一种可重构以太网数据包解析器中可重构单元的设计*
2020-03-04殷树娟李翔宇
赵 宇,殷树娟,李翔宇
(1.北京信息科技大学理学院,北京 100192;2.清华大学微电子学研究所,北京 100084)
1 引言
近年来互联网产业迅猛发展,各种新型网络技术层出不穷,随着网络体系的不断膨胀及特殊服务种类的增加,出现了大量的新型协议,如MPLS(Multi-Protocol Label Switching)、GRE(Generic Routing Encapsulation)、IP-in-IP等。为了适应新的网络业务需求,运营商不得不快速更新网络中转设备,但是更新硬件开发周期较长且部署成本较高,问题随之而来。
交换机作为网络中不同设备之间数据交互的中转机制,是设备之间的链路枢纽。如果能够提高网络中转发设备(交换机)的性能,尤其是通用性和灵活性,使其能够在不重新部署的情况下随着网络体系升级,这将对解决上述问题有极大的帮助。
交换机在工作时,第1步是实现数据包的解析,而传统网络数据包包头的报文序列通常是具有固定格式的。但是,现代网络中,如前文所述,交换机需要处理的报文格式更加丰富,而且可能需要处理用户自定义的未知协议报文,因此需要实现更加灵活通用的数据包解析器来满足现代网络中不同业务的需求,在不降低解析速度的情况下可支持新的协议加入。
在这之前相关研究人员已经做出了大量努力,如CPHP(Configurable Parser for Heterogeneous Protocols)[1]和RDFE(Reconfigurable Dataplane for network Function Evolution)[2]设计通过引入可配置用户定制模块和配套的解析树映射算法,将用户定制的协议映射到硬件结构中,从而实现异构协议的解析。但是,这2个设计在解析较长的数据包包头时解析路径相对较长,其相应消耗的解析时钟周期较多,解析速度会明显下降。CAFE(Configurable pAcket Forwarding Engine)[3]和SwitchBlade[4]设计是通过一种任意比特提取器来实现包头解析时包头中的任意比特域的提取或组合,这种设计思想仅初步实现了用户自定义匹配域抽取模式,没有解决关键字匹配和解析动作的可编程性问题。Kozanitis等人[5]提出了Kangaroo结构,通过可编程的协议树预测解析,实现多个数据包的同时处理,其解析能力可以达到40 Gbps。但是,它利用TCAM(Ternary Content Addressable Memory)来实现对数据包中预定义偏移的预测性提取,其数据包存储在内存系统中,提取指令每次都要从中取出相应的字段,这样其处理协议的预测跨度将受限于可从内存子系统中提取字段的多少。DrawerPipe模型[6]将网络功能抽象为5个标准的“抽屉”,不同的“抽屉”根据需要装载不同的处理模块,通过组合处理模块实现各种网络功能。这一模型目前仅能实现对数据中心网络中各种数据进行不同功能的分组处理,还没有用于数据交换的实例。刘中金等人[7]提出了EPC(Elastic Protocol Customization)结构及其对应的映射算法,其核心思想是通过偏移量信息来提取匹配域,但仅支持4个匹配域的提取,故无法满足实际应用的需求。