改进YOLOv3在航拍目标检测中的应用
2020-04-07魏玮,蒲玮,刘依
魏 玮,蒲 玮,刘 依
河北工业大学 人工智能与数据科学学院,天津300401
1 引言
航拍目标检测在车辆检测、远程目标追踪、无人驾驶等领域有着十分重要的应用[1]。随着计算机视觉、人工智能技术的迅速发展,在众多的目标检测算法中,基于深度学习的方法因其无需特征工程,适应性强,易于转换等特点得到了较为广泛的应用[2]。目前通过深度学习来解决目标检测问题的方法主要有两种:两阶段(two-stage)检测模型与单阶段(one-stage)检测模型[3]。两阶段模型因其对图片的两阶段处理过程得名,也称为基于区域的检测方法,主要包括R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]、R-FCN[7]等。两阶段方法的检测精度虽然很高,但耗时过长,难以达到实时检测的效果。为了平衡检测速度与精度,单阶段检测模型被提出。抛弃了粗检测与精检测结合的思想,经过单个阶段的检测即可直接得到最终检测结果,因此有着更快的检测速度。单阶段检测方法也称为基于回归的方法,无需区域提取过程,直接从图片获得预测结果,实现了端到端的目标检测。主要包括YOLO[8]、SSD[9]、YOLOv2[10]、YOLOv3[11]等系列方法。
目前来看,YOLOv3方法维持了检测速度与精度间的较好平衡。国内外很多研究学者将其应用到目标检测领域,并针对具体问题提出了不同的改进方案。Benjdira 等[12]使用航拍汽车数据集对YOLOv3 和FasterRCNN 进行对比,证明了在精度相当的情况下,YOLOv3在灵敏度和处理时间上均优于FasterR-CNN 算法。Kharchenko 等[13]将YOLOv3 算法应用到无人机或卫星拍摄图像的地面目标检测问题中,实现了较高的检测能力和实时检测速度。李耀龙等[14]将简化的Tiny-YOLO[15]算法应用到飞机目标检测中,提高了检测速度。戴伟聪等[16]将YOLOv3算法应用于遥感图像中的飞机检测,加入密集相连模块,并结合多尺度特征检测,提高了飞机检测的精度和召回率。
本文将YOLOv3 算法应用于无人机航拍图像的目标检测领域,为提高算法的适用性和准确性,对YOLOv3算法进行改进。使用K-Means[17]方法对航拍数据集标签进行维度聚类,计算最优的宽高值并由此对YOLOv3中的anchor 进行修改。针对航拍数据集中检测目标大小不一,以及小目标分布过于密集的情况,对YOLOv3 算法的网络结构进行改进,在保证检测速度的前提下,使算法的检测精度得到了较大提升,加快收敛速度并减少了参数计算量。
2 YOLOv3算法
