基于高维混沌系统的伪随机序列生成器
2020-05-20马旭炯,于加武,杨飞飞,牟俊
马 旭 炯, 于 加 武, 杨 飞 飞, 牟 俊
( 大连工业大学 信息科学与工程学院, 辽宁 大连 116034 )
0 引 言
伪随机序列是具有某种随机特性的确定序列,由于其优良的随机性和接近于白噪声的统计特性,在许多科学技术和工程领域中有着十分广泛的应用,如卫星、飞船轨道、雷达技术、保密通信、数字信息处理系统和扩频通信等[1-3]。使用计算机系统并不能得到真正意义上的随机序列[4-6]。目前常见的由计算机系统迭代产生的基于线性同余理论的m-序列[7-8]、Gold-序列[9-10]等传统伪随机序列,因其复杂度较低,导致所产生的伪随机序列在信息安全中的应用存在隐患。同时,传统伪随机序列在密码学设计中密码生成速度也会受到限制[11]。因此,性能优良且安全可靠的伪随机序列发生器的设计成为信息安全领域的研究热点。
混沌系统分为连续混沌系统和离散混沌系统,不同种类的混沌系统的动力学行为表现不同,所以各自生成的混沌伪随机序列的随机特性也不同,因此混沌系统的选择对于伪随机序列的生成非常重要[12-13]。连续混沌系统很多基于此类系统的伪随机序列已经被证明具有良好的统计特性,但常用于连续混沌系统的定步长积分方法在求解微分方程时易导致其混沌动力学行为退化,而序列复杂度却不会因为吸引子中涡卷数的增多而提高[14]。离散混沌系统多采用低维混沌系统或在其基础上改进的低维混沌系统来生成伪随机序列。Dabal等[15]设计了一个基于一维Logistic映射的伪随机序列生成器。李孟婷等[16]基于一维Logistic映射和二维Henon映射提出了一种多级混沌映射交替变参数的伪随机序列产生方法。张丽姣等[17]设计了一个基于二维离散混沌系统的伪随机数生成器等。