王永娜等人[8]使用XML语言描述可扩展协议报文的方法,以简单协议解析为基础,将解析器功能模块化,从而设计出异构协议动态解析器模型,但是其目前只适用于工业控制网络。Bosshart等人[9]提出了基于 TCAM 的可编程解析器架构,同时在解析模块中引入 RAM 存储匹配域的偏移量,从而实现匹配域的用户自定义。为实现解析器的快速设计,Benacek等人[10]和Attig等人[11]分别将高级数据包处理语言 P4(Programming Protocol-independent Packet Processors)和PP(Packet Parsing)映射到FPGA中,实现了数据包解析器的快速生成,但是在每次处理协议变化时还要重新编译生成新的解析器的FPGA配置文件,FPGA作为一种通用的细粒度可重配置芯片,其实现效率相对较低,所实现的解析器性能受到了限制。
基于以上讨论,本文提出了一种可以通过静态配置实现不同解析逻辑(包括用户自定义的未知协议)的以太网交换机数据包解析器基本处理单元PE(Process Element),这种PE可以被用于任何一层协议的解析,配置文件由编译器根据协议帧格式生成,通过流水线式级联能够搭建支持各种协议(包括自定义的未知协议)集合的可重构数据包解析器。由于它是面向包解析器这一特定硬件类型设计的定制可重构结构,实现效率高于通用的FPGA,配置文件规模也得到大大压缩,与已有方案相比,其具有更少的资源占用率、更高的性能和更高的灵活性。
2 数据包解析器的整体架构
在高性能以太网交换机芯片中,目前数据包解析器普遍采用流水线结构,所有输入的数据包都按照相同的流水线逐级传递,中间不能停顿以确保数据在交换机芯片内部不会出现拥塞。包解析的各步操作按照协议封装层次顺序依次排列在流水线中,大多数网络数据包解析过程都可以看成是多叉树结构,在每一层针对本层树节点的对应域进行提取、匹配,从而实现本层协议的解析。因此,每层协议的解析硬件也具有相似性,每级流水线可以采用相同的可重构基本处理单元(PE)来构成,每级PE对应1层包头(1层协议)的解析,这样可以简化硬件设计和配置文件的生成。
本文数据包解析器的设计思想是将包解析中固定的内容,如变化较少的L1协议、checksum等内容采用固定逻辑实现,而将需要具备可编程性的包解析部分用可重构的PE级联实现。这样可以最大化系统的实现效率和灵活性,同时因为采用规则的结构(复用PE),又能够有效降低硬件设计复杂度,满足设计时间的要求。
本文主要关注PE单元的设计,因此忽略解析器中的固定逻辑部分,这样的解析器主体部分的整体结构示意图如图 1所示,它由多个可重构基本处理单元 (PE)级联组成。PE之间的数据交换通过帧寄存器(Frame)和中间值寄存器堆IRF(Intermediates Register File)实现。交换机接收到的数据包包头(PKT_header)会随着Frame数据通路进行传输,首先由前面的预处理逻辑匹配出首层的协议所要提取的关键字段的位置及下1层协议类型,并对关键字段进行提取存放到IRF中,然后由PE单元对数据包剩下协议进行逐层解析,提取出的关键字段及处理结果均存放于IRF寄存器中。
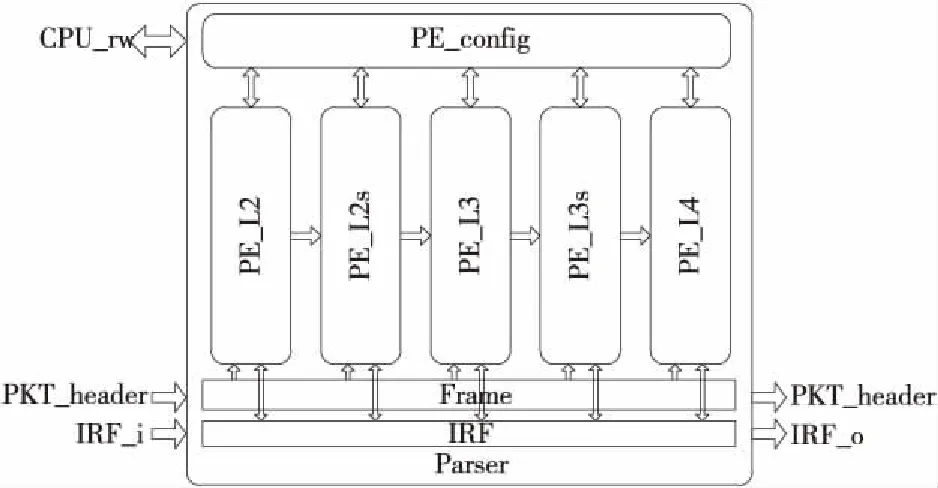
Figure 1 Overall structure of Parser图1 Parser的整体结构框图
