基于Attention-CLSTM模型的商品评论分类
2020-05-25张鹏张再跃
张鹏 张再跃

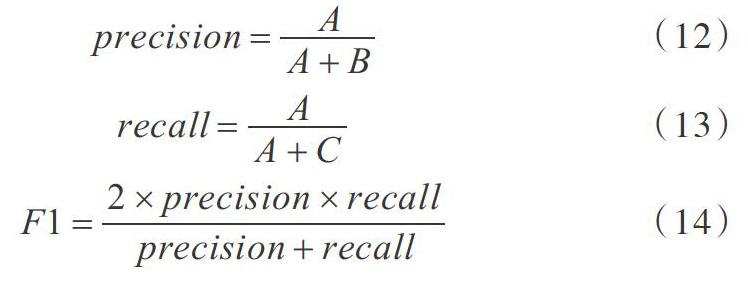
摘 要:文本分类是自然语言处理中的一项重要基础任务,指对文本集按照一定的分类体系或标准进行自动分类标记。目前网络文化监督力度不够、不当言论不受限制,导致垃圾评论影响用户体验。因此提出一种基于注意力机制的CLSTM混合神经网络模型,该模型可以快速有效地区分正常评论与垃圾评论。将传统机器学习SVM模型和深度学习LSTM模型进行对比实验,结果发现,混合模型可在时间复杂度上选择最短时间,同时引入相当少的噪声,最大化地提取上下文信息,大幅提高评论短文本分类效率。对比单模型分类结果,基于注意力机制的CLSTM混合神经网络模型在准确率和召回率上均有提高。
关键词:文本分类;深度学习;注意力机制;CLSTM
DOI:10. 11907/rjdk. 191506 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)002-0084-04
英标:Classification of Commodity Reviews Based on Attention-CLSTM Model
英作:ZHANG Peng,ZHANG Zai-yue
英单:(School of Computer Science and Engineering, Jiangsu University of Science and Technology, Zhenjiang 212003, China)
Abstract: Text classification is an important basic task in natural language processing, which automatically classifies text sets according to certain classification systems or standards. Problems prevail because of current lack of supervision of the network culture and restriction of improper comments, which leads to the problem of spam comments affecting the user experience. In this paper, a CLSTM hybrid neural network model based on attention mechanism is used to classify commodity reviews, which can quickly and effectively distinguish normal comments from spam comments. At the same time, compared with the traditional machine learning SVM model and the deep learning LSTM model, it is found that the hybrid model can select the shortest time in time complexity, introduce relatively little noise, and maximize the extraction of context information in the comments. The effect of short text classification has been significantly improved. Compared with the single model classification results, the CLSTM used in this paper has improved both accuracy and recall rate.
Key Words: text classification; deep learning;attention mechanism; CLSTM
0 引言
隨着电商网站的兴起,网上购物用户数量急剧增长,购物网站及各种购物APP也针对用户开放评论功能。这些评论一方面有助于为用户提供更好的购物体验,另一方面也有助于商家更好地搜集信息,但是由于网络开放性及用户言论自由,有些用户给出垃圾评论,对其他用户构成误导,不仅不利于系统维护与完善,也造成了极大的信息资源浪费。通过对商品进行评论短文本分类,可有效区分垃圾评论与正常评论,从而净化网络、为消费者提供可靠信息依据。
