事件表示学习综述
2020-11-11黄虎杰
廖 阔, 丁 效, 秦 兵, 刘 挺, 黄虎杰
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨150001)
0 引 言
事件通常指包含参与者在内的某种动作或情况的发生,或事件状态的改变。 在粒度上,事件介于词与句子之间,与词相比,事件通常包含多个词,用来描述事件的发生及事件的组成要素,是一种语义更完备的文本单元;与句子相比,事件更关注对现实世界中动作或变化的描述,是对现实世界一种更细粒度的刻画。 在形式上,事件的组成要素通常包括事件的触发词或类型、事件的参与者、事件发生的时间或地点等,与纯自然语言形式的文本相比,事件是现实世界中信息的一种更为结构化的表示形式。 事件在粒度上与形式上的特点使得对其进行表示时,面临着与其他文本单元不同的问题,由此引出了事件表示学习的概念。 将结构化的事件信息表示为机器可以理解的形式,对许多自然语言理解任务都十分必要,例如:脚本预测与故事生成。 早期的研究大多采用离散的事件表示,随着深度学习的发展,人们开始尝试使用深度神经网络为事件学习稠密的向量表示,同时逐步有研究探索将事件内信息、事件间信息、外部知识等多种类型的信息融入事件表示中,下面将分别对以上研究进行介绍。
1 离散的事件表示
早期的研究主要基于离散的事件表示,通常将事件表示为由事件元素构成的元组。 Kim 等将事件表示为三元组(Oi,P,t),给定对象的集合O, 其中Oi⊆O 为对象的谓词,P 为对象间的关系或属性,t为事件发生的时间[1]。 Radinsky 等进一步将角色加入事件表示中,每个事件包含标记事件发生的动作或状态P,一个或多个事件的实施者O1, 一个或多个事件作用的对象O2,一个或多个使事件发生的工具O3,以及一或多个地点O4, 以及时间戳t, 记为六元组(P,O1,O2,O3,O4,t)[2]。 Ding 等将其简化为(O1,P,O2,T) 形式的元组,其中P 为事件动作,O1为施事者,O2为受事者, T 为时间戳,一个事件只包含一个施事者和一个受事者[3]Chambers 与Jurafsky 在脚本事件预测任务中,提出了Predicate-GR 事件表示方法,该任务中与同一个角色相关的事件按照时间顺序整理成事件链,Predicate-GR 将每个事件表示为动作以及动作与角色之间的依存关系构成的二元组[4],例如: (arrest,obj) 表示一个逮捕事件,且事件链关联的角色在该事件中为宾语,即被逮捕的对象。 因为同一个事件链中的角色是相同的,因此无需将角色加入事件表示中。
