表示学习中句子与随机游走序列等价性的一种新证明*
2020-03-04孙茂松赵海兴冶忠林
孙 燕,孙茂松,赵海兴,冶忠林
(1.青海师范大学计算机学院,青海 西宁 810016;2.清华大学计算机科学与技术系,北京 100084; 3.青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008; 4.藏文信息处理教育部重点实验室,青海 西宁 810008;5.青海民族大学计算机学院,青海 西宁 810007)
1 引言
表示学习是机器进行数据挖掘和数据推荐的基础。表示学习可以通过神经网络训练学习数据特征,并将数据及其关系映射到低维度向量空间中。目前表示学习有词表示和网络表示学习,分别应用于自然语言处理和社交网络的研究中。词表示学习是通过算法学习建模句子中当前词语及其上下文词语之间的关联关系,而网络表示学习是通过算法建模当前节点与邻居节点之间的关联关系。
词表示学习中经典的方法是word2vec词向量[1],word2vec是2013年由Google的Mikolov团队提出的用来生成语言模型的工具。它是用浅层的神经网络训练并重构语言学的词和上下文关系的语言模型。
Mikolov等[1]提出word2vec语言模型可以用 CBOW和Skip-Gram 2个浅层的神经网络模型训练,并有2个优化方法Hierarchical Softmax和 Negative Sampling加速词向量训练速度。
Levy等在文献[2]中证明了word2vec中负采样Skip-Gram模型SGNS(Skip-Gram with Negative-Sampling)[1]是对移位正定(非负)互信息SPPMI(Shifted Positive Pointwise Mutual Information)[2]的隐式分解,其中SPPMI矩阵是统计词和上下文共同出现概率的矩阵,它是对PMI(Pointwise Mutual Information)矩阵的改进。因为互信息是一个比值,还要进行对数运算,分母不能为零,所以计算互信息时需使PMI 矩阵正定,即PPMI矩阵,如果节点采样时用负采样,互信息矩阵改进为SPPMI矩阵,进一步加快计算速度。
网络表示学习中经典的算法是DeepWalk算法,该算法是Perozzi等[3]提出的网络表示学习模型,将网络节点关系映射到低维度的向量中,以便人们更好地研究各种复杂网络。DeepWalk算法可使用Skip-Gram模型建模网络节点之间的关系,并可采用Negative Sampling方法优化和加速网络建模过程。但是,与word2vec不同的是,DeepWalk用随机游走获取了网络上节点的关系序列,所以Perozzi等认为随机游走序列等同于语言模型中的句子。
文献[4]证明DeepWalk算法本质是一种隐式的矩阵分解算法,其通过分解矩阵M=(A+A2)/2代替DeepWalk算法中被分解的矩阵Mij,即Mij是网络随机游走矩阵A组成的,A表示网络随机游走转移概率矩阵,矩阵A的每个元素的物理意义是顶点vi和随机游走到其他顶点vj的概率, 定义矩阵A的每一个元素为Aij=1/di,其中di是节点的度[4]。
