基于SSD算法的茶叶嫩芽检测研究
2020-08-24王子钰赵怡巍刘振宇
王子钰,赵怡巍,刘振宇
(沈阳工业大学信息科学与工程学院,沈阳110870)
1 引言
中国是茶叶的主要原产地,是世界上茶叶种植量、消费量、出口量最大的国家之一。目前茶叶的采摘通常采用人工采摘,但是难以保证采摘的质量,成本也较高。
茶叶的自动化采摘目前还处于研究阶段,通常是基于茶叶嫩芽的颜色特征和形状特征,运用图像处理的方法先将茶叶嫩芽识别出来,再进行采摘。如杨福增等人[1]利用G颜色特征以及“两瓣一心”的形状特征来识别嫩芽。汪建[2]利用颜色空间的H、S特征和区域生长算法完成了对3种拍摄角度的茶叶嫩芽的分割。唐仙[3]等人则根据R-B颜色特征,利用多种阈值分割反法实现嫩芽分割。吴雪梅[4]等人在G-B颜色特征的基础上,加入了中值滤波和形态学运算来实现嫩芽的识别。张可[5]等人则在前人的基础上加入k-means聚类分割和伪目标去除的形态学方法。方坤礼[6]等人在G-B颜色特征基础上采用了改进的JSEG技术来识别嫩芽。基于颜色和形状的算法虽然研究较多,但普遍存在诸如适用性差、易受多种因素影响等不足之处。
近年来,随着硬件和大数据的发展,人工智能与深度学习的应用日渐广泛,利用深度学习来实现目标检测已经成为计算机视觉的热门研究方向。目标检测算法主要分为两种思想:第一种是“两步走”,先进行区域推荐,而后进行目标分类,典型代表有RCNN系列(R-CNN[7]、Fast R-CNN[8]以及Faster RCNN[9]等),其检测准确率虽然不低,但是在速度方面还远不能满足实时检测需求;第二种是“一步走”,即基于深度学习的回归思想,采用一个网络进行端到端的一步到位,典型代表有YOLO[10]、SSD[11]。YOLO虽然能够达到实时检测的需求,但是其检测准确率与第一种方法存在较大差距,且对于多尺度目标检测的准确率较低。相比而言,SSD对于多尺度目标的检测准确率更高,同时兼具速度快、精度高等优点,在如今的各个行业都有许多最新的研究,如江鹏等人[12]利用SSD检测苹果叶片的病害;吴水清等人[13]实现了不同场景下车辆的检测;方阳等人[14]利用SSD将人脸的检测与头部姿态的估计融合在了一起;朱玉刚[15]实现了无人驾驶时的多目标检测;黄豪杰[16]等人对SSD输入模型进行了改进,使其在水果识别上有了更好的效果。但目前国内外运用SSD算法识别茶叶嫩芽则仍处于构思状态,尚无相关研究。
在茶叶嫩芽的实际采摘中,常存在一张茶叶图像中含有多个嫩芽的情况,需要一种算法对茶叶图像中的多个嫩芽目标进行检测识别。在此提出一种基于TensorFlow深度学习框架的目标检测算法,即利用SSD算法来对茶叶嫩芽进行检测识别。其主要工作包括两部分:第一部分是茶叶数据集的制作,在采集了茶叶图像之后,利用提取颜色特征的方法对茶叶图像进行预处理,使茶叶与背景信息分离。随后通过数据集增强的方法建立茶叶数据集,流程如图1所示。第二部分是利用SSD算法检测茶叶嫩芽,首先要对茶叶数据集进行人工标注,随后导入神经网络中利用SSD算法进行训练,之后多次调整参数得到可以检测识别出茶叶嫩芽的神经网络模型,并进行测试评价,流程如图2所示。

