深度学习框架下说话人识别研究综述
2020-04-07曾春艳马超峰王志锋朱栋梁
曾春艳,马超峰,王志锋,朱栋梁,赵 楠,王 娟,刘 聪
1.湖北工业大学 太阳能高效利用及储能运行控制湖北省重点实验室,武汉430068
2.华中师范大学 数字媒体技术系,武汉430079
1 引言
在日常工作和生活中,很多场合需要身份认证,即鉴定一个人的真实身份或确认一个人所宣称的身份与他实际的身份是否符合。随着时代的发展,身份认证的方法从原来的证件、ID 卡及用户名和密码结合到现在利用人的生物特征不断克服以往的缺陷[1]。
目前发展比较成熟的生物特征识别技术包括:指纹、手形、视网膜、虹膜、面孔、语音、签名等[2]。语音是人们在日常生活中交流和沟通的最自然,并且也是最直接的方式之一。人类的语音信号传达丰富的信息[3],如语言学的文本信息、语种信息等;说话人自身情感、种族、年龄以及人的心理活动特性等,甚至传达语音产生时的外界环境因素以及传输的信道信息等。同时,语音信号采集方便,成本较低,获取渠道多样;不涉及说话人的隐私;识别过程是非接触式的,因此亦具备远程识别特性[4]。
自20 世纪30 年代开始研究至今,说话人识别技术的发展取得了一系列的成果,国内外研究人员从各个角度出发发表了相关综述[5-11]。1985 年,Doddington 从人工和计算机识别两方面概述说话人识别技术[5]。1996年,Furui按照文本相关、文本无关和文本提示型将说话人识别技术分为三类[6]。2003 年,Fu 等从建模技术、背景模型、信道补偿三个模块概述说话人识别方法[7]。2010 年,Kinnunen 等分别从特征提取和说话人建模两个方向总结以往的说话人识别技术的进展[8]。2015年,Hansen 等综合人类感知和机器识别的特点,从特征、建模、评估等方面分析了说话人识别技术[9]。2016 年,郑方等主要概述说话人识别的应用现状及面临的技术难题[10]。2019 年,覃晓逸等从语音增强方向,介绍了说话人识别在远场环境下语音信号的处理技术[11]。然而,综合以往综述,对近年来发展迅猛的基于深度学习的说话人识别技术分析总结则相对较少。
传统的说话人识别算法所采用的模型,一般属于浅层结构,只是对原始的输入信号进行较少层次的线性或者非线性处理以达到信号与信息处理的目的。这种结构的优点在于易于学习,而且有比较完整的数学算法证明推导。但是对于复杂的语音信号,其模型表达能力有限,不能够充分地学习到信号中的结构化信息和高层信息。而深层结构的模型,如深度神经网络(Deep Neural Network,DNN),由于其多层非线性变换的复杂性,具有更强的表达与建模能力,更适合处理这类复杂信号[12-13]。因此本文着重深度学习方法,总结并分析目前深度学习在该领域进展,并对典型网络及其性能进行了汇总分析,更具时效性,并总结了说话人识别研究面临的问题及挑战,以期推动说话人识别技术的进一步发展。
本文首先叙述了说话人识别的任务模型、框架流程、传统算法,按照深度学习在说话人识别中的作用方式,将目前的研究分为基于深度学习的特征表达、基于深度学习的后端建模、端到端联合优化三种类别,并分析和总结了其典型算法的特点及网络结构,对其具体性能进行了对比分析。最后,总结了深度学习在说话人识别中的应用特点及优势,并进一步分析了目前说话人识别研究面临的问题及挑战,并展望了深度学习框架下说话人识别研究的前景。
2 说话人识别的相关理论
2.1 说话人识别任务模型
说话人识别是指通过对说话人语音信号的分析处理,确认说话人是否属于所记录的说话人集合,以及进一步确认说话人是谁。按其最终完成的任务不同,说话人识别可以分为两类:说话人确认(Speaker Verification)和说话人辨认(Speaker Identification)。前者判断某段语音是否是由指定的
某个人所说,是“1V1”的判别。后者是判断某段语音是由若干人中的哪一个人所说,是“1VN”的判别。
