基于改进姿态估计算法的嵌入式平台实时跌倒检测
2020-12-04王红豆孙连浩陈向辉
郭 欣,王红豆,孙连浩,陈向辉
(1.河北工业大学人工智能与数据科学学院,天津 300131;2.中国烟草总公司河北省公司,石家庄 050011)
传统的基于图像的跌倒行为检测算法是使用背景差分法和形态学算法来获取人体的轮廓信息。首先将图像转换为灰度图,利用背景差分法粗略的提取人体的边界信息,然后通过滤波以及边缘检测算法得到人体的清晰轮廓,最后判断人体行为。算法的总体效果较差,各类动作的错误率较高。
深度学习行为识别算法包括基于视频帧动作分类和基于提取人体关键点以及骨架信息的行为分类。基于深度学习的处理视频帧方法主要包括双流网络[2]和三维卷积(three dimensional convolution,C3D)[3]网络。2014年,双流网络被首次提出,通过处理视频序列得到密集光流,然后对彩色图像和光流分别训练,最后将两个分支进行融合得到动作分类结果,缺点是处理速度慢。而C3D网络与此不同,通过使用不同的三维卷积核来同时理解视频中的时间特征和空间特征,从而捕捉到视频流的运动信息。C3D网络的速度比双流网络快,但是精度相对较低。
提取人体关键点以及骨架信息的方法主要包括:自下而上的算法和自上而下的算法。其中自上而下的算法为先运行一个人体检测器,找到所有的人,然后对每个人使用关键点检测,这种方法虽然准确度可观,但是往往速度极慢。而自下而上的方法为先检测图像中人体的各个部分,然后将各个关键点分配到不同的人体实例上,这类方法的判断往往更快速,模型更小。2016年,Fang等[4]提出一种多人姿态估计算法,该算法使用自上而下的方法,先使用SSD(single shot multibox detector)网络检测人,再使用沙漏网络进行姿态估计。2018年,Güler等[5]提出另一种姿态估计算法,先用深度学习算法将二维的图像坐标映射到三维人体表面上,然后处理密集坐标,最终实现动态人物的定位和姿态估计。2019年,Ning等[6]提出了多目标姿态估计和追踪算法,先使用YOLOV3算法检测目标,然后进行单人姿态估计并使用图卷积网络对姿态进行追踪。
