基于CNN 和粒子群优化SVM 的手写数字识别研究
2020-09-21贺冬葛戴丽珍
杨 刚,贺冬葛,戴丽珍
(华东交通大学电气与自动化工程学院,江西 南昌330013)
手写体数字识别在银行、税务和邮政系统等领域有着重要的应用和广阔的发展前景,尤其在脱机工作环境下有很大的提升空间[1]。 传统的手写体数字识别方法主要有支持向量机[2-4],神经网络算法[5-6]等。 但由于手写数字本身所包含的特征较少,加上不同人书写数字字符差异较大,在识别率方面具有较大的提升空间。以深度学习为代表的机器学习方法的出现[7],大大降低了图片识别的难度,为手写体数字识别提供了有效工具。卷积神经网络由于其“深层结构”的优势,常被用于图片特征提取,并通过Softmax 对相关特征进行分类。尽管该方法具有较理想的处理效果,但对电脑要求过高,且计算复杂、耗时较长。 为了提高手写体数字的识别率,本文拟结合卷积神经网络的特征提取能力、支持向量机的分类能力、粒子群优化的寻优能力,通过CNN 对手写体数字图片进行特征提起,采用粒子群优化SVM 关键参数对数字特征进行识别,从而实现手写体数字的识别。
1 卷积神经网络
卷积神经网络(convolution neural network,CNN)[8]是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
CNN 是一个受生物视觉启发、以最简化预处理操作为目的的多层感知器的变形,它结构的可拓展性很强,可以采用较深的层数,构成的深度模型具有更强的表达能力[9]。 卷积神经网络由一个或多个卷积层(convolution layer)和末端的全连接层组成,同时也包括关联权重和池化层(pooling layer)。 这一结构使得卷积神经网络能够利用输入数据的二维结构,并且也可以使用反向传播算法进行训练。 相比较其他深度、前馈神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构[10]。
1.1 卷积层
卷积层的主要作用是通过对卷积核大小的设置,由浅入深不断对前一层传输的数据进行特征提取。 由于设置了共享权值,在同一特征图中神经元使用同一组卷积核,可以减少训练参数。 其中,卷积核数值在初始化后由后续的网络训练确定[11]。
图片各像素点的值与卷积核的乘积加入偏置后经过激活函数的运算即可得到图片的一个特征映射:

其中:ajL表示L 层卷积后第j 个神经元的输出;wijL表示卷积核;bjL表示偏置。 f(·)为神经元激活函数,这里我们采用Sigmoid 函数,即

1.2 池化层
池化是卷积神经网络中的一个重要操作,能够减少图片中冗余特征,同时保持特征的局部不变性[12]。
图片经过卷积处理后,每个n×n 邻域内的像素点采用最大池化(MaxPooling)的方法变为一个像素

其中:down(·)表示下采样函数,该层运算不包含可学习的权值和阈值。
1.3 全连接层
全连接层可以整合前向传来的具有类别区分性的局部信息;同时,可以增强网络的非线性映射能力;限制网络规模的大小。
2 支持向量机
支持向量机是建立在统计学理论基础上的一种数据挖掘算法, 其工作机理是寻找一个满足分类要求的最优分类超平面, 使得该超平面在保证分类精度的同时, 能够使超平面两侧的空白区域最大化。 理论上,支持向量机能够实现对线性可分数据的最优分类[13]。其原理示意图如图1 所示。
本文使用LIBSVM 工具箱通过一对一的方法来实现分类器的设计构造。 当要对一个未知类别样本分类时,输出结果值最大的即为该样本类别[14]。
经过多年来国内外的研究表明,SVM 以RBF核(径向基函数)为核函数具有很强的学习能力和分类效果。 文中选用RBF 作为SVM 的核函数


