基于属性相似性度量的BIM构件聚类
2020-05-21王万齐马宝睿卢文龙刘玉身
王万齐,马宝睿,李 倩,卢文龙,刘玉身
基于属性相似性度量的BIM构件聚类
王万齐1,马宝睿2,李 倩2,卢文龙1,刘玉身2
(1. 中国铁道科学研究院集团有限公司电子计算技术研究所,北京 100081;2. 清华大学软件学院,北京信息科学与技术国家研究中心,北京 100084)
近年来,随着建筑信息模型(BIM)构件库资源在互联网上迅猛增长,对大量BIM构件资源的聚类和检索应用变得日益迫切。现有方法还缺乏对BIM构件所承载的领域信息提取,基于BIM构件所承载的领域信息,对BIM构件库资源开展聚类研究:①针对BIM构件,提出了一种基于属性信息量的BIM构件相似性度量算法,以充分利用BIM构件属性信息。通过与传统的Tversky相似性度量算法以及几何形状相似匹配算法相比,其在相似性度量上效果更好。②基于BIM构件间的相似性度量算法,提出了一种BIM构件库聚类方法。并在BIMSeek检索引擎中集成了BIM构件的关键字检索功能以及分类器查看功能,为用户提供更丰富的检索和查看方式。通过与传统的K-medoids和AP聚类算法相比,其聚类方法效果更好。
建筑信息模型;工业基础类;信息检索;相似性度量;聚类
近几十年来,继声音、图像、视频之后,三维模型作为第四代多媒体资源,已被广泛地应用于机器学习、虚拟现实等领域,大量可共享的三维模型在互联网上迅猛增加[1]。由于采用多媒体检索技术可以提高开发效率、缩短开发周期、节省开发成本,因此得到了众多研究人员的重视,特别是在CAD工程制图设计领域。
随着BIM在AEC领域的迅猛崛起,互联网涌现出大量的BIM资源库,目前比较主流的有Autodesk Seek,BIM Object,National BIM Library,Modlar,SmartBIM,Arcat,RevitCity网站等。这些网站中少则拥有几千个多则拥有几万个BIM构件,面对如此日益庞大的三维模型库,设计人员需要将主要精力从如何构建三维模型转变为如何基于已有的模型构建出符合需求的新模型的问题上。GUNN[2]在美国科学杂志上发表文章表示,40%的构件可以在已有的模型之上重新设计,40%的构件可以修改已有的模型,仅有20%的构件需要重新设计。ULLMAN[3]认为超过75%的设计可以复用以前的设计来满足新的需求。由此可见,构件复用的需求量相当大。如何快速准确地查找到满足设计人员需求的构件,实现设计资源的重复利用,成为当前的热点研究问题[4]。
聚类的最初目的是将具有相似特征的物体放在一起[5]。聚类分析有4个功能:①对数据分类进行进一步扩展;②对归类进行概念性探索;③通过探索数据形成假说;④对实际的数据集归类假说的测试方法。一般而言,聚类是对数据集分成若干个簇的过程。所以对BIM构建进行聚类有利于生成更好的检索结果。
基于上述分析,本文针对如何快速准确查找符合设计需求的三维模型的问题,提出了一种BIM构件库聚类方法。并在BIMSeek检索引擎中集成了BIM构件的关键字检索功能以及分类器查看功能,为用户提供更丰富的检索和查看方式。
1 相关工作
由IAI (International Alliance for Interoperability)组织定义的IFC (industry foundation classes)国际标准是BIM的最主要数据交换标准[6]。因此,本文使用IFC文件表示BIM构件,展开对BIM构件的聚类研究。
