一种融合上下文特征的中文隐式情感分类模型*
2020-03-04潘东行袁景凌盛德明
潘东行,袁景凌,李 琳,盛德明
(武汉理工大学计算机科学与技术学院,湖北 武汉 430070)
1 引言
随着社交媒体用户的爆发式增长,网络上积累了海量的文本信息。针对这些文本数据进行情感分析可以帮助挖掘网民行为规律[1]、帮助决策机构了解舆情倾向[2]和改善商家服务质量[3]。因而,针对社交媒体的文本数据情感分析已经成为国内外研究领域的热点话题。
情感分类作为情感分析基础性的研究任务,可以根据不同特点进行划分。根据任务目标,情感分类可以分为常见的极性分类和多元情绪分类[4]。根据情感词的出现与否,情感分类任务可分为显式情感分类和隐式情感分类2种。由于带有显式情感词的文本表述在日常生活中占有极高的比例,显式文本情感分类任务在自然语言处理NLP(Natural Language Processing)领域中已取得了丰富的研究成果[5],而隐式情感分类的相关任务还处于起步阶段。对多个领域多个主题网络文本进行研究可以发现,隐式情感表达占有一部分比例。与显式情感表达相比,隐式情感表达多采用比较含蓄的方式,如中立性事实描述和讽刺等等。如微博“再访故地可能还会有别样的风景,别样的感受哦!”中,博主并没有采用明显的显式情感词如“开心”“快乐”等来表达重游故地的开心,但采用了中立性事实表述表达自己内心积极的感受;如博客“是啊,被疯狗咬了,反正咱们不能再去咬疯狗了。”中,博主采用讽刺的手法表达内心的消极感受。隐式情感分类作为情感分析的重要组成部分,其研究成果将有助于更全面、更精确地提升在线文本情感分析的性能,可为文本表示学习、自然语言理解、用户建模、知识嵌入等方面的研究起到积极的推动作用,也可进一步促进基于文本情感分析相关领域的应用和产业的快速发展。
然而针对中文的隐式情感分类任务还存在诸多困难。首先在句子语义特征提取上,隐式情感文本采用了较为含蓄的陈述,这给基于词袋模型的特征提取方法带来极大的困难。在表达载体上,中文缺乏一些词形态上的变化,其语义关系和社会、文化等因素密切相关[6],因而在底层语义关系的捕捉上更加困难。其次,在分类方法选择上,隐式主观文本缺乏情感词,这使得传统基于词典的情感分类方法不再适用。在分类模型学习句子有效特征时,情感词的存在可以直观地判别整个句子的倾向,如文本“今天天气真好,我喜欢这样的天气。”中,显式情感词“喜欢”暗示了整个句子积极的情感倾向。在学习句子特征表示时,对显式情感词特征突出表示,可以提升整个句子分类效果。采用注意力机制的分类模型也采用类似的思想,增加句子中情感词的比重,从而达到提升分类效果的目的。隐式情感文本不存在显式情感词,这对分类模型有了更高的要求。最后,隐式情感表达中事实性情感表达更加依赖上下文的信息,如主观表达“桌子上有一层灰”,不包含任何情感词,但在情感类别中倾向于贬义。查询句子上下文信息,篇章内部表述中包含诸如“简直太脏了”和“床铺也不整洁”等重要信息,上下文特征可以辅助中立性表达的情感判别。
word2vec[7]作为底层的词嵌入技术,可以从海量的语料库中训练出合适的词向量,这些词向量可以捕捉词与词的语义关系,如词语之间的相似性和差异性。作为一种词预训练方法,word2vec已经被广泛应用于各种NLP任务[8]。相关研究显示,高质量的词向量特征可以提高分类的性能。以预训练技术为基础,可以更好地对中文文本特征进行表示,同时使用该技术提取上下文语义特征,将其融入到分类模型中,从而为句子的判别提供更多的特征。
