改进的均值插补不完备数据聚类算法
2020-09-08王平心
施 虹, 杨 鑫, 王平心
(1.江苏科技大学 计算机学院, 镇江 212003)(2.江苏科技大学 理学院, 镇江 212003)
聚类分析是数据挖掘与机器学习的重要技术之一[1],广泛应用于商务智能、图像处理[2]、生物信息学[3]、安全保障[4]等多个领域.同时作为一种无监督学习技术,在识别无标签数据的隐藏结构方面发挥了极大的作用.现有的聚类算法大致可以分为两大类:层次聚类方法和划分聚类方法[5].根据相似性度量可以将相似度高的样本划分到同一类簇中,使得同一类簇中样本的相似度达到最大而不同类簇中样本的相似度达到最小[6].
然而,在实际场景中,由于随机噪音、数据丢失、数据获取困难、数据误读等原因造成了一些数据值的缺失.根据文献[7-8]提出的分类法,缺失数据被分为完全随机缺失(MCAR)、随机缺失(MAR)以及非随机缺失(NMAR).由于缺失数据的出现,传统的聚类算法无法直接处理这些数据.因此,如何解决缺失数据的聚类问题成为聚类分析研究中一个亟待解决的难题.针对缺失型数据,文中研究的数据对象是完全随机缺失型数据(MCAR).
如何对缺失数据进行有效填充是解决不完备数据聚类的一个关键之处.目前不完备数据填充方法有很多如:均值插补、回归插补、多重插补、热卡填充、冷卡填充[9];通过迭代产生最大似然估计值的EM算法[10];使用频繁出现的属性值替代缺失值的最常见属性值法[11];由文献[12]提出基于互信息的最近邻方法评测缺失值以及文献[13]通过不完备数据对象的k个邻居的均值填充缺失数据.
国外的学者在已有聚类算法的基础上提出了不完备数据的聚类策略,如文献[14]提出了4种基于FCM算法的聚类方法:Whole Data Strategy(WDS)、Partial Distance Strategy(PDS)、Optimal Completion Strategy(OCS)、Nearest Prototype Strategy(NPS).同时国内学者也探讨了众多方法如:文献[15]使用区间形式来估计缺失的属性值、在OCS-FCM算法的基础上引入属性权重的思想[16]、将遗传算法和FCM算法相结合在得到最终聚类结果时得到对缺失数据的最佳估计值[17];文献[18]提出RFCM算法处理不完备数据;文献[19]提出基于q近邻不完备数据三支决策聚类方法;文献[20]提出一种不完备混合数据集成聚类算法.
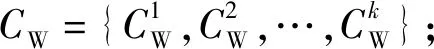
1 相关工作
1.1 聚类算法
James Macqueen于1967年提出k-means算法[21],是数据挖掘中的一种常用聚类分析算法,应用于计算机视觉、市场划分、天文学以及地质统计学等多个领域[21].k-means算法简单快速,处理大规模数据集也能保持可伸缩性以及高效性.然而,k-means算法也存在一些不可避免的缺陷:① 类簇数k值需要事先给定;② 该算法对初始值比较敏感,不同的初始值会不产生不同的聚类结果;③ 算法很容易陷入局部最优解.具体步骤见算法1.

