基于机器深度学习的智能材料预审模型构建
2020-09-16周向明贝聿运
周向明 贝聿运
摘要:近年来,机器人过程自动化(RPA)因代替人工操作电脑以实现业务自动化而备受瞩目。从业务流程自动化(BPA)到机器人过程自动4GRPA,商业领域基于规则自动化业务流程,有效简化了企业运营并降低成本。本文探讨了如何基于机器深度学习构建智能材料预审模型,简化政务领域材料预审人力成本,以期为各地“一网通办”线上线下实现申请材料预审智能化、自动化提供可供借鉴参考的方法。
关键词:智能材料预审;深度学习;Faster R-CNN;OCR;NLP
随着各地“一网通办”工作的深入推进,越来越多的政务服务实现在线可办。与此同时,由于线上线下服务不同源、申请人业务不熟悉等原因,申请人容易提交不规范、不完备、无关联的“无效电子材料”,导致用户材料反复补正、在线申报效率较低。本文在通过引用深度学习技术、OCR技术和NLP技术,构建智能材料预审模型,推动实现智能材料预审场景的落地应用,有效减少用户提交“无效材料”的情况,提升审批效率,增进企业及群众办事便捷度和获得感。
1智能材料预审要点与核心问题
1.1行政预审材料受理要点
在日常审批过程中,审核人员主要关注三个方面,即申请内容的完备性、一致性和规范性。完备性是指申请人是否提供数量完整的材料,材料包含的内容和要素是否全部涵盖。一致性指申请材料与填报内容是否一致,材料与材料之间的关联信息是否一致。规范性指申报内容和材料类型是否符合常规、常识;申报内容和材料的格式是否满足申报条件和法律規章制度要求。
1.2智能材料预审需解决的两个核心问题
针对审核人员的关注要点的分析和技术论证,要实现智能材料预审需重点解决两个问题:一是如何提取申请人上传附件材料中的关键信息;二是如何自动鉴别非固定版式材料的申请内容,如何自动核验非固定版式材料的规范性。
(1)附件材料关键信息要素提取
针对申请附件材料的关键信息提取问题,本文分析常见的行政审核材料类型,提出相应技术解决方案。常见的附件材料主要分为两类:
2.2关键技术
(1)材料信息识别——基于深度学习的OCR模型构建
1)固定版式材料:如证照类、图纸类、照片类;承诺书、通知书、表格类等。这类材料格式比较固定,通过基于深度学习的OCR(光学字符识别)技术能够实现关键信息的快速准确提取。
2)非固定版式材料:证明类(婚育证明、表格类等)、文档类(告知承诺、判决书等),这类材料一般没有有统一模板,需要针对每类材料进行要点识别提取和分析建模,通过深度学习技术结合光学字符识别(OCR)技术,快速完成历史材料数据的关键信息标注,自动生成抽取模型。
(2)申请内容信息处理
对于非固定版式材料申请内容、材料的规范性辨别,本文采用自然语言处理技术(NLP)和规则模型算法,通过机器学习自动处理大量重复性、基于规则的预审业务流程,模拟人工操作路径,完成业务信息的查询和校验,自动判断申请内容的规范性。