相较于传统算法,基于深度学习的姿态估计算法在人体行为识别[7]中取得了很好的效果,但是这些算法在部署的时候,对部署设备提出了很高的要求。近年来,嵌入式设备应用得越来越广泛,虽然移动设备上的圆形处理单元(graphics processing unit,GPU)计算能力相对较弱,但是和服务器相比,它的功耗更低。
近年来,随着深度学习的快速发展,在传统卷积的基础上,许多高效的卷积结构和网络结构被搭建出来。其中三维卷积核可以同时融合时间特征和空间特征,空洞卷积和标准卷积相比极大地扩大了感受野,组卷积和通道混合也可以代替标准卷积。另外,残差网络中的直连结构缓解了梯度消失的问题,使得网络可以拥有更深的结构,学习到更深层的特征。基于此,MobileNet[8]、ShuffleNet[9]等轻量化网络被相继提出,使用这些轻量化网络虽然会损失一小部分精度,但是可以大量减少参数数量和计算量。为此,从实际部署的角度考虑,采用带有注意力机制和深度可分离卷积的网络提取人体骨架信息,然后利用前后帧的骨架信息计算关节点加速度大小、运动方向及宽高比等信息判断是否跌倒。
1 改进人体姿态估计算法
传统的基于深度学习的姿态估计算法模型很大,部署在嵌入式开发板上很难达到实时效果,使用轻量化结构搭建网络可以减少大量的参数,减少模型的大小,同时引入注意力机制可以更好地提取特征,提高人体关键点检测的准确率。
1.1 特征提取网络
在网络搭建中,VGG(Oxford Visual Geometry Group)[10]网络被广泛用于对输入图片的特征进行提取,但是这些网络的参数太多,因此基于轻量级带有注意力机制的基本模块[11]搭建网络。基本模块包含了MobileNetV2[12]中的深度可分离卷积以及具有线性瓶颈的逆残差结构,同时加入了SE(squeeze-and-excitation)结构[13]的轻量注意力模型,将SE结构放在深度可分离卷积之后,在保证速度的同时,提升了精度。SE结构和基本模块结构分别如图1、图2所示。