离散的事件表示面临稀疏性的问题。 为了缓解稀疏性,一系列工作提出基于语义知识库对事件进行泛化。 Ding 等基于WordNet 将各事件元素中的单词还原为词干,之后将事件动作词泛化为其在VerbNet 中的类别名称,得到泛化事件[3],例如:单词“adds”首先被还原为词干“add”,之后被泛化为VerbNet 中的类别名“multiply_class”。 Zhao 等将事件元素中的名词泛化为其在WordNet 中的上位词,将动词泛化为其在VerbNet 的类别,之后在所有事件中的单词组成的词对(bi-gram)中筛选频率最高的词对,称为“高频共现词对(FCOPA)”,作为泛化后的事件[5]。 例如,“Hudson killed Andrew”首先被泛化为“people murder-42.1 people”,之后高频共现词对“murder-42.1 people”被作为一个泛化的事件。
2 稠密的事件表示
自2013 年起,随着深度学习技术的发展,人们开始探索为文本学习分布式的语义表示。 分布式语义表示将文本单元(如字、词等)嵌入到向量空间中,每个文本单元的语义信息由所有语义单元在向量空间中的位置共同决定。 这种分布式的语义表示通常具有良好的性质。 例如,相关性较强(语义相近)的文本单元具有相似的向量表示,并且在很大程度上缓解了文本单元的稀疏性。 在这一系列工作的基础上,基于分布式语义的稠密的事件表示应运而生。 稠密的事件表示通常以预训练的词向量为基础,根据事件结构对事件元素的词向量进行语义组合,为事件计算低维、稠密的向量表示。 按照组合的方式,可以分为基于词向量参数化加法的事件表示与基于张量神经网络的事件表示。
2.1 基于词向量参数化加法的事件表示
基于词向量参数化加法的事件表示方法将事件元素的词向量进行相加或拼接后,输入一个参数化的函数,将相加或拼接后的向量映射到事件向量空间。 Weber 等对事件元素的词向量求均值,作为一种基线方法[6]。 Li 等将事件元素的词向量进行拼接作为事件的向量表示[7]。 Granroth-Wilding 等提出EventComp 方法,将事件元素的词向量拼接后,输入多层全连接神经网络,对事件元素的词向量进行组合[8]。 作为词向量参数化加法的一种特例,Lee等直接使用Predicate-GR 的向量表示作为事件的向量表示,从而省略了将事件元素的词向量进行组合的步骤[9]。
Tilk 等与Hong 等对事件元素向量求和或求均值作为事件表示,但额外考虑事件元素的角色,同一个词出现在事件的不同角色中时,使用不同的词向量[10-11]。 设词表大小为, 角色数量为, 词向量的维数为H,不同角色的词向量构成了三维的张量T ∈R|V|×|R|×H。 为了减少模型的参数数量,进一步将该张量分解为F 个一阶张量乘积的形式,使用三个矩阵A,B,C 代替原本的三维张量T, 公式(1):
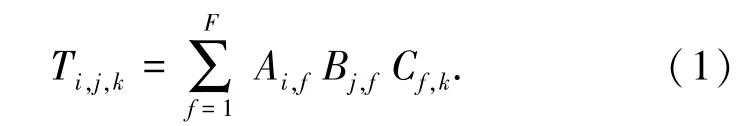
设r 为表示角色的独热(one-hot)向量,角色r对应的词向量矩阵为T 的一个切片,表示为公式(2):
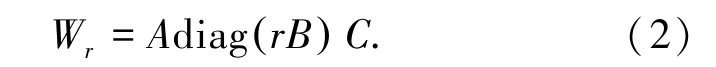
最终,对于每个事件元素,分别在该事件元素对应角色的词向量矩阵中查找其词向量,并将所有事件元素的词向量进行组合作为事件向量。
