基于双通道卷积残差网络的人脸识别
2020-11-11蔡茂国沈冲冲
吴 涛, 蔡茂国, 沈冲冲, 周 航
(深圳大学 电子与信息工程学院,广东 深圳518000)
0 引 言
人脸识别是计算机视觉领域中的一个非常具有挑战性的课题。 同一个人在不同的姿势、光照和表情(PIE)条件下,看起来是不太一样的,如图1 所示。 为了消除这些因素对人脸识别的影响,本文提出的算法要求在增加个体间变化的同时减少个体内变化。 为此, 研究人员提出了线性判别分析(LDA)、主成分分析(PCA)、贝叶斯分析等子空间人脸识别学习方法以及改进的方法。 LDA 是PCA的增强,PCA 不使用类的概念,而LDA 使用。 同一人的面部图像在LDA 中被视为同一类。 PCA 和LDA 都做了降维,并且它们都以矢量的形式将图像变换到新的空间和新的坐标轴。 其他的改进还包括将人脸图像投影到一个易于分类的子空间中。 除此之外,还有一些基于不同特征表示的方法,例如:局部二值模式、Gabor Filter、Scale-Sobel Filer 和Scaleinvariant feature transform(SIFT)等手工图像算子。结合几种不同的算子,可以获得更高的精度。

图1 不同条件下的同一人脸Fig. 1 The same person under a different illumination environment
在过去的十年中,卷积神经网络(convolutional neural network, CNN)已经成为计算机视觉中一种非常流行的技术,并且取得了显著的成功。 与传统的图像处理方法相比,卷积神经网络在目标检测、图像分类、语义分割等领域取得了很大的成就。 基于卷积神经网络的人脸识别也取得了重大突破。DeepID、DeepID2、DeepID3、FaceNet 和VGG-Face 是需要大量数据训练的人脸识别模型,这些模型可以达到较高的准确率。 为了提高训练速度,Xiang Wu等人提出了一个轻量型的卷积神经网络[1],其计算成本达到了VGG 模型的9 倍以上。 Xi Yin 等人认为人脸识别不是单一任务,他们将人脸识别视为一个多任务问题。 虽然这些卷积神经网络模型已经达到了很高的精度,但是它们需要非常庞大的数据集来训练,由于训练过程中会产生大量的参数,这些方法对计算机硬件有较高的要求。 为了充分利用图像的信息,减轻网络模型的负担,本文提出了一种参数较少的双通道卷积残差网络用于人脸识别。 人脸识别系统的结构图如图2 所示。 首先,利用人脸检测和对齐来消除背景的影响。 其次,通过数据增容来获得更多的训练数据。 最后,利用双通道残差网络进行训练识别原始图像,经过Sobel 算子处理过的图像能够表征人脸的不同信息,因此,利用多通道输入获得不同的人脸特征,将两个通道得到的特征进行融合,经过残差网络进一步的特征提取,最后用于识别。 提取特征之后,使用平均池化层而不是全连接层,这样可以使得网络更加轻盈。 本文提出的模型在FERET、AR 和FEI 数据集上进行了训练和测试。 实验结果表明,该人脸识别算法更有优势。