图1中可重构PE模块是此报文解析器的核心部分,可重构PE模块通过配置可以实现不同的硬件解析逻辑,从而支持对不同协议报文的解析。基本的设计原则是数据包的每层封装的解析对应1级PE单元,对应现代需要解析到L4层的交换机,典型应用场景中包含5级PE。通过配置可以实现不同层之间的配合解析,也可以每层独立解析,因此具有较高的灵活性。
3 可重构基本处理单元
硬件可重构解析处理单元的实现是本设计的关键所在。包含不同协议的网络数据包,其对应数据域的位置、长度、类型均不相同,因此要处理不同协议的数据包,就需要灵活地调动同一层或不同层的硬件资源,通过这些资源的相互配合来协同工作,这就要求必须实现可灵活配置的硬件可重构单元。
由于数据包包头是各种报文序列的组合,因此数据包的解析过程可以按层进行划分,每层报文的解析可以概述为提取、查找、动作3个过程。接收到的数据包输入到数据包解析器中,对应任一层协议的解析,首先要根据协议类型提取出当前协议包头的关键字段,然后进行查表匹配出需要执行的动作,最后执行相应的动作(如提取关键字段值、字段值的比较、设定报文类型描述符等),这就完成了一层报文解析的过程。
可重构PE是实现上述解析逻辑可重构的基本单元,其结构如图 2所示,主要是由PE配置模块(PE_config)、 Cell_A单元、Cell_B单元、PE_bypass模块、Offset模块、Frame数据通路、IRF 数据通路几个部分组成。
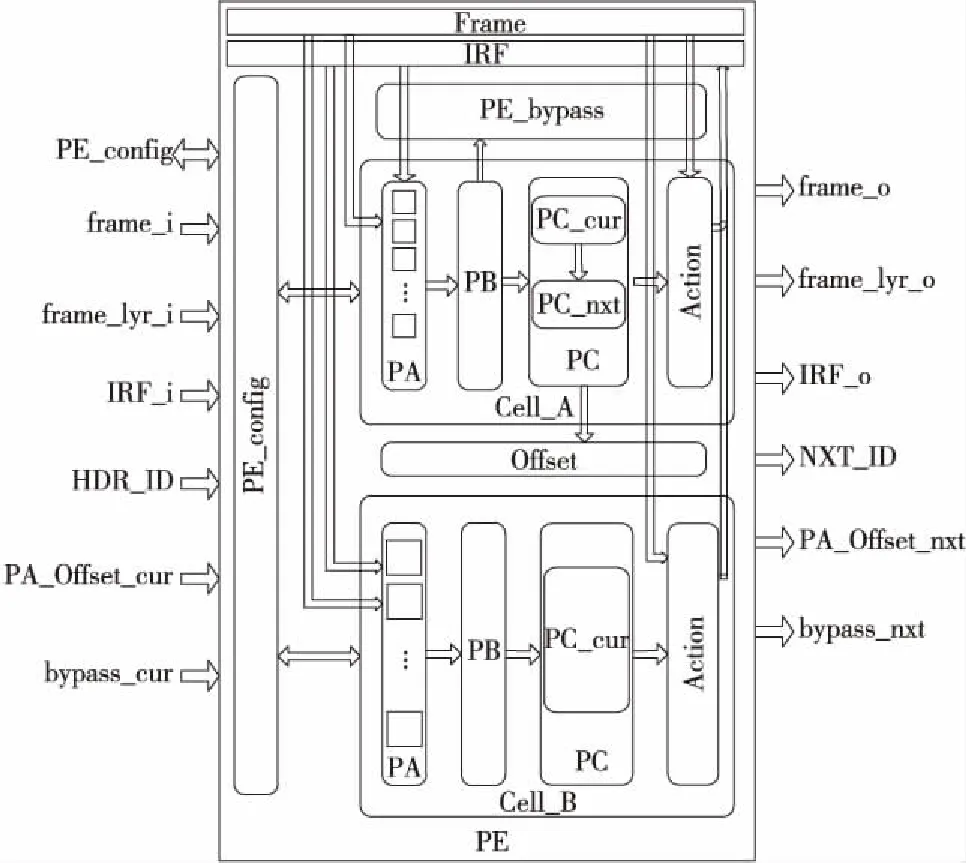
Figure 2 Structure of reconfigurable PE图2 可重构PE结构框图
在这里将Cell_A单元和Cell_B单元统称为Cell单元,其用来实现对协议报文的解析,Cell单元的硬件实现逻辑可以根据协议帧格式进行配置,从而支持不同的协议帧的解析。Cell单元中包含PA、PB、PC和Action几个部分,其中PB、PC主要为查找表结构,而Cell_A单元和Cell_B单元的区别将在下1小节中具体说明。
典型情况下,Frame数据通路中传输的是1 024 bit的数据包包头信息,主要是向Cell单元提供数据,Cell单元可以在Frame中提取出任意指定的数据匹配域(即关键字段)。
IRF数据通路是用来暂存解析过程中所产生的结果(描述符)和需要跨层传递的临时中间数据,其在第1层输入的是由前端的报文预解析模块产生的初始数据,如端口号、是否为环回报文等,然后每经过1层PE单元,寄存器的数量增加相应的量,为每层PE处理过程中所新产生的数据包描述信息。
PE_config单元是完成Cell单元中PB、PC的查找表的表项内容的配置。
PE_bypass单元主要实现跨层协议的处理,如Ethernet+IPv4+…的数据包,在PE_L2层完成了Ethernet的解析,而IPv4是在PE_L3层解析的,则需要跳过L2子层,此时PE_L2s内的PE_bypass单元就完成该工作,其根据上1层传来的bypass_cur信号执行跳过本层的动作,同时为了匹配各层的延时,需要将数据通路的数据信号进行相应的延时。
Offset单元用来实现每层PE单元的Frame数据通路的起始数据访问位置的偏移工作,对于1个数据包,上1层解析过的数据,在下1层不需要再次访问,因此下1层的起始访问数据将要越过上层已解析的数据,该单元就完成对应操作。这种做法可以减少偏移量的存储位宽,同时缩小访问范围,降低硬件设计复杂度和硬件开销。
