BP神经网络和多元线性回归模型对碳排放预测的比较
2020-12-09赵金元唐海亮
赵金元, 马 振, 唐海亮
(北京瑞太智联技术有限公司, 北京 100102)
经济飞速发展的同时,对于能源的消耗不断增加,造成二氧化碳等温室气体大量排放,使得大气中的二氧化碳浓度急剧增加,远超大自然的吸收能力,使得全球气候变暖,并逐步发展成一个日益严峻的环境问题[1]。目前国内外针对温室气体的研究主要集中于减排技术,通过建立大量的减排评价模型来研究在各个层面对经济领域的影响,且主要着重于对国家或区域层面的研究。而针对微观层面,尤其是钢铁企业,对其碳排放量的预测分析的研究更少,作为一个高耗能、高排放的企业,预测其生产过程中产生的碳排放量对国家减排目标的实现具有重要意义。构建企业碳排放预测模型,有助于企业了解自身碳排放情况,利于企业积极主动减少碳排放,打造绿色低碳循环经济。
由能源环境污染引起的“温室效应”已使能源碳排放成为社会各界关注的焦点,能耗所产生的环境污染问题也越来越严重[2]。准确对企业碳排放进行预测是科学制定和完善政策措施的前提,采用合理的模型对钢铁企业碳排放量进行预测,对于制定与完善相关碳减排政策和措施具有重要意义[3]。也可以为我国大气环境治理及区域可持续发展提供决策支持[4]。
不同学者从不同角度入手,寻找新的方法建立不同的预测模型,不断探索与收集对碳排放影响程度最高的指标与数据,并不断对预测方法进行创新和完善,致力于促进碳排放预测模型的发展。宋杰鲲和张宇[5]在STRIPAT模型的基础上,运用BP神经网络方法对2010-2015年我国碳排放进行预测。张发明和王艳旭[6]利用系统聚类对世界碳排放指标进行筛选,运用BP神经网络对世界碳排放量进行预测,为碳排放预测提供了一种新的可供借鉴的方法。於慧琳和肖铭哲[7]提出一种基于灰色神经网络模型的企业碳排放峰值预测模型,进行企业碳排放峰值的预测,帮助企业了解自身碳排放情况,并设计碳排放的减排路径。马彩云等[8]以2008-2016年安徽省建筑业直接碳排放量作为样本基础,采用灰色预测模型对安徽建筑业2017-2021年的直接碳排放量进行预测,发现其碳排放量呈上升趋势。利用灰色关联分析原理[9]研究发现BP神经网络模型能很够好地运用于中国碳排放的预测。提出一种整体自适应神经模糊推理系统,以学习预测和分析可再生能源消耗、经济增长和二氧化碳之间的关系,并进行碳排放的预测[10]。使用向量自回归模型来分析企业二氧化碳排放量变化的影响因素,确定二氧化碳排放的主要驱动力[11]。基于情景分析的应用,动态预测2030年中国PRCI的二氧化碳排放量,为中国实现减排目标提供了参考[12]。Jie Hu等[13]针对铁矿石烧结,开发了基于实际运行数据的集成预测模型,实现了碳排放的高精度预测,为实际烧结过程中的节能降耗提供了有效的解决方案。Lu Can, Li Wei和Gao Shu bin[14]采用粒子群优化算法优化的BP神经网络模型来预测重化工行业的碳排量。