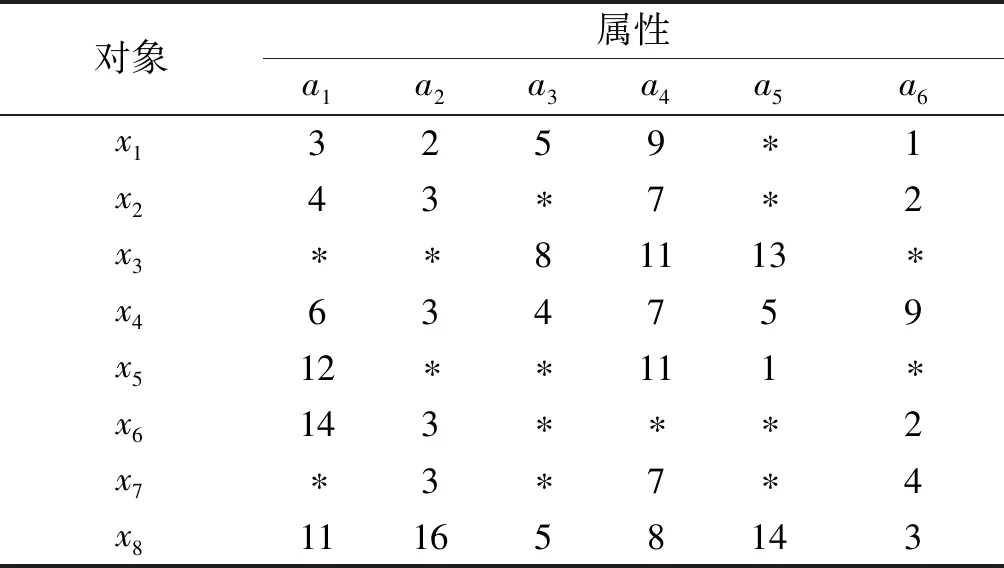
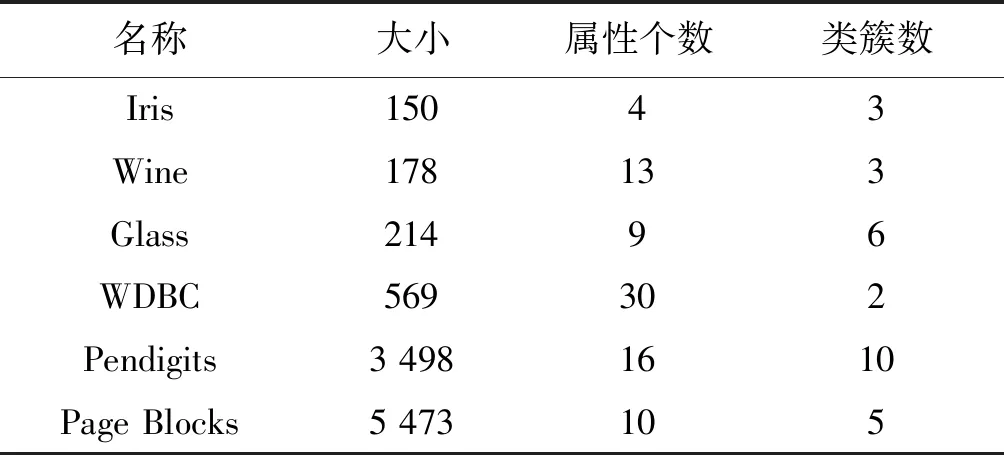
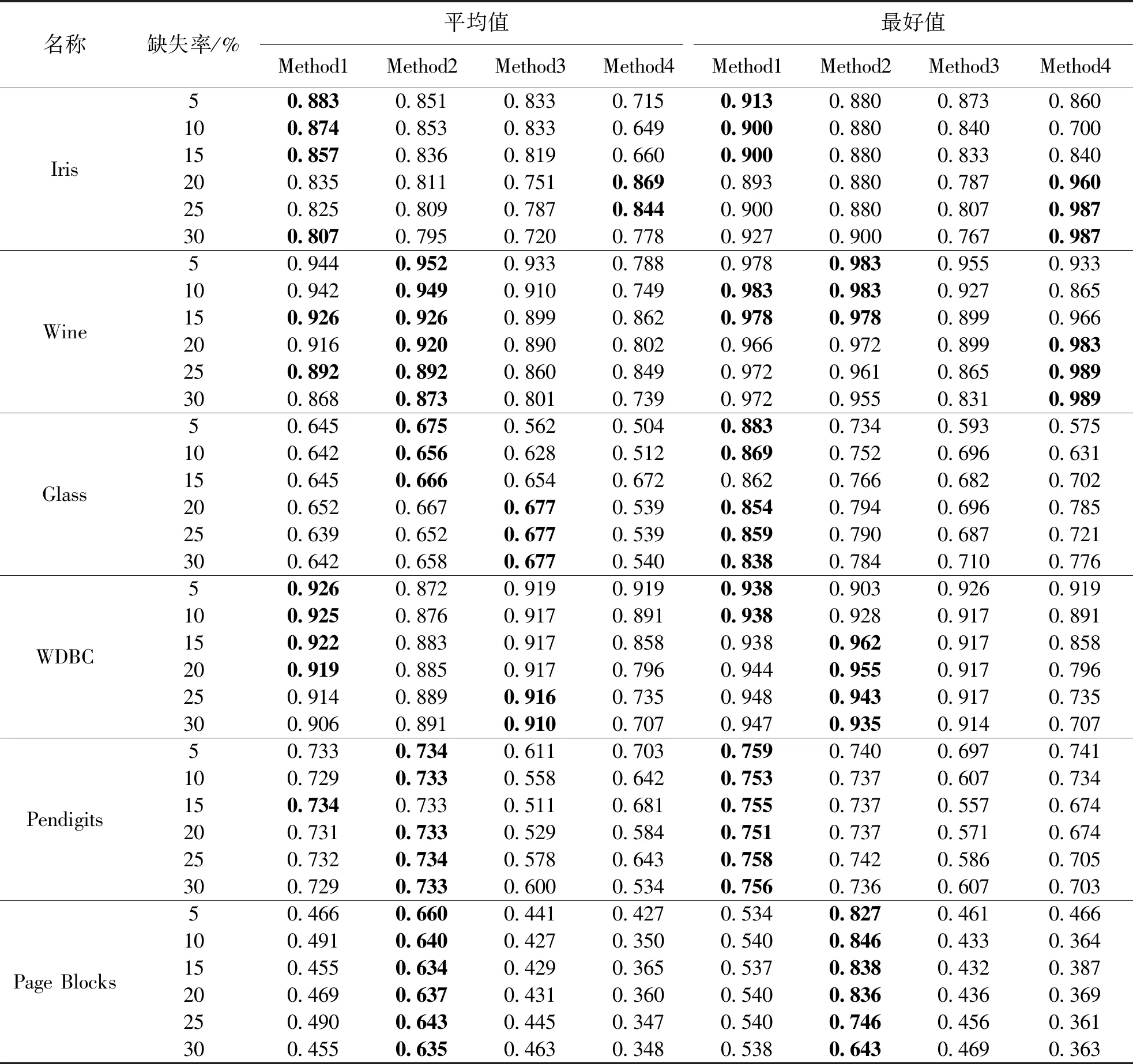
算法1:k-means算法输入:数据集U={x1,x2,…,xn}∈Rm,聚类数k.输出:聚类结果C={C1,C2,…,Ck}.Step1:从U中随机选择k个数据对象作为初始“簇中心”向量:z1,z2,z3,…,zk,其中k 原始的k-means算法易于收敛到局部最优解并且对初始数据敏感.为了能在任意形状样本空间聚类并收敛到全局最优解,提出了谱聚类方法[22].它是基于图论的无监督学习方法,其实质是将聚类问题转化为图的最优分割问题.算法2中为谱聚类算法的详细过程. 算法2:谱聚类算法输入:S={s1,s2,…,sn}∈Rm,聚类数k,参数σ.输出:聚类结果C={C1,C2,…,Ck}.Step1:构造对应的相似矩阵A,其中Aii=0,Aij=exp(-‖si-sj‖2/2σ2)(i≠j);Step2:定义对角矩阵D,其中元素dii的值等于矩阵A第i行元素的和(i=1,2,…,n),构造矩阵L=D-12AD-12;Step3:求解矩阵L的前k个最大特征值以及与之对应的特征向量,构造矩阵X={x1,x2,…,xk}∈Rn×k;Step4:单位化X得到矩阵Z,Zij=Xij/(∑jX2ij)1/2;Step5:将矩阵Z中的每一行看成是Rk空间中的样本点,使用k-means聚类算法进行聚类;Step6:最后,样本点si聚类于类j中当且仅当矩阵Z的第i行被聚于类j中;Step7:返回聚类结果C={C1,C2,…,Ck}. 信息系统(Information System)也称知识表达系统(Knowledge Representation System).它用一个四元组来表示S={U,A,V,f}也可以简写成S={U,A}.U={x1,x2,…,xn}是有限非空数据集称为论域,n为论域中的样本个数;A={a1,a2,…,am}是有限非空属性集,m表示数据对象的属性个数;V={V1,V2,…,Vm}为属性的值域集,Vi是属性ai的值域;f是信息函数,f:Vik=f(xi,ak)∈Vk,Vik为数据对象xi在属性ak上的取值.例如,xi表示论域中的第i个数据对象有m维属性,即xi={xi1,xi2,…,xim},其中xil(i≤n,l≤m)为样本xi在l维属性上的取值. 当数据对象含有缺失数据时,信息系统S是一个不完备信息系统(Incomplete Information System),如表1,不完备信息系统中有8个数据对象且每个数据对象有6个属性,表中的“*”表示缺失数据. 表1 不完备信息系统Table 1 An incomplete information system 该算法需要在完备数据集的聚类结果的基础上对缺失数据进行填充聚类.