3.1 Cell单元
Cell单元是每层PE实现对应协议解析的关键所在,其有2种不同的形式——Cell_A单元和Cell_B单元。如图 2所示,Cell单元中均包含PA、PB、PC、Action几个模块。
Cell中的PA模块用来实现特定数据域的提取,每1个Cell单元中设置了若干个PA。PA模块的输入为前1级PE输出的关键字段偏移量、本级Frame寄存器的待提取的数据帧,输出为提取出来的关键字段。PB模块的输入为本级各PA模块输出的关键字段,其核心是1个匹配查找表,把关键字段组合和其中存储的匹配模板一一比较,输出匹配的模板所对应的协议类型信息。如果关键字段和任何特征模板都不匹配,则发送非法标识到PC单元,PB单元每个匹配模板还有1个对应的掩码字,用来忽略不关心的比特。PC中有PC_cur和PC_nxt 2种表,其中PC_cur表用来根据PB表的匹配结果索引要执行的动作,PC_nxt表用来根据PB表的匹配结果索引下1层PE单元要提取的关键字的偏移量。Action用来执行PC表索引的对应的动作,这些动作的定义以超长指令字的形式表示,Action执行的指令的源操作数来自Frame(即数据包头字段)、IRF或立即数寄存器,执行结果被写入IRF。
在数据包头解析的过程中,存在同时检查多个关键字段的情况(如QinQ协议解析时就需要同时提取外层Type、内层Type和MAC 3个字段域,PA取出这些字段后,再将他们拼接成1个Keyword输出给PB进行查表),特别是如果这些关键字段彼此是独立还要考察其各种组合,则需要对应增加很多表项(如MAC域要进行的是比较操作,Type域要进行的是协议类型查找操作,假使MAC域有m种可能,Type域有n种可能,如果把这2个独立的域合成1个Keyword给PB进行查表,则存在m×n种组合的可能性,即会使PB表增加m×n行,这将使存储开销激增),而各层协议的匹配任务数量(即需要支持的协议种类数量)差异也较大,业务类型越丰富的层匹配任务越多,如果只使用1种固定的Cell单元,同时满足所有层次的需求,会引入很大冗余开销,因为匹配任务数量少的层无需大的存储表,而如果采用较小的Cell单元,某些层可能仅靠1个Cell单元无法完全解析,如果串联多个Cell单元解析,则时钟周期将大大增加,降低解析速度。因此,本文采用多个小单元任意组合的解决方案,即在不同层次上根据需要并行放置不同数量的Cell单元。同时使用多个Cell单元并行解析,这样可以解耦复杂的解析操作,即将彼此独立的条件匹配复杂操作进行分解,然后存储到并行的多个Cell单元的表中,这样不仅可以保证1层协议头在PB处只需1个时钟周期即可完成解析,降低了配置的复杂度;同时也可以去除表项之间的耦合关系,使独立的匹配条件分别存储到多张表中,减少表项的条目,即减小存储开销。例如,上述Type和MAC 2个字段的匹配操作,如果分别使用2个并行的Cell单元来处理,则一共仅需m+n行表项,这将大大节约存储开销。因为每层协议解析仅需1张存储下1层协议类型的表(即PC_nxt表),如果直接使用相同的Cell单元并行解析1层协议,则PC_nxt表资源会存在浪费,因此这里设计了2种形式的Cell单元:Cell_A和Cell_B。在Cell_A单元中PC模块包含PC_cur和PC_nxt 2种表,而Cell_B单元的PC模块仅有PC_cur这1张表。考虑到一些协议解析操作比较复杂,为了简化硬件配置逻辑,PE有3种组合情况,Cell_A单元都是1个,但其可以分别含有0个、1个、2个Cell_B单元,具体使用哪种情况,在设计调用时要根据实际解析的数据包在各层解析所占用的硬件资源来确定。