2.2 基于张量神经网络的事件表示
基于词向量参数化加法的事件表示充分利用了事件元素的词向量信息,但在建模事件元素间的交互上较为薄弱。 尽管这些方法均取得了一定的效果,但其加性本质使得难以对事件表面形式的细微差异进行建模。 例如,在这些方法下,“She throw football(她扔足球)”与“She throw bomb(她扔炸弹)”会得到相近的向量表示,尽管两个事件语义上并不相似。 为了解决这一问题,人们陆续提出了基于张量神经网络的事件表示方法。 这一系列方法使用双线性张量运算组合事件的元素,设事件两个元素的向量分别为v1,v2∈Rd,三维张量T ∈Rk×d×d是张量神经网络的参数,则双线性张量运算的计算方式如公式(3):
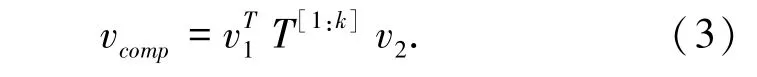
其中,计算结果vcomp是一个k 维向量,它的每一个维度i 上的元素是由向量v1,矩阵Ti和向量v2做矩阵乘法得到的。 在双线性张量运算中,模型以乘性的方式捕获了事件论元的交互,使得即使事件论元只有细微的表面差异,也能够在事件表示中体现出语义上的较大差别。
Ding 等在2015 年提出了Neural Tensor Network模型,简称NTN,模型结构如图1 所示。 该工作考虑(O1,P,O2)三元组形式的事件结构,其中O1为事件的施事者,P 为事件的动作或触发词, O2为事件的受事者,此处用同样的符号表示三种事件元素的词向量。 模型首先对施事者和动作词、动作词和受事者进行组合,再对得到的两个向量进行组合,得到最终的事件表示E[12]。 每次组合由一个双线性张量运算,一个常规的线性运算与激活函数f 组成,计算方法如公式(4)~(6)所示:
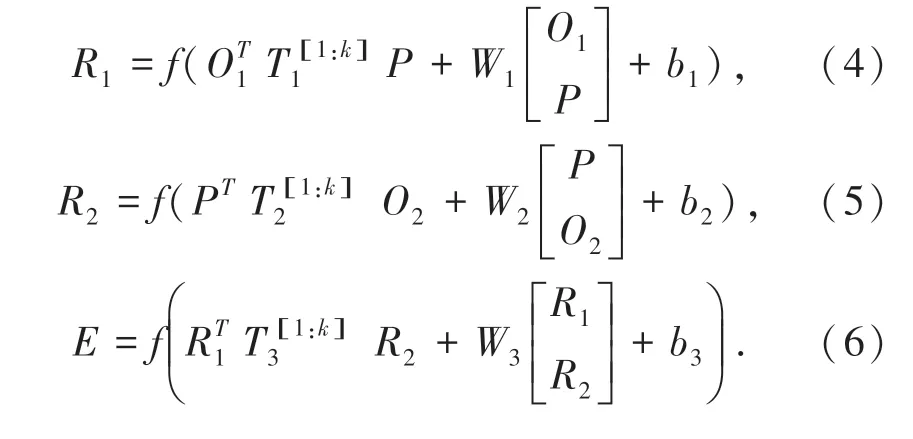

图1 Neural Tensor Network 模型结构Fig. 1 Architecture of Neural Tensor Network
Weber 等在2018 年提出了Predicate Tensor 模型与Role-Factored Tensor 模型,模型结构如图2 所示。 该工作同样考虑(s,p,o) 三元组形式的事件,其中s 为主语,p 为谓语,o 为宾语,并考虑使用三维张量P 建模谓语p,并用该张量对主语s 和宾语o进行语义组合得到事件向量e[6],其每个元素ei的计算过程如公式(7):
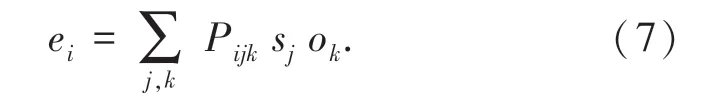
该方法需要为每个谓语单词学习一个单独的三维张量,但谓语的集合非常大,在实践中不可行。Predicate Tensor 方法由谓语的词向量p 动态地计算张量P,并用动态计算的张量对主语和宾语进行语义组合。 其中,W 与U 为模型参数,设词向量的维数为d,W 与U 均为大小为d ×d ×d 的三维张量,见公式(8)和公式(9):
