基于深度学习的数学书面作业智能批阅研究
2020-07-22黄松豪徐建华杜佳玲
黄松豪 徐建华 杜佳玲
摘要:针对深度学习如何应用于数学书面作业批阅问题,通过对图像的预处理以及优化图片训练集和图像处理算法,实现文本字符切割,采用Tesseract-OCR光学字符识别方法,训练公式中存在的字符样本,通过与纸面上的公式匹配提高识别的准确性,最后采用java可视化界面实现算式识别的功能,对不同情况下拍摄的照片进行测试。测试结果表明该系统高效、精准、实用。
关键词:深度学习;图像处理;光学字符识别;算式识别
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)12-0196-02
教育领域对作业批改智能化的需求越来越多。教师每天需要批改大量数学作业,费时费力。将纸质作业拍摄成照片用机器智能识别并评判成为一个有价值的课题。当前市场上已推出多个OCR产品广泛应用于车牌识别、名片识别、身份证识别等。但这些OCR产品中,除了Tesseract OCR外,其他均为商业性软件,收费高。由于并无与教学场景具有对应性的专项算式字库,造成实际识别度并不高,无法直接应用于书面作业的识别。本文研究如何将OCR技术运用于学校的数学书面作业批改与分析中,设计具有可实施性的识别方法。
1方法
1.1作业图像处理
由于拍摄受外面环境的影响,如空气中的尘埃,光照,摄像头拍摄角度等因素影响,作业图像处理容易受到干扰。为确保图像质量,提高字符识别度,在机器进行识别之前需要对图像进行一定的预处理。排除对应图像中存在的各项干扰项,以提升图像处理效果,为字符识别创造条件。在OCR技术应用时,首先开展的预处理工作流程可以分为读取图片、灰度化、二值化、降噪等。
1.1.1作业图像灰度化
我们日常所见的图片,其实都是由RGB模型(Red,Green,Blue)组成,如果R=G=B时,则表示一种灰度色,因此各灰度像素可通過单个字节的方式进行灰度值存放,相应的灰度值结果介于0至255之间,通常对图片进行二值化之前都要进行灰度化操作,经过灰度化操作的图像在进行二值化处理时的效率就会高很多,并且能有效地减少图像中的噪声像素,当前常见的灰度化算法包括分量法、最大值法、加权平均法等。在纸面作业拍摄过程中,时常会遇到图像亮度分布不均衡的情况,为便于后续处理,本论文选用加权平均法的方式进行处理,对坐标为(x,y)的像素点进行灰度化,见公式(1):
Gray(x,y)=0.31Red(x,y)+0.591Green(x,y)+0.11Blue(x,y)(1)
1.1.2作业图像二值化
在作业图像处理流程中,图像二值化是其中的一项重要环节,在进行视觉检测、智能识别时,都需要开展图像二值化工作。现阶段常见的二值化算法主要包括固定阈值法、双阈值法、大律法、递归阈值法等。在经过上文的灰度化处理之后,本文对比上述方法发现图像采用固定阈值二值化处理会方便许多,拍摄的纸质作业经过灰度化处理之后,通过迭代的阈值分析,选取出170作为最优阈值,处理之后的图像效果非常理想。
1.1.3作业图像降噪
图像噪声主要是指图片中所出现的不必要、对图片质量造成干扰的像素信息。在生活中进行拍摄或传输时,可能形成图像噪声,这会在一定程度上降低图像质量,使得机器和人眼对图像的敏感度下降,成为后期图像识别等一系列操作中的难题。图像降噪处理可以在很大程度上降低这些噪音数据给后期进行识别带来的麻烦。图像降噪工作不光可以使得图像更为平滑,更能突出图像的主要表达信息,也是对图像进行识别时需要首先开展的前提工作,图像识别的前期进行降噪处理能够很好地提高后期识别的精准度和识别速度。
图像中出现频率较高的噪声可以分为椒盐噪声、瑞丽噪声、高斯噪声等,本文的处理对象为普通图像中的椒盐噪声。
椒盐噪声通常是图片中在随机位置形成的黑点或白点。其产生大部分是由图片的切割出现问题引起,一般对应于这种情况,可以采用中值滤波的方式实现椒盐噪声消除。
中值滤波是将周围的像素进行排序之后进行排序取出中值来替代各点。同时它也是目前消除图像噪声最常用的方法之一,特别是对于椒盐噪声的降噪效果。因此中值滤波进行噪声消除成为本文的首选方法。
1.2作业图像OCR技术
Tesseract是由普惠实验室进行研发后来交由谷歌优化升级的开源OCR引擎。同时也是当前市场上较少能够支持汉字的专项开源识别库。Tesseract精确性较高,在1995年的全球测试中排名第三位,其精准度与商业领域的OCR技术引擎十分接近。用户可以根据自己的需求有针对性地进行样本数据的训练,并且研发出满足自身实际需要的专用引擎。本文以Tesseract为基础,首先研究作业批改要进行的流程和实现细节,然后开发了作业批改OCR引擎。
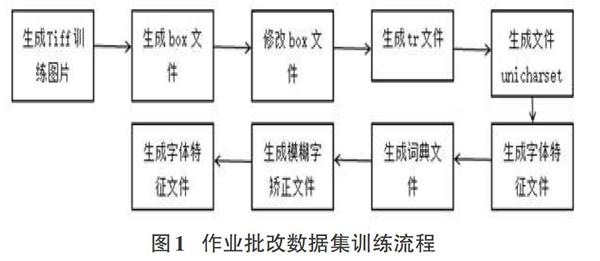
