基于时序Landsat 8 OLI多特征与随机森林算法的作物精细分类研究
2020-07-28刘吉凯安晶晶
刘 杰,刘吉凯,安晶晶,章 超
(1.淮河流域气象中心,安徽 合肥 230031;2.安徽省气象台,安徽 合肥 230031;3.安徽科技学院资源与环境学院,安徽 凤阳 233100)
作物类别识别是农业遥感应用的重要方向,是农业精细化管理、农情监测的基础[1-2]。传统的作物信息获取主要以行政部门的地面抽样为主,费时费力,数据获取量少、分布离散,在国家、州、省等区域尺度推广应用的时效性差[3-4]。随着农业遥感技术的深入发展,基于不同分辨率的遥感影像可以快速、无损、实时地获取全球、区域、局部范围内的作物信息,对粮食估产、作物监测、作物生长周期模拟等研究具有重要意义[2-7]。
作物类别识别研究中,除原始影像的光谱特征被利用最多外,由影像波段经线性或非线性变换而来的植被指数能有效增加作物信息识别的效率,是农业遥感研究中至关重要的特征参数[2,8,10-11]。此外,研究表明作物的纹理特征作为影像空间特征的局部表示,对于作物类别及耕作方式等较为敏感,在作物精细分类中的应用日益深入[11-14]。
在中等分辨率层面(一般其空间分辨率在10~250m范围内),作物类别识别常用的方法主要是基于像元的分类方法,如最大似然法、支持向量机和决策树分类方法,它们简单易行、高效快捷,且精度有一定的保障,是目前国家级或区域级农情遥感监测业务化平台中的常见方法[1-5,11-12]。随着大量遥感卫星的发射,已经组建起完整的农业遥感观测系统[2,4-5,15],可用于作物类别识别的分类特征呈现出高维、异源、海量等特点,使得传统分类方法在数据处理效率、多源特征组合、数据深度挖掘等方面日益难以满足业务化运行的需求[2,8-9,13-15]。最近几年机器学习算法迅速发展,在处理多维复杂数据时展现出了更好的精度和效率。例如,神经网络[2,16-17]、决策树[2,7,10-12,15]、随机森林[9,13-15,18]、支持向量机[2,8,15-16]等。其中随机森林(Random Forest, RF)是一种具有优秀性能的集成学习算法,被广泛应用于复杂遥感数据集的分析处理[9,13-15,18-19]。
本文选择多时相Landsat 8 OLI数据提取研究区时序光谱特征、纹理特征、植被指数等信息,利用随机森林算法对分类特征进行降维以节约计算资源,获取最优参数与特征子集后对研究区农作物实现精细分类。同时评估基于随机森林多时相多特征类型的分类算法对农田作物的辨别能力,为农业遥感的进一步研究提供依据。
1 数据与方法
1.1 研究区概况
研究区主要位于新疆维吾尔自治区阿克苏地区温宿县西南部(见图1),属典型的大陆性气候。区域内土地肥沃、水源丰富、光照充足、无霜期长,适宜各类农作物生长,是国家重要的商品粮、商品棉基地。

图1 研究区2015年8月14日Landsat 8 OLI标准假彩色 合成卫星影像(a)及其在新疆阿克苏地区的地理位置(b) Fig.1 The Landsat 8 OLI false color image of study area on 14 August 2015 (a) and the location of study area in Aksu, Xinjiang (b)
通过对县域实地调查,研究区内农作物类型多样,种植复杂,物候期高度重叠。主要种植的农作物有水稻、棉花、春玉米和冬小麦等,主要的林果种类为枣树、核桃、苹果、香梨、葡萄等。
