面向新闻事件的故事树构建方法
2020-07-20陈黎明黄瑞章秦永彬陈艳平
陈黎明,黄瑞章,秦永彬,陈艳平
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 贵州省公共大数据重点实验室,贵州 贵阳 550025)
0 引 言
新闻数据的爆炸级增长使得人们难以获得总结性的信息,丧失对信息的全局把控[1]。因此对新闻事件进行动态追踪并构建其发展脉络是如今迫切需要解决的问题。事件追踪是在后续新闻报道中辨认出给定事件所相关的报道[2]。脉络构建是根据追踪到的新闻来对事件发展进行梳理,以一定的形式,比如时间线、事件线索等方式来呈现事件的发展过程[3]。然而现有方法存在以下问题:①随着时间发展,事件重心会发生漂移[4],在事件追踪时容易遗漏相关新闻;②事件脉络构建仅在时间以及内容相似度等层面做研究,没有从全局的角度来进行脉络构建,造成事件脉络不连贯,整体性较差。
针对上述问题,本文提出了一种面向新闻事件的故事树构建方法。首先在事件追踪过程中,根据追踪到的新闻的关键词词频-逆类别频率(term frequency-inverse category frequency,TF-ICF)和热度对事件关键词进行反馈更新。其次采用有主干和分支的故事树结构来展现事件脉络,并利用新闻热词来定位事件发展的关键节点,生成故事的主干结构。本文利用真实事件新闻数据集来实验提出的面向新闻事件的故事树构建方法,并基于用户体验来评价方法表现。实验结果表明,该方法所构建的事件故事树在可读性、完整性上表现良好。
1 相关工作
信息过载的问题日益凸显,如何提高知识获取的效率一直以来是一个热点研究问题。事件追踪作为传统TDT的子任务,被广泛用于获取事件相关的信息。传统的追踪方法基于分类[5]和聚类[6]算法,但由于漂移现象的存在,因此已经不能满足动态话题追踪的需求。近年来,基于自适应追踪的方法成为该领域的研究热点。文献[7]提出了一种基于动态阈值及分类器集成的自适应话题追踪方法,旨在解决动态阈值和传统分类器集成方式的不足。文献[8]通过自动抽取出的话题相关特征词条来描述话题中的事件信息,并且通过本体的不断进化来进行话题自适应追踪。文献[9]提出了一种基于关键词衰减指数的自适应追踪方法,然而在新增关键词权重上每次只增加固定的值,未考虑到新增词的重要性信息。文献[10]利用最小特征平均可信度阈值更新策略来完善话题模型。文献[11]基于时间的分布属性调整特征向量权重分配,实现模型的自适应学习更新。文献[12]提出一种基于关联语义网络的话题追踪方法,解决了无法详细描述话题追踪趋势的问题。
构建事件脉络是TDT领域衍生的新研究问题,旨在用一定的形式来展现事件的发展趋势。目前有许多方法基于相似度来寻找子事件之间的联系。文献[3]基于内容相似度和时间距离计算新事件与已有事件的连接强度,将新事件连接到连接强度最大的节点。文献[13]构造了一种结合文本相似度、时间相似度和实体相似度的多视图属性图来表示文章之间的关系,并提出了一种社区检测算法,对图中的子事件进行分割和链接。文献[14]先识别重要的事件,并根据语义相关性来捕捉它们之间关系。文献[15]根据动态阈值的设定、相似度平滑、子主题动态增量策略等过程来进行事件演化分析。文献[16]基于事件地点、人物、核心词等相似度生成事件有向无环图,然后从有向无环图中构造最大生成树,并用最大生成树表示事件的分支。这些基于相似度的方法仅停留在关系分析上,未从全局的角度考虑到事件的发展结构是有规律的,同一发展阶段的子事件描述的内容各不相同,基于相似度很难将它们联系到一起。
