一种面向不确定极大团枚举的高效验证算法
2020-07-04杜明钟鹏周军锋
杜明 钟鹏 周军锋


摘要:极大团作为稠密子图中具有代表性的一种,一直是数据挖掘领域关注的重点。极大团中蕴含的重要数据信息也被广泛应用于各种领域,例如社交网络中的社区发现等。本文研究在不确定图上枚举所有极大团的问题。现有方法基于“子图划分-求解-验证”的思想,可以有效利用极大团性质加速计算过程,但其问题在于验证算法DPMC的效率不稳定。当满足条件的极大团数量增多时,验证的效率会急速下降,严重影响系统的整体性能。本文提出一种高效的验证算法FDPMU,通过构建映射表以及动态构建的倒排表,提高了算法的运行效率。最后,在多个真实数据集上进行比较,实验结果验证了FDPMU算法的高效性。
关键词: 不确定图; 不确定极大团; 验证算法
【Abstract】 As a representative type of dense subgraphs, the maximal clique has always been the focus of attention in the field of data mining. The important data information contained in maximal clique has also been widely used in various fields, such as community discovery in social networks, etc. This paper studies the problem of enumerating all maximal cliques on an uncertain graph. The existing method is based on the idea of "subgraph division-solving-verification", which can effectively use the property of maximal clique to accelerate the computation. Here, the problem is that the efficiency of the verification algorithm DPMC is unstable. When the number of maximal cliques increases, the efficiency of verification will drop rapidly, which seriously affects the overall performance of the system. This paper proposes an efficient verification algorithm, FDPMU, which improves the operation efficiency of the algorithm by constructing a mapping table and a dynamically constructed inverted table. Finally, the comparison is performed on multiple real data sets, and the experimental results verify the efficiency of the FDPMU algorithm.
【Key words】 uncertain graph; uncertain maximal clique; verification algorithm
0 引 言
因為现实生活中信息的繁杂多样,所以获得的数据往往有着不确定性,这些带有不确定性的数据通常用不确定图来存储表示,例如带概率信息的社交网络[1]、DNA网络[2]、通信网络[3]等等。从不确定图中挖掘稠密子图,能够有助于更好地了解信息并解决实际生活中的问题[1,4-6],例如对于社交网络,可以通过发现稠密子图了解到人们之间的好友信息进行好友推荐[8]。
