C藤Copula自回归模型及其预测
2020-09-18王罗楠李述山
王罗楠,李述山
(山东科技大学 数学与系统科学学院,山东 青岛 266000)
在金融时间序列分析领域,经典的ARMA类模型是目前最常用的平稳时间序列拟合模型,但这类模型本质上是线性模型,不但不能刻画金融时间序列中的非线性相关信息,而且无法解释金融时间序列呈现出的波动聚集、尖峰厚尾等时变特征。Engle[1]提出ARCH模型,将历史波动信息作为条件,采用自回归的形式来刻画波动的变化,克服了ARMA类模型的局限性。随后,Bollerslev提出GARCH模型,克服了ARCH模型滞后阶数过大的缺点[2]。GARCH模型能够迅速捕获聚集性波动,反映金融时间序列中所蕴含的风险,但这类模型同样也无法充分利用金融时间序列中的非线性相关关系。
Copula函数是一类定义在[0,1]上的多维联合分布函数,它能够将多个随机变量的边际分布连接起来得到它们的联合分布,在金融市场间相关性分析、金融风险管理等方面有着广泛的应用。为解决传统Copula模型难以扩展到高维的问题,Joe等[3]在多元Copula的基础上发展了Pair-Copula,将高维随机变量的联合分布分解为一系列边缘分布和Pair-Copula函数的乘积。随后,Tim等[4]基于Pair-Copula理论提出了藤Copula模型,运用图论的方法详细描述了各变量间的连接关系,为构建高维随机变量联合分布函数提供了一种简便清晰的方法。C藤Copula模型是藤Copula模型中应用最为广泛的模型之一,适合描述具有根节点变量的多个变量之间的相关关系。在以往的大部分文献中,Copula函数和藤Copula模型往往被应用于研究多个时间序列之间的相依性[5-6],本文将Copula函数和C藤Copula模型运用于研究严平稳时间序列的非线性自相关性,建立C藤Copula自回归模型,提取序列中有用的信息,并运用模型进行预测。
本文的主要工作是:(1)研究严平稳时间序列的非线性自相关性,建立C藤Copula自回归模型,给出序列相关自变量的筛选方法;(2)给出C藤Copula自回归模型的参数估计方法和预测方法;(3)运用模型进行预测和对比分析,通过实例来说明模型的有效性和实用价值。
1 C藤Copula自回归模型
1.1 C藤Copula模型
考虑n维随机变量(X1,X2,…,Xn),设其联合分布函数和联合密度函数分别为F(x1,x2,…,xn)、f(x1,x2,…,xn),边际分布函数和边际密度函数分别为Fi(xi)(i=1,…,n)、fi(xi)(i=1,…,n)。C藤结构的每棵树Tj有且仅有一个节点连接到n-j条边,这个节点被称为根节点,每条边对应一个Pair-Copula。n维随机变量的C藤Copula密度函数可以表示为[7]
