融合深度学习与规则的民族工艺品领域命名实体识别*
2020-04-09王海宁周菊香徐天伟
王海宁, 周菊香, 徐天伟
(云南师范大学 民族教育信息化教育部重点实验室,云南 昆明 650500)
1 引 言
通过研究一个民族的工艺品,可以快速了解该民族的生活习惯、民族风情等;许多特色民族工艺品还可以增加当地人的收入、提高人们的生活质量.随着社会现代化的快速进行,许多民族工艺品失去了原有的应用价值,逐渐淡出人们的视线,但其所蕴含的文化与历史价值独一无二,依然需要人们的保护和传承.
随着网络信息化的发展,与民族相关的网站逐渐增多,此类网站一般都有介绍民族工艺品的专栏,将以前隐藏于民间的民族工艺品展现于网络,但由于网页呈现的文本类资源结构化低,可利用和传播性较差,构建民族文化资源知识图谱是有效保存和传播民族文化的有效手段.在知识图谱的构建过程中,从大量不同来源的非结构化网络文本资源中自动提取民族相关实体是最为重要的基础工作之一.
命名实体识别[1](Named Entity Recognition,NER)是信息抽取的任务之一,旨在识别并自动标记文本中特定实体,在知识图谱、智能问答等领域发挥重要作用.目前基于神经网络的民族工艺品实体识别研究尚处在起步阶段,研究面临的主要问题有:(1)当前暂无公开的民族工艺品数据集,数据集的规模及实体标注的质量会影响命名实体识别的效果.(2)由于一些少数民族使用不同民族语言,对于同一工艺品,可能有不同的名称.如“哈达”,藏族称为“卡达尔”,蒙古族称为“哈达噶”.民族工艺品名称的复杂性带来大量未登录词,难以构建一个全面和完善的词库.(3)传统词向量无法解决多义词问题,比如民族工艺品中佤族的“牛头”与常识中“牛头”代表不同的实体,而传统词向量会将不同的“牛头”映射为同一向量,与客观事实不符.(4)大量民族工艺品实体由不同类别实体嵌套组成,系统容易预测出错.
目前,基于深度学习的命名实体识别方法逐渐取代基于词典和规则、基于传统机器学习算法等方法,多以RNN-CRF序列标注模型为基础的改进,并在不同领域的命名实体识别任务中取得了更好的效果.Huang等人[2]首次将手工拼写特征和词向量的拼接向量输入到BiLSTM-CRF模型,在CON-LL2003数据集F1值为90.10%.Rei等人[3]加入注意力机制将字符向量和词向量加权求和作为输入特征.Zhang等人[4]将提出Lattice LSTM代替传统的LSTM,将词信息加入基于字向量的模型中,在MSRA中文数据集的F1值为93.18%.以上命名实体识别方法为基于固定的词向量的输入特征,无法解决多义词问题.为了解决多义词问题,Jacob 等人使用BERT(Bidirectional Encoder Representations from Transformers)[5]预训练语言模型在命名实体识别任务取得了最好的效果,其将CON-LL2003数据集F1值提升至96.6%,极大地提高了在此数据集上的成绩.杨飘等人[6]使用BERT预训练语言模型增强字的语义表示,将动态生成的字向量序列输入到BiGRU-CRF模型,用以提高中文命名实体的识别效果,在MSRA中文数据集上F1值为95.43%.上述方法证明加入BERT预训练语言模型代替传统词向量可以显著提升命名实体识别效果.在特定领域方面,张应成等人[7]提出使用BiLSTM-CRF深度学习模型提取招标人、招标代理和招标编号三个实体,并证明效果优于传统机器学习模型.禤镇宇等人[8]提出把多特征(字向量、边界向量、用字向量)输入到BiLSTM-CRF模型,提取影评之中的人名.何阳宇等人[9]针对老挝语的军事领域命名实体识别任务,提出用CRF(Conditional Random Fields)与规则相结合的方法,实验证明加入领域规则后可以显著的提升军事领域实体识别效果.
综合以上相关工作,本文针对民族工艺品领域实体提取任务,在传统的BiLSTM-CRF模型的基础上加入BERT预训练语言模型,构建BERT-BiLSTM-CRF模型,保证实体识别取得较好的效果,同时又避免构造复杂的特征工程.另外针对民族工艺品领域特点制定了相应的规则,对模型的输出结果进行优化调整,使预测效果进一步提升.
