Spark环境下基于子图的异步迭代更新方法
2020-04-07董新华陈建峡
李 超,董新华,陈建峡
湖北工业大学 计算机学院,武汉430068
1 引言
随着信息时代的快速发展,基于图的迭代算法有着广泛应用[1]。例如,PageRank算法可以对网页的重要性进行排序,SimRank算法可以对社交网络中用户之间的相似度进行分析。由于真实网络的数据规模较大,通常采取分布式框架对图数据进行迭代处理,基于全局同步更新机制[2](BSP)的图处理系统由于实现简单且易于扩展,为大规模图数据的分析提供了便利。
受全局同步更新机制的启发[3],Spark 环境下的Graphx[4]图处理系统基于子图对数据进行全局同步迭代更新。通过弹性分布式数据集以分区方式存放顶点和连接边属性,Graphx可以利用顶点的局部状态更新顶点的全局状态,并且在迭代过程中将中间计算结果放入内存,以此避免频繁地I/O 访问。但是,由于Graphx 要求子图之间的计算任务保持全局同步,因此降低了图的收敛速度。
针对全局同步机制收敛速度较慢的问题,研究人员提出了异步迭代更新方法[5],Zhang[6]阐述了异步迭代收敛需要满足的条件。当迭代算法满足该条件时,顶点的状态更新能够绕开同步路障。虽然异步迭代提高了算法的收敛速度,但是以顶点为中心的异步迭代需要邻居节点频繁跨连接边发送消息[7-8],当邻居节点状态的变化对顶点状态更新的作用不大时,会降低网络的通信效率[9]。
为了解决图迭代收敛速度较慢以及通信效率较低的问题,本文在Spark 环境下提出一种基于子图的异步迭代更新方法,总体研究思路如下:首先,对图的切分、全局同步和异步迭代更新等概念进行简要介绍;其次,结合Spark 环境下图数据存储和更新的特点,推导出基于子图的异步迭代更新条件,分别从异步消息通信和迭代更新机制等方面给出具体的研究方案,在此基础上给出研究方案在分布式环境下的具体实现;最后,通过PageRank 算法分别从图的收敛结果、收敛速度和通信代价等方面验证了方法有效性,并对实验结果进行分析。实验结果表明,本文方法不仅能够提高算法收敛速度,同时还能降低通信开销。
2 相关概念
2.1 图切分
图数据有较强的关联性,因此图的切分对数据的迭代更新有较大影响[10-11]。将图1中顶点E 切分成4部分后,边分区可以存放连接边的完整属性和顶点的局部状态,点分区可以存放顶点的全局状态,计算节点分别对边分区中顶点的局部状态和点分区中顶点的全局状态进行迭代处理。
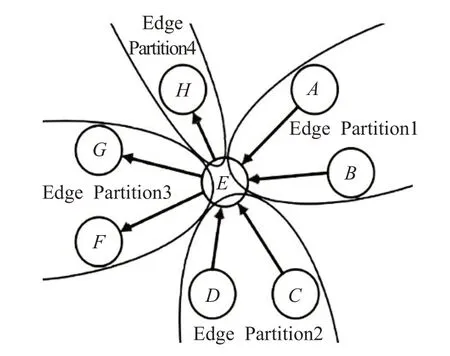
图1 有向图的点切分方法
在图迭代过程中,连接边上的顶点需要频繁交互信息。由于图1中边分区存放了连接边两端的顶点,因此连接边上的顶点可以直接在本地交互信息。对于连接边数量多于顶点数量的真实网络来说,这种切分方式可以显著减少顶点通过连接边跨分区发送消息的次数[11]。
2.2 全局同步更新
图的状态迭代更新可以用公式(1)描述:

公式(1)表明目的节点j 在第k 轮的状态值根据连接边上的源节点在第k-1 轮的状态值计算得到。
在全局同步机制下,顶点的全局状态依赖于所有边分区内顶点的局部状态。当所有边分区顶点的局部状态全部计算完毕,顶点的全局状态更新才能开始。异构环境下如果连接边分布在多个不同的边分区,那么本地计算耗时最长的边分区将直接影响下一轮迭代开始的时间。
2.3 异步更新
为提高算法收敛速度,Zhang[6]认为对公式(1)作适当变形后,可以得到公式(2):
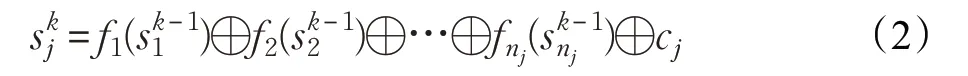
公式(2)表明目的节点j 在第k 轮的状态可以通过nj个源节点在第k-1 轮的状态计算得到。如果只考虑源节点在第k 轮与第k-1 轮的状态变化值,令,那么公式(2)可变为公式(3):
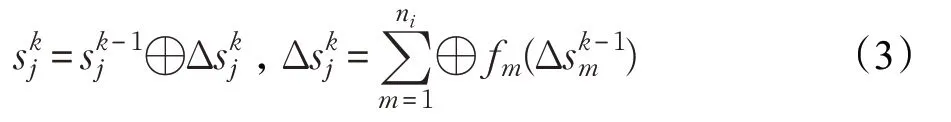
公式(2)和公式(3)表明异步更新能够减少图的收敛时间,但是分布式环境下图的迭代对异步更新条件、消息通信和更新机制有着不同的要求,需要根据实际情况加以具体分析。本文首先给出Spark环境下基于子图的异步迭代形式,在此基础上给出消息通信模型和异步处理机制。
3 研究方案
3.1 基于子图的异步迭代
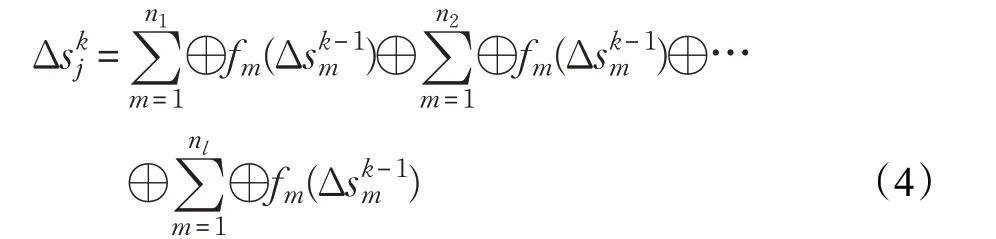
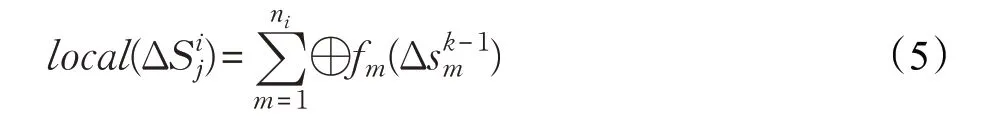
式中的⊕算子定义为局部算子,将公式(5)带入公式(4),可以得到公式(6):

式中的⊕算子定义为全局算子,公式(6)表明顶点的全局状态改变值可以根据不同边分区的局部改变值进行更新。由于不同分区的本地计算任务互不影响,因此全局算子满足交换律。在函数fm作用下,如果局部算子也满足交换律和分配律,那么顶点收到任一局部状态变化值,就能立即更新顶点的全局状态。
3.2 消息通信
分布式图处理系统主要采取消息传递[12]和共享内存的通信方式。基于共享内存通信的分布式图处理系统一般采取分布式锁保证数据的一致性。由于分布式环境下的计算节点有独立的内存地址,共享内存的通信方式实现起来较为困难。基于消息传递的通信方式在计算节点之间发送消息,目前主要有基于Netty 的通信协议[13]、消息传递接口协议[14]和远程过程调用协议。
根据Spark 环境下顶点状态更新的特点,本文采取远程过程调用协议实现分区数据集之间的异步消息通信,将每个分区数据集看作基于Actor 模型[15]的通信实体。另外,远程过程调用不仅能够实现异步消息通信,底层通信协议还支持数据块传输。由于顶点的局部状态值分布在不同的边分区,而顶点唯一的全局状态值存放在点分区,边分区m 与点分区n 之间存在交集。当边分区在本地获取本地目的节点的局部汇聚值之后,可以将本地局部汇聚的结果以数据块Blockm->n(local(ΔSID))的形式发送给顶点所在的点分区,数据块中顶点ID 满足式(7):