图1数据集制作
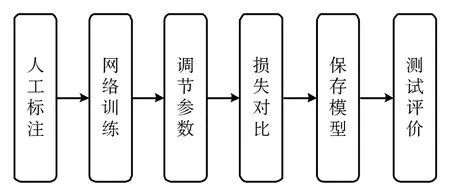
图2 SSD算法检测茶叶嫩芽
2 数据集制作
2.1 图像采集
图像的采集就是茶叶图像的拍摄。此处所拍摄图像主要是浙江省湖州市安吉县溪龙乡黄杜村的白茶以及杭州市西湖风景区的龙井茶,采用单反照相机拍摄,共800余张,图像素质为3216×2136像素。从中挑选出拍摄清晰的多张图像,经分割等处理后,全部统一为512×512像素,jpg格式,用于后续的图像预处理。
2.2 图像预处理
图像预处理旨在利用传统的提取颜色特征的方法来隐去茶叶图像中的一些无关的背景和噪声信息,以便于后续的训练。主要的图像预处理步骤包括:图像降噪、提取颜色特征、图像分割、形态学处理、掩模处理等。
2.2.1 图像降噪
茶叶图像在拍摄过程中因为相机硬件因素、拍摄环境、光照强度等因素,会包含大量噪声,因此需要进行滤波降噪来获取高质量图像。
滤波降噪在尽量保证茶叶原始图像信息完整的同时,可以初步消除图像中无用的噪声信息,便于后续的图像处理。由于茶叶图像均为512×512像素,1×1、2×2的滤波器降噪效果不明显,而4×4、5×5的滤波器降噪效果又过强,会破坏原始图像的信息,使图像变得模糊,因此此处采用3×3的均值滤波器来对茶叶原始图像进行滤波降噪。
2.2.2 提取颜色特征
颜色特征是茶叶与背景进行区分的一个重要特征,茶叶图像中,嫩芽多为嫩绿色与浅绿色,老叶多为深绿色,背景信息则为其他颜色,颜色差别较大。因此可以通过提取茶叶图像的颜色特征来区分出茶叶与背景信息。
提取颜色特征需要用到颜色模型,常用的主要有RGB、HSI、Lab等。提取颜色特征后,将图像进行灰度化,可以进一步缩减每张图像的信息量,便于对比与分割。
图3给出了对G-B、S、a、R-B四种颜色特征进行提取的灰度图。其中,图3(a)提取的是G-B颜色特征(一般称为超绿因子),可以看到,相比于其他三种特征,这一图像中的嫩芽和老叶,与背景的灰度区分度最大,可以被更好分割出来。

图3提取颜色特征灰度图
2.2.3图像分割
提取颜色特征转化为灰度图后,需要进行图像分割处理。
图像分割的目的是剔除茶叶杆、过老的老叶等与茶叶嫩芽差别较大的背景信息,将茶叶嫩芽和一些老叶保留下来。图像分割时使用Otsu算法,它是由日本学者大津(Nobuyuki Otsu)于1979年提出的一种图像灰度自适应阈值的分割算法。Otsu算法的思想是根据图像灰度值的特性,将图像分成背景和前景(即茶叶嫩芽和一些老叶)两部分。
分割之后,图像变为了二值图,即仅有“0”、“1”两个元素的黑白图像。其中,茶叶嫩芽和一些老叶部分变为了“1”元素,在图像中表现为白色,背景信息为“0”元素,在图像中表现为黑色。
2.2.4 形态学处理与掩模处理
通常,受到噪声、嫩叶轮廓不完整等因素的影响,图像在阈值化分割后所得到的二值图的边界都不平滑,目标内部有孔洞或轮廓不连续,背景区域上也会散布一些小的噪声点,还需进一步处理[17]。形态学运算的腐蚀和膨胀可以有效地解决上述问题。
相较于原图像,因为腐蚀的结果要使得各像元比之前变得更小,所以适用于去除高峰噪声。而膨胀的结果会使得各像元比之前的变得更大,所以适用于去除低谷噪声。因此,这里使用半径为4的“disk”结构来对分割后的二值图进行开运算(先腐蚀后膨胀)来去除噪声,再进行闭运算(先膨胀后腐蚀)填充空洞。
随后对茶叶图像进行掩模处理,即令二值图与原图进行按位与运算,便可得到去除了背景信息的图像。图4给出了图像预处理的一个示例。