2 BERT-BiLSTM-CRF模型
BERT-BiLSTM-CRF模型整体结构如图1所示,主要由三部分组成:BERT预训练语言模型层、BiLSTM层和CRF层.其训练过程主要如下:(1)将文本预处理后输入到BERT预训练语言模型中获取字向量序列.(2)将字向量序列输入到BiLSTM模型进一步提取语义特征.(3)加入CRF层中预测概率值最大的标签序列.
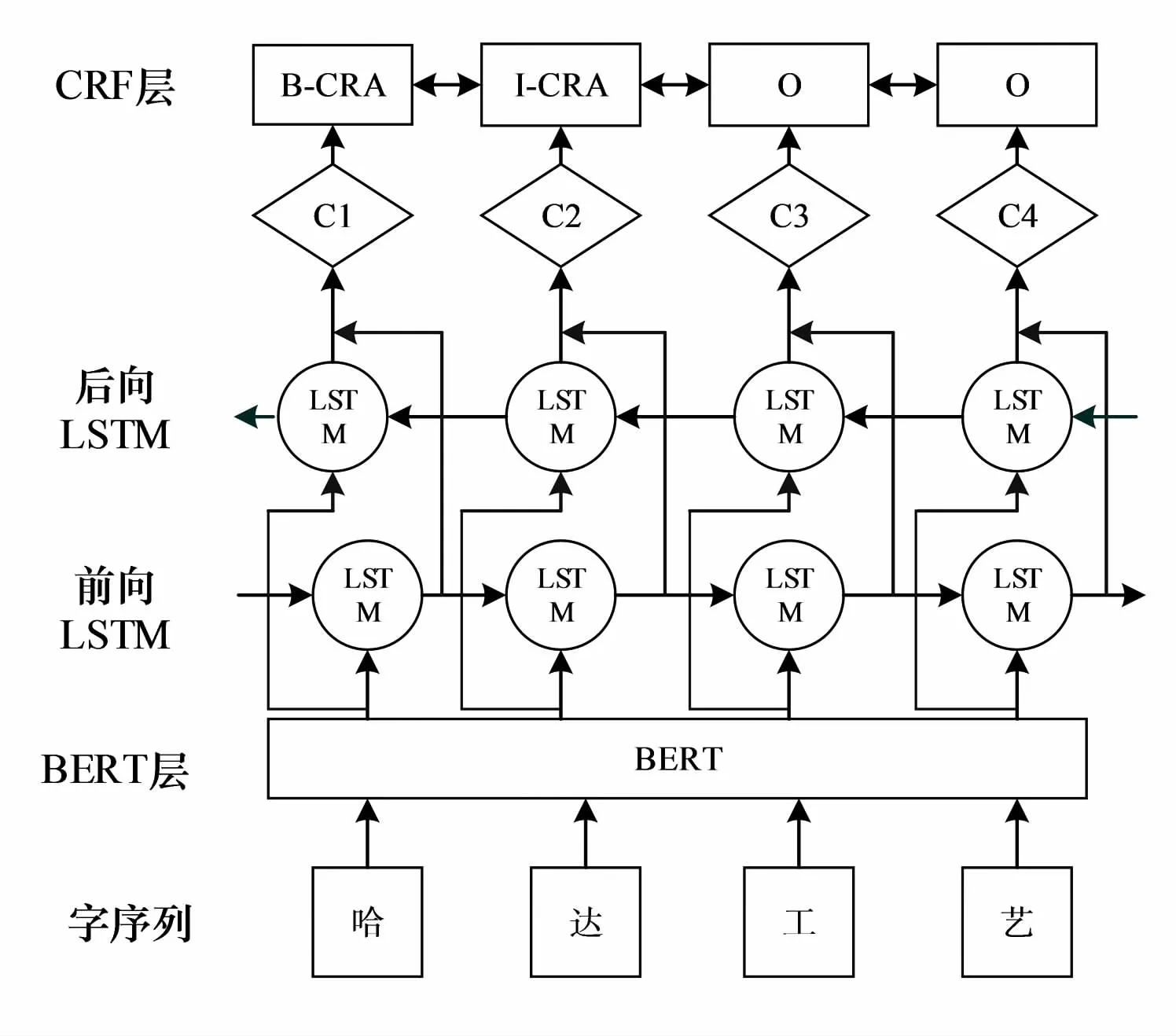
图1 BERT-BiLSTM-CRF模型
2.1 BERT预训练语言模型
BERT训练包括两个部分:Pre-training和Fine-tuning.Pre-training为双向语言特征提取模型的训练.Fine-tuning为根据不同的自然语言处理任务对模型微调训练.BERT的预训练语言模型结构如图2所示.
