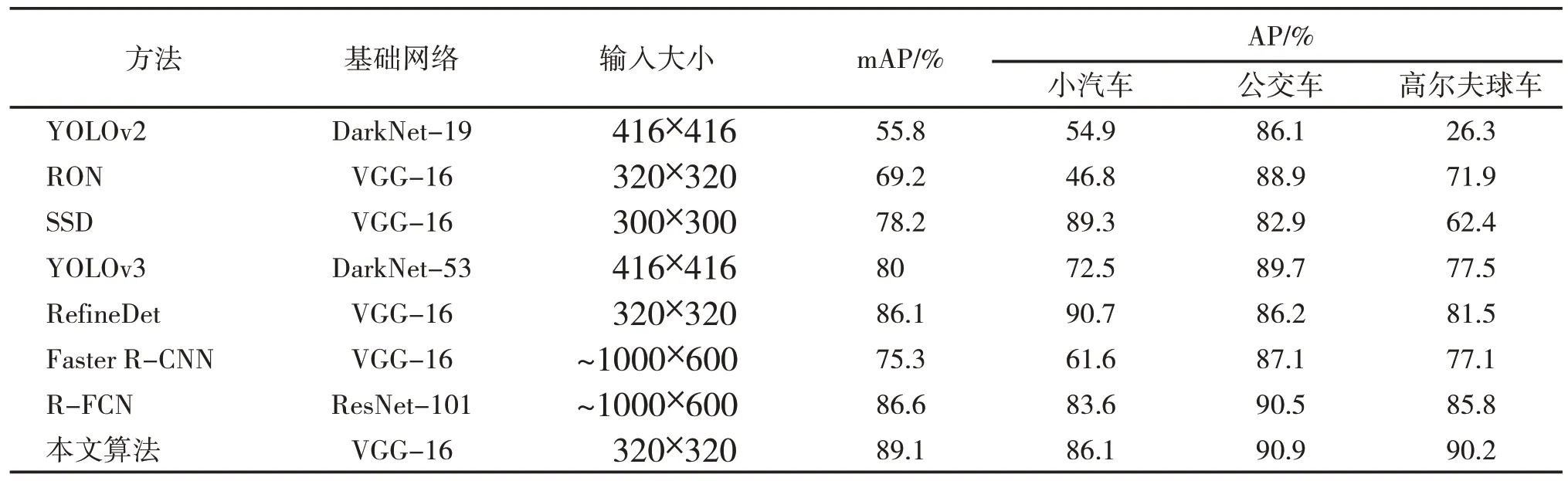
表1 斯坦福无人机数据集在不同目标检测算法中准确率的实验结果对比

图3 小目标在复杂场景下识别定位的实验结果图
