基于集成学习模型的二手房价格影响因素分析
2020-10-21潘楚文王佩琪温嘉琪
潘楚文 王佩琪 温嘉琪

摘 要:随着我国社会经济不断发展,房地产行业也逐渐发展扩大。但如今一手房房价过高,而二手房房价适中且地理位置较好,因此人们更倾向购买二手房。本文以广州市天河区的普通二手房为研究对象,选取了15个变量来建立指标体系以此研究影响二手房的房价因素。本文利用集搜客收集二手房信息资料、R-Studio清洗数据,并使用python编程语言建立评估模型从而研究分析影响二手房价格的因素。
关键词:集成学习模型;统计机器算法;二手房价格;房价影响因素;
如今,我国房地产行业的被越来越多的人关注,迫切需要建立一套科学合理的房地产评估模型,为二手房的购买,销售、和其他行为提供有价值的参考。从“中国房价行情”官网中发现二手房平均价格基本呈上升趋势;从2019年3月到2019年6月价格上升趋势稳定在约5万元/平米。随着科学技术的不断创新发展,研究人员已将机器学习算法应用于房地产评估模型,并在实践中不断优化算法。如王勇胜[1]首先构建线性回归模型、时间序列等五种单一评估模型,田一梅[2]首先采用灰色系统对某市生活用水量进行预测,其次将预测结果作为输入,代入偏最小二乘法回归(PLS)模型,结果表明预测误差更低。因此,本文将基于集成学习模型来研究分析二手房影响因素。
1.数据收集与预处理
首先分析归纳二手房交易网站,主要有房屋基本信息、社区配套设施和社區概况等信息,本文提取部分数据信息[3]。为了收集本文所需更为详细的天河区二手房数据,运用集搜客GooSeeKer的层级采集获取天河区二手房房源详细资料。依据内在规则在第一层数据采集下,挖掘第二层详细数据,通过MS谋数台与DS打数机运行工作,搜集天河区的第二层数据资料,此次收集共有1100个数据。
同时,为了提高数据挖掘的质量,使用R语言对数据进行清理。这些数据处理技术在数据挖掘之前使用,大大提高了数据挖掘模式的质量并减少实际挖掘所需的时间。
2.理论基础
2.1随机森林算法
随机森林被称为当前最好的算法之一,2001年Breiman Leo[4]等人提出了随机森林算法,不仅减少预测误差,还可以衡量特征变量的重要性。近年来,它以被广泛应用于经济、管理等领域。
随机森林算法的基本步骤如下[5;6]:
2)采用Bootstrap方法,从训练集中随机抽取n个样本作为新的数据集;
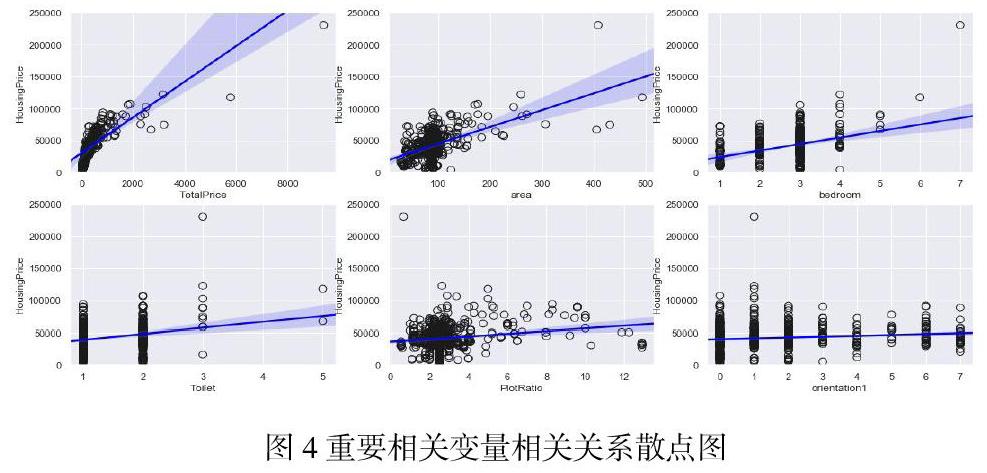
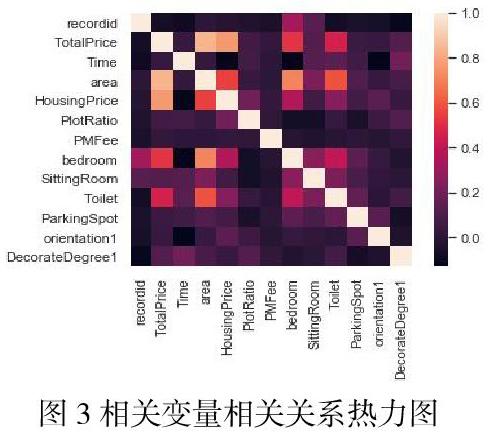
3)基于新数据集构建决策树,并对决策树的每个节点,重复一下步骤,直到节点的样本数达到设定的最小值nmin: 从P个特征值中随机取m(m 4)根据基尼系数或信息增益率准则,从m个随机特征变量中选择最终要的特征变量,分为两个部分; 输出B棵树,针对分类和回归不同问题的预测,对新样本X*在每棵树进行预测,记第b棵树的新样本点X*预测为: 分类对新样本点X*的预测结果为: 2.2梯度提升算法 1)初始化: 2)for m=1 to M 计算负数梯度: 2.3极限树算法 Extra-Trees(Extremely randomized trees,极端随机树)算法与随机森林算法非常相似,并且由许多决策树组成。