(F(xj|x1,…,xj-1),F(xj+i|x1,…,xj-1))
(1)
式中:j为第j棵树Tj的标号;i遍历所有树的每一条边。
本文运用C藤Copula模型研究严平稳时间序列的非线性自相关性,找出序列中与t时刻条件分布相关的连续滞后项个数,以这些滞后项为自变量建立C藤Copula自回归模型,从而剔除与t时刻不相关的历史信息,更加充分地利用序列的非线性自相关性。
1.2 C藤Copula自回归模型
设{Xt}为一严平稳时间序列,若在t时刻xt的条件分布仅与其前k个滞后项xt-1,xt-2,…,xt-k有关,而与其他滞后项xt-k+1,xt-k,…无关,那么剔除与xt不相关的历史信息,建立以xt-1,xt-2,…,xt-k为自变量,xt为因变量的自回归模型,就能够充分利用t时刻之前的历史相关信息,完成对xt的预测。因此本文将结合C藤结构的思想,建立C藤Copula自回归模型,利用xt的前k个滞后项xt-1,xt-2,…,xt-k,预测t时刻的值xt。
为方便描述,本文将xt节点记为k+1,将其前k个滞后项节点xt-1,xt-2,…,xt-k记为1,2,…,k,作出C藤Copula自相关模型的结构图,如图1所示。
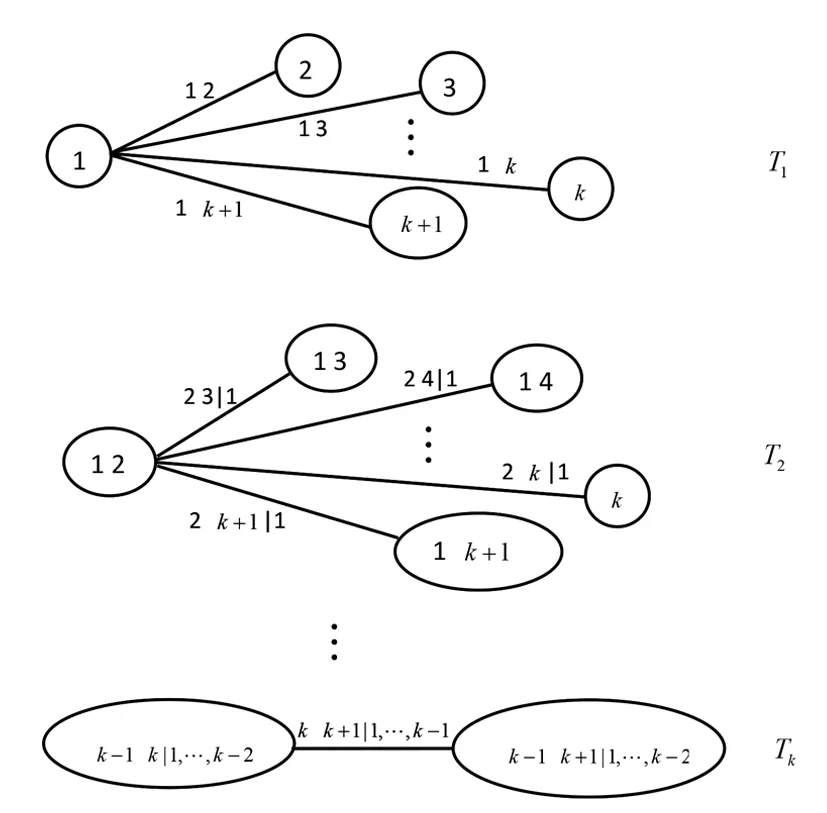
图1 C藤Copula自相关模型结构图Fig.1 Structural chart of the C-Vine Copula autoregressive model
由图1和式(1)得出,条件集为xt-1,xt-2,…,xt-k时,xt的条件密度为
F(xt|φt-i-1))
(2)
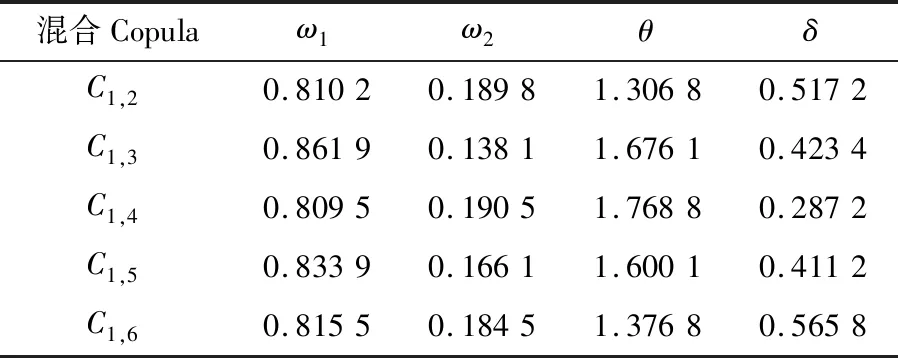
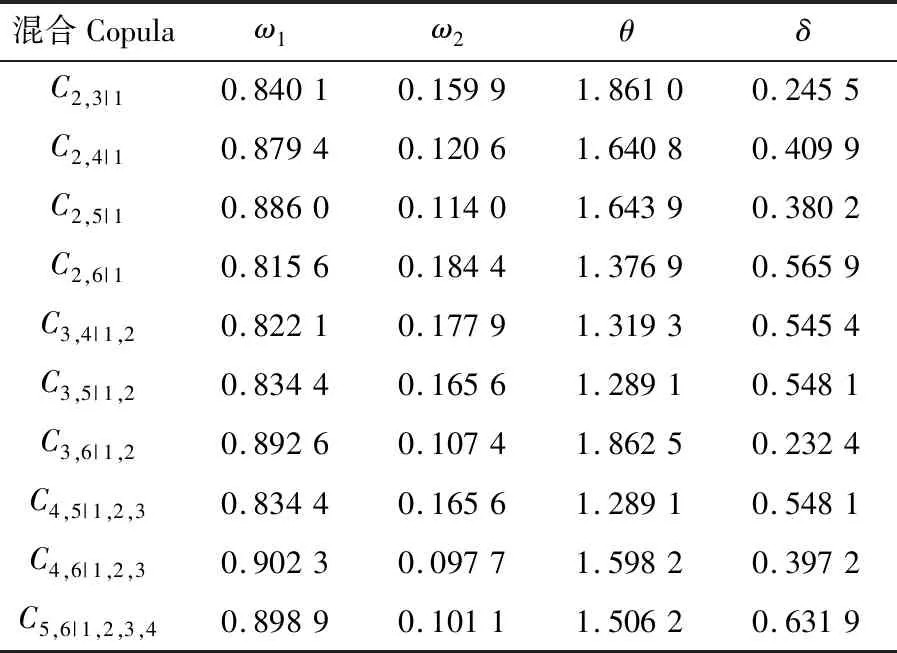
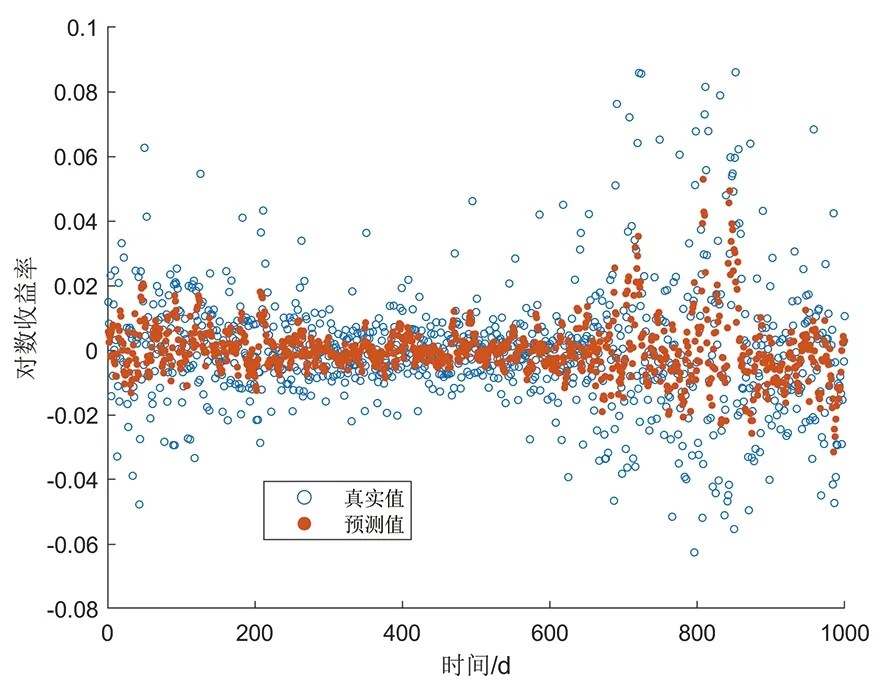
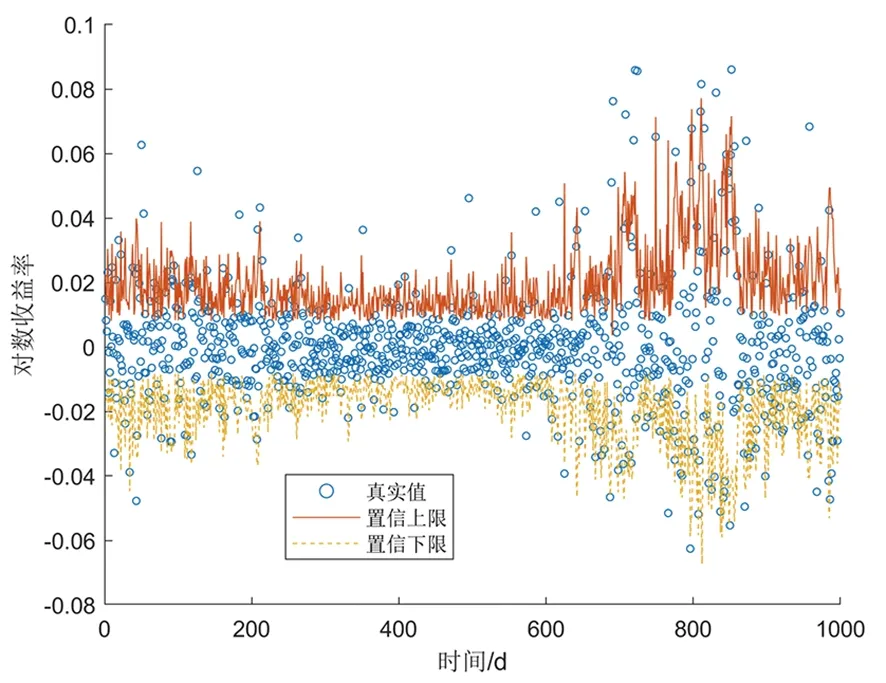
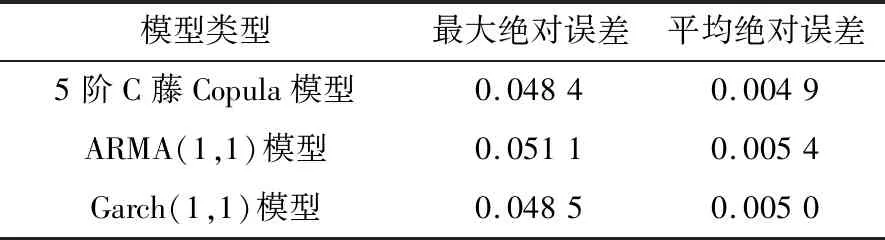
式中:φt={xt-1,xt-2,…,xt-k},表示t时刻前1阶到前k阶滞后项的集合;φt-i={xt-i,xt-i-1,…,xt-k},(1 设与xt相关的连续滞后项个数为k,那么自变量集合为φt={xt-1,xt-2,…,xt-k},结合条件密度函数表达式(2)建立C藤Copula自回归模型: (3) 其回归函数为 (4) 考虑严平稳时间序列{Xt},若存在任一k(k∈N+)满足:对于任意q∈N+,在条件集(Xt-1,Xt-2,…,Xt-k)已知时,Xt与Xt-k-q条件独立;在条件集(Xt-1,Xt-2,…,Xt-k+1)已知时,Xt与Xt-k不条件独立,则称Xt-1,Xt-2,…,Xt-k为序列{Xt}在t时刻的k个相关自变量。 (5) H00:对于任意q∈N+,Hk,1|Φt(Xt|Φt)与Hq,k|Φt(Xt|Φt)独立; 本文采用两步法对模型参数进行估计。第一步估计边际分布参数,第二步估计相关Copula参数。 边际分布有多种拟合方法,由于带位置参数与尺度参数的有偏广义误差分布(SGED)能够很好地刻画收益率序列尖峰后尾的特征,因此本文选取此分布来拟合收益率序列的边际分布。将得出的边际分布函数带入C藤Copula的对数似然函数,便可以对相关Copula参数进行极大似然估计,其中C藤Copula的对数似然函数为[9] …,xt-i+1),F(xt-i-j|xt-1,…,xt-i+1) (6) 式中:θ为Copula参数的集合;T代表观察值的组数。 在实证分析中,为了保证估计精度,本文模型中所涉及的Copula及Pair-Copula均采用混合Copula。由n个不同种类Copula函数得到的混合Copula函数表达式为 MCn=ω1C1(θ1)+ω2C2(θ2)+ …+ωnCn(θn) (7) 式中:ω1,ω2,…,ωn表示n个不同Copula函数相应的权重系数,ω1,ω2,…,ωn≥0,ω1+ω2+…+ωn=1;θ1,θ2,…,θn为相应的相关系数。 (8) [qα/2,q1-α/2] (9) 本文选取近20年共5 081个深证成指每日收盘数据作为样本观察值,数据涵盖1998年1月5日至2018年12月19日,并使用日对数收益率xt=lnpt-lnpt-1(t=1,2,…,5 081)作为研究指标,其中pt表示第t日收盘价。借助Matlab进行数据建模与分析,得到对数收益率序列的描述性统计及ADF检验结果,见表1。 表1 描述性统计及ADF检验结果Tab.1 Descriptive statistics and ADF test results 由表1可知xt序列偏度为负值,峰度为6.518 7,因此序列为有偏的,且表现出显著的尖峰厚尾特征。ADF检验统计量的值为-67.480 1,对应P值接近0,在0.01的显著性水平下拒绝原假设,表明对数收益率序列为平稳序列。 3.2.1 边际分布 鉴于xt为有偏的、具有显著尖峰厚尾特征的序列,因此本文采用有偏广义误差分布(sged)拟合序列的边际分布,并通过K-S检验进行拟合优度评估。得出边际分布参数的最大似然估计值及K-S检验结果,见表2。 