YOLOv3 算法是Redmon 等于2018 年在YOLOv2的基础上提出的,使用全卷积网络(Fully Convolutional Network,FCN)[18],结合了残差网络ResNet[19]中的跳跃连接和特征金字塔网络(Feature Pyramid Networks,FPN)[20]等算法思想,用步幅为2的卷积层替代池化层完成对特征图的下采样,同时在每个卷积层后增加批量归一化操作(Batch Normalization,BN)[21]并使用激活函数LeakyRelu[22]来避免梯度消失及过拟合,通过残差结构加深网络层数,形成了53层的骨干网络DarkNet-53。针对YOLOv2中由于下采样造成的细粒度特征丢失问题,仿照FPN设计了多尺度预测网络,采用3个不同尺度的特征图来进行位置与类别预测,有效提高了目标检测的准确率。YOLOv3的网络结构如图1所示。
首先,YOLOv3将输入图像缩放至416×416,把图像划分为S×S 个网格。每个网格负责预测中心落入该网格的目标,并计算出3个预测框。每个预测框对应5+C个值,C 表示数据集中的类别总数,5 代表预测边界框的属性信息:中心点坐标(x,y)、框的宽高尺寸(w,h)和置信度(confidence)。网格预测的类别置信度得分为:
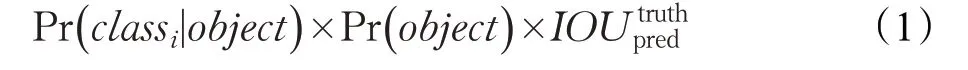
其中,若有目标中心落入该网格,则Pr( obj ect )=1,否则Pr( obj ect )=0。Pr( cla ssi|object )为网格预测第i 类目标的置信概率。IOU truthpred 为预测边界框与真实框的交并比(Intersection Over Union,IOU)[23]。
最后,使用非极大值抑制(Non-Maximum Suppression,NMS)[23]算法筛选出置信得分较高的预测框,即为检测框。
在损失函数中,YOLOv3算法将方差损失改为交叉熵损失。在置信度和类别预测中,考虑到某一目标可能属于多个类别,YOLOv3 对检测目标执行多标记分类,舍弃softmax 分类方法,采用多个独立的逻辑分类器来预测类别分数,并设置阈值预测目标的多个标签。
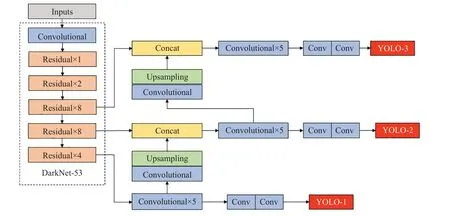
图1 YOLOv3网络结构
YOLOv3与其他常用目标检测框架效果对比如表1所示,可以看出YOLOv3能够在检测精度和速度上取得较好的平衡。
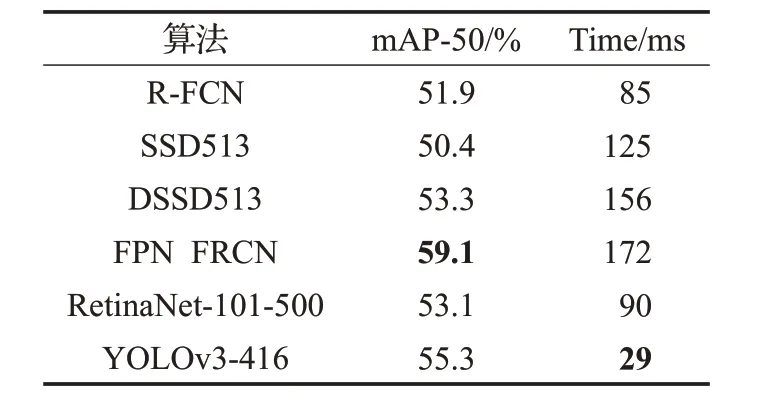
表1 YOLOv3与其他框架效果对比
3 改进YOLOv3算法