聚类研究方法包括:基于划分的方法,将每个样本划分为一个归属,例如K-means[7],EM[8],K-medoids[9];基于层次的方法,创建层次,递归将样本合并或拆除,例如BIRCH[10],CUBE[11],ROCK[12];基于密度的方法,区域中点的密度大于阈值时,将其加入到最近的类簇中,例如DBSCAN[13],OPTICS[14];基于网格的方法,将数据空间量化为网格单元,将样本点分配到相应网格中,例如WaveCluster[15];基于模型的方法,为每个类簇定义一个模型,根据给定模型为每个样本点选择合适模型,例如SOM[16]。
对BIM构件的聚类研究有很多应用,例如将BIM构件聚类应用到对BIM信息的挖掘和噪声数据的检测[17-18];将BIM聚类应用到对缺少标注的模型提取有用信息;本文将BIM构件的聚类算法应用到检索,集成到BIMSeek检索引擎中完成检索和分类器查看功能。
之前部分工作是在BIM领域做检索的研 究[19-21],而本文则是应用于BIM构件自身上。其结合复杂的语义信息减少数据集成的不一致性,是结合语义构建领域知识[22-24],本文工作是结合语义信息进行聚类和检索。
在传统的三维模型检索领域中,主要通过提取模型的几何特征来构建向量,但是对于工程设计领域的三维模型,不仅包括几何特征,还包含语义属性,因此,仅通过提取几何特征是不足以描述整个模型。而基于模型本身内容的三维模型检索可以更好地支持针对BIM构件展开聚类的研究。
本文从Arcat、Autodesk Seek和BIM Object网站上提取了一万个BIM构件,对其开展检索与聚类的研究,首先提出了一种基于属性信息量的BIM构件相似性度量方法。基于BIM构件间的相似性度量算法,本文提出了一种BIM构件库聚类方法,并将聚类结果应用于检索结果分类展示中,从而生成更好的检索聚类效果。同时,为了给用户提供更丰富的检索和查看方式,本文在BIMSeek检索引擎中集成了BIM构件的关键字检索功能以及分类器查看功能。
2 方法
针对BIM构件的相似性度量方法,提出了一种BIM构件库的聚类算法,首先使用近邻传播(affinity propagation,AP)算法[25]对初始种子进行选取,然后使用K-medoids算法进行聚类,在进行相似性度量时使用本文提出的基于属性信息量的BIM构件相似性度量算法。将从多个BIM资源库中提取的构件进行聚类,并将聚类应用于检索中,实现了检索结果的分类展示以及分类器查看功能。由于使用基于属性信息量的聚类结果类别比较精细,类别比较多,需要给其聚类结果打标签作为二级聚类标签。而类别太多不易于浏览,因此,需要将聚类结果合并,并将其结果再次打标签作为一级标签。
BIM构件库聚类算法的流程如图1所示。

图1 BIM构件库聚类算法流程图
2.1 基于属性信息量的构件相似性度量
由于IFC文件中包含了该BIM构件的所有几何属性和语义属性,因此每一个BIM构件均需一个相应的属性向量表示,从而BIM构件的相似性度量即转换为构件属性向量的相似性度量。在此提出了一种基于RESNIK[26]提出的信息量计算和TVERSKY和GATI[27]相似度模型的BIM构件属性相似性度量算法。
本文提出BIM构件的语义信息量为


将所有BIM构件的属性信息量保存到计算机中,便于后续读取使用。
由于每个BIM构件均被处理成一个属性向量,其既包含了几何属性(长度、宽度等),又包含了语义属性(材质、厂商等),本文中默认的属性权重值设置为1,当属性名称相同时,为了保证在相似度的计算中更加精确,需要在以下2种情况下修改属性的权重值:①对于几何属性,设定了一个阈值为5%,当相差比例大于5%时为不相同属性,其权重值为0;相差比例小于5%的属性设定为相同属性,但其权重值按比例缩小。②对于语义属性,如果描述2个部件的描述词有部分匹配也认为其属性是一样的,只不过其权重相应缩小,但若2个属性值完全不同,那么权重值则为0。此外,对于自定义属性,由于不同的人可能会使用不同的单词来表达同一个意思,本文使用WordNet来解决这种相同属性的不同表达问题,即通过同义关系得到相应的同义词列表。