此外,还有一些方法从其它角度来进行脉络构建。文献[17]从词覆盖的角度提出一种新闻脉络链构建方法, 利用新闻的评论信息来定位新闻事件转折点。文献[18]提出了一种基于无参数生成模型的故事情节结构化表示和演化模式提取方法,并结合中国餐馆过程(CRP)自动确定故事情节的数量。文献[19]提出了一种基于神经网络的方法来提取故事情节的结构化表示和演变模式。文献[20]通过分析社交媒体中的文本、时间、图像、评论、观点、情感和用户交互等多模态数据,感知事件并刻画事件的关系,从而实现对事件的总结。
相比于上述的方法,本文方法更适用于新闻事件的追踪与发展脉络构建,从关键词的角度出发,对事件相关新闻进行动态追踪,并根据新闻热词定位事件的关键发展节点,解决事件脉络构建仅在时间以及内容相似度等层面做研究而造成脉络不连贯、整体性较差的问题。
2 术语定义与研究目标
2.1 术语定义
定义1 新闻(news):一篇新闻d由新闻标题、正文、发布时间组成。
定义2 子事件(subevent):子事件指涉及特定的时间和地点、相关人物的某件具体事情,由四元组
定义3 事件(event):事件由一个种子子事件以及与其直接相关的子事件组成。新闻事件通常会包含不同的子事件,反应的是事件的不同侧面或者发展。比如“埃航波音客机坠毁”事件,它是由“埃塞俄比亚157人客机起飞6分钟后坠毁”这个种子子事件以及后续的“救援”、“调查”、“停飞波音737MAX”、“索赔”等一系列高度相关的子事件组成。
定义4 故事树(story tree):每颗故事树S={branch1,branch2,…,branchn} 对应一个事件,由多个分支按时间先后顺序连接而成。每个分支branch=
图1展示了“孟晚舟被捕”事件对应的故事树,该故事树包含了20个节点,3个分支,其中分支上的每个圆节点代表了一个子事件,每个分支代表了该事件的一个发展阶段,3个分支的根节点构成了树的主干结构,展示了事件的发展过程。分支A 对应着“孟晚舟在加拿大被捕”初始阶段的信息,分支B对应着“孟晚舟保释”相关信息,分支C对应着“孟晚舟引渡”相关信息,该事件还在继续发展,还会产生新的分支。由此可见,通过有主干和分支的故事树来展现事件的发展脉络,有助于用户快速了解事件的主要信息,轻松掌握事件的发展过程。
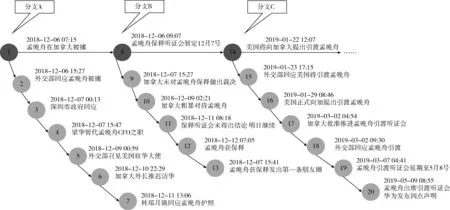
图1 “孟晚舟被捕”事件故事树
2.2 研究目标
给定一组新闻信息流 {D1,D2,…,Dt,…}, 其中Dt是时间窗口t内的新闻集合,本文的目标是:
(1)从Dt内提取事件相关新闻;
(2)将事件相关新闻聚类成子事件集合subevent_set={se1,se2…se|E|}, 并提取相关信息将子事件进行封装为四元组
(3)将步骤(2)输出的子事件组装成故事树S, 并进行可视化。
3 故事树构建方法
3.1 方法总体设计