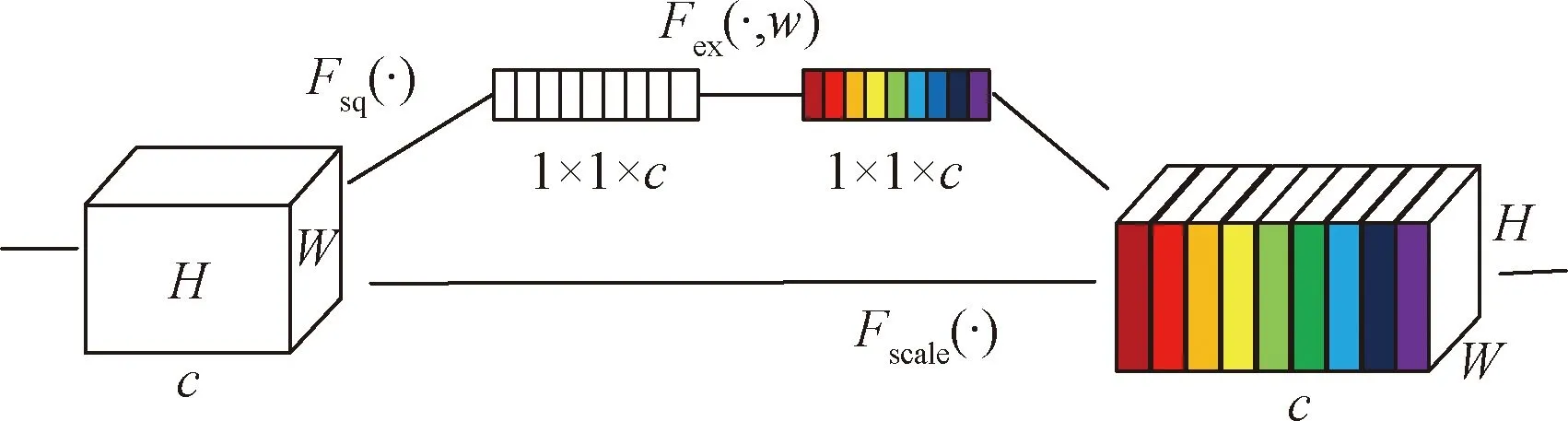
图1 SE模块结构Fig.1 SE module structure
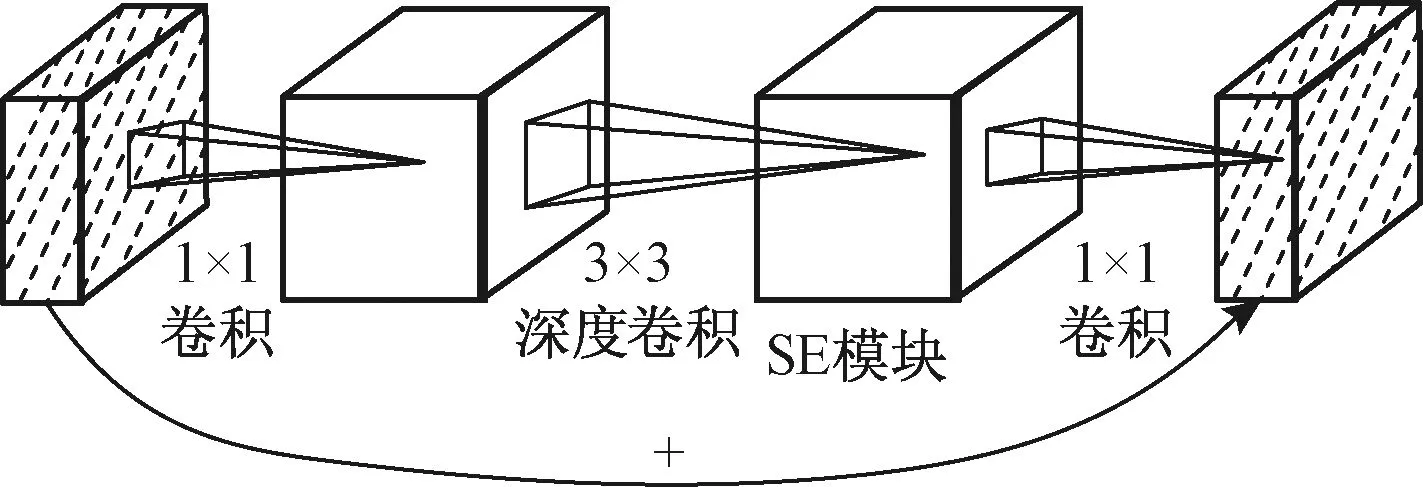
图2 基本模块结构Fig.2 Basic module structure
图1中,Fsq(·)表示在空间维度缩小特征图,计算公式为
(1)
式(1)中:uc为输入的特征图,下标c表示特征图通道;H为特征图的高;W为特征图的宽。
Fex(·,w)表示用学习权重w来了解通道之间的关联,计算公式为
s=Fex(z,w)=σ[g(z,w)]=σ[w2σ(w1z)]
(2)
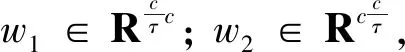
Fscale(·)用来重新衡量特征图的权重。计算公式为
Fscale(uc,sc)=scuc
(3)
式(3)中:sc为通道重要性的标量值。
在部分的基本结构中使用h-swish激活函数来代替relu6激活函数。Switch激活函数相比relu激活函数性能更佳,但是比relu计算更加复杂,使用和Switch函数类似的h-swish激活函数可以在减少内存开销的同时提升性能,适合在移动设备上使用。h-swish激活函数的公式为
(4)
特征提取部分搭建的网络结构如表1所示。
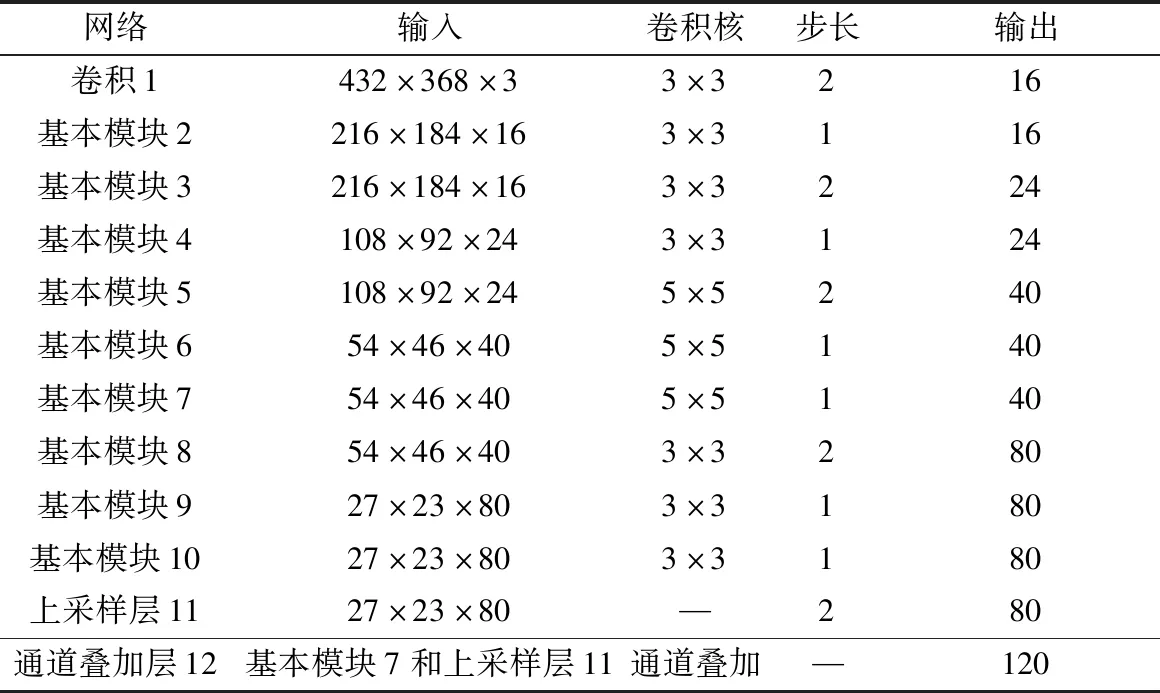
表1 特征提取网络结构Table 1 Feature extraction network structure
特征提取网络的最后,在网络搭建中将最后基本模块的输出经过上采样之后与第7层模块的输出进行通道叠加。浅层的网络更注重位置信息,而高层的网络更关注于语义信息,同时融合深层特征能同时运用不同大小的感受野,适合做复杂任务,能更好地提取特征。
