基于卷积神经网络的隧道掌子面图像质量评价方法研究
2020-04-11鲜晴羽仇文革王泓颖许炜萍孙克国
鲜晴羽,仇文革,王泓颖,许炜萍,孙克国
基于卷积神经网络的隧道掌子面图像质量评价方法研究
鲜晴羽,仇文革,王泓颖,许炜萍,孙克国
(西南交通大学 交通隧道工程教育部重点实验室,四川 成都 610000)
鉴于隧道掌子面图像的多样性和复杂性,提出一种基于深度卷积神经网络(Convolutional Neural Network,CNN)的图像质量评价方法,以筛选出满足工程需求的掌子面图像。基于多条隧道创建掌子面图像数据集,采用Keras深度学习框架,应用多种主流的CNN进行对比试验,并结合传统的图像评价指标,分别从清晰度、分类和相似度3个方面对掌子面图像质量进行评价。其中基于DenseNet169的多分类模型可达到88.7%的准确率。研究结果表明:跟传统的图像处理技术相比,深度学习方法在隧道掌子面图像识别上具有精度高、效率高的显著优势。该方法可为实现隧道掌子面的自动素描提供技术支持,具有良好的工程应用前景。
隧道;图像质量评价;卷积神经网络;掌子面;深度学习

隧道建设受控于工程地质条件,准确地掌握掌子面地质条件对安全、快速的隧道建设至关重要。掌子面是工程地质条件最准确和直观的反映,地质工程师须进行实时、快速的地质素描。基于获取的掌子面节理信息、岩体完整程度和地下水发育状态等,结合相关规范进行地质编录、围岩分级,从而指导支护选型和实现信息化施工。但人工地质素描存在强度大、效率低、危险系数高、数据共享率低等问题。在此背景下,掌子面自动素描技术应运而生:通过对隧道掌子面照相,采用图像处理技术,自动提取掌子面节理等信息,据此定量计算岩体完整程度,以便围岩分级。该技术有益于降低地质工程师的工作强度、保障人身安全,大幅推动隧道信息化和智能化施工进程。获取质量合格的掌子面图像是掌子面自动素描技术的基本前提。然而受施工环境、现场设备和技术人员拍照技术水平的限制,拍摄的掌子面图像时常“不合格”,出现诸如模糊、光线太暗、明暗不均、有遮挡、没有拍全等情况。同一个掌子面的多张图像质量往往参差不齐,此时须甄别出合格的图像,并进行实时反馈,筛选出真实反映当前掌子面情况的图像。隧道掌子面图像具有多样性和复杂性的特点,传统处理技术在图像质量判别上的表现差强人意。近年来,深度学习的快速发展给计算机视觉领域提供了一条全新的思路:采用深度学习技术进行图像识别,从而评价图像质量的好坏,弥补了传统技术的不足,使掌子面自动素描成为可能。深度学习在计算机视觉、语音识别和自然语言处理等方面已取得重大突破。卷积神经网络是一种常见的深度学习架构,广泛应用于图像分类、检测和分割等方面。对于图像分类问题,合理提取图像特征是决定分类正确与否的关键。传统的图像处理技术通常是采用人为设计手工提取图像特征,准确率和效率均较为低下。卷积神经网络可以从训练数据中学习到更高层次、更加抽象的特征,在图像分类中表现超强,远胜传统方法。层出不穷的CNN模型不断刷新记录,也展示着该领域的研究热度,具有代表性的如AlexNet[1],VGG[2],ResNet[3],Xception[4]和DenseNet[5]等。图像质量评价分为有参考和无参考2种模式,本文属于后者。在无参考图像质量评价中,图像的清晰度是衡量图像质量优劣的重要指标。徐贵力等[6]提出了一种基于图像边缘灰度变化率的算法用以评价图像的清晰度。李郁峰等[7]提出了灰度方差乘积法,该方法计算性能较好,但其灵敏度在焦点附近不高。Horita 等[8]在WANG等[9]的研究基础上针对JPEG压缩图片定义了全新的质量指标。李祚林等[10]基于面向无参考图像质量评价,介绍了多种具有代表性的清晰度评价算法,并将对它们各种性能进行了对比和分析。图像相似度算法的关键在于提取具有高稳定性、高匹配度的局部特征。传统算法中,尺度不变特征(SIFT)算法[11]由加拿大英属哥伦比亚大学的David Lowe教授于1999年首次提出并于2004年总结完善,常应用于特征提取和匹配算法。吴伟交[12]基于SIFT特征点进行了图像匹配试验,取得了较好的结果。图像哈希算法[13]也称为图像感知哈希或鲁棒哈希,在图像认证和识别领域应用广泛。刘兆庆等[14]则提出了一种基于SIFT的图像哈希算法。近年来随着深度学习技术的发展,基于CNN的相似度算法在人脸识别等方面引起诸多研究者的关注[15−17]。CNN在图像识别领域应用广泛,但是在特定场景下的研究尚为欠缺,隧道掌子面处的环境复杂,尤以光线差、空气污浊为代表。本文针对隧道掌子面图像,对当下几种主流的CNN网络模型展开了对比研究,以选取合适的图像分类模型,并结合清晰度和相似度算法,提出了一种基于卷积神经网络的掌子面图像质量评价方法,从而为掌子面的自动素描提供技术支持。
1 掌子面图像质量评价算法
1.1 总体思路
图像质量评价方法依次包括清晰度判定、图像分类和相似度判定3个方面。首先对掌子面图像进行清晰度判定,再将筛选出来的清晰图像进行分类,最后通过相似度判别降低重复率。其中,清晰度判定是基础,图像分类是核心,相似度判别是进一步保障。具体算法和流程如图1所示。
1.2 图像清晰度算法
对于无参考模式的隧道掌子面图像,通过多种清晰度算法的对比分析,从而确定科学的清晰度算法。基于 Python实现Brenner梯度函数、Tenengrad梯度函数和Laplacian梯度函数等6种算法。