本文采用底层的词嵌入技术获取了句子及其上下特征表示,以TextCNN[9]、长短期记忆神经网络LSTM(Long Short-Term Memory)和双向门控循环BiGRU(Bidrection Gated Recurrent Unit)神经网络为基础对中文隐式情感文本进行倾向分类研究,在各个模型基础上还研究了融合注意力机制的分类模型。针对句子上下文可以辅助隐式情感分类的特点,设计了一种融合上下文特征与注意力机制的分类模型,采用GRU对标签句子特征进行编码,使用BiGRU+Attention的结构组合对上下文语句中的重要特征进行编码。由于在最终对句子进行分类时,会通过Softmax层获得各个类别的概率,特征数值越大概率越高,因而在获得2者特征编码后,获取各维度取值最高的特征,再通过一个Softmax层获取该句子各个类别最终情感倾向。通过监督学习的方式不断完善模型内部结构,从而达到当句子本身情感倾向分明时,依靠句子本身进行倾向判别;当句子本身情感倾向不明确时,通过Attention机制对句子上下文进行重要信息提取,从而辅助句子情感倾向性判别。本文的主要贡献如下:
(1)从情感计算的角度出发对隐式情感句的情感计算资源进行了分析,发现隐式情感句本身具备较小比例的情感计算资源。针对隐式情感分类任务困难与研究不足的问题,探索了TextCNN、LSTM和BiGRU基础模型的中文隐式情感分类效果。
(2)在分类模型基础上,研究了为输入分配权重的注意力机制思想,发现在显式情感句分类研究中取得效果提升的注意力机制模型无法明显地提升隐式情感分类效果。
(3)使用Attention机制对句子上下文重要特征进行编码,提出了一种融合注意力机制与上下文特征的分类模型,为上下文特征在隐式情感分类任务中的应用提供了一种新思路。SMP2019评测数据结果显示,在3个评价指标上,本文提出的模型取得了最优的综合分类性能。同时还发现了在隐式情感句中,褒义的情感类别分类任务相对于其它2个类别的分类任务更加困难的现象。
2 相关工作
根据显式情感词的有无,情感分析可分为隐式情感分析与显式情感分析。显式情感分析已经在多个方面取得了显著的成就,而隐式情感分析还处于起步阶段.在以往的研究中,大多数研究忽视了隐式情感分析与显式情感分析的差别,将2者的分析任务无差别对待。相关统计数据显示,在不同主题领域中,隐式情感句占据不同的比例。由于情感分类是情感分析的基础研究领域,本文从隐式情感句分类入手,主要研究社交媒体中隐式情感句的褒贬中三元倾向性分类任务。
用于情感分类的方法大体上可以分为3种:基于情感知识的分类方法、基于特征提取的机器学习方法和深度学习方法。基于情感知识的分类方法,大多数通过对文本中情感词的识别实现整个句子的情感倾向性判别。由于隐式情感文本缺乏显式情感词,传统的基于情感知识的分类方法不再适用。基于特征提取的机器学习方法,需要选取有意义的特征,通过搭建分类器的形式实现情感句的倾向性分类[10]。机器学习方法存在着文本特征不易提取、很难处理文字长度不一的问题以及模型不容易扩展的特点。基于深度学习的方法在情感分类任务中取得了广泛的应用。首先,深度学习模型在结构上更加灵活,可以更便捷地将多种关系融入到分类模型中。文献[11]设计了一种结合区域卷积神经网络和分层长短期记忆网络的深度分层网络模型,有效获取了句子中的局部特征和整个评论中的长距离依赖关系,解决了情感极性表达不清晰、难句的情感极性判断问题。