这类方法计算速度快,形式简单,且系统动力学特性不会退化。缺点是复杂度低,易被破译。而超混沌系统具有两个或两个以上正李雅普诺夫指数[18-23],一般而言其序列随机性比普通混沌系统好,所以目前解决这些问题的有效途径之一就是采用超混沌系统生成伪随机序列,可有效提高生成的伪随机序列的安全性。
基于上述原因,本研究采用高维离散超混沌系统设计高性能的伪随机序列,基于修正版Marotto定理构造四维离散超混沌映射系统,首先分析其动力学特性,以便选定合适的系统参数,使得伪随机序列生成器产生的混沌伪随机序列在理论上具有最好的随机性能;其次采用重复量化算法设计出伪随机序列生成器;最后对生成的伪随机序列进行性能测试。
1 四维离散超混沌映射系统及其动力学特性
1.1 四维离散超混沌映射系统
四维离散超混沌映射系统方程:
(1)
式中:令参数a=4,b=4,c=3.5,d=2,t=4,系统初值[x0,y0,z0,w0]=[0.7,0.8,1.5,0.8],仿真步长为0.000 1。此时系统的李雅普诺夫指数分别为[0.866 5,0.694 1,0.624 8,0.199 3],表明系统此时存在不止一个正的李雅普诺夫指数,系统为超混沌态。其超混沌吸引子相图如图1所示。
1.2 动力学特性分析
1.2.1 分岔图和李雅普诺夫指数谱
取b∈[0,5],令a=4,c=3.5,d=2,t=4,系统初值[x0,y0,z0,w0]=[0.7,0.8,1.5,0.8],计算得系统李雅普诺夫指数谱和分岔图,如图2所示。系统的分岔图和李雅普诺夫指数谱的结果吻合。当0≤b≤0.88、1.75≤b≤2.19和2.47≤b≤5时,系统存在4个正的李雅普诺夫指数,系统处于超混沌态;当b∈[1.248,1.252],b∈[1.556,1.573] 时,系统中存在两个明显的周期窗口,因此选取混沌序列时,b的取值应尽量避免该周期窗口范围的值。