极限树与随机森林的主要区别: 1)Random Forest应用的是Bagging模型,Extra Tree使用的所有的样本,只是特征是随机选取的,因为分裂是随机的,所以结果在某种程度上要比随机森林好。 2)随机森林在随机子集中获得最好的分支属性,而Extra Tree完全随机地获得分支值,从而实现决策树的分支。 当特征属性为类别的形式时,随机选择具有某些类别的样本为左分支,将具有其他类别的样本作为右分支;当特征属性是数值的形式时,随机选择一个处于该特征属性的最大值和最小值之间的任意数,当样本的该特征属性值大于该值时,作为左分支,当小于该值时,作为右分支。这样就实现了在该特征属性下把样本随机分配到两个分支上的目的。然后计算此时的分叉值(如果特征属性为类别的形式,可以应用基尼指数;如果特征属性是数值的形式,可以应用均方误差)。遍历节点内的所有特征属性,按上述方法得到所有特征属性的分叉值,我们选择分叉值最大的那种形式实现对该节点的分叉。从上面的介绍可以看出,该方法比随机森林更具随机性。 2.4极端梯度提升 XGBoost(eXtreme Gradient Boosting)全名叫极端梯度提升,xgboost归根到底属于boost集成学习方法最终的学习器表示如下: 2.5模型组合Stacking 1992年Wolpert提出集成学习Stacking算法,主要组合多个不同学习器提高预测效果。Stacking算法分为初级学习器和次级学习器。集成学习Stacking算法首先数据集分为训练集(Training Data)和测试集(Test Data)。 第一层初级学习器:训练集采用5折交叉验证,其中训练模型数据集(Learn)占4/5,验证模型数据集(Predict)占1/5,首先选择第一个评估模型Model 1 ,用数据集(Learn)训练模型,将训练好的模型对数据集(Predict)进行预测,在第一次交叉验证后,预测结果记为a1,同理训练集对测试集(Test Data)进行预测结果为b1,这样经过五次交叉验证,训练集得到的预测结果为(a1、a2、a3、a4、a5),将其合并为一列多行的矩阵A;测试集的预测结果为(b1、b2、b3、b4、b5),对各部分预测值对应相加求平均值,结果记为矩阵B,以上步骤为Stacking中第一个基本学习器为Model 1的完整算法流程。 第二层次级学习器:矩阵A为训练集,矩阵B为测试集,构建简单的多元线性回归模型,其中第j个单一评估模型Model j对第i个训练样本点的预测值,作为新的训练集中第i个样本的第j个特征值,即解释变量为不同模型的预测值,被解释变量是实际因变量值。 3.各阶段二手房重要影响变量 本文参照安居客等二手房网站,将房地产评估的相关文献与天河区的内涵和特征相结合,选择总价格、房龄、面积、朝向、楼层与层数、装修程度、房子单价、容积率、物业费用、卧室、客厅、卫生间、参考首付、参考月供、绿化率共15个指标,进而将特征指标分为定性变量与定量变量细分。 采用箱线图方法研究房龄对房价的影响程度,如图1所示: 从图1可知,不同房龄阶段的房价变化趋势比较明显。1900年到1993年的房龄对房价的影响尚未稳定,而1995-1997年、19998-2000年房价则相对稳,但对比前三年房价有下跌趋势,随后2001年到2009年都是逐步回升的状态,且房价保持稳定,而到了2010年到2019年房价略有下降趋势。