基于LSTM的地震前兆数据分析算法设计与实现
2020-04-29王圆圆孙可可
王圆圆, 孙可可
(防灾科技学院 应急管理学院, 河北 三河 065201 )
0 引 言
地震前兆现象主要分为宏观现象和微观现象。本文主要分析地震前兆现象中的微观现象,例如逸出气氡、气压等。地震台站检测到的地震前兆数据在不间断且不规律的波动中会蕴藏着动态演化和信号变化[1]。地震前兆数据具有在结构上的复杂性、前兆观测方法的不固定性、数据位精度的可变性、数据采样率的不一致性、数据源的多样性等特点。地震前兆数据变化规律有长期、中期、短期变化[2]。通常用逐级降采样率取年、季度、月、周、日、小时、分钟、秒的平均值进行数据分析。正是由于这些大量高采样率的观测数值和与其协作的分析人员逐天逐台的采集和处理模式,传统的处理模式和计算方法己经很难在海量的观测数据中迅速自动定位精确位置,这也制约了人类研究地震前兆数据的进展[3]。未来,在保证数据完整性的前提下,面对海量的地震前兆数据,利用机器学习进行地震前兆数据分析是一个至关重要的研究方向[4]。如果人类通过数据分析掌握了地震前兆数据变化规律,会对我们的研究带来莫大的帮助[5]。
1 LSTM原理
长短期记忆(long short-term memory,LSTM)模型由不同的记忆单元组成,例如单元状态(cell state)和通过“门”(gate),其中通过“门”又分为3类[6],分别是:遗忘门(forget gate)、输入门(input gate)、输出门(output gate)[7]。LSTM的通过“门”(gate)发挥增加或删除信息的功能,对应着模型中的记忆或遗忘的功能。“门”是一种将抽象具体化的结构,进行信息过滤,且由一个点乘和一个sigmoid函数构成。sigmoid函数的输出值域区间为[0,1],1代表全部通过,0表示直接全部丢掉。3个这样的门组成一个LSTM单元。LSTM记忆单元总图如图1所示。对此拟做研究分述如下。
(1)遗忘门。遗忘门的sigmoid函数的输入值是上一单元的输出ht-1和本单元的输入xt数据,再为ct-1中的每一项产生一个在[0,1]内的值。通过这种方式来控制上一个单元状态被遗忘的程度[8]。主要函数如下:

图1 LSTM记忆单元总图
ft=σ(Wf*[ht-1,xt]+bf),
(1)

(2)
it=σ(Wi·[ht-1,xt+bi]),
(3)
(4)
(3)输出门。输出门用来控制当前的单元状态有多少被过滤掉。先将单元状态激活,输出门为其中每一项产生一个在[0,1]内的值,控制单元状态被过滤的程度[10]。主要公式如下:
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot*tanh(Ct).
(6)
(4)单元状态(cell state)。这是LSTM的关键,即用图1上半部分的水平直线来表示,可以将数据从上一个单元传输到下一个单元,就象一条数据传送带一样贯穿在整个结构中,在传输数据的同时只会有很少的线性相互作用[11]。单元状态局部图如图2所示。
2 实验数据预处理
由于数据是精确到秒的检测值,据统计分析可知,一个月的分钟数据会达到三十万。而在庞大的数据量中,却会因为检测仪器故障、自然环境、人为因素等作用导致监测结果中存在缺失值。为了保证提取数据的完整性和预测结果的准确性,就要对缺失值进行处理。在本次研究中,则将缺失值补齐,再进行数据分析。对此可做分析论述如下。