在表1中,基本模块5、基本模块6、基本模块7使用了SE结构,卷积1以及基本模块8、基本模块9、基本模块10使用的激活函数是h-swish,而其他部分使用relu6激活函数。
1.2 姿态估计主网络
经过前面提取特征的网络部分,提取得到维度为54×46×120的特征图,将这些特征图送入第一阶段,每个阶段包含两个分支,每个分支都首先通过5个3×3的深度卷积结构(depthwise convolution structure,DWconv),然后再通过2个1×1的卷积(conv),每个阶段的两个分支的最后输出通道数分别为19、38,下一个阶段的输入为此阶段的输出与特征提取网络输出的特征图的通道数融合,总共有五个这样的阶段,输出中的19通道特征图表示每张特征图预测人体的一个部位,共有18个,外加一张背景特征图,而38通道的输出表示人体部位关键点连接的矢量图。除了最后的阶段,其他阶段的19通道和38通道的输出都会和特征提取的输出特征图进行融合,作为下一个阶段的输入。
一个深度卷积结构是指先通过3×3的深度可分离卷积,再通过1×1卷积和批归一化(BN层)。使用深度卷积结构可以大幅降低计算量和参数量,深度卷积结构的思想是把普通的卷积分成深度可分离卷积(depthwise)和1×1卷积两步,即先在空间维度上进行信息的融合,不对通道做任何操作,后面的1×1卷积则只在通道上进行信息融合。使用3×3的普通卷积和使用3×3的深度卷积结构,后者在参数量和计算量上约为前者的1/8~1/9。深度卷积结构如图3所示。
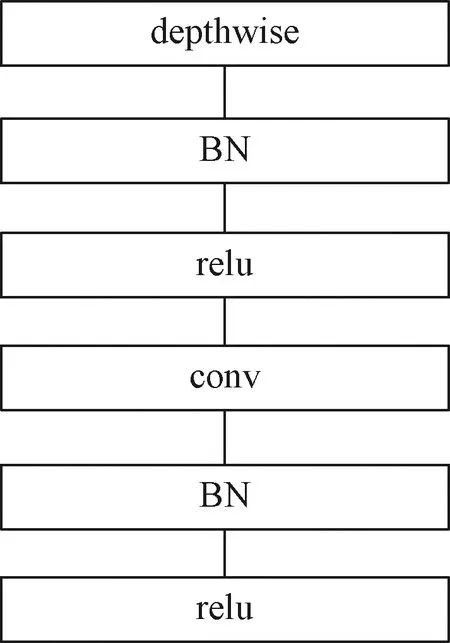
图3 深度卷积结构Fig.3 Depth convolutional structure
分支网络的结构如表2所示。
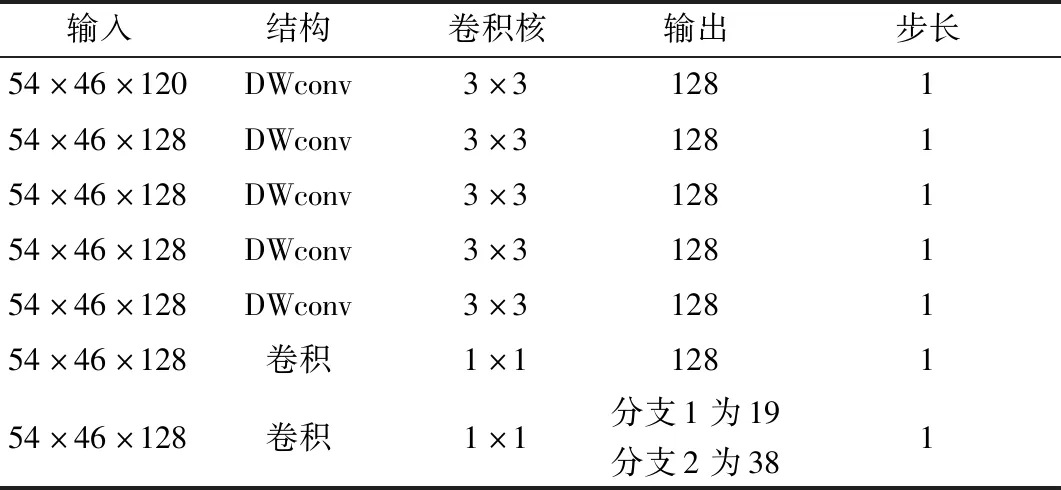
表2 分支网络结构Table 2 Branch network structure