文献[12]提出了融合区域卷积神经网络和LSTM网络的混合模型,有效获取了句子的时序关系以及整个评论的长距离依赖关系。在特征融合上,基于深度学习的情感分类方法要比基于机器学习的分类方法更加便捷。为了将上下文特征融入到分类模型中,本文开展了基于深度学习的分类模型研究。其次,深度学习模型可以更好地学习词语之间的联系、局部特征或者全局特征。基于LSTM网络的分类模型[13]可以把握词语之间的时序关系,获取不同词语之间的依赖关系。文献[13]首次将TextCNN应用于情感分类任务中,采用不同长度的filter对文本矩阵进行一维卷积操作,以获取不同词语长度的特征信息,并通过最大池化层完成句子特征的提取。文章还研究了不同词嵌入技术对分类结果的影响以及静态(Static)方式和非静态(Non-static)方式对训练过程的影响。在后续的研究中,词嵌入技术与深度学习模型的组合[9,14]成为了情感分类任务中的主流方法。本文以该研究思路为基础,探索了LSTM模型、静态方式的TextCNN和非静态方式的TextCNN对隐式情感句的分类效果。
在显式情感分类领域中,结合注意力机制的分类模型可以在不同应用方向取得更好的应用效果。文献[15]最早在NLP领域中应用注意力机制。文献[16]提出了一种简化版本的注意力机制。文献[17]针对文章中重要的句子和句子中重要的词语,提出了句子级和词语级2种注意力机制模型。这种注意力机制模型采用BiGRU对不同级别的输入进行编码,并为每个输出分配了不同的权重,从而突出更有价值的特征信息。本文以该思路为基础,首先搭建了基于BiGRU的基础分类模型,其次通过句子级的注意力机制为编码后的特征输入分配不同权重。
针对中文在语义规则和社会特征因素上有较大差异的特点,文献[18]以word2vec技术为基础,将 n-gram 特征引入上下文中,使用词-词和词-字符的共现统计来学习词向量。由于词向量的质量会影响到分类的性能,本文以该文献在维基百科训练的词向量为基础开展中文隐式情感的分类研究。
在中文隐式情感分类领域,文献[19]对中文隐式情感领域做了基础性的研究工作。在隐式情感分类方向,该文献将上下文显式情感语义背景融入到构建的卷积神经网络中,并突出了上下文语义特征在隐式情感分类中的重要作用。文献[20]采用句子内部词语上下文语境和注意力机制融合的思想来对不同语境的词特征进行学习。上述研究文献缺乏循环神经网络对隐式情感句分类的相关研究,因此本文进行基于循环神经网络及其变体的隐式情感分类模型研究。循环神经网络结构可以捕捉句子内部时序关系,并为句子分类提供重要的特征信息。在上下文研究中,文献[19]将句子内部上下文语义信息融入到模型中,文献[20]对不同语境下句子内部词语特征进行学习,本文则从句子外部所在的上下文特征入手,构建了融合句子外部上下文语义特征的分类模型。
3 模型描述
本节主要介绍应用到的基础模型、注意力机制以及融合注意力机制与上下文特征的分类模型。
3.1 隐式情感分类
人们的情感表达是丰富而抽象的,人们在社交媒体中表达直观感受时,除采用显式情感词表达情感外,还会采用客观陈述或者修辞方式来隐式地表达自己的情感。相关研究显示,隐式情感句占总情感句的15%~20%。在隐式情感句中,句子本身不含有显式情感词,但表达了主观情感。对隐式情感句进行划分,可以分为事实型隐式情感和修辞型隐式情感。修辞型隐式情感又可划分为隐喻型、比喻型、反问型和反讽型。本文研究目标是对隐式情感句的情感倾向性进行分类,与以往的显式情感句分类的区别如表1所示。