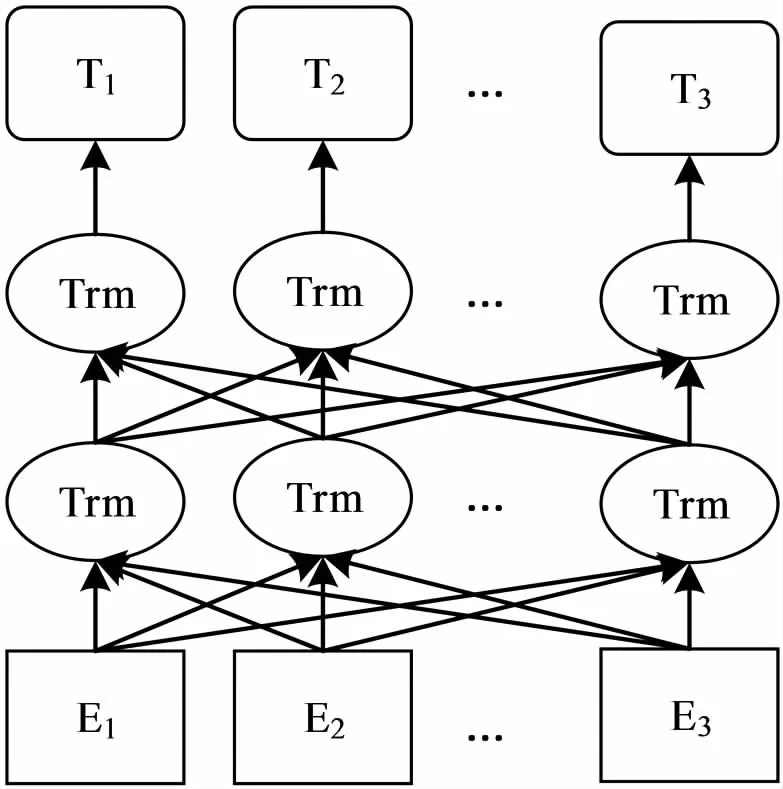
图2 BERT预训练语言模型
Pre-training部分采用了以下两个无监督训练任务.(1)为了训练深度双向语言表示向量,采用了“Masked LM”方法.即随机掩盖句子中15%的单词,然后训练模型预测这些单词.(2)为了使模型获得理解句子关系的能力,提出了“预测下一个句子”的训练任务.在为每个训练样本选择句子A和B时,50%的训练样本中句子B是语料库中句子A之后的句子,另外50%训练样本中句子B是语料库中随机的句子,然后训练模型预测句子B是否为句子A的下一句.
BERT使用双向Transformer[10]提取自然语言特征.Transformer使用Attention机制实现不同层级间的信息传递,并行处理,提高运行速度和准确度.Transformer的编码单元如图3所示.