本节提出基于属性信息量的BIM构件相似度计算公式,通过集合运算计算出任意2个构件之间的相似度,即

其中,
()为该集合中所有属性的信息量与权重值相乘之和,即

其方法可读取保存在属性信息量的中间文件,找到所表示的所有属性,假设中属性个数为,将这个属性的信息量和权重值相乘之后再求和;IC为第个属性的信息量;W为第个属性的权重值。
2.2 基于相似性传播算法的初始种子选取
本文在AP算法的基础上,融入了对BIM构件的语义相似性度量。在AP算法运行过程中,不断地从BIM构件预存好的相似度矩阵中提取数据,其算法称为Tversky-AP算法,具体如下:
算法1. Tversky-AP算法。
输入:BIM构件语义相似度矩阵simiMatrix,该矩阵为二维矩阵,simiMatrix[i][j]代表BIM构件i与BIM构件j的相似度。
输出:初步聚类的BIM构件clusters。
rebuildSimiMatrix对输入语义相似度矩阵的重建,即

其中,当≠,使用基于属性信息量的相似度表示(,);当=,其值称为参考度,由于本文认为所有的构件均有可能成为聚类中心,因此该参考度的值需相同,其值取自相似度矩阵的中位数。
updateR更新式见式(5)。当吸引度矩阵均有值后,需要根据吸引度的值更新归属度的值,updateA在≠时,更新为式(6),在=时,更新为式(7)。
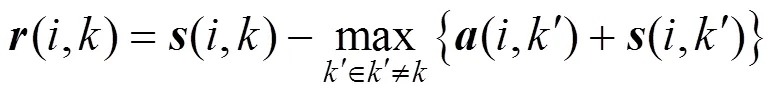



chooseClusterCenter可对每一个BIM构件确定其聚类中心。若=,则构件本身是聚类中心;若≠,则构件是构件的聚类中心。每次迭代选取(,)+(,)最大值对应的BIM构件作为聚类中心。
2.3 基于K-medoids算法的BIM构件聚类
本文将Tversky-AP算法的结果作为K-medoids算法的初始聚类中心,因此称该算法为AP-medoids算法,具体如下:
算法2. AP-medoids算法。
输入:Tversky-AP算法的结果clusters。
输出:聚类好的BIM构件idResult。

chooseCenter为每一个非初始聚类中心的BIM构件选取初始类别,读取在2.1节中保存的BIM构件的相似度矩阵,得到每一个BIM构件与初始的个聚类中心的语义相似度,选取语义相似度最大的聚类中心作为应该属于的类。
chooseClusterCenter计算该构件与其余构件之间的语义相似度之和,将语义相似度的和最大的构件作为该类的聚类中心。updateClusters更新所有的聚类中心供下一次迭代使用。
原始的K-medoids算法的时间复杂度主要浪费在计算彼此的距离,本文算法不需要实时地计算BIM构件之间的相似度,而是采取了预处理的方法,这也是本文对K-medoids算法的第二点改进。
2.4 二级聚类标签的统计和选取
经过聚类之后,每一类BIM构件需要一个标签来概括该类构件,便于用户浏览。并将小类别合并成为大类别,相当于大类别的标签为一级标题,而小类别的标签为二级标题,在分类器中显示BIM构件时,首先看到的是一级标签,点进之后分列表显示二级标签。在标签选取后根据WordNet将具有相似标签描述的小类别进行一次初始合并。二级聚类标签的选取算法如下:
算法3. 二级聚类标签的选取算法。
输入:AP-medoids聚类算法的结果idResult。
