基于短文本分类的电子发票自动生成会计分录
2020-08-04李燕萍宋磊
李燕萍?宋磊
引言
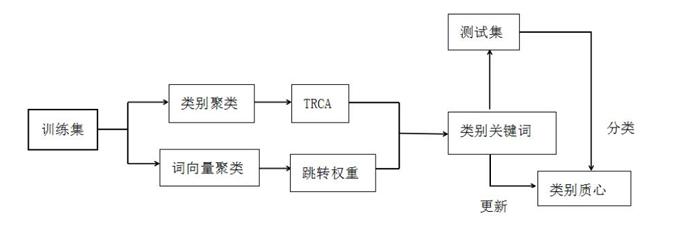
电子发票中的信息抽取属于自然语言处理中信息抽取子领域。自然语言处理可以分成3个层级,分别是文本理解、信息抽取和信息检索。在以往的纸质发票报销中,通常要经过一系列流程,层层审批,然后财务部门根据报销的內容进行分类,做账。而线上报销流程与线下一致,软件自动识别发票,报销人虽无需填写发票,但财务依旧需要根据报销内容制作会计分录才能做账。将报销内容自动生成分录,可节约财会人员时间和精力[1]。
一、自动生成目录可行性
电子发票具有文字稀疏性、产品术语、名词术语较多等特点,将其内容分类自动生成会计分录,可减少企业资金投入,提高企业做账效率。在报销的项目内容中,大多数是一些属性相近的词,可以看作是单个词语到语义一般概念的映射。词聚类算法可以分为三种:第一,各种启发式量度表示聚类过程中的元素的距离;第二,以统计模型计算距离量度并给定聚类结果的类总数;第三,同样以统计模型计算距离量度,但增减例如困感度等量度的值[2]。
二、短文本分类存在问题
报销的内容较为简洁明了,属于短文本,但传统的向量空间模型(VSM, Vector Space Model)对长文本的分类有较高的敏感度,而用于短文本分类时却存在特征稀疏性等问题。1、传统的向量进行空间分析模型对关键字的文档数据处理方式方法是依据词频信息,难以分辨自然语言的语义模糊性。2、传统的向量空间模型的假设词与词之间是相互独立的,是一一对应的关系,但在实际情况中,文档存在着很多一词多义和同义词的现象,所以这种假设难以满足实际情况。 3、文档中的词与词通常存在着一定关联性,通过简单的词汇模式匹配进行语义检索会降低信息检索结果的查准率与查全率,直接应用传统的向量空间模型进行短文本分类难以达到理想的效果[3]。
三、短文本的Word2Vec模型
在此基础上,本文探讨采用Word2Vec的词向量模型+K-means聚类,利用Word2vec浅而双层的神经网络重新构建给定语料库的文本,快速有效地将关键词表达成词向量,再使用词向量聚类得到类别关键词达到理想的短文本分类效果。
(一)文本预处理
首先使用结巴分词将获取的两千万条淘宝商品名称数据集进行分词处理,过滤掉标点符号、停用词等将文本标准化。由于中文没有词形变化,不需要还原词形、词缀的转化以及词性识别。为了准确地分析和表达文本,利用Word2vec将向量化的文本进行特征提取。
(二)文本向量化
词袋模型(Bag of Words)是对文本中的单词进行统计,简单说就是统计某个单词在一个文本中出现的频率或者次数。
(三)特征提取
Word2vec是一种估算式(Estimator),它采用的是训练商品名称一系列文档的重要词语,形成Word2vec模型,每个词语的模型映射成一个固定大小的向量。Word2vec模型使用商品名称中每个词语的平均数来将文档转换为向量,然后通过这个向量我们可以不断扩散,然后作为预测电子发票内容的特征,来计算商品名称的相似度。
Word2vec模型一般分为CBOW(Continuous Bag-of-Words)和Skip-gram两种模型。训练CBOW模型的输入是某一个特征词上下文相关的词对应的词向量,输出是某特定词的词向量。在Skip-gram模型中,每个词语受到上下文的影响,即利用上下文的预测结果,在梯度下降过程中不断调整当前词的词向量。因此,尽管 Skip-gram 的训练时间相对较长,但在数据量较少或生僻词含量较多的情况下,会使经过多次调整得到的词向量具有更高的准确度。在缺少报销具体内容领域扩展语料库的情况下,本文采用Skip-gram模型预训练商品标题语料得到词向量。经过训练后可以得到每个词语的词向量以及词语之间的余弦相似度。
四、商品名称训练
本文采用淘宝商品名称数据,以会计科目作为类别标签,将提取的关键词权重输入分类器,通过分类结果的准确率来衡量关键词提取的有效性。
五、K-means聚类后分类
聚类是一种无监督的机器学习,通过将相似的研究对象归到同一个簇中,利用相似度计算方法将其一一对应。K-means聚类算法用于数据集K个簇的聚类,K个簇采用事先制作凭证中的会计科目, 每一科目对应商品名称通过其所有点的中心来描述,聚类与前述分类处理算法的最大区别在于分类的目标类别已知, 但聚类的目标类别是一个未知的,将训练集中的科目对应商品名称按Word2vec模型的计算结果划分为k组,获得的聚类满足同一聚类中的名称相似度较高,而不同聚类中的名称相似度较小。以下是聚类算法的基本步骤:
1、从训练集的数据中选择k个名称作为聚类的初始中心;
2、用每个聚类名称到聚类中心的距离来划分类别;
3、重复计算每个聚类的中心;
4、计算标准测度函数,直到达到最大迭代次数停止,否则从第2步重复操作。
结论
目前市场中的移动报销应用还无法满足将报销内容自动分类,为了适应新时代科技发展的需求,各行各业要想在资金方面提供准确的资金状况,须采用移动报销下的短文本自动分类。基于统计的名称分类存在大型参数空间、足够的训练数据、数据稀疏等问题。本文利用Word2vec工具集和K-means聚类,探寻一种较为方便的方法对短文本进行文本分类,移动报销中的短文本分类自动对应到会计凭证的分录可提供准确的资金用途及细目,减少精力投入,提高效率,促进各行各业的长远发展。
参考文献
[1]李昕,文桂江.会计信息处理智能化研究[J].财会通讯,2014(07):90-91.
[2]杨军泽.互联网环境下自动化会计确认探讨[J].财会通讯,2019(01):104-108.
[3]徐建国,肖海峰,.基于多示例学习框架的文本分类算法[J].计算机工程与设计,2020,41(04):1017-1023.
基金项目:国家级大学生创新创业训练计划项目,项目编号:201910379018
作者简介:李燕萍(2000—)女,安徽省黄山市祁门县人,本科在读。