在大多数情况下,数据集中的缺失率越高,聚类结果的准确性越低.由于缺失率越高,不完备数据填充的准确性也会降低,直接导致聚类算法的性能下降,故对数据集的缺失率有一定的要求,即该算法仅适用缺失值较少的数据集.文中数据集的缺失率分别设置为5%、10%、15%、20%、25%、30%. 算法3:填充不完备数据聚类算法输入:不完备数据集U={x1,x2,…,xn},聚类数k.输出:聚类结果C={C1,C2,…,Ck}.Step1:给定数据集U,根据特定缺失率(5%~30%)随机选择一些缺失的特征值来获得不完备的数据集U,其中缺失值的随机选择受两个条件的约束:每个原始特征向量至少保留一个分量;每个特征在不完整数据集中至少存在一个值.Step2:将数据集U划分为两个互不相交的子集UW和UM,其中UW∪UM=U;Step3:使用算法1或者算法2处理UW中的数据对象,获得聚类结果CW={C1W,C2W,…,CkW};Step4:UM中对象x通过式(1)进行填充,获得填充结果xl={x1l,xl2,…,xkl}(l∈{1,2,…,m});Step5:为了验证填充后的样本对象对各类簇聚类中心值的影响程度并能获得最佳填充值以及该样本所属类簇,分别往每类CiW中添加(|CiW|/k)个相同的样本x,得到新的类Ci∗W;Step6:使用式(2)重新计算聚类中心值;Step7:计算新旧聚类中心的差值di=|zi-z∗i|;Step8:选择最小的di(i=1,2,…,k),确定样本x的所属类以及缺失属性值的填充值;Step9:重复执行Step4~8直到UM=⌀;Step10:使用相应的算法1或者算法2再次处理填充后的数据集U,获得最终的聚类结果;Step11:返回聚类结果C={C1,C2,…,Ck}. 算法的第一阶段,可以根据不完备信息系统的定义来区分完备数据对象和不完备数据对象,得出集合UW以及集合UM,其中UW∪UM=U. 算法的第二阶段,通过聚类算法1或者算法2处理集合UW获得聚类结果CW={CW1,CW2,…,CWk}. 算法的第三阶段,填补集合UM中数据对象的缺失数据.例如,UM中对象x,通过式(1)插补缺失属性值,得到插补后的结果xl={xl1,xl2,…,xlk},即k种填充结果.填充公式为: (1) (2) 算法的最后一个阶段,通过阶段三的处理,不完备数据集U转变成完备数据集.使用聚类算法再次处理数据集U获得最终聚类结果. 通过给出在UCI数据集[23]上的实验结果来验证算法的性能,如表2给出了6组数据集的名称、大小、属性个数和类簇数.给定数据集U,根据特定缺失率:5%、10%、15%、20%、25%、30%.随机选择一些缺失的特征值来获得不完备的数据集U,其中缺失值的随机选择受两个条件的约束:① 每个原始特征向量至少保留一个分量;② 每个特征在不完整数据集中至少存在一个值. 准确率(Accuracy)是一种常见、易于理解的聚类性能度量指标,它表示那些被正确划分的样本数与总样本数之间的比值,值越大表示被划分正确的样本越多,否则被正确划分的样本数就越少.