本文方法总体设计如图2所示,主要分为4个部分。第一个部分是数据预处理,对于持续到来的新闻数据流,先过滤掉正文长度低于20的新闻,然后使用Hanlp工具包对新闻进行分词和去停用词处理。第二个部分是事件追踪,包含了提取有故事偏向性的新闻关键词、提取事件相关新闻、反馈更新事件关键词3个步骤。第三个部分是子事件聚类,在提取出事件相关新闻后,使用流式聚类算法SinglePass聚类出子事件,并提取相关信息来封装子事件。最后一个部分是故事树构建,首先根据当前时间窗口内的新闻热词来定位事件发展的关键节点,判断是否需要新建故事树分支,即判断故事是否发展到了一个新阶段,其次是判断故事树中是否存在当前子事件,如果存在则合并子事件,否则查找该子事件在故事树中所属的分支,并更新故事树。接下来,将详细介绍后3个部分。
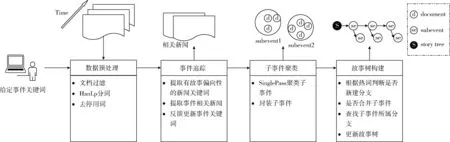
图2 方法总体设计
3.2 事件追踪
事件追踪阶段,其主要目的是从大量的日常新闻中提取出事件相关的新闻,其流程如图3所示。在每批待追踪新闻数据到来时,其追踪流程是一个循环处理的过程。首先,通过对事件关键词进行加权的TextRank算法来提取有故事偏向性的新闻关键词来作为新闻文本特征表示。其次是通过计算相似度来提取事件相关新闻。最后,判断这一轮提取的新闻数量和上一轮提取的是否相同,相同则结束追踪流程。否则计算本轮提取出所有新闻的关键词TF-ICF和热度,并根据TF-ICF、热度和衰减指数来反馈更新事件关键词,继续下一轮循环,直至提取出的新闻数量不再发生变化,这可以最大程度地将事件相关新闻提取出来。在接下来的小节里,将详解介绍这些步骤。
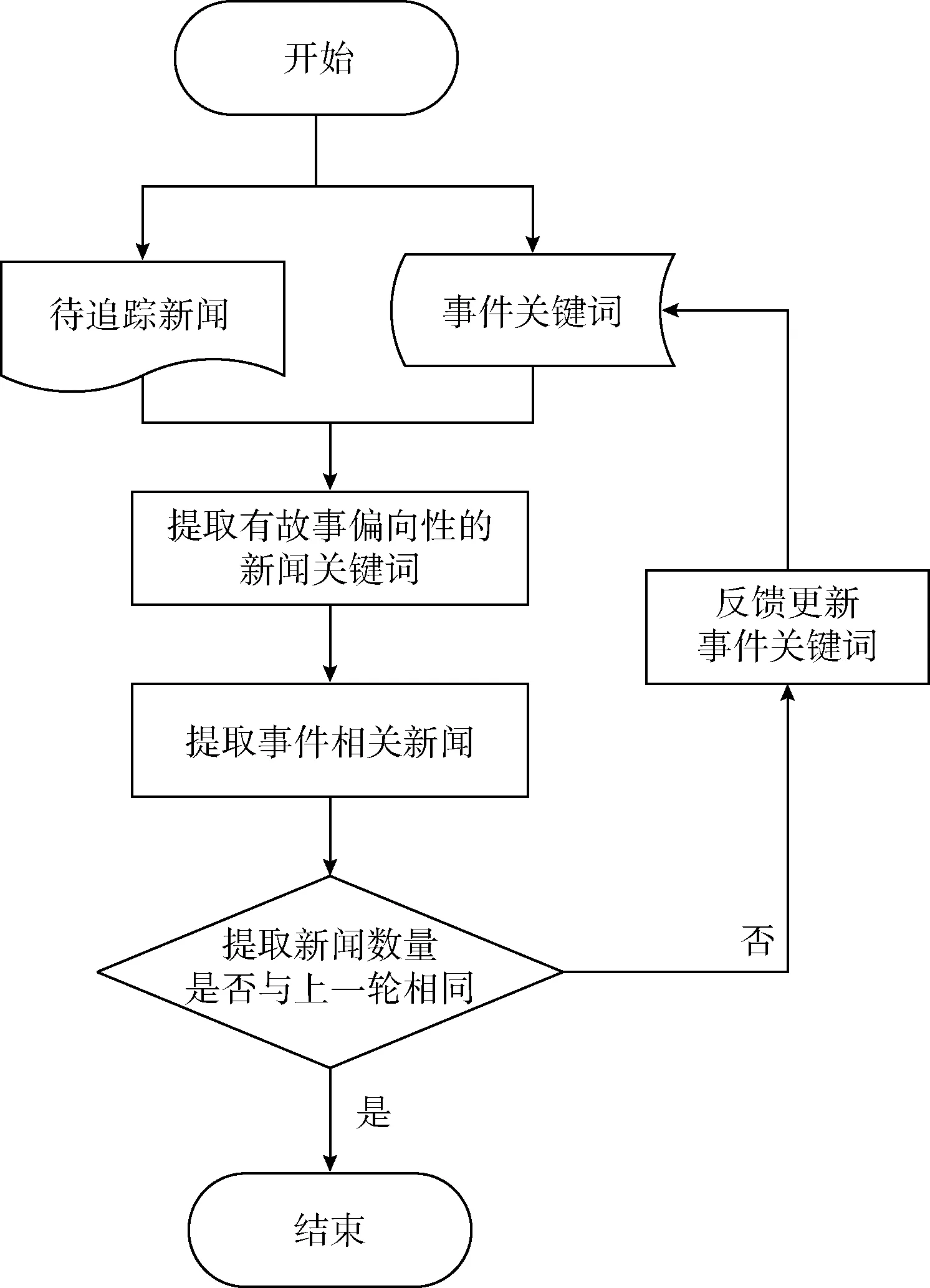
图3 事件追踪流程
3.2.1 提取有故事偏向性的新闻关键词
TextRank是一种常见的关键词抽取算法,但该算法忽略了词语本身的重要性信息。在该算法中词语的重要性会影响相邻节点间的影响力传递而导致关键词抽取效果不佳。当对某个的特定事件进行追踪时,随着时间发展而变化的事件关键词的重要性比其它词语高,因此,本文对事件关键词的权重进行了调整,使用加权的TextRank算法来提取有故事偏向性的新闻关键词,提高事件关键词在新闻中出现时被作为新闻关键词提取出来的概率。
设Vi为给定文本中的任何一个词语,则基于加权Text-Rank算法的权值迭代公式为
(1)
式中:d为调节系数,一般取0.85;In(Vi) 表示指向节点Vi的所有节点的集合;Out(Vj) 表示节点Vj指向的所有节点的集合。wji为节点Vj的词语重要性影响力传递到节点Vi的权重,其计算公式如下
(2)
式中:I(vi) 表示节点Vi的重要性取值。设λ为对词语进行加权的参数,本文中λ取2,则I(vi) 赋值如下

(3)
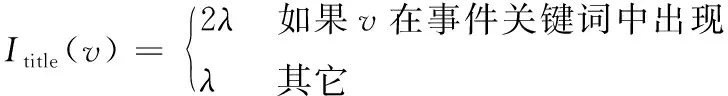
(4)
基于式(1)~式(4)进行迭代运算,当式(1)两次迭代结果之间的差异非常小时停止迭代运算,该值一般取0.0001。然后按照大小对WS(V) 进行降序排序,选取前8个候选词作为新闻文本关键词。
3.2.2 提取事件相关新闻
通过式(5)计算追踪的事件和新闻文本之间的相似度,其中KT为事件关键词集合,KN为新闻文本关键词集合。Jaccard相似度用来比较样本集之间的相似性,Jaccard系数值越大,说明相似度越高。相似度大于阈值的新闻文本被判定为与事件相关,相似度低于阈值的则判定为与事件不相关