与顶点为中心的消息发送方式相比,以数据块为单位将计算结果集中发给点分区,不仅可以批量处理数据块,同时还能提高通信效率。
3.3 更新机制
当点分区收到数据块之后,为避免顶点状态在异步更新过程中产生数据读写冲突,本文创建数据块缓存队列以及线程池,在顶点状态表上设置读写锁,保证顶点状态在异步更新过程中的一致性。
图2中,线程池分别执行数据块的接收(receive)、更新(update)和发送(send)任务。receive线程将收到的数据块放入缓存队列,update线程从缓存队列中取出数据块进行处理,将数据块中顶点的局部状态变化delta 写进状态表(state table),同时更新顶点的全局状态。如果更新后的顶点作为源节点指向其他目的节点,则将最新的状态变化值发送给该点作为源节点的边分区,以更新其指向的目的节点。另外,update线程通过设定发送阈值,将满足条件的状态变化值放入待发送数据块,当数据块达到一定规模后唤醒send 线程,由send 线程将数据块发给边分区,以更新边分区中源节点的状态。当点分区内顶点全局状态变化值小于阈值时,终止迭代过程。
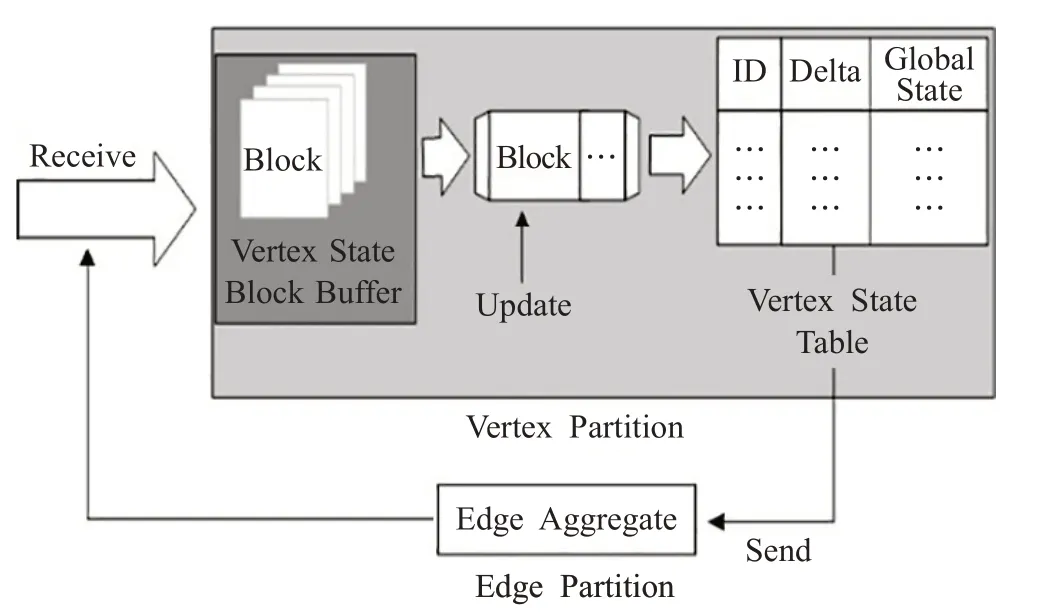
图2 点分区和边分区之间异步迭代更新机制
4 方法实现
4.1 PageRank定义
本文以PageRank[16]算法验证基于子图的异步迭代更新方法,PageRank的迭代计算公式为:

4.2 PageRank的异步迭代形式
Spark 环境下边分区以三元组((srcId,srcAttr),(dstId,dstAttr),attr)的格式存储本地连接边的状态值,其中srcId、dstId 是连接边上源节点的ID 和目的节点的ID,srcAttr 是源节点在分区内当前的状态值,dstAttr 是目的节点的状态值,attr是连接边完整的属性值,取决于源节点的出度数。
根据图数据的特点,在连接边上定义map 函数和reduce函数,顶点的局部状态可以直接利用数据的本地性计算获取。与传统的MapReduce 分布式计算模型[12]不同,由于采用弹性分布式数据集存放图数据,Spark环境下通过map 函数和reduce 函数实现的消息映射和汇聚结果不需要频繁写入外存,每条连接边上的Map函数定义如下:
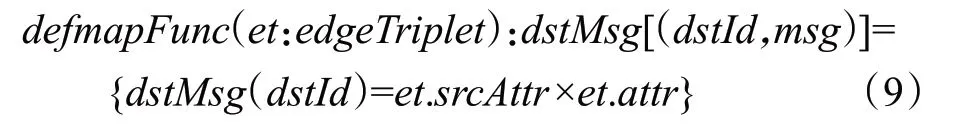
在边分区内执行map 函数时,源节点src 以并行方式向本地目的节点集合dstIds发送消息,消息度量值是源节点当前的状态值与该条连接边属性的乘积。当目的节点存在多条入度连接边,目的节点dst 在本地局部聚合的结果是该点所有入度连接边上消息聚合的总和,通过reduce函数得到:
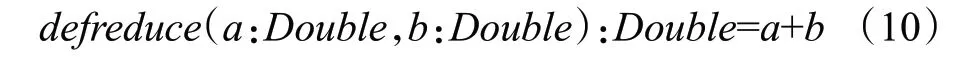
Spark 环境下的局部计算可以通过公式(9)和公式(10)实现,⊕算子是乘积算子和加法算子,满足交换律、结合律。根据公式(6),目的节点dst 的全局状态值是上一次更新后的全局状态值与最新的状态变化值直接求和:
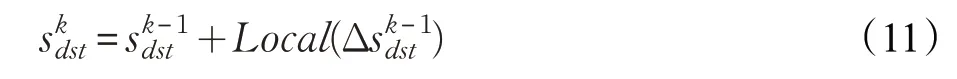
式中,⊕是加法算子,满足交换律和结合律,因此顶点在第k 轮的全局状态与不同边分区中顶点的局部状态值到达的次序无关,而通过式(9)、(10)计算得到,因此全局状态值的更新满足异步迭代条件。本文接下来结合公式(9)、(10)和公式(11)给出PageRank算法异步更新的具体实现。
4.3 分布式环境中的实现
根据公式(9)、(10),Spark 环境下边分区内部的活跃节点沿其出度连接边给目的节点发消息,而目的节点对其每条入度连接边上对收到的消息进行局部聚合,如算法1。
算法1在边分区内对目的节点的局部状态聚合
输入:点分区的活跃源节点集合activeSet,源节点状态值变化的数据块newSrcAttrblock
输出:边分区内部目的节点的局部状态信息local_aggregates,并将localBlockForVertexPartition发给点分区vertexPartition
/*遍历本地的源节点集合*/
1.for each srcId in localSrcIds
/*如果活跃节点集合包含源节点sccId*/
2.if activeSet.contains(srcId)
/*更新边分区三元组上活跃源节点srcId的状态值*/
3. newSrcAttr=update(srcId,newSrcAttrblock)
4. newedgeTriplet=updateEdgeTriple(tsrcId,news rcAttr)
/*在源节点srcId的出度连接边上给目的节点发送消息*/
5. mapFunc(newedgeTriplet=>dstMsg([dstId,msg)])
/*在目的节点dstId入度连接边上作本地局部聚合*/
6. for each dstId,msg in dstMsg([dstId,msg)]
7. reduceFunc(local_aggregates(dstId),msg)
/*根据目的节点所在的点分区对局部聚合结果进行切分*/
8.dstBlockToVertexPartition=split(dstVidsInVertexPartition,local_aggregates)
/*将分区后的数据块依次发送至所在的点分区*/
9.for each vertexRef in vertexPartitionRefs
10.vertexPartitionRef.send(dstBlockToVertexPartition)