BP神经网络和多元线性回归模型均可用于碳排放预测研究,但很难详细区别两者的碳排放预测精度,且碳排放数据有限,无法获取大样本而不能对碳排放做出精确的预测,根据小样本数据进行预测就成为一个亟待解决的问题。本文分别建立BP神经网络和多元线性回归模型对钢铁企业碳排放进行预测分析,通过对神经网络仿真值和回归方程模拟值进行比较,以期找到一种精确、实用的碳排放预测模型,为工业化生产提供参考依据,致力于帮助企业做好提前的碳排放预测,掌握自身排放情况,能够更有效的实施温室气体减排,将企业的碳排量控制在国家政策允许的范围内。
1 方法原理
1.1 BP神经网络模型
BP神经网络是一种按照误差逆向传播算法训练的多层前馈网络,其原理是输入学习样本,通过反向传播算法对网络的偏差和权值进行反复的调整训练,使最终得到的输出值尽可能与期望值相接近。
BP神经网络模型具有三层或更多层的神经网络,每一层都由若干个神经组成,采用最速下降法,通过反向传播来不断调整网格的权值和阈值,使网络的误差平方和最小。通过这种过程不断迭代,最后使得信号误差达到允许的范围内。BP神经网络模型拓扑结构包括输入层、隐层和输出层,其拓扑结构如图1所示。
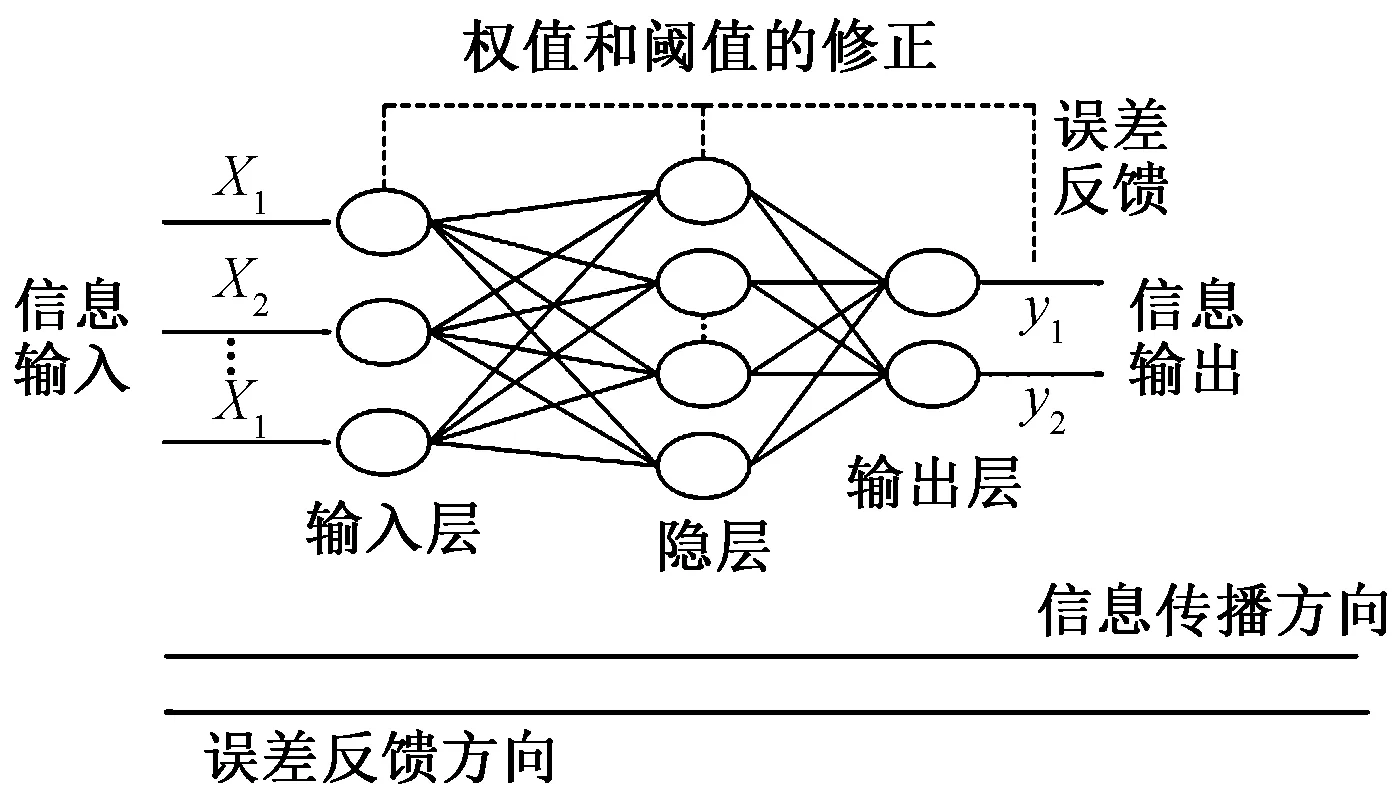
图1 BP神经网络的拓扑结构
1.2 多元线性回归模型
线性回归分析是描述一个因变量Y与一个或多个自变量X之间的线性依存关系,用一定的线性拟合因变量和自变量的关系,确定模型参数来得到回归方程,并用回归方程预测因变量的变化趋势,运用回归分析方法能够建立反映具体数量关系的数学模型,即回归模型。
一种现象通常是与多个因素相联系的,由多个变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际,自变量主要由实际影响因素决定数量,方程如下所示:
Yhat=β0+β1X1+β2X2+…+βnXn+e
(1)
上式中:n是解释变量的个数;βi是常数项;β1~βn为回归系数;e是误差项的随机变量值,是去除n个自变量对Yhat影响后的随机误差。
采用最小二乘法对上式中的待估回归系数β0,β1,…,βn进行估计,求得β值,便可利用多元线性回归模型进行预测。
2 碳排放影响因素的确定