输出:打过二级标签的聚类结果labelResult。
changeToDespResult即为将id转换成相应的构件描述信息。fliter为对描述信息的停用词处理。停用词列表中需要去除6类单词:①单词中含有数字;②单词长度为1;③常用的一些介词;④无用的形容词;⑤含特殊字符的单词;⑥人名、地名、厂商名。
calculateTfidf和maxTfidfWord基于权重值进行聚类标签的选取。本文使用TFIDF进行权重值的赋予。使用WordNet中的同义词组,在为每个类别描述信息的每个单词计算出权重值之后,选取权重值最大的那个单词作为该类的标签。
mergeWithWordnet在给聚类结果打标签之后,由于某些类别的标签依据WordNet是相似的,因此,可以将具有相似标签的类别进行一次初始的简单合并。例如标签“toilet”,“lavatory”和“bathroom”,而这3个标签在WordNet中是同义词,如图2所示,而这3个标签的词根是toilet,因此合并成一个大类别,使用“toilet”作为标签。
2.5 聚类结果合并
由于基于属性信息量的相似度计算方法,使得聚类结果更加精细,导致聚类类别较多。例如,原本均是门,但是由于内部结构不同(双开门、单开门等),被聚成了多个类别,而类别太多不易于浏览,因此有必要将原本相关的小类别合并成大类。
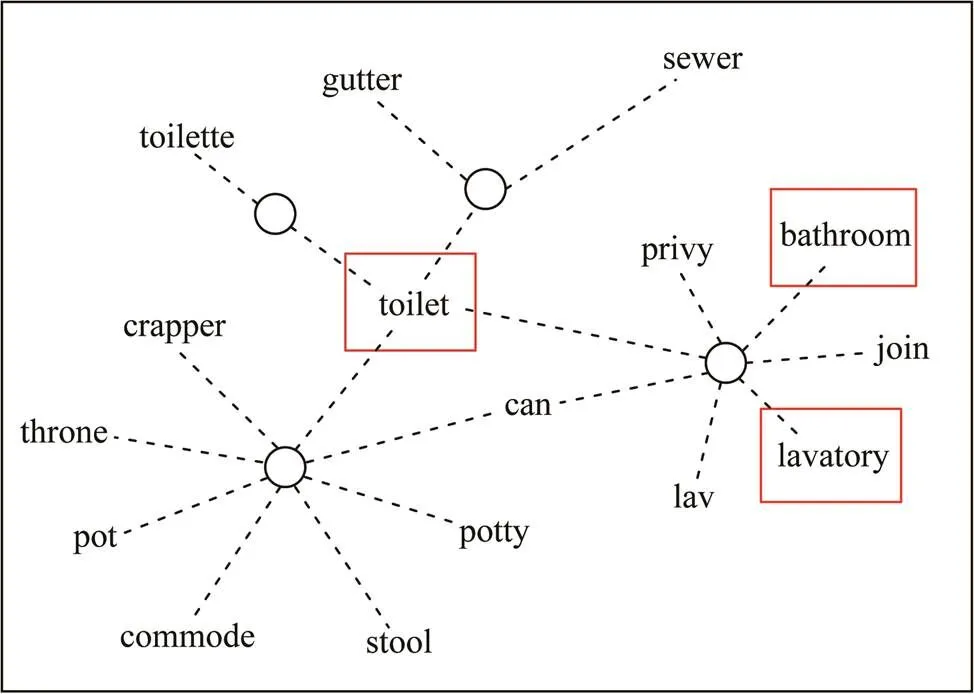
图2 WordNet中toilet的同义词示意图
本文采用VSM[28]向量空间模型(vector space model)进行构件描述信息相似度的比对,根据构件的描述信息的相似性进行类别的合并。基于构件描述信息的聚类合并算法如下:
算法4. 基于聚类描述信息构件合并算法。
输入:打过二级标签的聚类结果idResult。
输出:经过合并的BIM构件聚类结果mergedResult。
changeToDespResult是将打过二级聚类标签的聚类结果使用构件描述信息表示。buildDespVector是使用向量空间模型表示构件描述信息集合。对于BIM构件的描述信息集合,将其进行分词,最终形成一个由“key=value”构成的描述文档向量。由于语言本身就客观存在着诸多的不确定性,本文仍使用WordNet表示,凡是在其中具有相同词根的单词均被认为是相同的单词。changeToTfidfRes是通过计算向量空间模型中每个词项的权重值来构建描述信息集合的数值向量,便于相似度的计算。每个词项的权重值使用TFIDF来表示,其为TF值与IDF值的乘积。TF为某一词项在文中出现的频率,IDF为一个词项在多个文档中出现频率,代表词汇的普遍性。calculateSimi计算BIM构建文档信息向量之间的相似度度量方法是余弦距离相似度。
时间复杂度分析:假设打过二级标签的聚类结果有个类簇,将聚类结果转为其对应的描述信息的时间复杂度为();将描述信息集合使用向量空间模型表示的时间复杂度为();假设所有向量空间模型中不同的词项个数为,为每一个词项计算TFIDF的时间复杂度为(),那么转为TFIDF向量的时间复杂度为(××);使用余弦相似度计算相似度的时间复杂度为(),因此计算任意2个向量之间相似度的时间复杂度为(××);将相似向量合并的时间复杂度为(2);去重的时间复杂度为(),因此总的时间复杂度为(××)。
算法在实现过程中的改进。对于每个向量而言,其中0占了绝大多数,而在计算2个向量的相似度时只有非0值才起作用,因此本文在保存TFIDF向量时仅仅保留非零部分,就能大大降低的值,从而提高算法运行效率。
2.6 一级标签的选取