使用2种形式的Cell单元并行解析的实现方式,通过PE_config单元的配置,可以使Cell_A、Cell_B单元协同工作,同时解析协议树中同1层的多个协议。当2个Cell_B单元仍无法完全解析1层协议时,可以通过对相邻2层PE单元中查找表的协同配置,使相邻2层或多层PE单元来处理1个较为复杂的协议层。这样,只要不超出硬件资源的容量,可以实现任意1种未知协议的解析,提高硬件资源的复用率和通用扩展性。
3.2 可重构处理单元的数据通路
3.2.1 关键字段提取单元PA
PA负责解析器中Frame数据和IRF数据的提取工作,其通过输入的Offset值,对输入数据中相应的字段值进行提取。PA可以分别访问到Frame和IRF 2个数据存储单元,具体访问哪一路数据由PE_bypass单元指定。PA提取的数据作为关键字传给PB。PA单元的结构如图 3所示。
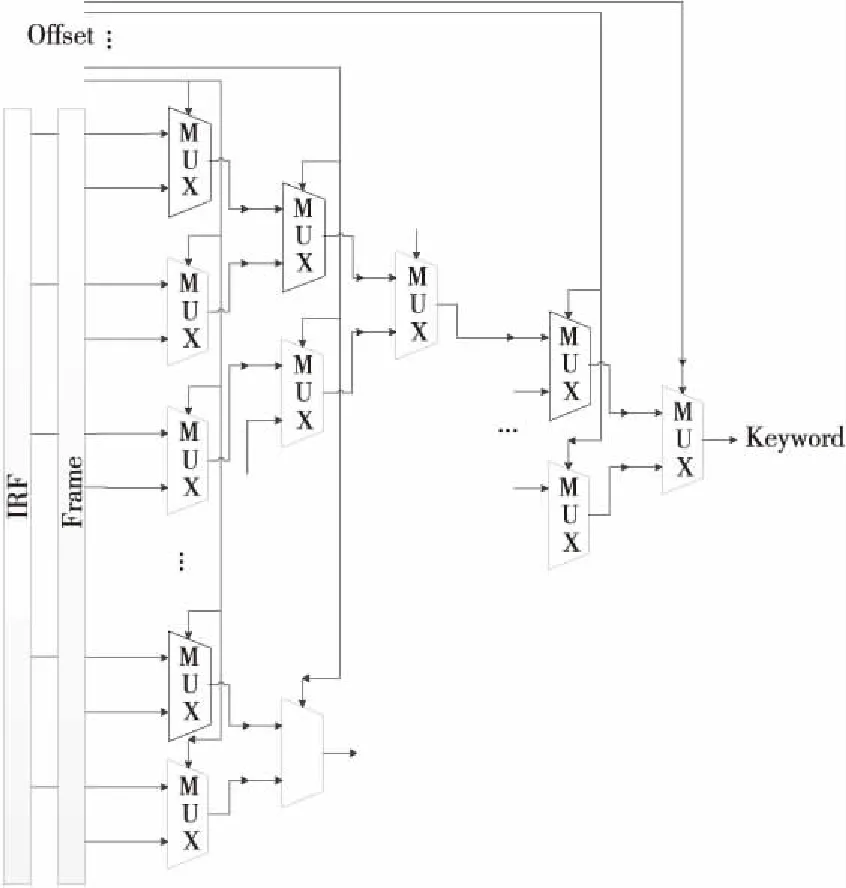
Figure 3 Internal structure of PA图3 PA内部结构
如图 3所示,PA用来实现特定数据域的提取,每1个Cell单元中设置了若干个PA,在实现提取时采用统一提取的方式,一次性提取出本级PE后续解析所需要的所有关键字段,以提高提取效率。由于前1层解析过的包头数据在下1层解析中不需要再次访问,因此通过偏移对齐每层协议头部(偏移工作由Offset单元完成),可以减少用来描述可访问数据的位宽,即缩小偏移量位宽,不仅节省硬件开销,也提高了解析速度。因此,在本设计中,PA只能访问当前层协议帧头部的数据,即整体访问跨度等于所有协议帧头部长度的最大值,本设计每个PA可访问16字节的数据。同时,又由于匹配域(即关键字段)的长度不定,很难做到通用,如果使用固定逻辑会浪费硬件开销,分散提取会增加数据偏移量的存储开销,因此为了降低后续处理硬件逻辑的复杂度,在该模块采用固定长度的提取方案,即每个PA单元1次可提取出1个字节数据。长度超过1个字节的字段,则由多个PA分别提取后拼接,当长度不是字节整倍数时,则额外提取相邻位补充成完整字节,多余的比特在匹配时再利用掩码功能忽略掉。
3.2.2 关键字段匹配单元PB
PB是查找表结构,其表项内容如表 1所示,PB可以根据PA传来的关键字和上级PE解析出的本层协议类型(HDR_ID)匹配出本层协议所执行的动作索引SUB_ID和下1层协议类型(NXT_ID)及Bypass信息。为了降低配置的复杂度,采用二级表结构将表项进行拆分,对于一些复杂运算先经过前级表进行转换,变换成已有的简单运算,再在后级表中进行匹配。

Table 1 Contents of PB table表1 PB表的表项结构
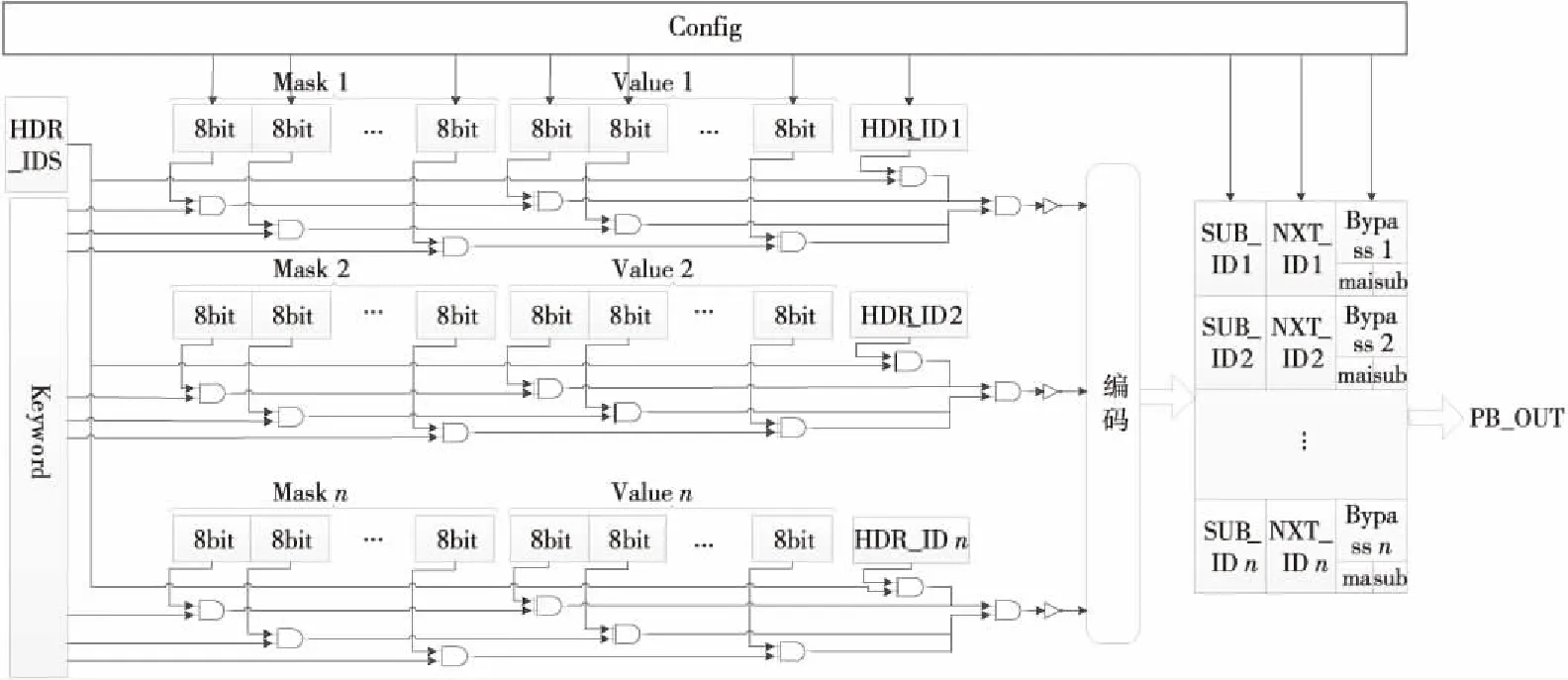
Figure 4 Internal structure of PB图4 PB内部结构