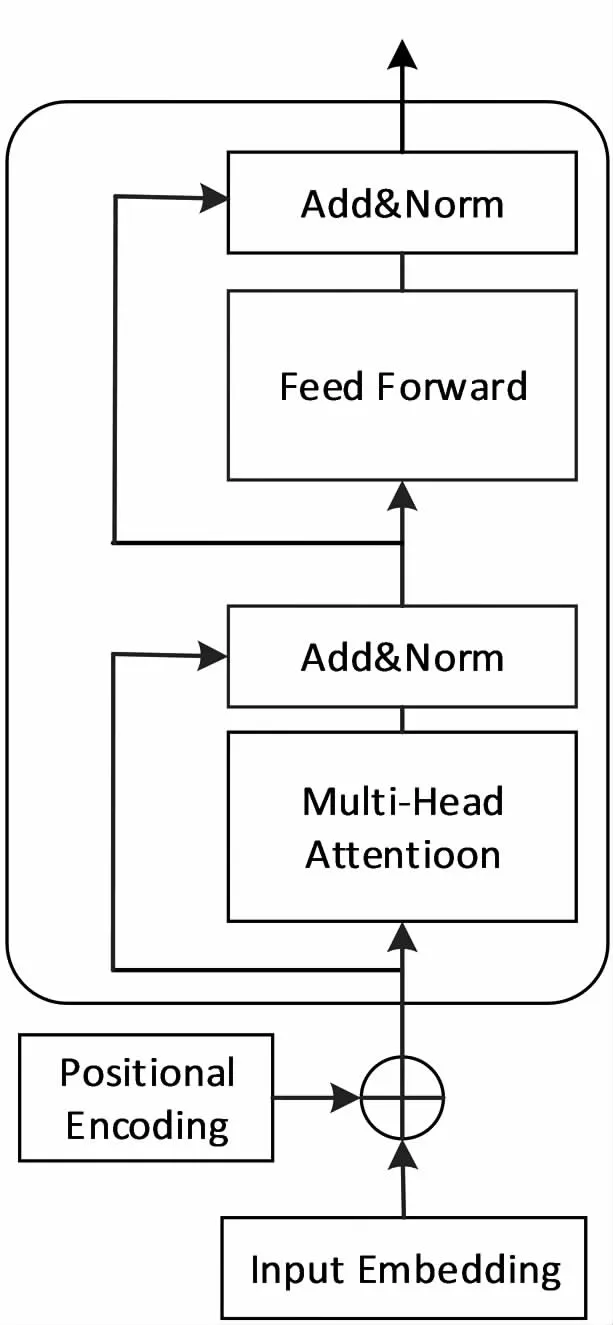
图3 Transformer编码单元
Transformer每个编码器由自注意力层和前馈神经网络构成.一个编码器接受向量表作为输入,将向量表中的向量传递到自注意力层处理后递到前馈神经网络处理,然后传递给下一个编码器.其中自注意力层如公式(1)所示.其中Q为查询矩阵,K为键矩阵,V为值矩阵,dk为输入向量的维数.
(1)
Transformer使用“多头”注意力机制完善注意力机制,扩展了模型专注于不同位置的能力,使注意力层有多个“表示子空间”,如公式(2)、(3)所示:
MultiHead(Q,K,V)=Concat(head1,...,headh)
(2)
(3)
前馈神经网络如公式(4)所示:
FFN(x)=max(0,xW1+b1)W2+b2
(4)
2.2 BiLSTM
循环神经网络[11](Recurrent Neural Network,RNN)模型常用于解决序列标注问题,能够将长时间的历史信息作为预测当前信息的指标,但可能伴随着梯度消失与梯度爆炸的问题.长短期记忆网络(Long Short-Term Meory,LSTM)为RNN的一个变种模型,有效地解决了这个问题.LSTM通过遗忘门、输入门、输出门等结构,遗忘次要的信息,保留重要的信息,记忆新的信息,从而使信息有效的传递.LSTM如公式(5)-(10)所示.
ft=σ(Wf.[ht-1,xt]+bf)
(5)
it=σ(Wi.[ht-1,xt]+bi)
(6)
(7)
(8)
ot=σ(Wo.[ht-1,xt]+bo)
(9)
ht=ot⊗tanh(ct)
(10)

由于LSTM只能获取历史信息,而判断一个字的标签,不仅要依据上文还要关联下文,所以使用双向长短期记忆网络[12](Bi-directional Long Short-Term Memory,BiLSTM)模型代替LSTM模型.BiLSTM模型由前向LSTM与后向LSTM构成,输出由两者的输出向量拼接而成,能充分利用上下文信息,自动提取句子特征.
2.3 CRF
条件随机场是给定一组随机变量条件下另一组输出随机变量的条件概率分布模型[13].传统序列标注模型常使用softmax函数预测标签,预测的标签之间相互独立,不能利用上下文信息,而实际预测时需要处理标签的上下文关系,如“I-CRA”标签前不能为“B-LOC”.CRF能够考虑标签之间的关系来获取全局最优标签序列,充分利用句子级别的标签信息,使实体抽取结果更加准确.