隐式情感句与显式情感句最主要的差别在于显式情感词的有无。在情感计算中,大规模的情感词汇本体资源可以辅助文本情感识别。由于隐式情感句中不包含显式情感词,本文采用大规模情感词汇本体库[21]对隐式情感句中的词语进行分析。采用分词技术对隐式情感句进行分词,查询各个词语在情感词汇本体库中的词性、词语强度以及情感分类。隐式情感句来源于SMP2019中文隐式情感分析评测提供的数据集。数据来源主要包括微博和论坛等媒体,主要领域或者主题包括传统文化、时事热点和生活等多个方面。情感词汇本体库从词语词性种类、情感类别、情感强度及极性等维度对中文词汇或短语进行了描述。中文隐式情感分析评测数据集中隐式情感句包含的情感词汇本体,统计结果如表2所示。

Table 1 Sentiment sentence difference comparison 表1 情感句差异对比
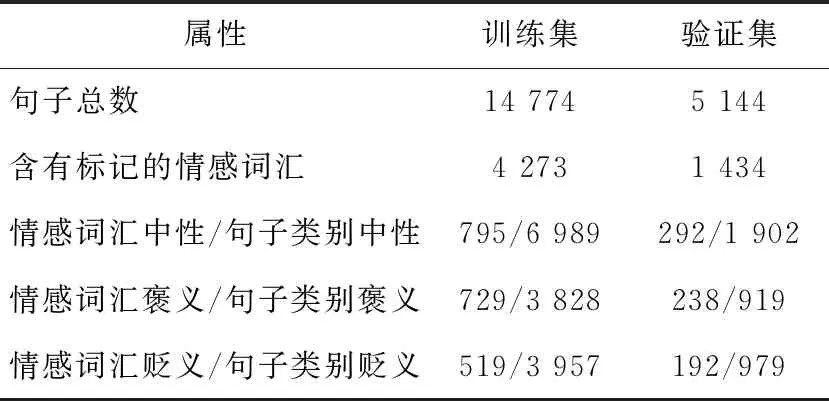
Table 2 Statistical results on implicit sentiment vocabulary ontology 表2 隐式情感句词汇本体统计结果
根据句子中是否包含标记的情感词汇,句子可以分为2大类:一类为句子中包含1个及以上数量的标记词汇,另一类为句子中完全不包含标记的情感词汇。对统计结果进行分析,含有1个及以上数量标记词汇的句子约占总体的28%,这也证明了传统的基于情感词典的分类方法对于隐式情感分类领域并不适用。同时由于含有情感词汇的句子比例较小,在情感计算中这一特点会加大情感倾向判别的难度。
标记的词汇所拥有的情感强度从强到弱大小不一,同时词汇不带有明显情感倾向。将情感词汇的类别与句子整体类别进行比较,当辅助情感词倾向与句子整体倾向相同时,该词汇的特征在一定程度上可以帮助句子情感倾向的判别,其中褒义类别词汇的辅助情感词倾向与句子整体倾向一致比例最高为25.89%,其中还存在着某情感词被用于相反的情感表达的情况,如“对法乐第未来而言,在近期遭遇一系列困难之后,这处总部代表了新的未来。”中,标记词汇为遭遇,词语极性为贬义,词语强度为5,句子整体表达了褒义的倾向。不含显式情感词、句子中较低比例的情感计算资源、标记词汇类别与句子标签不一致等问题的出现给隐式情感句的倾向性分类带来了极大的困难。
在社交媒体中,用户的表达方式存在口语化和用词不规范的问题。隐式表达的情感倾向在某种程度上和表情符号的情感倾向具有一致性,如句子“[good]当然还有荫姐,一直等你回来!”的情感倾向为褒义,表情“[good]”在情感上偏向于褒义情感。同时,由于表达的不规范性,还存在隐式表达的情感倾向与表情符号情感不一致的特点,如句子“[酷]乐视员工的悲剧在于没有选择中国银行的信用卡。”表达的倾向为贬义,而表情符号“[酷]”更多地应用在褒义或者中性的词语表达中,如何处理文本中的表情符号和不规范用词对于隐式情感文本分析有较为重要的影响。
本文在文本处理的基础上,使用深度学习模型和添加注意力机制的分类模型对隐式情感分类任务进行研究。
3.2 GRU神经网络
GRU神经网络是长短期记忆网络(LSTM)的一种变体结构[22],可以有效解决循环神经网络中出现的梯度消失或者爆炸问题,同时保留了LSTM较长距离记忆的能力,并简化了LSTM结构,缩短了模型训练的时间。在NLP领域,GRU可以捕获词语在句子中的长短依赖关系,被广泛应用于机器翻译等任务中。