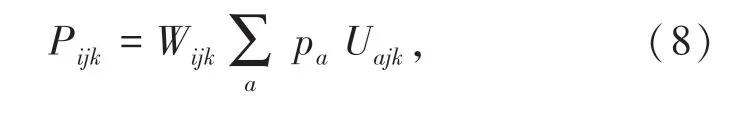
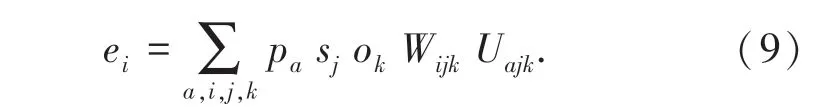
Role-Factored Tensor 方法单独地对事件的主语及谓语、谓语及宾语进行语义组合,组合后的两个向量通过线性变换后相加得到事件向量,见公式(10)~(12):
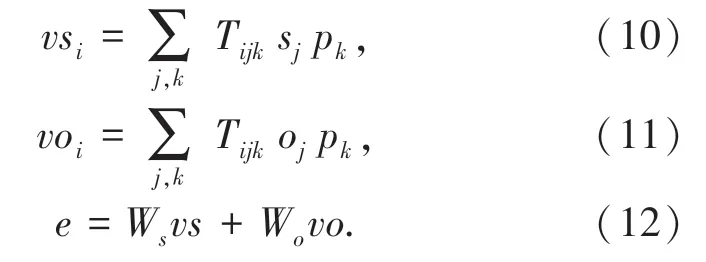
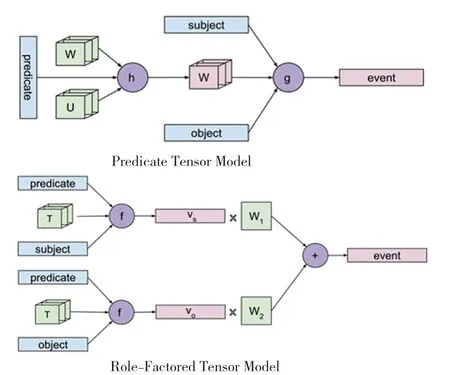
图2 Predicate Tensor Model 与Role-Factored Tensor Model 模型结构Fig. 2 Architecture of Predicate Tensor Model and Role-Factored Tensor Model
基于张量神经网络的事件表示方法面临“维度灾难”的问题,限制了该方法在许多领域的应用。Ding 等在2019 年提出使用低秩张量分解(Low-Rank Tensor Decomposition),将张量神经网络中的三阶张量参数使用维度较小的张量进行近似,以减少模型的参数[13]。 图3 为低秩张量分解运算的示意图。 具体地,将模型中的三阶张量参数T 替换为T1∈Rk×d×r,T2∈Rk×r×d,t ∈Rk×d三个参数,使用Tappr作为T 的近似,其每个切片是通过公式(12)计算得到的:
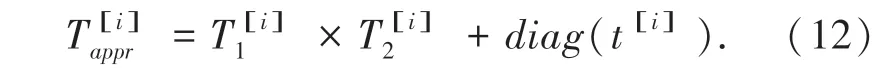
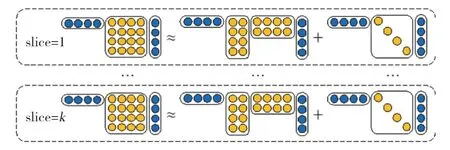
图3 低秩张量分解示意图Fig. 3 An illustration of low-rank tensor decomposition
Ding 等在事件相似度、脚本事件预测、股市预测多个任务上的实验结果表明:使用低秩张量分解,可以在减少模型参数的同时取得与原模型相当的效果,有些任务上甚至取得了比原模型更好的性能。
3 事件表示的学习方法
稠密的事件表示使用深度学习的方法,将事件嵌入到向量空间中,为了使嵌入后的向量保留丰富的语义信息,需要为事件表示设计合适的训练目标。一种学习事件表示的方式是直接使用下游任务作为训练目标,这种方式学习得到的事件表示往往只在特定的任务上具有较好的效果,而缺乏较好的泛化能力。 其他学习事件表示的方法,包括基于事件本身的结构信息与事件在文本中的分布信息构造自监督的训练目标,在大量文本上进行预训练;以及使用知识库指导事件表示的学习,在事件表示中融入外部知识。 下文具体介绍基于事件内信息的事件表示学习、基于事件间信息的事件表示学习与融合外部知识的事件表示学习。
3.1 基于事件内信息的事件表示学习
基于事件内信息的事件表示学习充分利用了事件的结构信息,通常采用自编码的思想,由事件表示恢复出事件元素,并由此构建训练目标,使得事件表示中尽可能地保留事件元素的信息。