根据识别对象的不同,说话人识别还可以分为三类:文本有关型、文本无关型和文本提示型。文本有关的说话人识别方法,要求说话人的发音关键词和关键句子作为训练文本,识别时按照相同内容发音。文本无关的说话人识别方法,无需限制训练和识别时的说话内容,识别对象是自由的语音信号。值得注意的一点是文本无关难度大,必须在自由的语音信号中找到能表征说话人的信息的特征和方法,建立其说话人模型困难。文本提示的方法,需要在每一次识别时,识别系统从一个规模很大的文本集合中选择提示文本,要求说话人按提示文本发音,识别和判断都是在说话人对文本内容正确发音的基础上进行的,防止说话人语音被盗用。
2.2 基本框架流程
一个完整的说话人识别系统如图1所示,主要实现语音特征提取和识别两个功能。具体可以分为两个阶段:训练阶段和识别阶段。训练阶段需要使用者的若干训练语音片段,提取这些语音片段的特征参数以作为标准,使系统训练学习,从而建立特定说话人模板。在识别阶段,截取待识别者的语音片段,对其进行特征参数的提取,然后与建立的模板进行比较,根据一定的相似准则进行判定。

图1 基本的说话人识别系统框架
2.3 传统方法及分析
如表1 所示,目前高斯混合模型-通用背景模型(Gaussian Mixture Model-Universal Background Model,GMM-UBM)[14]、高斯混合模型-支持向量机(Gaussian Mixture Model-Support Vector Machine,GMM-SVM)[15]、联合因子分析(Joint Factor Analysis,JFA)[16]、i-vector[17]成为说话人识别领域主流的研究框架,它们在说话人建模表示和打分判决上的不同特点,使得建立在各自方法基础上的信道鲁棒算法也存在差异。
2.3.1 GMM-UBM
GMM 作为通用的概率统计模型,能够有效地模拟多维矢量的任意连续概率分布,同时引入与说话人无关的UBM 弥补建模样本的不足,因此GMM-UBM 框架十分适合文本无关的说话人识别[14],如图2所示。然而由于GMM-UBM 框架在为说话人建模时采用高阶高斯模型,导致待估参数较多,识别时运算量大,从而影响其推广使用;并且缺乏对于信道多变性的补偿能力,不能很好地解决信道鲁棒问题。又由于其主要针对目标说话人语音特征分布建模,不考虑不同说话人语音特征分布之间的差异信息,所以该框架区分能力也较弱。

图2 基于GMM-UBM的说话人识别算法
2.3.2 GMM-SVM
为提升对信道的抗干扰能力,Campbell 将SVM 引入到GMM-UBM 的建模中。因为GMM-UBM 模型中,在MAP(Maximum A Posterior)[18]自适应环节仅仅是利用UBM模型对目标说话人数据做了均值的自适应。如图3 所示,通过将GMM 每个高斯分量的均值单独提取出来组成高斯超向量(Gaussian Super Vector,GSV)[15],进而搭建GSV-SVM 系统。依靠SVM 核函数的强大非线性分类能力,在GMM-UBM 的基础上大幅提升了识别的性能。另外加入基于GSV 的一些规整算法,例如扰动属性投影(Nuisance Attribute Projection,NAP)[19]、类内方差规整(Within Class Covariance Normalization,WCCN)[20]等,都在一定程度上补偿了由于信道易变形对说话人建模带来的影响。但是,研究发现其识别率进一步提升受到信道因素影响仍较为严重。
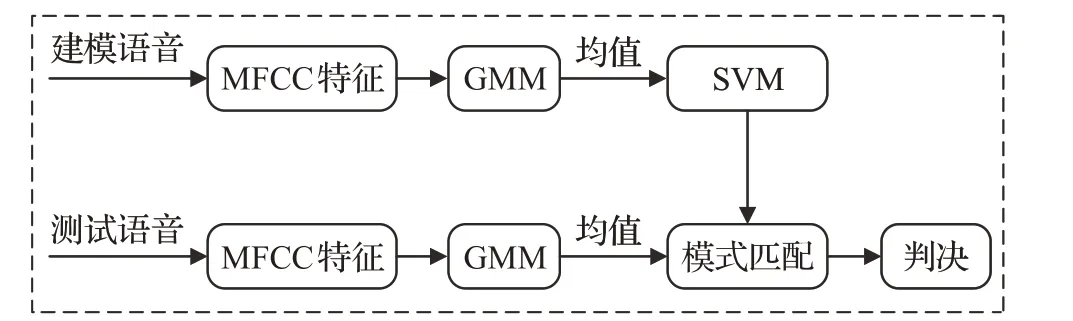
图3 基于GMM-SVM的说话人识别算法
2.3.3 JFA
为了解决GMM-UBM 模型抗信道干扰性弱的问题,Kenny等提出了JFA[16]。在JFA中,将说话人GSV所在的空间划分为本征空间(跟说话人本身有关的矢量特征)、信道空间(跟信道有关的矢量特征)和残差空间(跟其他变化有关的矢量特征)。JFA的思路是保存跟说话人相关的特征而去掉和信道相关的特征,很好地克服了信道的影响,系统的性能得到了明显提高。
