面向CUDA程序的线程放置优化策略研究
2020-04-29谢根栓张伟哲
谢根栓, 张伟哲
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
近年来,基于强大的数据并行处理与浮点计算能力,GPU已广泛应用于工程应用和科学计算领域,并且取得了长足的进步和可观成绩。在GPU程序中,程序员需要设置线程块大小(block size)以明确程序的线程数量。不同的线程块大小会带来不同的线程的并发度。只有通过合理设置线程块大小才能使程序运行的性能达到最好,因此线程块大小是影响程序性能的关键因素。
本文中,使用机器学习完成性能最佳线程块大小的自动设置,可以避免全局遍历方法中多次反复运行程序的高耗时,相较于传统启发式搜索等方法,也避免了搜索结果陷入局部最优的问题。
1 相关工作
目前,CUDA线程块放置优化方法主要有2类。一类是不运行程序、简单地依靠经验完成线程块优化;另一类是基于性能模型驱动的优化。
用第一类方法进行线程块优化的典型代表有Sorensen等人[1]提出的在Fermi架构GPU上对一系列BLAS程序设置线程块大小等参数的方法。
基于性能模型驱动的优化研究成果相对多一些。Tran等人[2]开发了一个评估线程块大小优化效果的调参模型,该模型会提出多个备选的线程块大小,从而避免了大范围穷举线程块大小。但该模型评估标准只是GPU利用率,并且忽略了决定线程块大小更重要的kernel函数的信息。Gupta等人[3]设计了一款名为STAtuner的工具。该工具使用LLVM编译CUDA核函数以从中收集kernel函数的多个静态信息。在此基础上,还使用支持向量机预测性能最佳的线程块修正方向。Connors[4]提出了类似的思路,都是使用机器学习来获得最佳线程规格调整方向,不同之处在于使用动态程序信息而不是静态程序信息。
国内关于CUDA程序线程放置优化方面,郑祯等人[5]设计实现了一套针对GPU程序性能的分析工具。该工具的编程接口采用CUPTI底层接口,在测试环节对部分Benchmark程序做性能瓶颈分析,并分析总结了常见性能瓶颈的原因,同时给出了一些开发高效CUDA应用的建议。
2 模型研究
2.1 整体设计
本文的模型研究基于机器学习的常规设计,主要包括训练数据获取、训练模型、模型评估三个步骤。模型整体设计见图1。
2.2 程序信息采集与处理
2.2.1 采集运行时信息
nvprof是NVIDIA官方提供的一款命令行形式的CUDA程序的性能分析工具,可以收集GPU的硬件计数器信息生成程序的运行时信息。本文参考郑祯等人[5]对CUDA性能信息的提炼汇总,只采集这些信息中最具代表性的一部分。本文获取的metric信息见表1。此外,本文训练数据的标签数据也通过nvprof采集CUDA程序执行时间获得。

图1 基于LLVM对CUDA程序线程分配优化模型的改进
Fig. 1 Improvement of thread allocation optimization model for CUDA program based on LLVM

表1 通过nvprof获得的CUDA函数运行时信息
2.2.2 静态信息替代运行时信息的方法
由于nvprof采集运行时信息会存在耗时过长的问题,研究提出了静态信息替代运行时信息的方法。CUDA程序静态信息对运行时信息的替代详见表2。研究可得阐释分述如下。
(1)浮点计算单元利用率。研究可以用静态信息浮点指令数量Ninstr_float计算得到浮点计算单元利用率。设核函数的执行时间为Tkernel,GPU浮点计算理论峰值为Pmax,则GPU浮点计算单元利用率Ufloat_static可以表示为:
(1)
(2)线程分歧率。在CUDA程序的指令集中,影响线程分歧率的指令包括分支指令、同步指令,因此研究中用静态信息分支指令数量Nbranch、同步指令数量Nsync、指令总数Ninstr等替代nvprof工具的信息branch_efficiency,计算公式为:
(2)
表2 CUDA程序静态信息对运行时信息的替代
Tab. 2 Replacement of runtime information by static information of CUDA program

运行时信息用以替换的静态信息branch_efficiencyNloop、Nbranch、Nsync、Ninstrgst_throughputNinstr_storegld_throughputNinstr_loadflop_dp_efficiencyflop_sp_efficiencyNinstr_float
2.2.3 基于LLVM的CUDA程序信息提取
LLVM项目是一个获得广泛使用的编译工具框架,Pass是LLVM系统的重要组成部分,可以通过分析程序的模块、函数、基本块等信息以提供程序的高级的信息。本文中,使用LLVM完成CUDA程序静态信息的采集。对此可做重点剖析如下。
在进入IR的Module后,分析pass会遍历Module内的全部函数,进入kernel函数内部后,pass会遍历函数的全部基本块与指令,依据与CUDA程序性能指标关联度,pass主要完成对int型数据操作指令、float型数据操作指令、存储交互操作指令、程序分支操作指令、线程同步指令、函数内循环次数的统计。
分析pass的指令信息统计的实现流程如图2所示。