CRF对x=(x1,x2,…,xn)序列和其对应的标签序列y=(y1,y2,…,yn)的评估分数如公式(11)所示:
(11)
其中M为状态转移矩阵,Mi,j表示每个元素从i变化到j的概率.Pi,yi表示第i个字符对应第yi标签的分数.
x序列的标注序列为y的概率如公式(12)所示:
(12)
3 实验结果与分析
3.1 实验数据
通用领域的命名实体识别一般指识别人名、地名和机构名等三类名词.经过筛选查阅来自网络、书籍的介绍民族工艺品的文章几乎都包含三类实体:民族工艺品名、民族名、地域名,所以本文将主要识别这三类实体.本文的所识别民族工艺品主要指具有民族特色的陶器、青铜器、工艺、生活用具、传统技艺等名称.地域名所指民族工艺品的主要分布地区,如省、市、县、镇、村、寨、地区等,另外因某些珍贵民族工艺品保存在博物馆中,所以将博物馆名也归到地域名.民族名指民族工艺品所属的民族名,包括五十六个民族名、民族自称、民族史称等.
本文所用获取的语料主要来自民族网、云南民族网等网站以及《少数民族大辞典》[14]系列书籍.经过去重、去无意义字符等文本预处理,共获得有效句子6 428条,约30万字符.采用BIO标注方式对数据中的民族工艺品名称、民族名、地域名三类实体标注.具体为:“O”标注非实体;“B-CRA”“I-CRA”标注民族工艺品名的首字和非首字;“B-NAT”“I-NAT”标注民族名的首字和非首字、“B-LOC”“I-LOC”标注地域名的首字和非首字.标注样本如表1所示.
表1民族工艺品数据集标注样本
Table1Labelsamplesofethnichandicraftdataset

白族传统扎染B-NATI-NATOOB-CRAI-CRA成为了周城村OOOB-LOCI-LOCI-LOC的产业优势.OOOOOO
将标注完成的数据集按照7.5∶1∶1.5的比例分为训练集、验证集和测试集.每个数据集的详细信息如表2所示,其中测试集括号中的数字为对应实体的未登录词(未在训练集中出现的词)的数量,总未登录词数量约为测试集总标注词的35%.

表2 民族工艺品数据集信息
另外,为了验证BERT-BiLSTM-CRF模型的可移植性,本文选用MSRA公开中文命名数据集进行对比实验,MSRA数据集包括人名、地名、机构名等三类通用实体,同样为BIO标注模式.
3.2 评测指标
预测结果中每个实体的首字与非首字与测试集的对应实体的标注完全正确匹配则判定该实体识别正确.实验采用的评价指标为准确率(P)、召回率(R)和F1值.如公式(13)-(15)所示.其中Np表示模型识别的正确实体个数,NF表示模型识别的实体总个数,NA表示测试集中所有的实体个数.
(13)
(14)
(15)
3.3 实验设置
通过实验证明,在民族工艺品数据集上,不同模型取得其最高F1值所设置的参数都有所不同.其中BERT-BiLSTM-CRF模型取得最高F1值时的参数配置如下:lstm_size为128,max_seq_length为128,batch_size为32, learning_rate为5e-5,dropout_rate为0.5,clip为0.5,warmup_proportion为0.1,num_train_epoch为12.
所有实验环境如表3所示.