目前垃圾评论识别研究成为研究热点。垃圾评论的形式不断变化,每个时间段呈现的主要形式各不相同。该类评论内容没有明显规律,而且评论中主题相关信息也较少,特征较为稀疏。
本文将垃圾评论分为3类:①和主题不相关,主要表现为评论者出于情绪发泄而随手发布的无意义文本,其中可能包含谩骂、色情、人身攻击等信息内容,与产品毫不相干,该类评论用户体验极差,甚至使用户产生厌恶情绪;②客观性商品咨询文本,仅将商品介绍的一些参数和性能指标复制粘贴到评论中,不涉及对产品的评价内容,用户不能从中获取任何有用价值;③通过图片、链接等形式推销产品及发布一些黄色或病毒网页链接。垃圾评论特点包括:评论太短或过长、主观意向较重、口语化用词较多,受当时热点话题影响,含有超链接、图片评论、特殊字体。
20世纪90年代以来,基于机器学习的分类算法模型[1]被应用到文本分类中,如支持向量机SVM[2-3]、决策树[4]、朴素贝叶斯[5]等,赋予了文本分类较高的实用价值。在实现文本分类的算法中,传统机器学习在进行文本分类时需要进行特征工程[6]。如甘立国[7]指出随着机器学习的发展,机器学习方法将逐渐取代传统知识工程构建方法,但也会存在一些问题,例如在文本表示方法上存在维度灾难,不能有效提取文本深层次的语义关系。近年来,深度学习神经网络[8-9]在特征自动获取中发挥着越来越重要的作用,给研究者们带来了很大便捷。如Kim等[10]将卷积神经网络应用在文本分类任务上,将向量化后的文本使用卷积神经网络进行提取特征信息,最后使用Softmax分类器对提取的特征进行分类。它能够最大程度池化所获特征,但由于卷积器大小固定,所以对参数空间调节和信息存储大小有很大限制。同时,也有学者[11]通过LSTM模型进行文本分类,LSTM模型可在更复杂的任务上表征或模拟人类行为和认知能力,但在训练时长及对抗梯度爆炸等方面需进一步改善。CNN[12-13]在文本中的不同位置使用相同的卷积核进行卷积,可以很好地提取n-gram 特征,通过池化学习文本短期和长期关系。LSTM可以用来处理任意长度的序列,并发现其长期依赖性。总的来说,CNN从时间或空间数据中学习局部响应,但缺少学习序列相关性能力,而LSTM 用于序列建模,但不能并行地进行特征提取。本文结合CNN与LSTM 两种模型的优点,充分利用CNN识别局部特征与LSTM利用文本序列的能力,最大化提取上下文信息以实现对评论文本的有效分类,提出一种基于注意力机制的深度学习CLSTM混合模型算法。
1 文本分类相关工作
1.1 深度学习
传统机器学习在进行文本分类时会出现文本表示高纬度、高稀疏的问题,同时,特征表达能力很弱,需要人工进行特征工程,成本很高。而深度学习之所以在图像与语音处理方面取得巨大成功,一个很重要的原因是图像和语音原始数据是连续、稠密的,有局部相关性。应用深度学习解决大规模文本分类问题的关键是解决文本表示,再利用深度神经网络结构自动获取特征表达能力,去掉繁杂的人工特征工程,端到端地解决问题。
1.2 文本分类
本文对商品评论短文本通过语义进行分类,处理流程包括:文本预处理、词向量训练、训练模型以及分类效果评估4部分。首先,对收集的评论短文本进行预处理工作;再通过Word2Vec模型[14-15]对评论短文本进行词向量训练;然后,采用混合深度神经网络模型CLSTM进行特征提取学习,通过引入Attention注意力机制[16]获取文本特征表示;最后通过Softmax分类器对评论短文本进行最终分类。其流程如图1所示。
1.3 文本预处理
文本预处理过程指在文本中提取关键词表示文本的过程。不是所有商品文本数据均对研究有实际作用,且部分数据往往带有大量噪声,对于这些无关数据,例如不规范的字符、符号等,应进行有效过滤以排除对文本数据信息挖掘的干扰,所以在文本分类前首先需预处理数据集。
中文不像英文那样具有天然的分隔符,所以一般情况下,中文分词[17-18]的第一步是对语料进行分词处理。近年来随着机器学习研究的深入,可以选择的分词算法工具也越来越多,常见分词工具有Stanford NLP、ICTClAS分词系统、jieba、FudanNLP等。本文选择Python编写的jieba开源库对文本进行分词,以行为单位,将文本保存到输出文件。中文停用词对文本研究没有太大价值,故需将文本中介词、代词、虚词等停用词以及特殊符号去除。
1.4 词向量训练