Tesseract的识别主要基于KNN算法。KNN算法又叫K邻近算法,是分析测试图片中的每个像素点和样本图像中对应像素点距离的总和实现的,一般计算距离的方式有欧氏距离和曼哈顿距离两种方式(欧氏距离采用较多),将距离最近的K个点排序出来,选取其中出现频率最高的几个样本标签作为预测值。Tesseract使用KNN算法来返回预测的值。图1展示了基于Tesseract的作业批改OCR引擎训练步骤:
1.2.1字库训练步骤
(1)生成Tiff图片集。在进行训练集的生成前,需要先准备一些自己手写字符的图片和电脑印刷体字符的图片。并确保各字符产生的最低频次。通常而言,对于较少出现的字符需保持十次以上的数量样本,对于较多出现的字符需保持二十次以上的数量样本。尤其在进行字库训练时,需将该字库中的样本图片作出整合,放入专用Tiff图片集中,以备后期训练时处理。需要特别注意的是,在一个字库的训练样本中,要确保文本字体统一。若有多种字体的要求,要分开训练成不同的字库。把准备好的同一个字库的样本图片整合进一个Tiff图片集里面,供后面训练使用。实现步骤首先打开JTessBoxEditor,随后以此打开打开tools选项和merge tif选项,点击样本图片,生成Tiff格式图片集。
(2)生成Box文件。在字库训练过程中,需要开展文本检测工作,对文本做出定位,且形成包围框。Box文件会有序的检索样本图片中的字符,并且用蓝框上下左右包围当前字符以及显示当前字符的坐标位置。
(3)修正Box文件,更正样本中存在的各项识别错误。修改Box文件,纠正样本中的识别错误问题。在识别复杂情况下拍摄的图片时,Tesseract识别率较低,造成Box文件中出现较多错误字符。因此需采取手动修正的方式进行更改。尽管该过程耗时较长,但是能够直接的影响最后识别效果的精准度。实现步骤首先打开JTessBoxEditor,選择BoxEditor选项,最后单击Open,选择Tiff图片集。打开之后将Tiff图片集与Box文件处于同一层目录,否则会没有字符坐标、识别结果等对应信息。
随后对左侧文字识别错误做出修改,并且可以通过Merge、Split、Insert、Delete来对识别框进行合并、分离、添加和删除。
(4)生成Unicharset文件。该文件包括Tesseract引擎在完成训练后所识别的各字符信息,因此也被视为Tesseract新字库中的重要组成项目,该文件会显示当前文件中存在多少个字符,以及每个字符的信息。
(5)创建字体特征专用文件。在日常生产生活中,同一语言可能会出现手写体、印刷体等多种字体,因此在训练集中出现的字体形式也较多。创建专用的font.txt文件,里面的内容为“”。
其中“font-name”可以表明对应字体的具体名称,与前面的Box文件名相对应。
(6)编制作业批改的词典。为加强搜索效果,Tesseract中的词典以向无环字图(DAWC)进行表示,DAWG可以支持多部词典搜索,如系统词典、文档词典、用户自建的单词词典等。写词典时,首先建一个TXT文件,每行一个字,将所有四则运算中会出现的字符都写入文件中,然后保存为UTF-8文本文件。
(7)整理形成模糊字文件。模糊字文件不是生成最终文字库必需的文件,但能够有效识别并修改存在的错误,提高实际应用中的准确率,保存为UTF-8格式的文本文档,并以“unicharambigs”进行命名,在创建该文件时,需做出多次验证,找寻常见的易错字符,这也是模糊字文件整体形成的关键。
(8)创建.traineddata格式的训练文件。步骤为:首先以“tesser-act名称,tif名称nobatchbox.train”的方式创建TR文件;再通过“mftraining-F font-Unicharset名称.tr”指令,并将对应的字体加入,tr文件;随后,启用“cntraining why4.tr”命令,会发现文件夹下生成了很多新文件,对这些文件加上前缀,以“combine_tessdata why4”命令的方式实现文件合并,即形成专项字典文件。
2识别准确率的验证结果及分析
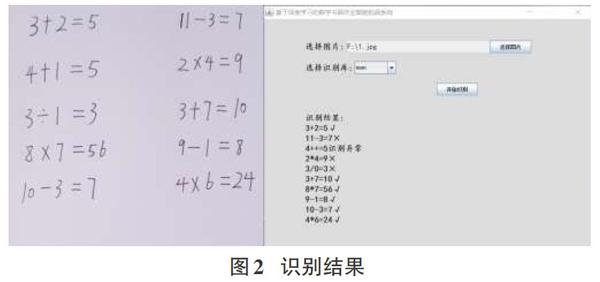
为验证该方法的有效性,从南京某校园内收集作业100份,统计题目共1000条,利用开发的作业识别应用进行识别,实验结果为其中911条识别完全正确,另外89条有识别错误,准确率为91.1%。识别结果如图2所示,从图中可见,大部分的识别能够保证正确并且也能做出正确判断,只有少数的数据存在识别异常或者识别错误的情况,图中可以看出第三行将“1”识别成“+”,第五行将“1”识别成“0”,无法完成较好的错误纠正,只能通过Tesseract判断,故识别错误率较高。图片清晰度较差也会对图像的处理造成很大的问题,添加识别难度,故图片拍摄光线较好的情况下识别正确率会大大提高。
3讨论与总结
经实验得到总体识别率能保持在91.1%,精准度相对较高,基本满足正常情况下的应用,其中少数的错误需要老师或者家长进行手动校对,而对于这些错误,最根本的办法就是提高样本的数量以及质量,在往后实际应用的深度优化中拟采用BP算法对本文进行进一步的优化以提高精准度,在识别出现异常时用BP算法训练的数据集来替代模糊字文件进行错误矫正。