极大团是一种典型的稠密子图。对于图中的任意顶点子集,如果其中任意两个顶点之间都有边相连,那么这个顶点子集就是一个团。如果不存在其它团包含该团,那么这个团就是一个极大团。给定不确定图及概率阈值α,如果一个团的团概率大于等于α,这个团就是一个α-团。进一步,如果不存在一个更大的α-团包含这个团,则该团就是一个α-极大团。过去一段时间,α-极大团枚举问题得到了研究者的关注和深入研究[8-12],然而,现有方法的效率仍然较低。
为了枚举α-极大团,一种基本思路是通过选取不确定图中的任意顶点,然后以不断向外扩张的方式枚举所有的极大团[8-14]。其中典型的算法就是MULE算法[12],MULE算法按照每个顶点的编号顺序,递增地不断扩张,每一次扩张都选满足要求的顶点向里添加。以此来枚举出所有的α-极大团,在递增过程中需要检测是否为α-极大团,也就是极大性检测。该算法的时间复杂度是O(n·2n),效率较低。
针对MULE算法存在的问题, 文献[15]提出了一种基于子图划分的极大团枚举算法EUMC+。EUMC+算法将枚举出所有α-极大团的过程分解为“子图划分-求解-验证”三个阶段来高效地完成枚举过程。在子图划分阶段,将不确定图G作为确定图处理,将其划分成极大团子图。在求解阶段,对所有的极大团子图,调用MULE算法进行处理,得到所有的α-团。最后,使用验证算法去除伪极大团,正确枚举出所有的α-极大团。EUMC+中使用的验证算法DPMC[15],通过动态建立倒排表来完成去除伪极大团的工作。该算法在验证过程中,需要对每个α-团中顶点的倒排表做交集,在α-团数量非常多时,验证的效率会急速下降,严重影响系统的整体性能,不适宜处理稠密的不确定图。
针对以上问题,本文提出一种高效的验证算法FDPMU,可以高效去除伪极大团,从而提升α-极大团的枚举效率。本文后续内容安排如下:首先介绍问题定义及相关工作,然后提出新的高效验证算法FDPMU,并详细描述算法的实现过程,接下来在7个真实数据集上运行算法并进行实验对比,最后总结全文。
1 相关工作
1.1 问题定义
1.2 相关算法
1.2.1 MULE算法
MULE(Maximal Uncertain cLique Enumeration)算法基于深度优先遍历(DFS),采取顶点编号升序来处理不确定图中的顶点,并且通过维持集合I和集合X对搜索空间进行优化,以此高效地枚舉不确定图中所有的α-极大团。
MULE算法中用集合C来表示当前找到的α-团,当要去扩充α-团C时,只加入C的公共邻居顶点中编号大于max(C)的顶点。但是每次C中添加进新的顶点后,C的团概率会降低,可能导致clq(C,G)<α,此时的集合C就不再是一个α-团。算法通过维持集合I来保证添加的顶点符合相邻以及概率的要求,集合I中存放的是数据对(u,r),u表示顶点编号,且u>max(C),r表示将顶点u添加进入α-团C后,C的团概率需要乘上的值。在不断的递归过程中,每次添加新的顶点进入C后,都需要更新集合I,保证集合I中的顶点符合要求。
MULE算法会维持另一个集合X,确保团的极大性。X集合中存放的也是数据对(u,r),含义和I集合中相同,只是X集合中存放的结点是已经在递归过程中处理过的顶点。当I集合为空时,只能说明此次递归过程结束,但是并不能证明C是一个α-极大团,可能X集合中依然有顶点能扩充C,只有当I集合和X集合都为空时,C才是一个符合条件的α-极大团。
MULE算法降低了进行极大性检测的时间,但是MULE算法在处理大规模图时,因为待检测集合的增多,算法性能会急速下降。
1.2.2 EUMC+算法