由此可知,购房者可能偏向于01-09年的二手房。 采用直方圖方法研究二手房房价,如图2所示: 为了研究在不同阶段影响二手房价格的因素。本文首先将房价离散化。其中通过图2可以看出,说明天河区房价主要集中在50K/平方-70k/平方。 同时,由于随机森林具有更好的准确性和稳健性,为了研究所选特征变量是否很好解释并将房价划分,因此本文使用随机森林,对变量重要性度量,利用R语言“RandomForest”包构建模型,进行相关因素的离散化。 3.1影响二手房房价重要因素 颜色越深代表重要性以及影响程度越大,颜色越浅代表重要性以及影响程度越小。特征变量的重要程度主要分为3种,如图3所示: 3.2影响二手房房价相关因素 从图可以看出特征变量的相关程度主要分为6种,如图4所示: 3.3影响二手房变量重要性 采用随机森林对变量重要性的度量,测量的特征变量重要性程度不同,其十分重要特征和一般程度的特征如图5所示: 4.总结 本文得出的结论为天河区的二手房房价主要集中在50k/平方-70k/平方。通过15个变量来建立指标体系以此研究影响二手房的房价因素。房龄、楼层与房价为负相关,地段的繁华程度则与房价呈正比。通过相关关系散点图得出总价、地段与参照首付是消费者首要考虑最重要的因素。其次,房型与绿化率也和房价有相关关系,房型的面积的大小与房价呈正比关系。随着生活质量的提高,人们也越来越注重有氧生活,因此,绿化率也会成为参考首选之一。除了以上的因素外,房子的朝向、物业费用、容积率等因素也对房价有重要的影响。 本文以广州市天河区二手房价格为例,基于天河区的特征变量建立评估模型,进而得出每一种因素的相关影响程度。由于采用单一评估模型可能不具有一致性,而采用模型stacking算法则有效解决这一问题。但是,本文也存在不足,由于本文搜集的数据是二手房网站的挂牌数据,无法获取最终交易价格,因此收集到的数据受到限制,构建的评估模型可能会受到一些影响。 统计机器学习作为统计学领域的新生事物,它的强操作性预示了它不是一个循规蹈矩、墨守成规的形式与手段,更是为统计学的长远发展带来了新的曙光与希望。 参考文献: [1]王勇胜,薛继亮.基于多种模型组合的我国2015年人口总数预测[J].西北农林科技大学学报(社会科学版),2009,9(1):75-79 [2]田一梅,汪泳,迟海燕.偏最小二乘与灰色模型组合预测城市生活需水量[J].天津大学学报.2004,37(4):322-325. [3]张汉中,张倩,董起航等,大数据下基于房屋交易网站的数据获取的二手房价格走势分析——以上海为例[J].黑龙江科技信息.2017(21):142-143. [4]Breiman L.Radom forests[J].Machine Learning.2001,45(1):5-32 [5:6]吕晓玲,宋捷.大数据挖掘与统计机器学习[M].北京:中国人民大学出版社.2016. 作者简介: 潘楚文(1999-), 女,广东省广州人,广东培正学院2017级经济学统计学专业在读学生。 王佩琪(1998-), 女,广东省广州人,广东培正学院2017级经济学统计学专业在读学生。 温嘉琪(1998-), 女,广东省江门人,广东培正学院2017级经济学统计学专业在读学生。