YOLOv3 算法在MSCOCO、PASCAL VOC 等数据集上表现良好,但本文所使用的航拍数据集,实例种类众多,且实例间的分布十分密集,这给检测任务带来了较大挑战。因此要针对航拍数据集进行目标检测任务,就需要对YOLOv3 算法做出相应改进,以适应特定的需求。
3.1 对锚点进行参数优化
受Faster R-CNN 算法中提出的锚点机制启发,YOLOv3 算法中也引入了anchor 机制。早期的anchor值由经验确定,而Redmon 在YOLO 系列算法中提出使用K-Means 聚类方法来获取anchor 值。在目标检测任务中,合适的anchor取值能够提高检测任务的精度与速度。YOLOv3 算法中使用的anchor 是根据COCO 和VOC数据集训练所得,这9组anchor值分别是(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90),(156,198),(373,326)。但如图2 所示,对于本文使用的航拍数据集来说,COCO 与VOC 数据集中的实例尺寸过大,对应anchor值也偏大,不适用于本数据集,因此需要重新进行维度聚类,选取合适的anchor 参数,对航拍数据集进行更好的预测。
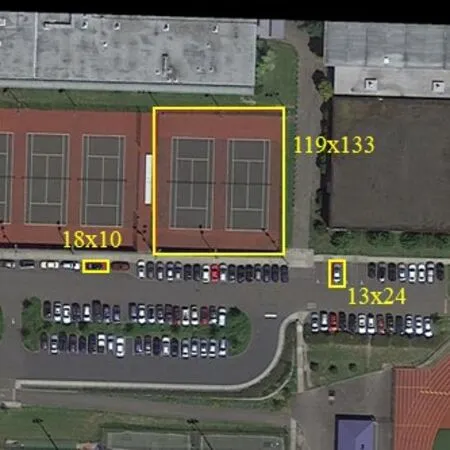
图2 目标检测框的尺寸
考虑到在目标检测任务中,聚类的目的是使先验框(anchor box)与正确标注(ground truth)的IOU 值尽量大,因此距离度量的目标函数不使用欧氏距离,而是采用IOU作为衡量标准,度量函数的公式如下:
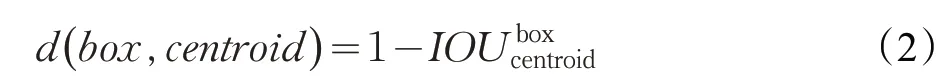
其中,box 为样本标签的目标框,centroid 为聚类中心。IOU 越大,距离越小。
按照上述方法,在航拍数据集中使用K-Means 算法重新对实例的标签信息进行聚类分析,得到的9 组anchor值为:(10,14)、(26,13)、(21,26)、(51,34)、(31,58)、(63,190)、(76,77)、(148,128)、(275,282)。将这些anchor 按照面积从小到大的顺序分配给3 种尺度的特征图,尺度较大的特征图使用较小的anchor 框,每个网格需计算3个预测框。
预测时采用直接预测相对位置的方法,如图3 所示,公式如下:

其中,cx和cy表示的是每个网格的左上角坐标。pw和ph表示anchor映射到特征图中的宽高值。tx、ty、tw、th是网络需要学习的目标。
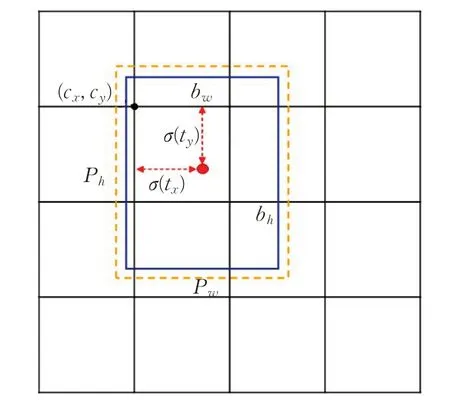
图3 边框预测
3.2 网络结构改进