GRU[23]简化了LSTM的网络结构,其主要包括2种门控:循环单元更新门和重置门。GRU使用更新门结构代替了LSTM中的遗忘门和输入门,使用该结构实现对数据的丢弃和更新,使用重置门结构储存遗忘信息的步长。如图1所示,GRU包含重置门和更新门2个门控单元。
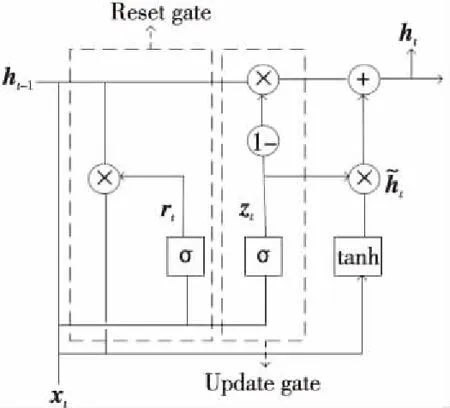
Figure 1 Structure of GRU unit图1 GRU单元结构
在不同时间步内,GRU对输入信息的计算如式(1)~式(4)所示:
有非常多的案例都是青少年在初次接触毒品的时候并不知道毒品为何物,不但没有远离,反而对它充满好奇,直到在好奇心的推动下开始吸毒,从此走上不归路。因此当社会上、学校里介绍关于毒品的知识时,一定要认真学习、牢记于心。平时也可以通过上网、翻阅书籍等方式了解与毒品相关的知识。总之,一定要充分了解毒品的特性以及危害,这样才能让自己时刻保持警惕,远离毒品。
zt=σ(Wz·[ht-1,xt])
(1)
rt=σ(Wr·[ht-1,xt])
(2)
(3)
(4)
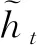
3.3 注意力机制网络
注意力机制可以从众多信息中选取对当前任务最有价值的信息,在机器翻译[24]、文本分类等自然语言处理领域中,注意力机制在提升模型效果的同时,还可以对内部有价值的信息进行可视化。在文本分类任务中,注意力机制可以凸显决定句子倾向分类词语的重要性。本文使用的注意力机制思想来源于文献[17]提出的2种分层注意力模型。原文是对文档级别的句子进行分类,提出的模型可以简化为如下4个部分:词语序列编码器、词语级别注意力层、句子序列编码器和句子级别注意力层。在对隐式情感句进行分类时,仅采用了词语级别的注意力机制。句子情感分类任务也可简化为2个部分,词向量编码器和Softmax处理层。词向量编码器可以对词向量特征进行提取与编码。Softmax处理层则可以计算各个类别的概率。添加注意力层的句子分类模型主要包括3个部分:词向量编码器、Attention注意力层和Softmax处理层。添加的Attention注意力层用于强化句子中有价值信息的权重。在词向量编码器部分采用TextCNN、LSTM和BiGRU等不同的神经网络对句子的向量表示进行编码。以分类模型中的Attention+BiGRU组合为例,阐述注意力层分配权重的方法,预测模型网络结构如图2所示。
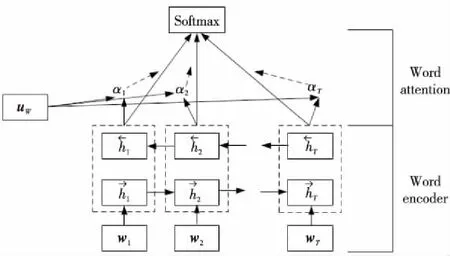
Figure 2 Structure of Attention+BiGRU图2 Attention+BiGRU结构图
图2中,wt代表一个句子中每个单词的词向量表示,We代表BiGRU结构的权重矩阵,T代表句子的长度,经过式(5)的计算,得到BiGRU结构的输入xt。
xt=Wewt,t∈[1,T]
(5)
(6)
(7)
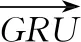
μt=tanh(Wwht+bw)
(8)
(9)
s=∑tαtht
(10)
其中,Ww代表注意力层的权重矩阵,bw代表注意力层的偏置项,μw为随机初始化的数值,在训练学习阶段不断改变,αt为每个输入分配的独立权重,s为分配权重后的输出。
3.4 融合模型