图2 人脸识别系统的结构图Fig. 2 The structure of face recognition system
本文的主要贡献如下:(1)使用原始图像和Sobel 算子处理过的图像作为网络的输入。 (2)提出了一种用于人脸识别的双通道卷积残差网络。 该模型将多通道卷积神经网络与残差网络相结合,使用平均池化层代替全连接层。 (3)网络模型参数较少,不到300 K,网络模型文件大小约为20 M。 通过与其他模型的相比,本文提出的模型不仅参数少、网络简单,还加快了人脸识别的处理时间。
1 相关工作
传统的CNN 模型如AlexNet、VGGNet 以及新提出的InceptionNet、ResNet 等在图像分类方面取得了显著的效果。 这些方法也可以应用于人脸识别。AlexNet 由Alex Krizhevsky、Geoffrey Hinton 和Ilya Sutskever 组成的研究小组所设计,它比LeNet 更深。AlexNet 首先使用线性整流单元(ReLU)、Dropout 层和局部响应归一化(LRN)来提高CNN 的性能。 在2012 年的全球最权威的计算机视觉识别挑战(ILSVRC)中,该网络获得了15.3%的top-5 错误,领先亚军10.8 个百分点。 VGGNet 是由牛津大学的K.Simonyan 和A.Zisserman 提出的CNN 模型。 整个网络只使用3×3 卷积核和2×2 池化层,VGGNet 表明网络的深度对于特征的提取起着重要作用,网络越深,效果越好。 但是随着网络模型的加深,网络变得越来越难训练,这主要是由于梯度弥散和梯度爆炸导致的,为了解决这个问题,何凯明提出了ResNet,并于2015 年在ILSVRC 中获得冠军。ResNet 可以训练数百甚至数千层网络,并且仍然可以获得非常好的效果,该模型比VGGNet 参数少,收敛速度快。
DeepFace 是Facebook 的一个研究小组创建的人脸识别的深度学习模型,是第一个在440 万张人脸数据库中训练卷积神经网络,采用人脸对齐进行数据预处理,网络参数超过1.2 亿。 据称,该模型在Wild(LFW)数据集中的人脸识别准确率高达97%。然而,由于使用局部连接层,模型的参数出现了指数增加。 为了进一步提高精度,Sun Y、Wang X 和Tang X 采用了多尺度模型。 DeepID 通过深度学习网络来提取人脸深层次的抽象特征,这种特征可以区分出两张不同的人脸,在提取特征后,输入到联合贝叶斯模型,进行人脸验证,DeepID 在LFW 数据集上的准确率达到了97.53%。 Florian Schroff 等人提出了一个名为FaceNet 的系统,该系统可以将原始图片降维到欧式距离空间的映射,其中距离与人脸相似性相关,FaceNet 首次引入三重态损耗。 Visual Geometry Group 提出了一个名为VGG-Face 的模型,该模型结合了VGGNet 和三重态损失。 VGGFace 和FaceNet 使用类似的度量学习方法,并在260万人脸数据集进行训练,在LFW 上准确率达到了98.95%,在YTF 上准确率达到了97.3%。 虽然这些方法在LFW 上达到了很高的精度,但是他们都是通过设计复杂的网络模型来提取人脸特征,都需要大量的数据来训练模型,对计算机硬件的要求比较高。因此,本文主要针对一种轻量级的CNN 人脸识别模型进行研究。
本文提出的人脸识别模型如图3 所示。 它是由两个输入通道构成,包括6 个卷积层,6 个maxpooling 层,1 个残差模块,1 个average-pooling 层和1 个SoftMax 层,具体每层的参数数量如表1 所示,在TensorBoard 上运行的数据流图如图4 所示,残差模块如图5 所示,该模块中总共有三层卷积构成,卷积核分别为1×1,3×3 和1×1。 残差模块解决了网络训练过程中出现的梯度弥散和梯度爆炸等现象。

图3 双通道卷积残差网络结构图Fig. 3 The architecture of dual-channel residual network

表1 双通道卷积残差网络的参数数量统计表Tab. 1 The total params about dual-channel residual network
将大小为64×64 的人脸图像作为两个并行通道的双通道卷积残差网络的输入,把原始图像作为第一通道的输入,利用Sobel 算子提取原始图像的一阶导数特征,并将其作为第二通道的输入。 每个通道都有3 个卷积层,每个卷积层后面都有一个最大值池化层。 这两个通道之间唯一的区别是卷积核的大小不同。 考虑到Sobel 算子处理的图像对轮廓更敏感,在第二通道中,统一选择尺寸为3×3,步长为1 的卷积核,这样做的目的是提取图像小区域的特征。 在第一通道中,除最后一层采用尺寸为3×3的卷积核,其余两个采用5×5 的卷积核。 来自两个通道的特征融合在一个残差模块中,然后经过平均池化层,最后用于分类。 本文将多通道卷积神经网络与残差模块相结合,充分利用融合后的特征,克服了反向传播时造成的梯度消失等现象,这样不仅能提高人脸识别的准确率,还能加快网络的收敛速度。