2智能材料预审模型构建
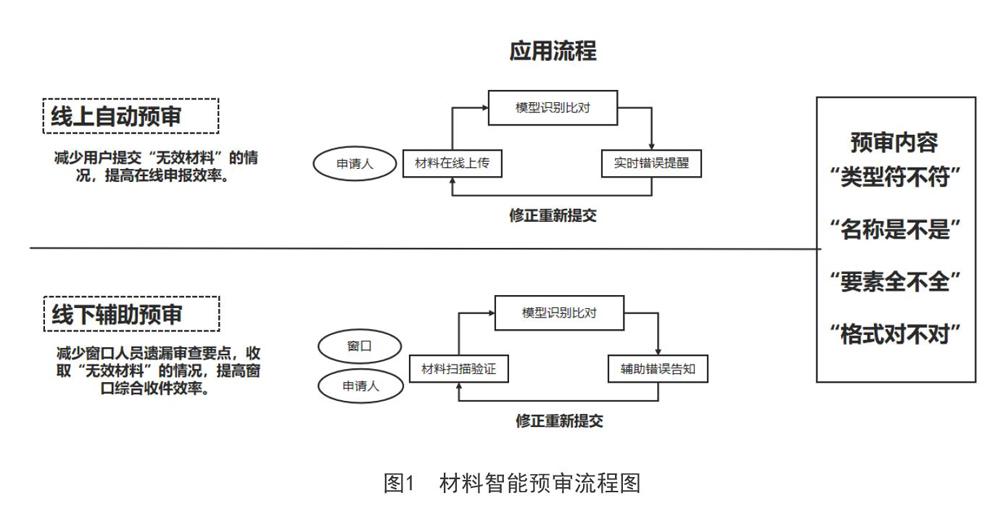
2.1智能预审流程
本文构建的材料智能预审流程如图1所示。材料智能预审可分为线上自动预审与线下辅助预审。当申请人在线上提交材料时,通过智能材料预审模型识别比对,对申请人提交的材料进行在线核验,对申请人提交材料存在的错误实时提醒。当申请人在“综合窗口”进行业务办理时,通过OCR识别、扫描验证等方式将申请材料识别处理,基于材料智能预审模型识别比对,辅助工作人员错误告知申请人。
OCR技术在智能材料预审中的作用主要是信息识别提取,基于现有技术和材料预审涉及的OCR场景为受控场景,本文构建了基于深度学习的OCR模型框架,模型架构由四个部分组成,输入材料图像、基于Faster R-CNN受控场景文字定位、基于序列识别学习的文本识别、识别输出结果。
1)基于Faster R-CNN的受控场景文字检测
对于受控场景(如身份证、营业执照等)的文字检测,采用基于Faster R-CNN算法的关键字检测。Famer R_CNN算法结构由RPN(候选区域生成网络)和RCN(区域分类网络)两个子网络组成。RPN通过监督学习的方法判断候选框是否为目标,输出结果为无标签的区域和粗定位结果。RCN引入类别概念,对候选区域进行分类损失和位置回归,输出精细定位结果。Faster R-CNN整个网络流程都能共享卷积神经网络提取的特征信息,可以通过多次检测确定不同粒度的文本区域。
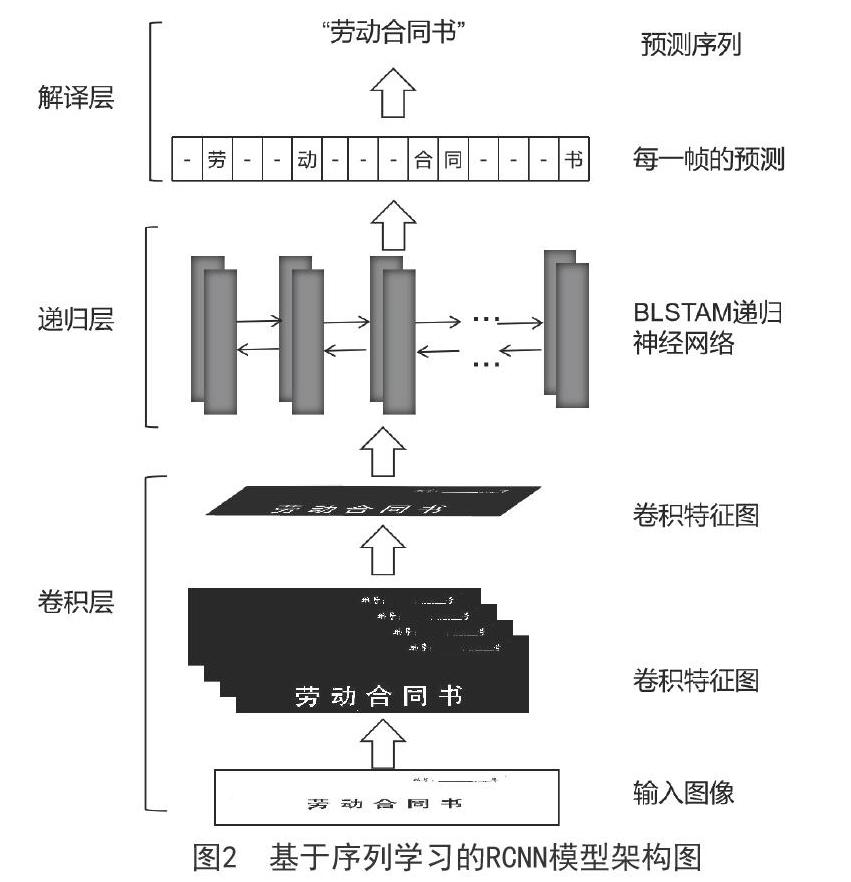
2)基于CNN序列学习的文本识别
基于序列学习的文本识别网络结构分为三层:卷积层、递归层和解译层。模型构建过程如图2所示,首先通过卷积层网络神经模型(CNN)提取字符特征,生成卷积特征图;其次在递归层,利用基于双向长短期记忆神经网络(BLSTM)的递归神经网络作为序列学习器,学习特征序列中字符特征和字符的先后关系,有效建模序列内部关系;最后在解译层,通过CTC(联结主义时间分类器)操作将每一时刻的预测结果联合起来,去掉空白和重复的模式,就形成最终的序列预测结果文本“劳动合同书”。
(2)材料信息处理—基于深度学习的自然语言处理技术
对于已经识别提取的材料信息,需进行文本语义分析。本文采用NLP最新算法BERT(Bidirectional EncoderRepresentations from Transformers),使政务领域材料预审中的关键信息抽取、材料预审合规性检查等需要认知参与的复杂任务实现智能化、自动化的应用效果。输入表示
