基于python的汽车运行状态参数对油耗影响的聚类
2020-04-21马荣影储江伟艾曦锋李宏刚
马荣影,储江伟,艾曦锋,李宏刚,韩 锐
(东北林业大学 交通学院,黑龙江 哈尔滨 150040)
在不断开发应用先进的汽车节能技术的同时,深入研究分析汽车驾驶行为对汽车运行能耗的影响,改善不良驾驶习惯,是提高燃油利用率降低油耗的行之有效的方法。针对汽车驾驶行为对运行燃料消耗影响的研究,目前已开展的主要工作有:分析影响油耗的主要因素,提出减少油耗的措施[1];根据汽车实际运行工况建立数据库,构建试验工况,分析汽车的燃油经济性[2];通过分析各工况的时间特征参数、速度特征参数和加速度特征参数对燃油消耗的影响[3];利用k-均值聚类方法对行驶工况的构建方法进行研究[4,10-11];以曼谷某试验车辆在标准底盘测功机上行驶的实测数据为基础,研究不同驾驶周期对汽油客车尾气排放和油耗率的影响[5];依托自然驾驶设备设计自然驾驶实验,研究测试者行驶工况与车辆能耗间的作用关系,发现不同运行工况会导致显著的油耗差异,测试者频繁地加减速会增大油耗水平[6];以合肥市典型道路为研究对象,利用粒子群优化的模糊 C 均值聚类方法对运动学片段分类,建立基于运动学片段的工况构建模型[7];对典型道路上采集的百公里燃油消耗和行驶工况数据进行划分,获得大量行驶片段,采用主成分分析和神经网络相结合的燃油消耗预测模型[8];针对采集的不同驾驶员所驾驶的商用车和乘用车的行驶数据,基于 K-means 聚类,将驾驶风格聚为 3 类具有较好的分类效果[9]。
上述研究主要是基于车辆行驶工况对车辆油耗的影响进行分析,本文则不仅仅运用车辆的行驶工况数据且基于发动机工作状态参数数据对车辆运行油耗进行聚类分析。定义车辆从行车开始至行车结束为一个行程片段。利用同一个驾驶员驾驶同一辆汽车采集的89个行程片段,近20万条的车辆运行状态参数数据,基于每个行程的平均油耗,使用可代表每个行程的运行特征参数数据,将行程片段进行聚类,进而找出汽车运行状态参数对油耗的影响。
1 数据样本属性描述
1.1 数据样本采集方法
本文研究所用数据样本是通过OBD检测仪获取的车辆运行的89个行程片段共190 173条数据集,平均采样间隔为1.1 s;采集的发动机工作状态参数和车辆行驶特征参数有:怠速时间(TI)、节气门位置(TP)、发动机转速(ne)、热车时间(TH)、车速(v)、加速度(a)与平均油耗(FA)等。