Ding 等在2015 年提出以区分正确的事件元组与被破坏的事件元组作为事件表示的训练目标。 该方法首先使用开放事件抽取工具ReVerb 从大量新闻文本中抽取包含施事者、事件动作、受事者的事件元组E =(O1,P,O2),将事件论元中的单词随机替换为词表中的其他单词,构造被破坏的事件元组Er=(,P,O2)。 事件元组经过NTN 模型嵌入到向量空间中,并进一步由函数f 映射一个分数。 训练目标为使正确的事件元组分数高于被破坏的事件元组,具体使用最大边际损失进行计算[12],其中, λ为L2 正则项,公式(13):
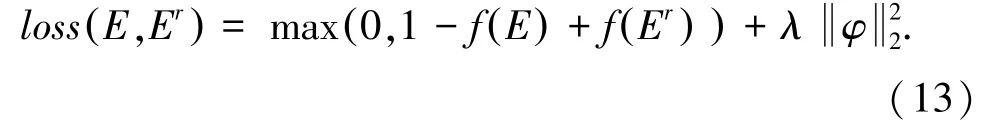
Tilk 等在2016 年提出NNRF 方法,使用事件表示预测事件角色作为训练目标。 该方法中,事件的结构被表示为包含谓词、论元的元组,其中每个事件论元被限制为一个单词,并被分配一个预先定义好的角色。 事件元组首先由事件表示模型嵌入到向量空间中,得到事件向量h。 之后,对于每种事件中的每种角色t,使用一个分类器对整个词表进行分类,以预测唯一正确的事件角色词作为训练目标。 为了缓解事件角色数较多带来的分类器参数量大的问题,该方法进一步将分类器中的参数进行分解,采用事件角色的独热向量t 与各分类器共享的模型参数Ac,Bc,Cc动态地计算每种角色的预测结果[10],见公式(14)和公式(15):
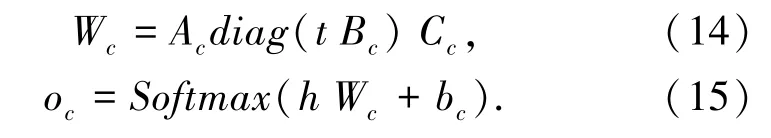
其中, oc是该角色上每个单词的概率分布,使用该概率分布计算交叉熵损失,作为模型的训练目标。
Hong 等在Tilk 等的基础上,提出NNRF-MT 方法,进一步引入角色分类的训练目标,输入事件表示h 与单词wt,由分类器预测该单词在事件中的角色类别[14]。 类似地,该分类器的参数按照词表进行分解,由单词的独热向量wt与共享的参数Ar,Br,Cr动态地为每个单词计算预测结果[11],公式(15)和公式(16):
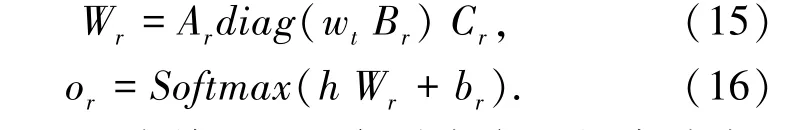
其中, or是该单词属于每种角色的概率分布,使用该概率分布计算交叉熵损失作为角色分类的训练目标。 最后,对角色预测与角色分类的损失进行加权平均得到最终的损失,采用多任务学习(Multi-Task)的形式同时优化两个训练目标,对事件表示进行学习。
3.2 基于事件间信息的事件表示学习
事件的发生并不是独立的,而是按照事件演化规律接连地发生,因此良好的事件表示,除了充分保留事件论元的信息外,还应该含有事件的演化规律信息。 为了捕获事件间的演化规律,一系列研究提出考虑事件间的交互,利用事件在文本中的分布信息指导事件表示学习。 开放事件抽取工作[]的进展,使得挖掘事件在文本中的分布信息成为可能,为这一系列的工作提供了基础。 具体地,这一系列工作可以分为基于事件对的方法、基于事件链条的方法与基于事件图的方法。