准确率(ACC)计算如下: (3) 式中:N为数据集中的总样本数;θi为类i中被正确划分的样本个数;k为聚类数. 表2 实验中使用的数据集Table 2 Datasets used in experiments 表3为UCI数据集上的ACC值,其中加粗的数据表示最好的实验结果.数据集在不同缺失率的条件下进行100次的实验测试获得ACC的平均值和最好值.表中的Method1、Method2、Method3、Method4分别表示基于k-means的不完备数据填充聚类算法、基于谱聚类的不完备数据填充聚类算法、OCS-FCM算法、NPS-FCM算法[12].其中,Method3和Method4是不完备数据聚类算法中较为经典的算法,基于FCM的大多数不完整数据聚类方法都是在文献[14]的基础上实现的. 从表3的实验记录可以看出:Method1和Method2中ACC的平均值与最好值的实验结果都是优于Method3和Method4的,比如数据集WDBC、Pendigits以及Page Blocks.除了数据集Iris上的实验结果Method1和Method2不如Method3和Method4.分析实验结果不难发现:对比方法是基于模糊C均值算法的,很难在非球形数据集上获得良好的结果;谱聚类算法可以在任意形状的样本空间中聚类,并以全局最优解收敛,故在处理高维数据方面具有明显的优势.因此,文中提出算法的ACC值高于对比算法的ACC值,尤其是基于谱聚类的不完备数据填充聚类算法.同时,在数据集Pendigits和Page Blocks上,Method1和Method2的实验结果尤其优于Method3和Method4.在大多数情况下,数据集中的缺失率越高,聚类结果的准确性越低.由于缺失率越高,不完备数据填充的准确性也会降低,这直接导致聚类算法的性能下降. 表3 UCI数据集上的ACC值Table 3 Experimental results of ACC on UCI datasets 文中研究对不完备数据集填充聚类,提出了填充算法的改进的均值插补方法(improved mean imputation,IMI),该其将硬聚类算法和改进后的均值插补不完备数据算法相结合.通过比较k-means IMI、spectral clustering IMI和k-medoids IMI 3种硬聚类算法的填充在UCI数据集上的实验结果,可以得出如下结论: (1) 3种算法在解决不完备数据集的填充聚类问题上是可行的,其中谱聚类算法的效果更佳. (2) 尽管算法在不完整数据填充聚类方面是有效的,但是这种算法在某些数据集中表现不佳,这表明需要进一步改进和完善. (3) 在接下来的工作中,要考虑如何完善不完备数据的填充和聚类算法,而且也要思考如何将不完备数据与三支决策聚类思想相结合.
1.2 不完备信息系统
2 改进的均值插补不完备数据聚类算法

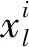
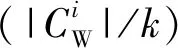
3 实验分析
4 结论