3.2.1 DarkNet-53网络
YOLOv3 中使用的特征提取网络是DarkNet-53,网络结构如图4所示。该网络在DarkNet-19的基础上,融合了ResNet 残差网络跳跃连接的思想,去掉池化层和全连接层,使用卷积层完成池化和上采样操作。Dark-Net-53 中主要用到的是大小为3×3 与1×1 的卷积核,其中3×3卷积核主要负责增加通道数,而1×1卷积核用于压缩3×3 卷积后的特征表示,加深网络深度的同时,提高了网络的性能。
3.2.2 改进YOLOv3
在DarkNet-53 中,虽然加深网络深度使特征提取能力得到了提高,但过多的下采样及卷积操作会出现较小实例特征消失的情况。此外对于航拍数据集来说,实例间的尺寸大小相差悬殊,难以平衡检测精度与特征大小。针对上述问题,增大图像输入尺寸,减少卷积层数并加入跳跃连接,降低小目标漏检率,并提高不同尺寸实例的检测精度。改进YOLOv3 网络结构如图5(a)所示。
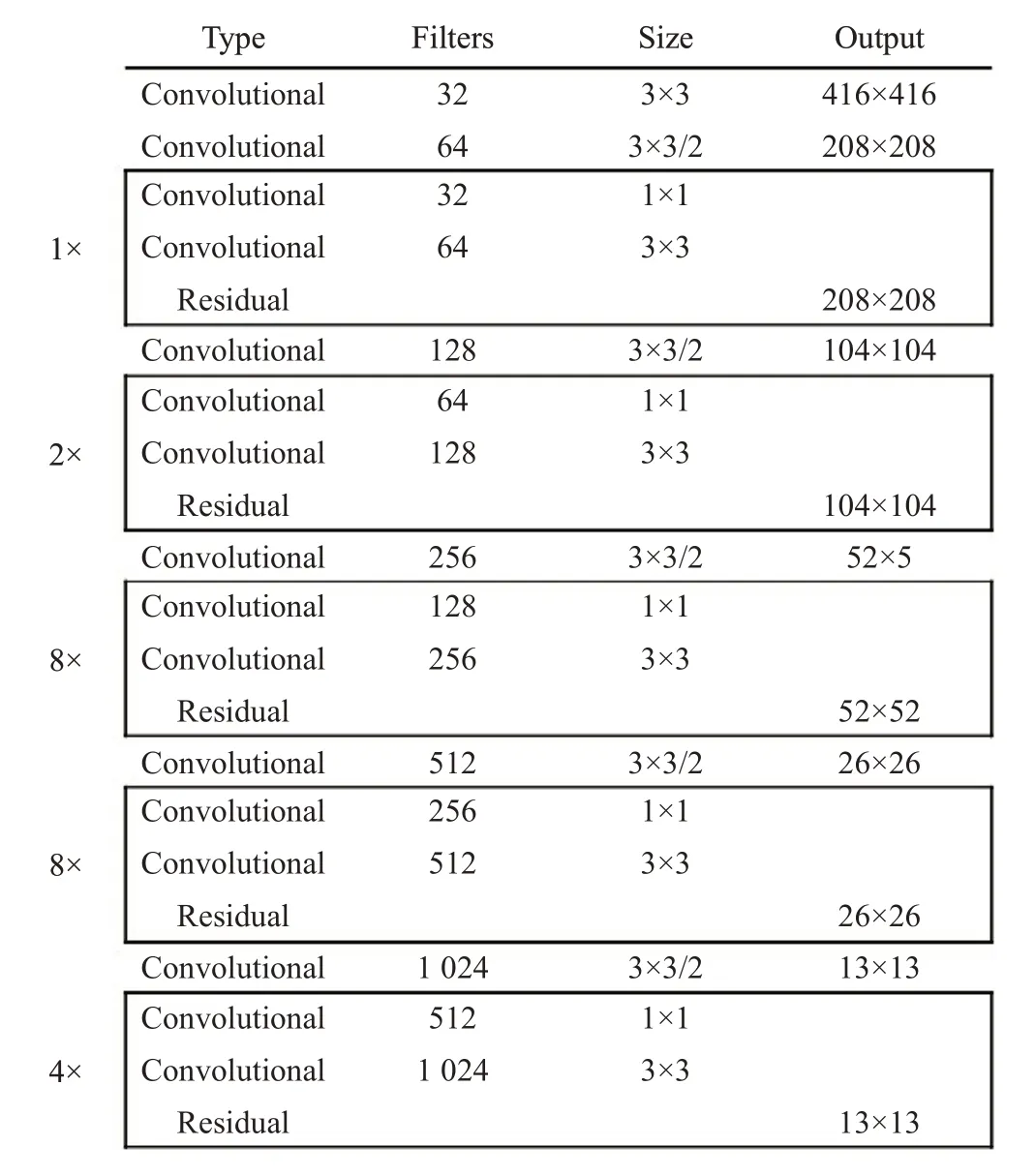
图4 DarkNet-53网络结构图
首先修改输入图像的尺寸,将原尺寸为416×416的三通道输入图像增大至608×608,确保多次下采样操作后,较小尺寸的实例不会出现特征消失的情况,降低复杂场景下小目标的漏检率。然后使用修改的DarkNet-53作为特征提取网络,经过5 次下采样后,特征图大小依次变为304×304、152×152、76×76、38×38、19×19。沿用特征金字塔的思想,分别使用3个尺度的特征图进行预测,即先对74 层处19×19 的特征图进行处理后,送入检测较大尺度的YOLO层,同时将该尺度特征图上采样后与61层处38×38的特征图进行拼接操作,送入检测中间尺度的YOLO 层。最后对当前尺度的特征图进行上采样,与36层处76×76的特征图拼接后送入检测小尺度的YOLO 层。多尺度特征检测能够较好的平衡不同尺寸实例的检测情况。其中,如图5(b)所示,在每个YOLO层进行位置和类别预测之前,减少相连卷积层数量,使用3×3与1×1的卷积进行特征维度转换,并引入残差网络跳跃连接的思想进行连接,缓解随网络层数加深而引起的效果退化问题。
4 实验与分析
4.1 数据预处理
本文使用的航拍图像数据主要来源于DOTA[24]数据集,包含15 类目标:飞机、船只、储蓄罐、棒球场、网球场、篮球场、田径场、海港、桥、大型车辆、小型车辆、直升飞机、英式足球场、环形路线和游泳池。
本文实验的数据预处理过程主要包括两个部分:图像预处理与标签格式转换。