有趣的是文献[2]证明了word2vec中的SGNS框架是隐式矩阵分解SPPMI矩阵;文献[4]证明了DeepWalk算法是在网络表示中利用了word2vec中负采样Skip-Gram框架(SGNS框架), 而word2vec中的SGNS框架是被Levy等在文献[2]中证明了隐式分解矩阵的框架,所以基于上述事实,显然可以得出2个结论:
第1,由于自然语言处理的词可以看作是复杂网络表示学习网络中的节点,所以在自然语言处理中基于词向量的SGNS模型既可以训练语言模型,也可以训练网络表示学习模型。
第2,SGNS框架在复杂网络表示学习学科和自然语言处理的词表示学习中都被证明是隐式的矩阵分解,只是SGNS框架分解的目标矩阵不同。词表示学习中SGNS模型分解的是互信息SPPMI矩阵,其中SPPMI矩阵是表示词和上下文之间关系的矩阵。网络表示学习中SGNS分解的是随机游走M矩阵,其中M矩阵是表示网络随机游走序列中节点之间关系的矩阵。
Perozzi等[2]在文献中提到了网络随机游走序列等同语言中的句子(移位正定互信息),他从以下2方面说明:(1)网络节点无标度,大多数复杂网络研究者认为无标度网络节点具有幂律分布特性,即网络中度大的节点比较少,度小的节点比较多;(2)语料中的单词词频符合Zipf规律(幂律),即语言中常用词很少,很多词不常被使用,并给出了2个数据实例:
第1个是YouTube网络。YouTube是社交网络,社交网络是无标度网络[2],无标度网络的节点是符合幂律分布的;
第2个是维基百科的语料库,并统计了语料库中单词出现的频率,结果发现词频符合Zipf幂律规则。
但是,基于词频和节点频率符合幂律从而证明随机游走序列等同于句子是不充分的,原因有下面3点:
(1)仅从基于网络节点度服从幂律与自然语言中词频服从幂律,就将网络中随机游走序列等同于自然语言中的句子[3],理论上并没有严格的证明,这样的类比是牵强的;
(2)这种类比没有比较实验做支撑;
(3)到目前没有其他文献比较过2者是否等同。
那么,语言模型中分解SPPMI矩阵和网络表示学习中分解的M矩阵是否存在等价关系?即句子是否等同随机游走序列?本文旨在通过实验验证随机游走序列和句子的等同性。
2 相关工作
本文用奇异值分解SVD(Singular Value Decomposition)方法[5 - 7]和诱导矩阵补全IMC(Inductive Matrix Completion)方法验证句子和游走序列的等同性。
(1)用SVD方法分解SPPMI矩阵与M矩阵。
(2)用IMC方法也分解SPPMI矩阵与M矩阵。
基于以上2个对比实验,本文从理论上基于自然语言处理方面和网络表示学习方面的相关文献,设计了2个实验进行命题实证,如果网络节点分类准确率几乎相等或近似,则认为网络随机游走序列等同于句子。如果实验结果差异较大,则2者不等同。这种等价可以作为自然语言表示学习和网络表示学习的桥梁,也为学习潜在的表示时提供相互借鉴。
3 词向量模型和隐式分解
3.1 word2vec模型