Granroth-Wilding 等在2016 年提出了基于事件对的EventComp 方法,利用事件对的顺承关系作为事件表示的训练目标。 该方法首先从大规模文本中自动抽取事件链条,将事件链条拆分为多个满足顺承关系的事件对,并通过随机采样的方法构造不满足顺承关系的事件对。 之后,使用全连接网络对事件对是否满足顺承关系进行分类,使用分类器的输出计算交叉熵损失,作为事件表示的训练目标。 具体地,对于第i 个训练样本中的事件对(e0i,e1i),使用全连接网络计算两个事件的相关性分数coh(e0i,e1i), 并与事件对的真实类别pi∈{0,1}计算交叉熵损失[8],公式(17):
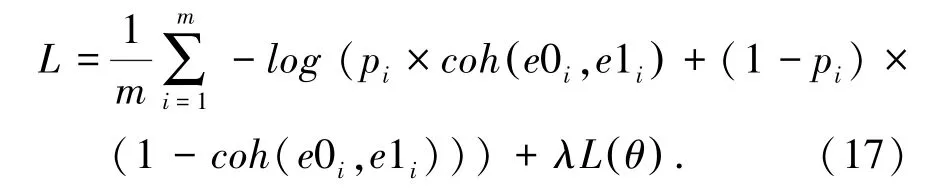
Weber 等在该方法的基础上,在事件链条的窗口中采样满足顺承关系的事件对,并以余弦相似度度量事件向量的相关性分数,采用最大边际损失作为训练目标。 具体地,对于一个输入事件ei, et为事件链条中ei前后窗口中的一个事件,en为从整个语料中随机采样的一个事件, sim(ei,et) 为两个事件的余弦相似度,使用(ei,et) 与(ei,en) 两个事件对的相似度计算最大边际损失[6],公式(18):
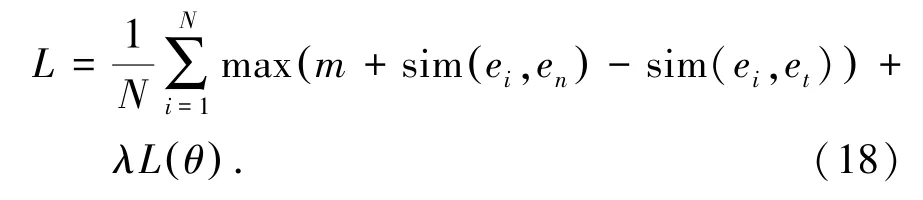
Wang 等采用事件链条信息指导事件表示的学习,其训练方式为给定事件链条中的上下文事件,预测下一个会发生的事件。 上下文事件和候选结尾事件首先被拼接为完整的事件链条,之后每个事件的向量表示被输入长短时记忆网络(LSTM),得到上下文相关的事件表示,基于上下文相关的事件表示计算,计算候选事件与每个上下文事件的相关性得分,并由该得分计算交叉熵损失作为训练目标[14]。具体地,对于上下文事件e1,…,ei,…,en-1与候选事件ec,采用公式(19)~公式(22)计算其上下文相关的向量表示:

其中, e (ei) ,e(ec) 为事件ei,ec的初始事件表示,hi,hc为其上下文相关的向量表示,h0为随机初始化的向量。 候选事件ec与上下文事件ei的相关性分数si由一个全连接网络计算, Wsi,Wsc,bs为该网络的参数,ec作为候选事件的概率s 为其与所有上下文事件相关性的均值。 最终由该概率值计算交叉熵损失作为模型的训练目标,公式(23):
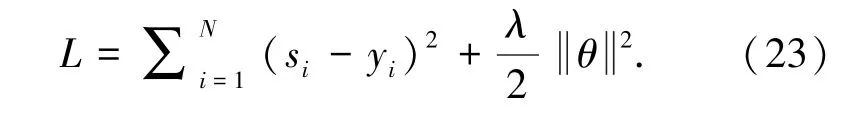
Zhao 等由自动抽取的因果事件对构造抽象的因果事件图,并提出基于图嵌入的事件表示学习方法Dual-CET,在因果事件图上学习事件表示[7]。 这一方法为图中每个事件节点以及原因关系、结果关系学习一个向量表示[5],对于一个因果事件对(c,e) ,定义其能量函数为公式(24):
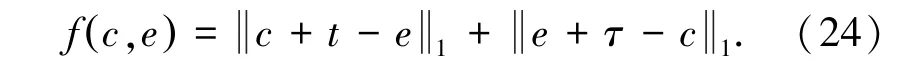