1.2 数据源与预处理
研究区属大陆干旱半干旱性气候区,在农作物生长周期内(4—11月)的光学影像主要受沙尘影响。本文经筛选后共获取2014—2015年生长季的7景无云、无沙尘影响的Landsat 8业务化陆地成像仪(operational land imager, OLI)数据,成像时间分别为2015年3月23日、4月24日、5月26日、7月13日、8月14日、9月15日和10月17日,格式为L1T,多光谱空间分辨率为30 m,下载至USGS[20]。对所获取的多时相多光谱数据使用ENVI5.5软件分别进行了辐射定标、FLAASH大气校正、几何配准(双线性内插,几何误差小于0.5个像元)处理,投影选择为UTM(44N)/WGS-84。
结合研究区野外实测数据、Google Earth高分辨率影像目视解译结果,将研究区分为棉花、小麦、玉米、水稻、香梨、核桃、苹果、葡萄、枣树、林地、草地、水域、沙地、戈壁和建筑共15个类别。野外实测主要是采用手持GPS仪获取农作物的解译样本标志,人工目视解译主要在高分Google Earth影像上根据实测解译标志勾绘研究区内的主要地物类别,利用ENVI5.5软件将矢量化结果转换至OLI影像,共选取了667754个像元点,按7∶3随机分为训练样本和验证样本。
冉清桓后来说:“但是我活着回来了。说句实话,我掉下去的时候其实没想到能活着,但是我尽力……如今我仍然不知前途怎么样,但是我仍然尽力,将来,便可以无怨无悔了。”
1.3 分类特征处理
植被指数(vegetable indices, VIs),作为地表植被特征的重要表征参数,在植被长势、生物量、结构信息等应用中具有重要意义[2,8,10-11]。本文在波段反射率基础上提取16种常用于农作物信息识别的植被指数[21-23]。
纹理特征能够弥补基于像元光谱分类的不足,可以突出作物细节信息,是作物分类识别的常用特征之一[12-14]。本文对波段影像进行主成分变换,利用变换后的第一主成分(principal component analysis 1, PCA1)替代原始影像基于灰度共生矩阵(gray level co-occurrence matrix, GLCM)的方法进行纹理特征提取。
综上所述,本文根据研究区内主要农作物的波段反射率、植被指数特征和纹理特征共217个特征(见表1),利用随机森林方法根据特征重要性选取最佳分类特征子集,并实现最优特征集支持下的农作物精细分类识别。

表1 参与分类的所有特征
1.4 随机森林算法
2001年,美国科学家Breiman提出了一种称为随机森林(RF)的新型分类算法[19]。它由多棵CART决策树分类器构成,能够高效处理多维特征的数据集,并具有准确性高、模型稳定等优点[9,13,18]。RF通过k次Bootstrap随机有放回抽样,每次随机抽取约2/3的原始数据建立单棵决策树,形成k棵树组成的随机森林。在每棵树节点分裂时再从M维的特征向量中随机选择m(m≤M)个参与,最终通过所有树的统计投票,决定最可能的分类结果[18-19]。
1.4.1 随机森林的关键参数 在构建随机森林时,树的个数k和节点分裂特征个数m是影响模型精度与运行效率的最重要的两个参数[13,18-19]。一般来讲,随着决策树个数k的增加,模型泛化误差有效降低,但计算效率下降;节点分裂特征个数m决定单棵决策树分类能力,并影响树之间的相关性。本文使用Python Scikit-learn库实现随机森林的构建,以另外的约1/3未被抽中的袋外数据(out-of-bag)计算OOB误差(oob_error)和验证数据计算的误差(test_error)作为评价依据,综合考虑模型效率和精度,选择最优参数k和m获取分类结果[18-19,21]。