图1 支持向量机示例Fig.1 Example of support vector machines
2.1 基于的SVM 的参数优化
在用SVM 做分类预测时若想要提高结果的准确率往往需要对SVM 参数进行优化以选取最优的参数[15](主要是惩罚参数c 和核函数参数g)。
SVM 中惩罚系数c(c 为正数) 用来表征对误差的宽容度;c 值过高或过低均会影响SVM 的泛化能力。参数g 是选择RBF 函数作为Kernel 后该函数自带的一个参数,隐含地决定了数据映射到新的特征空间后的分布。
PSO 首先是在可行解中初始化一群粒子,每个粒子都有自身的速度、位置跟适应值,通过不断的迭代搜索最优解。 在每一次迭代中粒子通过个体最优值跟全局最优值来更新自己。
对于随机初始化产生的粒子,将其视为第一代初始种群,通过目标函数Q(Xi)计算得出的适应度值来衡量种群Xi的优劣。 种群中粒子i 当前最优位置为

其中:Xbesti为粒子i 所经历的最优位置标记;Qbesti为粒子i 位置最优时所对应的适应值。 寻优过程中,粒子不断更新自己的位置跟速度,速度更新公式为

其中:Xbestg为粒子g 所经历的最优位置标记(对应的适应度值应为Qbestg此处没有体现),Vmax为粒子单步更新的速度最大值;c1、c2为加速度常数, 表示PSO 参数局部搜索能力;r1、r2是两个相互独立的随机参数;w为惯性权重,在优化过程中能够起到提高全局搜索跟局部搜索的作用。
位置更新公式为