(5)
3.2.3 反馈更新事件关键词
由于在事件追踪过程中存在漂移现象,事件重心会发生变化,事件关键词也随之变化,使用初始给定的关键词对后续新闻进行追踪时效果较差。为了更全面准确地对事件进行追踪,需要融入新的事件特征,对事件关键词进行反馈更新。因此本文提出了融合关键词TF-ICF、关键词热度以及关键词衰减指数计算的反馈更新方法,TF-ICF和热度旨在融入新的事件特征,衰减指数旨在对事件原始特征进行减弱。值得一提的是,事件最重心的词并不会随着时间的推进而消失,因为它一直出现在事件新闻中,在减弱的同时也增加了其权重。
TF-ICF被用来衡量词语的重要程度,一个词语的重要性与它在文档中出现的次数成正比,但同时会随着它在各个类别中出现的频率成反比下降。例如 “继续”这类词,虽然它出现的频率较高,但由于它出现在各类别的频率也比较高,由此可以推断出是一个常用词,重要性较低。通过ICF的计算可以过滤掉这种词频很高但不重要的常用词。TF是一种用于数据挖掘的常用加权技术,表示一个词语在一篇文章中出现的频率,在本文中表示词语在事件新闻关键词中出现的频率。ICF是逆向类别频率,由总类别数目除以包含该词语的类别数目,再将得到的商以10为底取对数得到,在本文中ICF的类别由Kmeans预聚类得到。
设n(vi) 为词语Vi在新闻关键词中出现的次数,Ci为词语Vi出现的类别,则TF-ICF的计算公式如下所示
(6)
(7)
tficf(vi)=tf(vi)*icf(vi)
(8)
此外,一个词语的重要性还与其热度有关。热度代表了词语被提及或被关注的趋势。一个词语的热度越高,它出现的频率相比于历史时刻就会有明显的增高趋势。这种在使用频率上发生较大变化的词,称之为热词,代表着事件有了新的发展,在更新事件关键词时其重要性比较高。例如对于西安奔驰维权事件来说,“金融”以及“服务费”在2019年4月14日的新闻中频繁出现,而在之前的事件新闻中从未出现,在融入新的事件特征时,考虑到它们反映了事件的发展情况,其权重要有所增加。
本文通过热度分数来衡量一个词语的热度。设K为词语个数,n(vi,tj)为词语vi在时间窗口tj内的词频,g(vi,tj) 为词语vi在时间窗口tj内的词频梯度,aver(g,tj) 为在时间窗口tj内所有词语的平均词频梯度,n(vi,t1,t2,…,tj) 为词语vi在全部时间窗口内的词频,aver(n,t1,t2,…,tj) 为在全部时间窗口上所有词的平均词频,则词语vi在当前时间窗口tj的热度分数s(vi,tj) 计算公式如下所示
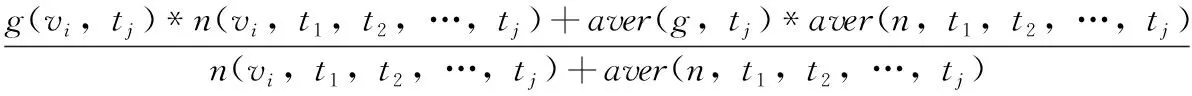
(9)
(10)
(11)
(12)
在每一轮提取出事件新闻后,通过以上方法计算提取出的所有新闻的关键词TF-ICF值和热度分数,将新的特征融入至事件模型,并根据关键词衰减指数对原始特征进行减弱,具体的计算方法如下。
设当前时间窗口tj的事件候选关键词向量为V(tj)=(v1∶w1,tj,v2∶w2,tj,…,vi∶wi,tj), 其中vi表示事件候选关键词,wi,tj表示候选关键词vi在时间窗口tj的权重。wi,tj计算公式如下