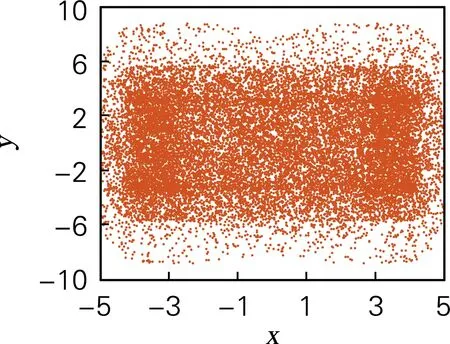
(a) x-y平面
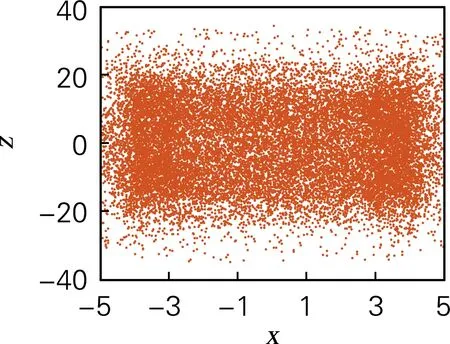
(b) x-z平面
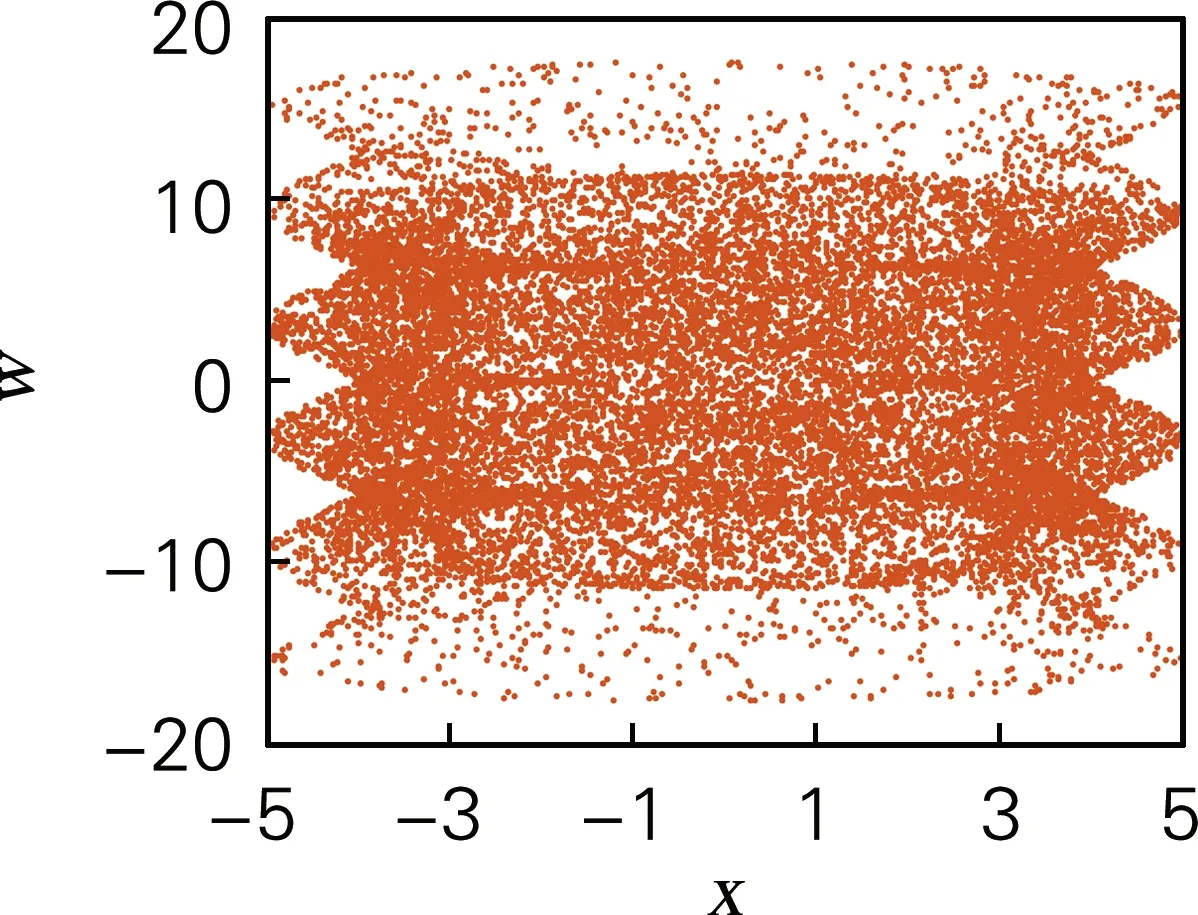
(c) x-w平面
图1 四维离散超混沌系统相图
Fig.1 Phase diagrams of four-dimensional discrete hyperchaotic system
当d∈[0,2.5]时,其余系统参数保持不变,仿真得系统李雅普诺夫指数谱和分岔图,如图3所示。系统的分岔图和李雅普诺夫指数谱相对应。当1.19≤d≤1.38和1.53≤d≤5时,系统的4个李雅普诺夫指数均为正值,说明系统状态为超混沌态,但系统在d∈[0.586,0.594]时存在周期窗口,因此参数d的选取也应避免该周期窗口范围内的值。
(a) 分岔图(b∈[0,5])
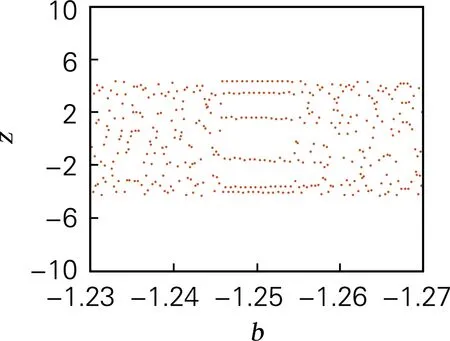
(b) 分岔图(b∈[1.23,1.27])
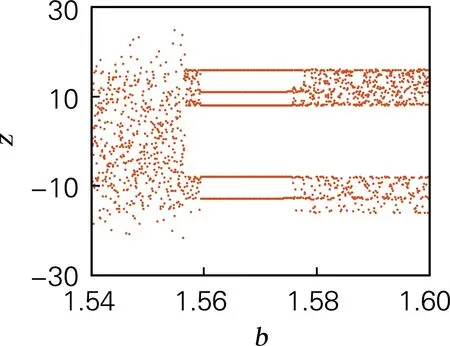
(c) 分岔图(b∈[1.54,1.6])
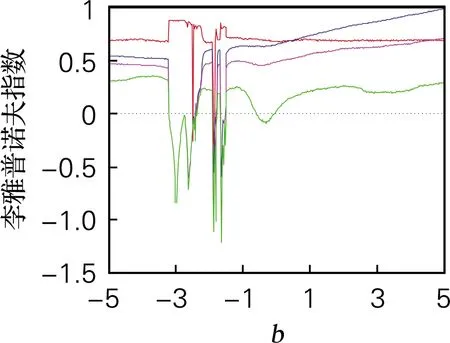
(d) LE (b∈[0,5])
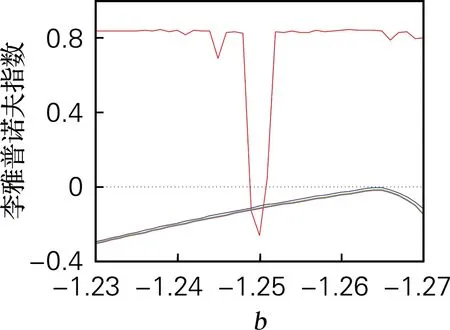
(e) LE (b∈[1.23,1.27])
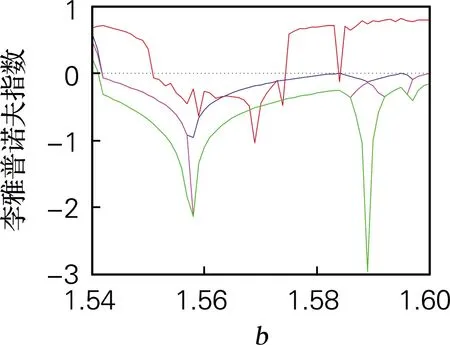