图1 隧道掌子面图像质量评价算法
对于二分类问题(本文指掌子面图像清晰或模糊),根据混淆矩阵(Confusion Matrix),分类器预测结果分为4种情况:真正例(TP)、假正例(FP)、真反例(TN)及假反例(FN)。准确率(Accuracy)是指分类正确的样本个数占总样本个数的比例,表达式如下:

查准率(Precision)是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例,表达式如下:
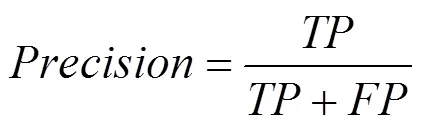
查全率(Recall)是指分类正确的正样本个数占真正的正样本个数的比例,表达式如下:

1值是查准率和召回率的调和平均值,表达式如下:
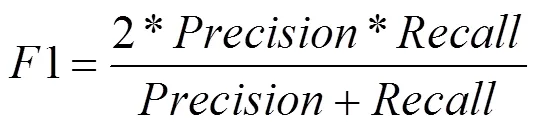
准确率是分类中最简单和直观的评价指标,但当不同类别下的样本比例十分不均衡时,占比大的那类易主导准确率。P-R曲线刻画的是查准率和查全率之间的关系,对比不同分类器即6种算法所对应的P-R曲线,选择性能较优的那一个。再通过计算查准率和查全率的调和平均1值寻找该分类器较优的阈值。
1.3 图像分类算法
1.3.1 隧道掌子面数据集的建立
通过采集多条隧道不同里程和不同地质条件下的掌子面照片,经过人工清洗和标注,生成一个符合深度学习多分类模型训练的数据集。考虑到施工现场诸多干扰因素(人、机、光线等)和拍摄条件限制,结合拍摄呈现出来内容和特征,掌子面图像可分和不合格2类。其中,合格细分为3类:明显轮廓线、模糊轮廓线和台阶;不合格细分为7类:局部带拱、局部不带拱、有人/人影遮挡、有机械/机影遮挡、有岩渣遮挡、光线不好和有集中光源。每种分类对应的标签及备注见表1。建立的数据集包含 4 014 张图像,其中3 607 张作为训练集,407张作为验证集,划分比例为9:1,具体的数据集分布见表2。10类掌子面图像的典型代表如图2所示。

