基于BERT-CNN的电商评论情感分析
2020-04-29史振杰董兆伟庞超逸张百灵孙立辉
史振杰, 董兆伟, 庞超逸, 张百灵, 孙立辉
(河北经贸大学 信息技术学院, 石家庄 050061)
0 引 言
随着信息技术的快速发展,网络已经融入到人们生活的方方面面。网络上具有平等、自由、共享、虚拟等特点,近年来,互联网上出现越来越多的网络应用,例如微博,论坛,电子商务等等,其中,电子商务指的是买卖双方在不相见的互联网平台进行交易的商贸活动。电商应用平台的飞速发展改变了社会的生活方式,给人们的生活带来了极大的便利。同时,各电商平台之间的竞争也尤为激烈,为了增强竞争力,各平台不仅保证商品的质量和价格合理外,还要了解消费者对商品和服务的反馈,以便更好地制定相应的营销策略。如今,很多电商平台都涉及了评论系统,消费者在系统中可以自由发表自己的观点与看法[1],表达自己的情感,在这些评价、观点与情感中,包含着许多有价值的信息,这些信息反映了消费者对于商品的主观感受,对于其他消费者挑选符合心意的商品具有极大的参考价值[2],同时,也是商家改进自身营销模式的重要依据。
近年来,随着深度学习的发展以及自然语言领域的使用,越来越多的学者采用深度学习技术来处理海量的文本信息。深度学习可以经过多层次的学习,自动学习到数据的本质特征,能够在预测与分类任务中获得较高的准确率。例如常用的网络有:长短期记忆网络[3]、卷积神经网络[4]、循环神经网络[5]等。
Mikolov等人[6]提出一种使用Skip-gram和CBOW的方式学习词的分布式表示,通过这样的方式可以在一定程度上表示出词语之间的相关性,得到词语在更高维空间的映射。为了弥补RNN网络自身在梯度传递上的缺陷,Hochreiter等人[7]提出了基于循环神经网络的优化形式,长短时记忆网络LSTM,在一定程度上解决了梯度爆炸或者梯度消失的问题。Denil等人[8]提出一种多层次的CNN模型来提取文本中的特征,通过多层次的卷积与池化结构,加强对句子中关键的局部特征的获取,以达到更好的效果。Kalchbrenner等人[9]将静态卷积网与动态卷积网相结合,对于解决不同文本的不同长度具有较好的效果。Zhou等人[10]提出了将CNN与RNN的特点相结合,先对文本用CNN进行分布特征的提取,再用RNN进行序列特征的提取,最后用于分类。Cao等人[11]改变了两种模型顺序,由此提取出来的特征用于文本分析。Yogatama等人[12]采用生成对抗模型,其中一部分模型用于生成数据,另一部分通过预测数据来进行分析。
李然[13]在进行本文情感分析时采用了神经网络语言模型,通过自适应的学习短文本向量,提取更深层次的语义信息,在大规模的商品评论数据集上表明了深度学习的分类性能更好。胡朝举等人[14]提出了一种将CNN与GRU相结合的方法,不仅能采用CNN捕捉句子的局部特征,而且能够较好地获取句子的上下文信息,实验获得了较高的F值。陈葛恒[15]针对GRU网络只能前向学习而不能预测到后面的信息问题,提出了双向的GRU来进行句子前后信息的学习,有效地解决了上下文之间的关联性。冯兴杰等人[16]使用注意力模型与CNN相结合的方法,能够减少人为对于特征的构造,在相关数据集上结果表明,与传统的机器学习方法和卷积神经网络相比有着明显的提升。马思丹等人[17]根据词向量的特点,提出了一种加权Word2Vec的文本分类方法,通过设置文本词语相似度阈值,分为加权的部分与不加权的部分,在此基础上进行分类,实验表明该方法比传统的TF-IDF效果要好。