各个分支网络的输入为
S1=ρt′(F),t′=1
(5)
L1=φt′(F),t′=1
(6)
St′=ρt′(F,St′-1,Lt′-1),t′≥2
(7)
Lt′=φt′(F,St′-1,Lt′-1),t′≥2
(8)
式中:F表示特征提取网络的输出特征图;ρ和φ表示连续的3×3卷积和1×1卷积操作;S表示关键点热图;L表示关键点之间连接关系的矢量图;t′表示不同阶段。
人体关键点位置和矢量图的损失函数为
(9)
(10)
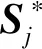
(11)
对于图像中的每个人的每个关键点,在热图上表示形式都为一个极值点,通过高斯函数确定关键点的置信度,对于第m个人的第j个关键点可得某一位置的置信度为
(12)
式(12)中:xj,m表示的是图像中关键点的位置。如果图像中不止一个人,则第j个关键点在此位置的置信度为所有人中的最大值。
(13)
对于关键点之间的骨架信息方向的判断为
(14)
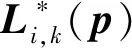
根据关键点热图和矢量图,使用二分图匈牙利匹配算法将人体的关键点连成骨架,最终得到每个人的关键点坐标以及骨架信息。
网络的整体结构如图4所示。
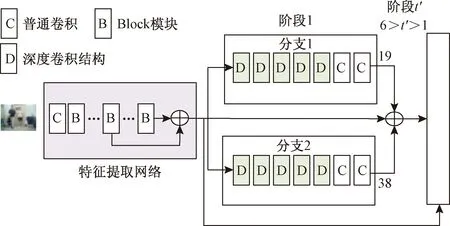
图4 网络整体结构Fig.4 The overall structure of the network
2 人体姿态追踪和识别
根据训练好的模型可以得到一帧图像中每个人的关键点和骨架信息,对于多人姿态的追踪,可以通过几个度量方式来前后帧检测到的人进行匹配,从而达到追踪的目的。
同一帧中不同的人之间的姿态距离。选择水平向右为x轴正方形,竖直向下为y轴正方形。使用前面训练好的模型对每帧图片进行姿态估计,得到每个人的关键点坐标,构成每个人的关键点坐标矩阵,计算两个人的对应关节点中置信度都大于阈值的欧氏距离。其中第j′个人的第k个关键点的坐标矩阵为