表1 数据标注
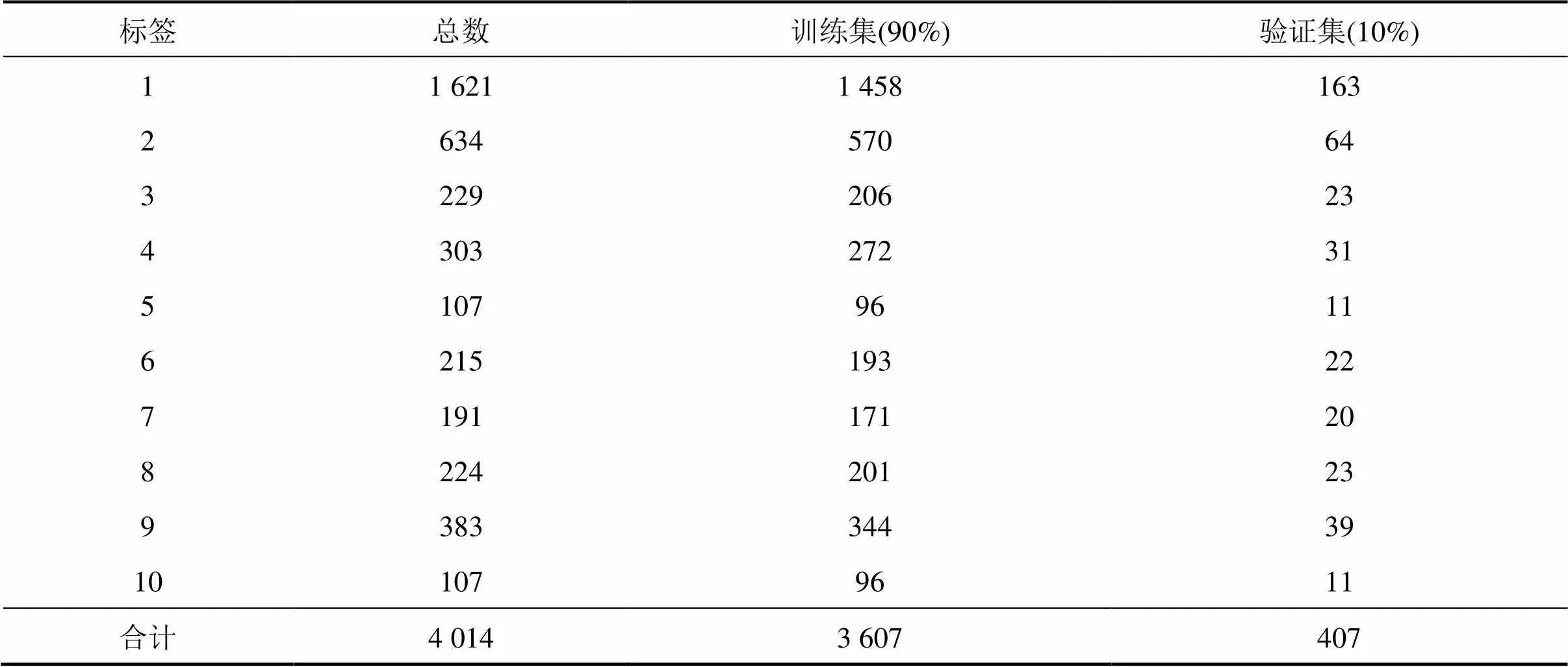
表2 数据集分布
1.3.2 网络结构
作为深度学习的代表算法之一,CNN是一类包含卷积结构的深度前馈神经网络,通常由输入层、隐含层和输出层3部分组成。