(f) LE (b∈[1.54,1.60])
图2 系统随b变化的分岔图和李雅普诺夫指数谱
Fig.2 Bifurcation diagrams and Lyapunov exponent spectra of the system asbchanges
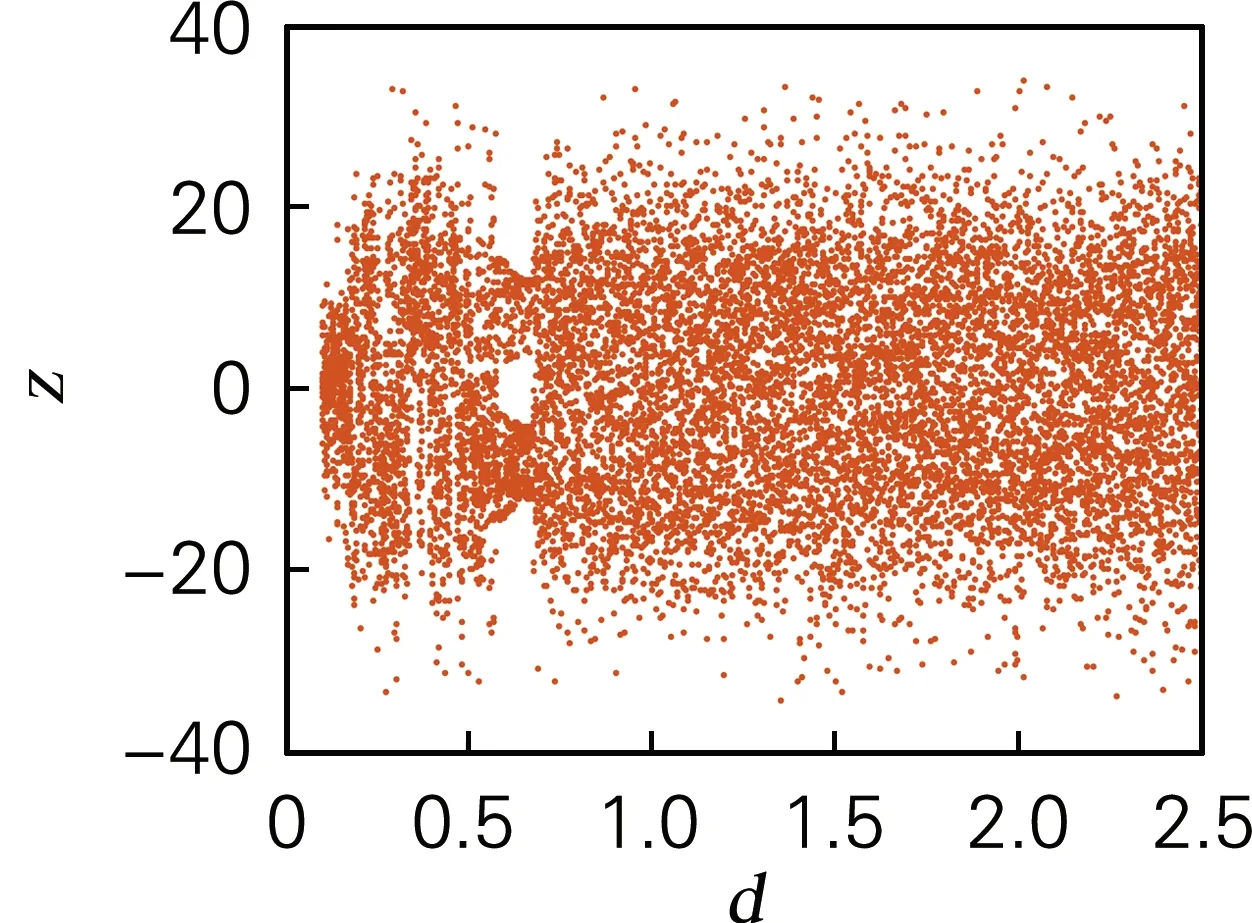
(a) 分岔图(d∈[0,2.5])
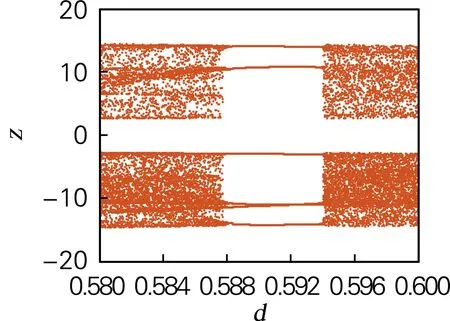
(b) 分岔图(d∈[0.58,0.6])
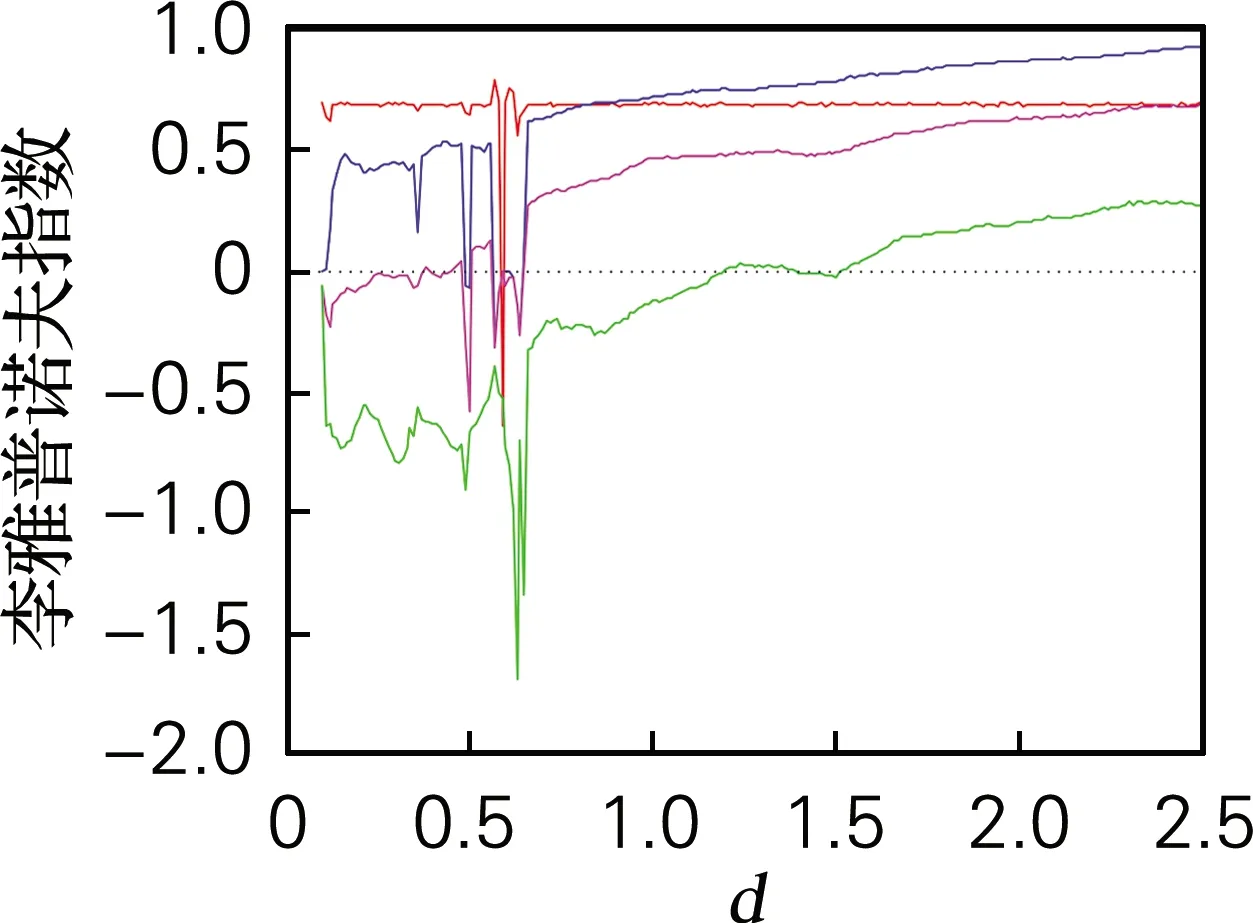
(c) LE (d∈[0,2.5])
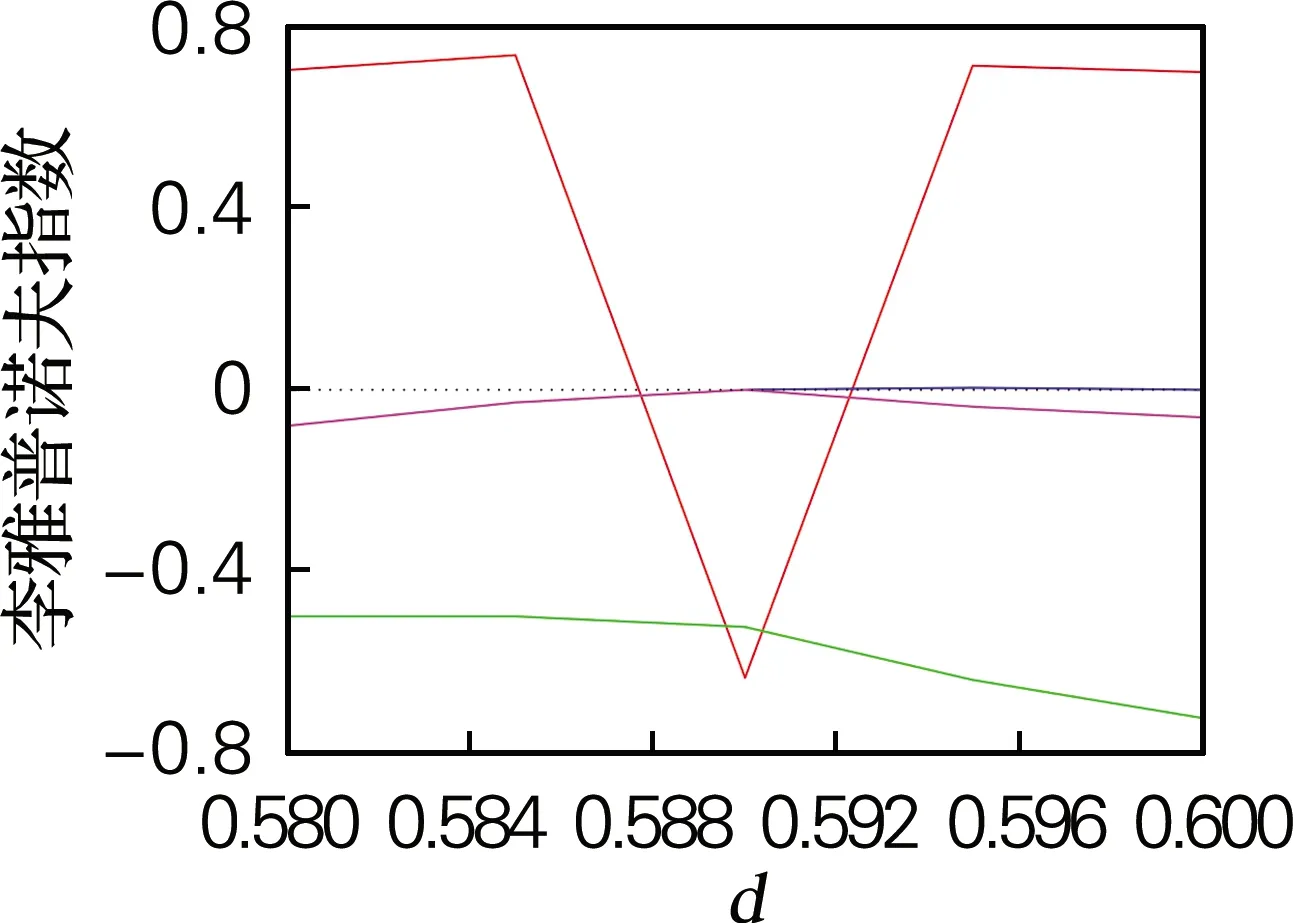
(d) LE (d∈[0.58,0.6])
图3 系统随d变化时的分岔图和李雅普诺夫指数谱
Fig.3 Bifurcation diagrams and Lyapunov exponent spectra of the system asdchanges
1.2.2 混沌序列复杂度分析
为了度量和分析混沌序列的复杂性,采用排列熵复杂度算法进行分析,该算法计算简便,易于实现[24]。取混沌序列长度为10 000,其他系统参数不变,取b∈[0,5]和d∈[0,2.5]时,得到混沌序列的排列熵复杂度,如图4所示。可以明显地看出,在b和d变化时,系统的动力学特性的变化趋势与分岔图和李雅普诺夫指数谱一致。
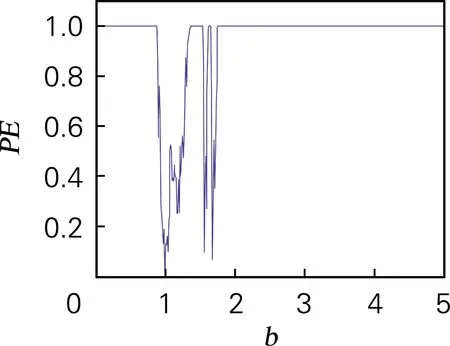
(a) 排列熵复杂度(b∈[0,5])
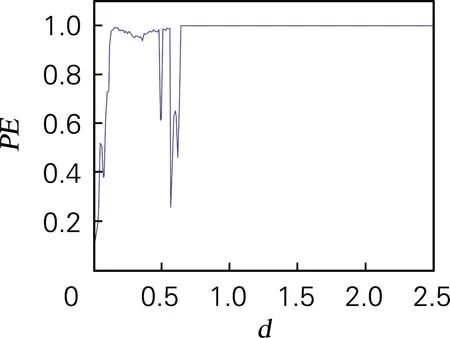
(b) 排列熵复杂度(d∈[0,2.5])