经过合并后即可得到一级聚类,且需要有一个标签来进行描述,称其为一级聚类标签,其是直接给用户进行浏览的,因此类别不能太多。由于本文的研究对象是使用IFC文件来表示的BIM构件,构件基本都隶属IfcBuildingElement,含有21个子类别,可使用自然语言来表示21个子类别,使用IfcBuildingElement的子类别(以下简称IFC标签)来引导一级聚类标签的选取。使用WordNet的同义词功能,可以得到IFC标签的同义词列表,用该列表过滤BIM构件的描述信息,这样就能够起到引导聚类标签选取的效果。
一级聚类标签的选取算法如下:
算法5. 基于聚类描述信息构件合并算法。
输入:经过合并后聚类结果mergedResult,IFC标签列表ifcList。
输出:打了一级标签的聚类结果labelResult。
getSynonyms为获取IFC标签的同义词列表,filter为BIM构件描述信息的过滤。将描述信息进行分词,对于每个单词使用WordNet计算其同义词列表,如果同义词列表中有一个单词与IFC标签的同义词列表中的单词相同,那么该单词保留,否则滤掉。calculateTfidf和maxTfidfWord是基于权重值的聚类标签的选取。基于WordNet计算初始标签的同义词列表,看同义词列表中的单词与哪个IFC标签的同义词列表中的单词相同,就选取那个IFC标签作为一级聚类标签。
3 实例验证与评估
3.1 BIM构件聚类应用于检索系统的实现
本文将BIM构件的聚类应用于BIMSeek[20-21]构件检索系统和3DSeek[29-35]三维模型检索中,实现了对于关键子检索结果的分类展示以及分类器查看2个功能。将关键字的检索结果进行分类展示,便于用户浏览。
图3为系统首页,用户可以通过3种方式进行检索:①输入关键词进行检索;②点击分类查看器中的一级聚类标签进行检索;③上传BIM构件进行属性检索。图4为当输入的关键词为“window”时的查询结果示意图(分类器查看页面与其类似),在右侧可以选择“window”下面的任意一个二级聚类标签,左侧的结果会根据二级聚类标签而变化,结果列表展示了检索结果构件的名称、类别、厂家、简要描述、属性信息、三维模型的展示以及IFC文件和RFA文件的下载。
针对上传BIM构件进行属性检索功能,例如上传一个门的BIM构件根据属性检索,Door_Industrial_RiteHite_FasTraxCL-VerticalLift这个构件在使用基于信息量和Tversky的BIM构件属性相似性度量方法的结果列表中第6个出现,而在使用传统的Tversky相似性度量方法的结果列表中是第12个出现,如图5所示。由于该构件与上传构件的共同属性中包含的信息量更大,例如Door Slab Material,Vision Panel Material这些属性,因此该构件应当在检索列表的前面显示,此例子说明本文方法可以更好地根据属性检索到信息量更接近的模型。

图3 系统首页示意图
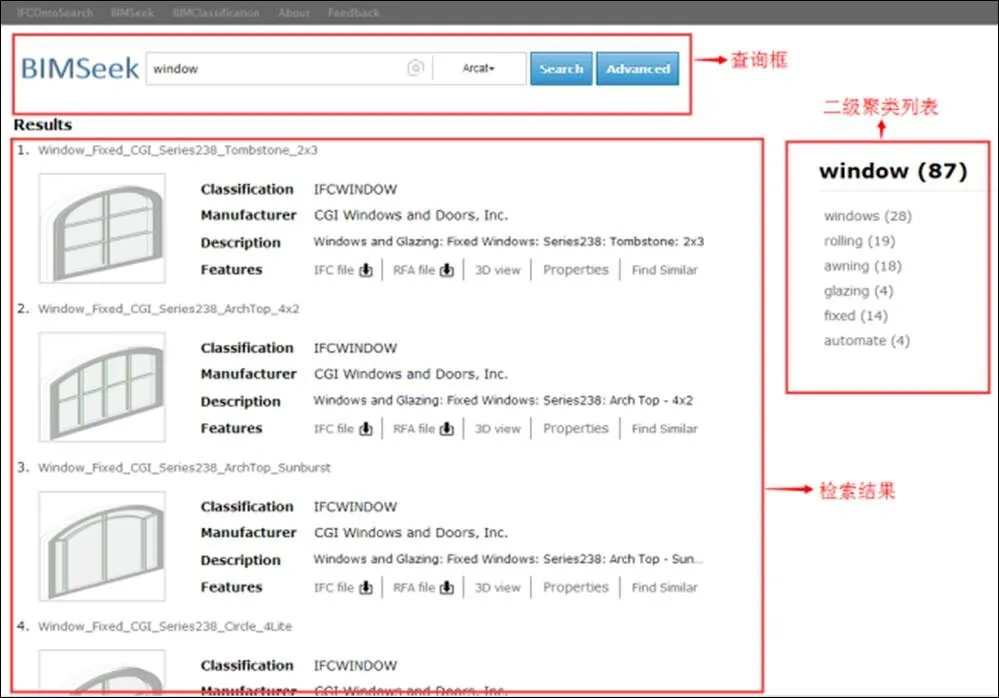
图4 关键字检索结果示意图

图5 Door_Industrial_RiteHite_FasTraxCL-VerticalLift构件在2种相似度比较方法中的实例对比图
3.2 聚类结果比较
本文采用类内类外标准和Purity标准对聚类结果进行评判,且进行实验的数据是经过AP-medoids聚类之后的数据。
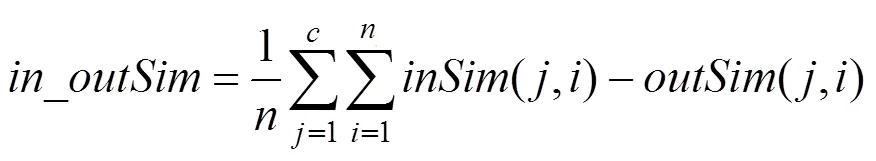
其中,_的值越大说明聚类结果越好。
Purity标准:计算正确聚类的模型占总模型数的比例,即