图2 1~10类掌子面图像
1) 输入层是模型的入口,在计算机视觉领域,通常一个样本对应一个三维数据,即平面上的二维像素点(0~255)和RGB三通道。
2) 隐含层包含卷积层、池化层及全连接层,其中,卷积层和池化层是CNN特有结构, 基本顺序一般为:输入−卷积层−池化层−全连接层−输出。卷积层中常用的非线性激活函数有:Sigmoid函数、双曲正切函数、ReLu函数及其变体Leaky ReLu函数等。其中,ReLu函数具有收敛速度快、梯度求解简单等特点,在CNN中应用广泛,表达式如下:
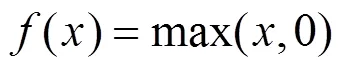
3) CNN输出层的结构和工作原理与传统的前馈神经网络中相同,其上一层通常为全连接层,这里便不再赘述。对于图像多分类问题,输出层一般采用归一化指数函数(Softmax Function)作为分类器输出分类结果,表达式如下:
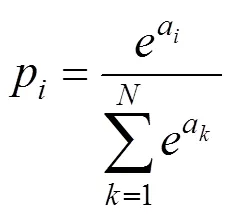

Softmax将多个神经元的输出,映射到(0,1)区间内,可理解为概率值,所有概率值之和为1,最大概率值对应的分类即为正解,从而实现多分类。Softmax层的交叉熵损失函数表达式如下:

式中:y表示该样本对应第类的真值。
将10类图像和对应标签作为输入数据对网络进行训练,采用梯度下降法不断优化损失函数,表达式如下:

式中:θ表示网络中的权重参数;()为待优化的损失函数。
1.3.3 模型训练与测试
使用Keras深度学习框架进行模型的训练与测试,模型训练采用基于ImageNet数据集的预训练模型进行迁移学习。初始学习率设置为 0.001,并使用学习率衰减策略,即每一轮进行一次衰减,衰减率为0.8。图片批数量为4,训练100次全数据,图片进入网络前统一缩放至 299×299 像素大小。
模型训练对输入图像应用了多种预处理方案:旋转、平移、错切变换、放大、改变颜色和水平翻转。通过这些图像预处理手段,在一定程度上实现了数据集的扩充,能更好地提升模型的准确率。测试时,输入新图像,利用训练完成的模型可直接给出图像分类结果。分类模型框架如图3所示。
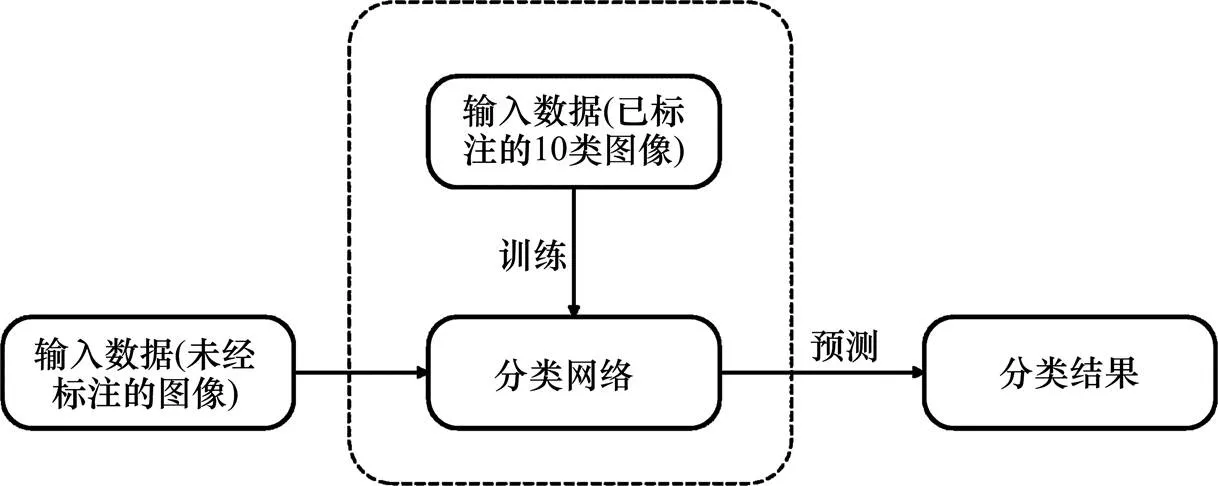
图3 分类模型框架
DenseNet网络借鉴ResNet网络中“抄近路”思想,在不同层之间建立了全新的连接关系(通道上的叠加),如图4所示。
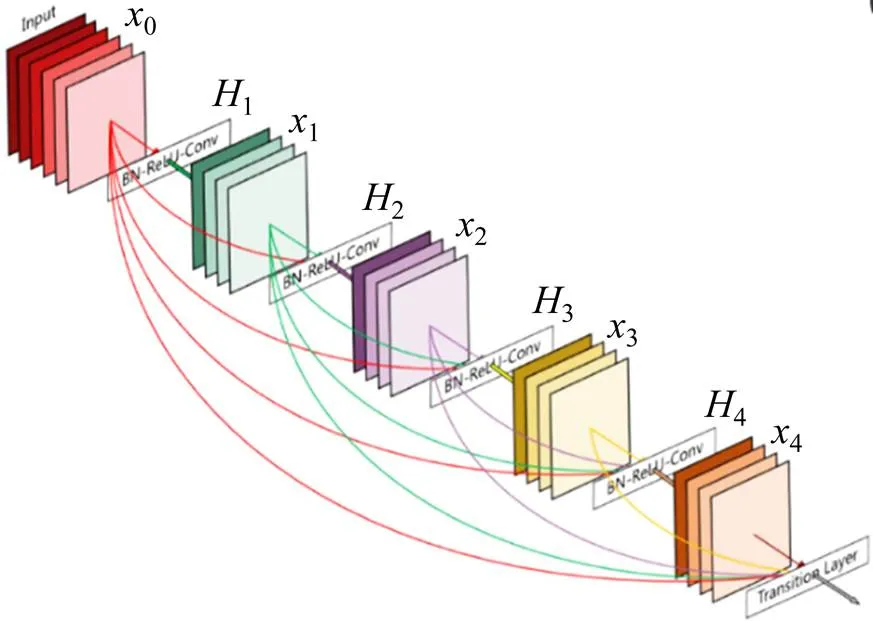
图4 Dense Block结构示意图
将DenseNet169,Xception,ResNet50以及VGG16模型分别应用于掌子面图像分类中,基于Keras(用Python 编写的高级神经网络API,以 TensorFlow或 Theano 作为后端运行)实现,模型训练工作在GPU(1050 Ti)上完成。
1.3.4 可视化分析
深度学习因其内部算法不可见被人们称为“黑盒子”,但是CNN能够实现可视化。ZFNet[18]为CNN可视化的开山之作,其通过对AlexNet进行可视化,并根据可视化结果进行优化研发而成。利用反卷积实现可视化,可深入了解识别图像的过程:CNN是从底层到高层,从抽象到具体来学习特征的,同时该可视化为我们改进网络结构提供了可能。
可视化主要有4种模式:1) 卷积核输出的可视化;2) 卷积核的可视化;3) 类激活图可视化; 4) 特征可视化。本文采用第3种可视化模式,通过热度图,了解对图像分类起关键作用的具体部位,同时可以定位图像中物体的具体位置,以对分类结果进行辅助验证。
1.4 图像相似度算法
将第2步分类中训练好的CNN模型作为特征提取器以获取图像特征,生成唯一特征向量,将待判别图像与数据库里既有图像进行对比,根据特征向量计算相似度,选择合适阈值,满足阈值要求的图片即为相似图片。常用的相似度指标有:余弦相似度、欧式距离和汉明距离等。在文本、图像和视频等领域,研究对象的特征维度往往很高,余弦相似度在高维情况下仍然保持:相同时为1,正交时为0,相反时为−1,这体现了方向上的相似性。受拍摄角度、距离、光线等的影响,同一个掌子面拍摄的照片可能在亮度、尺寸、长宽比等方面存在波动,计算图像特征在方向上的差异相较于计算数值上的差异更能反映真实情况,故这里采用余弦相似度作为相似度指标,表达式如下:


其中:A,B分别代表特征向量,的各分量。
给出的相似性范围是从−1到1,−1意味着2个向量的方向截然相反,1表示它们的方向完全相同的,0通常表示它们是相对独立的,而在−1,0或0,1之间的值则表示不同程度的相似性或相异性。本文研究的相似度判别是指:将新输入的掌子面图片和数据库里既有的图像进行对比,若判定相似,则说明该掌子面的图像已存在从而驳回,否则,则将其视为新的掌子面图像而接收。
2 试验结果与分析
2.1 图像清晰度试验
经过大量试验,Laplacian算法的计算速度、区分度以及在P-R曲线上的表现,都较其他算法有明显优势,且与人眼判定基本相符。其梯度函数采用Laplacian算子提取梯度值,因此基于Laplacian梯度函数的图像清晰度可定义如下:

式中:是给定的边缘检测阈值;(,)是像素点(,)处Laplacian算子的卷积。
这里展示3组测试数据在6种清晰度算法下各自的得分。为方便对比,每组中的4张图像均采集于同一或相邻掌子面,它们处于不同的清晰级别,且根据人眼判定从模糊到清晰依次排列,以第一组为例,清晰度排序:1−1<1−2<1−3<1−4,其它组同理,具体如表3所示。图5展示了第2组测试图像。分析数据得出,6种算法对每组图像的评分和人眼判定顺序基本一致,评分越高,图像越清晰。

表3 清晰度评分

(a) 2-1模糊(6.0);(b) 2-2模糊(15.0);(c) 2-3模糊(19.0);(d) 2-4清晰(21.1)
结合相关文献,Laplacian算法的初始化阈值为10,上限为30,以1为步长递增,试验结果表明,当阈值取21时,1值可取到最大,此时准确率也达到98%,故设定阈值为21。得分小于21,则判定模糊,大于21,则判定清晰。实际运用中,大部分图像在清晰度的表现上基本合格,此阶段过滤掉的图像较少,但此步骤仍然不可或缺。
2.2 图像分类试验
构建的模型中最后1层使用的是Softmax分类器,预测时,对提取的深层卷积特征进行分类,输出为每一类的概率值(见式(6)),取概率最大值为预测结果,和真实标签比较,统计结果得到在验证集上的准确率.分别训练了4个模型(DenseNet169,Xception,ResNet50和VGG16),经过大量的调参训练,结果如表4所示,保存的模型为训练过程中验证集损失最小时的模型,准确率即为此时该模型在验证集上的准确率。以DenseNet169为例,图6展示了DenseNet169模型在100轮的训练过程中准确率(见式(1))和损失函数(见式(7))的变化曲线。

表4 不同模型的训练结果

(a) 模型准确率;(b) 模型损失量
综合考虑模型的准确率和在GPU上的实测时间,选定DenseNet169模型作为掌子面图像分类网络。部分预测结果如图7所示。
图中展示了概率前3的预测结果及其对应的概率值,结果基本和人眼判定相符。实际上,分类正误取决于数据集的“好坏”,数据集越大、标注越客观、分布越均衡,越易得到好的训练结果。

图7 DenseNet169部分预测结果

(a) 原图;(b) 热度图;(c) 叠加图
以DenseNet169为例,从测试集中选取4张掌子面图像进行基于Keras的CNN类激活图可视化,将热度图叠加到原图像,获得对图像分类起到关键作用的部分,即热度图中的高亮部分,与实际情况相符,也验证了本文方法的正确性。如图8所示。
2.3 图像相似度试验
由于该阶段样本数量较少,试验中采用了K折交叉验证(=10)以得到可靠稳定的模型,相似度阈值初始化为0.800,上限为0.999,以0.001为步长递增,分别计算10次试验中准确率取得最大值时对应的阈值,再将10次结果求平均,得到最终的阈值,根据试验结果设定阈值为0.955。
通过清晰度判定和图像分类后,系统可筛选出基本合格的掌子面图像。在图像相似度测试阶段,余弦相似度大于0.955,则判定摄于同一个掌子面,否则,则判定摄于不同掌子面。限于篇幅,仅展示一组测试图像,具体如图9所示。