EUMC+算法基于“子图划分-求解-验证”的思想枚举不确定图中所有的α-极大团。在子图划分阶段将不确定图当作确定图处理,调用Degeneracy算法[16]将不确定图划分为极大团子图。EUMC+算法可以在子图划分阶段将不可能成为极大团的顶点子集排除,同时确保不会造成α-极大团的缺失。在求解阶段对所有的极大团子图调用MULE算法,枚举所有的α-团。由于不同的极大团子图中有公共部分,所以在MULE算法枚举出的α-团中,会存在某些团被其他α-团包含的情况,这些被包含的团就是伪极大团。最后在验证过程中调用验证算法DPMC去除伪极大团。
在验证过程中,可以通过让所有的α-团两两比较来去除伪极大团,但这样会导致算法效率低下。对于2个α-团,只有结点个数较少的那个团才可能被包含,所以在将所有α-团按照各团的结点个数降序排序后,只需要计算当前α-团是否被序列前面的团包含,就可以判断该团是否为伪极大团。虽然在将α-团排序后,加速了验证的过程,但DPMC算法依然存在许多的冗余计算,从而导致整个枚举极大团过程效率低下。
2 高效的验证算法FDPMU
2.1 FDPMU算法的思想
在介绍本文方法之前,首先分析一下EUMC+的验证算法DPMC中存在的冗余计算问题。以图1为例,给定概率阈值0.1,在经过“子图划分-求解”过程后得到所有α-团,再按各团的结点个数降序排序后得到A={{1,2,3}、{5,6,7}、{1,3}、{1,4},{3,4}、{3,5}、{7,8}}。DPMC算法通过动态构建倒排表来去除伪极大团,其中倒排表是(Key,Value)集合,Key表示顶点编号,Value是A集合中包含Key的α-团的下标。在验证过程中,首先根据A中的第一个α-团{1,2,3}建立倒排表,倒排表见表1,其中第一列表示顶点编号,第二列是根据{1,2,3}建立的初始倒排表,其中存放的是{1,2,3}在A集合中的下标0,第三列,第四列为后续验证过程中更新的倒排表。
遍历到{5、6、7}时,对倒排表中结点5、6、7对应的Value值求交集,交集为空集,说明{5、6、7}不被其他团所包含,即{5、6、7}是一个满足条件的α-极大团。更新倒排表,如表1中第三列“二次”所示。在后续的验证过程中,每遍历到一个α-团,即对团中顶点的Value值求交集,以此判断是否为伪极大团。在验证过程中,不断更新倒排表,直到验证结束,最终倒排表见表1中第四列。
DPMC算法将遍历过程中获取的信息保存在倒排表中,提高了验证的效率,然而该算法依然存在着不足之处。对图1,在子图划分阶段获得了{5,6,7},{7,8}等极大团子图,对子图调用MULE算法获得{5,6,7},{7,8}等α-团,这些α-团和极大团子图完全一致,不可能被其他α-团包含,所以这些团一定是符合条件的α-极大团,进行验证处理带来了冗余的计算。当这些团的数量增多时,验证的效率会急速下降,严重影响系统的整体性能,DPMC算法还有待进一步优化。
定理1 给定不确定图G,对于图中的所有α-团,如果某个α-团中存在着不属于其他团的顶点,则此α-团是一个满足要求的α-极大团。
证明 不确定图中的任意顶点一定会属于某个α-极大团,因为无论怎么设定概率阈值,枚举的α-极大团只能是图中的顶点子集,这些子集里一定包含了所有的结点。所以,如果一个极大团中存在着不属于其他团的顶点,则该团一定是一个符合条件的α-极大团。
基于定理1,本文提出一种高效的验证算法FDPMU(Fast Delete Pseudo Maximal cliqUes)。其基本思想可以表述为:对于待处理的α-团,如果其中存在着不属于其他团的顶点,则该团是一个满足要求的α-极大团,不再进行验证。
2.2 FDPMU算法
FDPMU算法中,使用映射表R来记录顶点的出现次数,映射表是(Key,Value)集合,其中Key表示顶点编号,Value表示包含Key的α-团个数,Value初始值为0。在“子图划分-求解-验证”的求解过程中,每枚举一个α-团,就将α-团中顶点对应的Value值加一,求解过程结束时映射表的建立也同时完成。此后,FDPMU算法根据映射表以及动态构建的倒排表完成验证过程。FDPMU算法流程具体如下。