wi,tj=θ×wi,tj-1+c(vi,tj)
(13)
其中,c(vi,tj) 表示时间窗口tj内候选关键词vi新增的权值,α和β为系数,分别取值0.4和0.6,θ为候选关键词衰减指数,c(vi,tj) 的计算公式如下
c(vi,tj)=α×tficf(vi,tj)+β×s(vi,tj)
(14)
式中:热度分数s(vi,tj) 是一个0-1的数,tficf(vi,tj) 经过单位化处理也是一个0-1的数。
通过式(14)对事件候选关键词向量进行更新后,按其权重大小进行排序,挑选权重值排前8的候选关键词作为事件新的关键词,完成事件关键词的一次反馈更新。
3.3 子事件聚类
子事件聚类阶段其主要目标是提炼新闻信息,将事件追踪阶段提取的新闻聚类成子事件,并提取相关信息来对其进行封装,作为构建事件脉络的节点。
SinglePass是一种增量聚类算法,简单高效,其主要思想是将流式数据作为输入,计算每一条新数据与已有类的相似度,相似度大于阈值则纳入类中,否则新建一个类。本文使用SinglePass算法来对子事件聚类,聚类特征选取的是新闻标题TF权重、正文TF权重、关键词TF权重,其中关键词是在事件追踪阶段提取的有故事偏向性的关键词。
通过聚类得到的子事件新闻集合由于易读性差,无法直接用于故事树构建,为了更直观简洁地在故事树中展示事件的主要信息,接下来从这些新闻簇中提取信息来对子事件进行封装,详细的过程如下:
(1)将子事件新闻最早的发布时间作为子事件的发生时间Tse;
(2)将子事件新闻的关键词集合作为子事件的关键词Kse;
(3)将聚类得到的子事件新闻集合作为子事件News_set;
(4)新闻类文章的标题就是对文章内容的高度概括,而且在标题中出现次数越多的词越与子事件有关,因此使用基于标题高频切分的新闻热点短语提取方法[21]来提取子事件的概要描述Dse。 该方法对同一子事件的多篇新闻,筛选出标题词频最大的前N个词作为该子事件高频词集,使用高频词集来寻找每个标题的高频切分边界,并根据切分边界对其进行切分,将切分结果作为候选短语集,并且最终只选择一个最佳短语来描述子事件。
3.4 故事树构建
故事树构建阶段的目标是为新闻事件生成发展脉络。新闻事件的发展是有一定规律的,一系列的关键节点推动着事件不断往前发展,在某个关键节点下又有着描述不同方面的子事件。当事件到达一个新的关键节点时,这代表着事件进入了一个新的发展阶段。在其未进入下一个发展阶段时,会有描述该发展阶段不同方面的子事件被报道出来。这些子事件涉及面较广,内容差别较大,例如“孟晚舟被捕”事件初始阶段有“被捕”、“各方回应”、“股价受影响”等子事件。基于相似度的方法倾向于将相似的子事件聚集到一起,无法捕捉到事件的这一发展规律,因此所构建的发展脉络不连贯、整体性较差。根据新闻事件的这一发展规律,本文认为梳理新闻事件的发展脉络时需要区分主干和分支,其中主干结构应该由事件的一系列关键发展节点构成,分支由各发展阶段的子事件组成。
如何从大量的新闻数据中提取事件发展的主干结构是个难点。本文通过分析事件新闻关键词的演变发现,当事件进入一个新的发展阶段时,会频繁提及某些词,而这些词在之前的新闻中几乎从未出现,它们出现的频率较之前有着异常的变化。因此,可以通过这些出现频率有着异常变化的词来定位事件发展的关键节点,生成故事树的主干结构。在本文中称这样的词为热词,热词由热度分数计算得出,当一个词的热度分数大于设定的阈值0.6时,它就是一个热词,其中热度分数计算在3.2.3节做了介绍。
