基于机器学习的P2P网络借贷违约风险识别模型比较
——以“人人贷”为例
2020-07-25裴晓伟张馨予
裴晓伟,张馨予
(南京邮电大学经济学院,江苏南京 210023)
0 引言
近年来,P2P网络借贷市场中由信息不对称所引发的借款人违约问题日益严重。自2017年起,众多平台相继因为借款人违约引发平台资金链断裂而爆雷,使P2P平台和投资者惨遭损失。2018年,随着监管措施进一步加强,问题平台全面爆发,此后P2P存量平台持续减少。至2019末,P2P网络借贷平台正常运营数量仅剩343家,网贷行业总体贷款余额同比2018年下降了37.69%[1]。总体来看,P2P网络借贷生态已经转向无担保化和严监管方向发展,相应地,对平台的风险控制和风险定价能力的要求逐渐走高。P2P网络借贷依托于互联网,已经积聚了量级巨大的借贷交易数据,因此,如何通过对这些大数据进行深度挖掘,从而识别借款人的违约风险,成为网贷平台和学者们近年来研究的重点。其中,机器学习在大数据分类问题中的优异表现为P2P网络借贷违约风险识别提供了新的思路。
本文将以“人人贷”平台的借贷数据进行实证分析,分析4种主流的机器学习算法——CART决策树、支持向量机、BP神经网络和随机森林在P2P网络借贷违约风险识别中的适用性,并对4种算法的预测效果进行比较。
1 文献综述
国内外许多学者已经将机器学习算法运用到P2P网络借贷违约风险的识别中,并取得了实质性的成果。
国外方面,Harris[2]发现在进行违约风险识别时,集群支持向量机比传统支持向量机在分类效果上展现出更好的优势。Jing[3]对来自Lending Club的借贷数据进行SMOTE采样,并运用深度神经网络(DNN)对其进行违约风险评估,发现DDN的预测精度显著高于多层感知机(MLP)。国内方面,安英博等[4]发现基于Stacking集成学习方法构建的违约风险识别模型可以综合单一机器学习模型的长处,预测效果更好,且可以减少对非违约用户的误判。张晨[5]基于Lending Club的个人信贷数据,使用随机森林和Easy Ensemble方法进行模型构建,发现随机森林模型在违约风险识别中的预测效果好于Logistic回归,且Easy Ensemble方法可以提升随机森林模型在不平衡数据上的分类表现。
从上述文献研究中,发现许多学者多基于某个或某类模型来进行违约风险评估,或者注重对某一类机器学习算法的优化,关于多种机器学习算法在评估P2P网络借贷违约风险时的性能对比方面研究较少。
2 实证分析
2.1 数据来源与预处理
(1)数据来源。本文选取“人人贷”作为数据源平台,考虑到P2P网络借贷期限短则3个月,长则36个月,因此,本文运用Python爬虫程序爬取了“人人贷”平台2016年1月至12月的散标数据,共32 081个样本。本文只保留“还款完成”和“标的违约”的样本,分别对应因变量——“违约情况”中的“违约”与“不违约”,其中违约样本为210个,非违约样本为26 342个。
(2)特征变量确定。对于自变量,本文结合变量间的相关系数矩阵,剔除了原始数据集中无意义、意义表达一致以及有唯一性的特征变量。此外,考虑到信用变量“成功借款次数”“申请借款次数”和“还清笔数”单独存在时可解释性较差,本文重新构造了“成功借款比率”与“清偿比率”并取代了之前的3个特征,其中:

经过上述筛选和处理,本文所选用的自变量共有30个,其中,描述借款信息的有:标的总额、投资人次、年利率、期限、标的类型和借款性质;衡量借款人基本信息的有:性别、年龄、学历、婚姻状况、收入、房产、房贷、车产、车贷、工作时间、公司性质、公司规模、公司行业、居住地区、工作认证和收入认证;衡量借款人信用信息的有:信用额度、借款总额、信用评级、成功借款比率、清偿比率、待还本息、逾期次数、累计逾期金额。
(3)独热编码(one-hot coding)与归一化。对于数据集中的无序分类变量,其标签数值大小无实际意义,本文对其进行了独热编码,用一组比特位表示一个无序分类变量的不同类别。此外,为了缩短BP神经网络模型和SVM模型的训练时间,提高求解的收敛速度和精度,本文对具有较强稀疏性的数据集采用绝对值最大标准化方法将数据压缩至[0,1]范围内。
2.2 评价指标选取
考虑到本文数据的非平衡性,在模型性能评估指标的选取上,本文将重点参考适用于评价非平衡数据集上分类器性能的AUC和Fβ指标,其中由于在违约风险识别中将潜在违约借款人贷前评估为正常借款人往往比将正常借款人评估为潜在违约借款人具有更大的风险,即召回率要比查准率更加重要,因此Fβ具体将选用F2,同时将查准率(Precision)和召回率(Recall)作为辅助参考指标。
2.3 模型构建
由2.1可知,本文数据为非平衡数据,考虑到重采样会破坏数据的比例信息,对数据集的分布改变较大,因此本文采用代价敏感学习方式来处理非平衡数据,即用不同权重的代价来区分各分类错误,以达到类别加权损失值近似的效果,从而达到整体代价最小。对于以下4种分类模型,本文通过设置各分类模型中的类别权重参数进行代价敏感学习,类别权重ωi计算方式如式(3)所示:

其中:ni表示第i类样本的个数,Nclass表示类别个数,n为样本总数。
2.3.1 CART决策树模型
决策树(Decision Tree)是一种由节点和有向边组成的以树形结构来展示决策规则和分类结果的机器学习模型[6],具有可解释性强、分类速度快的优点。因其在节点处选择特征时所依据的标准不同,决策树可分为ID3、C4.5和CART。鉴于CART决策树可以处理连续和分类两种自变量类型,同时适用于大样本,因此本文选择CART决策树。
CART决策树使用基尼系数(Gini coefficient)作为选择节点处分类特征的标准,对于给定的样本集合D,基尼系数的计算如公式(4)所示:

其中:Ck是D中属于k类的子集数量。给定特征条件下样本D的基尼系数为依据该特征值所划分的两子集基尼系数的加权平均值。
本文将数据集按照7∶3的比例划分为训练集和测试集,对训练集使用CART决策树算法进行训练,为了避免模型过拟合,本文利用网格搜索来寻找树模型最大深度的最优取值,以便对决策树进行“剪枝”,最终确定当树的最大深度为6时,测试集的F2最大,寻优过程如图1所示。CART决策树模型中AUC为0.980 8、F2为0.931 9,召回率为 0.963 0、查准率为0.825 4。
此外,本文根据剪枝后的决策树得出了各个特征的重要性程度,重要性由高到低依次为信用评级、清偿比率、累计逾期金额、借款期限、逾期次数、公司性质和成功借款比率,其余特征变量在决策树模型中重要性均接近于0。其中,信用评级的特征重要性高达0.91,是判断借款人是否会违约的重要依据。结合决策树的决策规则可以得出,信用评级在B及B以上的借款人违约风险较小,信用评级在B以下的借款人中,具有以下一个或几个特征的,如在非国家机关和非事业单位工作、借款期限大于15个月、无车产或清偿比率小于0.4等的借款人违约风险较大。

图1 CART决策树最大深度寻优过程
2.3.2 BP神经网络模型
BP神经网络是一种按误差逆向传播算法训练的多层前馈神经网络。其基本过程为,输入层信号经由隐含层正向传播,在输出层计算得到误差,再将误差按照梯度下降的方式反向传递,修正各层的权值和偏置。其中,训练集被整个网络训练的次数称为epoch,网络中各层权重的更新次数随epoch的增加而增加,epoch过高可能导致模型过拟合。
本文运用Python的Keras高层神经网络API来构建3层BP神经网络,对训练集进行训练,因为已有理论证明,3层BP神经网络可逼近任意复杂度的函数。对于隐含层节点数,先用经验公式确定初始值,根据下述经验公式,可求得本文中隐含层初始节点数为8。

其中:l代表隐藏层的节点数,n代表输入层的节点数,k代表输出层的节点数,i代表0~9之间的任意常数。
本文进一步运用网格搜索确定隐含层节点数和epoch的最优值,其中节点数的取值范围为8~15,epoch的取值范围为0~20。最终确定epoch的最优取值为16,隐含层节点数的最优取值为9,具体的参数寻优过程如图2—3所示。最终确定的BP神经网络模型中,AUC为0.940 5、F2为0.894 5、Recall为0.881 6、Precision为0.950 4。
2.3.3 支持向量机模型

图2 BP神经网络epoch寻优过程

图3 BP神经网络隐含层节点数寻优过程
支持向量机(SVM)是一种应用广泛的二分类机器学习算法,其基本思路是求解能够正确划分训练数据集并且实现几何间隔最大化的分离超平面。针对非线性及高维数据,SVM可利用核函数将原始空间的数据映射到高维空间,在新的特征空间完成分类,基本的SVM模型如下:

其中:w为法向量,ξ(i)为松弛因子,C为惩罚系数,C越高,对误差容忍度越小,模型越容易过拟合。
本文使用在非线性分类中效果较好的高斯径向基(rbf)核作为核函数,该核函数的表达式为:

其中:γ定义了单个样本对整个分类超平面的影响,γ越大,越容易被选择为支持向量。
本文对训练集使用SVM算法进行训练,利用网格搜索对初步模型中的惩罚系数C和γ进行调优,最终确定惩罚系数C的最优取值为1.2,γ为0.062,参数寻优过程如图4、5所示优化后的模型中AUC为0.999 2、F2为0.911 6、Recall为0.942 9、Precision为0.804 9。
2.3.4 随机森林模型

图4 SVM中参数C寻优过程

图5 SVM中参数γ寻优过程
随机森林(Random Forest)是一种以CART决策树作为基础分类器、运用Bagging方法组合成多颗决策树进行预测的集成学习算法。随机森林模型集成了每棵决策树的分类结果,并通过“投票”的方式输出票数最多的分类结果作为最终预测结果。相较于决策树而言,随机森林通过引入随机选择属性的方式有效地提高了模型的泛化能力。
本文对训练集使用随机森林算法进行训练,并使用网格搜索对每棵树的最大深度进行寻优,确定随机森林中单颗树的最大深度的最优取值为7,最终模型在测试集上的分类表现良好,AUC为0.999 8、F2为0.981 6、Recall为0.999 7、Precision为0.915 3。同时,本文得出了随机森林模型中各个特征的重要性程度,由高到低依次为逾期次数、信用评级、累计逾期金额、标的类型、年利率、标的总额、投资人次、借款总额、信用额度、借款期限、待还本息、清偿比率和公司规模,其余特征变量重要性均为接近于0。
2.4 模型比较
由表1可知,综合来看,随机森林模型的性能最好,CART决策树次之,支持向量机和BP神经网络分别位列三、四名。单独来看,4种机器学习方法的AUC均在0.9以上,F2均在0.85以上,表明4种机器学习模型都可以对借款人是否会违约做出很好的判断。此外,BP神经网络模型的查准率最高,达95.04%,显著高于其他3类模型,但召回率较低,仅为88.16%。随机森林模型和CART决策树模型的召回率较高,分别为99.97%和96.30%。
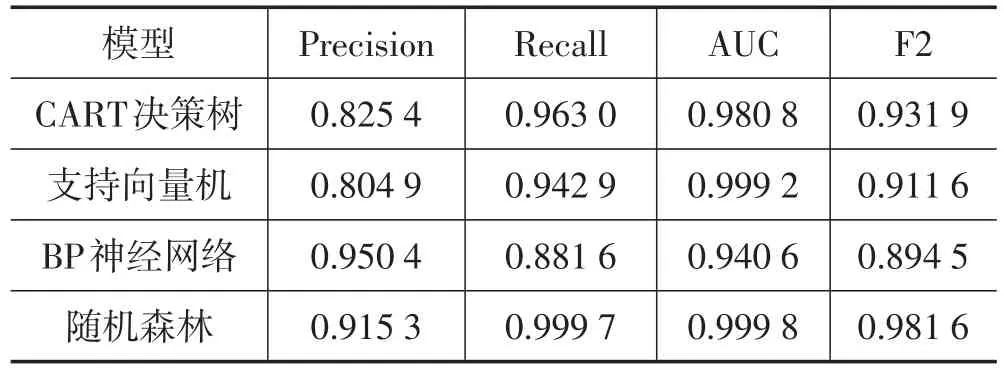
表1 4种模型性能比较
3 结语
本文以“人人贷”平台借贷数据为例,对包含借款人基本信息、借款人信用信息和借款标的信息3个方面共30个特征变量的借贷数据,利用4种主流机器学习算法建立P2P网络借贷借款人违约风险识别模型,并对各模型的性能进行对比,得出以下结论:
第一,机器学习算法在多维度借贷数据下的违约风险识别中适用性较强,各评价指标如AUC、F2等均较高,可以有效地利用借款人贷前数据预测借款人的违约情况。第二,相比于SVM和BP神经网络模型,CART决策树模型和以随机森林为代表的集成学习方法在P2P网络借贷违约风险识别中性能较优,可解释性强,两类树模型的召回率均达到96%以上,F2达到93%以上,其中随机森林模型综合性能在4类模型中表现最优。第三,结合两类树模型,发现借款人信用评级、清偿比率、累计逾期金额、借款期限、逾期次数这5个变量对违约的影响较大,年利率、标的类型、借款期限和标的总额等变量也会对违约产生影响。