航拍图像的尺寸很大,通常在800×800~4 000×4 000 像素之间,基于卷积神经网络的特征提取网络无法直接使用,因此将原始图像统一按照512的步幅裁剪为1 024×1 024 大小。考虑到裁剪过程中目标可能会被切分成两部分,故对切分后的目标与原目标求面积比,比值小于0.8 的部分定义为新目标。裁剪处理后共计12 260 张图像,其中8 582 张作为训练集,3 678 张作为测试集。训练集中各类别目标的图像数量分布如图6所示。
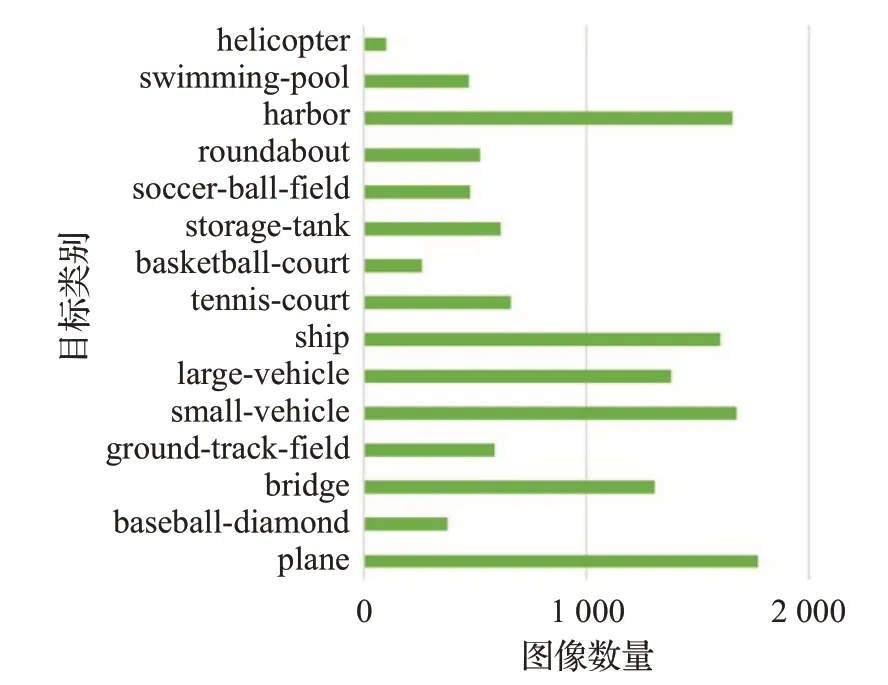
图6 训练集中各类别目标图像的数量
DOTA数据集中使用的是任意四边形边界框,标签为顺时针排列的边界框的四个顶点坐标。但本文改进YOLOv3 方法需要的数据标签格式为x、y、width、height,其中x、y 为原任意四边形的外接矩形边界框的中心点坐标,width、height 为此边界框的长和宽。因此对原数据格式进行如下变换:

其中,xmax、xmin分别为x 坐标中的最大、最小值,ymax、ymin分别为y 坐标中的最大、最小值。使用时需要对这4个值进行归一化处理。
4.2 网络训练
本文使用DOTA数据集的航拍图像进行训练。实验基于Pytorch 深度学习框架,使用方法为改进YOLOv3算法,训练与测试均在NVIDIA 1070Ti 显卡、CUDA9.0上进行。经实验验证,在此数据集上使用迁移学习进行训练的效果较差,因此使用YOLOv3的官方权重作为网络训练初始化参数。本文改进方法的部分实验参数设置如表2所示。
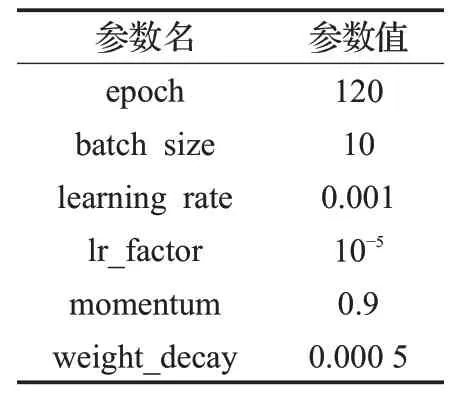
表2 部分实验参数
4.3 实验结果及分析
随着训练epoch数量的增加,对比的loss曲线如图7所示,橙色线条代表原算法曲线,蓝色线条为本文改进方法曲线。横坐标表示训练轮数,纵坐标为训练过程中的loss值,其中,loss值为坐标损失、边界框长宽损失、置信度损失和类别损失值的总和。

图7 loss曲线
由图7 可以看出,原算法的初始损失值较大,约为7.86,而改进算法的初始损失函数值较小,在3.24 左右。前期二者的损失值均下降较快,随着训练轮数的增加,loss 曲线逐渐降低,趋于平稳。当epoch 达到120 左右时,改进方法的损失值在前几个epoch 就已经降至1以下,最终稳定在0.294左右,而原算法的值约为0.536。可以明显看出,相比原算法,改进方法的效果更佳,显著提高了收敛速度并降低了损失值。
图8 为120 轮左右的mAP 和F1,其中橙色线代表YOLOv3 算法的效果,蓝色线表示本文的改进算法。YOLOv3 的mAP 在51%左右,而本文改进算法的mAP可达65%左右。因此相比原方法,本文改进方法在检测精度及检测效果方面均得到了较大提升。