Lj′,k=(xj′,k,yj′,k,cj′,k)
(15)
式(15)中:xj′,k和yj′,k表示人体关键点的坐标点;cj′,k表示关键点的置信度。
第j′个人的坐标矩阵为
Pj′=(Lj′,1,Lj′,2,…,Lj′,18)
(16)
不同帧之间同一个人的姿态距离。通过计算不同帧每个人之间的姿态距离,利用时空信息可以显著提高识别前后帧同一个人匹配的任务。
根据前后帧之间的人体关键点的坐标变化情况,计算出靠近人体中心点的关节点(髋关节、颈关节、肩关节、膝关节)的加速度,这些关节点的加速度[14]可以反映出人体运动的剧烈情况。
因为在人体跌倒时,人体的中心点会快速向下移动,所以根据髋关节、肩关节以及膝关节的运动方向和加速度来进一步对人体跌倒进行检测。
根据检测到的各个关节点位置可以得到人体的宽高比,根据宽高比对人体跌倒进行辅助判断。
(17)
式(17)中:a为关节点运动的加速度;(xt-1,yt-1)为关节点在t-1时刻的位置;(xt,yt)为关节点当前时刻t的位置;Δt为两个时刻的时间差。
检测跌倒的流程如下。
(1)根据关节点的加速度大小判断人体运动的剧烈程度,加速度越大,表示当前人体运动越剧烈,当加速度小于阈值的时候,可以排除掉行走、站立等不运动或者缓慢运动的状态。
(2)对于剧烈运动的状态(跑步、跳动、跌倒等),跌倒过程和其他运动的区别是其他过程是周期性重复过程,而跌倒行为是一次性行为,所以在检测到周期性或持续性的加速度很大可以判断为跑步等其他行为。
(3)根据人体跌倒后关节点的相对位置以及宽高比的变化排除下蹲等行为,最终确定人体姿态并判断是否为跌倒状态。
跌倒行为的检测流程如图5所示。
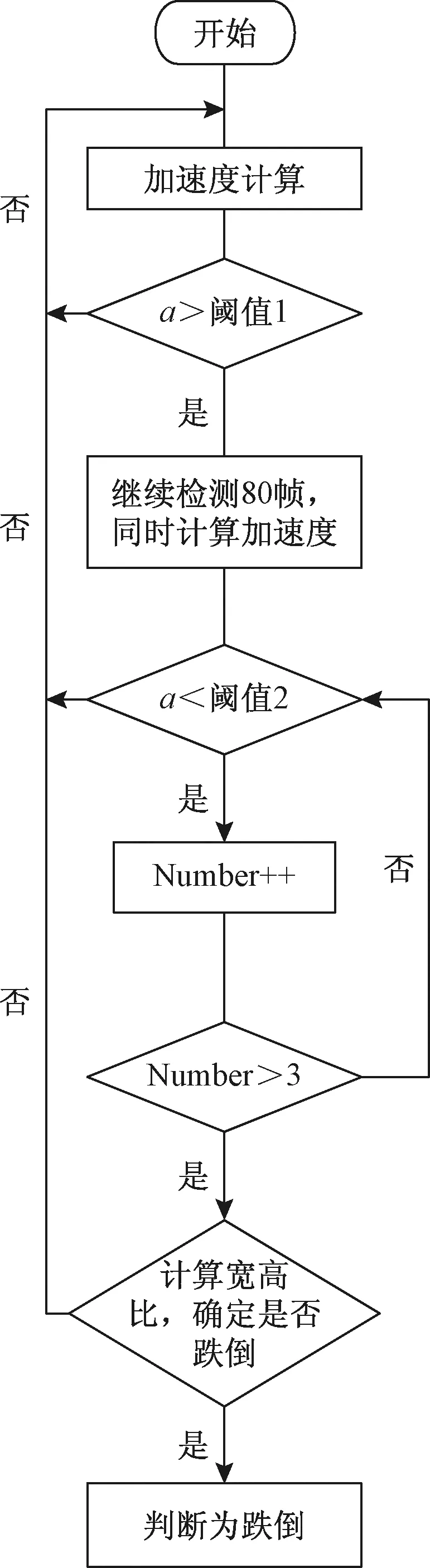
图5 跌倒检测流程图Fig.5 Fall detection flow chart
3 实验与结果分析
3.1 实验总体框架和参数选择