2.1 碳排放核算方法
本文主要针对某一钢铁企业进行碳排放的预测,由于缺少大样本数据的支撑,可用于碳排放预测的数据较少。碳排放预测模型的预测精度受其影响因素选取的影响,通过分析碳排放计算方法,来确定与碳排放关系密切的影响因素,选用最直接的数据量来建立更为准确的预测模型。
采用排放因子来进行碳排放量的计算,排放因子法是由 IPCC(联合国气候变化政府间专家委员会)提出的一种碳排放估算方法,其计算公式为[15]:
E=AD×EF
(2)
上式中:E是温室气体排放量;AD是活动数据,具体指单个排放源的具体使用总量;EF是排放因子,单位排放源使用量所释放的温室气体数量。
某企业的碳排放总量等于企业边界内所有的化石燃料燃烧排放量、工业生产过程排放量及企业净购入电力和净购入热力隐含产生的碳 排放量之和,还应扣除固碳产品隐含的排放量:
EC=E燃烧+E过程+E电-R固碳产品
(3)
上式中:EC为企业碳排放总量;E燃烧为企业所有净消耗化石燃烧活动产生的碳排放量;E过程为企业工业生产过程中产生的碳排放量;E电为企业净购入电力和净购入热力产生的碳排放量;R固碳产品为企业固碳产品隐含的碳排放量。
2.2 碳排放影响因素
选取与碳排放关系密切的因素,借助于模型来进行预测,可提高预测精度和实用性。根据碳排放因子计算企业碳排,企业会使用焦炭和电极糊,也会使用半焦、焦沫等来替代焦炭的使用,其计算公式为:
E燃烧=AD焦炭×EF焦炭+AD半焦×EF半焦+AD焦沫×EF焦沫+AD电极糊×EF电极糊
(4)
在生产过程中需要白云石作为溶剂,其产生的碳排放量为:
E过程=AD白云石×EF白云石
(5)
计算使用电量时需除去由企业自身发电而产生的用量,即:
E净购入电=AD净购入电×EF电
(6)
在实际生产运行中,除了关键的生产要素外,还有一些使用量较小的替代的能源物质,但由于物质的种类并不确定,且排放因子也不确定,不适合当作预测模型中的影响因素。因此考虑使用电量、焦炭使用量、电极糊使用量、白云石使用量和固碳产品产量作为企业碳排放预测的影响因素。
3 预测分析
3.1 现场数据
根据某钢铁企业数据汇总表和几何碳排放核算方法,采用主成分分析的方法,最终选用使用电量、焦炭使用量、电极糊使用量、白云石使用量作为钢铁企业碳排放量预测的影响因素,借此分析各能源用量与碳排放量之间的关系。选用以下26组经过预处理的现场数据,其中产量、焦炭、电量、电极糊、白云石使用量为输入数据,碳排放量为输出数据,如表1所示。

表1 现场数据
根据企业提供的现场数据,将BP神经网络模型和多元线性回归分析模型应用到企业碳排放预测中。
3.2 BP神经网络模型