图4图像预处理示例
2.3 数据集增强
数据集的数量决定着训练效果的好坏。因为采集的图像数量有限,所以采取数据集增强的方法来扩充数据集,包括每一张图像镜像翻转、每一张图像旋转±15°、施加随机颜色特征(亮度、饱和度)等。
经过数据集增强后,样本数量可达到2400张。按照3:1的比例分配训练集与验证集。其中训练集数量为1800张,验证集数量为600张。
将该数据集命名为tea_leaf。由此,便建立了后续SSD算法训练所需要的数据集。
3 SSD算法检测茶叶嫩芽
SSD(Single Shot MultiBox Detector)是刘伟(Wei Liu)在2016年提出的一种目标检测算法,是目前主流的目标检测框架之一。SSD的网络模型基于一个前馈的卷积神经网络VGG16,其结构如图5所示。但相比VGG16做出了如下的更改[18]:
(1)将VGG16全连接层中的FC6层和FC7层替换成3×3的卷积层Conv6和1×1的卷积层Conv7;
(2)去掉VGG16中所有的Dropout层和FC8层;
(3)将VGG16中的池化层pool5由原来stride=2的2×2变成stride=1的3×3;
(4)添加了Atrous算法(hole算法),目的是获得更加密集的得分映射;
(5)在VGG16的基础上新增了卷积层来获得更多的特征图用于检测。
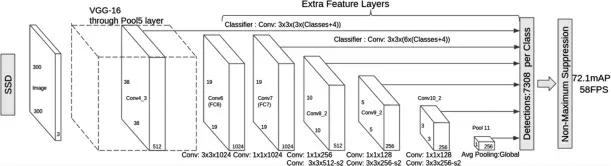
图5 SSD网络框架图
SSD算法在训练后会产生一个如图6所示的矩形框,用以标记检测物体所在区域,被称为bounding box(边界框)。目标检测的是为了使边界框生成的和人工标注的ground truth(真实框)尽可能的一致,因此还需要经过设置默认框、人工标注真实框、NMS算法、损失函数计算、参数调节几个步骤。

图6 SSD边界框选中区域
3.1 设置默认框
在SSD算法的神经网络结构中,共有Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2、Conv4_3这六个卷积层,当图像输入网络后,每个卷积层的特征图上都会以每个特征点为中心,生成一系列同心的矩形框,称为默认框,如图7所示。换言之,默认框是特征图上预设的一些目标预选框。
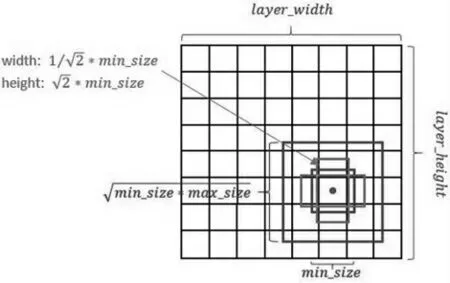
图7设置默认框
一般情况下,每个特征图上都会设置多个默认框,其尺度和长宽比存在差异。假设网络中有m个特征图,每个特征图会生成k个默认框,则每个默认框的尺度为:

其中,Sk表示默认框大小相对于图像的比例,Smin和Smax表示比例的最小值与最大值,这里取0.2和0.9。对于不同的特征图,默认框的尺度都会随着特征图大小的降低而线性增加。
按照上述基础尺寸会生成一个正方形的默认框,但默认框数量太少且类型单一,所以在此引入五种长宽比ar:

根据式(1)的尺度和式(2)的五种长宽比,可以得到在不同特征图上的每一个默认框的宽和高:

此外,每个特征图还会设置一个长宽比ar=1且尺度为的默认框,以此每个特征图都会对应六种默认框。这样定义的默认框在不同特征图有不同尺度,在同一个特征图有不同的长宽比,基本可以覆盖输入图像中各种形状和大小的目标。
3.2 人工标注真实框
确认了默认框后,还需要确认真实框,真实框是人为地在茶叶原图上标注出来的嫩芽位置。在神经网络中,真实框就是数据集的标签,引导神经网络进行有监督学习。
利用labelImg工具制作标签,人工标注出每幅图像中茶叶嫩芽的位置,如图8所示,进而生成xml文件,再将其转化成tfrecords文件。xml文件包含着图像的全部标注信息,tfrecords文件用于导入tensorflow深度学习框架中。