图4 排列熵复杂度
Fig.4 Permutation entropy complexity
在采用超混沌映射设计伪随机序列生成器时,为确保系统具有多个正的李雅普诺夫指数,选取a=4,b=4,c=3.5,d=2,t=4,使系统具有4个正的李雅普诺夫指数,用以设计超混沌伪随机序列生成器。
1.2.3 概率密度
如经典Logistic映射所生成的混沌序列,其概率密度函数分布近似于切比雪夫型,特点是中间均匀,两头稠密,这样的概率密度分布能减少盲目搜索,加快搜索效率[25]。四维离散超混沌映射系统生成的4个离散序列Xn、Yn、Zn、Wn的概率密度,如图5所示。其概率密度均相似于切比雪夫型分布,说明其概率密度分布符合需求,生成的混沌序列随机性能良好。
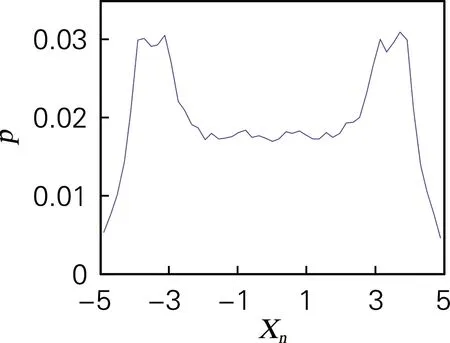
(a) 概率密度测试(Xn序列)
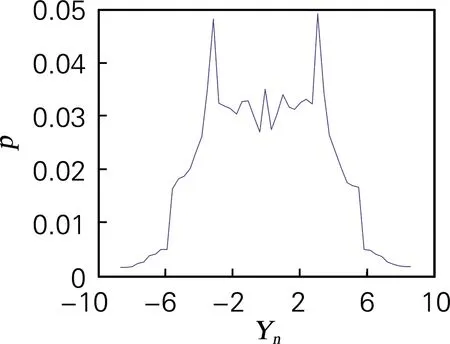
(b) 概率密度测试(Yn序列)
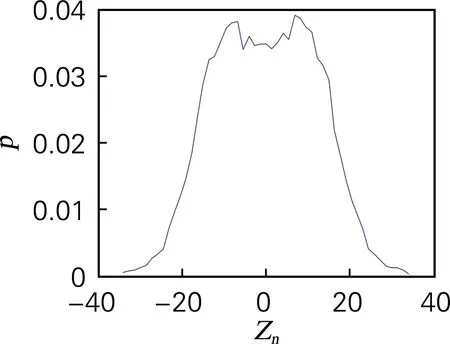
(c) 概率密度测试(Zn序列)
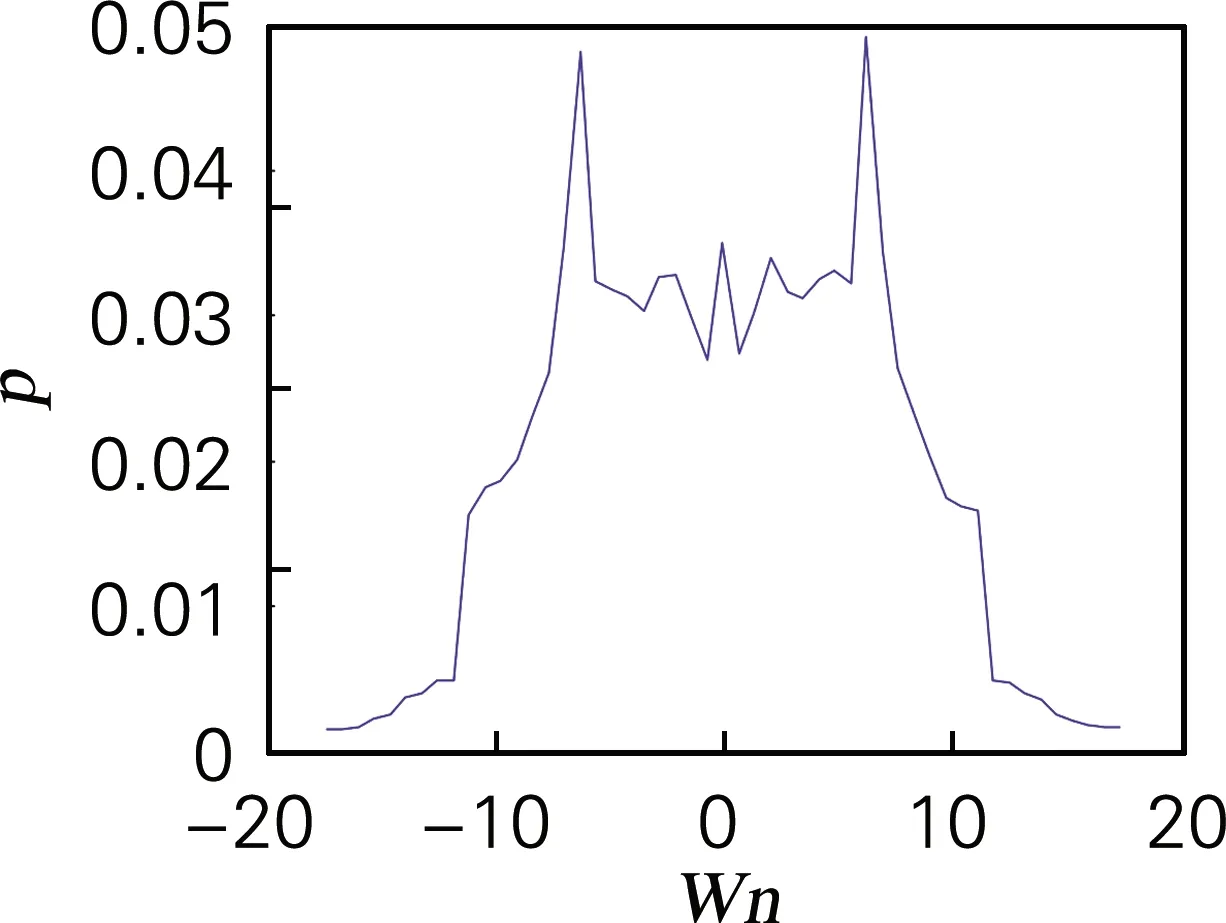
(d) 概率密度测试(Wn序列)
图5 概率密度测试
Fig.5 Probability density test
2 伪随机序列生成器设计
混沌伪随机序列是将混沌系统产生的序列进行量化后所得的二进制序列,这个二进制序列包含混沌系统的随机性。在生成伪随机序列的过程中,量化是一个重要的环节,量化算法的选择直接影响到生成的伪随机序列的随机性、复杂性以及使用安全性[26]。因此,为保证伪随机序列生成器的性能,必须选取合适的量化方法。取a=4,b=4,c=3.5,d=2,t=4,系统初值[x0,y0,z0,w0]=[0.7,0.8,1.5,0.8],将系统生成的4个超混沌序列采用重复量化算法进行量化,具体步骤如下:
步骤1设定系统参数和初值后,迭代N次用以消除暂态效应保证系统进入混沌态。继续迭代超混沌系统得到4个实数值xn、yn、zn、wn,通过式(2)得到4个新的实数值x′n、y′n、z′n、w′n。
k′=πlnk,k=xn,yn,zn,wn
(2)
步骤2通过式(3)去掉x′n、y′n、z′n、w′n4个实数值的整数部分,保留实数值的小数部分A=(Ax,Ay,Az,Aw)。
A=abs(k′)-floor(abs(k′))
(3)
其中abs和floor分别是Matlab软件中的绝对值函数和取整函数。
步骤3采用乘二取整法,将小数A用二进制表示出来。
A′=a1a2…am
(4)
其中A′=(A′x,A′y,A′z,A′w),am可取0或1,m为计算精度。
步骤4将所得4个二值序列按式(5)进行异或运算得到一个新的序列S。
S=A′x⊕A′y⊕A′z⊕A′w
(5)
步骤5继续迭代超混沌系统,重复上述4个步骤直至获得所需长度的超混沌伪随机序列。
上述算法中,超混沌系统的初值产生的序列x0、y0、z0、w0和迭代次数N可以作为密钥,如果计算机的精度是16,则算法的密钥空间可达2212,所以本算法密钥空间对一般的穷举攻击有足够的抵御能力。
3 伪随机序列性能分析
3.1 NIST SP800-22测试
检测伪随机数随机性能的标准有很多,如美国联邦信息处理标准FIPS 140-2,Marsaglia制定的Diehard Battery检测以及美国国家标准技术研究所(NIST)制定的随机序列测试标准SP 800-22等。