一种基于视频的人脸检测及识别方法
2020-08-25李有乘
李有乘


摘 要:基于视频的人脸检测及识别是一个比较热门的研究方向。本文使用了一种方法对视频中的人脸进行检测。在收集檢测后的人脸模型后,本研究训练了一个轻型的深度神经网络模型,并使用该模型来进行人脸识别。试验结果表明,该模型可以较为高效地检测出人脸。
关键词:视频监控;人脸检测;人脸识别;CNN
中图分类号:TP389.1文献标识码:A文章编号:1003-5168(2020)20-0027-03
Abstract: Face detection and recognition based on video is a popular research direction. This paper used a method to detect faces in the video. After collecting the detected face models, this study trained a lightweight deep neural network model and used this model for face recognition. The experimental results show that the model can detect faces more efficiently.
Keywords: video surveillance;face detection;face recognition;CNN
近年来,深度学习是计算机领域发展最为迅速的一个方向,人脸识别也是目前非常热门的研究方法。与传统的一些认证方法相比较(如密码认证、指纹认证等),人脸识别具有可以轻易采集相关信息(监控)、不需要接触目标等优势。人脸识别流程一般分为两个部分:一是人脸检测,即在一张图片里面正确检测人脸的具体坐标;二是人脸识别,即把不同的人脸信息进行认证对比,从而识别哪个是真正的目标。有别于深度学习,传统的人脸检测主要是基于统计和知识的。例如,江伟坚等[1]基于Haar-like特征和积分图的方法进行人脸检测。而深度学习则不一样,是通过对图片的底层特征(像素级别)进行抽取从而得到高维的特征[2],这样抽取得到的特征,不会受到其他因素的影响,如信道干扰等,具有很强的抗噪性。王玮等[3]提出了一种基于高斯拉普拉斯算子得到人脸边缘进而进行人脸检测的方法。Zhang等[4]提出了MTCNN(Multi-task Convolutional Neural Networks),MTCNN是一种基于多个检测框级联的卷积神经网络,这个网络可以同时检测人脸的特征点,从而大幅提高检测的成功率。而人脸识别就是对人脸的信息进行一个多分类的判断。郑德伟[5]提出了一种基于机器学习的人脸识别方法。
本文基于Zhang等[4]提出的想法,设计了一个人脸检测模型,对视频中的人脸信息进行检测,在检测出人脸信息之后,构建了一个轻型的CNN(Convolutional Neural Networks,卷积神经网络)来对人脸的信息进行识别分类。结果表明,该模型在识别视频中的人脸信息时具有较快的速度。
1 流程设计
本文使用OpenCv来进行视频文件的读取,OpenCv是一个开源的跨平台计算机视觉库,具有高效、易于使用的特点。在使用OpenCv读取视频文件之后,视频会被分解为一个一个的图片,因为视频本身就是由多个图片构成的,1 s的视频有24张图片信息,将这些图片信息进行处理,放入MTCNN中进行人脸检测,检测结果放入单独的文件夹中。然后对这些图片进行手动标注,标注之后构建一个轻型的CNN网络,对这些人脸图片进行训练。
2 CNN及MTCNN网络结构
CNN是具有一定深度的前馈神经网络(Feedforward Neural Networks),是计算机视觉方向最具代表性的算法之一。其主要思想就是使用卷积层(Convolutional Layer),对输入的数据进行卷积运算,通过使用多个卷积核将图片信息提取成多个浅层的特征图(Feature Map)。从特征图上面,CNN可以得到该图片在某个卷积核大小上面的特征图像,使用该特征图像就可以赋予CNN一定的泛化能力。然后,对于得到的特征图,还可以进一步进行卷积运算,从而得到深层的特征图。一般来说,浅层的特征图是目标的一些比较通用的特征,如颜色、边缘等,而深层的特征图则是学习一些目标独有的特征,人脸识别中可以学习人脸特征,如五官在整张图片的大概位置。
MTCNN是一种基于级联架构的多任务CNN网络,该网络由三个网络构成:P-Net、R-Net和O-Net[4]。P-Net主要作用是把图像进行初分类,得到一系列的Archer BOX(选定的区域),将这些Archer BOX里面准确度不达标的去掉,从而得到一些准确度较高的待选Archer BOX。而R-Net和O-Net的主要作用,一个是进一步对Archer BOX进行筛选,将不合格的去掉,另一个是把人脸的五官作为监测点来判断是否合格。这样经过这三个网络共同的判断,最后可以得到一个准确率比较高的结果。
3 基于CNN的人脸识别模型
3.1 网络结构