尽管JFA 对于特征音空间与特征信道空间的独立假设看似合理,但事实上数据之间都具有相关性。绝对的独立分布假设往往为数学的推导提供了便利,却限制了模型的泛化能力,并且在分别建模说话人空间、信道空间以及残差空间期间,每一步均会引入误差。
2.3.4 i-vector
i-vector是基于JFA的简化版,即用一个全因子空间(Total factor matrix,T)同时描述说话人信息和信道信息,然后把语音映射到了一个固定且低维的向量上[17]。由于信道信息的存在,对识别系统产生干扰,甚至严重影响系统的识别准确率,所以通常会采用WCCN、线性判别分析(Linear Discriminant Analysis,LDA)[21]、概率线性判别分析程序(Probabilistic Linear Discriminant Analysis,PLDA)[22]进行信道补偿,如图4 所示,但噪声对GMM特征依然有很大影响。

表1 经典的说话人识别算法

图4 基于i-vector的说话人识别算法
i-vector 在文本无关说话人识别上表现优秀,但是在文本相关的识别上的表现却不如传统的GMM-UBM框架好。i-vector 看似简洁,是由于其舍弃了如文本差异性之类的信息,在文本无关识别中,注册语音和测试语音在内容上的差异性比较大,因此需要抑制这种差异性;但在文本相关识别中,又需要放大训练和识别语音在内容上的相似性,导致说话人的特征相似性被稀疏化,使得区分能力下降。
近年来,随着计算能力的加强,运用深度学习方法来解决语音信号处理领域的问题正逐步得到研究人员们的重视,如语音识别[23-26]、说话人识别[27-30]。深度神经网络作为模式识别研究领域中的一种建模方法,其不仅具有强大的表征能力,还具有很强的分类能力。同时,大数据的存在为深度学习提供了充足的样本支持。本文所要研究的说话人识别任务是一个复杂的分类问题,其要求所采用的说话人模型需具有很强的表征能力,同时对于不同说话人的语音特征分布又要有一定区分能力。因此,采用DNN 完成说话人识别任务有着其他机器学习方法不可相比的优势,本文按照深度学习在说话人识别中的作用方式大致分为特征表达、后端建模、端到端三类来综述国内外研究进展,并分析其特点和关键步骤,如表2所示。
3 基于深度学习的特征表达
说话人识别任务的性能提升的关键在于是否得到既富含说话人信息,又少含信道或噪声等无关信息的特征。深度学习强大的表现力得益于其深层次的非线性变换,利用DNN 来捕捉说话人特征是目前非常活跃的研究领域[31-32]。深度学习方法应用于说话人识别的前端,可分为如下两种:一是DNN 与传统框架结合,即DNN/i-vector 框架[33-42];二是完全使用深度学习的框架探索出一系列的embedding特征[43-45]。
3.1 DNN/i-vector
标准的i-vector 框架是使用UBM 来对语音声学特征序列进行对准并表示成高维的充分统计量,然后基于因子分析将该统计量映射成i-vector,最后利用PLDA模型来计算不同i-vector间的似然比分数并做出判决[17,22]。在以下两个小节中,描述如何在i-vector 框架下使用DNN后验概率和DNN瓶颈特征。
3.1.1 DNN后验概率
传统框架使用UBM估计每帧在每个高斯分量上的后验概率,其中每个高斯分量代表一个类别,这些类是通过无监督聚类方式得到的,但是这些类无任何具体含义,仅仅代表空间中的某块区域。如图5 所示,利用语音识别中监督训练的DNN 替代UBM 的作用,将DNN的每个输出节点作为一个类别,其中关键点在于这些类是通过语音识别中聚类后得到绑定的三音素状态,与发音内容有明确的对应关系,从而较大提升了说话人识别的性能[33-34]。