其中xi=(xi1,xi2,...,xin)表示粒子i 位置向量中的值。
适应度函数的确定是实现PSO 算法的先决条件,更是寻优的依据。 传统方法是寻找或者设计一个函数用以计算适应度值,以显示寻优效果的优劣[16],但计算复杂,使用困难。本文使用CV 算法,将对训练集在CV意义下的准确率作为粒子群中的适应度函数值。
2.2 交叉验证
交叉验证(CV)是一种常用的验证分类器性能的统计分析方法[17]。 关于对SVM 参数的优化选取是将c和g 在一定的取值范围内取值,然后将训练集作为原始数据采用K-CV 的方法对SVM 进行训练,训练后得到的模型再通过验证集验证后得出分类准确率,准确率最高的模型即为最佳参数。 对于可能出现的过学习状态的发生我们选择最佳参数中惩罚参数c 最小的一组(c,g)参数为最优参数。
这里将对训练集进行CV 意义下结果中最好的模型识别准确率作为PSO 的适应度值。 基于PSO 的SVM 全局参数寻优的整体算法过程如图2 所示。
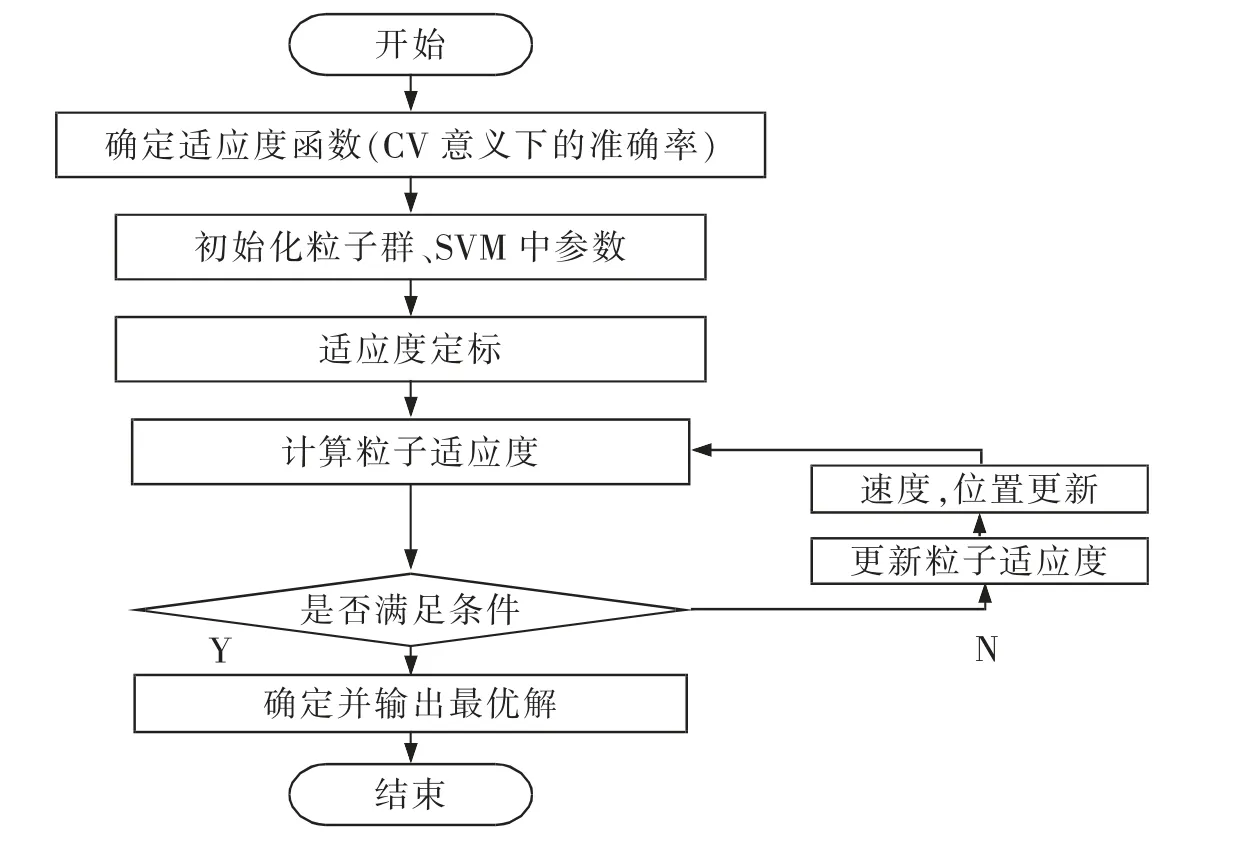
图2 PSO 优化SVM 参数流程图Fig.2 Flow chart of PSO optimized SVM parameters
3 基于CNN 和PSO-SVM 的手写数字识别
为提高网络对手写数字图像的识别精度,本文将卷积神经网络和支持向量机结合,并通过PSO 优化算法优化SVM;PSO 是基于个体间的协作实现搜索空间中的寻优,能很好的提高SVM 的识别性能。
在使用粒子群优化SVM 参数的实验中,相比于随机初始化粒子确定适应度值,本文使用CV 意义下的准确率将其代替,以达到快速收敛的效果。 整体结构如图3 所示。
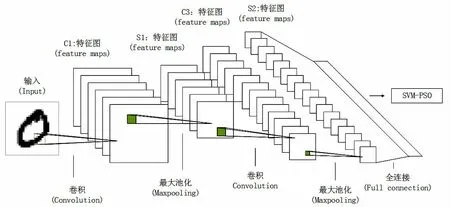
图3 CNN-SVM 整体结构图Fig.3 CNN-SVM overall structure diagram
基于CNN 和PSO-SVM 的手写数字识别流程主要步骤如下:
Step1:将手写数据集分为训练集和测试集;
Step2:通过Python 程序将二维图片数据传入卷积网络输入层;
Step3:图片经过卷积层、池化层得以特征提取跟降维,得到含有特征信息较高的数据集,经全连接层后,数据由二维转换为一维;
Step4:将全连接后的一维数据通过Matlab 传入SVM;
Step5:使用K-CV 的方法将一维的训练数据作为训练数据得到当前组(c,g)的分类准确率,并将其作为PSO 中粒子的适应度函数;
Step6:根据粒子群对SVM 参数的不断寻优,最终确定出最佳的c,g 参数(寻优过程如图4 所示);
Step7:训练完成后将一维的训练集送入最终的模型中进行分类验证,以最终对手写数字图片的分类准确率作为最后的结果。
4 实验与分析
本文设计构建的卷积神经网络包含两个卷积层、 两个池化层和一个全连接层, 分类层采用优化后的SVM 分类器。
通过使用UCI 提供的Semeion 手写数字集及经典MNIST 手写数字集分别对网络进行训练。两数据集均将图片分为0~9 十类,图片显示的手写阿拉伯数字即为该图片的属性类别。 实验中卷积核大小设置为5×5,池化层中采样大小为2×2。
4.1 Semeion 手写数字数据集
UCI 提供的Semeion 手写数字数据集共有80 人参与,每人在非刻意的情况下在纸上快速将数字0~9 手写2 次。 数据集共有1 593 张图片,从中随机抽取1 500 张图片进行实验并将其分为训练集跟测试集, 训练集共有700 张图片,测试集有800 张图片;图片为16×16 像素的一维灰度图片。 每张图片均采用固定阈值将像素点缩放为二进制(1/0)值。 图4 为该数据集石示例图片。