本文的模型基于VGG16的思想,即将一个大的卷积核转换为多个小卷积核共同工作,这样有两个优点:一是可以减少大卷积核的参数数量过多的问题,加快训练速度,二是卷积核减小,大大减少了内存的占用空间,从而可以减少训练平台的要求。
在接收经过MTCNN检测的人脸信息后,进行统一裁剪,将图片都转换成为128×128×3的规格,然后输入网络中。该网络一共有5个con层,每一个包含三个部分,即一个3×3的卷积层、一个BN(Batch Normalization,批标准化)层、一个池化层(Max Pooling,最大池化层)。卷积层的作用是提取图片的特征,BN层的作用是把经过卷积之后的参数标准化,从而加快训练速度,池化层的作用是进行降维操作,将关联较小的元素去掉,减少干扰。经过5层con后,会有3个全连接层,全连接层的作用是将数据打平变成一维数据,然后将它们放入softmax中进行分类,从而得到图片分属于哪个分类的概率,其中概率最高的就是模型预测的结果。
3.2 样本标注
CNN需要一定分好类的数据才可以进行模型训练。刚开始,从视频中检测的人脸信息是杂乱无章的,没有进行分类。所以,这里只能暂时使用手动方式进行分类操作。在进行大约1 000张的图片分类后,先使用1 000张的图片进行模型训练,训练完后将其他图片放入模型进行预测。当然会有很多的图片被预测错误。然后,需要将部分预测错误的数据放入正确的分类,再训练,然后继续预测。一直这样重复进行,并根据预测结果微调模型。
3.3 模型训练
将经过多轮手动标注后的数据集整合起来,划分为训练集、测试集和验证集三部分,三者的比例大约是6∶3∶1,其中,训练集和测试集主要用于训练和验证模型的性能,测试集用于训练完模型后,测试模型的准确度。将数据剪裁成128×128大小,使用Adadelta優化器,Adadelta的优点是不需要设置初始的学习率,会自动调整学习率,可以得到更好的训练结果。使用categorical_crossentropy作为优化函数。BatchSize是128,一共训练了约30 000次,共300个Epoch,达到了收敛。
4 试验结果及分析
4.1 试验结果
经过多轮数据标注的迭代后,笔者把训练好的模型放在验证集上进行测试。从结果来看,正脸的预测效果非常好,但是,侧脸表情变化比较剧烈,当光线条件不好时,结果并不是太好。这种结果并不理想。
4.2 数据增强及试验结果
按照李新叶等人提出的方法,使用数据增强(Data augmentation)的方法,对数据进行扩充。数据增强就是模拟现实环境中的图片,将已有图片进行各种各样的处理,如翻转、倾斜、调整明暗度等(见图1),从而达到扩充训练数据、提高模型泛化能力的结果。
4.3 数据增强后的试验结果
经过数据增强后,从结果来看,正脸和侧脸的验证效果很好,但是侧脸角度较大或者是遮蔽较多的效果很不好,因为从CNN的原理来看,遮蔽较多的话,这张图片提取的特征就和普通的人脸特征不一样,如图2所示,图片下面的数字表示该图片分类的概率。
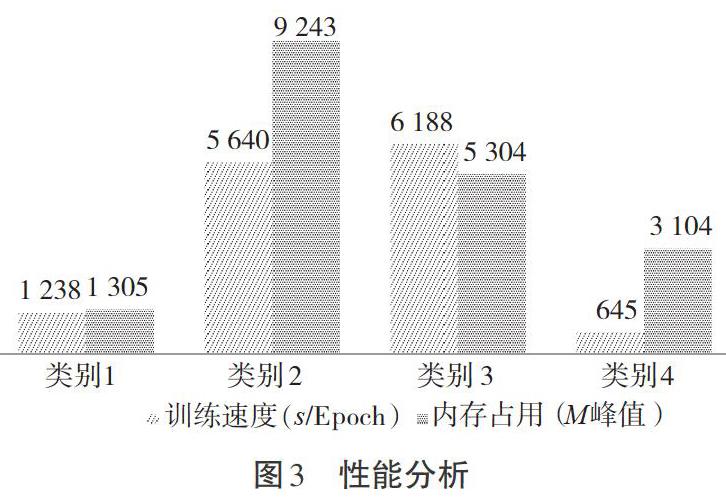
4.4 性能分析
本试验使用Python3.6+Keras2.2.2,台式机配置为i7-7700(3.6 G),16 G内存。性能分析如图3所示,性能分析包含训练性能和实时监测性能。作为试验对比的VGG19,ResNet50和Xception V3都是经过ImageNet预训练的模型,在训练本文的数据时都会将这些模型的低层训练权重解锁,重新训练。由图3可以看出,相较于VGG、ResNet等常见网络,本模型在训练速度和检测性能有一定的优势。该视频编码格式为h264,帧率为23.98,色彩空间为bt709。
5 结论
本文设计了一种基于OpenCv+MTCNN+轻型CNN的人脸检测识别方法。使用OpenCv截取视频图片,使用MTCNN截取人脸图像,再使用轻型CNN训练人脸识别。主要工作是提出了一种轻型的CNN网络结构用来进行人脸识别。和传统的VGG等模型相比,其具有训练速度块、检测性能好的优点。从试验结果来看,其对遮蔽物或侧脸的检测效果仍然不理想,此外,手动进行数据标注太麻烦,未来可以进一步探讨更加便捷的标注方式。
参考文献:
[1]江伟坚,郭躬德,赖智铭.基于新Haar-like特征的Adaboost人脸检测算法[J].山东大学学报(工学版),2014(2):43-48.
[2]Kivinen J,Szepesvári C,Ukkonen E,et al.On the Expressive Power of Deep Architectures[C]//International Conference on Algorithmic Learning Theory.2011.
[3]王玮,闵卫东,樊梦丹,等.基于择优检测和多尺度匹配的实时人脸识别[J].计算机工程与设计,2018(9):2957-2960.
[4]Zhang K,Zhang Z,Li Z,et al.Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks[J].IEEE Signal Processing Letters,2016(10):1499-1503.
[5]郑德伟.基于机器学习的人脸面部疲劳表情识别[D].北京:北京邮电大学,2019.