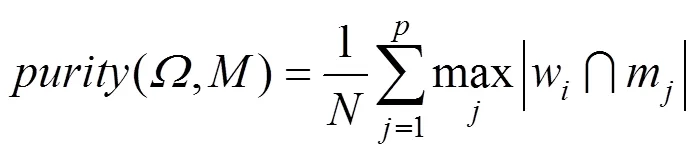
其中,为模型总数;={1,2,…,w}为聚类的集合;w为第个聚类的模型集合;={1,2,…,m}为标准分类的模型集合;m为第个标准分类的模型集合;(,)的值越高,聚类结果越准确。
为了验证使用AP-medoids聚类算法的聚类效果,分别将其与单独使用K-medoids算法和单独使用AP算法进行对比,并分别将3个聚类算法应用于Arcat, Autodesk Seek,BIM Object资源库和混合资源库这4个BIM资源库中,并使用2种聚类评价标准来评判聚类结果。
由于AP算法和AP-medoids算法聚类结果均是稳定的,而K-medoids算法由于初始聚类中心的选取是随机的,在本实验中,将随机选取初始聚类种子的个数为benchmark中对应资源库的BIM构件的类别数,而表1中的实验数据对于K-medoids聚类算法的结果是采用10次实验结果的平均值。

表1 benchmark中BIM构件的个数及其分类数
表2展示了针对4个资源库,使用类内类外标准的对比结果。
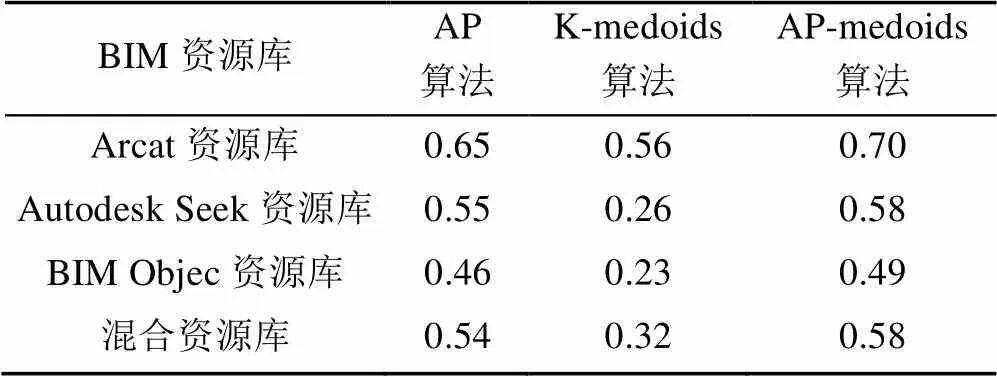
表2 3种聚类算法针对4个资源库的类内类外标准评判结果
由表2可知,无论哪个资源库,AP-medoids算法的类内类外相似度的值均大于单独使用AP算法的值;且单独使用AP算法的值均大于单独使用K-medoids的值。亦即使用AP-medoids聚类算法的效果要好于单独使用AP算法的效果,单独使用AP算法的效果要好于单独使用K-medoids算法。
表3展示了针对4个资源库,使用Purity标准的对比结果。
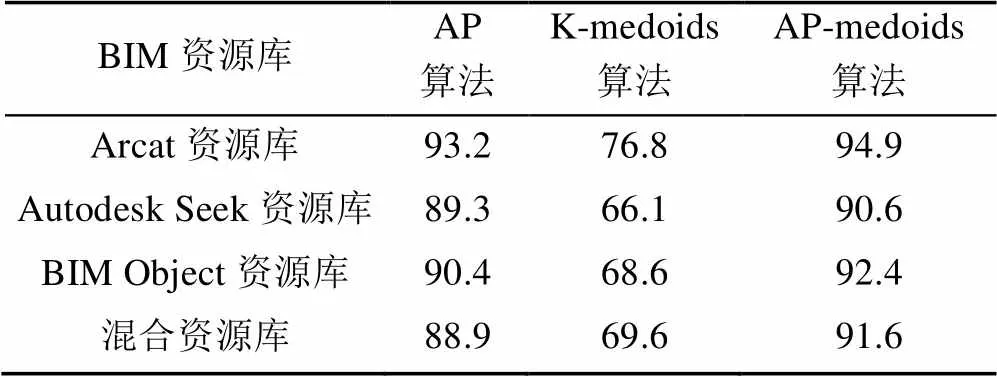
表3 3种聚类算法针对4个资源库的Purity标准评判结果(%)
从表3可知,AP-medoids聚类算法的准确度高于单独使用AP算法的准确度,且单独使用AP算法又高于单独使用K-medoids算法的准确度。亦即,AP-medoids聚类算法的效果最好。
4 结束语
本文提出的基于BIM构件属性信息量的构件聚类算法,其对传统经典的K-medoids聚类算法进行了2点改进:①利用AP算法的结果作为K-medoids的初始聚类中心,使得聚类结果变得稳定;②提出的基于属性信息量的BIM构件相似性度量方法,由于构件之间的相似度是经过预处理的,结果保存到中间文件,大大提高了K-medoids算法的运行速度和降低了算法复杂度,充分结合了BIM构件本身的领域信息。
为了验证本文提出的聚类算法的效果,针对Arcat,Autodesk Seek,BIM Object资源库和混合资源库4个BIM构件资源库,利用类内类外标准和purity度量2种聚类评价手段,将AP-medoids聚类算法与单独使用AP聚类算法和单独使用K-medoids聚类算法进行聚类结果的评判,实验结果证明使用AP-medoids聚类效果更好。
本文还将该聚类结果应用于BIMSeek检索系统中,实现了对关键字检索结果的分类展示以及分类器查看功能。为用户在分类器查看时更加方便,还对聚类结果进行了二次聚类标签的选取,并通过IFC领域信息再次对结果进行合并以及一级聚类标签的选取。
[1] GAO Y, DAI Q H, WANG M, et al. 3D model retrieval using weighted bipartite graph matching[J]. Signal Processing: Image Communication, 2011, 26(1): 39-47.