致力于帮助钢铁企业做好碳排放预测,掌握自身排放情况,能够更有效的实施温室气体减排。以产量、焦炭使用量、电量、电极糊使用量和白云石使用量为输入参数,碳排放量为输出参数,采用BP神经网络模型对钢铁企业碳排放进行预测。
利用训练好的神经网络模型对试验结果进行预测,表2为预测模型准确度测试数据汇总。
通过对筛选过的训练数据进行整体模型的训练,训练完的神经网络模型,再使用测试数据进行测试修正。
训练完成后的神经网络模型,通过7组测试数据得到的碳排放预测结果如表3所示。

表2 预测模型准确度数据汇总

表3 BP神经网络模型预测结果
从表3中可以看出,经过BP神经网络模型得到的碳排放量预测值的相对误差值均小于5%、平均相对误差值为2.24%,表明BP神经网络模型在当前数据的情况下,对钢铁企业的碳排放预测有相对较高的拟合程度。
3.3 多元线性回归模型
致力于帮助钢铁企业做好碳排放预测,掌握自身碳排放情况,能够更有效的实施温室气体减排。以产量、焦炭使用量、电量、电极糊使用量和白云石使用量为输入参数,碳排放量为输出参数,采用多元线性回归模型对钢铁企业碳排放进行预测。表4是使用多元线性回归模型得到的碳排放预测结果。
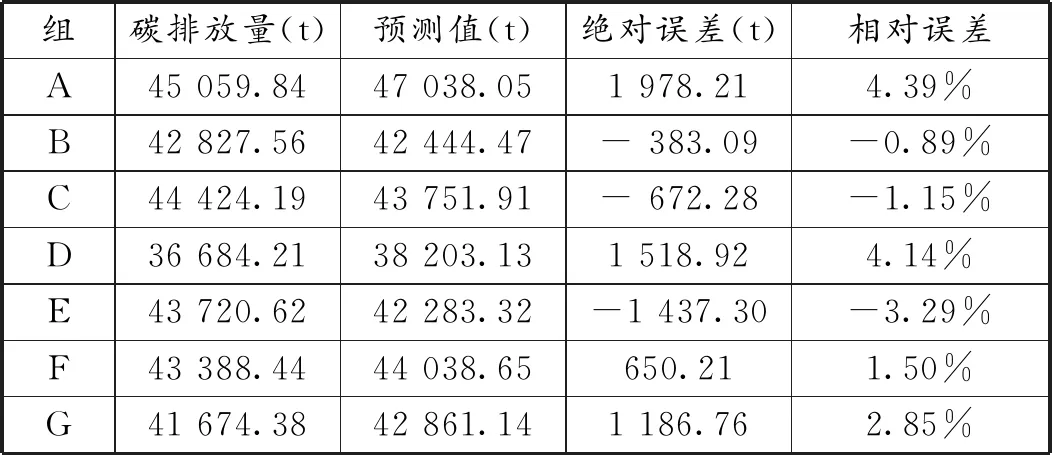
表4 多元线性回归模型预测结果
从表4中可以看出来,由多元线性回归模型预测的碳排放量整体的误差值均小于5%、平均相对误差值为2.60%,整体误差符合当前的数据需求,多元线性回归模型对于钢铁企业碳排放预测具有较好的拟合性。
3.4 模型对比分析
在通过两种方法对碳排放量进行预测后,为了选择更为合适的预测法,将两种模型的相对误差值进行对比,如表5所示。
通过对比两种预测模型的碳排放预测结果,可以看出BP神经网络模型对碳排放进行预测时,预测值的相对误差值整体上小于多元线性回归模型。BP神经网络可以处理复杂空间的非线性系统,受样空间分布影响较小,它通过调整内部的权重来提高网络优化的效果,使得其比多元线性回归模型在碳排放预测具有更高的精度和应用范围。有助于帮助企业掌握自身排放情况,提升企业在低碳经济下的竞争力。

表5 相对误差值
4 结论
通过对比分析BP神经网络模型与多元线性回归分析模型在钢铁企业碳排放预测中的实际应用,得出以下结论:
1)通过建立钢铁企业碳排放的BP神经网络预测模型和多元线性回归模型,发现两种模型均能有效的对碳排放进行预测,相对误差值均小于5%。
2)由于碳排放的变化趋势呈现非线性,采用具有很强的非映射能力的BP神经网络模型对碳排放的预测很适合,BP神经网络模型的优势还在于可根据实际情况灵活设置参数。