1.2 数据样本属性定义
将车辆行驶特征参数处理成可代表每个行程状态属性的数据,即怠速比例(IR)、匀速比例(CR)、加速比例(AR)、减速比例(RR)、平均速度(vA)、平均转速(NA)、热车时间(TH)、平均节气门开度变化率(PA)、平均节气门开度(TA)和平均油耗(FA),数据样本的行程状态属性见表1。

表1 数据样本的行程状态属性
2 基于K-means算法的聚类数确定
2.1 聚类数的确定方法
因每个行程片段的类别属性未知,所以使用聚类,即在没有给定划分类别情况下的分类方法。本文中使用的聚类算法是基于Python的机器学习函数库(Scikit-learn)中的K-means算法。K-means算法实现简单、计算速度快、原理易于理解、具有理想的聚类效果。该算法的基本思想是以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最理想的聚类效果。
聚类首先要确定的是聚类数K,其选取应以簇内的稠密程度和簇间的离散程度为依据,并以此来评估聚类效果。本文采取聚类评价指标是肘部法。
2.2 肘部法
K值的确定,通常是需要根据具体的问题由人工进行选择,为了确定最优聚类数K,使用“肘部法”。如图1所示,使用数据点与聚类质心的平均距离作为K值的度量,增加聚类数量总是会减少聚类点的距离,根据距离函数与K值的变化曲线,再选择变化率急剧下降的“肘点”,即可用来确定理论的最优K值[12]。因此,聚类效果可采用所有样本的聚类误差SSE来表达:
(1)
式中:Ci为第i个簇;P为Ci中的样本点;mi为Ci的质心(Ci中所有样本的均值)。
随着聚类数K的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。当K小于真实聚类数时,由于K的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当K到达真实聚类数时,再增加K所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着K值的继续增大而趋于平缓,也就是说SSE和K的关系图是一个手肘的形状,而这个肘部对应的K值就是数据的真实聚类数。
使用plt.plot()函数绘出K值与其相对应的SSE值,如图1所示。从图1中可看出K取值为2时,聚类效果最优。