图8人工标注真实框
3.3 NMS算法
由于生成的大量默认框可能存在相互重叠的情况,需要用到NMS算法(Non-Maximum Suppression,非极大值抑制)对生成的大量默认框进行后处理[19],去除冗余的默认框。NMS算法的本质思想是搜素局部最大值,抑制非极大值,通过合并策略生成一个茶叶嫩芽的最终预测框。合并时主要是socre(参考置信度)与IOU(Intersection over Union,交并比)这两个指标[20]。
在训练时,真实框与默认框按照如下方式进行配对:首先,寻找与每一个真实框有最大IOU的默认框。此处,两个框的IOU计算采用Jaccard系数,设A,B为两个框,则有:
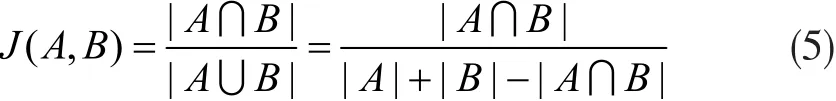
通过Jaccard系数求出两个框的IOU,可以保证每一个真实框与唯一的一个默认框对应起来。
然后将没有配对的默认框与任意一个真实框尝试配对,只要两者之间的IOU大于阈值(SSD300网络框架中默认为0.5),即判定为已匹配上,并将此归为正样本。
最后再将仍没有配对到真实框的设置为负样本,并在SSD神经网络训练时控制正样本与负样本之比为1:3。
3.4 损失函数计算
确定了训练样本后,还需要计算样本的训练损失值,以保证生成的预测框尽可能与人工标注的真实框接近。
因此,训练的最终目的就是求得使损失函数最小时的神经网络参数。SSD算法中神经网络的损失函数为定位损失(location loss)和置信度损失(confidence loss)两部分的加权和,其表达式如下:
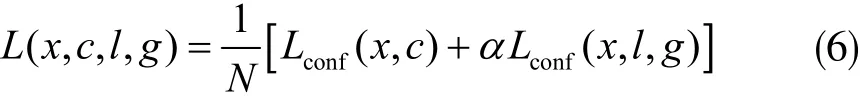
其中,N是匹配到真实框的默认框数量,如果N=0,则将损失设为0;参数琢用于调整定位损失和置信度损失之间的比例,默认琢=1。
定位损失函数的计算是典型的smmothL1损失,其公式如下:

其中:
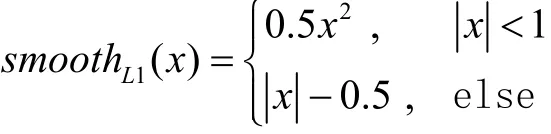
l为预测框,g为真实框,cx、cy为补偿后的默认框的中心坐标,ww 、h为默认框的宽和高。表示第i个默认框与第j个真实框是否匹配,取值为0或1为默认框经过编码后的位置预测值为真实框编码后的位置参数。
置信度损失函数是交叉熵损失函数,其式如下:
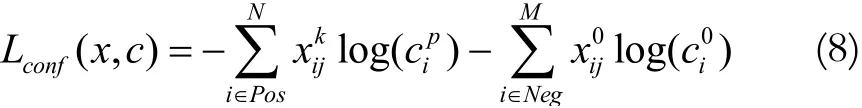
其中i为默认框序号,j为真实框序号,p为类别序号,p=0表示背景表示正样本的损失,即分类为类别p的损失表示负的损失,即分类为背景的损失表示第i个默认框对应类别p的预测概率,由神经网络中的Softmax层产生。默认框i与真实框j关于类别p匹配时,p的预测概率越高,则损失越小。
3.5 参数调整
在训练过程中,需要多次调整参数,进行多次训练,以求得损失最小的神经网络模型。
环境搭建主要是TensorFlow GPU版框架、NVIDIA CUDA9.0、NVIDIA cuDNN 8.0。
TensorFlow GPU版改变了常用的基于CPU进行计算的框架,改为运用GPU进行计算;CUDA是NVIDIA推出的运算平台;cuDNN则是专门针对深度学习框架设计的一套GPU计算加速方案。三者进行搭配,可以有效提高机器学习的速度。
在神经网络的训练中,Learning rate(学习率)、Learning rate decay(学习率衰减)、Batch size(一次训练样本数)是影响最终结果的三个重要因素。
其中,Learning rate作为监督学习与深度学习中重要的参数,它表示神经网络训练的速率,决定着损失函数能否以及在何时能内收敛到最优点。Learning rate过大会导致损失值振荡或无法收敛,过小会导致训练过慢,影响效率。在SSD算法对图像的训练中,它的范围通常为1×10-2~1×10-6。
Learning rate decay的目的是防止Learning rate过大,在收敛到最优点的时候会来回摆荡,所以要让Learning rate随着训练轮数不断按指数级下降。在SSD算法对图像的训练中,它的范围通常为略小于1的数,例如0.90~0.99。
Batch size的大小影响模型的优化程度和速度,同时其直接影响到GPU内存的使用情况。Batch size过大会导致GPU满载运行,引起内存爆炸。过小则会导致梯度跳动,影响训练的准确率和速率。在SSD算法对图像的训练中,它的范围通常为1~32(取2的平方数)。
经过多次调整参数训练,最终得出了如下的对比结果(任选其中三次为例,均为训练50000次后的结果),如表1所示。

表1三组网络参数
选取序号1所保存的模型,作为本次的实验结果。
4 结果与结论
4.1 实验结果
训练之后,选取一定数量的图像对保存的模型进行测试,嫩芽检测效果如图9。

图9茶叶嫩芽检测效果
图9由上到下分别为茶叶原图、掩模图、检测结果图。由左到右则为普通多株茶叶嫩芽、处于边缘位置的茶叶嫩芽、处于杂乱背景下的茶叶嫩芽。可以看出,对于不同的角度、不同位置、不同数量的茶叶图像,在经过预处理后,SSD算法都可以用矩形框将茶叶嫩芽检测出来。
4.2 结果评价
计算模型的AP和mAP,作为模型性能的评价指标。AP表示准确率(precision)的平均值,用于衡量检测器在每个类别上的性能好坏。mAP表示AP的平均值,是对多个验证集个体求平均AP值,即:
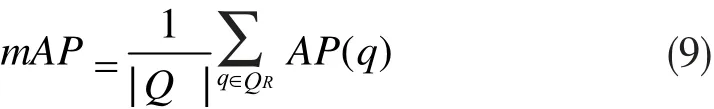
其中,QR为全部验证集为验证集中预测正确集合的累加和。由于茶叶嫩芽的识别是二分类,在检测识别时只需区分嫩芽和背景,所以此处m=1,即AP=mAP。
经过计算,算法的准确率达到了91.5%,相比于传统的只提取了颜色特征算法[21]的85.6%,有了出色的提升。说明此种不仅利用颜色特征进行图像预处理、还利用SSD神经网络进行目标检测的算法具有更高的准确率,同时对于多个嫩芽也有更好的检测效果。也说明所提算法对于茶叶嫩芽的识别效果更好,符合预期。
5 结束语
介绍了一种利用SSD算法来对茶叶嫩芽进行自动检测识别的算法,由实验结果可见,该算法以较高的准确率实现了对茶叶嫩芽的检测识别,符合设计预期。其结果也存在一些不足,如个别检测框位置有偏差,存在个别漏检情况等。后续可以通过比如进一步丰富数据集的方法,使目标具有更加丰富多样的特征,来加以解决。此外也可利用GAN(Generative Adversarial Networks,生成式对抗网络)来对数据集进行进一步扩充,对于提高识别的准确率以及适用性都有更大帮助,有待进一步研究。本研究可为未来大规模的茶叶自动化采摘打下理论基础,具有广阔的应用前景。