1.4.2 随机森林的特征重要性 在随机森林中,特征的有效增加能提高分类精度,但高维度的特征互相之间可能具有相似性,继而对模型分类能力贡献少,并影响计算效率。因此,筛选各特征变量对模型的影响非常重要。

本文以归一化重要性评分作为指标,客观评价各个分类特征的重要程度,并在试验中逐步减少输入特征维度,在保证模型分类性能和效率的基础上探索最好的特征子集,达到降维目的。
2 结果与分析
2.1 随机森林关键参数的确定
在提取了研究区217个特征后,构建不同k和m参数下的随机森林模型,利用oob_error和test_error作为评价判断标准,测试关键参数k(值的范围1~1 000)和m(值的范围1~30)对模型的影响。如图2所示,随着k值的增加,模型精度均有所提高,特别是少于100棵树,还未形成“森林”时精度提升明显。但在数目超过100棵后,oob_error和test_error两种误差均缓慢收敛并趋于稳定。以m=16的模型为例,当k从1增加到100,oob_error从68.85%下降到6.67%,test_error从15.72%下降到6.35%;k从100增大到1 000,oob_error仅从6.67%下降到6.18%,test_error仅从6.35%下降到6.21%。因此,本文认为树的数量能有效提高随机森林分类精度,但在超过100以后,模型对树的增加变得不那么敏感,分类模型趋于稳定。

图2 树的个数k、节点随机分裂特征数m与oob_error (a)、test_error (b)的关系Fig.2 Relationship between the accuracy of out of bag dataset (a) or test dataset (b) and the number of trees (k) and number of random split variables (m)
节点随机分裂的特征数m的增加也可以有效降低模型误差,但是相比参数k影响较小。m在小于5时,模型精度提升相对明显;在m大于15以后模型精度提升幅度很小,特别是当树的数量大于100后,m超过10时模型就已基本稳定。
为平衡模型的稳定、精度与效率,需要选取适当的参数k和m。本文选取了k=200、m=10参数下的模型用于进一步的最优特征子集筛选研究。
2.2 最优特征子集的选取
在获取217个特征变量重要性评分的基础上,选择随机森林分类模型的最优特征子集,该子集可使模型分类精度的降低最小,以实现降维的目的。图3展示了随着信息量最少特征的逐渐去除,分类的Kappa系数与总体精度随之变化的关系。当所有特征参与建模时,分类的(删减0%)Kappa系数为0.926、总体精度为0.935。在删减特征变量不超过30%时,随机森林模型的分类能力基本维持不变,Kappa

图3 随机分类模型精度随特征删减比的变化关系Fig.3 The effect of variable reduction on classification accuracies
系数在0.925左右,总体精度在0.935左右。当删减在30%至70%区间内,随着特征数的减少,模型的分类精度缓慢下滑。在删减超过70%以后,分类精度下降的幅度迅速加快,特别是在删减超过90%后模型的Kappa系数和总体精度均近直线快速下降。当仅保留归一化重要性评分最高的10个特征时,模型的分类能力仍然令人满意,Kappa系数和总体精度分别为0.842和0.861。经对比分析,本文选取了161个特征(约删减26%)作为随机森林模型的最优特征子集,该子集分类的总体精度为0.935,Kappa系数为0.926。