图2 LSTM单元状态图
2.1 缺失值处理
缺失值处理方法有3种,分别是:数据补差、删除记录和不处理。本次研究中,采用补差记录的方法。原始数据中的缺失数据,采用补差法,用其周围的数据进行补差。
2.2 数据规范化
由于个别数据会影响正常数据,不进行数据规范化会影响数据分析结果的准确性。本文采用Z-score方法进行数据规范化,因为Z-score的数据分布情况是正态分布(N(0,1)),并且正态分布又被称为零-均值规范化。Z-score公式可表示为:
(7)
其中,x是原始数据,z是规范后的数据[12]。
研究可知,mu是均值,signma是标准差,Z-score的分布如图3所示。
3 仿真实验
3.1 不同降采样方法对数据分析的影响
本实验中取2005~2009年山西省临汾地震观测站第三个测项的气压值,全球精确坐标度为(36.073*N,111.505*E)、海拔为443.31 m的数据。和2008~2013年地震研究所测点为白浮的逸出气氡值,精确位置度为(40.184*N,116.234*E)、海拔为45 m的数据。
3.2 气压值的不同降采样方法
分析不同的降采样方法对气压值数据拟合结果的影响。根据4种最大值、最小值、均值、中位数不同的降采样方法得出的采样率为3天时的气压值的数据拟合结果图和误差结果图,详见图4~图7。
分析图4~图7可知,当降采样方法为最大值时,RMSE=160.956 3、最小值时,RMSE=224.664 1、平均值时,RMSE=9.522、中值时,RMSE=12.390 9。通过比较4种降采样的数据拟合结果图和误差值RMSE,选出误差最小的情况为平均值法。
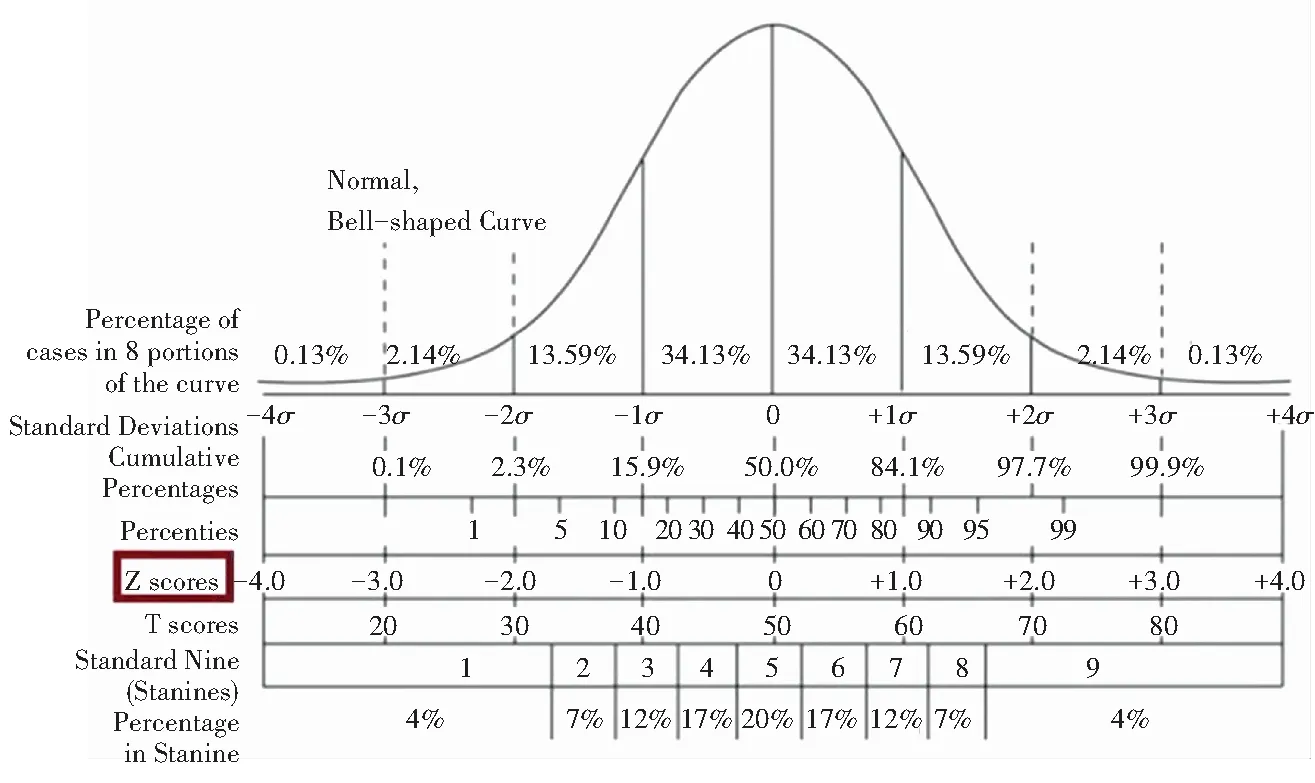
图3 Z-scores分布图

图4 MAX 气压数据拟合图

图5 MIN 气压数据拟合图

图6 MEAN 气压数据拟合图

图7 MEDIAN 气压数据拟合图
4 结束语
综前所述可知,在数据分析过程中,首先对数据进行预处理。预处理分为两步,分别是:缺失值处理,采用补差法;降采样处理,有最大值、最小值、平均值、中位数四种方法。然后,给出了具体的实验步骤,即:选出误差值最小的降采样方法,并用不同的采样率运行,再选出误差最小和数据拟合最优的情况。最后,得出数据预测结果。经过上述的实验步骤得出如下结论:2005~2009年山西省临汾地震观测站,全球精确坐标度为(36.073*N,111.505*E)、海拔为443.31 m的最优情况是采用平均值降采样方法,采样率为3天的情况下得到的误差值最小,数据拟合结果最优。