图5 基于DNN/i-vector的混合模型
3.1.2 DNN瓶颈特征
深度学习其一个重要的使用方式就是降维,即通过非线性变换减少网络中某个隐层节点数降低维度,可以更好地抽象出数据中的特征细节。由于降维后该隐层节点数远小于其他层,于是这层被形象的称为瓶颈(Bottleneck,BN)层,其输出被称为瓶颈特征(Bottleneck Features,BNF)[35]。BN 层的加入虽然限制了网络内部的信息流通,但也提高了特征信息的信噪比,抑制了网络多余的表达能力。通过抑制过拟合现象的发生,得到了更好的泛化模型。

表2 基于深度学习的说话人识别算法
如图6 所示,基于堆叠瓶颈特征(Stack Bottleneck Features,SBNF)方法的DNN在结构上使用了两个级联神经网络,第一个SBN输入到第二个SBN中,实现堆叠操作[36]。一般将梅尔倒谱特征(Mel-Frequency Cepstral Coefficients,MFCC)作为原始输入特征传输到瓶颈神经网络,之后对瓶颈层获得的值进行其他处理。研究发现BNF比传统的单帧短时频谱特征(如MFCC[38]和感知线性预测(Perceptual Linear Predictive,PLP)[39])包含更多的说话人信息[36-37]。张玉来等人将惩罚函数和套索算法加入到DNN中,进一步减少瓶颈特征中的冗余信息,提升特征的表征能力[40]。此外,通过特征融合的方式联合使用BNF 和MFCC,可以实现信息互补,使系统取得优异的效果[41-42]。

图6 基于堆栈瓶颈特征的网络结构
3.2 embeddings特征
embeddings 特征是一种将长度不一的语句映射为固定维度的表征向量,所以i-vector 也是Embedding 的一种。然而与i-vector 的贝叶斯建模不同,基于神经网络的embeddings 方法具有非线性建模的能力,且embedding 特征会在训练神经网络时更新,可以有很多变种。目前基于DNN 的embedding 特征有d-vector[43]、x-vector[44]、j-vector[45]等。
3.2.1 d-vector
2014 年,Google 提出使用使用监督训练的DNN 来提取特征而不同于DNN/i-vector 方法仅用于表示语音帧的概率分布。说话人的每个语音帧输入到该DNN,累积最后一层隐藏层的输出激活值作为该特定说话人的表示,即为d-vector 特征[43],如图7 所示。一般情况下,是将softmax 层作为输出层,此方法去除softmax 层将能够更好地表达未知说话者的紧凑模型。与传统方法不同,该方法不使用任何自适应技术来提取训练阶段中的已知特征,仅仅使用DNN 模型在注册和匹配阶段提取特定特征。d-vector虽然简单,但对DNN框架下的说话人识别研究的推广意义重大。

图7 基于d-vector的网络结构
3.2.2 x-vector
x-vector[44]是由Snyder从时延神经网络(Time-Delay Neural Networks,TDNN)中提取的embeddings特征,如图8 所示。其中网络结构中的统计池化层负责将帧级特征(frame-level feature)映射到段级特征(segmentlevel 或utterance-level feature),具体是计算帧级特征的均值和标准差。由于TDNN 是时延架构,因此其网络结构的特点在于输出层可以学习到长时特征,所以x-vector在短语音上表现出更强的鲁棒性。

图8 基于x-vector的网络结构
3.2.3 j-vector
i-vector 的提取依赖较长的语音信号,而在文本相关的说话人确认任务中,通常语音很短。文本相关的说话人确认任务既要解决验证身份的问题,又要解决验证语音内容的问题。j-vector(联合向量)[45]被提出来解决这类问题。如图9 所示,训练DNN 模型期间同时采用说话人和文本两个标签信息来更新网络参数,一旦网络训练完成,移除这两个输出层,使用最后一层隐藏层提取说话人-文本的联合向量。另外,多任务学习方式避免了DNN训练中的过拟合问题,并增强了DNN节点的表征能力。