故事树构建的伪代码如算法1所示。给定子事件集合subevent_set、 当前故事树S、 新闻热词hotwords、 当前时间窗口的事件关键词eventkeyword。 首先,判断该事件的故事树S是否存在,不存在则新建一颗故事树,并为故事树新建一个分支,将事件关键词设为分支关键词(行(2)-(4))。如果该故事树存在,根据是否存在新闻热词来判断是否需要创建新的故事树分支(行(6)-(8))。然后,循环遍历子事件集合,如果子事件相似度大于一定阈值则合并(行(10)-(12)),否则根据子事件关键词是否包含故事树分支的关键词来寻找子事件所属的分支(行(13)-(18))。最后,将分支的子事件按发生时间先后顺序连接起来,将分支按时间先后顺序连接起来,完成故事树的一次构建过程(行(21)-(25))。
算法1: 故事树构建算法
输入: 子事件集合subevent_set={se1,se2…se|E|}
当前故事树S={branch1,branch2,…,branchn}
新闻热词hotwords
当前时间窗口的事件关键词eventkeyword
输出: 更新后的故事树Supdated={branch1,branch2,…,branchn}
(1)Arrange subevents ofsubevent_setin ascending order of occurrence time
(2)ifSis not exist then
(3) createS/*新建一颗故事树*/
/*新建故事树第一个分支并将事件关键词设为分支关键词*/
(4)S.add(newbranch(eventkeyword))
(5)else
(6) ifhotwordsis not null then
/*新建故事树分支并将热词设为分支关键词*/
(7)S.add (newbranch(hotwords))
(8) end if
(9) forseiinsubevent_setdo
/*如果子事件的标题余弦相似度大于0.7*/
(10) if title_consinSsim(sei,seinS)>0.7 then
(11) merge(sei,seinS) /*合并子事件*/
(12) end if
(13) for j=n to j=1 do
(14) ifse.KsecontainsS.branchj.Kbranchthen
(15)S.branchj.E. add(se) /*将子事件添加到分支*/
(16) break;
(17) end if
(18) end for
(19) end for
(20) end if
(21)forbranchkinS
(22) 将分支branchk的子事件最早发生时间设为分支时间
(23) 将分支branchk的子事件按发生时间先后顺序连接起来
(24)end for
(25)将分支按时间先后顺序连接起来
(26)returnSupdated
4 实验及分析
4.1 事件追踪实验及分析