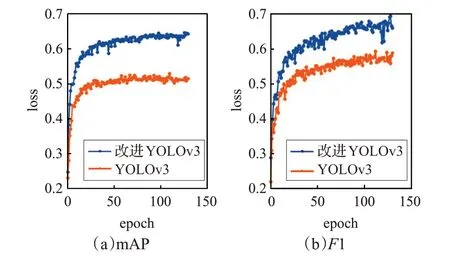
图8 实验结果图
表3为使用本文改进YOLOv3算法时,测试集中各类别目标的mAP与F1 值,其中过长的类别名称用单词首字母简写表示。表3显示,本文改进方法在航拍数据集上的mAP 可达65.5%,F1 为0.257。其中尺寸较大、分布稀疏的目标,如网球场(tennis-court)、飞机(plane)的检测效果较好。而尺寸较小且分布过于密集的实例,如船只(ship)的检测效果仍相对较低。

表3 本文算法检测效果
图9 为算法改进前后的检测效果对比图。使用同一组测试图片,第一行使用的是YOLOv3 算法,第二行是本文改进方法。可以看出,图9(a)组图片中,改进方法比原算法多检测出了外圈环形跑道。图9(b)组图片中目标尺寸较大且分布稀疏,YOLOv3 只检测出了2个港口harbor,而本文改进方法检测出了4个,其中较小的目标船只(ship)也没有发生漏检情况。图9(c)组图片,由于图中的目标主要是尺寸较小且分布过于密集的船只,因此检测效果相对来说都不是很好。YOLOv3方法检测出98 个船只和11 个港口,改进方法检测出112 个船只和11 个港口,在图片右下角的位置密集分布了很多尺寸更小的实例,原算法没有检测出任何目标,但本文的改进方法检测出了部分船只。
使用SSD、Faster R-CNN、YOLOv3、Tiny-YOLOv3以及本文改进算法进行对比,结果如表4所示。
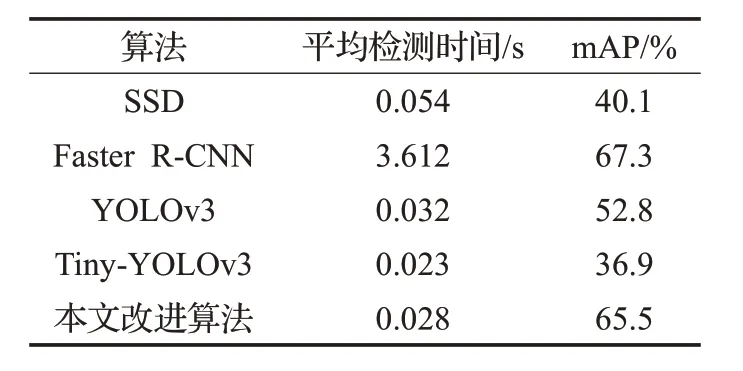
表4 不同算法检测结果对比
由图9和表4可见,改进的YOLOv3算法与原YOLOv3相比,平均检测时间减少了37 ms,mAP提高了12.7%,且在一定程度上缓解了小目标的漏检情况。Tiny-YOLOv3算法的检测速度较快,但精度很差。YOLOv3的检测准确率比Faster R-CNN 稍差,但检测速度约为其129 倍。而SSD 算法无论在检测精度还是检测速度上都较差。因此,本文改进的YOLOv3算法在实时性及检测精度上达到了较好的平衡,效果更佳。
5 结束语
本文将YOLOv3 算法应用到航拍图像的目标检测中,针对航拍图像中目标尺寸大小不一且分布不均的问题,使用K-Means 聚类方法优化参数,并提出了改进YOLOv3 算法,在保证实时检测速度的前提下,提高了航拍图像的目标检测效果。改进方法比原方法的mAP提高了12.7%,在加快了收敛速度并降低了漏检率的同时提高了检测准确性。
由于本文改进方法对航拍图像中尺寸较小、分布过于密集的目标仍存在检测上的局限性,因此下一步将结合旋转边界框的思路进行进一步的深入研究。