姿态估计算法主要在服务器端训练并部署在嵌入式平台上。具体流程为:先搭建网络并训练,得到训练模型并测试,再将模型移植到嵌入式平台上进行前向推理得到人体关键点信息,最后进行跌判断。具体流程图如图6所示。
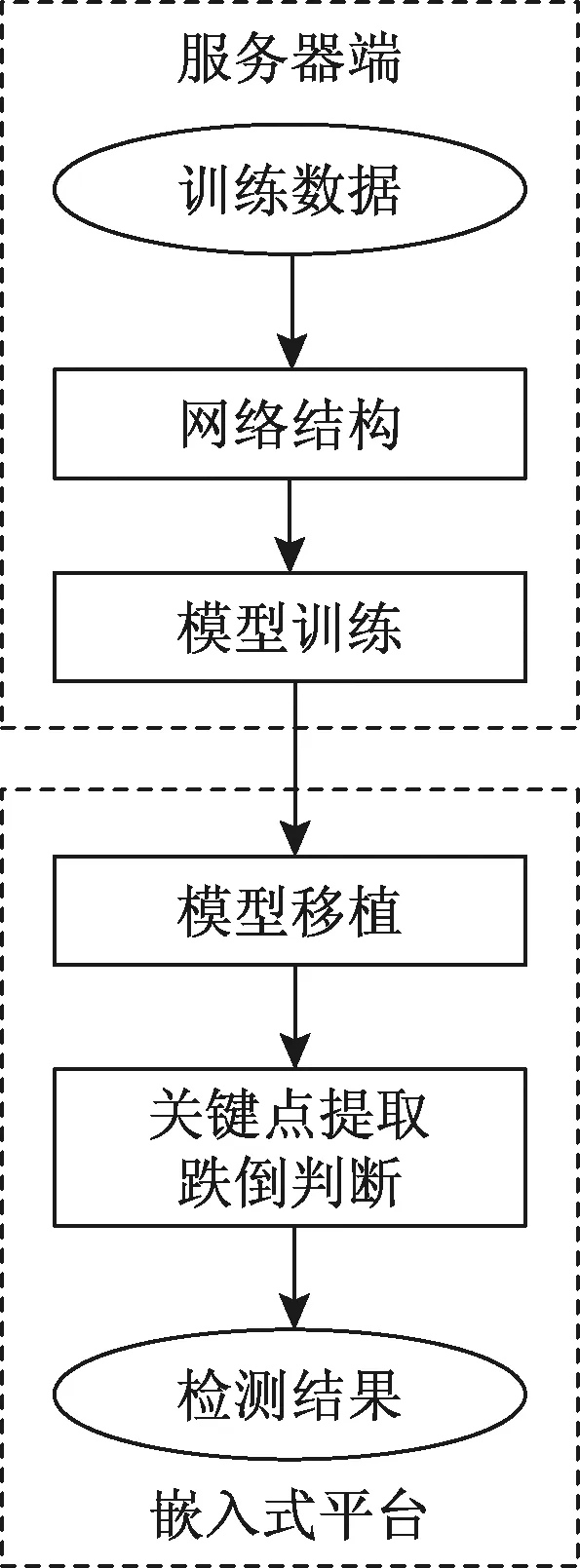
图6 总体流程图Fig.6 Overall flow chart
训练时采用的输入的图片大小调整为432×368,批次大小(batchsize)大小为128,初始学习率设置为1×10-3,每轮训练2×103次,训练200 轮,网络训练使用随机梯度下降(stochastic gradient descent,SGD)反向传播算法,使用的冲量为0.9,权重衰减系数为5×10-4,选用的开发板为Jetson TX2,相应的配置如表3所示。

表3 开发板配置Table 3 Development board configuration
3.2 结果分析
测试数据集选用的是MPII数据集。MPII是另一个人体姿态估计的数据集,该数据集包含了超过4×104人的图片,共标注了25 000 张图片,通过对比MPII数据集的测试结果来证明模型的精度和速度。在该数据集上对比人体各个关键点精度及关键点的平均精度如表4所示。
对比表4中各算法的精度,可以发现模型对踝关节以及腕关节的检测精度相对较低,这和图片中人体处于运动状态产生虚影有关,而对于靠近人体中心的肩关节、颈关节等的精度较高。本文算法在MPII数据集上的预测精度有所提高,和ArtTrack相比,平均精度提升了2.5%,同时对人体各关键点都能达到很好地识别效果。
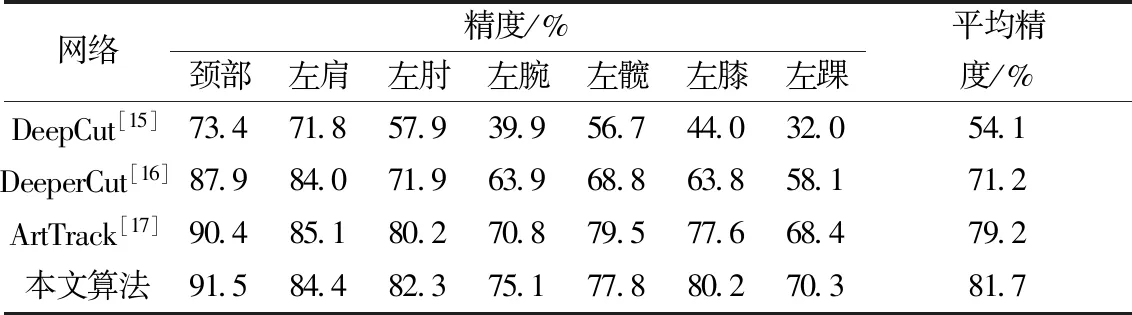
表4 MPII数据集上不同算法精度对比Table 4 Comparison of different algorithms on MPII datasets