图9 基于j-vector的网络结构
4 基于深度学习的后端建模
深度学习作用于说话人识别系统的后端部分,主要是用深度学习处理传统的声学特征,使更具区分性,更利于区分说话人[46-49]。
到目前为止,i-vector 在大多数情况下仍然是文本无关声纹识别中表现性能最好的建模框架,研究人员后续的改进都是基于对i-vector 进行优化,包括LDA、PLDA等。但以往的改进方式都是基于线性的方法,对模型的区分能力地提升有限。深度学习方法则提供了一种非线性的方式,通过对特征进行补偿操作,提高了特征的区分性。如Bhattacharya等提出了说话人分类器网 络(Speaker Classifier Network,SCN)用 于 对SRE2010数据集中的说话人建模,该方法是利用神经网络将i-vector 投影到相对高维的标签空间中,从而得到更具鲁棒性的说话人表示,以此提升i-vector 系统的性能[46];酆勇等人提出了基于深度独立子空间分析(Independent Subspace Analysis,ISA)网络,将度量学习的信息对约束和深度学习结合起来,有效降低信道差异对识别系统的影响[48]。
5 端到端联合优化
传统方法和embedding 的共同点,都是先从语音中提取出特征再做分类或者确认。与它们不同,端到端系统将两者合到一个系统,从输入到输出,一体化特征训练和分类打分。因此,端到端架构引起了人们的极大关注,并在说话人识别[50-58]中取得卓越的表现。本文基于卷积结构和循环结构介绍端到端结构的研究。
5.1 基于卷积结构的端到端网络
百度Deep Speaker在残差网络(Residual Networks,ResNets)的启发下,建立了深度残差卷积神经网络模型(ResCNN)[52]。具体是使用深度神经网络从话语中提取帧级特征;然后,池化层和长度归一化层产生说话人话语级的embeddings。使用Triplet loss[54]损失函数训练,最小化同一个说话人的embeddings 对的距离并最大化不同说话人的embeddings 对的距离;采用softmax 层和交叉熵进行预训练,优化模型。牛津大学模仿VGG(Visual Geometry Group),提出了VGGVox 网络结构,也采用了Triplet loss 损失函数训练网络,识别效果显著[53]。其中比较关键的一点在于使用Triplet loss 损失函数。
Triplet loss基本思路是构造一个三元组,由anchor、positive 和negative 组成,其中anchor 和positive 表示来自于同一个人的不同声音,negative 表示来自不同的人的声音,然后,用大量标注好的三元组作为网络输入,训练DNN参数。其优点在于直接使用embeddings之间的相似度作为优化的成本函数,最大化anchor 和positive的相似度,同时最小化anchor 和negative 的相似度。这样,在提取了说话者的embedding 之后,说话人识别任务就可以简单地通过相似度计算实现。
5.2 基于循环结构的端到端网络
与TE2E loss和Triplet loss相比,Generalized End-to-End(GE2E)loss 每次更新都和多个人相比,因此号称能使训练时间更短,说话人验证精度更高[55]。其基本思路是,挑选N 个人,每人M 句话,通过一定的顺序排列组合,接着通过LSTM RNN(Long Short-Term Memory Recurrent Neural Network)提取N×M 句话的embeddings,然后求取每个embedding 和每个人平均embedding 的相似度,得到一个相似度矩阵。最后,通过最小化GE2E loss 使得相似矩阵中有颜色的相似度尽可能大,灰色的相似度尽可能小,即本人的embedding 应该和本人每句话的embedding 尽可能相近,和其他人的embedding尽可能远离,从而训练LSTM RNN网络。