根据上述可知,FDPMU算法利用映射表和倒排表来完成验证的过程,而且可知结果集A中的第一个α-团{1,2,3}必定是一个满足条件的α-极大团,所以首先根据{1,2,3}建立倒排表,倒排表见表1,表1中各数据含义和2.1节中相同。
初始倒排表建立完成后,按照A集合中的顺序处理极大团,接下来处理α-团{5,6,7}。首先根据映射表判断{5、6、7}中是否有不属于其他团的顶点,取得该团中顶点对应的Value值,判断是有顶点的Value值为1,顶点5、6、7对应的Value值分别是2、1、2,其中编号为6的顶点的Value值为1,说明该顶点只属于{5,6,7}这个α-团,即该团是一个符合条件的α-极大团,不再进行其他验证,直接更新倒排表即可,表1中第三列“二次”即是再次更新后的倒排表。
在后续的验证过程中,每遍历到下一个α-团,先查找映射表,判断该团中是否存在Value值为1的顶点,若存在则该α-团是一个满足要求的α-极大团,若不存在则再对顶点对应的Value值求交集,来判断该团是否为伪极大团。在此过程中,不断更新倒排表,一直到验证结束,最终倒排表如表1中第四列所示。
FDPMU算法通过映射表可以快速查找出满足条件的α-极大团,减少了冗余的计算,提升了算法的性能。例如对于结果集A={ {1,2,3}、{5,6,7}、{1,3}、{1,4},{3,4}、{3,5}、{7,8} },DPMC算法会对A中每一个极大团都进行复杂的验证过程。但在FDPMU算法中,只通过映射表即可判断出{5,6,7},{7,8}是满足条件的α-极大团,不再需要额外验证。
2.3 算法分析
在顶点规模为n的图中,最多包含3n/3个极大团子图,对这些子图调用MULE算法后最少可以获得3n/3个α-团,所以仅仅使用倒排表的DPMC验证算法时间复杂度为O(n·3n/3)。FDPMU算法的最坏时间复杂度为O(n·3n/3),在最好的情况下FDPMU算法的时间复杂度仅为O(3n/3),在一般情况下,FDPMU算法的性能也高于DPMC算法。
3 实验分析
3.1 实验环境
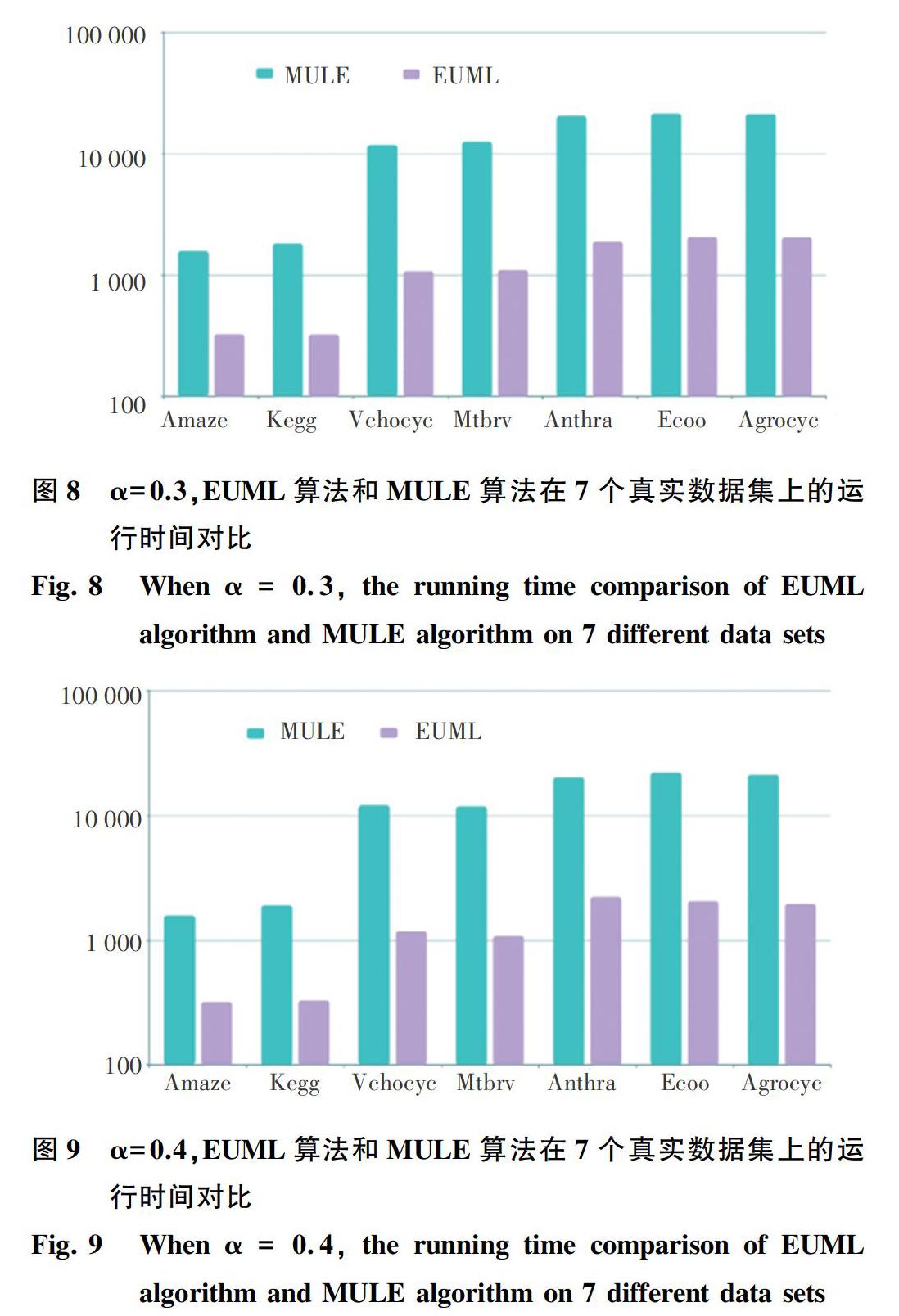
实验所使用的硬件平台是Inter Core i5主频为2.60 GHz的CPU,8 GB的RAM内存,操作系统为Windows10 64位的系統;实验的运行环境为 Microsoft Visual Studio 2013;首先比较FDPMU算法和DPMC算法在验证过程中的性能。将EUMC+算法中的DPMC算法替换为FDPMU算法后成为新的算法EUML,最后比较MULE算法和EUML算法枚举所有α-极大团的性能。以上算法均采用C++语言实现。
3.2 数据集
本文所使用的数据由7个数据集组成, 其中Amaze(www.amaze.ulb.ac.be)和Kegg(www.genome.ad.jp/kegg)数据集表示的是人的代谢网络;vchocyc、mtbrv、Anthra、ecoo、agrocyc这些数据集来自EcoCye(ecocyc.org),描述的是生物中基因组之间的结构。这些数据源自生活中的不同领域,其中都蕴含着不确定信息,适合用不确定图存储表示。这些数据集的相关信息见表3,其中符号|V|和符号|E|分别表示不确定图中的顶点数量和边的数量。
3.3 性能比较分析
3.3.1 验证算法性能比较
在现有的不确定图上,对于需要比较的验证算法FDPMU和DPMC,给定同一α值,得到枚举所有α-极大团的时间代价,最后通过时间的对比,验证了FDPMU算法的高效。
由实验结果可知,FDPMU算法不仅可以正确去除伪极大团,而且在时间效率上比DPMC算法快了4倍左右。FDPMU利用了伪极大团的性质,避免了冗余的验证计算,而且在FDPMU算法中寻找伪极大团以及删除伪极大团同时进行,提高了算法的效率。下面给定不同的概率阈值α,在多个数据集上进行比较,并对实验结果进行分析。
给定概率阈值α为0.1,DPMC算法和FDPMU算法在7个不同数据集上的运行时间如图2所示。图2中,横坐标表示7个不同的数据集,纵坐标表示运行时间,单位是ms。