算法1中,边分区中源节点是否对其出度连接边上的目的节点发送消息,取决于源节点是否处于活跃状态(active)。因此,边分区首先接收来自点分区的活跃节点集(activeSet)以及包含源节点变化值的数据块newSrcAttrblock,并且检查本地源节点是否在活跃节点集中。对于活跃的源节点,更新其状态变化值得到最新的以该点为中心的三元组集合newedgeTriplet。此后,mapFunc 并行作用于更新后的以srcId 为源节点的三元组上,同时reduceFunc 对目的节点dstId 入度连接边上的消息进行聚合,得到目的节点在本地局部聚合的结果local_aggregates。由于边分区中的目的节点分布在不同的点分区中,按照式(7)对本地聚合结果进行切分,将切分后的结果dstBlockToVertexPartition 通过每个点分区地址引用vertexPartitionRef发送给对应的点分区。
另一方面,点分区收到不同边分区的数据块,按照图2更新节点的状态信息,如算法2。
算法2点分区对收到的数据块后进行处理,将更新后的源节点状态变化值以数据块的形式发送到所在的边分区
输入:点分区从边分区收到的局部汇聚结果dstBlockTo-VertexPartition
输出:更新后的源节点状态变化值数据块newSrcAttrblock
/*receive线程将边分区发送的数据块dstBlockToVertex-Partition放入阻塞队列blockingQueue*/
1.blockingQueue.pu(tdstBlockToVertexPartition)
/*update线程池从阻塞队列取出数据块curBlock*/
2.curBlock=blockingQueue.take()
/*update 线程池遍历数据块中的节点vid 及其变化值delta*/
3.for each vid,delta in curBlock
/*将节点和状态变化值写入状态信息表stateTable*/
4.stateTable.write(vid,delta)
/*将满足条件的源节点放入状态更新数据集srcDelta-ToEdgePartition,活跃节点集activeSet中*/
5.if(delta>DELTA_THRESHHOLD)
6.srcDeltaToEdgePartition.append(vid,delta)
7.activeSet.add(vid)
/*根据源节点所在的边分区srcVidToEdgePartition 对状态更新数据集srcDeltaToEdgePartition进行切分*/
8.newSrcAttrblock=split(srcVidToEdgePartition,srcDelta-ToEdgePartition)
/*send线程将切分后的数据块newSrcAttrblock依次发送至所在的边分区*/
9.for each edgePartitionRef in edgePartitionRefs
10.edgePartitionRef.send(newSrcAttrblock)