表2 边际分布参数估计及K-S检验结果Tab.2 Parameter estimation of marginal distribution and K-S test results 其中μ、σ、k、λ分别为有偏广义误差分布的位置参数、尺度参数、分布参数和偏度系数。表中K-S检验的H值为0,并且K-S统计量及其概率值表明,没有充分的理由拒绝“xt的边际分布符合有偏广义误差分布”的原假设。 3.2.2 Copula函数参数估计 本文采用混合Copula对所涉及的Copula及Pair-Copula函数进行拟合。由于双参数的BB1 Copula函数能够较好地描述非对称的上下尾相依性,同时本文所涉及的变量间具有较弱的非线性相关性和较强的独立性,而独立Copula能够较好地刻画这种独立性,故本文选用BB1 Copula和独立Copula[10]的混合Copula对所涉及的Copula及Pair-Copula函数进行拟合。 根据图1依次画出k=1,…,i(i∈N+)时收益率序列的自相关结构图,结合本文给出的参数估计和假设检验方法分别对所求出的条件分布函数进行水平为0.05的独立性检验,在k=5时接受原假设H00和H10,确定对数收益率序列xt在t时刻相关自变量的个数为5,故建立5阶C藤Copula自回归模型。 假设检验及模型建立过程中所涉及的Copula和Pair-Copula参数估计结果见表3和表4,其中独立Copula和BB1 Copula的权重ω1、ω2以及BB1 Copula的参数θ、δ通过EM算法[11]进行估计。 表3 Copula参数估计结果 Tab.3 Copula parameter estimation results 表4 Pair-Copula参数估计结果 Tab.4 Pair-Copula parameter estimation results 3.2.3 模型预测 通过建立5阶C藤Copula自回归模型,本文可以对收益率序列时刻6及其以后的点进行预测。运用本文给出的预测方法,作出收益率序列最后1 000个真实值与C藤Copula自回归模型预测值对比效果图,如图2所示,收益率序列的最后1 000个真实值与C藤Copula自回归模型置信度为95%的置信区间对比如图3所示。可以看出,预测值与置信区间具有显著的时变特征,实际值趋于密集时预测值相对密集,实际值趋于离散时预测值也趋于离散,置信区间将大部分真实值包含在内。 图2 真实值与预测值对比图Fig.2 Contrast chart between real value and predicted value 图3 真实值与95%置信区间对比图Fig.3 Comparison between true value and 95% confidence interval 为了显示C藤Copula自回归模型的预测效果,本文将5阶C藤Copula自回归模型的预测结果分别与ARMA(1,1)模型和Garch(1,1)模型进行对比,结果见表5和表6。