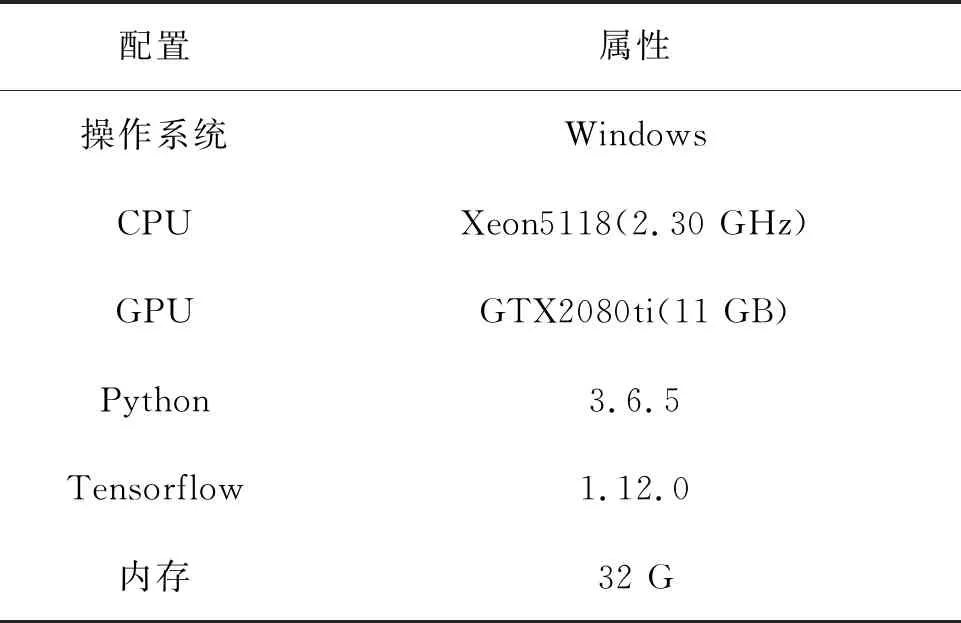
表3 实验环境
3.4 实验结果
本文首先在MSRA中文通用命名实体识别数据集上实验,将BERT-BiLSTM-CRF模型与其他相关模型进行对比,实验结果如表4所示.
表4MSRA数据集的各模型结果
Table4ResultsofeachmodeloftheMSRAdataset

模型P/%R/%F1/%BiLSTM-CRF89.4587.5288.47Lattice-LSTM-CRF93.5792.7993.18BERT-BiGRU-CRF95.3195.5495.43BERT-BiLSTM-CRF95.7395.3495.53
在MSRA数据集上,BERT-BiLSTM-CRF模型取得最高的F1值95.53%,比基于传统词向量的BiLSTM-CRF模型F1值提高7.06%,比Lattic-LSTM-CRF模型相比F1值提高2.35%.说明使用BERT预训练语言模型比传统的词向量或字词融合特征更好地提取语义特征.与BERT-BiGRU-CRF模型相比,主要区别将GRU[15](Gated Recurrent Unit)模型使用LSTM代替.GRU与LSTM比较,结构简单、参数少,需要根据具体任务在二者中进行选择效果更优者,在此数据集二模型结果相近.通过此实验说明了BERT-BiLSTM-CRF模型在公共数据集上可取得较高的成绩,证明模型具有较好的可移植性.
在民族工艺品数据集上,使用基于BERT预训练语言模型的各模型识别结果如表5所示.
表5民族工艺品数据集各模型的结果
Table5Resultsofeachmodeloftheethniccraftsdataset

模型P/%R/%F1/%BiLSTM-CRF88.2078.0182.79BERT-CRF92.1588.2090.13BERT-BiGRU-CRF91.4289.8290.61BERT-BiLSTM-CRF92.9889.3991.15
其中BERT-BiLSTM-CRF模型在民族工艺品数据集上取得了最高的F1值91.31%,比传统基于词向量的BiLSTM-CRF模型提高了8.52%,证明了加入BERT预训练语言模型能够显著提升在此数据集的识别效果,如在测试集中“热贡唐卡艺术声名鹊起”,BERT-BiLSTM-CRF模型能够正确识别民族工艺品名称“热贡唐卡”,而BiLSTM-CRF将其错误识别为“贡唐卡”.与BERT-CRF模型、BERT-BiGRU-CRF模型对比F1值略高.此模型详细的民族工艺品名、民族名、地域名三类实体的准确率、召回率、F1值如表6所示.
表6BERT-BiLSTM-CRF模型实体识别结果
Table6BERT-BiLSTM-CRFmodelentityrecognitionresults

实体类别P/%R/%F1/%民族工艺品名91.3587.7389.50民族名97.5194.7696.11地域名93.2389.2191.18
其中民族工艺品名的F1值偏低,分析原因为民族工艺品名中存在较多地域名、民族名嵌套,如“大姚彝绣”,系统将其判断为地域名“大姚”和工艺品名“彝绣”两个实体 ,此类嵌套实体预测错误会相应地影响民族名、地域名的识别效果.另外对于三类实体错误主要集中在未登录词,尤其民族工艺品测试集中未登录词的比例较高,约为40%,由于训练集的规模较小,如果没有完善的上下文信息则不能推断出部分未登录词.