算法2中,receive线程首先将来自边分区的数据块放入缓存队列,update线程从缓存队列取出数据块处理目的节点的变化值。为了避免对状态表中同一顶点同时写入状态变化值,update线程在写入数据之前需要首先获取状态表的写锁,在写入数据之后检查该顶点的状态变化值是否超过顶点状态变化的阈值,并将满足条件的顶点放入待发送数据块以及活跃顶点集activeSet中。另外,由于点分区中更新后的源节点分布在不同的边分区中,需要对点分区内更新后的结果进行切分,并将切分后的结果newSrcAttrblock 通过每个边分区地址引用edgePartitionRef 依次发送给对应的边分区。当边分区收到点分区的数据块之后再次执行算法1,并继续执行新一轮的局部聚合任务,当边分区内所有源节点为非活跃状态时,终止算法1和算法2。
5 实验和结果分析
5.1 实验准备
本文选取真实网络样本数据集wiki-topcats[17],该数据集共包含1 791 489个顶点,28 511 807条连接边。为实现负载均衡,以哈希方式对图数据作点切分,顶点和连接边的状态值分别存放在4 个点分区和4 个边分区。通过两组实验验证方法有效性:第一组实验统计PageRank 在全局同步和异步更新的收敛结果;第二组实验给出不同迭代方式下的收敛时间和通信开销。
5.2 初始化和结束条件
在执行迭代算法之前,首先对图中顶点状态进行初始化。根据公式(11),在迭代过程中需要保证第k+1轮状态值是第k 轮状态值与下一轮状态变化值求和的结果,因此设定点分区内顶点的初始值为0,边分区内顶点初始值1-d,边分区内所有顶点的状态为激活状态。另外,PageRank 算法中顶点状态值在迭代过程中呈单调增长趋势,因此采用顶点全局状态值的总和作为收敛程度的度量值,顶点的状态初始值以及整个图中活跃节点的个数将影响整个图的最终收敛结果。当d 值越小,顶点的初始状态值越大,并且图中活跃顶点个数越多时,图中顶点状态值的收敛总和越大。根据PageRank 算法的迭代公式,通常情况下设定d 值为0.8,使得孤立页面随机跳转到其他页面的概率为0.2。在异步迭代方式下,不同点分区内顶点的全局状态相互独立,只要点分区内顶点全局状态总和的增长区间小于设定的阈值,即认为该分区的顶点达到全局收敛。当设定阈值越大,图越容易达到收敛状态,当所有分区的顶点全部收敛,结束整个迭代过程。
5.3 收敛结果
首先,按照全局同步方式对图数据迭代。Spark 环境下的全局同步通过reduce 算子触发边分区内部的局部消息聚合任务,再将聚合后的结果发送给点分区作全局同步,图中所有顶点的状态总和与迭代次数之间的关系如图3所示。
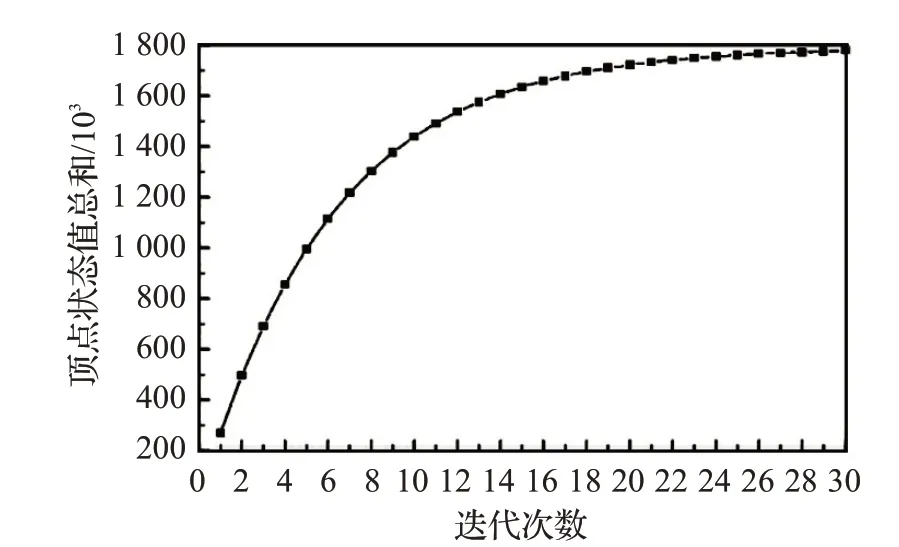
图3 全局同步迭代下顶点状态总和
在图3中,顶点状态值的总和随着迭代次数增长不断增大。迭代前10 轮顶点状态总和的增长速度较快,随后增长速度减缓,迭代到22轮时,顶点状态值的总和接近收敛状态。