6 基于深度学习的说话人识别应用特性
以往的说话人识别算法采用的特征都是基于人类设计的,因此性能的好坏依赖于人类知识的认知程度,受限性很大。然而,深度特征无需先验知识,可以自主学习提取有效特征,其特点总结如下所示。
(1)鲁棒性
DNN 其特点是深层次的网络结构,逐层训练的方式使得DNN 的每一层能够在不同级别上提取特征,从而一步一步将简单的特征转化为更加复杂的特征,而这种分层特性可以提升特征的鲁棒性,克服复杂环境带来的干扰。
(2)迁移性
虽说现在数据量巨大,但大部分是没有标签的,并且目前对学习模型的要求是易构建、强泛化。深度学习方法具备的迁移性则可以很好地解决这些问题。在实际应用中,大部分数据或任务是存在相关性的,迁移性便是最大程度找到这些相似性,进而加以合理利用。
7 面临的问题与挑战
前文分析了近年来研究人员对说话人识别技术的研究成果。从研究现状来看,在实际应用中仍面临诸多问题。
(1)短语音
说话人识别系统的精度越高,建立特定说话人的模型所需的数据就越多。受实际环境的限制,不易获得用户长时间的语音数据,且短语音条件下获得的信息量太少,无法提取出充足的区分性信息。为此,关于短语音问题的研究陆续展开[44,57,59-60],如x-vector[44]采用具有时延架构的TDNN,可以在输出层学习到长时特征;加入attention学习机制[59-60],attention机制的作用原理实际上是特征选择,因为每段特征对说话人自身特征的贡献程度并非是均等的,attention 机制会自动选择出重要的特征,从而提升识别系统在短语音条件下的鲁棒性。
(2)背景噪声
噪声的存在会影响语音信号的质量,甚至淹没语音信号,目前应用的降噪算法是语音降噪和语音增强。然而这些算法虽然有效地提高了语音信号的信噪比,却忽略了对说话人的语音信息的保留,使得处理后的正确识别率没有明显的提高。近年来,研究人员也提出了一系列方案[28,49,61]。例如,多任务学习(multitask learning)提升鲁棒性[28];利用DNN学习含噪语音与干净语音i-vector之间的映射关系[49];对抗式训练(adversarial training)[61-62]从数据增强入手,既平衡样本类别的数量,又使得训练出的模型更具鲁棒性。
(3)信道失配
信道一直是影响说话人识别的最大因素之一,由于通信线路的复杂性以及通话设备的多样性,经常使得训练与测试语音信道失配,导致识别性能的急剧下降。目前解决信道失配问题的方法也有很多[42,46],如融合传统的手工统计特征和深度特征[42],非线性的神经网络代替WCCA补偿i-vector特征[46]。
8 结论与展望
本文首先叙述了说话人识别的任务模型、框架流程、传统算法,按照深度学习在说话人识别中的作用方式,将目前的研究分为基于深度学习的特征表达、基于深度学习的后端建模、端到端联合优化三种类别,并分析和总结了其典型算法的特点及网络结构,对其具体性能进行了对比分析。最后,总结了深度学习在说话人识别中的应用特点及优势,进一步分析了目前说话人识别研究面临的问题及挑战,并展望了深度学习框架下说话人识别研究的前景。
深度神经网络的优势在于不仅能够描述目标说话人的语音特征统计分布,更重要的是其注重描述不同说话人语音特征分布间的差异信息,所以其在解决说话人识别技术的鲁棒性问题方面表现出极大的潜力。随着研究人员对说话人识别领域的关注度越来越高,深度学习方法也在不断创新和改善,相信未来研究人员能提出更有效提升识别系统鲁棒性的方法,使得说话人识别可以大范围落地实现。