图4 部分手写数字图像Fig.4 Partial handwritten digital images
实验主要是通过使用粒子群对SVM 中的参数不断寻优,以提高分类识别层的识别准确率。 参数c、g 均在一定范围内取值,于是我们根据实验经验设定c∈[0,100],g∈[-100,100],通过初始化选取20 个种群,经过200 次迭代寻优。
实验中我们随机将测试数据集均分为8 组,每组100 个样本进行实验仿真,实验结果如图5~图6 所示。
可以看到100 组图片中只有一张未能识别正确;通过测试验证可知该模型对数字的识别率达99.11%,PSO 寻优最佳参数为c=2.297,g=0.01。
在手写数字识别的实验中,对于每组能够正确识别的图片个数n 将其除以每组图片总数m,得出该组下的识别正确率p,即p= n/m×100%。 至此,将相同的训练测试数据试验在不同的模型中进行对比,结果如表1~表2,图7 所示。

图7 UCI-Semeion 数据集实验结果Fig.7 Experimental results of UCI-Semeiondataset
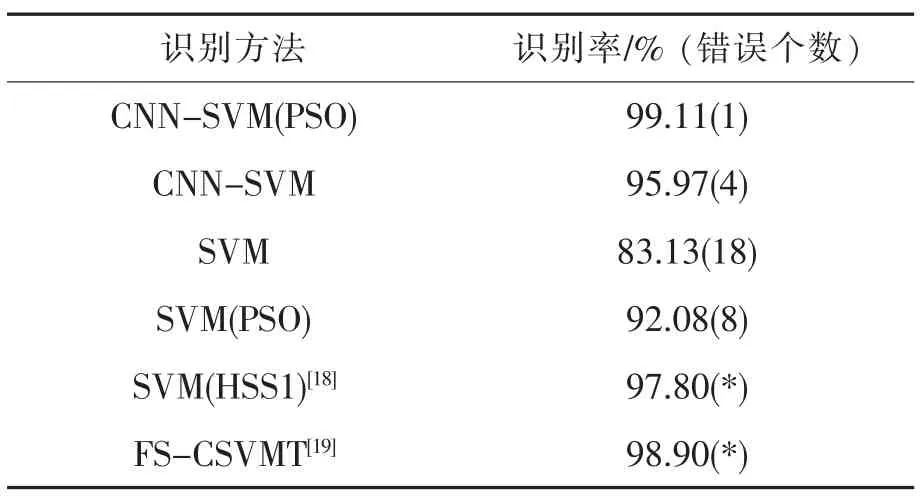
表2 UCI 数据集识别率Tab.2 UCI data set recognition rate
可以看出经过PSO 参数优化后的卷积神经网络结合支持向量机算法精度最高,均保持在95%以上,对处理图片分析上具有一定的优势。
文献[18]显示为SVM 在不同特征情况下在该数据集中的识别精度(文献中实验未显示识别错误个数),可以看到在对SVM 加入不同特征后,本文算法识别正确率仍然高于文献[18]中对应的识别算法。文献[19]中提出了一种基于边界对特征的敏感度值进行特征选择的支持向量机树混合学习模型,其识别率为98.9%。
4.2 MNIST 数据集
MNIST 手写数据集包含70 000 个样本,每个样本为28×28 像素的灰度图片,其中训练集有60 000 张图片,测试集有10 000 张。 图8 为该数据集的部分样例。
由于数据集数据样本较多,此次实验随机从数据库中选取600 张训练图片,1 000 张测试图片,并将测试集随机分为十等份(每份100 张图片)进行测试验证。 表3 显示十份验证集中最优识别情况。
由实验结果可知,本文中采用的方法识别率最高为96%,即100 个随机选取的数据样本中只有4 个未能识别正确。文献[20]使用SOM 简化算法及并行电路架构,采用1 000 组数据进行测试,得到84.13%的准确率。文献[21]中设计了分数阶梯度下降学习机制,在分数阶BP 神经网络中自适应更新连接权值,最终提出的PEO-FOBP 在MNIST 数据集中识别精度有96.54%其对应的未加入极值优化的自适应的PEOBP 算法识别度为95.67%。
对以上实验进行分析可看到,CNN 结合PSOSVM 的算法对分类识别手写数字图片有良好的效果,在一定程度上提高了对图片的的识别率。