隐式情感句的上下文信息可以辅助情感分类。如情感句“桌子上有一层灰”是贬义的,对该句进行情感分类,由于该句属于事实性陈述,会被误判成中性标签,而该句的上下文“很不高兴”则可以辅助该情感句的极性判别。当句子中不存在有直接情感倾向的词语时,可以寻找篇章内部与目标句相似的语句,如上下文“简直太脏了”“床铺也不整洁”等。文献[17]证明了BiGRU+Attention的组合在较长语句中获取重要特征的有效性,本文以此为出发点,采用BiGRU+Attention的组合对标签句的上下文重要特征进行提取。融合注意力机制与上下文特征的分类模型如图3所示。
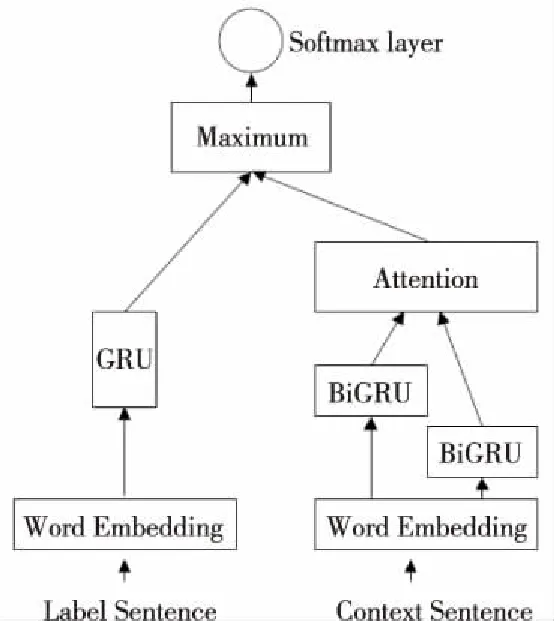
Figure 3 Classification model combining context and attentional mechanisms图3 融合上下文特征与注意力机制的分类模型图
(11)
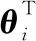
4 实验与分析
4.1 数据集
本文采用第八届全国社会媒体处理大会(SMP2019)举办的“拓尔思杯”中文隐式情感分析评测数据集进行实验。由于无法获得测试集的标注信息,仅采用了测评任务提供的训练集和验证集,将训练集按照4∶1的比例进行划分,用于模型的训练过程,将官方提供的验证集作为测试集,用于评估各个深度学习模型的性能。数据涉及微博、旅游网站、产品论坛等多个领域,主要的主题又包括春晚、雾霾、乐视、国考、旅游、端午节等。情感标签总共包含褒义、贬义和中性3种,标记的数据详细数量以及相关上下文信息如表3所示。其中,测评提供的训练集和验证集中包含共现的句子33个,本文选择在测试集中将其移除。

Table 3 Experimental data statistics 表3 实验数据统计
4.2 基础实验
在神经元的输出部分采用Dropout机制[25]来减弱网络的过拟合现象,共搭建了如下所述的几种基础分类模型:
(1)TextCNN。文献[9]首次将CNN网络应用在情感分类中。论文采用了拼接词向量的方法,将1个句子表示成为1个矩阵,矩阵的每1行表示1个word,构建不同尺寸的filter获取不同步长的词语特征,并将卷积后的特征通过最大池化层来进一步编码。本文在编码器部分采用了该文献提出的Static TextCNN和Non-static TextCN 2种模型。
(2)LSTM。由于长短期记忆网络可以获取词语之间的时序关系,文献[26]将该结构应用到aspect-level的情感分析中。本文采用基础的LSTM对词向量特征进行编码。
(3)BiGRU。双向GRU模型可以更好地获取句子双向编码特征,本文以其结构为基础,探索该结构在隐式情感倾向性分类中的表现。
(4)Attention-model。本文为各个基础模型添加了注意力机制,用于探索添加权重的注意力机制思想是否可以明显提升隐式情感句的分类效果。Model代表先前提到的Static TextCNN、Non-static TextCNN、LSTM和BiGRU模型。
4.3 实验流程
4.3.1 文本预处理
对实验得到的数据集进行初步的规则识别,分别提取出标签句子以及上下文,由于文本内容来源于网络,原始数据集中包含大量网络用语。在实验中发现,不合理的数据处理方式会降低各个模型的分类准确率,为了最大程度保留原始句子的语义信息,预处理阶段仅采用固定规则提取目标句子和句子上下文信息。在句子提取完成后,采用“结巴”分词工具对句子进行分词处理。
4.3.2 文本特征表示