针对不同的输入表示要求,可以在一个词序列中表示单个文本句或一对文本。对于给定的词,表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)三部分求和组成。
1)预训练任务
本文引用一个下一句预测任务NSP(Next SentencePrediction)进行句子之间关系理解模型的训练。训练语料从预审材料语料库中抽取包括A和B的两个句子进行生产,其中50%的概率是A是B的下一句,50%的概率是A是语料库中的一个随机句。NSP的任务是通过获取句子间的信息预测A是否是B的下一句。
2)算法模型构建
本文通过四个阶段构建BERT模型。
①开启混合精度实现训练加速,使用混合精度训练可以加速训练过程并且减少显存开销;
②在通用型材料预审语料基础上加入个性化材料语料进行模型训练;
③预训练过程中融入政务知识图谱中的实体信息,这种基于符号语义的计算模型,可以为BERT提供先验知识,使其具备一定的常识和推理能力;
④在业务数据上进行微调,支持不同类型的业务材料预审。
(3)规则算法构建
规则应用算法指对材料格式纠错、文字纠错、表单纠错、材料与材料之间的关系校验功能进行算法设计和加工,每个功能点都有独立的算法和规则。
1)两项关键工作——规则和数据
“规则”和“数据”是实现材料智能预审两项关键工作。规则是通过深度学习,梳理不同类型材料的预审规则,构建预审规则模型;数据是指基于政务知识图谱产生的大量材料文本数据,基于前面输入的预审规则模型进行大规模样本训练。完成上述两项工作后,从召回率和准确率两个方面,对于系统智能预审效果进行衡量,以提升模型计算能力。通过规则的梳理分析,训练样本的不断输入,持续地反馈和优化算法,逐步提高召回率和准确率。
2)业务规则分类
材料预审由于涉及的业务及材料类型多种多样,还需对不同类型材料和不同审批事项的业务规则进行分类。本文应用深度卷积神经网络(CNN)作为典型的监督学习方法,基于迁移学习对模型进行微调。模型迁移通过固定网络特定层次的参数,用目标域的数据来训练其他层次。对于业务规则分类任务而言,首先根据分类的类别数修改网络输出层,接着固定较浅的卷积层,基于业务标注数据训练网络倒数若干层参数。相比于直接提取图像的高层语义特征来进行监督学习,采用分阶段的参数迁移对原始域与目标域间的差异性更健壮。
基于深度学习的业务规则分类与检测方法替代传统机器学习方法,在构建的预审模型与迁移学习的基础上,通过从海量数据中的持续学习,实现了材料预审场景落地。
3结束语
随着各地政府越来越多的探索“秒批”、“无人干预自动审批”的实现,本文研究的基于深度学习构建智能材料预审模型的方法,对政务领域实现材料智能预审具有重要意义,也为审批智能化提的后续发展提供参考借鉴的方法。同时,本研究也存在以下不足:一是模型运转效能还需通过实验应用进行检测,二是模型应用落地的场景還有待丰富。这些不足也构成了本文后续的研究方向。