其中,c 为原因事件向量,e 为结果事件向量,t为原因关系向量, τ 为结果关系向量。 训练目标为使正确因果事件对的能量低于随机构造的错误因果事件对,公式(25):
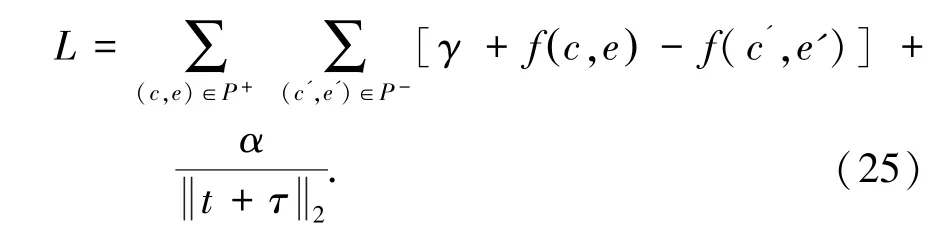
其中,P+为所有正确因果事件对的集合,P-为所有错误因果事件对的集合, γ 为最大边际损失的超参数,α 为正则项系数。
Li 等进一步使用图神经网络在事件图上学习事件表示。 该工作考虑事件间的顺承关系,从大规模文本中抽取事件链后构建叙事事件图,并使用门控图神经网络(GGNN)在事件图上学习事件表示,该模型的输入为事件节点的初始向量表示,输出为融合图结构信息的事件向量。 与Granroth-Wilding等相同,该方法使用预测事件链条的后续事件作为训练任务,但将训练目标替换为最大边际损失[7],公式(26):

其中,N 为训练样本数, sIy为第I 个训练样本中正确候选事件的得分,sIj为该样本中错误候选事件的得分。
3.3 融合外部知识的事件表示学习
基于事件内与事件间信息的事件表示学习方法,考虑了事件的结构信息以及事件在文本中的分布信息,但忽略了文本中未显式提及的常识知识。例 如, “Steve Jobs quits Apple” 与“John leaves Starbucks”尽管具有相似的结构,但“Steve Jobs”是“Apple”公司的CEO,而“John”与“Starbucks”并无特殊关系,因此两个事件会对它们的客体产生不同的影响。 为了解决这一问题,一系列工作提出将外部知识融入事件表示学习中,为事件表示补充文本中没有显示提及的信息。
Ding 等在2016 年提出将实体关系知识融入事件表示,这种知识可以从知识图谱如YAGO,Freebase 中获取。 该方法的示意图如图4 所示,对于一个事件元组(A,P,O),首先在知识图谱中找到包含事件施事者A 或受事者O 的三元组(e1,R,e2),其中e1为头实体,e2为尾实体,R 为两个实体间的关系。 之后,采用公式(27)的张量神经网络为(e1,R,e2) 三元组计算得分[15]:
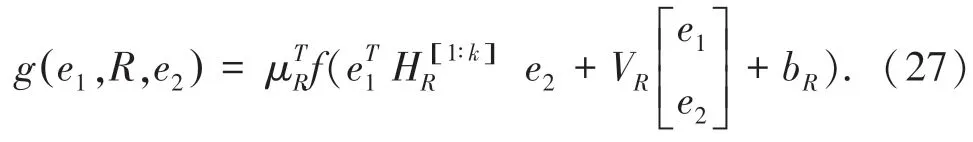
其中,μR,HR,VR,bR为特定于关系R 的参数。给定一个来自知识图谱中的正确三元组与随机替换头实体或尾实体后的错误三元组,使用最大边际损失训练正确三元组的得分高于错误三元组。 训练过程中,头实体或尾实体的词向量在反向传播时被更新,使其含有来自知识图谱的实体关系信息,进而使事件中的施事者或受事者通过共享词向量的形式融入这一信息。
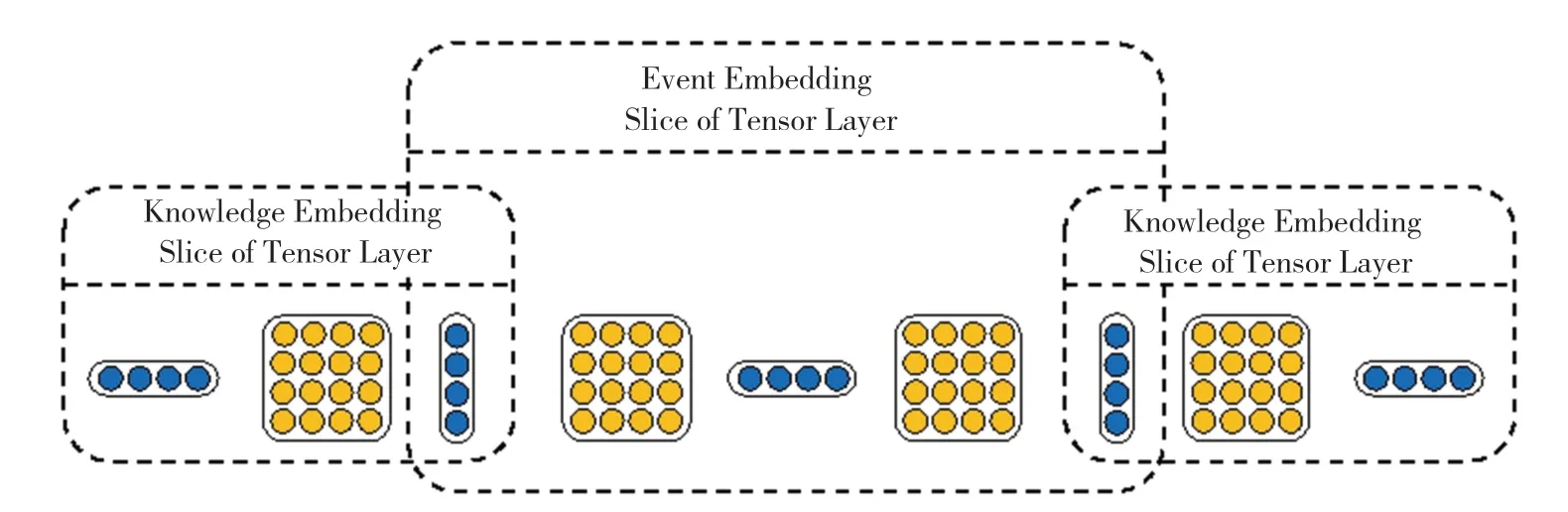
图4 融合实体关系知识的事件表示学习框架结构Fig. 4 Architecture of event representation learning framework enhanced with entity relation knowledge