本文采用Word2Vec技术生成词向量,可以实现将语义信息相近的词语映射到相近的低维度向量空间中。为了减少后期计算复杂度,通常词向量维度设置在100~300维度之间。
本文采用Skip-Gram模型[19-20]进行词向量训练,Skip-Gram通过给定输入单词预测上下文。该模型包含输入层、投影层和输出层3个层面,如图2所示。
将Skip-Gram模型得到的词向量存储在一个词嵌入矩阵M中,现假设一条评论T里面包含[n]个单词,每个单词在M中有唯一的索引[k],则一句话中第[i]个单词可表示为[ti=Mbk],其中[bk]为二值向量。则一条评论可用矩阵向量T表示,公式如下:
最后,在语料中用特殊标记“[]”对每一句话的结尾进行标记。
2 基于注意力机制的CLSTM混合模型与文本分类
为了提高商品评论中垃圾评论文本分类的精确率,结合CNN和LSTM两种结构优点,本文提出一种基于注意力机制的CLSTM混合神经网络模型,再通过引入Attention机制计算注意力概率分布,获得文本特征表示,从而提高模型文本分类精确率。模型结构如图3所示。
该混合模型由4个部分组成:首先CNN提取短语特征序列,主要使用一维卷积提取词向量特征,按顺序移动计算前后单词对当前状态下单词的影响,生成短语特征表示;其次提取评论中的文本特征,该部分使用LSTM处理短文本特征序列,逐步合成文本向量特征表示;然后采用Attention机制计算各个输入分配的注意力概率分布,生成含有注意力概率分布的文本语义特征表示;最后引入分类器,主要由dropout技术防止过拟合,用Softmax分类器预测文本类别。
在CNN提取短文本特征时,本文采用一维卷积核在文本不同位置滑动以提取词语上下文信息,生成短语的特征表示。通常,通过卷积操作提取短语特征后,会进一步执行池化操作,但是,文本分类是利用现有信息进行预测,强调特征序列连续性,而池化操作会破坏特征序列连续性。因此,本文在CNN卷积层之后直接采用LSTM模型。
CNN从时间或空间数据中学习局部响应,但缺少学习序列相关性能力,没有考虑词语间的相互关联。在文本分类过程中LSTM模型可用来处理任意长度的序列,并且具有长期依赖性。假设在某一时刻,LSTM某一重复模块的输入包括上一时刻历史隐藏状态[ht-1]和当前输入[xt],其输出包含3个门(forget gate、input gate、output gate),可控制信息并将信息传递给下一時刻。LSTM变换函数定义如下:
其中,将Input Gate、Output Gate、Forget Gate表示为:[it][ot][ft],当前时刻的记忆单元为[ct],[W∈RH?E],[ht]为LSTM单元最终输出,使用Sigmoid函数作为激活函数,[b∈R]为LSTM权重矩阵与偏置量。
由LSTM得到对应隐藏层的输出[h0],[h1],[h2],…,[ht]。通过在隐藏层引入注意力机制,生成含有注意力概率分布的文本语义特征,计算各个输入分配的注意力概率分布[α0],[α1],[α2],…,[αt],引入注意力机制可极大提高模型分类准确性。[us]是一种语义表示,是一个随机初始化的上下文向量。引入注意力机制后,文本特征表示计算过程为:
其中[ht]是由LSTM学习得到的[t]时刻的特征表示;[ut]为[ht]通过一个简单神经网络层得到的隐层表示;[t]为[ut]通过[Softmax]函数归一化得到的重要性权重;[v]是最终文本信息的特征向量。
为防止模型在训练时出现过拟合现象,本文引入dropout技术。最后,本文采用Softmax分类器对获得的文本特征进行分类处理。
[y]是函数计算后得到的预算类别。
3 实验结果与分析
3.1 数据集
本文使用的数据集来源于从京东商城上爬取的评论语料库,包含电脑评论、手机评论、图书评论、鲜花评论等6个种类的消费者评论,共计27万余条。在数据集中,每条评论独占一行,每条评论后面给出类别标注。本文选取3个种类的评论数据集进行训练,分别是手机评论、图书评论、鲜花评论,每种类型的评论数量如表1所示,其它3类可用于后备工作。在实验中,每种类型使用80%的评论数据进行训练,使用20%的数据集作为测试集。
本文所有实验均基于Tensorflow[21]平台库实现。实验使用的GPU为NVIDIA GTX1080处理器。
3.2 评价指标
本文讨论的分类类别是二分类问题,因此将样本标签记为正、负两种样本,根据实验结果建立二分类结果混合矩阵,如表2所示。
本文通过采用准确率P([precision])、R召回率([recall])、F1值3个标准作为模型性能评价指标,根据表2得到计算公式为:
3.3 实验结果
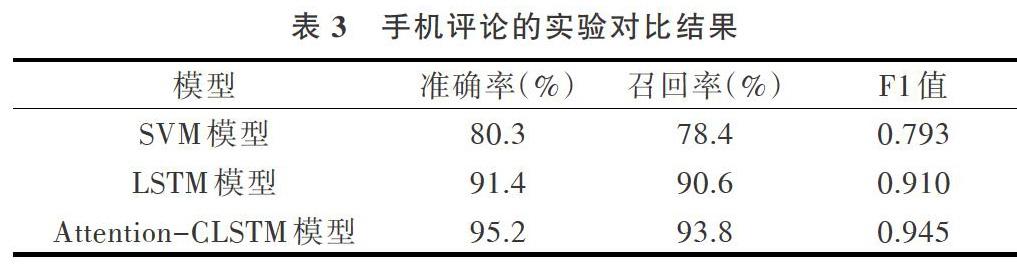