图4 Tensorboard 可视化模型数据流图Fig. 4 The tensor graph of tensorboard

图5 残差模块结构图Fig. 5 The architecture of residual block
2 前期准备
2.1 数据集
本文将采用3 种不同的数据集进行训练和测试,将数据集以8 ∶1 ∶1 的比例分别划分为训练集、测试集以及验证集,本次使用到的数据集分别为:AR、FERET 和FEI。 AR 数据集是由美国广播公司计算机视觉中心(CVC)的Aleix Martinez 和Robert Benavente 创建的,共包含了4 000 多张彩色的人脸图像。 图像以具有不同面部表情、照明条件和遮挡(太阳眼镜和围巾)的正面视图为特征。 这些照片是在CVC 严格控制的条件下拍摄的,参与者不受穿戴(衣服、眼镜等)、化妆、发型等的限制,每个人参加两次拍摄,间隔14 天。 图6 是来自AR 数据库的部分图像。 FEI 是巴西的一个人脸数据库,包含了一组在2005 年6 月到2006 年3 月之间在巴西圣保罗的圣贝尔纳·杜坎波的FEI 人工智能实验室拍摄的人脸图像,共有200 个人,每人有14 张图像,总共2800 张。 所有的图片都是彩色的,在白色均匀的背景下拍摄,正面直立,侧面旋转可达180 度,比例可能会变化约10%,每个图像的原始大小是640×480像素。 所有面孔主要由FEI 的学生和工作人员代表,年龄在19 到40 岁之间,有着独特的外貌、发型和装饰。 男性和女性受试者的数量完全相同,分别都为100 张。 图7 显示了来自FEI 数据库的部分图像。

图6 AR 数据集Fig. 6 AR dataset

图7 FEI 数据集Fig. 7 FEI dataset
2.2 人脸检测
目前实现人脸检测的方法有很多,本文采用2016 年中国科学院深圳研究院提出的多任务级联卷积神经网络模型[2]来对数据集进行人脸检测,该模型主要采用了3 个级联的卷积神经网络,3 个网络分别为P-net、R-net、O-net。 首先,将图片以0.709 的比例进行缩小,形成一个图像金字塔,P-net会对输入的图片进行第一次判断,把人脸置信度高的图片留下来,去除置信度低的图像;其次,进行非极大值抑制(NMS),将所有图片的置信度进行排序,将置信度最大的人脸图像和其他图像做iou 处理,粗略筛除重复框出的人脸,将输出的图像进一步放进R-net 里面,进一步筛选人脸图像,做非极大值抑制,筛除重复的人脸框。 最后,经过O-net 网络,这是最后一层筛选,也是最精确的一次筛选,最终得到的最精确的人脸框,将人脸的5 个关键的特征点标记出来,其过程如下图8 所示。

图8 mtcnn 人脸检测流程图Fig .8 The architecture of mtcnn
2.3 数据增容
随着网络的加深,训练批次的增加,在数据集不够大的时候,网络训练可能会出现过拟合,除了给网络添加正则化和dropout 以外,还可以进行数据增容,提高网络的泛化能力,常见数据增容的方式有以下几种:(1)图像翻转。 将图像镜面翻转,一般选择水平翻转。 (2)图像旋转。 将图像以一定的角度进行旋转。 (3)图像剪裁。 对原始图像进行一定尺度的裁剪。 (4)图像增强。 将图像变暗或者变明,增强图像的对比度,经过图像增容后的数据集如下图9 所示。

图9 数据增容后的部分数据Fig. 9 The data after data augmentation
2.4 sobel 边缘检测算法
Sobel 算子,有时称为Sobel 滤波器,在图像处理和计算机视觉中,用于图像中的边缘检测[3]。 sobel算子主要应用于边缘检测,在技术上,实际就是一个离散微分算子,用来运算图像亮度函数的梯度的近似值。 在图像的任何一点使用此算子,将会产生对应的梯度矢量或是其法矢量。 最终获取新图像的灰度值,其过程如下:
假设原始图像为I,分别在水平方向和垂直方向求导:
水平方向。 将图像I 和一个卷积核为奇数的矩阵相乘,一般将卷积核的大小设为3,如公式(1)所示。