由表5可知,从平均绝对误差的角度来看,5阶C藤Copula自回归模型的预测效果优于ARMA(1,1)模型,与Garch(1,1)模型的预测效果相当,但最大绝对误差相对较小,因此总体上可以认为5阶C藤Copula自回归模型的预测效果优于ARMA(1,1)模型和Garch(1,1)模型。由表6可知,在95%置信水平下,5阶C藤Copula模型的置信区间所包含的真实值百分比最大,并且非常接近置信水平,因此从置信区间角度来看,5阶C藤Copula模型的预测效果同样优于ARMA(1,1)模型和Garch(1,1)模型。 表5 预测结果对比表 Tab.5 Comparison table of prediction results 表6 95%置信水平下置信区间对比表Tab.6 Confidence interval contrast table under 95% confidence level 1)通过运用C藤Copula理论,建立了C藤Copula自回归模型,给出了严平稳时间序列某一时刻相关自变量个数的确定方法,从而剔除了不必要的历史信息,提高了预测精度。 2)基于C藤Copula自回归模型对深证成指5 081个日收益率数据进行了实证分析,并将预测结果与ARMA(1,1)模型和Garch(1,1)模型做比较,结果显示预测效果优于ARMA(1,1)模型和Garch(1,1)模型,从而证明了模型的可行性和实用价值。 3)本文的研究方法还有待改进。在实际操作方面,边际分布有多种拟合方式,可以选择不同的拟合方式比较择优,此外,对混合Copula估计可以引入更多的Copula函数;在实际应用方面,C藤Copula自回归模型还可以运用于风险价值分析,如VaR、CVaR估计等。1.3 相关自变量筛选方法
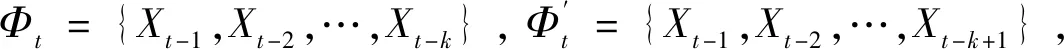
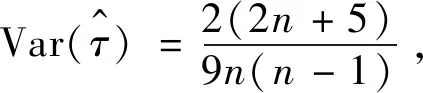
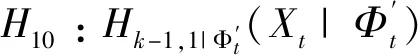
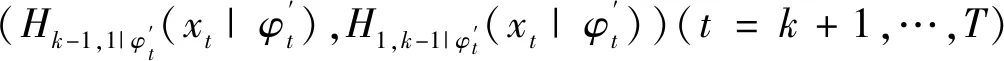
2 参数估计及预测
2.1 模型参数估计
2.2 模型预测方法
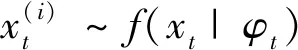
3 实证分析
3.1 数据的描述性统计及平稳性检验

3.2 模型建立


4 结束语