通过对比表5中算法在训练数据集(COCO数据集)上的准确率和速度,可以看出与OpenPose等算法相比,本文算法的精度有所提升,但提升效果不明显,但是在运行速度方面和OpenPose相比提升了35%,可达16.74 fps,可见使用轻量化的卷积网络结构可以在保持精度的同时去掉大量无用的参数。
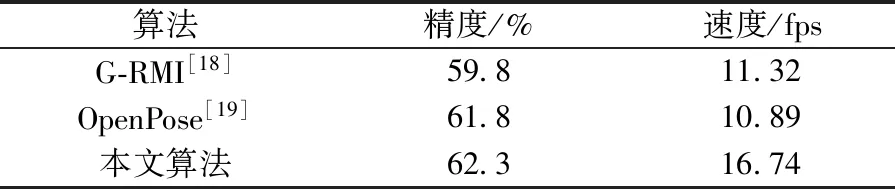
表5 训练集上算法对比Table 5 Comparison of algorithms on training set
与采用自上而下的检测方法不同,文章使用的是自下而上的检测方法,即先检测人体的关键点,然后将关键点组合成不同的人,检测速度不会因为人数的变多而变慢。提取的人体关键点以及骨架信息如图7所示。

图7 单人、多人姿态估计Fig.7 Single and multi-person pose estimation
对于跌倒检测,选取4个实验者分别进行20 次跌倒实验,对比背景差分法结合边缘检测算法与基于人体关键点进行跌倒检测的算法,得到的结果如表6所示。
对比表6数据可以看出,使用人体关键点对人体行为进行检测的方法优于传统的使用滤波加边缘检测算子的方法。对人体跌倒进行检测的过程如图8所示。
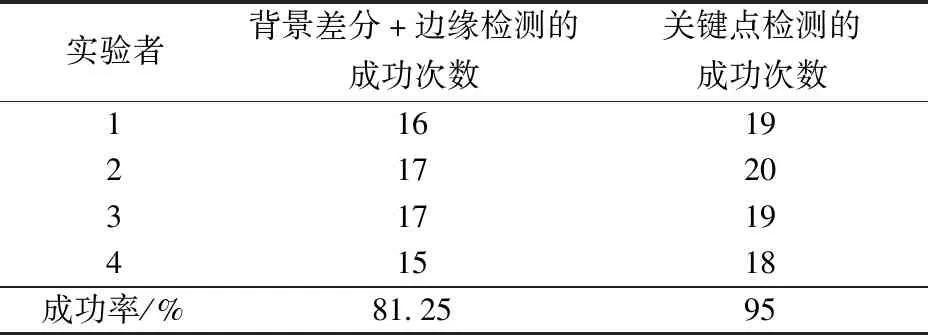
表6 跌倒检测数据Table 6 Fall detection data

图8 跌倒过程Fig.8 Fall process
4 结论
根据以上姿态估计以及跌倒检测等的实验结果,得到以下结论。
(1)使用带有注意力机制的轻量化网络结构和传统的全卷积网络结构相比,减少了大量的无用参数,在保持准确率的同时加快模型的运行速度。
(2)通过改进的姿态估计算法可以得到更加准确的人体关键点信息,并减少了模型的前向推理时间,在嵌入式设备上可以得到实时效果。
(3)通过前后帧中人体关键点移动的加速度、方向等信息判断人体行为,并通过宽高比等信息辅助判断人体跌倒。和传统方法相比准确率更高,误检更少。