本研究采用了现阶段应用最广泛、最具权威性的NIST SP800-22标准对本算法产生的伪随机序列进行检测,该标准一共有15项测试指标,将理想随机序列作为参考,在统计特性上从不同角度检验伪随机序列的偏离程度,普遍认为,能通过该检测的序列具有良好的伪随机性能[22]。SP 800-22标准的每项测试都会提供通过率和P值分布的均匀性两个判断依据。所有测试均取显著水平α=0.01,测试序列β组,则可定义通过率的置信区间为
(6)
当通过率落在此置信区间内,表示序列通过测试;而若P值>0.000 1,则表明被测序列的P值是均匀分布的,序列是随机的。
所用的测试条件为:显著水平α=0.01,测试序列β=100组,每组长度为106bit,置信区间为[0.96,1]。测试后得到的结果如表1所示。从表1的结果可以看出,所设计的伪随机序列生成器生成的伪随机序列通过了NIST SP800-22测试,说明伪随机序列具有较良好的伪随机性能。通过与Li等[27]提出的基于Logistic混沌映射系统和Akhshani等[28]使用三维离散超混沌映射系统设计的伪随机序列生成器所生成的混沌伪随机序列的NIST测试结果相比较,所设计的基于高维离散混沌系统的伪随机序列生成器生成的混沌伪随机序列的NIST测试结果,有12项指标的P值大于文献[27]中的结果,有11项指标的P值大于文献[28]中的结果,因此,此伪随机序列的随机性更好,在保密通信等信息安全领域中的应用更加安全可靠。
3.2 相关性分析
相关性是测试伪随机序列的一个重要指标,良好的相关性是系统能够可靠运行的重要保证,相关性包括自相关和互相关。理想的随机序列其自相关函数接近于δ函数,互相关函数接近于0。δ函数的定义为
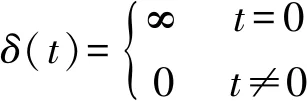
(7)