图8 MNIST 数据集部分样例Fig.8 Partial sample of MNIST dataset
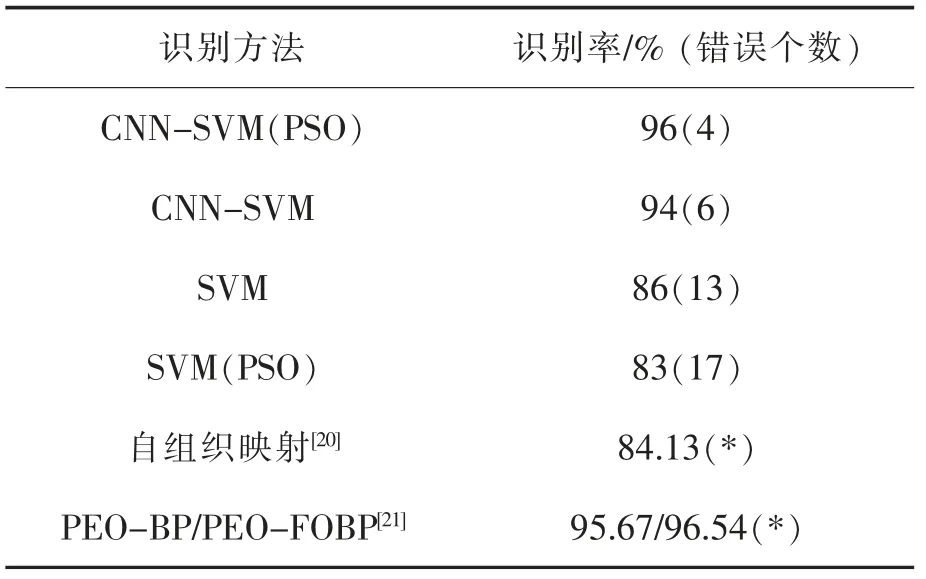
表3 MNIST 数据集识别率Tab.3 MNIST dataset recognition rate
5 结束语
本文提出使用卷积结合支持向量机的方法对图片进行识别,并采用基于K-CV 作为适应度函数的PSO对SVM 参数进行优化,以此提高支持向量机的识别性能。
在图像识别的问题中,卷积神经网络通过自身深度学习的能力获取图像特征,对图像有较高的识别率;传统卷积神经网络使用Softmax 进行分类识别,Softmax 属于线性模型,本身具有分类速度快、模型占用空间小等优势,但使用较强的线性假设,在分类问题上仍有一定的提升空间;进行计算时涉及指数函数的运算,当函数增长时过高的函数值将影响计算机的输出结果,因此对计算机硬件设备有一定的要求。
实验采用Python3.5 与Matlab2015b 作为实验平台, 对UCI 提供的手写图片和MNIST 手写数据集进行分类识别。在确定最佳参数c、g 的值后,最终对两款测试集的识别率分别达到99.11%和96%。然而,在实验过程中也遇到一些问题,比如实验设备比较老旧,对于更复杂的程序难以顺利运行(更深层次的卷积神经网络对硬件设备要求较高),像MNIST 这样文件较大的数据集也很难实现。但对于该次实验设计的网络结构较为简单且实验结果表明该算法识别性能较好,对手写数字正确识别率有一定的提高,因此该算法在研究领域有深入研究的潜在价值。