其次,异步迭代不受全局同步的限制,因此异步更新没有迭代次数的概念,不能通过迭代次数判断图的收敛状态。考虑到顶点的全局状态更新取决于边分区数据块到达的时间,并且不同分区内顶点的全局状态之间相互独立,因此可以统计不同点分区内顶点的全局状态总和判断图数据的收敛状态。图4 给出不同点分区内顶点状态总和随着数据块处理的变化关系。
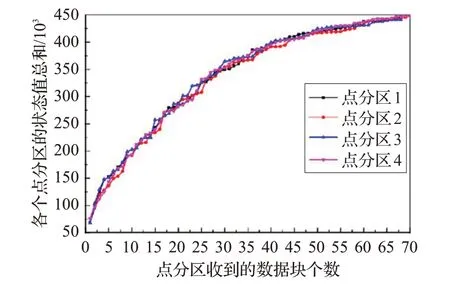
图4 异步迭代下各个点分区的顶点状态总和
在异步迭代初始阶段,边分区内所有源节点的初始状态都为激活状态,因此边分区内所有源节点都能向目的节点发送消息,使得初始阶段各个点分区内顶点的全局状态总和增长较快。另外,异步更新并不要求所有边分区的数据块同时到达,只要点分区收到数据块就能立即更新部分顶点的状态,因此各个点分区的顶点状态总和在收敛过程中出现不同幅度的震荡。当4 个点分区处理完65~70个数据块后,顶点状态总和与全局同步迭代到22轮的状态值接近,认为异步迭代接近收敛。
5.4 收敛速度
为比较全局同步和异步迭代的收敛速度,以图3和图4 的收敛值统计全局同步和异步迭代的收敛时间。图5给出全局同步下reduce和collect算子在每轮迭代过程中的平均运行时间。
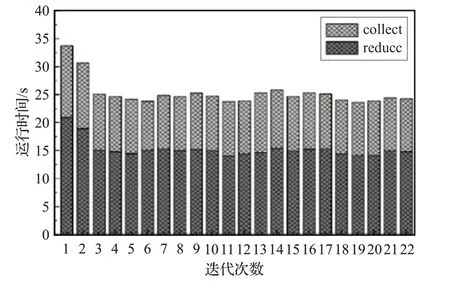
图5 全局同步每轮迭代的运行时间
从图5 可以看到,全局同步迭代轮数较少,但是由于存在路障限制,全局同步迭代需要等到所有边分区的结果全部到达才能对顶点的状态进行更新。每轮迭代过程中reduce 算子平均运行时间为12~18 s,collect算子平均运行时间在8~10 s。在已知图数据收敛状态情况下,仅考虑每轮迭代过程中reduce 算子运行的时间,并且只在最后收敛阶段使用collect算子将顶点状态汇总至driver 计算收敛结果,全局同步的平均收敛时间为335.7 s。
由于初始阶段点分区需要等待边分区局部聚合的结果,导致点分区发送数据块的时间变长,因此图6 中前后两个阶段消耗的时间比其他阶段长。在对图数据处理多次后,4个点分区的平均收敛时间分别为112.4 s、114.5 s、117.2 s、119.7 s,相同数据集下以顶点为中心异步更新的收敛时间为102.7 s。
图6 给出4 个点分区处理数据块的时间,起始点设为点分区收到数据块的时间,结束点为点分区将处理后的顶点状态变化值以数据块的形式发送给边分区的时间,图中每个点分区对数据块的接收、更新到发送时间集中在0.5~2.5 s。
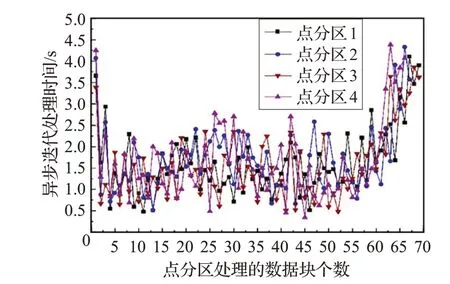
图6 异步更新下点分区对数据块的处理时间
5.5 通信代价
全局同步的通信开销主要由每轮迭代过程中的reduce算子产生,当边分区在本地的局部聚合全部结束之后,需要对所有边分区中具有相同索引顶点的局部状态作全局聚合,并将结果发送给点分区。统计发现全局同步迭代方式下每轮迭代的通信开销在125~132 MB。对图数据进行多次全局同步迭代后,通信量均值为2 850 MB。