[2] GUNN T G. The mechanization of design and manufacturing[J]. Scientific American, 1982, 247(3): 114-130.
[3] ULLMAN D G. The mechanical design process[M]. New York: McGraw-Hill, 1992: 47-51.
[4] 潘翔, 张三元, 叶修梓. 三维模型语义检索研究进 展[J]. 计算机学报, 2009, 32(6): 1069-1079.
[5] ALDENDERFER M S, BLASHFIELD R K. Cluster analysis[M]. Los Angeles: Sage Publications, 1984: 2-12.
[6] YU K, FROESE T M, GROBLER F. International alliance for interoperability: industry foundation classes[EB/OL]. [2019-08-10]. https://www.researchgate. net/publication/246506361_International_alliance_for_interoperability_Industry_foundation_classes.
[7] CAO J, WU Z A, WU J J, et al. Towards information-theoretic K-means clustering for image indexing[J]. Signal Processing, 2013, 93(7): 2026-2037.
[8] LIU Z, SONG Y Q, XIE C H, et al. Clustering gene expression data analysis using an improved EM algorithm based on multivariate elliptical contoured mixture models[J]. Optik, 2014, 125(21): 6388-6394.
[9] PARK H S, JUN C H. A simple and fast algorithm for K-medoids clustering[J]. Expert Systems with Applications, 2009, 36(2): 3336-3341.
[10] ZHANG T, RAMAKRISHNAN R, LIVNY M. BIRCH: an efficient data clustering method for very large databases[C]//Proceedings of the ACM SIGMOD International Conference on Management of Data. New York: ACM Press, 1996: 103-114.
[11] ZHANG Z J, SHU H, CHONG Z H, et al. C-Cube: elastic continuous clustering in the cloud[C]//2013 IEEE 29th International Conference on Data Engineering (ICDE). New York: IEEE Press, 2013: 577-588.
[12] LI R, LIU L. A method for large scale ontology partitioning and block matching based on ROCK clustering[J]. Applied Mechanics and Materials, 2014, 536-537: 390-393.
[13] CHAKRABORTY S, NAGWANI N K. Analysis and study of incremental K-means clustering algorithm[M]//High Performance Architecture and Grid Computing. Heidelberg: Springer, 2011: 338-341.
[14] ANKERST M, BREUNIG M M, KRIEGEL H P, et al. OPTICS: ordering points to identify the clustering structure[C]//ACM Sigmod Record. New York: ACM Press, 1999: 49-60.
[15] ANGGRAINI E L, SUCIATI N, SUADI W. Parallel computing of WaveCluster algorithm for face recognition application[C]//2013 International Conference on QiR. New York: IEEE Press, 2013: 56-59.
[16] LIU Y C, WU C, LIU M. Research of fast SOM clustering for text information[J]. Expert Systems with Applications, 2011, 38(8): 9325-9333.
[17] PENG Y, LIN J R, ZHANG J P, et al. A hybrid data mining approach on BIM-based building operation and maintenance[J]. Building and Environment, 2017, 126: 483-495.
[18] ALI M, MOHAMED Y. A method for clustering unlabeled BIM objects using entropy and TF-IDF with RDF encoding[J]. Advanced Engineering Informatics, 2017, 33: 154-163.
[19] LIU H, LIU Y S, PAUWELS P, et al. Enhanced explicit semantic analysis for product model retrieval in construction industry[J]. IEEE Transactions on Industrial Informatics, 2017, 13(6): 3361-3369.
[20] GAO G, LIU Y S, LIN P P, et al. BIMTag: concept-based automatic semantic annotation of online BIM product resources[J]. Advanced Engineering Informatics, 2017, 31: 48-61.
[21] GAO G, LIU Y S, WANG M, et al. A query expansion method for retrieving online BIM resources based on industry foundation classes[J]. Automation in Construction, 2015, 56: 14-25.
[22] EL-MEKAWY M. EL-MEKAWY M. Integrating BIM and GIS for 3D city modelling[J]. Licentiate Thesis Geoinformatics Division Department of Urban Planning and Environment Royal Institute of Technology (KTH), 2010, 25: 55-58.
[23] KARAN E P, IRIZARRY J. Extending BIM interoperability to preconstruction operations using geospatial analyses and semantic web services[J]. Automation in Construction, 2015, 53: 1-12.