word2vec是自然语言处理中语言建模及语言特征学习的模型和技术。从语料库中将单词映射到实数空间的向量被称为词向量。word2vec用大文本语料作为其输入,将语料库上千万维的单词映射到几百维的实数向量空间中。这样语料库中语义相近的单词,其词向量也会很接近。word2vec的SGNS模型目标函数[1]如式(1)所示。

(1)
(2)
其中,σ是激活函数,k是采样率,W是词矩阵,w为W中的词向量,Wc是上下文矩阵,c是Wc样本单词的上下文向量,|D|是词典大小,·是向量的点积。
3.2 word2vec隐式分解
对目标函数求导并极值优化,由互信息的概念:
得到
(3)
式(3)说明PMI是一对离散结果(词和上下文)之间的信息理论关联度量,PMI值取了词和上下文共同出现的联合概率与它们独立出现的概率之间的比值的对数,计算PMI矩阵是挑战性的工作,如果考虑一个单词和这个词的上下文没有共同出现的概率(如考虑的词是“数据”,“大数据会议”是数据的上下文),则矩阵MPMI的行包含许多从未观察到的词对或者只出现1次的词对,那么在语料库中只出现1次的词对(如“大数据会议”),这样做会导致PMI值为负,而对于未观察到的1对单词(如“数据结构”),PMI值会出现PMI(w,c)=log 0=-∞的情况,这种情况下的PMI矩阵定义不明确,大的语料库不仅密集且尺寸|VW|×|VC|很大,|VW|是词矩阵的维数,|VC|是上下文矩阵的维数,文献[2]将PMI构造为正定的PMI(PPMI)并取最大,得到:
PPMIk(w,c)=max(PMI(w,c),0)
(4)
利用移位的负采样可以显著改善由PMI矩阵得到的嵌入词的表示向量,k为构造PMI值的采样窗口值,所以如果设k>1,式(4)得到的矩阵将不包含任何无限值,从而使文档中所有的单词和上下文对被观察到,这样移位非负逐点互信息矩阵SPPMI为:
SPPMIk(w,c)=max(PMI(w,c),-logk,0)
(5)
4 网络表示学习模型和隐式分解
4.1 DeepWalk模型目标函数
DeepWalk使用随机游走来获取网络的结构,即假设网络采样是从网络中任意一个节点随机游走到另一个节点,DeepWalk算法是将网络节点及上下文的关系映射到实数空间的算法,其中网络节点在算法中表示为网络节点的表示向量。如果网络空间中节点彼此接近,则网络节点向量也会很近似。DeepWalk的SGNS模型目标函数[4]为:
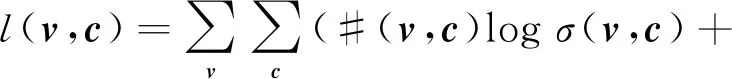
(6)
(7)
其中,σ是激活函数,k是采样率,v是网络节点的表示向量,c是网络节点的上下文向量,|D|是节点集合的大小,·是向量的点积。可以看出式(7)与式(1)中word2vec的SGNS目标函数是一致的。
4.2 DeepWalk隐式分解
文献[4]证明了DeepWalk本质上是对矩阵Mij的分解。作者将诱导矩阵补全的优化函数变换为式式(8):
(8)
其中,矩阵A是随机游走矩阵[8],t为随机游走步数。
(9)
其中,Aij表示一步转移矩阵的元素,(i,j)是从i到j点的边,(i,j)∈E。