3.5 加入规则改进预测结果
为了优化民族工艺品领域实体识别效果,针对民族语料的特点定制相应规则对BERT-BiLSTM-CRF模型的初步预测结果进行调整.具体调整规则如下:
(1)对民族工艺品名称:大量民族工艺品名称由不同实体嵌套组合而成.设定规则当预测结果中的民族工艺品名前紧邻出现地域名或民族名时,则将其共同判为一个民族工艺品实体.另外利用某些标点符号对民族工艺品名边界进行划分,如在引号中出现民族工艺实体,则符号内所有字符判断为一个民族工艺品实体.
(2)对地域名:民族语料中存在大量多级地名,如“吕江七叉镇机构村”.模型将其预测为“B-LOC I-LOC|B-LOC I-LOC I-LOC|O O O”,漏掉了“机构村”.按照我国行政区划级别设定规则,如“省市县乡镇村”,当检测地名则在相邻文本向前匹配高级别地名或向后匹配低级别地名.
(3)对民族名:民族名后常跟“族、胞、家、文、语、女”等文字.如“汉字”“瑶女”“藏文”等,因此可以在这些关键字相邻文本中向前匹配是否存在民族名.
另外对所有的BERT-BiLSTM-CRF模型预测结果调整,如去除对标点符号的预测、“I”标记开头的错误预测等.
将各模型加入规则后识别结果如表7所示,其中效果最佳的BERT-BiLSTM-CRF 的详细结果如表8所示.
表7各模型加入规则后实体识别结果
Table7Entityrecognitionresultsafteraddingrulestoeachmodel

实体类别P/%R/%F1/%BiLSTM-CRF89.6879.2484.14BERT-CRF93.5788.7791.11BERT-BiGRU-CRF92.8690.3291.57BERT-BiLSTM-CRF95.4390.8893.10
表7中可以看出,加入领域规则后,不同模型的F1值都有提升,其中BERT-BiLSTM-CRF模型加入规则后依然取得最好效果,其详细结果如表8所示.
表8BERT-BiLSTM-CRF模型加入规则后的实体识别结果
Table8EntityrecognitionresultsafteraddingrulestotheBERT-BiLSTM-CRFmodel
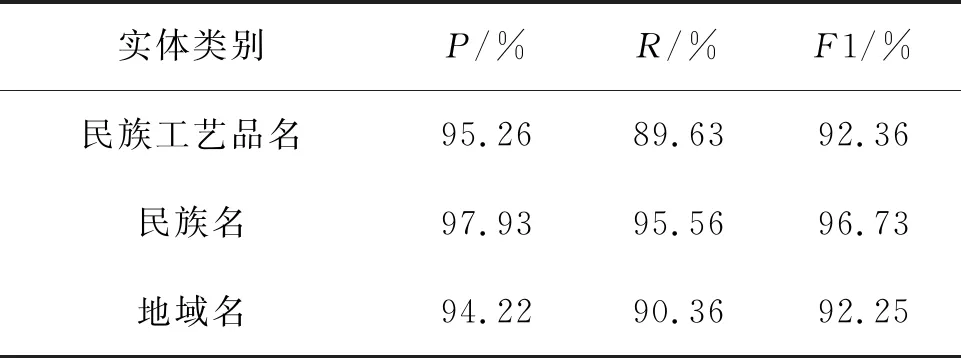
实体类别P/%R/%F1/%民族工艺品名95.2689.6392.36民族名97.9395.5696.73地域名94.2290.3692.25
由表8可以看出对BERT-BiLSTM-CRF模型的预测结果加入规则处理后三类实体的识别效果都有不同程度的提升.其中民族工艺品名最明显,F1值提高约为3%.由此证明了加入规则在一定程度上可以对BERT-BiLSTM-CRF模型的预测结果进行优化,可以纠正模型初步预测的部分错例.
4 结束语
对构建民族文化资源知识图谱工作做出初步探索,选取民族工艺品命名实体识别任务,提出融合BERT-BiLSTM-CRF模型与规则的工艺品命名实体识别方法,实验证明该方法可以有效提取民族文本中的民族工艺品相关实体.