Lee 等在2018 年提出将情感以及事件主体的有生性信息融入事件表示中。 事件的情感极性会影响后续事件的发生。 例如:带有积极情感的事件“Jenny liked the food”后,往往不会发生带有消极情感的事件“She scolded the server”。 事件元素的有生性也是很有价值的信息,有些事件的主体只能是有生的,还有些事件的含义在主体是无生命事物时会发生变化。 例如:“This song is sick”与“This person is sick”。 该工作将情感极性划分为“消极”、“中性”和“积极”3 个类别,将有生性划分为“有生命”、“无生命”和“未知”3 个类别,并将每个类别映射为一个嵌入向量,训练事件表示与其情感类别、有生性类别的嵌入向量尽可能相似[9]。
Ding 等在2019 年提出将意图、情感等有关参与者心理状态的常识知识融入事件表示中,以帮助更好 地 建 模 事 件 语 义。 例 如: “PersonX threw basketball”与“PersonY threw bomb”两个事件尽管字面上相近,但考虑两个事件的意图,“扔篮球”可能是为了锻炼身体,“扔炸弹”可能是为了杀伤敌人,因此考虑意图信息可以较好地区分两个事件;再如,“PersonX broke record”与“PersonY broke vase”两个事件也在字面上相近,但“打破花瓶”带有消极的情感,“打破纪录”带有积极的情感,因此考虑情感极性信息可以较好地区分两个事件。 该工作提出了一种多任务(Multi-Task)学习方法,加入了两个额外的训练目标,在事件表示中融入意图和情感的信息:对于意图,使用长短时记忆网络,将意图文本编码为一个向量,使用最大边际损失训练事件向量与意图向量尽可能相似;对于情感信息,使用全连接网络对事件向量进行情感分类,并与真实的情感极性标签计算交叉熵损失。 两个额外的训练目标与基于事件内或事件间信息的训练目标进行加权平均,得到最终的损失。 该方法的示意图如图5 所示。 事件的意图和情感信息可由ATOMIC 事件常识数据集与SenticNet 情感字典得到。 实验结果表明意图、情感信息在事件相似度、脚本事件预测、股市预测任务上都带来了有效的提升[13]。
4 结束语
本文对事件表示方法的发展进行了概述。 早期的研究大多基于离散的事件表示,随着深度学习的发展,人们开始探索为事件学习稠密的向量表示,其中基于张量神经网络的方法取得了令人瞩目的效果。 在事件表示的学习方法上,在融合事件内信息和事件间信息的基础之上,融合外部知识的方法带来了新的突破。 本文对各种事件表示方法的特点进行了梳理和总结,以期为后续工作提供参考。

图5 融合意图、情感信息的事件表示学习框架结构Fig. 5 Architecture of event representation learning framework enhanced with intent and sentiment information