从图2可知,FDPMU算法在性能上相较于DPMC算法有了较大的提高。尤其是,在Ecoo数据集和Agrocyc数据集中,FDPMU算法比DPMC快了将近12倍左右。在Amaze数据集和Kegg数据集上,虽然FDPMU算法的提升并不显著,但也比DPMC快2倍左右。在其他数据集中,FDPMU算法也有着较大的提升,图2可以很好地说明FDPMU算法的高效性。
给定概率阈值α为0.2,分别在7个不同数据集上运行DPMC算法和FDPMU算法,运行时间对比如图3所示。
从图3可知,在α为0.2时,FDPMU算法依然有着较大的提升,例如在Anthra数据集和Ecoo数据集上,[JP2]FDPMU算法相较于DPMC算法快了将近10倍。在有些数据集上也依然有着3倍的提升,这些数据都验证了FDPMU算法的高效性。可以看出在不同α值下FDPMU算法较DPMC算法都更高效。
[8]ROKHLENKO O, WEXLER Y, YAKHINI Z. Similarities and differences of gene expression in yeast stress conditions[J]. Bioinformatics, 2007, 23(2): 184.
[9]HARLEY E, BONNER A. Uniform integration of genome mapping data using intersection graphs[J]. Bioinformatics, 2001, 17(6): 487.
[10]JIN Ruoming, LIU Lin, AGGARWAL C C. Discovering highly reliable subgraphs in uncertain graphs[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, California:ACM, 2011: 992.
[11]KOCH I. Enumerating all connected maximal common subgraphs in two graphs[J]. Theoretical Computer Science, 2011, 250(1-2): 1.
[12]ARKO P M, PAN Xu, SRIKANTA T. Minig maximal cliques from an uncertain graph[C]//2015 IEEE 31st International Conference. Seoul, South Korea:IEEE, 2015: 243.
[13]ZOU Zhaonian, LI Jianzhong, GAO Hong, et al. Mining frequent subgraph patterns from uncertain graphs[J]. Journal of Software, 2009, 20(11): 2965.
[14]KHAN A, BONCHI F, GIONIS A, et al. Fast reliability search in uncertain graphs[C]//Proceedings of the 17th International Conference on Extending Database Technology. Athens, Greece: dblp, 2014: 535.
[15]朱成名. 不确定图上極大团枚举算法研究[D]. 秦皇岛:燕山大学,2017.
[16]TOMITA E, TANAKA A, TAKAHASHI H. The worst-case time complexity for generating all maximal cliques and computational experiments[J]. Theoretical Computer Science, 2006, 361(1): 28.