2.3 分类结果的精度评价
2.3.1 分类结果的混淆矩阵分析 经2.2节的分析与对比,本文选取由161个特征构成的最优特征子集利用随机森林实现分类,分类结果如图4(e)。分类结果的精度评价采用混淆矩阵的方式,利用未参与建模的30%,200326个像元建立精度评价矩阵表(见表2)。对研究区内的9种作物,分类精度最高的是棉花,用户精度和生产精度分别为0.902和0.925,其次为水稻(用户精度和生产精度分别为0.932和0.88,下同)、枣树(0.819和0.906)、苹果(0.855和0.815)与核桃(0.886和0.786)。香梨、小麦、玉米和葡萄的用户精度都低于0.7。由表2可知,核桃和苹果类别易被错分为香梨,这是由于三者同属果树类别,具有高度重叠的物候期。进一步分析发现(图5):参与分类的特征集中在3月到8月间,此生长期内的小麦与林果物候期重叠,是造成小麦用户精度低的主要原因。研究区内玉米、葡萄种植分散、地块较小,将高分辨率的影像上目视解译的结果叠置在30 m分辨率影像上时,样本数量(分别为117个和34个)明显小于其他作物类别,且远低于分类的特征数,由此计算而来的生产精度和用户精度不具有代表性[18],本文认为对其精度分析没有意义。但为了研究的客观性,其精度值仍被列在混淆矩阵表中,由此说明30 m空间分辨率数据对研究区小地块少量样本类别分类的局限性,亦说明随机森林方法对样本数量具有一定的依赖性,但该研究在本文中并未深入说明。其他非作物类别的用户精度和生产精度均较高,除林地外,均超过了0.9。
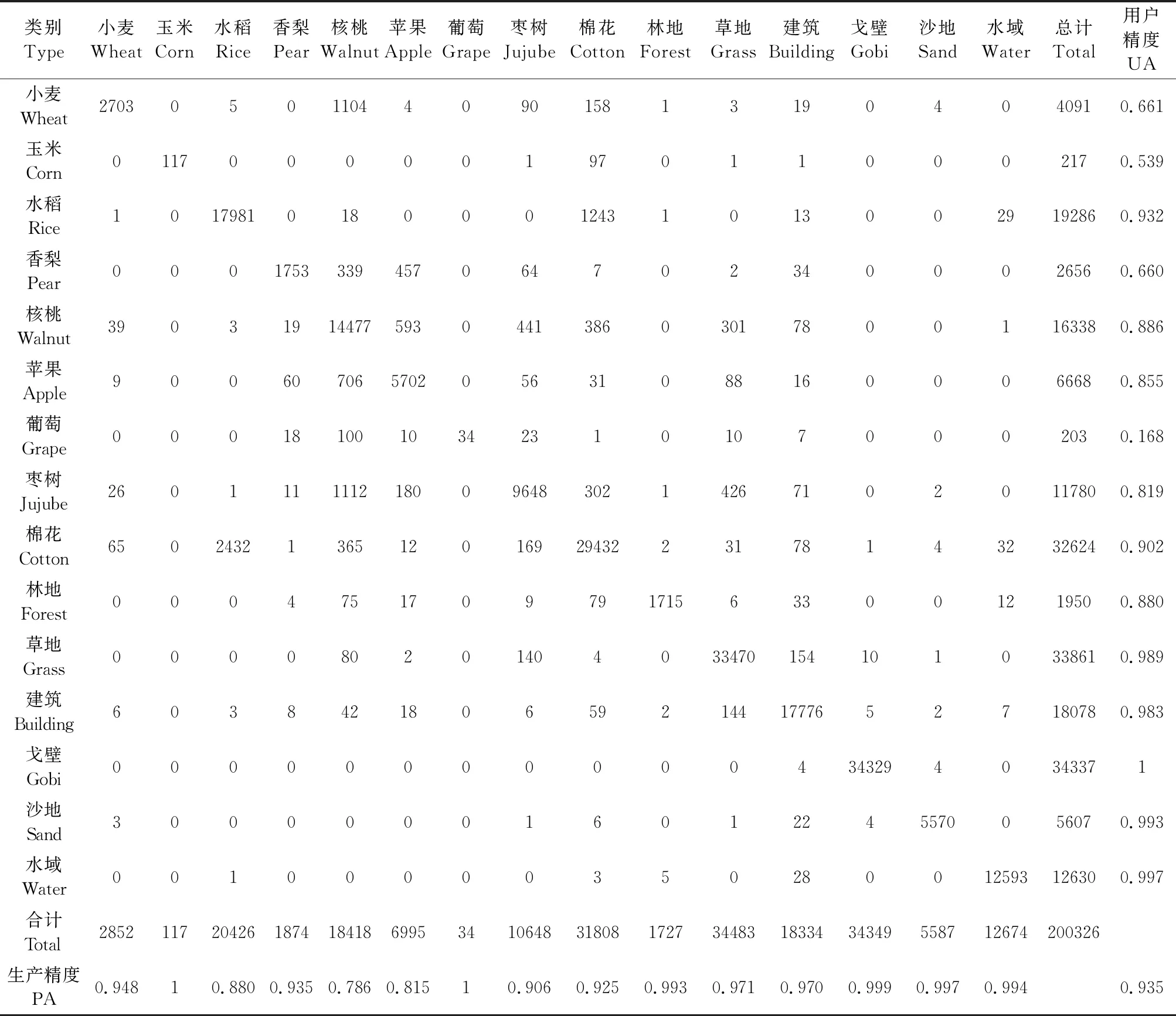
表2 随机森林分类模型混淆矩阵
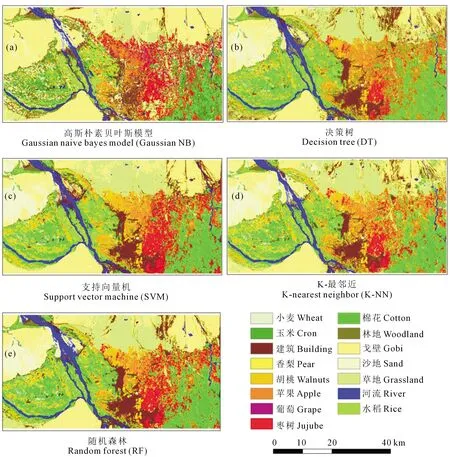
图4 5种监督分类算法的分类结果图Fig.4 Classification results produced by Gaussian NB (a) DT (b) SVM (c) K-NN (d) and RF (e)
2.3.2 随机森林方法与其他监督分类方法的比较分析 除了随机森林方法外,本文利用Python Scikit-learn模块实现了朴素贝叶斯高斯模型(Gaussian NB)、支持向量机(Support Vector Machine, SVM)、K-最邻近算法(K-Nearest Neighbor, K-NN)和决策树(Decision Tree, DT)4种常用的分类算法在研究区的地物分类,分类结果见图4(a~d),精度评价见表3。对5种常见监督分类方法的对比分析可知,随机森林分类模型的效果明显优于其他算法,其次是K-NN分类模型,其总体精度和Kappa系数也均超过了0.9,朴素贝叶斯高斯模型分类能力较差,Kappa系数仅为0.616。

表3 不同监督分类方法的精度对比
对比分析5种分类算法的分类结果,朴素贝叶斯高斯模型分类结果中存在明显错分漏分现象,其中棉花被错分为玉米,草地错分为戈壁。在决策树和支持向量机分类结果中,棉花与枣树混淆严重;在K-NN分类结果中存在棉花与苹果、枣树的混淆。但相比于其余4种监督分类模型,随机森林在特征选取后保持了较好的分类能力,在提取作物信息过程中,精度与效率均表现最好。因此,本文认为随机森林分类算法在作物的遥感提取中有很好的可用性。