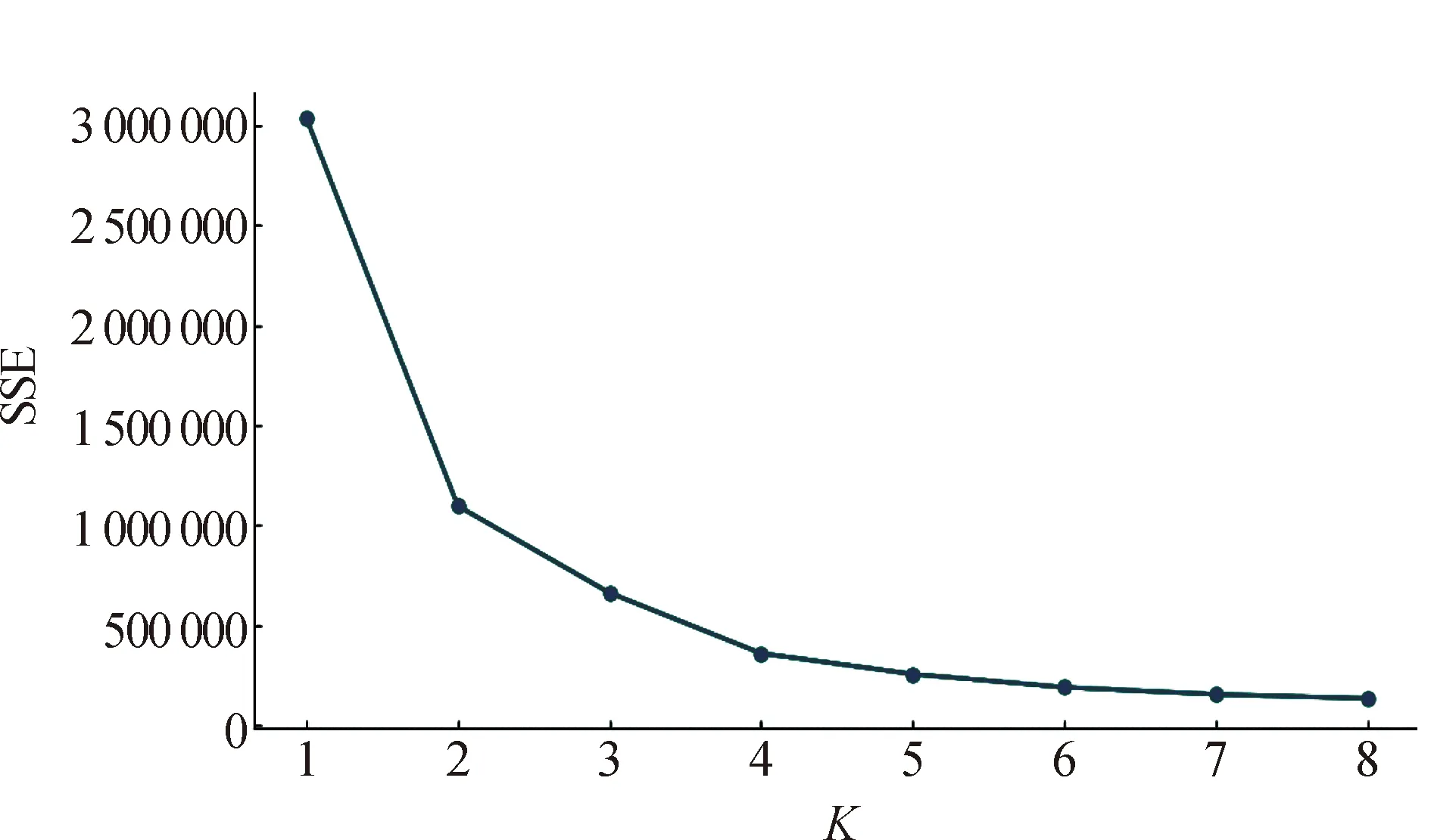
图1 基于肘部法K值的确定
3 基于汽车运行工况及发动机工作状态的聚类
3.1 汽车运行工况的聚类分析
调用Python语言平台使用K-means算法,基于手肘法可知,设置聚类数n_clusters=2,设置n_init=10,10个不同的初始化质心即运行算法的次数,最大迭代次数max_iter设置为300,algorithm设置为传统的K-means 算法“full”。将车辆运行状态参数中的汽车运行工况与其相对应的平均油耗进行聚类。聚类结果见表2。
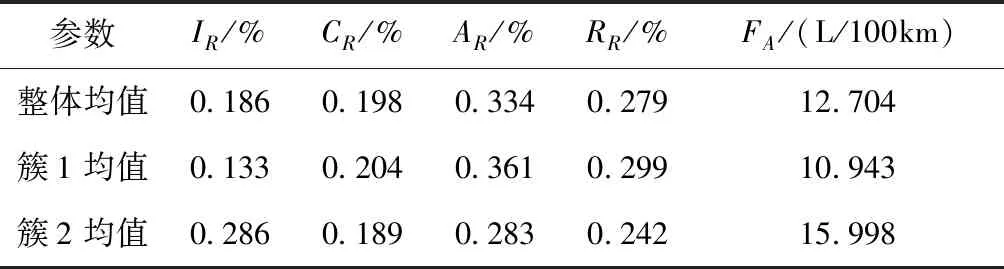
表2 基于工况聚类行驶片段的结果
由表2可看出,在簇1中油耗均值较整体均值低13.86%,在簇2中油耗均值相对总体油耗均值增加了25.93%,在簇2 中怠速比例占总工况比例的28.6%,相比簇1中增加了53.8%,可说明在簇2中所采集的数据是车辆可能处于交通状况不顺畅的路段,在整个行程中28.6%的时间车辆处于怠速工况下。
3.2 发动机工作状态的聚类分析
将车辆运行状态参数中的发动机工作状态参数与其相对应的平均油耗进行聚类,其聚类参数的设置与汽车运行工况一组聚类中相同。得到表3的聚类结果。
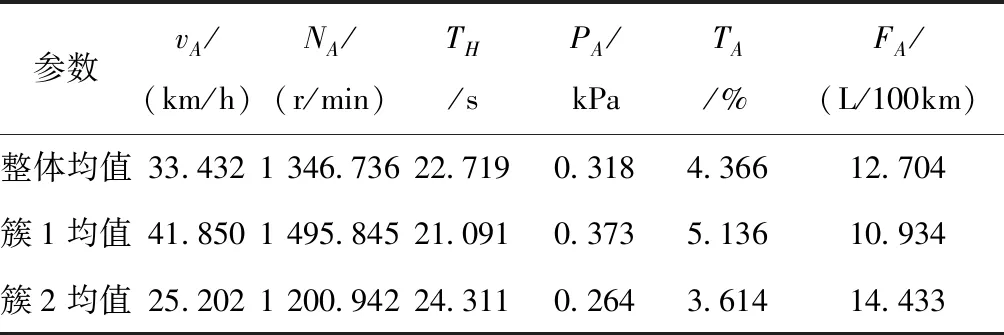
表3 基于发动机工作状态参数聚类行驶片段的结果
由表3可看出,在簇1中油耗均值较整体油耗均值低13.93%,在簇2中油耗均值较整体油耗均值增加了13.61%。在簇2中的平均速度相比整体的平均速度减少了24.62%,平均转速相比整体的平均转速降低了10.83%。
4 结 论
本文基于Python编程语言平台的K-means算法对含有车辆运行状态参数数据的车辆运行片段进行聚类分析,找出影响油耗的汽车运行工况和发动机工作状态参数,得到以下结论:
1)将车辆运行工况与其对应的油耗数据进行聚类时,在平均油耗值高的簇中,怠速比例较大,匀速工况所占比例较小,即车辆处于匀速状态下行驶比例较少,车辆处于频繁的加减速行驶,使一部分能量转化为加速阻力和或制动时的热能消失了。
2)在发动机工作状态参数与其对应的油耗一组聚类中,油耗高的簇中主要是由于平均车速较低时,平均速度越小,相应的车辆发动机处于低负荷率运行状态,导致燃油消耗上升。