假设di是顶点i的度,随机游走从节点i开始,ei表示顶点i的初始状态,式(8)相当于[eiA]j,该项表示从顶点i的初始状态走一步到顶点j的概率,[eiAt]j项表示顶点i从初始状态恰好以t步游走到顶点j的概率,其中At是随机游走概率矩阵,于是随机游走的过程可用式(10)表示:
[ei(A+A2+…+At)]j
(10)
从式(10)发现,精确计算Mij矩阵,计算代价高,Yang等[4]用近似矩阵M代替Mij实现,如式(11)所示:
(11)
这样的替代对网络节点分类[9]的正确率影响不是很大,而且可以加快计算速度。
5 word2vec和DeepWalk的关系
实际上DeepWalk也可以使用word2vec的CBOW模型和Hierarchical Softmax优化方法,底层的模型如图1所示。
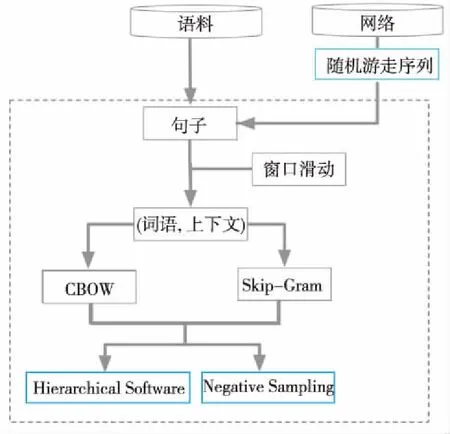
Figure 1 Model of word2vec and DeepWalk图1 word2vec和DeepWalk的共同底层模型
窗口滑动用于词或节点对采样。word2vec的2个神经网络模型CBOW和Skip-Gram实现训练的思路是不一样的,Skip-Gram神经网络模型是根据当前词出现的概率预测与它对应的上下文词语概率的模型。CBOW神经网络模型是一种根据上下文词语预测当前词语出现的概率的模型。Hierarchical Softmax优化方法是词向量训练时将神经网络的输出Softmax层的概率计算,用一棵霍夫曼树替代,那么Softmax概率计算只需要沿着树形结构进行统计训练。在霍夫曼树中,隐藏层到输出层的Softmax映射不是直接一步完成的,而是沿着霍夫曼树一步一步完成的,因此这种Softmax取名为Hierarchical Softmax。使用霍夫曼树编码方法,既可以提高模型训练的效率,也可以减少词向量存储空间。但是,如果训练样本里的中心词w是一个很生僻的词,那么会使得霍夫曼树的训练时间变得很长。于是Negative Sampling优化方法摒弃了霍夫曼树,采用了负采样的方法来加速词向量训练。
而文献[3]中证明了word2vec中的SGNS相当于分解SPPMI矩阵,文献[4]中证明了DeepWalk中的SGNS相当于分解M矩阵,在网络表示学习中,DeepWalk算法采用了Skip-Gram模型和 Negative Sampling优化方法,它是自然语言处理word2vec词向量里的模型用在网络表示学习DeepWalk算法里了,所以也可以使用word2vec模型中训练模型和优化方法的其他组合。工程和研究人员可以根据不同目的去选择训练模型和优化方法。
6 句子和随机游走等同的实例证明
本文设计了2个实验,实验流程如图2所示。
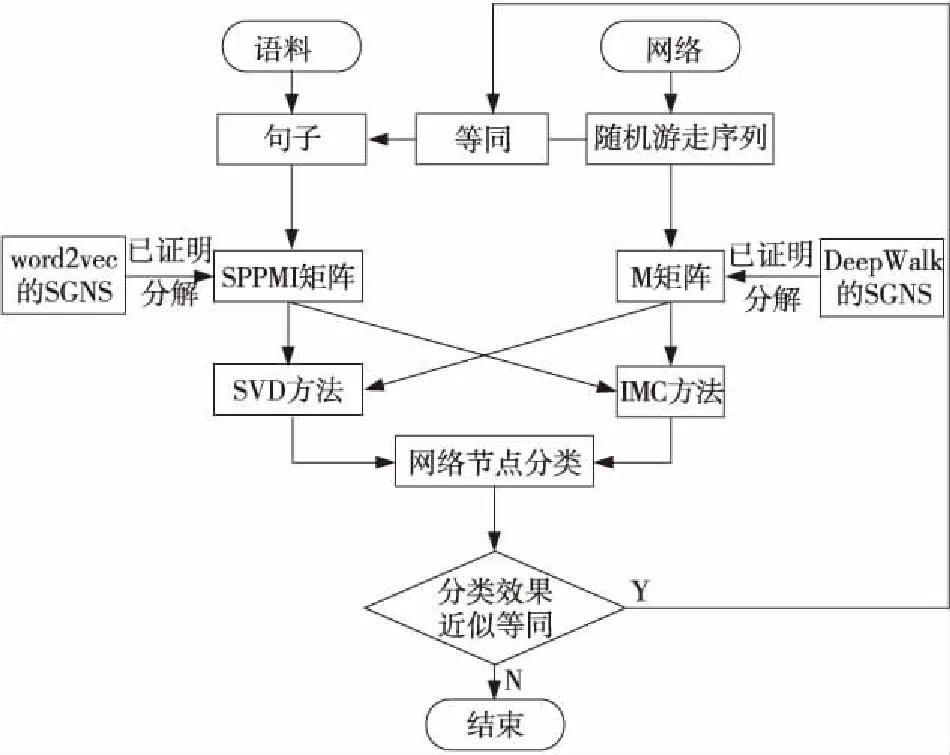
Figure 2 Flow chart of comparative experiment图2 对比实验流程图
文献[3]和文献[4]都用到了矩阵的隐式分解,但是它们使用的矩阵分解方法是不同的,1种方法是奇异值分解(SVD),另1种方法是诱导矩阵补全(IMC)[10]。
第1种方法:奇异值分解SVD。文献[3]使用SVD将SPPMI矩阵分解如下:
MSPPMI=U·Σ·VT⟹
(12)