垂直方向。 将图像I 和一个卷积核为奇数的矩阵相乘,同样,卷积核的大小和水平方向保持一致,如公式(2)所示:

接下来,将水平方向的Gx和垂直方向的Gy进行平方和再开方,得到近似梯度G,如公式(3) 所示:

图10 为通过sobel 算子边缘检测过的图像。

图10 sobel 算子处理过的图像Fig. 10 Images processed by Sobel operator
3 实验
使用MTCNN 人脸检测器来精确定位原始图像中的人脸,利用旋转、裁剪、翻转、缩放等数据增容方法,得到更多的训练图像,将得到的图像归一化为64×64,利用Sobel 算子获取图像的Sobel 边缘映射,最后将这些图像输入到网络。 采用留一法对模型进行评估,首先打乱所有数据的顺序,随机选择其中的80%的人脸图像作为双通道残差网络训练集,剩下的20%用来做测试集和验证集,验证集主要用来调节神经网络的参数。 使用开源的深度学习框架TensorFlow 对模型进行训练。 双通道卷积残差网络的第一通道输入为64×64×3 的RGB 人脸图像,第二通道的输入为64×64×1 的sobel 算子处理后的图像。 为了防止网络过拟合,采用L2 正则化,正则化中的权重衰减设置为0.003,初始学习速率设置为e-4,如果模型不收敛则降低学习率,采用交叉熵损失函数来计算损失,批量大小首先设置为256,然后减少到32。 设置200 个epoch 训练本文的模型,并在必要时增加。 卷积的参数初始化采用截断的正态分布。 本文的模型使用GeForce GTX1050TI-A4G GPU 进行训练。
表2 展示了所提出的模型与FERET 数据集上其他现有方法的人脸识别的准确性的比较,表3 展示了AR 数据集上其他现有方法的人脸识别的准确性的 比 较。 在FERET 数 据 集 中, 本 文 模 型 达到了99.83%的准确性,而CFV 达到了97.55%,而PCANet在FERET 数据集上的准确性是97.26%。在 AR 数 据 集 中, 本 文 模 型 达 到 了 99. 70%的准确性,而LCSPT 和CFV + LRA 的精度为99.16%。通过比较发现本文提出的方法优于其他方法。

表2 在FERET 数据集上的各种方法的准确性比较Tab. 2 Comparision of recongnition accuracies on FERET

表3 在AR 数据集上的各种方法的准确性比较Tab.3 Comparision of recongnition accuracies on AR
接下来,利用已有的VGG16 和ResNet18 模型来验证双通道卷积残差网络的有效性。 VGG16 是一个16 层的卷积神经网络,有13 个卷积层和3 个全连接层。 ResNet18 是一个残差网络,共有18 层,其中1 个卷积层,4 个残差模块,2 个残差单元。 这两个模型的架构如图11 所示。 在相同的配置下实现了VGG16 和ResNet18 两个模型,并在FERET、AR、FEI 人脸数据集上与本文提出的模型进行了比较。 表4、表5 和表6 分别为FERET 数据集、AR 数据集和FEI 数据集的人脸识别准确率,可以看出双通道残差网络的精度有了明显的提高,GPU 时间比VGG16 快3 倍,比ResNet18 快1.5 倍。 结果表明,本文的模型性能优于以前的模型。