在本节中主要介绍事件追踪实验,本文使用爬虫工具从各新闻网站收集了3个事件的新闻数据,将其标注为正例,此外还收集了事件同时间段的其它新闻,将其标注为反例,以此作为实验的数据集。事件名称以及对应的新闻数量、时间等见表1。实验设置相似度阈值为0.1,衰减指数θ为0.8,时间窗口设置为天。

表1 数据集
实验使用准确率P、召回率R和两者综合性能指标F值这3个指标进行量化考察,F值越高,事件追踪性能越好。设TP为在追踪结果中被判定属于某事件且实际也属于该事件的文本数量,FP为在追踪结果中被判定属于某事件但实际不属于该事件的文本数量,FN为在追踪结果中被判定为其它类别但实际属于该事件的文本数量。
则准确率P、 召回率R和F值的计算公式如下
(15)
(16)
(17)
为了验证本文方法在事件追踪上的效果,选取基于SinglePass的追踪方法以及Qi Y等[9]提出的方法作为对比实验,实验设置两篇种子新闻作为对比方法的初始类心。基于SinglePass的追踪方法选取的文本特征表示方法是TF-IDF。Qi Y等提出的方法引入了反馈更新事件关键词的机制,每次调整关键词权重时增加固定的值0.5。在表2展示了在所有时间窗口的平均追踪结果。图4~图6分别展示了在单个时间窗口上对事件进行追踪的统计结果。

表2 事件追踪方法实验结果
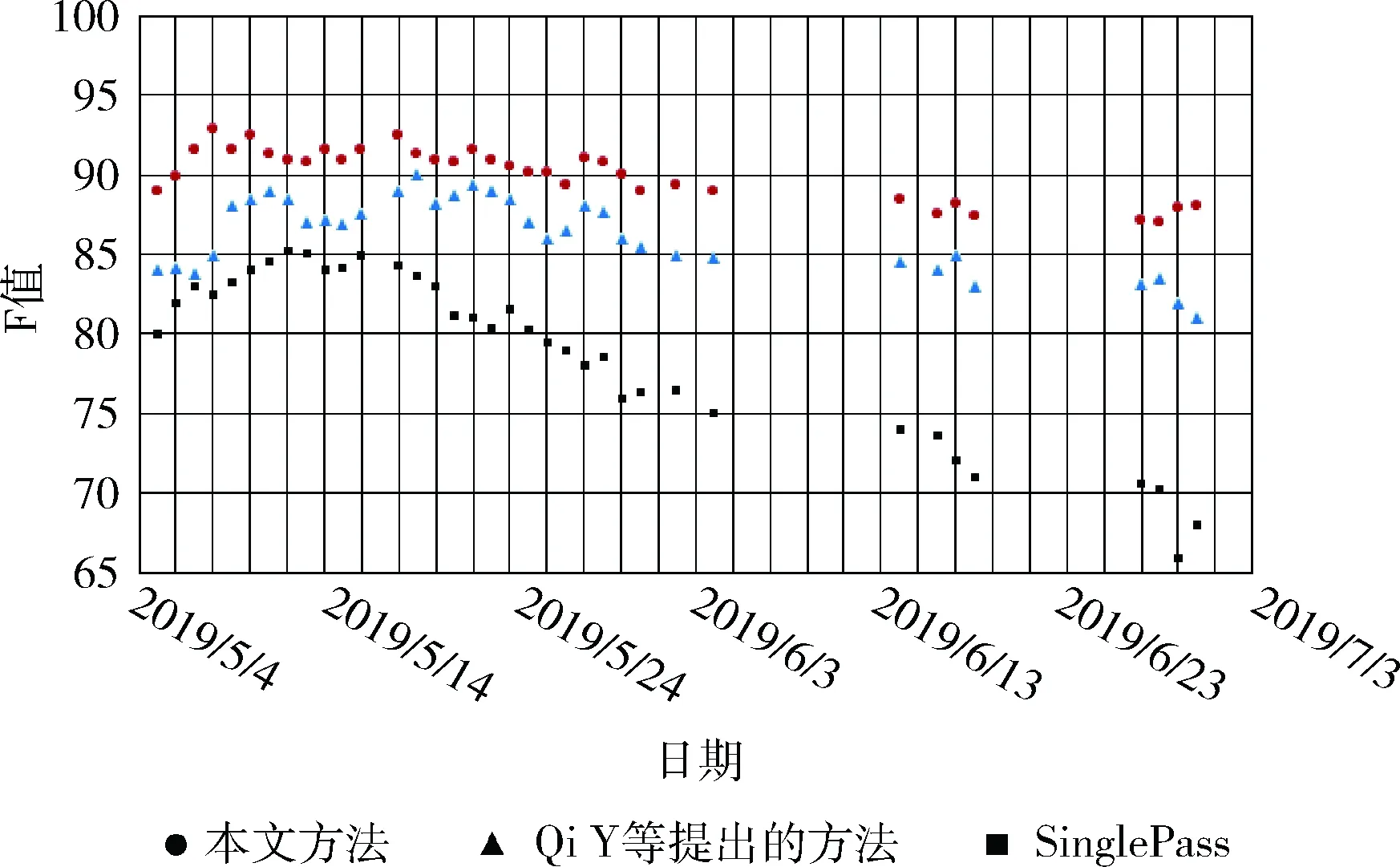
图4 事件1追踪结果统计
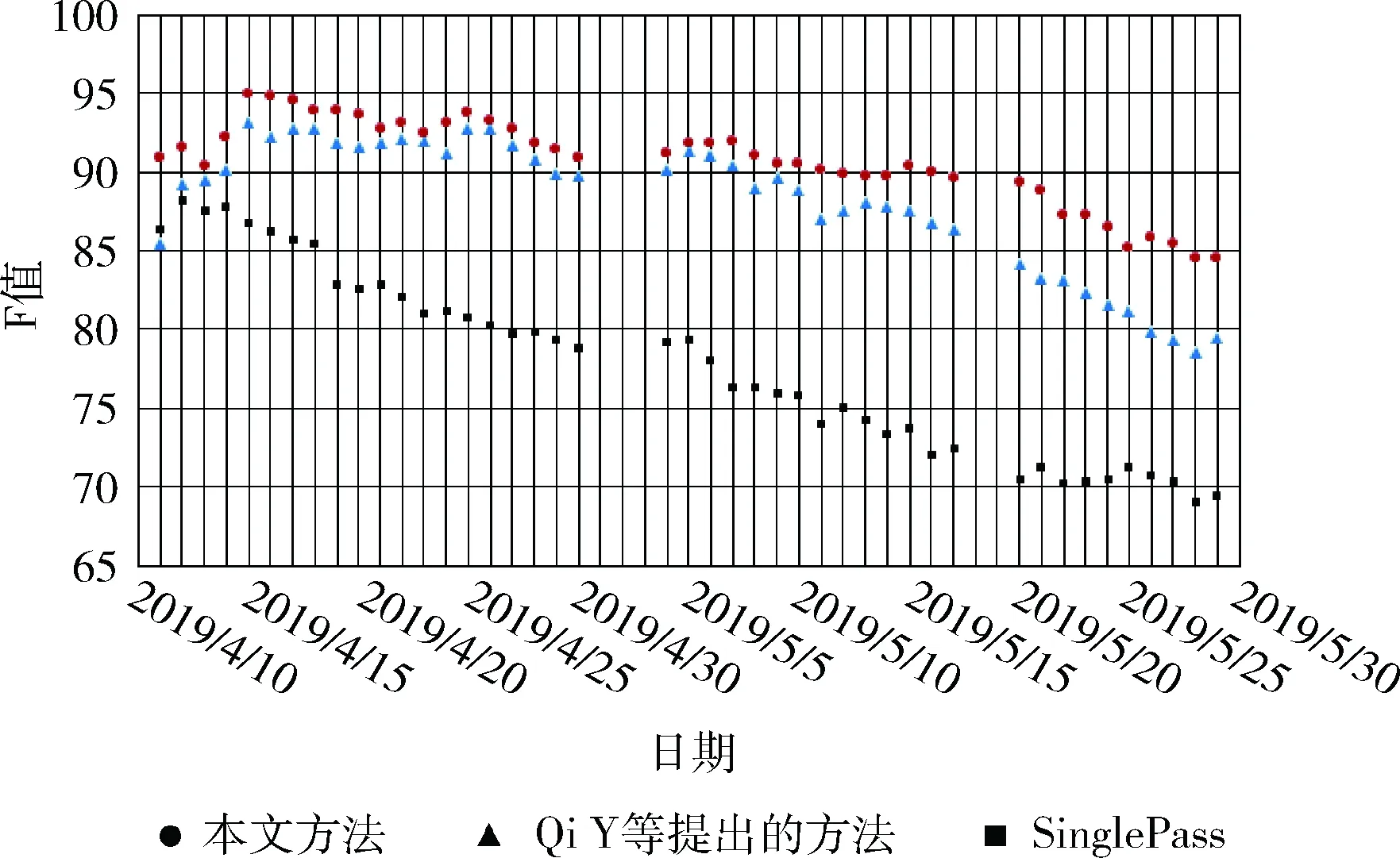
图5 事件2追踪结果统计
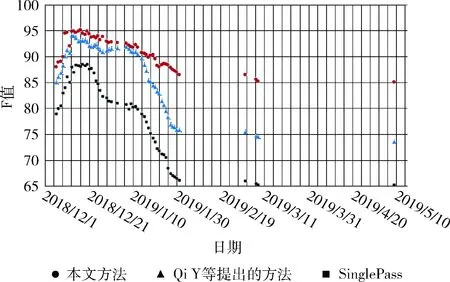
图6 事件3追踪结果统计
从表2的平均追踪结果可以看出,本文方法在事件追踪效果上整体优于基于SinglePass的追踪方法和Qi Y等提出的方法。结合图4~图6,可以看出在事件发展的前期,本文方法优于基于SinglePass的方法,原因是本文在新闻文本特征上选择了有故事偏向性的新闻关键词,加大了事件关键词出现在新闻中时被提取为新闻关键词的概率,而SinglePass方法选取的是常规的TF-IDF文本特征表示方法,当事件关键词在新闻中出现频率较低时,这样的新闻很难被追踪到。
此外,从图4~图6可以看出,随着事件的不断发展,事件追踪效果也会随之下降。下降得最快的是基于SinglePass的方法,其原因是随着时间的推移,SinglePass的类心特征逐渐变得稀疏,新的事件特征所占权重较小,导致后期聚类效果不理想。其次下降得较快是Qi Y等提出的方法,其原因是在反馈更新事件关键词时,对关键词新增权值的调整未考虑到词语的重要性差别,而是统一增加固定的值,导致事件关键词质量不佳,从而影响到后期的追踪结果。虽然本文方法追踪结果有所下降,但整体下降趋势比较缓慢,在事件发展的后期,其追踪结果明显优于另两种方法,F值在86%左右,其原因主要是本文引入了事件关键词候选向量,在反馈更新策略上做了改进,增加了关键词TF-ICF和热度计算而不是只增加固定的值。
通过以上分析可知,本文的事件追踪方法提升了事件追踪效果,在面对事件漂移的问题上取得了不错的结果,能够有效的对事件进行动态追踪。
4.2 事件脉络构建实验及分析
在本节中主要介绍事件脉络构建实验。实验选取事件追踪的3个事件进行脉络构建,选取两个方法StoryTel-ling[16]、StoryForest[3]来进行对比。