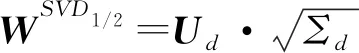
第2种方法:诱导矩阵补全(IMC)[10,12],它使用了基因特征辅助矩阵X∈Rd1×m和疾病特征辅助矩阵Y∈Rd2×m分解基因-疾病目标矩阵M∈Rm×n,它的优化目标函数如式(13)所示:
(13)
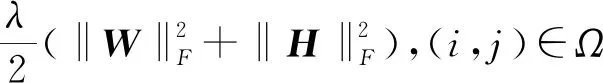
文献[12]中利用了诱导矩阵补全(IMC)算法,将文本信息加入到诱导矩阵中,文献[4]用简化的矩阵M代替了DeepWalk算法中的矩阵Mij,从而得到了准确率更高的网络节点表示向量,他的算法名为TADW(Text-Associated DeepWalk),TADW算法相当于IMC方法分解随机游走矩阵。而采用诱导矩阵补全,可将网络节点的文本属性构造成文本特征矩阵,让网络结构学习包含更多的网络节点信息[12],使分类任务准确率更高。本文基于TADW算法进行了改进,用诱导矩阵补全对SPPMI矩阵进行分解,并与分解M矩阵[13 - 18]进行对比。
7 实验与结果
本文设计了2个实验用于验证本文的命题:
(1)用SVD分解SPPMI矩阵和网络随机游走构造M矩阵,并在数据集上进行网络节点分类性能测试。
(2)用IMC方法分解矩阵W和H,具体实现时本文针对文献[12]进行改进,用诱导矩阵补全方法对M矩阵和SPPMI矩阵分解(本文将改进对比的算法标为STADW),并在数据集上进行网络节点分类性能测试。
实验设置:对于3个社交网络的数据集Citeseer,Cora和Wiki[16 - 18],实验设置的参数为:表示向量维数为128,数据集的数据训练比例是10%,30%,50%,70%,90%,负采样率为5。实验结果如表1~表3所示。表中的M和SPPMI分别代表只分解M和SPPMI矩阵后分类算法。
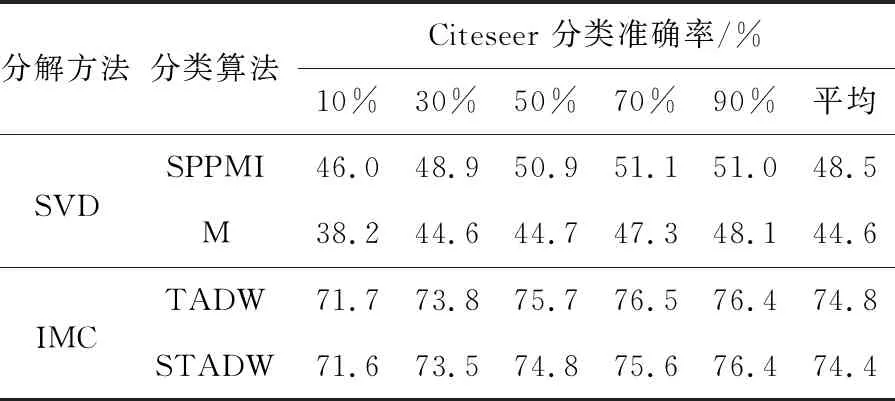
Table 1 Classification experiment by various methods on Citeseer data set表1 数据集Citeseer上各种方法分类实验
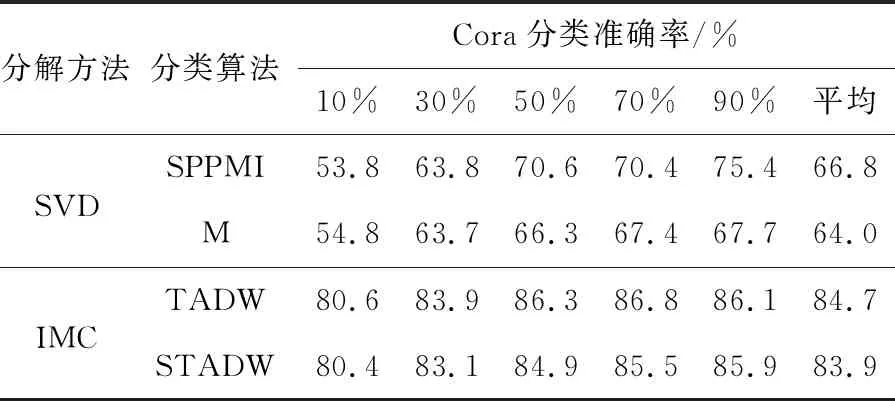
Table 2 Classification experiment by various methods on Cora data set 表2 数据集Cora上各种方法分类实验
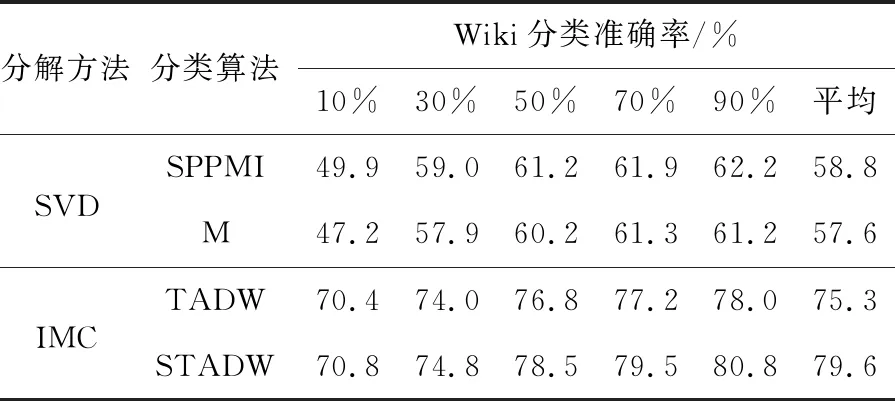
Table 3 Classification experiment by various methods on Wiki data set 表3 数据集Wiki上各种方法分类实验
对比实验是在3个公开的社交网络数据集上进行的,数据集的类别已分好,对比实验为奇异值分解(SVD)和诱导矩阵补全(IMC)2种方法对社交网络数据集的网络节点的进行分类。使用的3个数据集为Citeseer,Cora和Wiki。 其中引文数据集Citeseer是有6个类别的3 312种出版物,共有4 732条边的数据集; 引文数据集Cora集有7个类别的2 708篇机器学习论文,共有5 429条链接的边。Wiki数据集包含来自19个类2 405篇文档共有17 981条边。