表4 在FERET 数据集上不同算法的准确性比Tab. 4 Comparision with different architecture on FERET

表5 在AR 数据集上不同算法的准确性比较Tab. 5 Comparision with different architecture on AR

表6 在FEI 数据集上不同算法的准确性比较Tab. 6 Comparision with different architecture on FEI
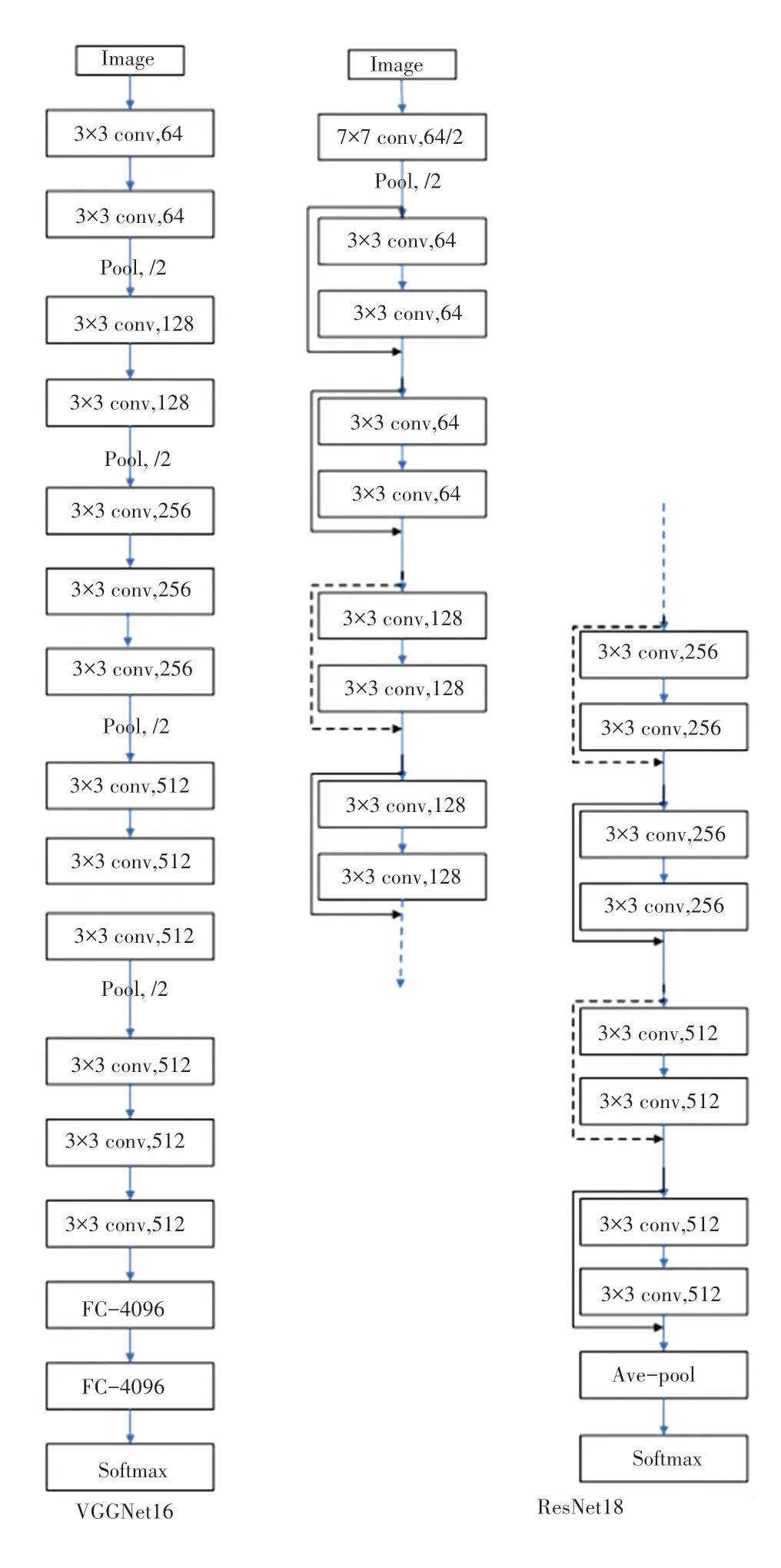
图11 VGGNet16 和ResNet18 网络结构图Fig. 11 The architecture of VGGNet16 and ResNet18
为了进一步比较这些模型的性能,分析了训练和测试中的精度和损失等参数。 AR 数据库中不同模型的结果如图12 所示,比较中可以看出,本文的模型比其他模型收敛更快,获得了更高的精度。 本文提出的模型在训练过程中训练集和验证集的收敛情况如图13 所示,从图中可以看出,在训练100 个epoch 时,模型基本上已经收敛,准确性已经达到一个比较好的结果。