使用文献[18]提供的具有Word+Character+Ngram特征的词向量集,该词向量的语料库来源于维基百科。在使用该向量表示时,未在词向量集中出现的文本统一用0填充。本文提出的模型输入为句子以及上下文,当单独句子无上下文信息时,用句子本身填充上下文。
4.3.3 模型参数设置
官方提供的数据集为训练集和测试集,训练集和测试集的比例大约为3∶1。将训练集按照4∶1的比例划分训练集和验证集,验证集用于判断分类模型的训练效果及调整参数。对所有模型进行3次重复实验,取平均值评估各模型的分类效果。模型中还包括一些超参数设置,如表4所示,其余参数均为默认值。
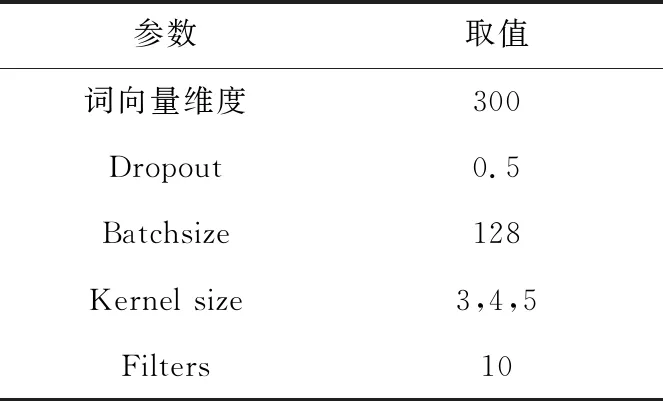
Table 4 Parameter setting表4 参数设置
4.3.4 评价标准
模型评估使用文本分类中常用到的准确率(P)、召回率(R)及F1值。在进行重复实验后,求得3个评价指标的平均值,并将其作为各个分类模型的最终评价标准。
4.4 实验结果
4.4.1 模型的训练
在模型训练过程中,为了选取泛化性较高的分类模型,采用不同的Epoch值训练各分类模型。首选对各模型进行较大数值Epoch的训练,根据模型训练日志确定大致的Epoch取值和模型在验证集上的准确率。在确定Epoch数值后,丢弃欠拟合与过拟合的训练模型,进行3次重复实验获取每个分类模型的平均性能。以其中1个分类模型为例,训练过程如图4所示。
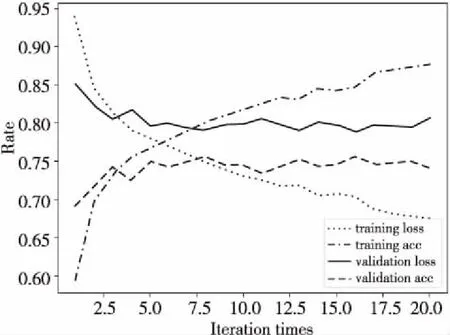
Figure 4 Model training process图4 模型训练过程
在第1次训练时,将Epoch数值设置为20。重复多次实验,发现当模型经过9次迭代后,验证集的准确率和损失率稳定在一个区间范围内。将模型Epoch取值设定为9,多次训练模型,舍弃其中欠拟合、过拟合以及未达到较好训练效果的分类模型。在获得训练结果较好的3个模型后,在测试集上对该分类模型进行测试,取各类别评价标准的平均值。
4.4.2 实验结果
本文使用基础分类模型、在基础模型上添加注意力的分类模型和融合模型对隐式情感句进行三元倾向性分类实验。情感倾向类别分别为褒义、中性和贬义。实验结果如表5所示,其中Static TextCNN和Non-static TextCNN为基础实验(1)中提到的模型,Attention-Static TextCNN 和Attention-non-static TextCNN 分别为在上述2种基础模型后添加注意力机制层;LSTM和BiGRU分别为基础实验(2)和(3)中提到的模型,Attention-LSTM和Attention-BiGRU分别为在上述2种基础模型后添加注意力机制层;Model proposed则为本文提出的模型。
从表5中可以看出,褒义类别的分类相较于其它2个类别更加困难。对比所有的分类模型可以发现,本文的融合上下文特征与注意力机制的分类模型在褒义类别分类上拥有最优的召回率与F1值,其它评价指标虽未达到最优,但均有良好的表现。对比结合注意力机制模型与对应的基础分类模型实验结果,可以发现当为句子分配不同权重后,句子的分类效果并未取得较明显的提升,在基础分类模型融合注意力机制后,部分评价指标有所提升。为了进一步研究各分类模型对褒义类别识别效果较差的原因,对所有分类模型的预测结果进行混淆矩阵的研究,仅列举提出的融合模型混淆矩阵,如表6所示。