比较表1~表3的数据,可以看出在3个数据集上,奇异值分解SVD方法的2行数据相差0.01,在诱导矩阵补全方法上,TADW 和STADW的2行数据相差0.03。
本文还研究了不同向量维数的IMC方法和SVD方法网络节点分类的正确性,如图3~图5所示。
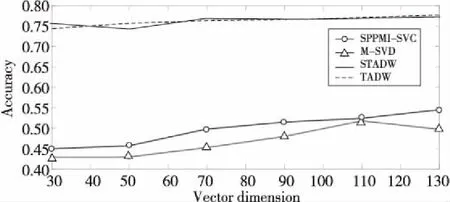
Figure 3 Comparison of classification accuracy on Citeseer data set图3 数据集Citeseer上分类准确率对比
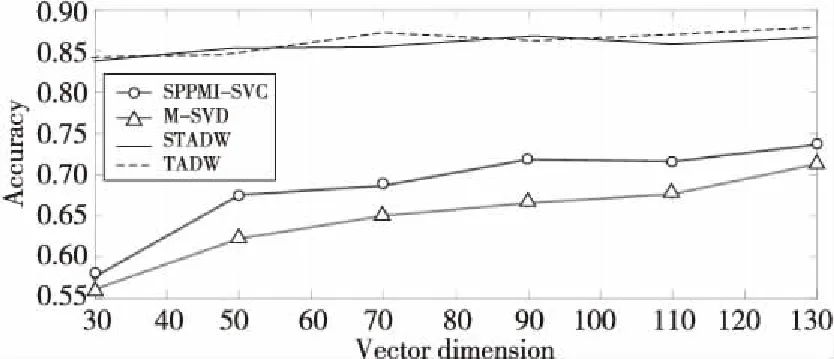
Figure 4 Comparison of classification accuracy on Cora data set图4 数据集Cora上分类准确率对比
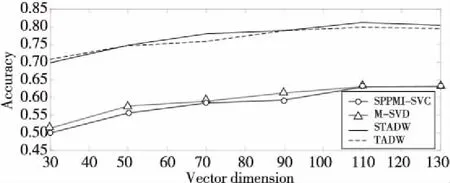
Figure 5 Comparison of classification accuracy on Wiki data set图5 数据集Wiki上分类准确率对比
图3~图5 分别表示在3个数据集上用2种方法(SVD和IMC)分解M矩阵和SPPMI矩阵的结果。实验设置为:表示向量维数为30,50,70,90,110和130,需要注意的是,在TADW与STADW算法中学习得到的网络表示向量维数需要在上述表示向量维数上乘以2,为了直观表示,在图3~图5中对这2种算法并没有乘以2,实验数据集的数据训练比例取0.9,负采样率k为5。
从图5~图7可知,SVD方法和IMC方法准确率差距浮动值为1%,一般的准确率差距浮动值不超过5%,准确率是可信的,直观地从图3~图5的上半部分的实线和虚线及图3~图5的下半部分的带圈线和带三角形线可观察到。
实验用2种方法(即SVD和IMC)对M矩阵和SPPMI矩阵分解,并在不同的表示向量的维数下研究句子和随机游走的等同性,从表1~表3和图3~图5都能明显观察出随机游走和句子等同,证明了本文提出的命题。
8 结束语
本文在对词表示学习[19 - 22]和网络表示学习理论研究基础上,发现它们可以采用相同的SGNS模型。而 SGNS模型在词表示学习[22 - 30]领域和网络表示学习领域都已经被证明是隐式地分解目标特征矩阵,只是在这2个领域中分解的目标特征矩阵不同,即词表示学习中SGNS模型分解的是SPPMI矩阵,分解SPPMI矩阵相当于神经网络建模语句中词语之间关系的过程,网络表示学习中SGNS分解的是M矩阵,相当于神经网络建模网络随机游走序列中节点之间关系的过程,但是对分解的目标特征矩阵没有研究结果。为此,本文提出了一种新的证明方法,通过设计2个对比实验,分别在3个公开的网络数据集上做节点分类任务,实验结果证明了句子和随机游走序列的等同性。实验涉及网络表示学习和自然语言处理2个学科,为更深层次地理解语言本质和网络表示学习的本质研究提供了实验依据。