PB单元的内部结构如图 4所示,其接收到的关键字先与Mask进行掩码操作,然后再与查找表中存储的Value项进行匹配。这里使用掩码操作是为了在提取时可以实现固定长度的统一提取操作,这样不仅降低了硬件设计的复杂度,规范了数据的处理位宽,同时减小了存储开销。
3.2.3 动作及协议类型索引单元PC
PC中有PC_cur和PC_nxt 2种表,如表2所示,PC_cur表根据PB表的匹配结果(SUB_ID)索引要执行的动作的超长指令字VLIW(Very Long Instruction Word)信息和下1级PE单元的Frame数据通路的起始数据访问位置的偏移(LYR_offset)信息,并分别将VLIW通过Action、LYR_offset输出给本级PE的Offset单元;PC_nxt表根据PB表的匹配结果(NXT_ID)索引下1层PE单元的每个PA所要提取数据域的位置偏移信息PA_offset。
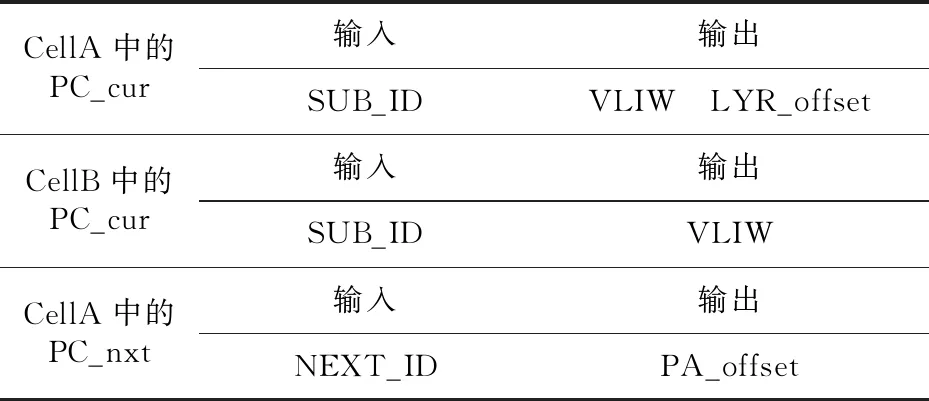
Table 2 Contents of PC table 表2 PC表的表项结构
PC_cur表的实现结构如图 5所示,其主要使用SRAM(Static Random Access Memory)实现,为了节省存储空间,在配置PC_cur表时,使其表项条目顺序按照PB表中对应的SUB_ID条目的顺序进行存储,这样在PC_cur表中可以省去SUB_ID的匹配过程,简化了硬件设计复杂度。
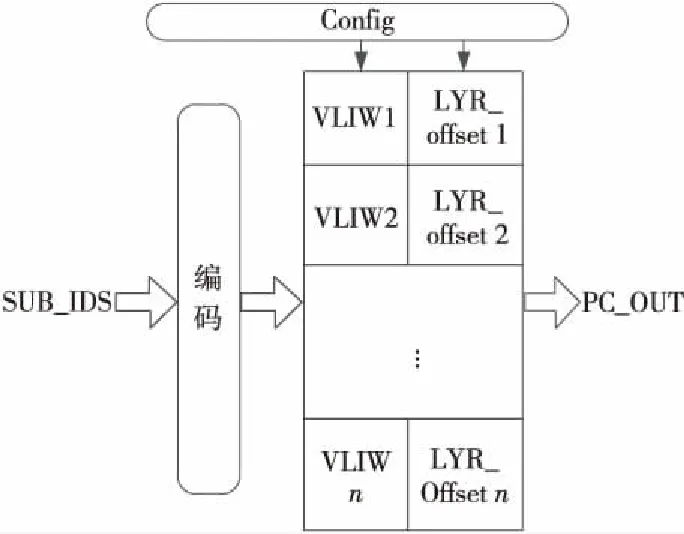
Figure 5 Internal structure of PC_cur图5 PC_cur内部结构
PC_nxt表的内部实现如图 6所示,其根据PB给出的NXT_ID信息,与自己表中的HDR_ID信息匹配出下1层PE单元的PA模块所提取的关键字段的偏移量PA_offset信息。其表项内容通过配置可以做出相应的改变,以此来满足不同协议解析的要求。
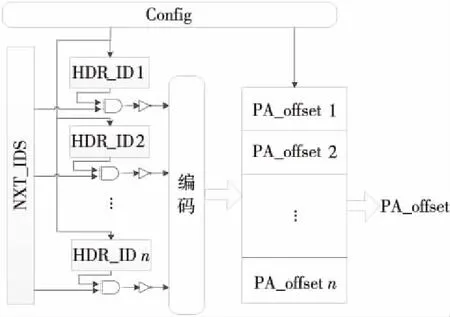
Figure 6 Internal structure of PC_nxt图6 PC_nxt内部结构
3.2.4 动作执行单元Action
Action用来执行PC表索引出的对应动作,其接收来自PC的超长指令字(VLIW),解析指令,取源操作数并执行。Action内部有3种指令单元,如图 7所示,每种指令单元各8个,共24个。1个超长指令字包含24个子指令,分别控制这24个指令单元。在本设计中对每级PE做了IRF的预分配,每个Action单元对应分配到24*8 bit的IRF空间,即每个指令对应8 bit的IRF空间,用来存储指令的运行结果;同时,为了简化IRF的存储结构复杂度,在本设计中,将指令单元与存储空间进行了绑定,而存储空间的实际意义(即存储的数据结构)由编译器进行指定,与硬件结构无关。
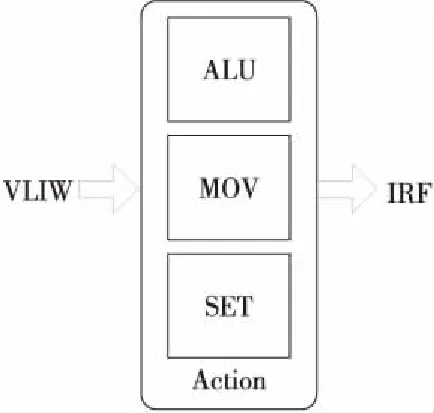
Figure 7 Diagram of Action图7 Action框图