相比全局同步要求4 个边分区将数据块汇总后同时发送到点分区,以子图为中心的异步迭代不需要等待其他分区的局部聚合结果,能够直接将边分区聚合后的数据块发送给点分区。分别对边分区和点分区发送的消息量进行统计,结果表明边分区给点分区发送的数据块大小在3~4 MB,点分区给边分区发送的数据块大小在2~3 MB。当各个点分区接近收敛状态,产生的网络通信量共1 950 MB。基于顶点为中心的异步迭代通过顶点更新次数统计网络通信开销,统计发现以顶点为中心的异步迭代方式下每个顶点平均更新9 次达到收敛状态。对图数据进行多次异步迭代后,网络通信量均值为2 520 MB。
根据以上分析,图7给出了不同迭代方式下的图迭代的收敛时间和通信开销。从图7可以看到,与全局同步迭代方式相比,以子图为中心的异步迭代不仅能有效降低收敛速度同时能提高通信效率。与顶点为中心的异步迭代方式相比,基于子图为中心的异步更新方式在收敛时间上虽略有增长,但是能够显著降低通信开销。
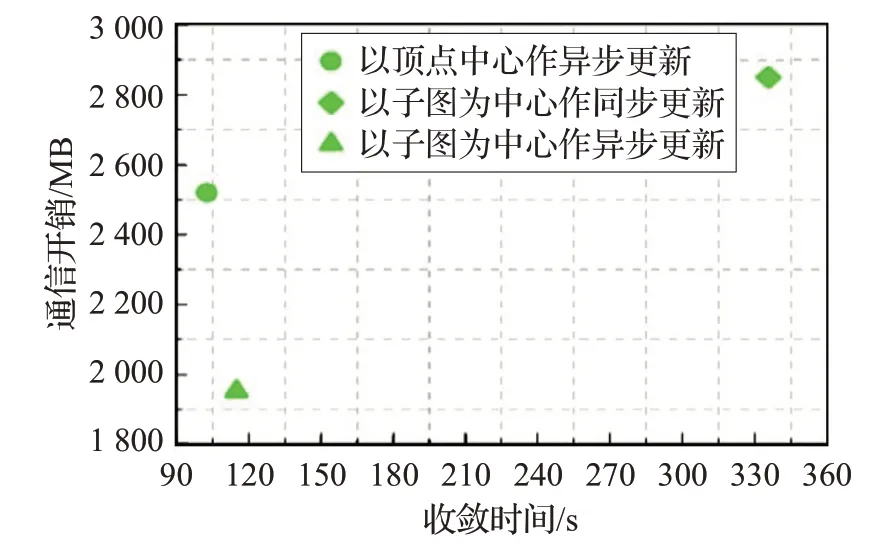
图7 不同迭代方式下的收敛时间和通信开销
5.6 原因分析
图3 表明全局同步迭代轮数较少,但是由于存在路障限制,全局同步迭代需要等到所有边分区的结果全部到达才能对顶点的状态进行更新。图4 中异步更新处理的数据块个数虽然较多,但只要迭代算法满足异步更新条件,点分区收到任一边分区的局部聚合结果,就能够立即从缓存队列中取出数据块进行处理,因此基于子图的异步更新方式能极大缩短图的收敛时间。由于整个迭代过程时间较短,这也使得异步迭代产生的通信量远少于全局同步产生的通信量。
另外,以顶点为中心的异步迭代以顶点为单位更新顶点状态,以子图为中心的异步迭代以数据块为单位更新顶点状态,因此以顶点为单位进行异步更新能够更快地加速图状态收敛。相比较于以顶点的异步迭代在收敛时间上略有增长,基于子图的异步迭代可以通过以下方式极大提高通信效率:
(1)大部分网络拓扑服从幂律分布,网络中连接边的数量远远超过顶点的个数,因此以顶点为对象发送消息的次数远少于跨连接边发送消息的次数[18]。
(2)基于子图的划分方式将大量顶点连接边存放在同一分区,少部分顶点的连接边分布在不同的边分区,这种存储方式不仅减小了消息发送的次数,基于子图为中心的异步迭代通过在边分区内通过聚合机制获取顶点的局部状态后,以批量方式集中将分区的局部聚合结果发送给点分区。
(3)单个顶点在同一边分区中存在多条连接边,更新后的顶点状态发往同一边分区后在很大程度上能够对顶点状态信息重用,因此进一步减少了同一顶点跨越计算节点发送消息的次数。
6 结束语
Spark 环境下的Graphx 图处理系统要求子图之间的计算任务保持全局同步,因此限制了图迭代的收敛速度[19]。根据Spark 环境下图切分和数据存储的特点,本文提出了一种基于子图的异步迭代更新方法。实验结果表明,该方法能够有效提高图迭代的收敛速度,同时降低网络通信开销。未来,将对方法的扩展性[20]作进一步研究。