为了证明本文混合神经网络模型算法的优越性,同时进行两组实验对比。第1个实验采用常见的机器学习SVM模型算法进行文本分类,第2个实验采用深度学习LSTM模型算法进行文本分类。将数据集的20%作为测试集放入已经训练好的模型中,通过给定的3个标准性能评价指标,比较测试结果并计算分类结果。不同模型生成的结果对比如表3-表5所示。
从表格中可以看出,3种分类算法在进行评论文本分类时均可达到较好的效果。其中深度学习神经网络算法分类效果优于机器学习SVM分类算法;在经过一系列调参后,针对3种商品种类的评论实验,可以发现基于注意力机制的CLSTM混合神经网络模型方法在准确率、召回率和F1值3个方面均比单模型深度学习方法的分类识别效果更好。
4 结语
本文采用的混合模型算法充分利用了?CNN识别局部特征与 LSTM利用文本序列的能力,可在时间复杂度上选择最短时间,同时引入相当少的噪声,最大化地提取上下文信息,大幅提升评论短文本分类效率。深度神经网络可以处理多分类问题,但会增加训练难度。本文可以为后续文本特征多分类研究提供参考。
参考文献:
[1] 王静. 基于机器学习的文本分类算法研究与应用[D]. 成都:电子科技大学, 2015.
[2] JOACHIMS T. Text categorization with support vector machines: learning with many relevant features[C]. Proceedings of Conference on Machine Learning, 1998:137-142.
[3] 孫晋文, 肖建国. 基于SVM的中文文本分类反馈学习技术的研究[J]. 控制与决策, 2004, 19(8):927-930.
[4] 田苗苗. 基于决策树的文本分类研究[J]. 吉林师范大学学报, 2008, 29(1):54-56.
[5] 邸鹏, 段利国. 一种新型朴素贝叶斯文本分类算法[J]. 数据采集与处理, 2014, 29(1):71-75.
[6] 姜百宁. 机器学习中的特征选择算法研究[D]. 青岛:中国海洋大学, 2009.
[7] 胡侯立, 魏维, 胡蒙娜. 深度学习算法的原理及应用[J]. 信息技术, 2015(2):175-177.
[8] 郭元祥. 深度学习:本质与理念[J]. 新教师, 2017(7):11-14.
[9] 甘立国. 中文文本分类系统的研究与实现[D]. 北京:北京化工大学, 2006.
[10] KIM Y. Convolutional neural networks for sentence classification[DB/OL]. https://arxiv.org/pdf/1408.5882.pdf.
[11] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8):1735-1780.
[12] GOODFELLOW I, BENGIO Y, COURVILLE A, et al. Deep learning[M]. Cambridge:MIT press,2016.
[13] 陈先昌. 基于卷积神经网络的深度学习算法与应用研究[D]. 杭州:浙江工商大学, 2014.
[14] 周练. Word2vec的工作原理及应用探究[J]. 图书情报导刊, 2015(2):145-148.
[15] 熊富林, 邓怡豪, 唐晓晟. Word2vec的核心架构及其应用[J]. 南京师范大学学报:工程技术版, 2015(1):43-48.
[16] 赵勤鲁, 蔡晓东, 李波,等. 基于LSTM-Attention神经网络的文本特征提取方法[J]. 现代电子技术, 2018, 41(8):167-170.
[17] 王威. 基于统计学习的中文分词方法的研究[D].沈阳:东北大学,2015.
[18] 韩冬煦,常宝宝. 中文分词模型的领域适应性方法[J].计算机学报,2015,38(2):272-281.
[19] 黄聪. 基于词向量的标签语义推荐算法研究[D]. 广州:广东工业大学, 2015.
[20] 李晓军. 基于语义相似度的中文文本分类研究[D]. 西安:西安电子科技大学, 2017.
[21] HELCL J, LIBOVICKYA A J. Neural monkey: an open-source tool for sequence learning[J]. Prague Bulletin of Mathematical Linguistics,2017, 107(1):5-17.
(责任编辑:江 艳)