在指令集设计中,尽量精简指令集,以缩短指令长度,指令长度缩短可以降低PC模块中的表项规模,简化指令译码逻辑复杂度。各指令单元如图 7所示,ALU单元用来执行大于(Greater than)、等于(Equal)等比较操作,MOV单元和SET单元分别执行复制(Move)、置数(Set)操作。Move子指令将Frame或IRF中的数据赋值到IRF寄存器中。Set子指令将数值域的值赋值到对应的IRF寄存器中。报文解析中用到的其它操作(如大于或等于等操作)都可以转化为这几种操作。这3种指令单元的指令格式如表 3所示。
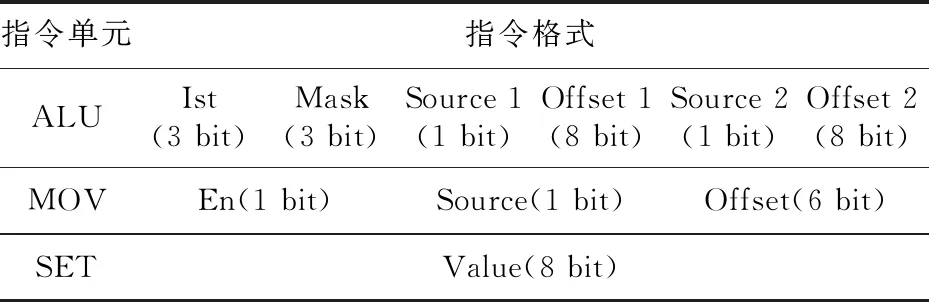
Table 3 Sub instruction format of Action表3 Action的子指令格式
ALU单元子指令共24 bit,分为6个域,分别为指令名称域(Ist)、掩码域(Mask)、操作数1源选择域(Source 1)、操作数1偏移量域(Offset 1)、操作数2源选择域(Source 2)、操作数2偏移量域(Offset 2)。Ist域用来指定操作类型;Mask域对操作数做掩码操作,去除操作数中无用信息,其做掩码时以字节为单位,最高支持64 bit;操作数源选择域指示操作数来源于Frame还是IRF;操作数偏移量域指示从数据源中提取的具体数据位置偏移量。ALU单元的操作结果存放到IRF寄存器中。
MOV单元子指令共8 bit,分为3个域,分别为使能域(En)、操作数源选择域(Source)、操作数偏移量域(Offset)。En域指示是否执行MOV操作;Source域指示操作数来源于Frame或IRF;Offset域指示从数据源中提取的具体数据位置偏移量。
3.3 存储开销分析
在可重构处理单元中,存储开销主要包括:存储类型域内容的查找表、存储偏移量信息及匹配域字段的查找表、存储中间数据的寄存器IRF、存储数据包包头的Buffer。这几个部分的开销分析如下:假设PE中PA模块的个数为Npa;PB模块查找表可以支持的协议条目数为Pb;PC模块中当前级查找表(PC_cur)支持的协议条目数为Pccur,下1级查找表(PC_nxt)支持的协议条目数为Pcnxt;ALU指令的位宽为A,MOV指令的位宽为M,SET指令的位宽为S,Action单元中指令单元总个数为Z;每层可重构处理单元(PE)所支持的最大和最小包头长度分别为Max_header和Min_header。那么,各种存储开销计算公式如表 4所示。

Table 4 Storage overhead calculation formula表4 存储开销计算公式
对于包含1个Cell_A单元、2个Cell_B单元(每个Cell单元中包含24个PA单元、1个PB单元、1个PC单元、1个Action单元)的PE(可支持的协议条目为32,数据包包头长度为1 024 bit)开销如下:PB表总计38 496 bit;PC表总计49 632 bit;IRF寄存器总计704 bit;缓冲寄存器总计1 262 bit,即1层PE的总存储开销约为87.98 Kb。
3.4 基于本文PE的包解析器实例
本节将给出1个基于本文所设计的PE实现的支持如表 5所示的协议集合的数据包解析器作为示例,说明PE的配置方法。
以太网数据包包头包含的首先是链路层协议,如Ethernet Ⅱ、Vlan、 IP-in-IP(802.1q)等;然后是