(1)StoryTelling:该方法基于事件地点、人物、核心词等相似度生成事件有向无环图,然后从有向无环图中识别弱联通分量,并为每个弱联通分量构造一个最大生成树,最后用最大生成树表示故事树的分支。
(2)StoryForest:该方法计算新事件与已有事件的连接强度,连接强度计算基于内容相似度和时间距离,将新事件连接到连接强度最大的节点,如果小于设定的阈值则连接到故事树根节点。
(3)本文方法:采用有主干和分支的故事树结构来展现事件脉络,并利用新闻热词来定位事件发展的关键节点,生成故事的主干结构。
由于事件脉络具有很强的主观特性,比如可读性、完整性等,因此本文基于用户体验来评价事件脉络构建方法的表现。本文将3个不同方法生成的事件脉络呈现给18位志愿者,并邀请志愿者对事件脉络的可读性和完整性进行评分。其中,可读性是指事件脉络易阅读、易理解、逻辑连贯、展现形式生动;完整性是指事件脉络完整地描述了事件的发展历程。评分标准为:5(优秀)、4(良好)、3(一般)、2(差)、1(很差)。评价结果见表3、表4。
从评分结果可以看出,本文采用有主干和分支的故事树来展现的事件脉络在可读性和完整性上表现良好,在保证事件发展历程被完整展现的同时,也考虑到了用户的习惯,让用户更容易阅读和理解。相比于StoryTelling和StoryForest方法,用户更倾向于选择本文方法生成的事件脉络。
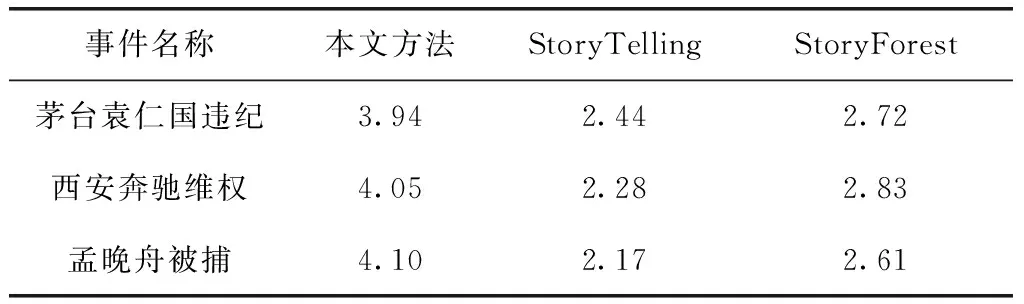
表3 基于用户体验的事件脉络可读性评分
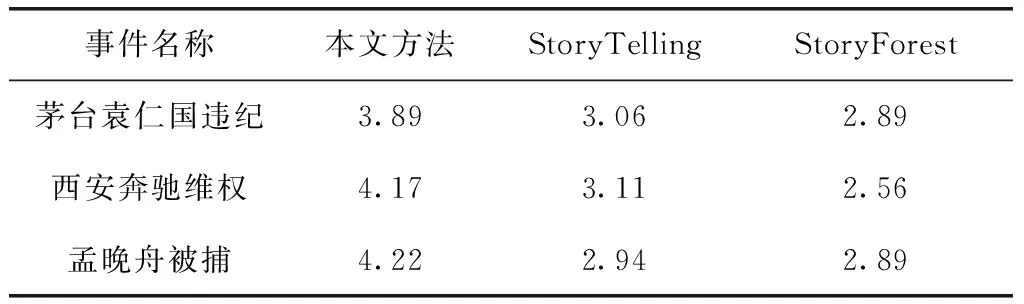
表4 基于用户体验的事件脉络完整性评分
图7和图8展示了本文方法为“茅台袁仁国违纪”和“西安奔驰维权”事件构建的故事树。从图中可以看出,有主干和分支的故事树在结构方面十分清晰。利用热词来定位事件发展的关键节点,生成故事树的主干结构,可以让事件的发展历程一目了然。然而根据相似度来确定子事件之间联系的方法,无法将同一发展阶段讲述不同内容的子事件聚集到一起,比如对于图7中分支A的子事件,它们描述的都是事件初始阶段的信息,但在内容描述上差别较大,基于相似度很难将它们聚集到一起,因此会陷入局部构建,缺乏整体性。虽然本文在故事树的构建中没有分析分支上子事件之间潜在的一些联系,但是本文认为这是不必要的,因为当用户看到以故事树形式展现的事件发展脉络时,可以很容易地人为分析出它们的联系,不需要付出很大的努力。

图7 “茅台袁仁国违纪”事件故事树
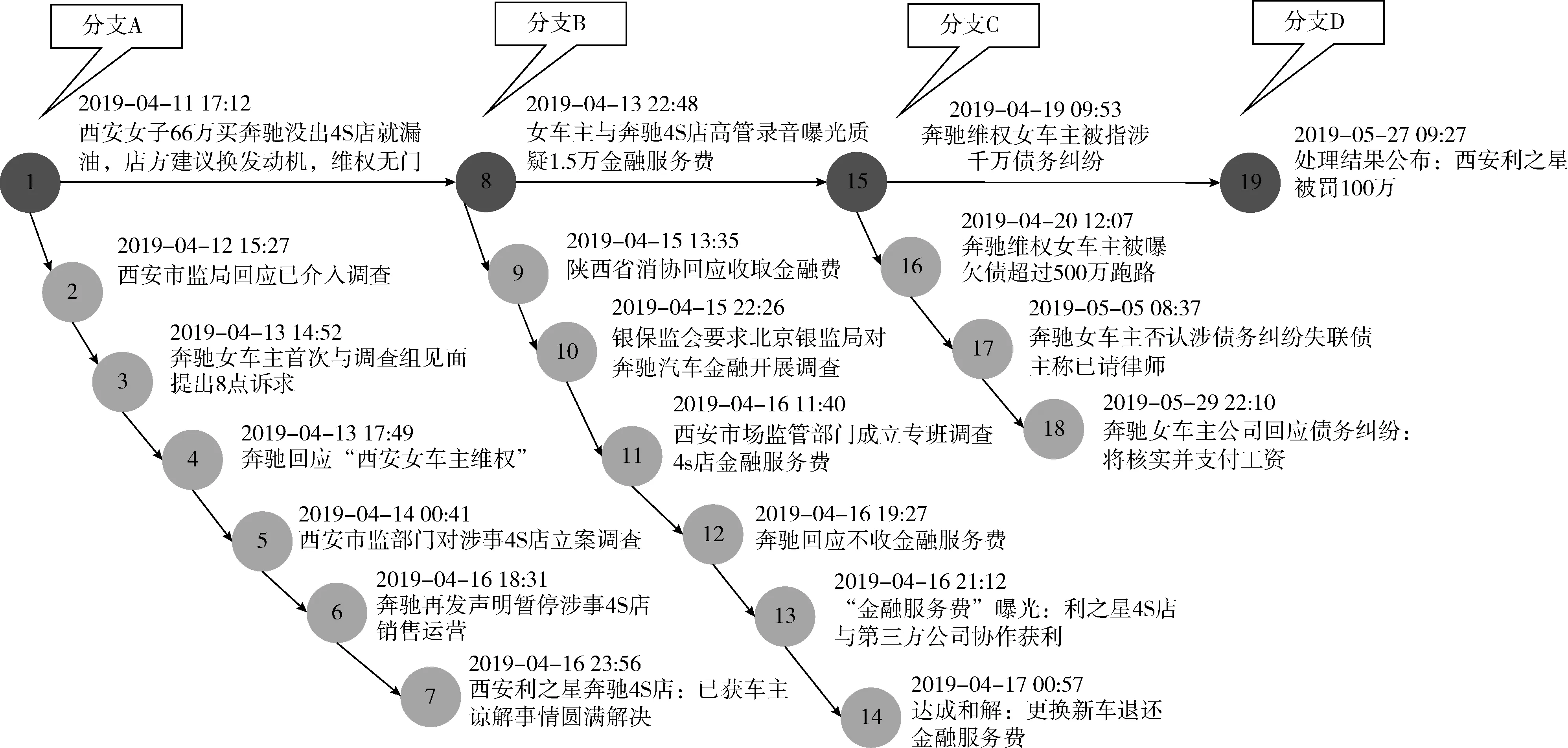
图8 “西安奔驰维权”事件故事树
5 结束语
本文提出了一种面向新闻事件的故事树构建方法,这是一套完整的解决方案,针对用户关注的特定事件,从大量的日常新闻中对事件相关新闻进行动态追踪,以在线的方式将事件相关新闻组织成有主干和分支的故事树,并利用新闻热词来定位事件发展的关键节点,帮助用户轻松地了解事件发展演变整个过程。实验结果表明,本文方法提高了事件追踪的效果,所构建的事件脉络在可读性和完整性上表现良好。此外,热点新闻事件的发生会引发大量的讨论,这些评论信息也会对事件的发展起到一定的推动作用,为了更全面地展示事件信息,下一步拟将评论分析融入至故事树构建中。