在以上的研究中,都使用了基于深度学习的方法进行情感分析,这种方法虽然在一定程度上表现优异,但是要进行长时间的训练,而且需要大量的语料用于学习,语料不足时很难达到满意的效果。
综上,针对现有的文本情感分析方法特征提取不充分,难以表达句子的复杂语义,不能关注上下文信息等问题,提出了一种基于BERT-CNN的网络结构,通过BERT结构进行语义的向量化表达,运用卷积网络结构来进一步提取局部特征,最后使用Softmax分类器进行文本的情感分类,在某手机的评论数据集中,相比于其他模型,准确率有一定的提升。
本文的主要工作如下:
(1)利用BERT对评论信息的句子进行向量化表达,充分考虑了句子中每一个词语对其他上下文中词语的影响,以及同一个词语在不同语境中的不同含义表达。
(2)先利用BERT网络结构来处理文本中上下文特征的提取,再对已经提取的特征使用卷积神经网络CNN进行局部语义特征提取,既能同时利用BERT与CNN特征提取的优势,又能很好地解释要处理文本的语义,从而提高文本情感分析的准确率。
1 BERT模型
BERT的出现在自然处理领域带来了很大的提升,之前的模型是从左向右或者是将从左向右和从右向左的训练结合起来,而BERT使用了多层Transformer模型[18],实现了将句子中的每个词的信息都涵盖进词向量中去,实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,其中文本分类中,用到了Transformer中的Encoder。
BERT中的Transformer由6个Encoder-Decoder叠加组成,在结构上是相同的,但是彼此间却不共享权重[19]。注意力机制运算如图1所示。图1即为一层编码器(Encoder)和对应的一层解码器(Decoder),在Encoder中,输入(input)经过Embedding后,要做位置嵌入(positional Encoding),然后是多头注意力机制(multi-head Attention),再经过全连接层[20],每个子层之间都有残差连接。

图1 注意力机制计算图
多头注意力机制就是将一个词的向量切分成h个维度,求Attention的相似度时每个h维度计算,由于每个单词在高维空间表示唯一个向量,每一维空间都可以学到不同的特征,相邻空间所学结果更相似,相较于全体空间放到一起对应更加合理。比如对于vector-size=512的词向量,取h=8,每64个空间做一个Attention,学到的结果更加准确。
自注意力机制中,每个词都可以无视方向与距离,有机会直接和句子中的每个词进行编码。权重的大小代表了两者之间联系的深刻度,一般意义来说,模糊词所连的边都比较深。
位置嵌入能够表示句子的序列信息的顺序,对于模型学习句子的含义有重要的影响。Transformer计算token的位置信息使用了正弦波,类似模拟信号的周期性变化,这样的循环函数在一定程度上能够增加模型的泛化能力。运算公式如下所示:
PE2i(p)=sin(pos/100 0002i/dpos),
PE2i+1(p)=cos(pos/100 0002i/dpos),
(1)
将id为p的位置映射为一个d维的位置向量,这个向量的第i个元素的数值就是Ei(p)。
但BERT直接训练一个position Embedding来保留位置信息,每个位置随机初始化一个向量,加入模型进行训练,能够得到一个包含位置信息的Embedding,最后这个Position Embedding与Word Embedding进行直接拼接。