Table 5 Protocol set supported by the packet parser表5 数据包解析器支持的协议集合
MPLS层协议,典型的如MPLS L2/L3VPN等;接下来是网络层协议(如IPv4、IPv6等)和传输层协议(如TCP、UDP等),本设计支持到传输层协议的解析。如图 8所示,数据包的解析过程可以按照树形结构进行分解,每1个树的节点为1种协议,树的每1层为1个解析层次,与之对应,采用层的硬件结构对数据包进行解析,每1级或2级PE单元对应协议树的1层节点,通过配置可重构处理单元来实现本层协议的硬件解析逻辑。
根据数据包的层封装结构的解析过程,将整个解析器设计为流水线(层)结构。在本示例中,为支持到传输层协议的解析,选用5层PE进行级联,为能够支持IP-in-IP、MPLS等协议的解析,每层PE单元内部包含1个Cell_A单元、2个Cell_B单元,每个Cell单元中均包含24个PA单元、1个PB单元、1个PC单元、1个Action单元,每层PE单元所支持的解析协议类型如表 5所示。在每级PE单元中,需要配置7张表(Cell_A中1个PB、1个PC_cur和1个PC_nxt,2个CellB中各1个PB和1个PC_cur),它们的具体内容由配套设计的编译器生成(编译器的设计本文不做讨论),然后通过PE_config单元加载。根据3.3节的公式估算,所用存储资源共计0.429 6 Mb。

Figure 9 Simulation results of packet parser图9 数据包解析器功能仿真结果
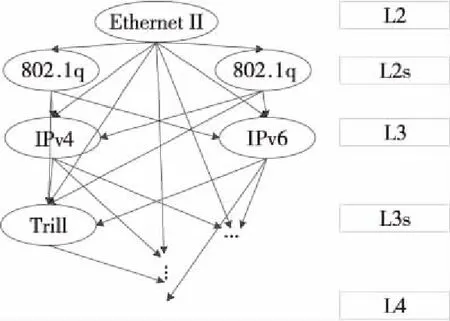
Figure 8 Schematic diagram of message protocol tree structure图8 报文协议树结构示意图
4 性能分析
本文提出1种可重构的以太网数据包解析器中可重构单元的实现,以EthernetⅡ+Vlan+IPv4+MPLS+TCP数据包为例对其功能进行验证分析,如图 9所示为其功能仿真结果。
将图9输出结果与Wireshark工具软件的输出结果进行了比较,结果显示一致。并使用Synopsys公司的逻辑综合工具对本设计做了DC综合分析,使用40 nm的工艺库,最终系统能达到的时钟频率为240 MHz,由于测试实例使用了5级PE单元,每级时延为4个时钟周期,故此数据包解析器处理1个数据包大约需83 ns,由本文PE按照流水线级联方式组成的解析器理论上每个时钟周期可以输出1个数据包,因此由解析器决定的最高数据包吞吐率可达每秒2.4亿个数据包(假设不存在环回报文)。同时,对1级PE(包含3个Cell单元,每个Cell单元中包含24个PA单元、1个PB单元、1个PC单元、1个Action单元)的面积做了评估,其面积为3 528 761.77,约为147.56万门。
5 结束语
针对目前网络体系中数据中转设备的更新速度难以跟上网络结构的更新速度的问题,以及为了降低硬件部署成本的现实需求,本文提出了1种以可重构的方式实现更改解析逻辑的数据报文解析器基本处理单元,并对其进行了功能测试及资源分析,其灵活性可以很好地满足现实需求。通过测试这种结构可以看出,该结构支持多种协议且具有较高的转发速率。该设计对软件定义网络(SDN)[11]的交换机芯片设计具有重要的价值。