令a=4,b=4,c=3.5,d=2,t=4,系统初值[x0,y0,z0,w0]=[0.7,0.8,1.5,0.8],从公式(4)所得的序列A′中随机抽取长度为60 000的二进制序列,其自相关性和互相关性,如图6所示。该伪随机序列生成器生成的二进制序列A′的自相关函数接近于δ函数,互相关函数接近于0,说明其自相关性和互相关性良好。
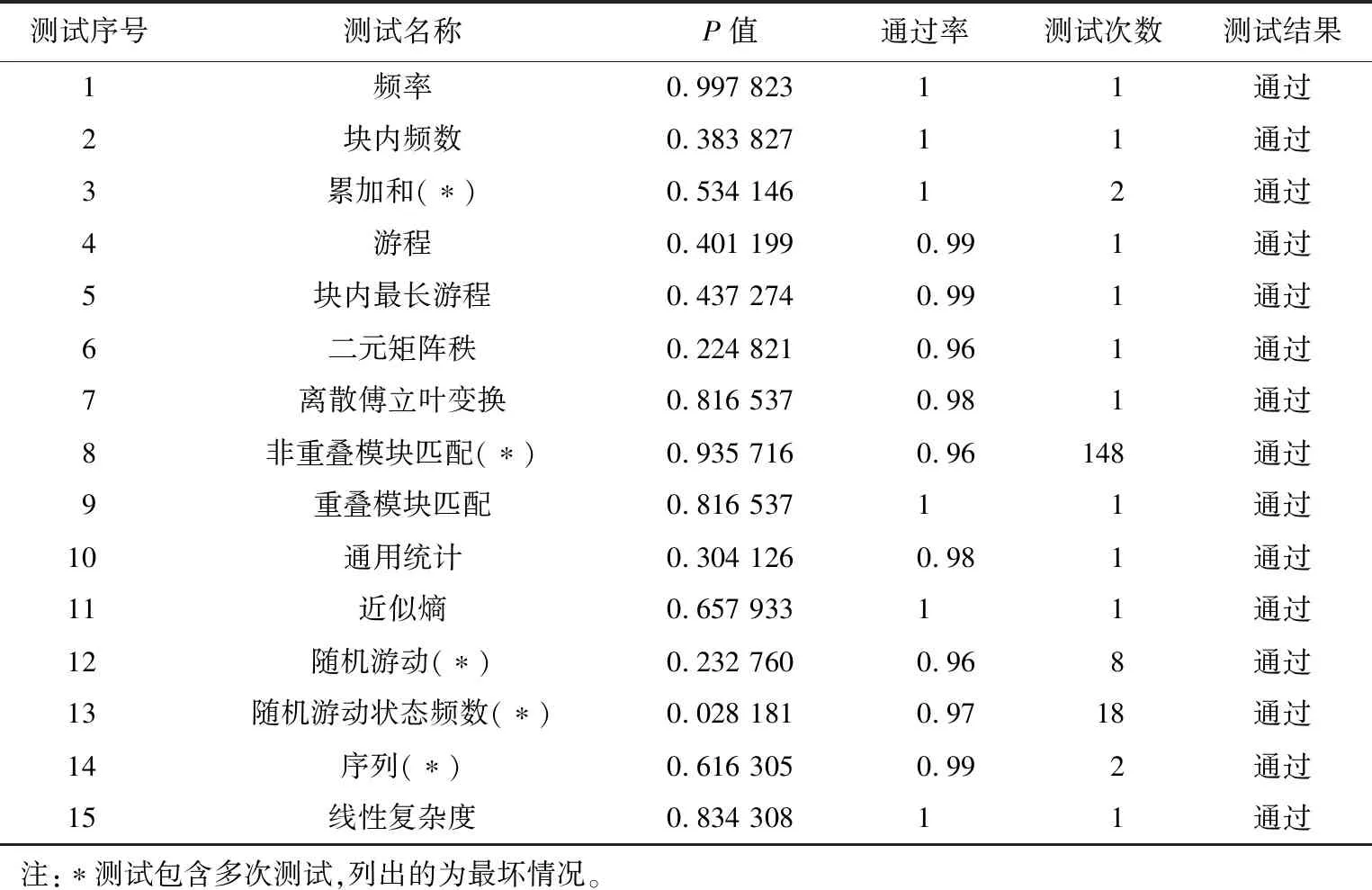
表1 NIST SP800-22测试结果Tab.1 Test results of NIST SP800-22
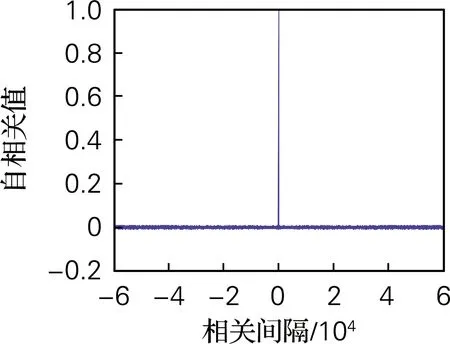
(a) 自相关
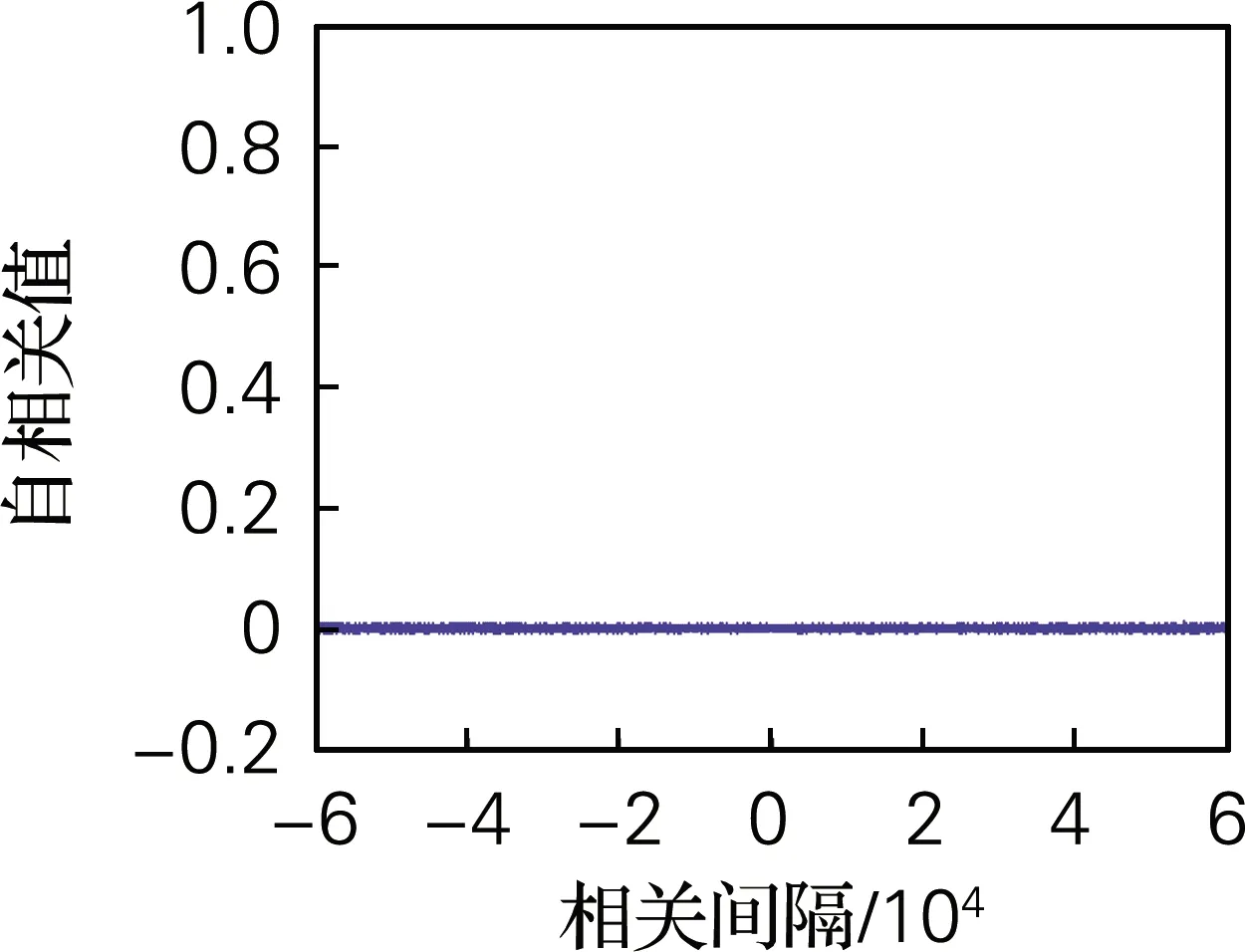
(b) 互相关
图6 相关性分析
Fig.6 Correlation analysis
4 结 论
通过对基于修正版Marotto定理构造的四维离散超混沌映射系统的动力学特性进行分析,确定了系统处于超混沌状态的参数范围,为伪随机序列生成器的实现提供了理论依据。
通过结合重复量化算法设计了伪随机序列生成器,仿真结果表明,该伪随机序列生成器能将该超混沌系统生成的序列量化为超混沌伪随机序列。对量化后的超混沌伪随机序列使用NIST SP800-22随机数检验标准进行测试,测试的结果表明本文所设计的伪随机序列生成器生成的序列具有良好的随机性,并通过与其他文献对比表明,使用高维离散超混沌映射系统设计的伪随机序列生成器,其性能比使用低维混沌伪随机序列生成器的性能更好。
经分析超混沌伪随机序列的自相关性和互相关性,可见此生成器生成的序列具有接近于δ函数的自相关性和接近于0的互相关性。因此,此混沌伪随机序列生成器生成的序列可应用于保密通信等信息安全领域。