(a) 原图;(b) 1相同(0.967 7);(c) 2相同(0.958 6);(d) 3不同(0.940 4);(e) 4不同(0.931 6)
3 工程应用
以成都天府国际机场高速公路龙泉山隧道为例,其“两进两出”龙泉山,设计采用了全国首创的“双向四洞十车道”。4座隧道的长度约4 651 m,车道布置为2+3+3+2,以实行客货分流。
通过人工拍摄采集了龙泉山隧道10个里程处的掌子面图像300张,每个掌子面均对应在不同距离、角度、光照等因素影响下的30张图像,部分图像展示如图10所示。

图10 龙泉山隧道掌子面图像
经过人工标记,将该300张图像输入本文研发的掌子面图像质量评价方法体系中,依次通过清晰度判定、图像分类和相似度判别,测试结果如下:
首先通过清晰度判定模块,基于阈值21,筛选出了7张模糊图像,该阶段的准确率、查准率、查全率和1值分别为94.0%,94.8%,98.9%和96.8%,基本满足工程要求。将剩下293张满足清晰度要求的图像传入下一模块即图像分类。
在图像分类阶段,评价方法筛选出92张不合格的图像,其中大多存在没拍全、有人影遮挡、有岩渣遮挡和有集中光源的情况,该阶段的准确率为86.3%,接近模型在验证集上的准确率,说明该模型的泛化能力较好。
最后将剩余的201张掌子面图像进行相似度判别,基于阈值0.955,该阶段的准确率稳定在92%左右,基本符合预期。
通过以上工作完成对掌子面图像的质量评价,筛选出满足工程需求的掌子面图像,部分如图11所示。可以看出,经本文方法挑选出来的掌子面图像具备清晰高、完整度好、光线均匀和遮挡物较少等特点,为下一步掌子面节理识别与自动素描提供优秀素材。与传统人工地质素描相比,节省了人力物力,降低了人员要求和施工风险,且耗时更短:以一次性对同一掌子面拍摄10张图像为例,传入本文提出的评价体系中,历经清晰度判定−图像分类−相似度判别3个阶段,基于GPU计算总耗时可控制在毫秒级。此外,借助人工智能和大数据技术,实现了数据共享,推动隧道施工信息化和智能化进程。