3 讨 论
3.1 分类特征的重要性分析
为了评估模型(k=200、m=10)217个特征的重要性,利用归一化重要性评分量化各个特征对模型的贡献大小。图5排列出了模型中重要性排名前20的特征,可知7月13日、8月14日的特征重要性均较高,其次是3月23日。特别是7月13日影像的特征明显高于其他时相,高排名的特征数量也最多,这是因为在盛夏(7—8月)时,作物生长处于旺盛阶段,植被信息较为明显,有利于作物信息的识别。3月23日影像上的主要绿色作物为小麦和果树,其他农作物尚未播种,易于区别。
重要性排名靠前的特征主要是纹理特征的均值0713Mean和0814Mean、植被指数的0713LSWI、0713RVI、0713EVI、0713DVI、0814LSWI和0713NDVI等。其中Mean表示的是纹理规则的平均值,是作物在卫星遥感影像上的形态特性反映,与作物种类及其生长状态相关。LSWI指数表示了作物体内的水分含量,可知不同作物体内水分差异明显,成为类别识别的重要依据。其他排名靠前的植被指数(RVI、EVI、DVI和NDVI等)均与红波段和近红外波段密切相关,是农业信息识别中常用的波段或植被指数。由植被指数可知尽管不同农作物的生育期重叠,但结合其生长所需水分和生长状态的不同可以实现有效的识别。排名靠前的波段反射率为0323b7和0323b6,这两个波段均为短波红外波段,对水分信息敏感,可用于对绿色作物或水分含量差异的类别识别。
3.2 分类时相的重要性分析
遥感时相的选择是光学遥感农业应用的关键环节[2,6-8,10]。即使是处于干旱半干旱气候类型的研究区也未必每个生长季均能获取完整的时间序列影像数据,对其他气候区由于云、雾、雨、沙等因素的存在,仅能获取作物生长季的关键时期数据,因此对不同时相的重要性分析将对于指导影像的选择具有实用价值,图6列出了参与分类的不同时相特征的重要性值。由图6可知7月13日、8月14日和3月23日的特征重要性均较高,与上文3.1节分析相同。其中7—8月为研究区作物生长旺盛季节,3月为作物播种(栽培)或抽枝发芽季节,两个时期信息差异显著。由此可知,对研究区所代表的干旱区气候类型的作物识别,可选择两个关键时相:生长旺盛期与播种期,这一分析结果与赵良斌[25]与曹卫彬[26]等的研究结果一致。

注:研究中将所有特征按照影像时相加名称标记,如3月23日第4波段光谱反射率标记为0323b4;7月13日归一化水体指数(LSWI)标记为0713LSWI,其他类同。Note: Features are named according to the acquisition time of images and feature name. For example, the spectral reflectance of the 4th band from the image on March 23 is named 0323b4; The land surface water index (LSWI) from the image on July 13 is named 0713LSWI. Other features are named similarly.图5 特征重要性统计Fig.5 Variable importance of the three feature sets

图6 不同时相的重要性值Fig.6 Spider charts representing the temporal importance