[24] MIGNARD C, GESQUIERE G, NICOLLE C. SIGA3D: a semantic bim extension to represent urban environment[C]//Proceedings of the 5th International Conference on Advances Semantic Processing. Lisbon: IARIA XPS Press, 2011: 20-25.
[25] FREY B J, DUECK D. Clustering by passing messages between data points[J]. Science, 2007, 315(5814): 972-976.
[26] RESNIK P. Using information content to evaluate semantic similarity in a taxonomy[EB/OL]. [2019-08-10]. https://xueshu.baidu.com/usercenter/paper/show?paperid=d102100755fd36fcfcf6573f2b9b2593&site=xueshu_se.
[27] TVERSKY A, GATI I. Studies of similarity[J]. Cognition and Categorization, 1978, 1(1978): 79-98.
[28] SALTON G, WONG A, YANG C S. A vector space model for automatic indexing[J]. Communications of the ACM, 1975, 18(11): 613-620.
[29] LI N, LI Q, LIU Y S, et al. BIMSeek++: retrieving BIM components using similarity measurement of attributes[J]. Computers in Industry, 2020, 116: 103186, 1-12.
[30] HAN Z, SHANG M, LIU Z, et al. SeqViews2SeqLabels: learning 3D global features via aggregating sequential views by RNN with attention[J]. IEEE Transactions on Image Processing, 2019, 28(2): 658-672.
[31] HAN Z, LU H, LIU Z, et al. 3D2SeqViews: aggregating sequential views for 3D global feature learning by CNN with hierarchical attention aggregation[J]. IEEE Transactions on Image Processing, 2019, 28(8): 3986-3999.
[32] HAN Z, LIU Z, VONG C-M, et al. Deep spatiality: unsupervised learning of spatially-enhanced global and local 3D features by deep neural network with coupled softmax[J]. IEEE Transactions on Image Processing, 2018, 27(6): 3049-3063.
[33] HAN Z, LIU Z, VONG C-M, et al. BoSCC: bag of spatial context correlations for spatially enhanced 3D shape representation[J]. IEEE Transactions on Image Processing, 2017, 26(8): 3707-3720.
[34] LIU X H, HAN Z Z, LIU Y S, et al. Point2Sequence: learning the shape representation of 3D point clouds with an attention-based sequence to sequence network[EB/OL]. [2019-08-10]. https://xueshu.baidu.com/usercenter/paper/ show?paperid=140p0m30uu7p00v0kk6g02a02u626778&site=xueshu_se.
[35] HAN Z Z, SHANG M Y, LIU Y S, et al. View inter-prediction GAN: unsupervised representation learning for 3D shapes by learning global shape memories to support local view predictions[EB/OL]. [2019-08-10]. http://xueshu.baidu.com/usercenter/paper/ show?paperid=136m0cc0hy5206j0jy2x0rq0ru020636&site=xueshu_se.
Clustering of BIM components based on similarity measurement of attributes
WANG Wan-qi1, MA Bao-rui2, LI Qian2, LU Wen-long1, LIU Yu-shen2
(1. Institute of Computing Technology, China Academy of Railway Sciences Corporation Limited, Beijing 100081, China; 2. School of Software, BNRist, Tsinghua University, Beijing 100084, China)
In recent years, resources in the Building Information Modeling (BIM) components library are expanding rapidly on the Internet. There is an increasing demand for ways to cluster and retrieve appropriate BIM components among countless resources. However, the way to extract domain information of BIM components still can not be found in existing methods. This paper studies the clustering of BIM components based on the domain information of BIM components: ①For BIM components, tan algorithm measuring similarity is proposed based on the attribute information. Compared with the traditional Tversky similarity measure algorithm and geometry similarity matching algorithm, the newly proposed one the present study has produced a better result. ②A clustering method of BIM component library is proposed based on the similarity measure algorithm of BIM components. Users are provided with diverse ways to retrieve and check information thanks to the search engine of BIMSeek integrated with functions of keyword-based retrieval and classifier view. Compared with the K-medoids algorithm and AP algorithm, the results of ours are more desirable.
building information modeling; industry foundation class; information retrieval; similarity measure; clustering
TP 391
10.11996/JG.j.2095-302X.2020020304
A
2095-302X(2020)02-0304-09
2019-09-10;
2019-10-14
国家重点研发计划项目(2018YFB0505400);国铁集团科技研究开发计划项目(K2018G055, 2017X003)
王万齐(1978-),男,甘肃环县人,研究员,博士。主要研究方向为建筑信息模型与应用等。E-mail:13701314627@163.com
刘玉身(1976-),男,辽宁瓦房店人,副教授,博士。主要研究方向为计算机图形学与建筑信息模型。E-mail:liuyushen@tsinghua.edu.cn