图11 龙泉山隧道合格掌子面图像
4 结论
1) 提出一种基于深度卷积神经网络的隧道掌子面图像质量评价方法:从清晰度、分类和相似度3个方面依次对掌子面图像质量进行评价,过滤掉不合格的图像,最后成功筛选出能满足要求的掌子面图像。具有耗时短、反馈及时的优点,是隧道掌子面自动素描技术里最基础且不可或缺的一步,具备较高的工程应用价值。
2) 基于DenseNet169网络的分类模型与掌子面图像数据集的适应性最好,准确率可达88.7%。
3) 以Laplacian梯度函数为指标的清晰度判定和基于CNN图像特征提取以余弦相似度为指标的相似度判定,可用于隧道掌子面照片质量评价体系,且效果优良。
受时间、人力和物力所限,数据集的数量和质量尚存较大的提升空间,将来应注重数据集的扩充,改善人工标注,解决分布不平衡问题,完善和健全数据集。此外,探究不同的深度学习框架对训练结果的影响以寻找最优方案、进一步调整和改进CNN网络结构也可作为未来的研究方向。
[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
[2] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, America, 2016: 770−778.
[3] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, America, 2017: 1251−1258.
[4] Szegedy C, LIU W, JIA Y, et al. Going deeper with convolutions[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston America, 2015: 1−9.
[5] HUANG G, LIU Z, Van Der Maaten L, et al. Densely connected convolutional networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii, America, S 2017: 4700−4708.
[6] 徐贵力, 刘小霞, 田裕鹏, 等. 一种图像清晰度评价方法[J]. 红外与激光工程, 2009, 38(1): 180−184. XU Guili, LIU Xiaoxia, TIAN Yupeng, et al.Image clarity-evaluation-function method[J].Infrared and Laser Engineering, 2009, 38(1): 180−184.
[7] 李郁峰, 陈念年, 张佳成. 一种快速高灵敏度聚焦评价函数[J]. 计算机应用研究, 2010, 27(4): 1534−1536. LI Yufeng, CHEN Niannian, ZHANG Jiacheng.Fast and high sensitivity focusing evaluation function[J].Application Research of Computers, 2010, 27(4): 1534− 1536.
[8] Horita Y, Arata S, Murai T. No-reference image quality assessment for JPEG/JPEG2000 coding[C]// 2004 12th European Signal Processing Conference. IEEE, 2004: 1301−1304.
[9] WANG Z, Sheikh H R, Bovik A C. No-reference perceptual quality assessment of JPEG compressed images[C]// Proceedings of the International Conference on Image Processing. IEEE, 2002, 1: I-I.
[10] 李祚林, 李晓辉, 马灵玲, 等. 面向无参考图像的清晰度评价方法研究[J]. 遥感技术与应用, 2011, 26(2): 239−246. LI Zuolin, LI Xiaohui, MA Lingling, et al.Research on clarity assessment method for no-reference images[J]. Remote Sensing Technology and Application, 2011, 26(2): 239−246.
[11] Lowe D G. Distinctive image features from scale- invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91−110.
[12] 吴伟交. 基于SIFT特征点的图像匹配算法[D].武汉:华中科技大学, 2013. WU Weijiao. Image matching algorithm based on SIFT feature points[D]. Wuhan:Huazhong University of Science and Technology, 2013.
[13] Swaminathan A, MAO Y, WU M. Robust and secure image hashing[J]. IEEE Transactions on Information Forensics and Security, 2006, 1(2): 215−230.
[14] 刘兆庆, 李琼, 刘景瑞, 等. 一种基于SIFT的图像哈希算法[J]. 仪器仪表学报, 2011, 32(9): 2024−2028. LIU Zhaoqing, LI Qiong, LIU Jingrui, et al.An image hashing algorithm based on SIFT[J]. Chinese Journal of Scientific Instrument, 2011, 32(9): 2024−2028.
[15] Chopra S, Hadsell R, LeCun Y. Learning a similarity metric discriminatively, with application to face verification[C]// CVPR (1), 2005: 539−546.
[16] Zagoruyko S, Komodakis N. Learning to compare image patches via convolutional neural networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015: 4353−4361.
[17] Bell S, Bala K. Learning visual similarity for product design with convolutional neural networks[J]. ACM Transactions on Graphics, 2015, 34(4): 98: 1−98: 10.
[18] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]// European Conference on Computer Vision. Springer, Cham, 2014: 818−833.
Research on image quality assessment method of tunnel face based on convolutional neural network
XIAN Qingyu, QIU Wenge, WANG Hongying, XU Weiping, SUN Keguo
(Key Laboratory of Transportation Tunnel Engineering, Ministry of Education, Southwest Jiaotong University, Chengdu 610000, China)
In view of the diversity and complexity of tunnel face images, an image quality assessment method based on deep convolution neural network was proposed to select tunnel face images to meet engineering needs. A tunnel face image dataset based on several tunnels was created. The Keras deep learning framework was adopted. Various mainstream convolutional neural networks (CNN) were applied to carry out comparative experiments. Combining with traditional image evaluation indexes, the tunnel face image quality was evaluated from three aspects: clarity, classification and similarity. The multi-classification model based on DenseNet169 achieved 88.7% accuracy. The results show that, compared with the traditional image processing technologies, the deep learning method has the remarkable advantages of high accuracy and high efficiency in tunnel face image recognition. This method can provide technical support for realizing automatic sketch of tunnel face, and it has a good prospect in engineering application.
tunnel; image quality assessment; convolutional neural network; tunnel face; deep learning
U45
A
1672 − 7029(2020)03 − 0563 − 10
10.19713/j.cnki.43−1423/u.T20190586
2019−06−29
国家自然科学基金资助项目(51678495,51578463)
许炜萍(1981−),女,山东德州人,副教授,从事地下工程施工过程力学与动力学效应研究;E−mail:xwp1981@126.com
(编辑 涂鹏)