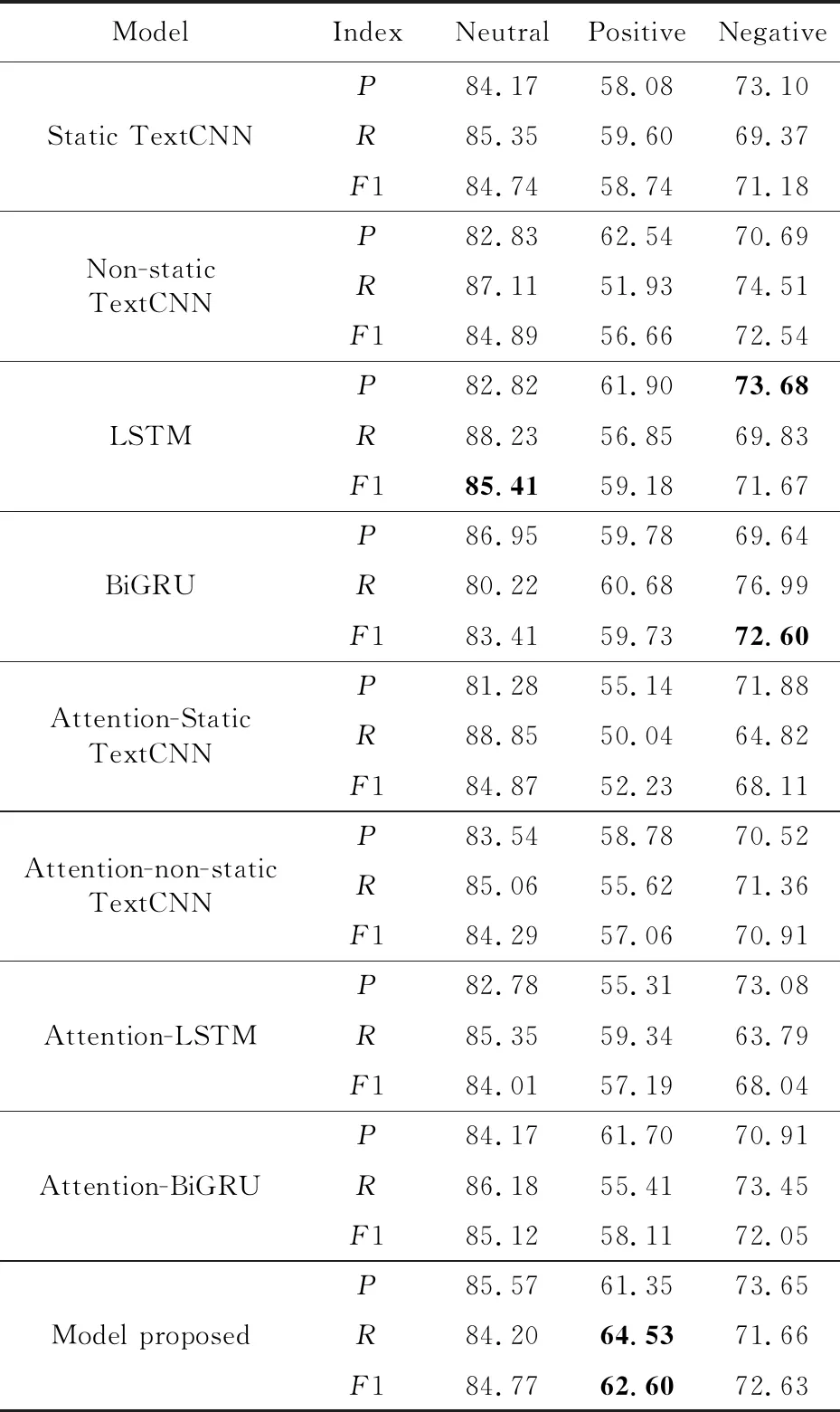
Table 5 Experiment results of classification model 表5 分类模型实验结果
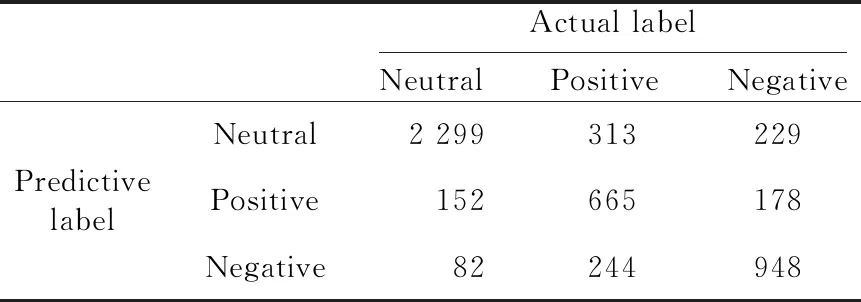
Table 6 Confusion matrix of classification model 表6 分类模型混淆矩阵
从表6中可以发现,褒义类别被误分成其它2个类别的比例大致相同。在实际的研究中发现,所有的分类模型尽管在数值上有所差异,但在褒义类别的识别上有相似的特点,即被误分成其它2个类别的比例大致相同。对具体的褒义文本进行研究,发现句子本身所带的褒义情感特征不是很明显,如表7所示,所有的分类模型在该类别特征识别上都未取得良好的效果。
为了更加直观地比较各模型的性能,统计各分类模型的平均准确率、召回率和F1值,实验结果如表7所示。
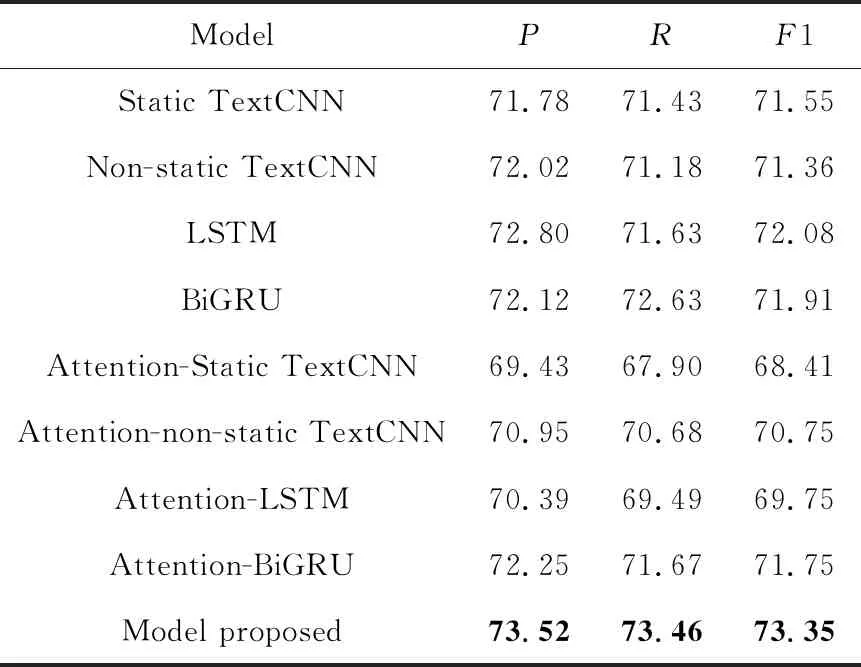
Table 7 Macro average accuracy,recall rate and F1 value of each classification model 表7 各分类模型宏平均准确率、召回率和F1值
从表7中可以看出,提出的融合上下文和注意力机制的分类模型在准确率、召回率和F1值上取得了最优的效果,在准确率上比最优的基础分类模型提升了0.72%,在召回率上提升了0.83%,在F1值上提升了1.27%,从而验证了融合上下文特征和注意力机制分类模型的有效性。
4.4.3 典型难句分析
为了进一步分析本文的融合模型在提取上下文特征辅助隐式情感分类的有效性,从数据集中抽取一些典型的难句进行分类结果对比分析,如表8所示。
表8中,其它模型代表大部分模型识别出的结果,差异结果代表占较小比例分类模型识别的结果。从表8中可以看出,所提出的模型具备一定的优势与不足。在模型学习过程中,融合模型对句子进行判别时吸纳了更多的信息,因而在对某一类别进行判定时可以拥有更好的识别性能,如ID为1、2、4的结果。当标签句子的上下文与标签句子类别不同时,上下文内容会对标签句子的判别产生一定的误导作用,如ID为3、5的结果。融合模型的两处设计对这一误导现象产生一定的抑制作用。在上下文特征与注意力机制思想的融合部分,所使用的注意力机制思想会为上下文特征分配一定比例的权重,其次在Maximum层会取2个特征层中的最大值,当标签句子特征大于上下文的特征时,上下文特征会被舍弃。实验结果也表明了本文模型在一定程度上可以提升隐式情感文本的分类效果。
5 结束语
本文提出了一种融合上下文特征与注意力机制的分类模型,并基于TextCNN、LSTM和BiGRU和注意力机制对隐式情感句的分类进行了研究。由于隐式情感句与显式情感句在表达上的差异,所提出的模型可以提升隐式情感句的分类效果。与普通的分类模型和注意力机制模型相比,本文的融合模型可以提取更多有价值的信息。在公开数据集上的实验结果表明,本文的融合模型在准确率、召回率和F1值上优于已有的基础分类模型和注意力机制模型。从实验结果可以看出,尽管本文模型提升了基础分类模型的预测效果,但在上下文特征辅助标签句情感判别上仍具备一定的局限性。所以,接下来的工作将着重研究基于上下文特征语义相似度的分类模型,以达到更好的分类效果。

Table 8 Typical difficult examples表8 典型难句举例