图12 不同模型在AR 数据集上的损失和准确率Fig. 12 The results of different models on AR database
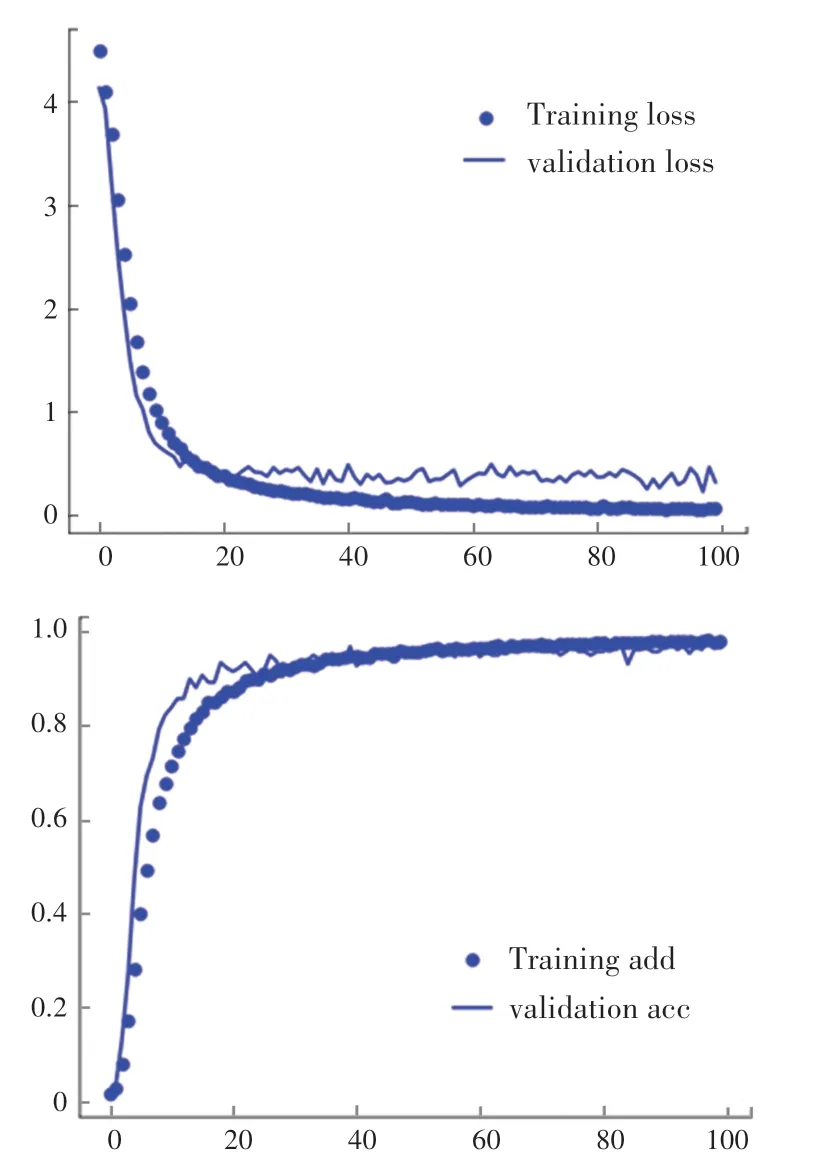
图13 本文提出的模型在AR 数据集上的收敛情况Fig. 13 The results of different models on AR database
4 结束语
本文提出了一种双通道卷积残差网络算法用来做人脸识别,利用双通道输入,将人脸图像的特征充分的利用,sobel 算子能对提取人脸的细节特征更有鲁棒性。 除此之外,该算法还利用到了残差网络,因此整个网络具有卷积网络和残差网络的优点,可以使模型收敛更快,达到更高的精度,还可以防止训练过程中梯度消失,导致网络无法正常训练。 本文的模型在FERET、AR、FEI 数据集上分别达到了99.83%、99.67%、99.20%的准确率,不仅超过了传统方法的性能,而且与深度学习方法具有一定的竞争力。 以上结果表明,本文的模型可以显著提高人脸识别率。 此外,本文模型的每个epoch 的时间大约比VGG16 快3 倍,比ResNet18 快1.5 倍,模型在硬盘上的存储空间仅占19.7 MB 左右,不仅准确性高,速度快,需要的内存小,明显优于其他现有的算法,更具有实用价值。