3.3 随机森林分类精度分析
随机森林方法作为机器学习领域的研究热点被广泛应用于地物信息分类识别中。黄双燕等[9]基于机器学习方法,采用时间序列Sentinel 2A遥感数据提取典型干旱区的农作物分类信息,探讨了不同分类特征组合对随机森林分类精度的影响,结果表明:随机森林分类器以有效集成光谱和植被指数等多维向量的优势,将其应用于干旱区典型农作物分类上的精度均在89%以上,总体精度最高可达94.02%。同样是典型的干旱区作物分类,本文运用随机森林算法虽然得到了令人满意的分类结果(总体精度93.5%,Kappa系数0.926),但也发现对不同的作物,RF分类结果的生产与用户准确度之间存在差异。本文研究结果与黄双燕等[9]研究结果有所出入,主要原因在于,黄双燕等的研究对象仅有棉花、春小麦和冬小麦三类作物,所选研究区内作物类型单一,地块规整,与本文地块破碎、作物多样的研究区差异巨大。岳俊等[12]运用多种监督分类方法,结合光谱与纹理特征对南疆盆地4种主栽果树(核桃、枣树、香梨和苹果)进行遥感识别,结果表明枣树的分类精度远高于其他3种果树,而香梨、苹果、核桃光谱和纹理特征差异较小,分类精度较低。虽然岳俊等[12]在分类方法选择上没有利用随机森林方法,但对于不同林果类别分类精度的结论与本文一致(枣树分类精度最高,苹果、核桃和香梨三者易混淆)。苏腾飞等[27]基于多种植被指数时间序列和机器学习算法研究了内蒙古五原县的作物遥感分类,结果表明对于随机森林而言,EVI、、NDVI和NDSVI等组合具有最佳分类精度,与本文特征重要性排名靠前的植被指数一致。
综合以上分析,可知随机森林法对农作物的精细分类具有高精度、泛化能力强、高维特征处理等优势,但对于不同类别样本量的不平衡性(如本文葡萄和玉米的过小样本)的适应性差,如何选择最佳分类样本数仍需深入研究,以确定随机森林方法的适用性。
4 结 论
本研究探究了随机森林算法在干旱地区作物遥感分类的适用性,利用多时相的时间序列Landsat 8 OLI遥感数据提取多种分类特征(波段反射率、植被指数和纹理特征),探寻了高维特征支持下的随机森林作物精细分类,并分析参与分类的特征重要性,以期为分类最佳时相数据的选择、最佳分类特征集的选取等关键问题提供参考。主要结论如下:(1)随机森林算法通过GINI系数可以实现分类特征的重要性评价。在作物分类中,表示影像纹理平均规则程度的特征Mean、对作物含水量十分敏感的地表水分指数LSWI及短波红外光谱反射率均有较高贡献度。(2)最佳分类时相的选择可以依据分类特征重要性确定。对研究区所代表的干旱区气候类型的作物识别而言,可选择两个关键时相:生长旺盛期与播种期。(3)随机森林分类精度受分类特征数量的影响。按照重要性评分值从低到高的顺序删除部分特征,当删除数量低于总特征数的30%时,RF模型的分类精度基本保持不变;当删除量超过70%时,分类精度下降的幅度加大。(4)随机森林方法相对于决策树、支持向量机、朴素贝叶斯、K-近邻等监督分类算法,无论是分类结果的精度上,还是分类效率上均具有优势。
本研究的不足之处有:(1)对于参与分类的原始特征选取缺乏目的性,导致选择很多特征,如多个植被指数间存在信息冗余,可能会限制随机森林方法的分类敏感性。(2)研究区内作物类别的样本选择没有考虑到影像的分辨能力,导致对葡萄和玉米的分类结果不可靠,因此需要进一步研究随机森林算法对样本数量的敏感性。(3)对最佳时相的选择仅研究了单一时相的分类重要性,缺乏不同时相的组合研究。