此外,BERT使用masked language model做到了真正意义上的双向编码,随机屏蔽预料中15%的token,然后将被屏蔽的token位置输出的最终隐层向量输送到分类器,预测被屏蔽的token,其中类似于完形填空,虽然能够看到所有的位置信息,但需要预测的词已经被特殊符号所代替,可以直接进行编码。但是确定屏蔽掉的单词后,并没有直接去掉,而是80%的会被直接替换,10%会被替换为任意单词,10%会保留原始token。这是为了增强模型的鲁棒性,避免出现模型不认识的单词,增强其泛化能力。
2 CNN模型
在传统的神经网络中,把每个神经元都连接到下一层的每个神经元上,这就是全连接,在CNN中,对输入层进行卷积得到输出,这就不是全部连接而成为了局部连接,即输入的局部区域连接到一个神经元上,每一层都用不同的卷积核,再将其组合起来。池化层是卷积神经网络中的一层重要结构,在卷积层之后应用,池化层对其输入进行下采样,最常用的方法就是保留最大信息,一般是经过窗口化的最大池化。
卷积的作用可以认为是发现一种特征,而池化的作用是减少输出维度同时保留显著的信息[21]。在卷积神经网络中,卷积层中的卷积核类似于一个滑动的窗口,如图2所示,在整个输入图像中进行特定步长的滑动,经过卷积运算后,能够得到输入图像的特征图,这个特征图就是卷积层提取出来的局部特征,这个卷积核是参数共享。在整个网络的训练过程中,包含权值的卷积核也会随之更新,直到训练完成。

图2 卷积神经网络结构图
全连接层的作用主要是对特征进行整合,池化层的输出以全连接的形式传递给全连接层,通过分类器得到分类,再将预测的结果与实际的结果进行比较,通过反向传播的方式更新网络参数。
在自然语言处理中,多数任务的输入不再是图片,而是以矩阵表示的句子或文档。矩阵的每一行对应一个token(象征),一般是一个单词或字符,也即每一行代表一个词向量。在图像中,卷积核划过的是图像中的一块区域,在自然语言领域一般用卷积核划过矩阵的一行,即单词。然后卷积核的宽度就是矩阵的宽度,而高度不是固定的,需要进行设置。
3 BERT-CNN模型建立
整个BERT-CNN神经网络模型主要分为BERT层、CNN层和情感分类输出层,整体框架如图3所示。
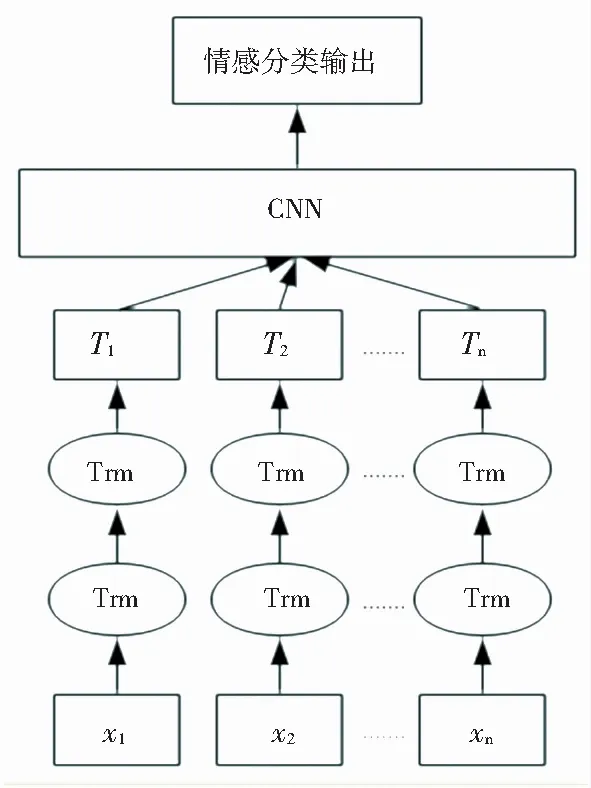
图3 BERT-CNN模型结构图
BERT-CNN神经网络模型的情感分类输出层基本相似,但是词向量输入层有差别,BERT-CNN神经网络模型采用预训练语言模型BERT作为文本信息的表示,而传统神经网络语言模型采用Word2Vec作为文本信息的表示。此外,BERT-CNN将BERT输出的词向量经过卷积神经网络做进一步特征提取,增强了模型的健壮性。CNN层分为卷积与池化两部分:
对BERT层的输出矩阵B={H1,H2,...,Hn}进行卷积操作,假设卷积核长度为m,即每次对m个分词向量进行卷积操作,卷积核滑动的步长一般设为1,对文本矩阵进行上下滑动,则B可以分成{H1:m,H2:m+1,...,Hn-m+1:n},其中,Hi:j表示向量Hi到Hj的所有向量的级联,对于每一个分量执行卷积操作后得到向量C={c1,c2,...,cn-m+1},而ci是对分量Hi:i+m-1执行卷积操作后得到的值,称为一个局部特征映射,计算公式如下所示:
ci=WTHi:i+m-1+b,
(2)
其中,W是卷积核的参数,按照均匀分布随机初始化,并在模型训练过程中不断学习,b是偏置变量。
接着对卷积捕获的文本特征映射向量C={c1,c2,...,cn-m+1}进行池化操作,研究中采用了最大池化方式,公式可表示为:
(3)
上述为1个卷积核经过卷积、池化操作得到的结果,对于q个卷积核得到的结果如下:
(4)
为了提取更好的特征,研究采用3种不同尺寸的卷积核去提取特征,经过池化后,再将不同尺寸的卷积核提取的特征拼接在一起作为输入到分类器中的特征向量。如图4所示。
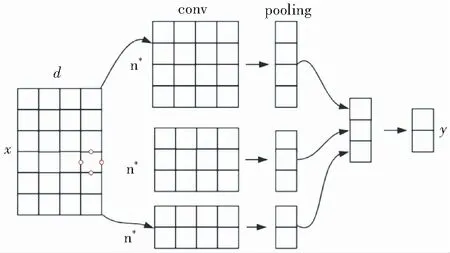
图4 CNN层结构图
卷积操作实质上完成了对文本特征中表示局部重要信息的捕获,池化操作则完成了局部重要特征的提取。此后CNN层的输出向量经过拼接得到最终的向量,输入到情感分类器中进行分类,得到模型对于每条输入数据对应的情感类别。
在前述流程后,研究中将通过平均池化得到的句向量利用全连接层来获取抽象特征。同时,该网络层使用ReLU激活函数,为了增强模型的泛化能力,再增加一层全连接层进行输出,由于本次分类是多标签分类任务,则需要经过分类器进行分类。
在模型中,BERT作为评论文本的编码器,使用BERT语言模型的嵌入功能,将每一条评论编码到各词向量堆叠而成的句子。作为新的特征用作CNN层的输入,为了防止过拟合,在全连接层前面加入一层丢弃率为0.5的dropout层。
4 结果与分析
本文模拟实验环境配置见表1。
本节在京东某手机评论数据集上对比了混合模型BERT-CNN与其他几种模型,不仅进行了模型准确性,稳定性的对比,同时对比了模型训练耗时程度。
采用几种不同的模型进行实验,研究得到的各指标的实验结果见表2,时间对比结果见表3。

表1 实验环境配置表
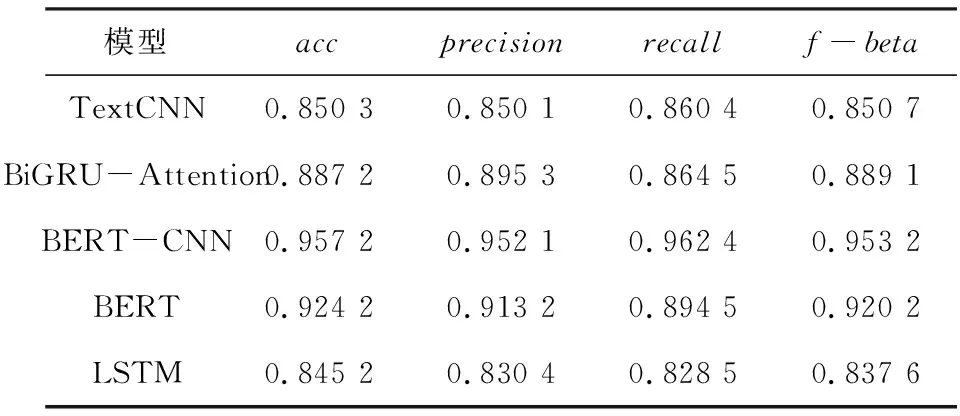
表2 实验结果表

表3 时间表
比较表2中BERT-CNN模型和其他几种常用模型,例如LSTM,BiGRU-Attention。可以看出,相比于这几种常用模型,混合模型BERT-CNN在准确率与F值上都有了明显的提升,这说明了BERT-CNN在该京东手机评论数据集上,情感分类效果比较好,同时,对比单独地使用BERT或者TEXTCNN进行文本分类,也得到了显著提升。
对比表3中BERT-CNN模型和其他模型所用的时间可以看出,除了BERT模型以外,其它模型虽然准率与F值相对较低,但是所用时间相比混合模型BERT-CNN明显少很多,这说明了BERT预训练词向量模型,需要耗费大量的时间进行句子中词向量的表示。BERT-CNN效果较好,但时间花费也很大。
5 结束语
近年来,电子商务发展渐趋火爆,电商评论情感分析已然成为一个研究热点,为了更好地进行研究,本文提出了结合BERT的词向量,与卷积神经网络相结合的BERT-CNN网络模型用于电商评论研究和分析中。该模型先利用BERT进行词向量编码表示文本的语义信息,然后在此基础上使用卷积神经网络对文本特征进行更加深入提取,实现模型对于文本信息语义的深层理解,完成对电商评论的情感分析。使用某手机的评论数据集进行仿真实验,实验结果表明,BERT-CNN模型较大程度地提升了情感分类的性能。
BERT模型使用过程中,参数量较大,训练及加载都会耗费大量时间,所以,研究对BERT模型进行压缩,在模型精度不会受到较大损失条件下降低模型的复杂度这也是后续一项重要的研究工作。