图2 分析pass的指令信息统计的实现
2.2.4 设置标签
本文提出的添加标签算法是针对每个核函数,按照执行时间排序,取执行时间较短的前20%设置标签为1,剩余的信息设置标签为0。添加标签算法的过程设计具体如下。
算法1 设置标签的算法
输入:D为原始训练数据;F为测试集中全体核函数集合
输出:DL为添加标签后的训练数据
过程:
forfiinFdo
Tfi← 提取D中的核函数fi的全部执行时间信息
Dfi← 提取D中的核函数fi的全部信息
依据Tfi对Dfi快速排序:Dfi←QuickSort(Dfi)
排序后的Dfi的前20%标签设置为1:前20%Dfi的DL← 1
剩余Dfi的标签设置为0:剩余Dfi的DL← 0
end for
2.3 模型训练
scikit-learn[6]工具为机器学习提供了良好的支持,本文通过其来建立优化模型。文中对此将给出如下研究论述。
2.3.1 参数组合
在小批量数据集下,支持向量机算法的可调参数包括惩罚系数和核函数参数。其中,惩罚系数表示了模型对误差的宽容度;核函数参数σ决定了数据映射到新的特征空间后的分布。研究中分别对应scikit-learn中的C、gamma。本次实验中SVC算法遍历的参数见表3。

表3 SVC网格搜索的参数
2.3.2 交叉验证
交叉验证(Cross Validation)也称作循环估计,指的是对原始数据分组,取大部分样本做训练集,留取剩余少部分数据做验证集用来评价训练出的模型效果,重复上述过程,直到全部数据都做过验证集。最后,选取这些验证评价的平均值作为最终的评价。
研究使用scikit-learn的网格搜索函数GridSearchCV遍历2.3.1节的参数组合,通过交叉验证确定最佳效果参数。GridSearchCV的参数cv是交叉验证参数,该参数指定了fold数量,本文设置为10。接着,研究通过调用fit函数利用建立好的网格搜索对象训练数据,得到最优的参数组合。
3 实验
3.1 实验条件
本次研究中的运行环境配置见表4。

表4 模型运行环境
全部代码运行在python3.6.5环境。模型训练选用的Benchmark为Rodinia[7]。
3.2 测试分析
在测试分析部分,本文与已有的Connors[4]模型进行了相同训练数据下的训练时间、训练精度对比分析。2个模型运行时间的对比结果如图3所示,2个模型在充足训练集下的训练准确率的对比结果则如图4所示。
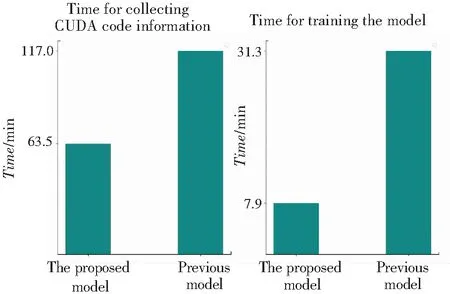
图3 与已有模型的时间对比

图4 与已有模型的训练准确率对比
通过对比2个模型的训练数据收集时间和模型训练时间可以看到,本文的模型相较Connors等人提出的模型只花费了近一半的时间。究其原因则在于:首先,本文模型采集的CUDA程序信息较少,而Connors的模型未对nvprof采集的程序信息做筛选;其次,本文的模型部分信息转为静态信息提取,降低了采集运行时信息的种类。综上分析可知,本文模型中nvprof潜在反复执行CUDA程序的次数减少,这使模型训练时间也随之减少。
由图4可以看到,在相同机器学习算法下,本文的模型基于上述改进,训练准确率获得了提升。究其原因则在于:首先,研究采集筛选后程序信息使模型避免了冗余信息可能产生的噪点和过拟合问题;其次,研究的模型提出了全新的标签设置算法,可以更真实地反映了不同线程配置下的程序运行性能间的差异。
4 结束语
本文提出了一个基于CUDA程序运行时信息与静态信息结合的线程配置优化模型。研究的创新点包括:
(1)运行时信息采集环节中,对采集信息做筛选,只保留了其中与程序性能相关的核心信息。
(2)提出并实现了基于LLVM的静态信息替代运行时信息的方法。
(3)提出了全新的标签设置算法,使模型的标签数据更真实地反映程序性能情况。
基于上述创新,将本文模型与已有研究中的模型在时间、准确率上进行对比分析,结果表明新模型在时间上获得了更大优势,准确率也有更高保证。
